大语言模型原理简解(LLM)
一、开场引子:什么是大语言模型(LLM)?
大语言模型(LLM, Large Language Models)是当前人工智能领域最为热门的技术之一。它们基于深度学习,能够理解和生成自然语言,广泛应用于文本生成、自动翻译、聊天机器人等领域。与传统的自然语言处理模型不同,大语言模型具有超强的文本生成能力和上下文理解能力,能够完成复杂的语言任务。
本文将带你走进大语言模型的世界,介绍其基本原理、训练方法及其应用。
二、大语言模型的基本原理
大语言模型的核心原理是基于深度神经网络,特别是Transformer架构,来处理和生成自然语言。Transformer 模型通过自注意力机制(Self-Attention)能够捕捉句子中词汇之间的关系,并通过多层堆叠的编码器和解码器对语言进行建模。
1. Transformer 模型
Transformer 是一种基于注意力机制的模型架构,它能够处理长文本中的远距离依赖关系,比传统的循环神经网络(RNN)更为高效。
-
自注意力机制(Self-Attention):通过计算词语之间的相关性,捕捉文本中的长距离依赖。
-
编码器-解码器结构(Encoder-Decoder):Transformer 的基础结构,由编码器和解码器组成,用于输入和输出序列的处理。
推荐链接:
-
Transformer模型介绍
图示:Transformer架构示意图
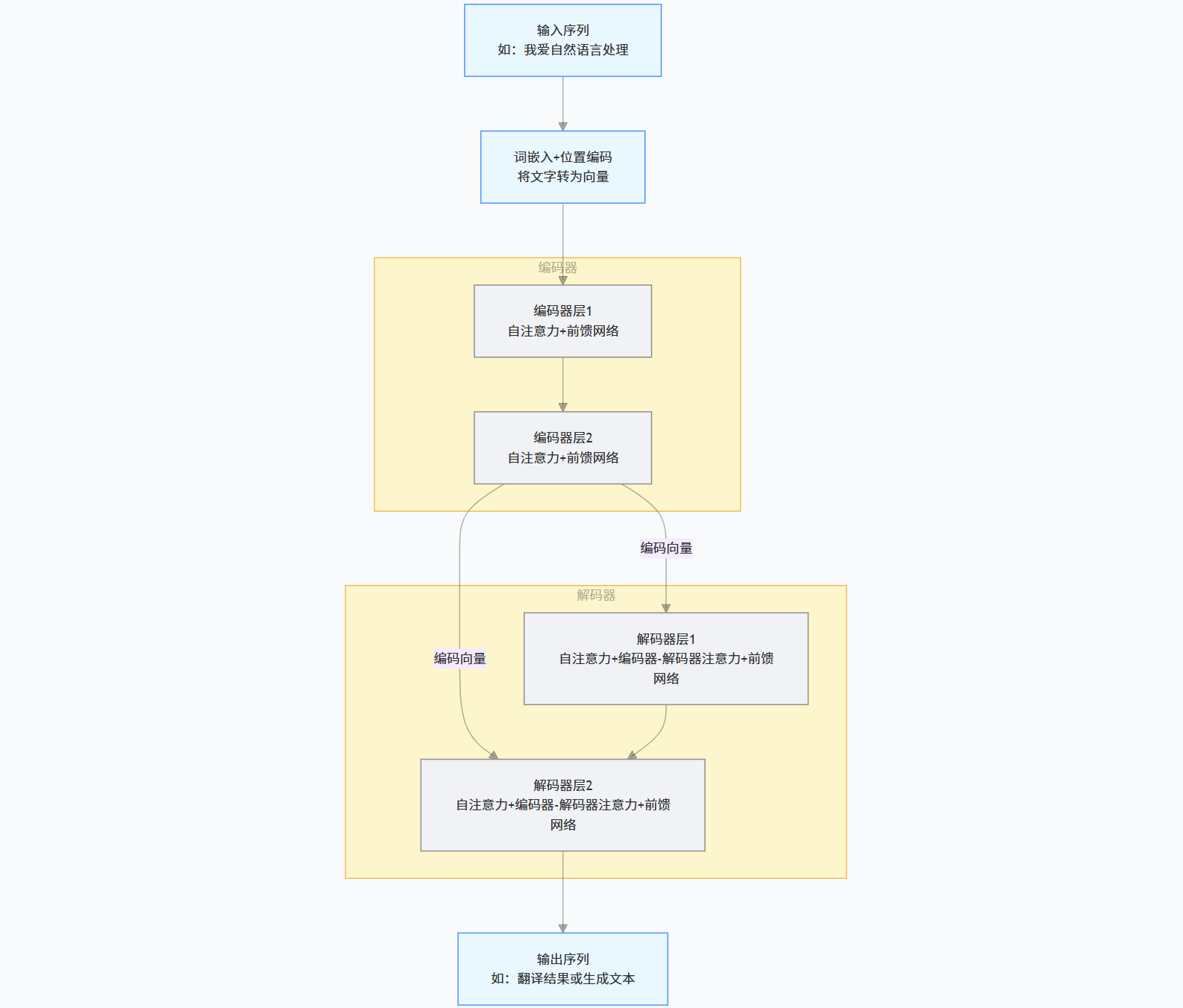
图解:Transformer模型的编码器-解码器结构。
2. 语言模型的训练:从数据到推理
大语言模型的训练过程包括数据收集、预处理和模型优化。大语言模型通常在大规模的文本数据上进行训练,使用的是自监督学习方法,即通过预测文本中的下一个词来学习语言的规律。
-
训练目标:通过输入文本数据,模型学习到如何生成流畅的、符合语法和语义的句子。
-
模型规模:大语言模型通常具有数以亿计甚至以千亿计的参数,使得它们能够更好地理解语言的深层次含义。
推荐链接:
-
大语言模型训练方法
三、大语言模型的关键特性
1. 预训练与微调(Fine-Tuning)
大语言模型的训练通常分为两个阶段:预训练和微调。
-
预训练:模型首先在大规模的无标签文本数据上进行预训练,学习词语之间的关系和语言的结构。
-
微调(Fine-Tuning):在特定任务(如情感分析、翻译等)上进行微调,使得模型能够更好地适应特定任务的需求。
推荐链接:
-
微调技术
2. 自监督学习(Self-Supervised Learning)
自监督学习是一种训练方法,通过让模型自己从数据中创建标签进行学习。在大语言模型中,通常采用**掩蔽语言建模(Masked Language Modeling, MLM)或自回归语言建模(Autoregressive Language Modeling)**等方法进行训练。
-
掩蔽语言建模(MLM):模型预测文本中被遮盖的部分。
-
自回归语言建模:模型预测文本中下一个词的概率,常用于生成任务。
图示:掩蔽语言建模与自回归建模示意图
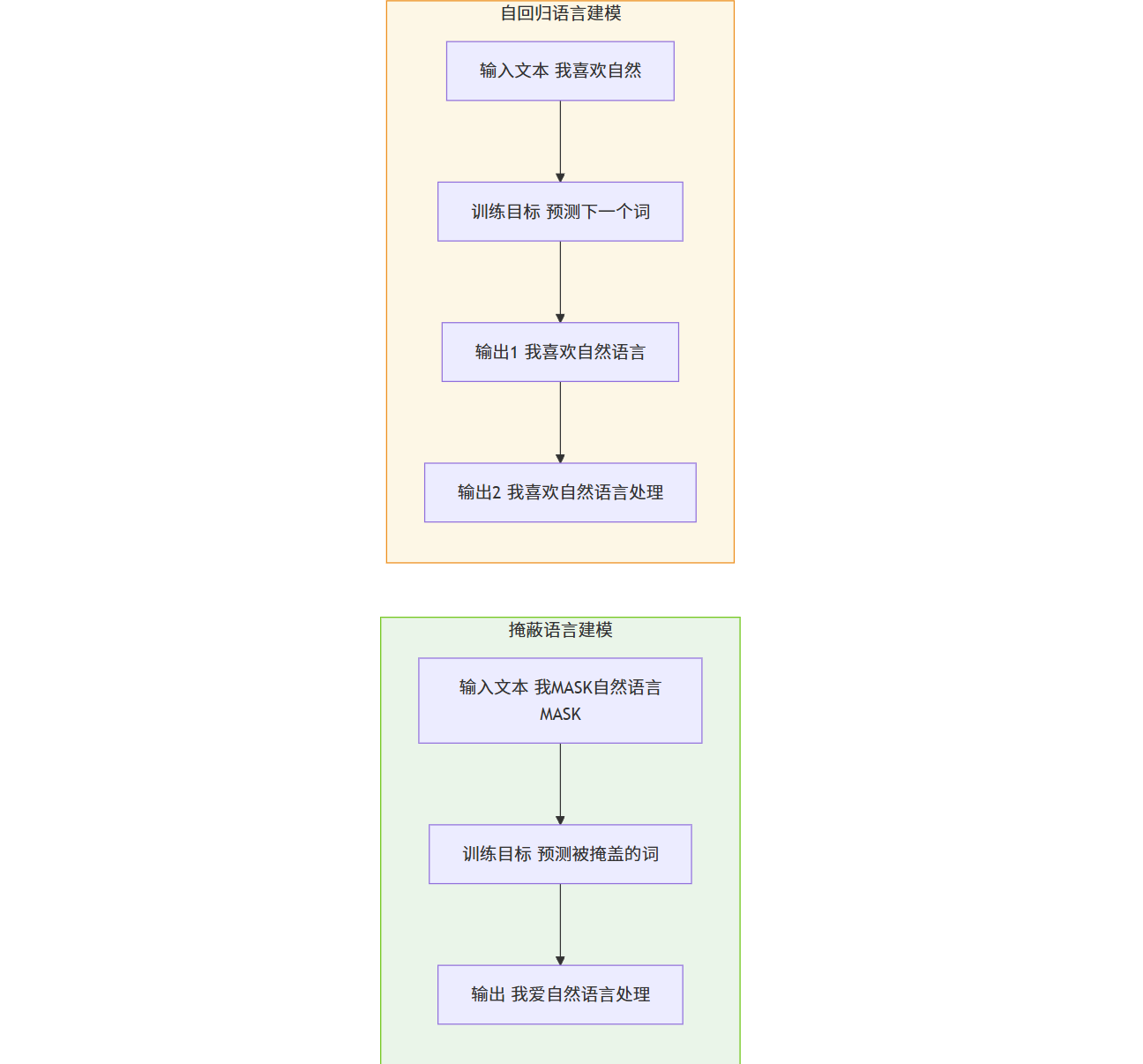
图解:掩蔽语言建模与自回归语言建模的区别。
四、大语言模型的应用
大语言模型的应用非常广泛,几乎涵盖了所有需要语言理解和生成的任务。以下是一些主要应用场景:
1. 文本生成与创作
大语言模型能够自动生成自然流畅的文本,广泛应用于文章撰写、诗歌创作、广告文案生成等领域。
-
应用实例:GPT 系列模型能够根据输入的提示生成与之相关的文本,广泛应用于自动化写作、内容创作等。
2. 自动翻译
通过大语言模型,机器翻译的质量有了极大的提升。模型不仅能够处理单词和语法,还能够理解上下文中的隐含含义。
-
应用实例:Google Translate 使用深度学习和大语言模型进行多语言的自动翻译,准确性不断提高。
3. 问答系统与聊天机器人
大语言模型使得聊天机器人能够进行更自然、流畅的对话。它们不仅能回答用户提出的问题,还能够生成与上下文相关的回答。
-
应用实例:ChatGPT 和其他基于 Transformer 的模型可以进行复杂的对话,处理用户的各种查询。
推荐链接:
-
GPT-3 和问答系统
4. 情感分析与文本分类
大语言模型在文本分类和情感分析中表现出色。通过对文本进行分类,模型可以判断文本的情感倾向,如积极、消极或中立。
-
应用实例:社交媒体分析、客户反馈分析等。
五、大语言模型的挑战与未来发展
尽管大语言模型在许多任务上表现出色,但它们仍然面临许多挑战,如:
-
计算成本高:训练大语言模型需要庞大的计算资源和数据。
-
理解深度有限:虽然大语言模型能够生成自然语言,但它们在理解语境、推理能力等方面仍然存在一定局限。
-
道德与偏见问题:大语言模型可能会在生成文本时放大偏见,产生不当内容。
未来,大语言模型的发展将更加注重提升模型的推理能力和多模态能力(即结合视觉、语言等多种输入)。同时,随着计算效率的提升,未来的模型将更加高效,并能够处理更多复杂的任务。
六、总结
大语言模型(LLM)是人工智能领域的重要突破,广泛应用于文本生成、翻译、问答系统等多个领域。通过深度学习的技术,尤其是 Transformer 模型,LLM 使得机器能够理解和生成语言。未来,随着技术的不断发展,大语言模型将变得更加智能,应用场景也将更加广泛。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)