DeepRare 中文实战教程:基于大语言模型的罕见病诊断系统安装与使用完整指南
你手头有一份复杂的罕见病病例,症状描述、HPO术语、基因检测结果混杂在一起,想快速生成一个可解释的鉴别诊断列表?今天介绍的这个工具,就是你的“诊断外挂”。DeepRare 是一个基于大语言模型的多智能体系统,它能整合超过40个专业工具和最新的医学知识源,处理多种临床输入,生成带有透明推理链的排名诊断假设。简单说,它能把复杂的诊断过程自动化、可追溯化,帮你从海量信息中快速定位方向。这篇教程将手把手带
工具信息
- 名称:DeepRare
- GitHub:https://github.com/MAGIC-AI4Med/DeepRare
- 语言:Python
你手头有一份复杂的罕见病病例,症状描述、HPO术语、基因检测结果混杂在一起,想快速生成一个可解释的鉴别诊断列表?今天介绍的这个工具,就是你的“诊断外挂”。DeepRare 是一个基于大语言模型的多智能体系统,它能整合超过40个专业工具和最新的医学知识源,处理多种临床输入,生成带有透明推理链的排名诊断假设。简单说,它能把复杂的诊断过程自动化、可追溯化,帮你从海量信息中快速定位方向。这篇教程将手把手带你把它跑起来。
1. 环境准备与安装
首先,我们需要准备好运行环境。DeepRare 主要依赖 Python,并且需要 Java 环境来运行其集成的 Exomiser 工具(如果你需要进行基因层面的分析)。请确保你的系统满足以下条件:
- 操作系统:64位 Windows, Linux 或 macOS。
- 内存:至少 16GB,推荐 32GB。
- Python:版本 3.8 或更高。
- Java:版本 21 或更高(用于 Exomiser)。
第一步:克隆代码仓库并安装 Python 依赖
打开你的终端(Windows 用户请使用 PowerShell 或 CMD),执行以下命令:
# 1. 克隆 DeepRare 仓库到本地
git clone https://github.com/MAGIC-AI4Med/DeepRare.git
# 2. 进入项目目录
cd DeepRare
# 3. 安装所有必需的 Python 包(这个过程可能需要一些时间)
pip install -r requirements.txt
第二步:配置 ChromeDriver
DeepRare 的部分工具需要浏览器自动化来获取网页信息,因此需要安装 ChromeDriver。请根据你的操作系统操作:
- 首先,查看你电脑上 Chrome 浏览器的版本(在 Chrome 设置 -> 关于 Chrome 中查看)。
- 访问 ChromeDriver 下载页面,下载与你 Chrome 版本匹配的驱动程序。
- 解压下载的文件。
- Linux/macOS 用户:将解压出的
chromedriver文件移动到系统路径并赋予执行权限。sudo mv chromedriver /usr/local/bin/ sudo chmod +x /usr/local/bin/chromedriver # 验证安装 chromedriver --version - Windows 用户:将解压出的
chromedriver.exe文件放在一个你记得的目录下,例如C:\chromedriver\。后续运行脚本时需要指定这个路径。
第三步:(可选)安装 Exomiser
如果你计划使用 DeepRare 的基因分析功能(处理 HPO+基因型输入),则需要安装 Exomiser。这是一个独立的 Java 程序。以下以 Linux/macOS 为例,Windows 用户请参考 README 中的链接下载预编译包。
# 下载 Exomiser 程序包和数据文件(数据文件很大,约20GB,请确保网络和磁盘空间)
wget https://data.monarchinitiative.org/exomiser/latest/exomiser-cli-14.1.0-distribution.zip
wget https://data.monarchinitiative.org/exomiser/latest/2410_hg19.zip
wget https://data.monarchinitiative.org/exomiser/latest/2410_hg38.zip
wget https://data.monarchinitiative.org/exomiser/latest/2410_phenotype.zip
# 解压程序包
unzip exomiser-cli-14.1.0-distribution.zip
# 解压数据文件到程序目录下的 data 文件夹
unzip 2410_*.zip -d exomiser-cli-14.1.0/data
安装完成后,建议将 Exomiser 的可执行文件路径(例如 exomiser-cli-14.1.0/bin/exomiser-cli)添加到系统的 PATH 环境变量,或者记住它的绝对路径。
第四步:获取 LLM API 密钥
DeepRare 的核心“大脑”是大语言模型。你需要至少一个 LLM 服务的 API 密钥。系统支持 OpenAI, Anthropic Claude, Google Gemini, DeepSeek 等。这里以获取 OpenAI 的 API Key 为例:
- 访问 OpenAI 平台,注册/登录。
- 在 API Keys 页面,创建一个新的密钥并复制下来。
- 在你的终端中,设置环境变量(每次打开新终端都需要设置,或写入
~/.bashrc等配置文件)。
Windows (PowerShell) 用户:export OPENAI_API_KEY='你的-api-key-字符串'$env:OPENAI_API_KEY='你的-api-key-字符串'
2. 核心功能演示:基于 HPO 术语进行诊断推理
DeepRare 最核心的功能是接收临床输入,输出诊断假设。输入可以是自由文本、结构化的人类表型本体(HPO)术语,或者 HPO 术语加上基因型。我们这里演示最常用的场景:输入一组 HPO 术语,让系统进行诊断推理。
首先,我们需要下载 DeepRare 运行所需的知识库数据。项目提供了一个 Hugging Face 数据集。
# 在 DeepRare 项目根目录下执行
# 使用 huggingface-cli 工具下载数据库文件
huggingface-cli download Angelakeke/DeepRare --repo-type=dataset --local-dir ./database
接下来,我们来看如何运行一个完整的诊断流程。项目提供了方便的 Shell 脚本。我们需要先配置脚本。
打开项目根目录下的 inference.sh 文件,你需要修改几个关键配置:
# 以下是 inference.sh 文件中需要你修改的部分示例
export OPENAI_API_KEY="sk-..." # 替换为你的真实 API 密钥
# 如果你使用其他模型,比如 Claude,则设置 ANTHROPIC_API_KEY
# export ANTHROPIC_API_KEY="your_key_here"
CHROMEDRIVER_PATH="/usr/local/bin/chromedriver" # Linux/macOS 用户,如果 chromedriver 在 PATH 里,可以直接写 `chromedriver`
# Windows 用户示例:CHROMEDRIVER_PATH="C:\chromedriver\chromedriver.exe"
# 输入文件路径。系统自带了一个示例输入文件 `./database/test.json`
INPUT_FILE="./database/test.json"
# 输出结果将保存在这个目录
OUTPUT_DIR="./results"
现在,让我们看看这个示例输入文件 ./database/test.json 里是什么结构。你可以用文本编辑器打开它。它定义了患者的表型信息(HPO术语)。
// 文件:./database/test.json
// 这是一个示例输入,定义了一个患者的 HPO 表型列表
{
"hpo": ["HP:0001250", "HP:0000252", "HP:0004322", "HP:0001249", "HP:0100543"] // 这里是一组 HPO ID
// HPO:0001250 代表“癫痫发作”, HP:0000252 代表“小头畸形”等等。
}
配置好脚本后,在终端运行它:
# 在 DeepRare 项目根目录下,赋予脚本执行权限(首次运行需要)
chmod +x inference.sh
# 运行诊断推理脚本
bash inference.sh
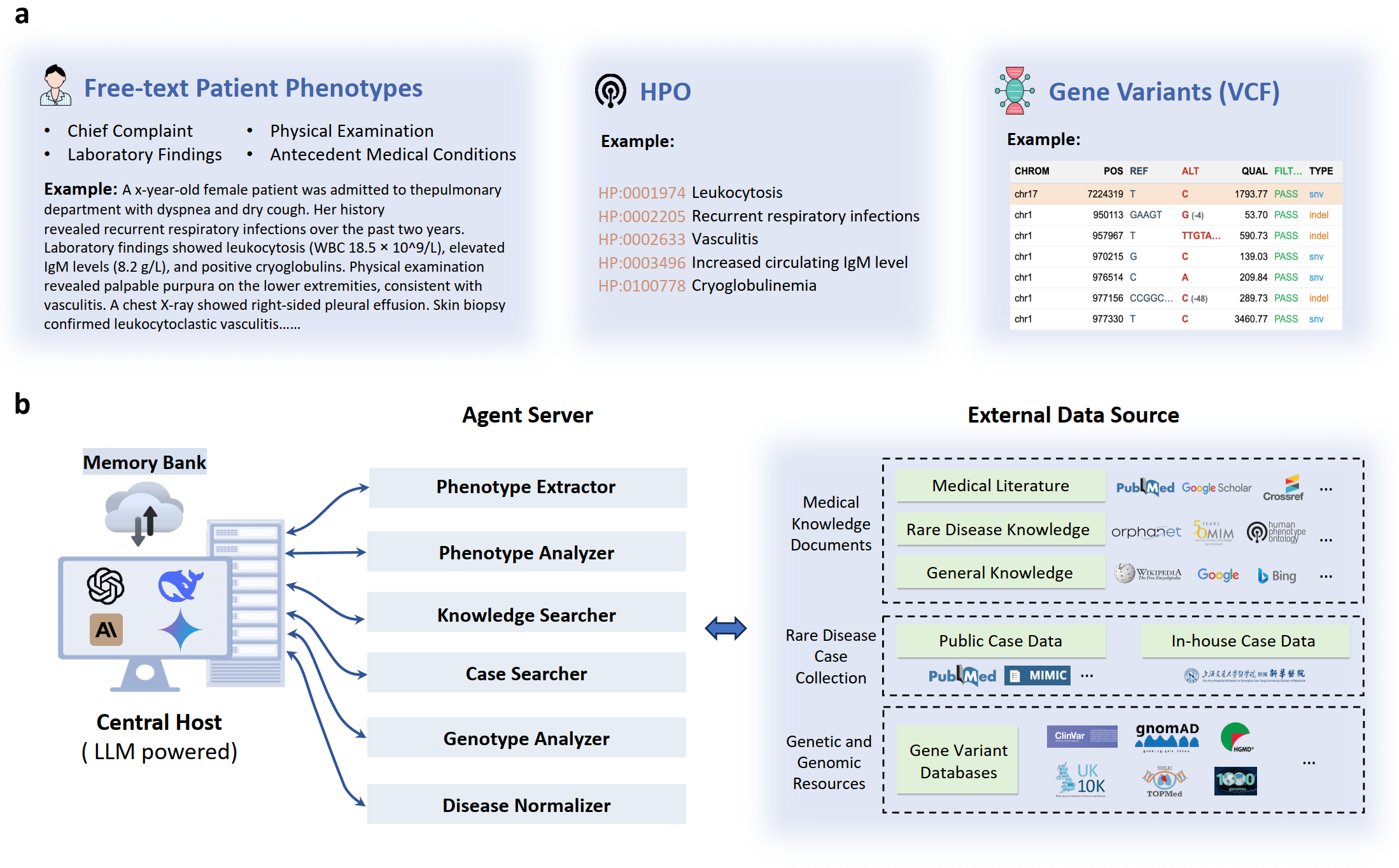
当脚本运行时,DeepRare 系统会启动:
- 中央主机(LLM) 会读取输入的 HPO 列表。
- 它会调用不同的专业智能体服务器,例如:
omim_search.py:查询 OMIM 数据库获取疾病信息。pubcase_finder.py:在病例报告库中寻找相似病例。search_pubmed.py:检索最新的相关医学文献。hpo_search.py:深入查询 HPO 本体的关系。
- 每个智能体使用其专业工具完成任务,并将证据返回给中央主机。
- 中央主机综合所有证据,进行多轮推理,最终生成排名的诊断假设列表和完整的推理链。
3. 运行效果说明
脚本运行完成后,结果会保存在你指定的 OUTPUT_DIR(默认为 ./results)目录下。输出可能是一个 JSON 文件或结构化的文本报告。
典型的输出会包含:
- 排名靠前的疾病诊断:例如“Rett syndrome”、“MECP2 duplication syndrome”等,每个疾病会有一个置信度分数或排名。
- 支持该诊断的证据:例如,引用了哪些 OMIM 条目、哪些 PubMed 文章 ID、与哪些 HPO 术语匹配。
- 透明的推理链:以自然语言描述系统是如何一步步从症状推导到这个诊断的,例如:“患者有小头畸形(HP:0000252)和癫痫发作(HP:0001250),这常见于MECP2相关疾病。通过查询OMIM发现Rett综合征(OMIM:312750)完全符合这些表型…”。
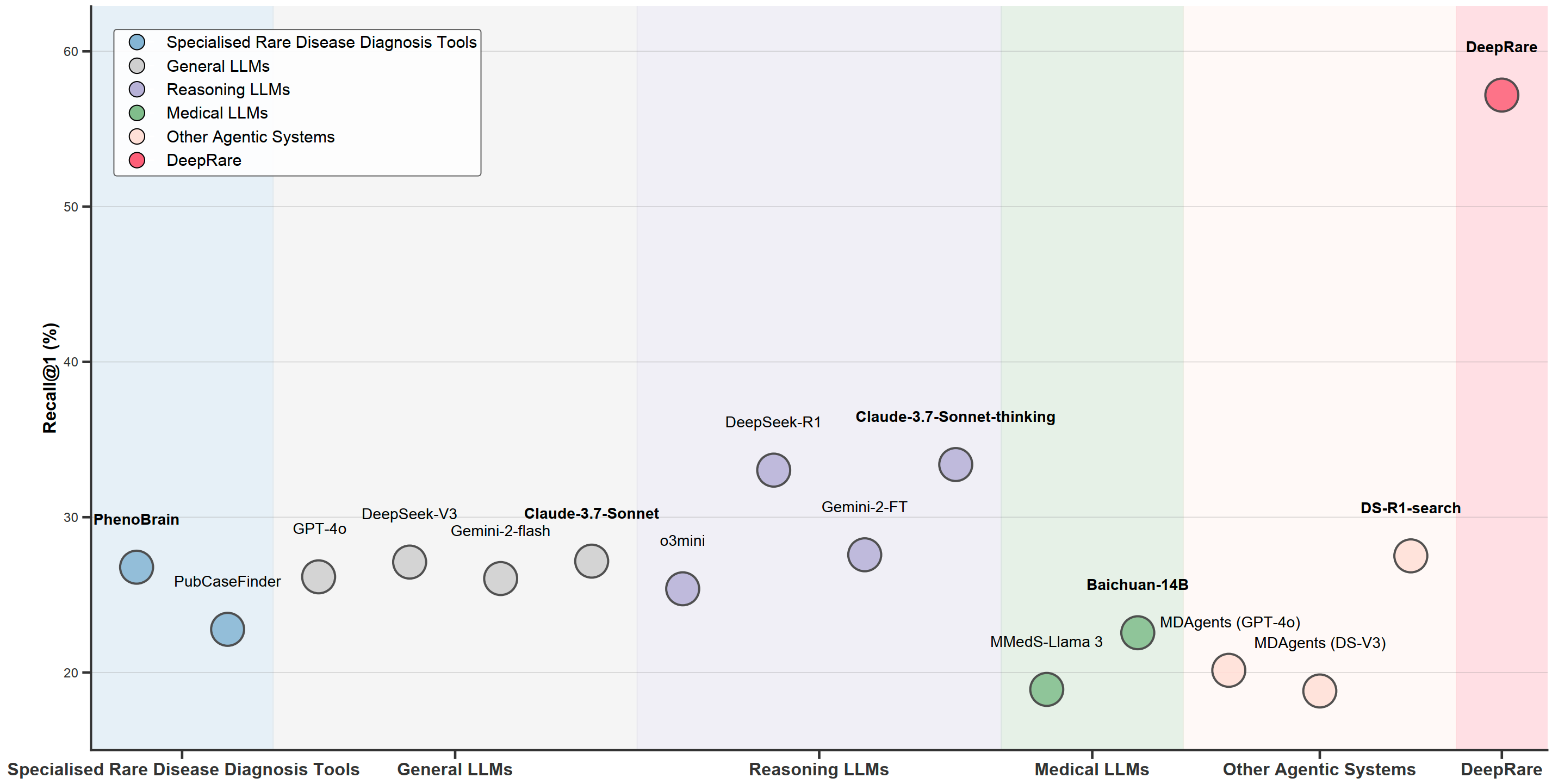
这个输出不仅给出了诊断方向,更重要的是提供了可追溯、可验证的理由,这对于临床决策支持和科研分析至关重要。
4. 处理自由文本临床描述
如果你的输入是一段自由的临床文本描述(例如出院小结的主诉部分),DeepRare 也提供了预处理功能,可以从中自动提取 HPO 术语。使用项目提供的另一个脚本:
# 运行自由文本提取 HPO 的脚本
bash extract_hpo.sh
这个脚本会调用 hpo_extractor.py 等模块,利用 LLM 将非结构化的文本“翻译”成结构化的 HPO ID 列表,为后续的诊断推理做准备。
小结与适用场景
DeepRare 是一个强大的、模块化的罕见病辅助诊断研究工具。它特别适用于以下场景:
- 临床研究者:对疑难病例进行快速的、基于证据的鉴别诊断筛查,辅助生成研究假设。
- 生物信息学分析:在完成基因测序(如外显子组测序)后,将候选基因变异与患者表型(HPO)结合,进行优先排序和解读。
- 医学教育:通过其透明的推理链,学习罕见病与表型之间的复杂关联。
完整用法、基因分析模式 (inference_gene.sh) 以及系统评估脚本 (eval.sh) 的详细说明,请务必参考项目官方 README 文档。
常见问题提示
- 网络问题:DeepRare 的许多工具需要访问外部数据库和搜索引擎(PubMed、OMIM等)。请确保你的网络环境能够顺畅访问这些国际学术网站,否则可能触发重试或超时错误。
- API 费用与速率限制:使用商业 LLM API(如 OpenAI)会产生费用,并且有调用频率限制。对于大量病例的分析,请关注你的 API 使用量和成本。可以考虑使用 DeepSeek 等性价比更高的 API,或者按照 README 指导配置本地模型。
- Exomiser 数据路径:如果你使用基因分析功能,务必在运行
inference_gene.sh前,检查并正确配置 Exomiser 的安装路径和数据路径,否则基因分析模块将无法工作。
本文首发于微信公众号【生信之灵】
欢迎关注,一起探索生信前沿!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)