2026年1~2月发布的十个开源大语言模型
如果要总结 2026 年春季这一轮架构趋势,可以说整体仍然是以自回归 Transformer 为核心。目前还没有完全颠覆性的全新架构出现(当然,DeepSeek V4 还没发布)。不过可以看到一个明显趋势:越来越多模型从更传统的 GQA 转向 MLA,甚至混合线性注意力结构。这意味着效率(更低延迟和更好的长上下文扩展能力)正变得越来越重要。Sebastian Raschka在X上按时间顺序梳理了一
如果要总结 2026 年春季这一轮架构趋势,可以说整体仍然是以自回归 Transformer 为核心。目前还没有完全颠覆性的全新架构出现(当然,DeepSeek V4 还没发布)。不过可以看到一个明显趋势:越来越多模型从更传统的 GQA 转向 MLA,甚至混合线性注意力结构。这意味着效率(更低延迟和更好的长上下文扩展能力)正变得越来越重要。
Sebastian Raschka在X上按时间顺序梳理了一下2026年1~2月开源的大模型,并重点关注这些大模型的架构设计。
如果要总结 2026 年春季这一轮架构趋势,可以说整体仍然是以自回归 Transformer 为核心。目前还没有完全颠覆性的全新架构出现(当然,DeepSeek V4 还没发布)。不过可以看到一个明显趋势:越来越多模型从更传统的 GQA 转向 MLA,甚至混合线性注意力结构。这意味着效率(更低延迟和更好的长上下文扩展能力)正变得越来越重要。
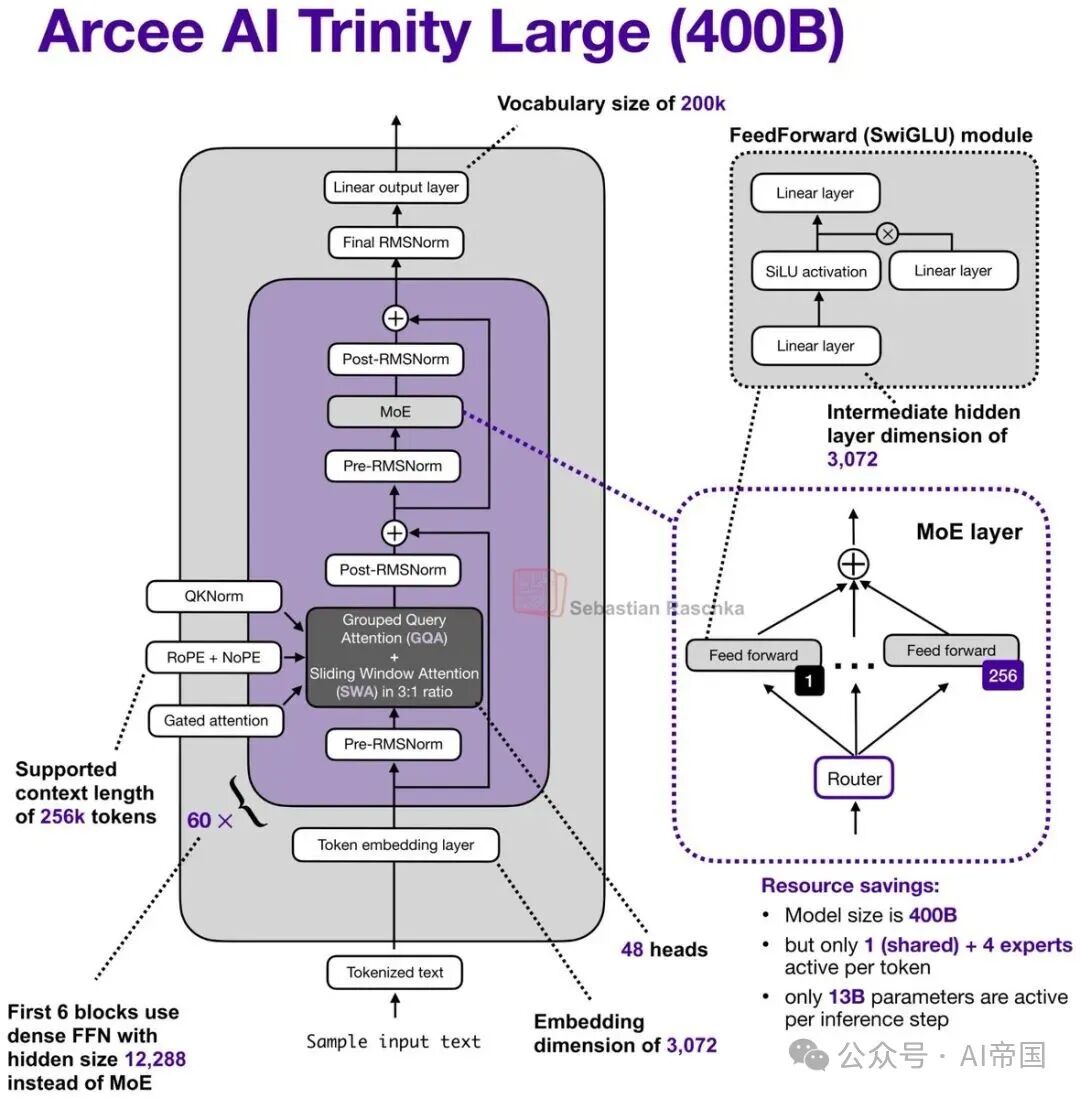
1.Arcee AI Trinity Large(1月27日)
Arcee 的 Trinity 系列对很多人来说几乎是“横空出世”。这是一个 400B 的 MoE 模型(13B 激活参数),同时还发布了两个更小的变体版本。
在架构上,它结合了几种熟悉的组件:Mixture-of-Experts(MoE)+ Grouped Query Attention(GQA)+ Sliding Window Attention(SWA)。
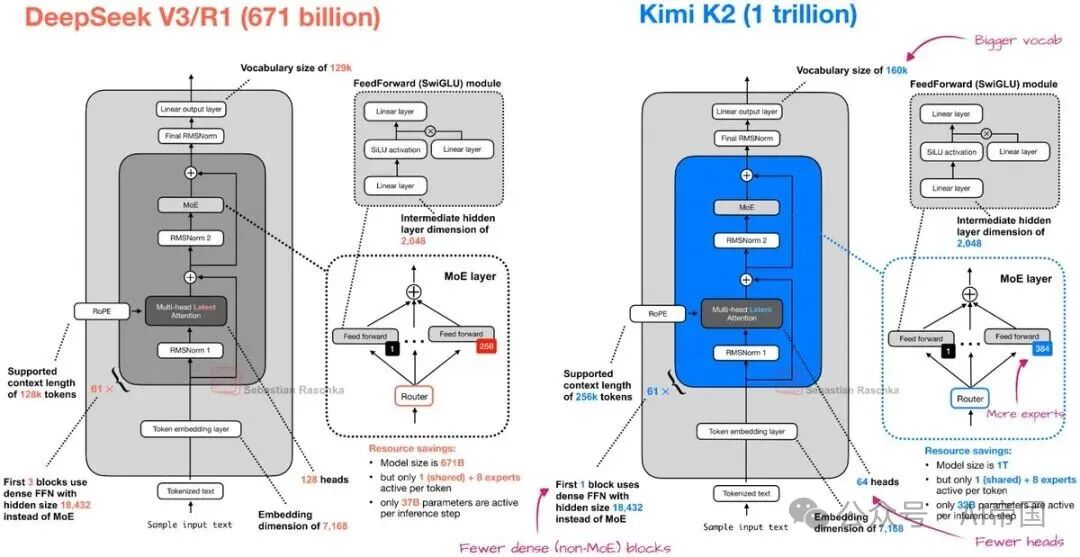
2.Kimi K2.5(1月27日)
与 Kimi K2 类似,Kimi K2.5 是目前最大的开放权重模型之一,参数规模达到 1 万亿。同样类似于 Kimi K2,它采用了类似 DeepSeek 的架构模板。
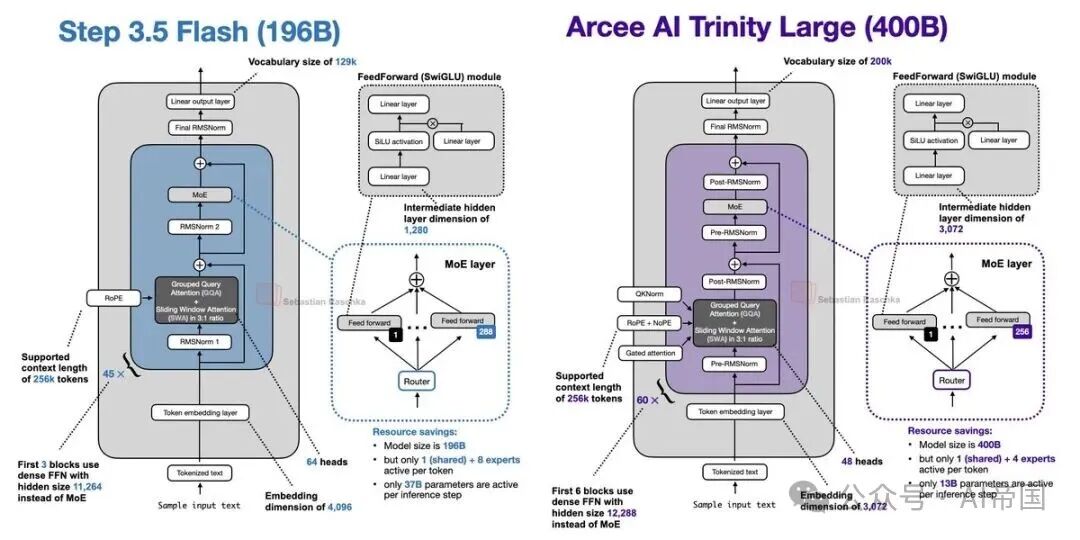
3.StepFun Step 3.5 Flash(2月1日)
Step 3.5 Flash 主要关注性能与吞吐量之间的平衡。整体来看,它在架构上与 Arcee Trinity 有些相似,同样使用 GQA + SWA,但模型规模小了大约一半。
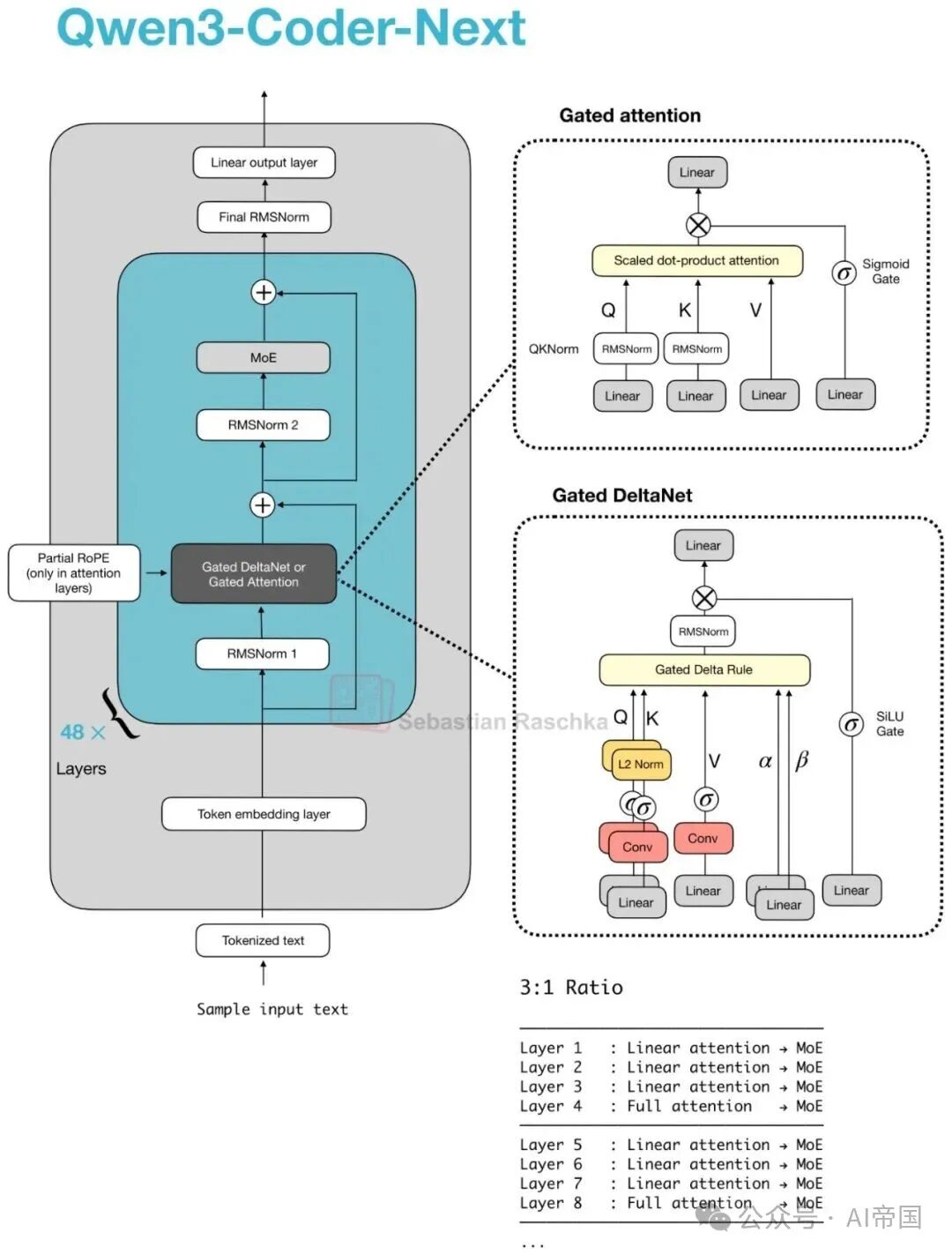
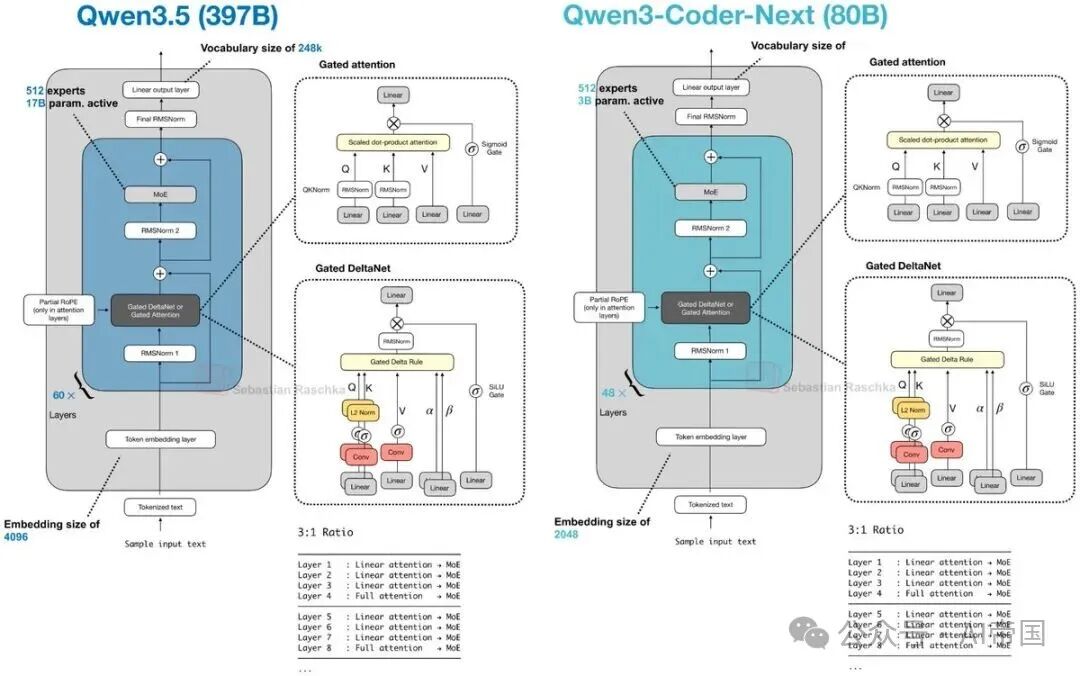
4.Qwen3-Coder-Next(2月3日)
Qwen3-Coder-Next 延续了 Qwen 在代码模型上对混合注意力(hybrid attention)的关注。其架构(以及规模)与此前的 80B Qwen3-Next 模型类似,只是针对代码场景进行了微调。
5.GLM-5(2月12日)
GLM-5 是一个旗舰级发布版本,整体遵循当前“大规模 MoE + 效率优化”的主流共识。它也引入了一些受 DeepSeek 启发的设计(例如 MLA 和 DeepSeek Sparse Attention)。
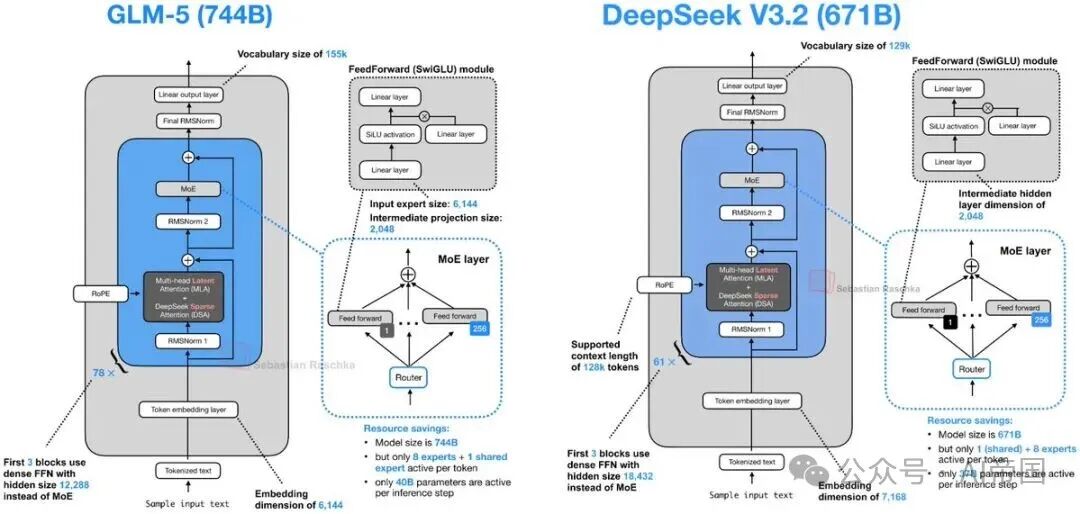
6.MiniMax M2.5(2月12日)
MiniMax M2.5 特别有意思的一点在于,它性能很强,但在架构上依然相当经典,主要使用的是标准 GQA。
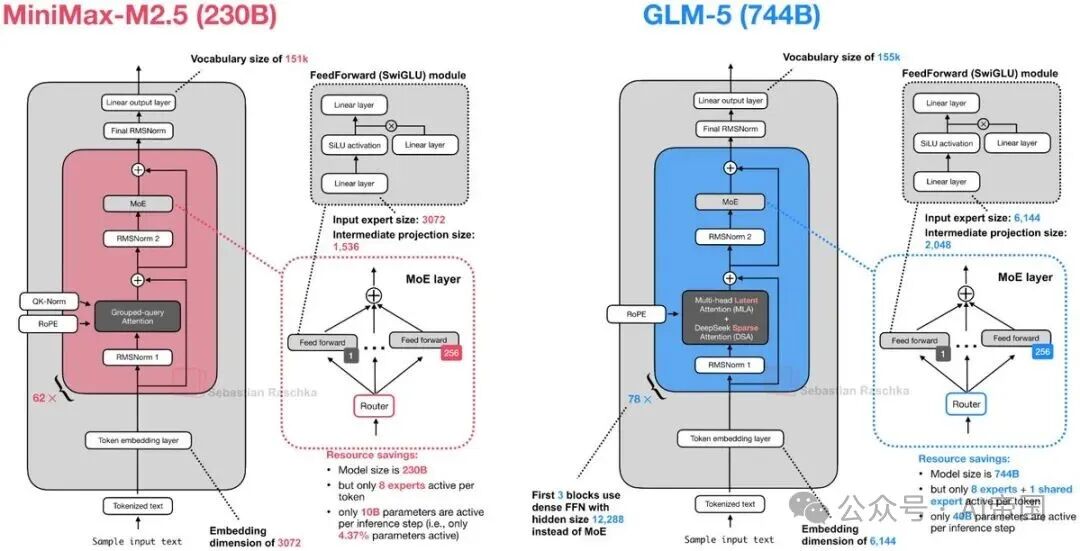
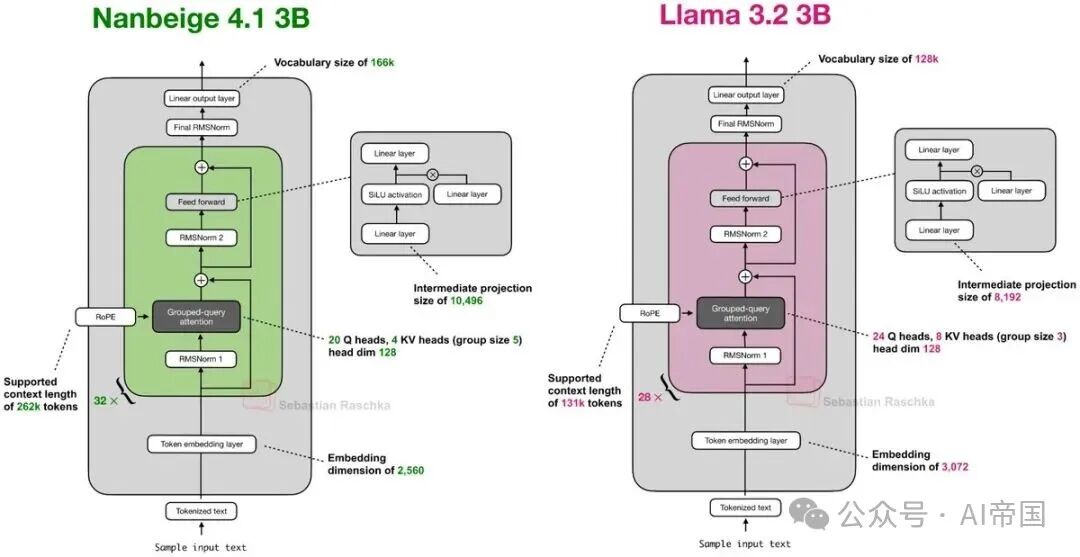
7.Nanbeige 4.1 3B(2月13日)
Nanbeige 4.1 3B 是这一波发布中较有代表性的“小模型”之一。本质上,它是一种 Llama 3 风格的模型(类似于 Qwen3 的 dense 模型)。
8.Qwen3.5(2月15日)
Qwen3.5(397B-A17B)值得关注,因为看起来 Qwen 团队也开始在其主线(非 Next 系列)中采用混合注意力机制。
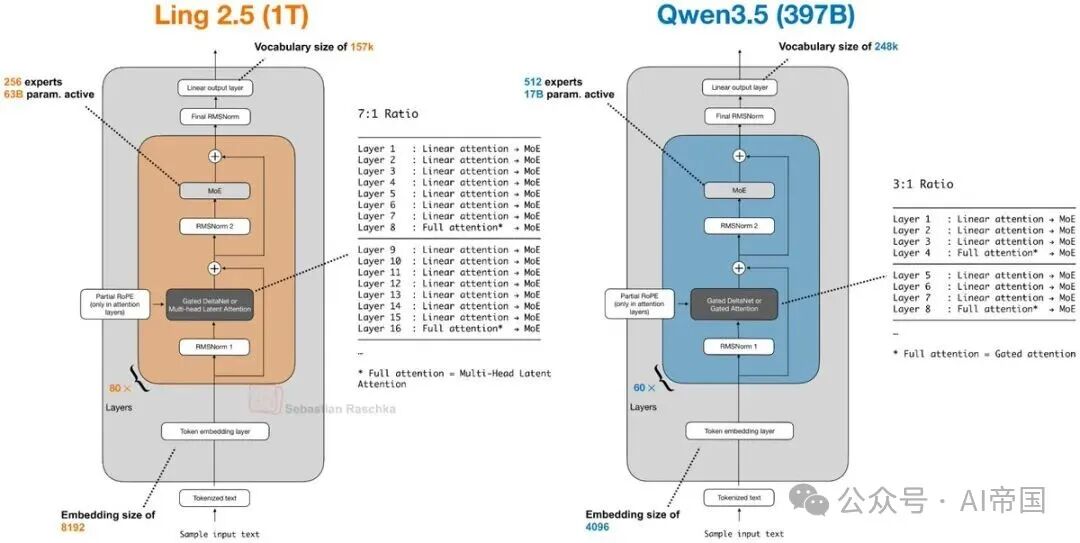
9.Ling 2.5 / Ring 2.5(2月16日)
与 Kimi 类似,Ling/Ring 2.5 也是一个 1 万亿参数的 MoE 模型。它采用了一种混合方案:Lightning Attention + MLA 风格压缩。它与 Qwen3.5 有些类似,但使用的是稍微更简单的线性注意力变体(相较于 Gated DeltaNet)。
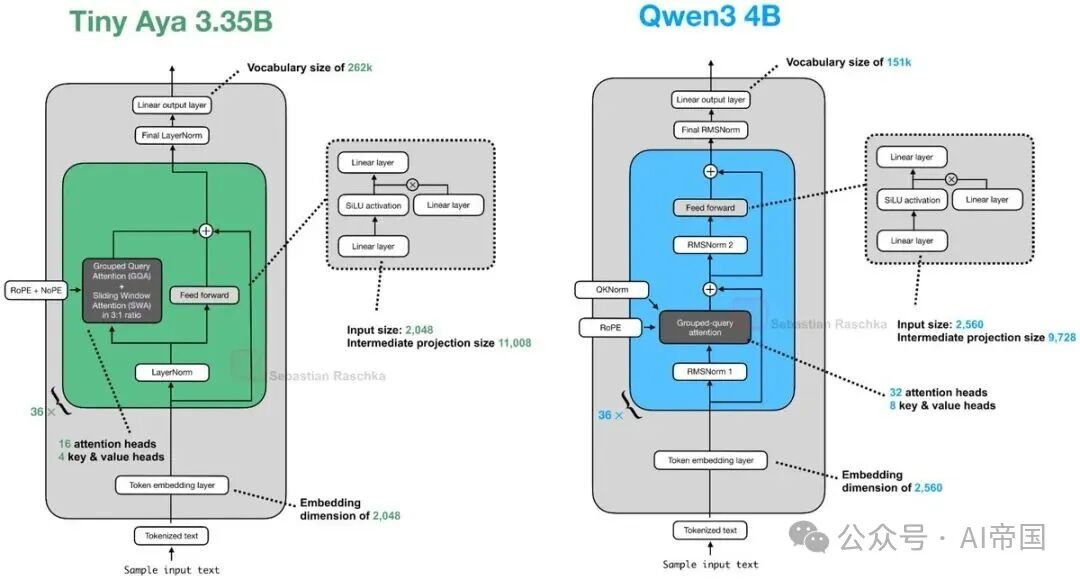
10.Cohere Tiny Aya(2月17日)
Tiny Aya 是一个较小的多语言模型。但从架构角度看,它采用了一种有趣的并行 Transformer Block 设计。
标题:10 open-weight LLM releases in January and February 2026
链接:https://x.com/rasbt/status/2026659971467706603

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)