中科算网算泥社区:多模态大语言模型技术发展报告 2026
全模态爆发(2025):技术核心转向解耦设计、流模型、实时交互,Janus 解耦双路径编码解决理解与生成的冲突,JanusFlow、NExT-OMNI 推动流模型崛起,VITA-1.5 实现接近 GPT-4o 的实时视觉 - 语音交互,Qwen3-Omni 完成工业级原生全模态落地,国内模型(文心 5.0、Emu3.5、DeepSeek-OCR)实现差异化突破。未来展望:①世界模型:融合更丰富的模
这份由中科算网算泥社区 2026 年 2 月发布的《多模态大语言模型技术发展报告》,系统梳理了 2017-2025 年多模态大语言模型(MLLMs)的发展脉络、核心技术、数据评估、应用场景,并剖析了当前挑战与未来展望,核心聚焦 2025 年全模态爆发阶段的技术突破与产业实践,同时展现了国内模型的创新成果,是一份兼具技术深度与产业视角的权威报告,核心总结如下:
一、发展历程:四阶段演进,2025 年迈入全模态爆发元年
报告将 MLLMs 发展划分为四大阶段,技术核心从早期模态融合探索,逐步走向全能、实时、原生全模态,2025 年成为技术爆发的关键节点:
早期探索(2017-2020):以双流架构(ViLBERT、LXMERT)和 CLIP 对比学习为核心,实现视觉 - 语言初步对齐,但缺乏生成能力,模态融合深度不足;
快速发展(2021-2023):LLM 驱动范式革命,BLIP-2 的 Q-Former 架构、LLaVA 的多模态指令微调成为核心技术,开源生态(LLaMA 系列)快速繁荣,模型实现基础的视觉理解与描述;
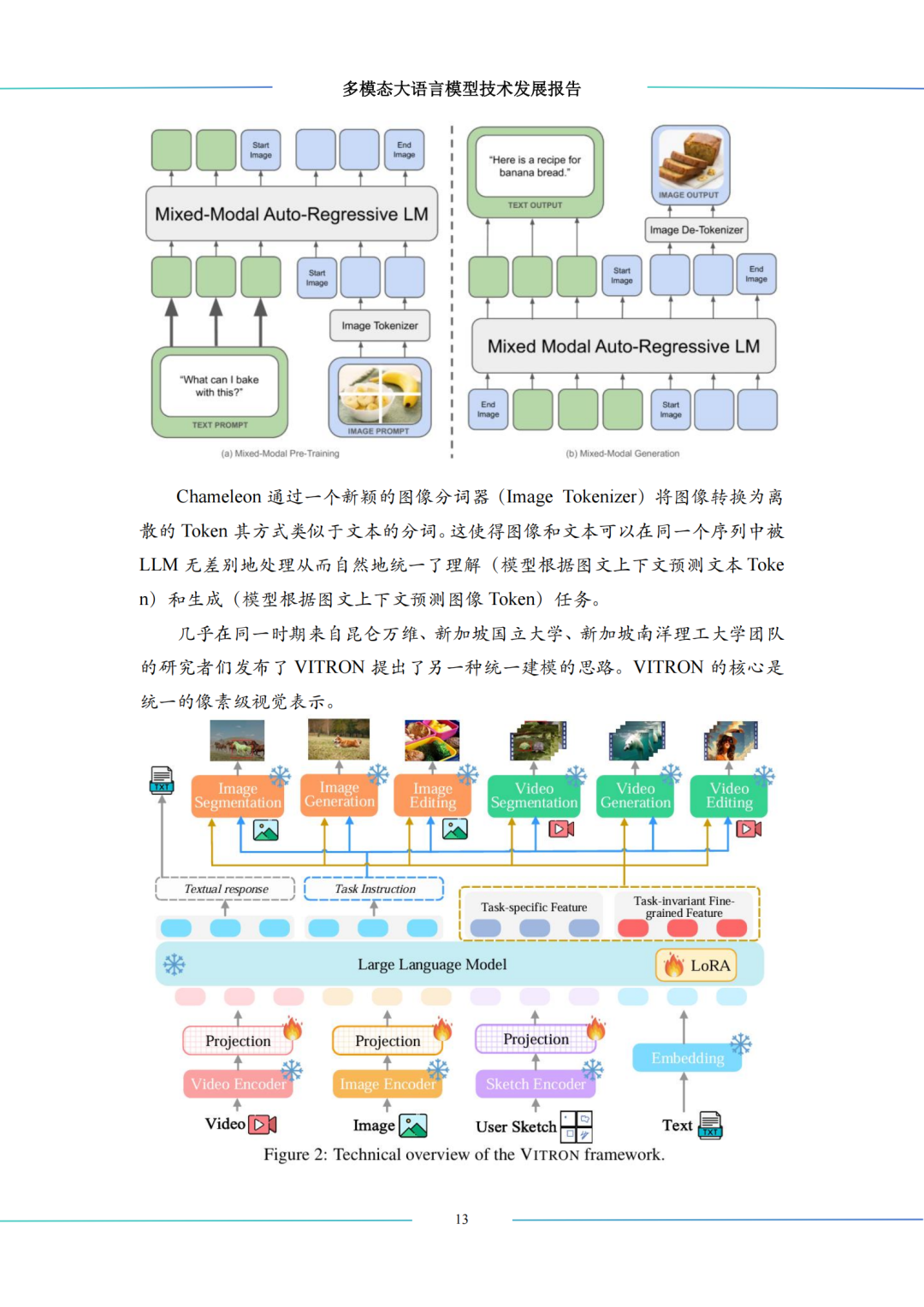
统一建模(2024):聚焦理解与生成的融合,Chameleon、VITRON 尝试单一架构统一多任务,Show-o 探索混合生成范式,GPT-4V、Gemini 开启工业界竞争,全模态模型萌芽;
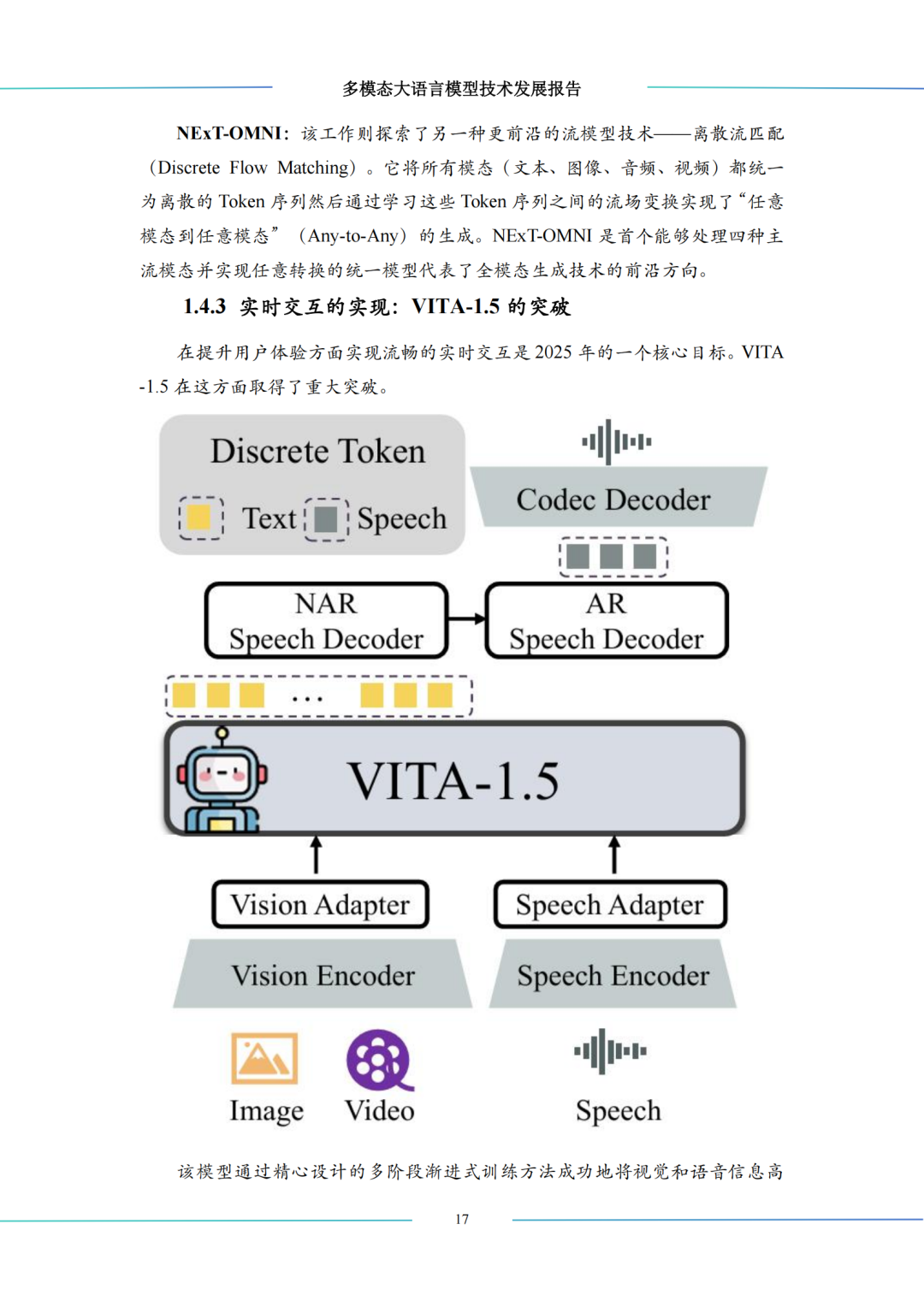
全模态爆发(2025):技术核心转向解耦设计、流模型、实时交互,Janus 解耦双路径编码解决理解与生成的冲突,JanusFlow、NExT-OMNI 推动流模型崛起,VITA-1.5 实现接近 GPT-4o 的实时视觉 - 语音交互,Qwen3-Omni 完成工业级原生全模态落地,国内模型(文心 5.0、Emu3.5、DeepSeek-OCR)实现差异化突破。
二、核心技术:架构与训练方法的系统性进化
支撑 2025 年技术爆发的核心是建模范式、编码器设计、对齐机制、生成范式、训练方法五大维度的创新,形成了从 “外部拼接” 到 “原生统一” 的技术体系:
建模范式:从 LLM 调用外部专家模型的外部集成,到模块化联合建模(Q-Former 适配器),最终走向端到端原生统一建模,2025 年解耦设计成为主流;
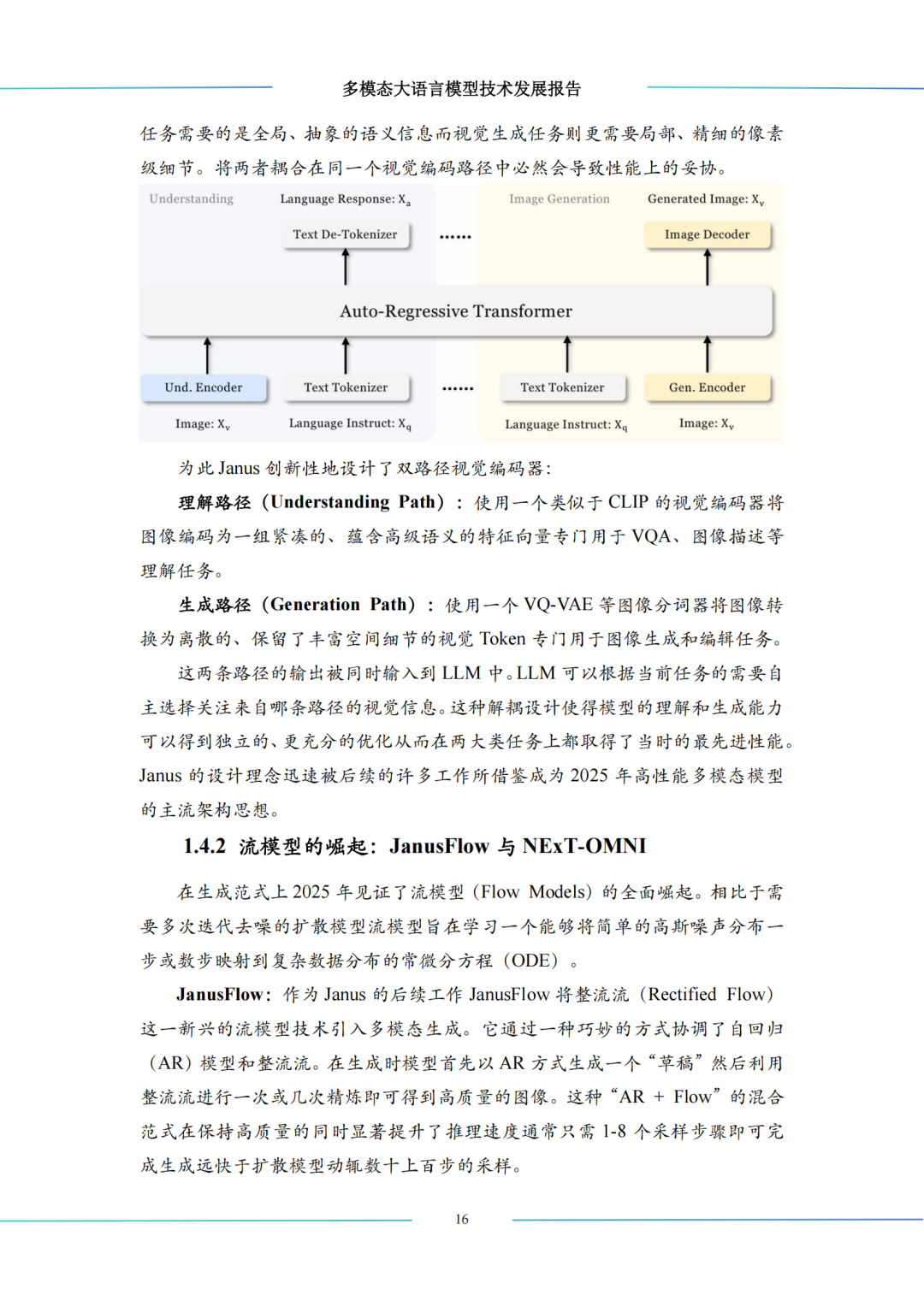
视觉编码器:从单一 CLIP ViT 特征提取,到多分辨率编码、Janus 解耦双路径编码(理解 / 生成分离),再到 VITRON 像素级统一表示,满足不同任务的精细化需求;
模态对齐机制:从简单线性投影,到 Q-4Former 高效查询压缩,再到 MoE 连接器实现自适应对齐,全模态对齐出现 “增强效应”,多模态融合反哺单一模态性能;
生成范式:从自回归与扩散模型的权衡,到 Show-o 混合范式,2025 年流模型成为核心,整流流、离散流匹配实现高质量、快速度的任意模态到任意模态生成;
训练方法:从经典 “预训练 + 指令微调” 两阶段范式,到 VITA-1.5 多阶段渐进式训练,数据策略从海量网络噪声数据,转向高质量合成数据、面向特定能力的结构化数据;
国内架构创新:Qwen3-VL 突破长上下文处理,DeepSeek-OCR 以 “光学压缩” 降低长文档处理成本,文心 5.0 实现原生全模态联合建模,Emu3.5 通过 DiDA 技术提升世界模型推理速度。
同时,OpenVLA 作为首个开源 VLA 模型,实现视觉 - 语言 - 动作的统一,开启开源机器人操控新时代。
三、数据与评估:质量重于规模,评估向真实世界靠拢
数据是 MLLMs 的基石,评估是技术发展的标尺,二者均呈现从规模到质量、从静态到动态的演进趋势:
数据来源:分为预训练数据集(学术数据集 COCO/Visual Genome、大规模网络数据集 LAION-5B/DataComp)和指令微调数据集(通用型 LLaVA-Instruct-158K、专业型 ChartQA/Video-MME),2025 年核心趋势是高质量合成数据和面向特定能力的结构化数据成为主流,图文对齐质量、数据多样性直接决定模型性能;
评估基准:从单一任务评估(VQA、图像描述)走向通用能力(MME、MM-Vet)、特定任务(ChartQA、MathVista)、交互式动态评估(VITA-Eval、竞技场模式) 三位一体,评估指标不仅关注准确率,还重视幻觉率、鲁棒性,“LLM-as-a-Judge” 成为主流评分方式,同时面临基准饱和、自动与人工评估权衡的挑战。
四、应用场景:从实验室走向物理世界,四大核心领域落地
2025 年 MLLMs 的应用从基础视觉理解,逐步渗透到内容创作、实时交互、具身智能,实现从虚拟到物理世界的跨越,形成四大核心场景:
高级视觉理解:超越 “看图说话”,实现复杂场景常识推理、专业领域视觉分析(医疗影像、金融图表、自动驾驶感知)、视频内容理解与摘要,成为各行业的 “超级专家”;
多模态内容创作:流模型实现高质量实时图像生成,Mogao 突破交错多模态内容生成(图文并茂文章、多模态幻灯片),VITRON 实现像素级精细化编辑,人机协同成为创作新范式;
实时交互式助手:VITA-1.5 等模型实现低延迟视觉 - 语音实时交互,EMOVA 融入情感交互,同时为视障、听障人群提供信息无障碍服务,迈向 “全能个人助理”;
具身智能与机器人:核心是构建世界模型(Google Genie 3、腾讯 HY-World 1.5、中科院 NeoVerse),实现语言指令到物理动作的转化,解决 Sim-to-Real 鸿沟,成为 MLLMs 发展的终极前沿。
五、当前挑战与未来展望:机遇与挑战并存,迈向通用自主智能
尽管 2025 年技术取得突破性进展,但 MLLMs 仍面临多重挑战,未来发展围绕世界模型、自主智能、技术融合三大主线展开:
核心挑战:一是计算资源 “诅咒”,训练与推理成本高昂,限制创新与普及;二是数据瓶颈,高质量视频 / 交错数据稀缺,且存在数据偏见;三是模型能力缺陷,幻觉问题、对抗性攻击脆弱性、物理世界常识缺乏;四是安全伦理红线,深度伪造、隐私泄露、责任界定等问题亟待解决;
未来展望:①世界模型:融合更丰富的模态(触觉、力觉),弥合 Sim-to-Real 鸿沟,涌现物理常识;②自主智能:模型从 “被动执行者” 变为 “主动规划者”,具备主动学习、长期任务规划能力,AI Agent 成为主流;③融合创新:与强化学习、知识图谱、脑机接口深度协同,实现技术互补,推动通用人工智能(AGI)发展。
六、核心结论
2025 年是多模态大语言模型的全模态元年,解耦设计、流模型、原生全模态成为技术核心,模型实现从 “理解” 到 “生成”、从 “静态” 到 “实时”、从 “虚拟” 到 “物理” 的跨越,国内模型实现从跟跑到并跑、部分领跑的突破。当前 MLLMs 正站在 AI2.0 时代的入口,未来发展需兼顾技术创新与伦理规范,通过算法、硬件、数据、法律的协同努力,推动其成为造福社会的向善力量。




























Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)