多模态大模型-对比学习
1. 什么是对比学习
对比学习是机器学习中的一种自监督学习方法,其核心思想就是创建一对pair的样本,让正样本尽可能的近,让负样本尽可能的远。
正样本:一般是通过数据增强得到的(如同一张图片的不同裁剪、旋转等)
负样本:就是毫无关联的图像
2. 对比学习的数学形式

如上图x通过数据增加得到xi和xj,然后通过resnet提取特征得到hi和hj,然后再加一个MLP层得到zi和zj,最后使用zi和zj计算loss
loss是通过上图中的infoNCE计算的,其中计算式子的分子是正样本的相似度,分母是所有样本之和,分子越大,分母越小值越大-log值越小也就是loss越小,这里相似度使用的是cosine。
因此负样本越多越容易收敛。
3. 数据增强

如上图:数据增强有很多方式,包括:随机裁剪、resize、随机翻转、颜色抖动、高斯模糊等
4. SimCLR
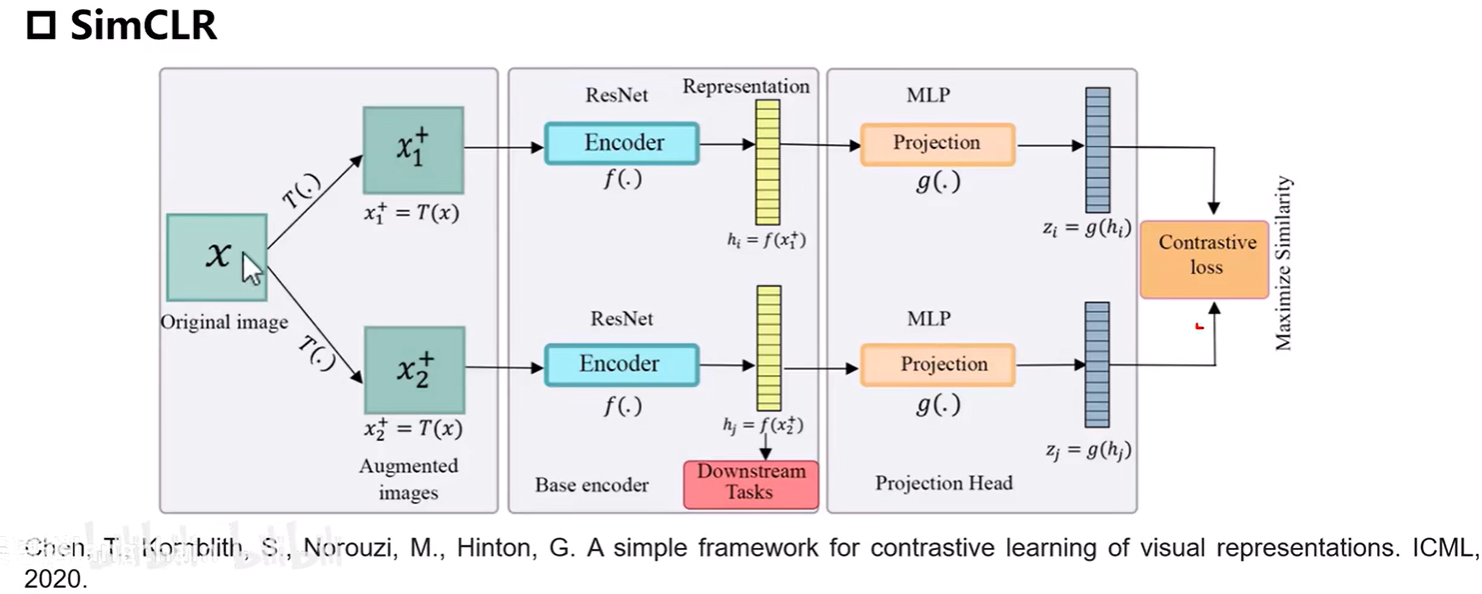
从上图可知,SimCLR与之前给出的数学形式差不多,唯一需要注意的是下游任务采用的hi和hj而不是通过MLP后的zi和zj,因为hi和hj保留了更多的图像特征。
实验发现,随机裁剪和颜色抖动能获取更好的效果,并且batch size越大效果越好,因为batch越大见过的负样本越多效果也就越好,而且还发现模型网络结构越大、训练时间越长效果越好,这个发现也奠定了大模型的基础。
5.MoCo
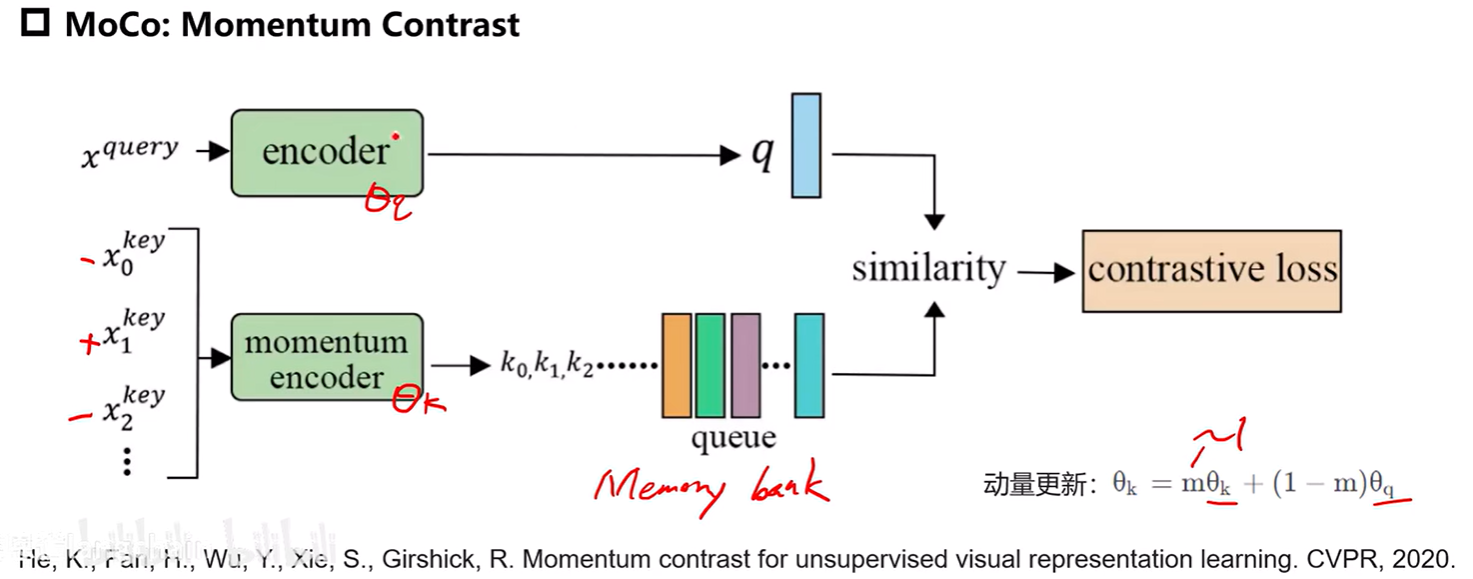
上图中key中只有一个正样本,其他都是负样本,key是通过momentum encoder获取特征的,而xquery是通过encoder获取特征的,所有的key通过momentum encoder计算特征存储在一个memory bank中,然后与q分别计算相似度。
momentum encoder的参数更新每次只考虑一小部分xquery的参数和本身上次的参数(m(0~1))
这里定义query和key是因为这个过程可以看作是一个检索过程
特点:
- 增加一个负样本特征队列,减少计算量同时增加了负样本的数量,从而提升效果
- 使用momentum encoder

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)