大模型算法(八):多模态大模型
1. 多模态大语言模型(MLLM)
1.1 定义和分类
模态(Modal)
模态是指信息被感知和呈现的方式。我们生活在一个由多种模态信息构成的世界,常见的模态包括:
- 视觉信息:图像、视频
- 听觉信息:音频、语音
- 文本信息:文字、语言
- 其他:嗅觉、触觉等
多模态数据示例:描述 “下雨天” 这一对象时,可以通过以下不同模态的数据来呈现:
- 图像:一张路面倒影的照片
- 视频:一段记录雨景的动态影像
- 音频:一段雨声的录音
- 文本:“下雨天,淅淅沥沥地,街道上布满了雨水,路边的树木倒影在路面上。”
多模态大语言模型(MLLMs)
MLLMs 是由传统大语言模型(LLMs)扩展而来的新一代模型,其核心能力是:
- 接收:同时处理和输入多种模态的数据(如图像、音频、文本)。
- 推理:对这些多模态信息进行综合理解、关联分析,并生成跨模态的输出或决策。
示例:当输入一张积水路面的图像和一段雨声的音频时,MLLMs 可以像人一样进行综合判断:
“听雨声,观察路面积水情况。判断现在是否适合出门?”
这体现了 MLLMs 超越单一文本处理,实现 “多感知 - 多理解 - 多决策” 的能力。

MLLMs 的核心价值
- 更贴近人类认知:人类本身就是通过视觉、听觉、语言等多种方式感知世界,MLLMs 模拟了这种多模态交互的认知方式。
- 信息处理更全面:单一模态信息往往存在局限,多模态融合可以提供更丰富、更准确的上下文。
- 应用场景更广泛:
- 视觉问答(VQA):根据图片回答问题。
- 多模态对话:结合图像、音频进行自然交流。
- 内容生成:根据文本描述生成图像,或根据图像生成描述性文本。
- 辅助决策:如医疗影像分析、自动驾驶环境感知等。
典型技术路线
MLLMs 的构建通常基于已有的大语言模型(如 LLaMA、GPT 等),通过以下方式扩展多模态能力:
- 模态编码器:为每种模态(图像、音频等)训练或使用预训练的编码器,将其转换为语言模型可以理解的 “特征表示”。
- 跨模态对齐:将不同模态的特征映射到同一个语义空间,使模型能够理解它们之间的关联。
- 指令微调:使用大量多模态指令数据对模型进行微调,使其学会根据多模态输入执行特定任务。

-
单模态大模型 (Uni-modal Large Model)
- 定义:只处理和生成单一类型数据模态的大模型。
- 典型代表:
- 语言大模型 (LLM):如 GPT、Llama,只处理文本。
- 视觉大模型 (LVM):如 SAM、ViT 系列,只处理图像 / 视频。
- 特点:在单一领域内能力极强,但无法理解和处理其他模态的信息。
-
跨模态模型 (Cross-modal Model)
- 定义:能够在两种不同模态之间建立映射关系,实现从一种模态到另一种模态的转换。
- 典型任务:
- 图像描述(Image Captioning):图像 → 文本
- 文生图(Text-to-Image):文本 → 图像
- 语音识别(ASR):音频 → 文本
- 语音合成(TTS):文本 → 音频
- 特点:重点在于 “转换”,而非 “融合理解”。它能把 A 模态的信息翻译成 B 模态,但不一定能像人一样同时理解两者的深层含义。
-
多模态模型 (Multimodal Model)
- 定义:能够同时接收和处理多种模态的输入,并在统一的语义空间中进行融合和推理。
- 核心能力:
- 多模态理解:同时 “看懂” 图像、“听懂” 语音、“读懂” 文字。
- 跨模态推理:利用多种模态的信息进行综合判断,例如 “看图说话” 不仅是描述,还能回答关于图片内容的复杂问题。
- 特点:相比跨模态模型,它更强调对多模态信息的深度融合与统一理解,而不仅仅是简单的转换。
-
多模态语言大模型 (Multimodal Large Language Model, MLLM)
- 定义:以语言大模型 (LLM) 为核心,通过适配器(Adapter)或其他技术,将视觉、音频等其他模态的信息编码成语言模型能够理解的 “语言”,从而让语言模型具备感知和理解多模态世界的能力。
- 典型代表:GPT-4V、Gemini、Qwen-VL、LLaVA 等。
- 特点:它是当前多模态技术的主流范式,利用了 LLM 强大的逻辑推理和知识储备,使得多模态交互更加自然和智能。
1.2 单模态大模型
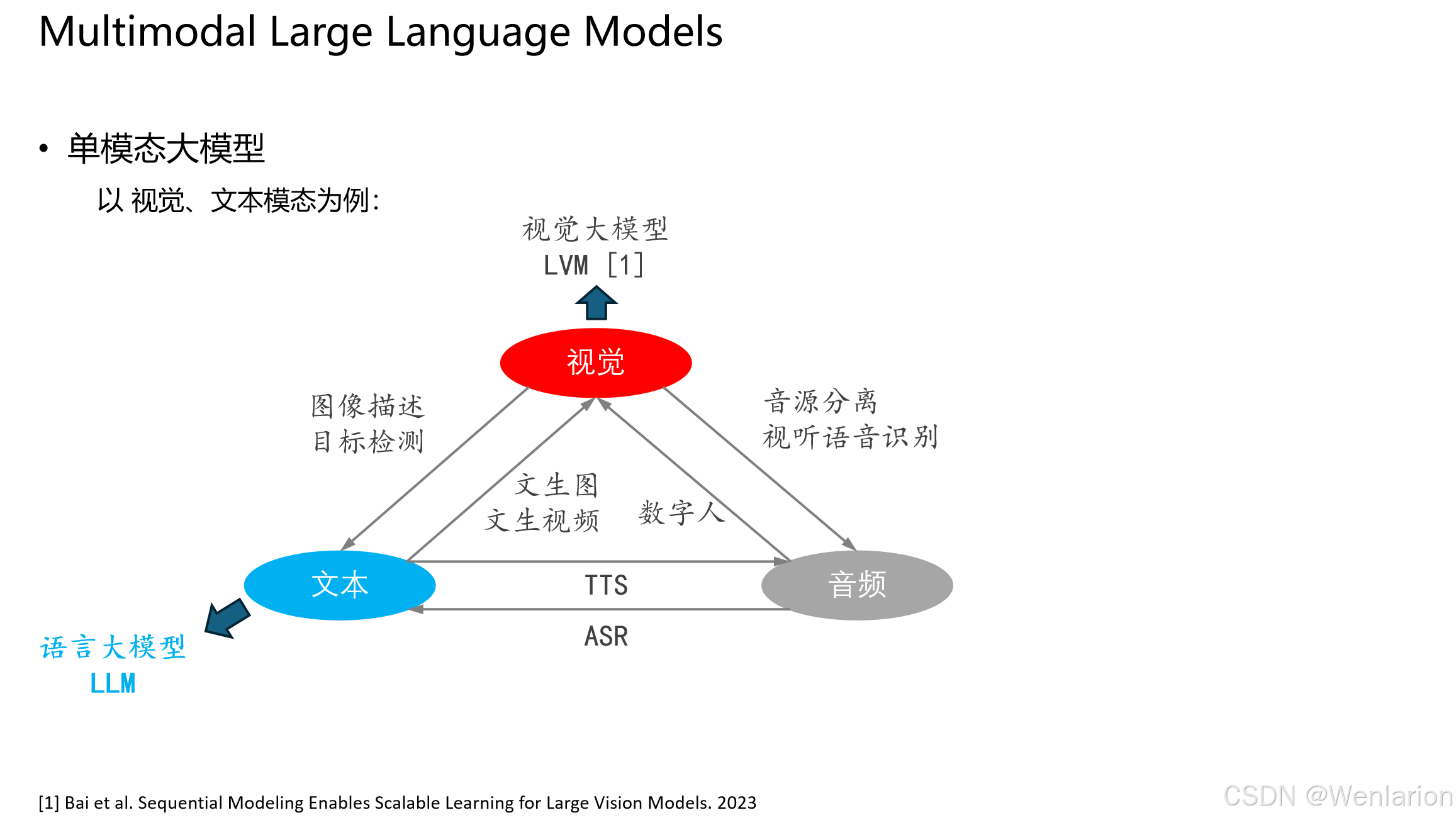
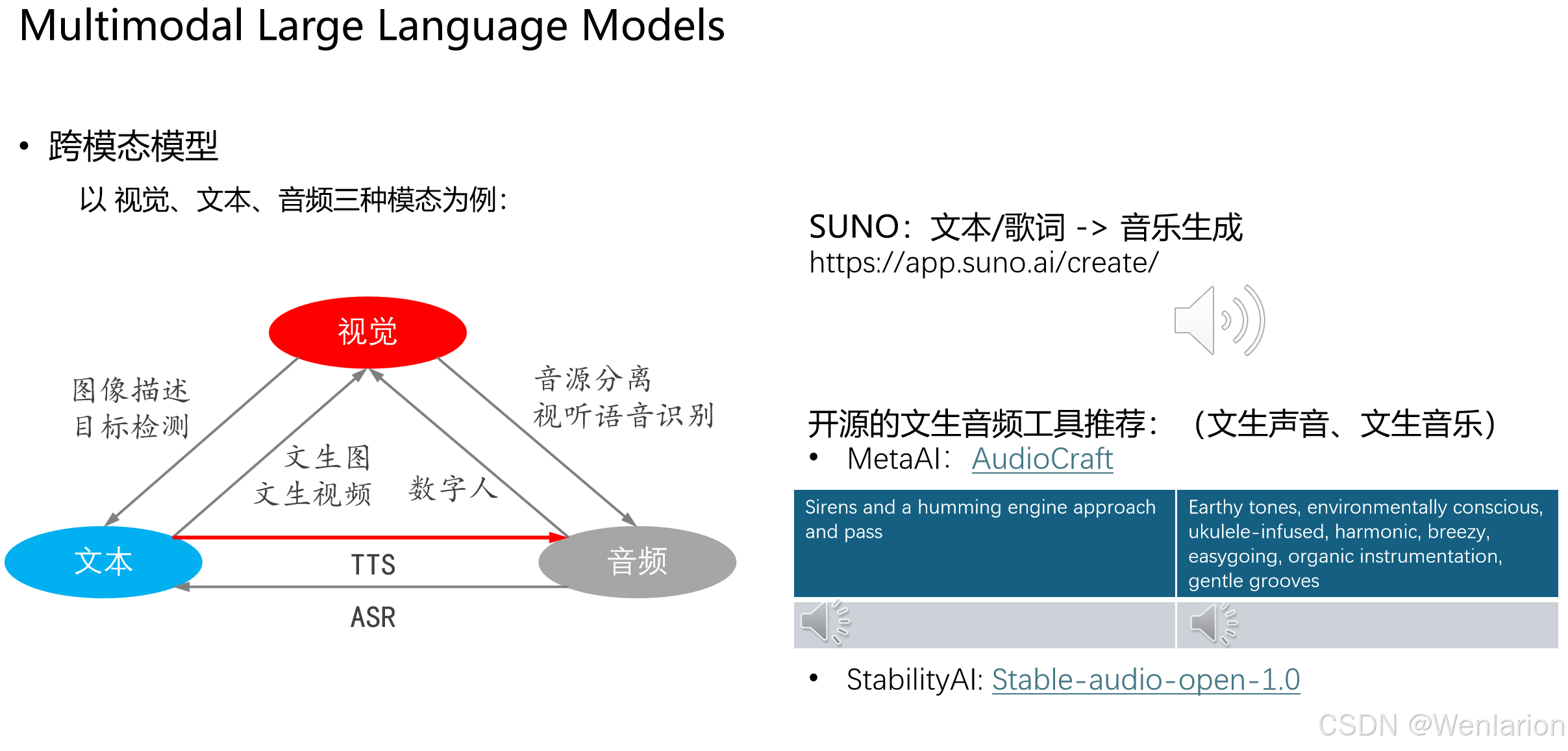
以视觉、文本、音频三种模态为例,展示单模态大模型的能力边界和交互方式:
- 文本模态(LLM):作为中枢,通过TTS(文本转语音)和ASR(语音转文本)与音频模态交互;通过文生图 / 文生视频等任务与视觉模态交互。
- 视觉模态(LVM):通过图像描述、目标检测等任务理解视觉信息;通过文生图、数字人等任务生成视觉内容;还可与音频结合完成声源分离、视听语音识别。
- 音频模态:作为补充,通过 ASR/TTS 实现与文本的转换,通过视听融合增强感知能力。
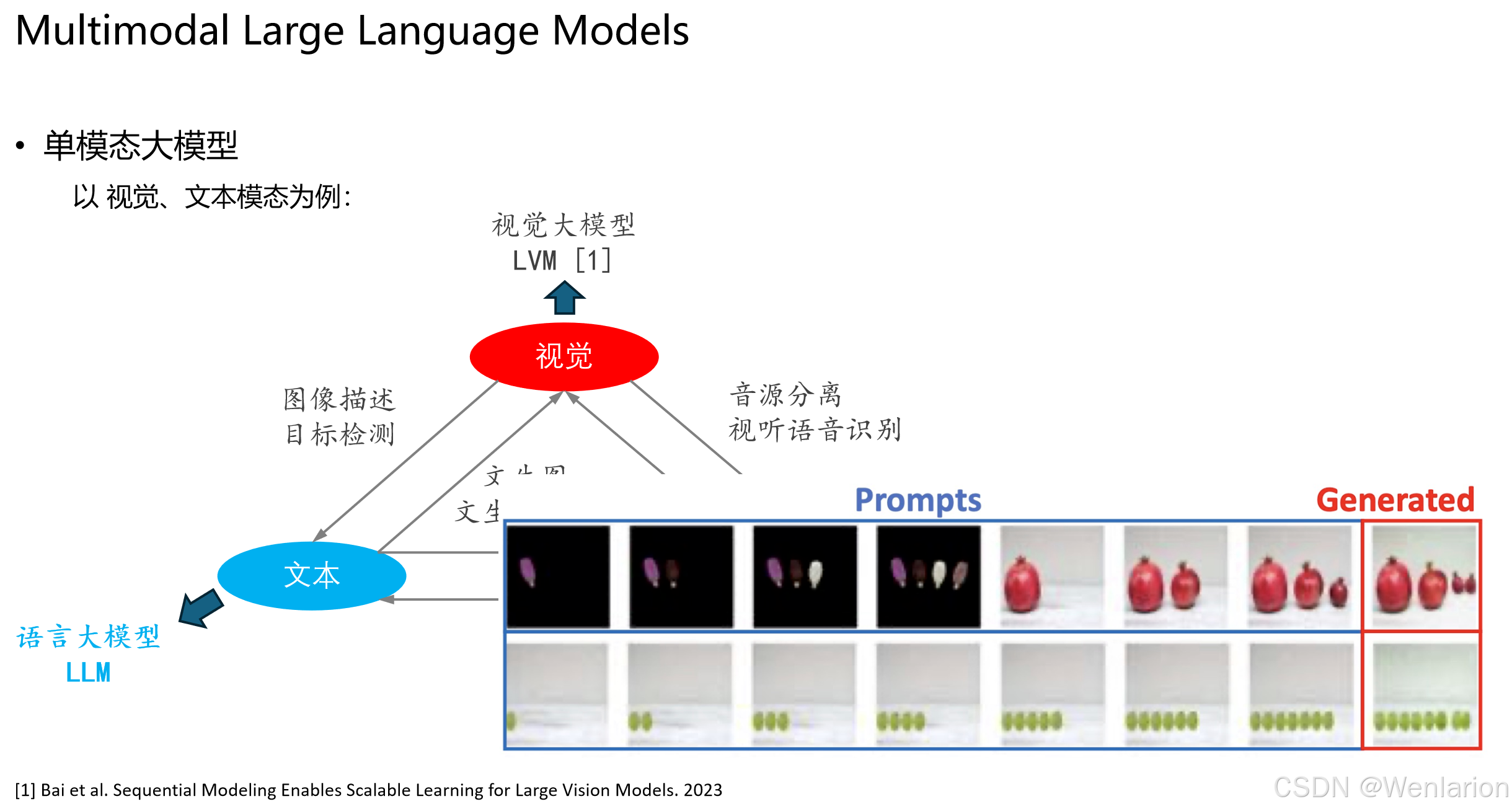
LVM 的文生图能力:
- Prompts:通过文本或视觉提示引导模型生成内容。
- Generated:模型根据提示生成对应的图像,如从 “一个石榴” 到 “多个石榴” 的递增生成。
代码和资源
视觉大模型(LVM)
- 论文标题:Sequential Modeling Enables Scalable Learning for Large Vision Models
- 作者:Yutong Bai, Xinyang Geng, Karttikeya Mangalam, Amir Bar, Alan Yuille, Trevor Darrell, Jitendra Malik, Alexei A. Efros
- 发表信息:CVPR 2024,arXiv:2312.00785
- 论文地址:
- 核心贡献:
- 提出 “视觉句子”(Visual Sentences)概念,将图像、视频、语义分割、深度图等多种视觉数据统一表示为离散 token 序列。
- 在包含 420B tokens 的 UVDv1 数据集上训练了 3B 参数的 Transformer 模型,证明了纯视觉模型的可扩展性。
- 通过提示工程(Prompt Engineering),在测试时实现了图像描述、目标检测、文生图、视频生成等多种任务。
1.3 跨模态大模型





1.3.1 音频驱动视觉生成(数字人 / 肖像动画)
1. SadTalker(西安交大、腾讯,CVPR 2023)
-
核心能力:单张图片 + 音频 → 生成风格化、逼真的 3D 说话人脸动画。
-
论文:SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
-
核心创新:
-
提出 ExpNet 和 PoseVAE,从音频中学习 3DMM 运动系数(表情 + 姿态)。
-
设计 3D 感知渲染器,生成自然的头部运动和唇形同步。
-
2. Real3D-Portrait(浙大、字节,ICLR 2024 Spotlight)
-
核心能力:单张图片 + 音频 → 生成逼真的 3D 半身说话人像,支持躯干运动和背景切换。
-
论文:Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
-
核心创新:
-
用大图像到平面模型蒸馏 3D 先验,提升单图 3D 重建能力。
-
设计头部 - 躯干 - 背景超分辨率模型,生成更完整的半身动画。
-
3. AniPortrait(腾讯游戏)
-
核心能力:音频驱动生成逼真的肖像动画,支持面部表情和头部姿态的自然变化。
-
论文:AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
-
核心创新:
-
分两步:Audio2Lmk(音频→面部关键点)+ Lmk2Video(关键点→视频)。
-
结合扩散模型和运动模块,保证时间一致性和视觉真实感。
-
4. EchoMimic(蚂蚁)
-
核心能力:音频驱动生成逼真的肖像动画,支持可编辑的地标条件控制。
-
论文:EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditioning
-
核心创新:
-
支持音频和地标条件的组合输入,实现更精细的动画控制。
-
后续升级的 EchoMimicV2/V3 支持半身人体动画和多任务统一建模。
-
5. LivePortrait(快手、中科大、复旦)
-
核心能力:视频驱动肖像动画,将表情和姿态迁移到目标人像,速度快(RTX 4090 上 12.8ms / 帧)。
-
论文:LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
-
核心创新:
-
基于隐式关键点的高效框架,平衡速度和质量。
-
设计拼接和重定向模块,提升动画可控性。
-
6. Audio2Photoreal(Facebook Research,CVPR 2024)
-
核心能力:音频驱动生成逼真的 Codec Avatar,包括面部表情和全身动作。
-
论文:From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
-
核心创新:
-
包含面部扩散模型、姿态扩散模型等四个核心模块,从音频生成全身 3D 化身。
-
1.3.2 视听语音识别和音源分离
一、视听语音识别 (AVSR)
1. 核心论文(附可访问链接)
|
论文标题 |
发表会议 / 年份 |
论文链接 |
核心亮点 |
|---|---|---|---|
|
Lip Reading in the Wild |
CVPR 2016 |
首个大规模唇语数据集 LRW,经典唇语识别基线 |
|
|
AV-HuBERT: Audio-Visual Hidden-Unit BERT for Speech Recognition |
NeurIPS 2021 |
跨模态预训练 AVSR 模型,工业界强基线 |
|
|
Audio-Visual Speech Recognition with Self-Supervised Pre-Training |
ICASSP 2022 |
自监督预训练提升小样本 AVSR 性能 |
|
|
End-to-End Audio-Visual Speech Recognition with Conformers |
ICASSP 2023 |
基于 Conformer 的端到端 AVSR,性能领先 |
2. 代码仓库地址(可直接克隆 / 使用)
|
项目名称 |
代码地址 |
适用场景 |
|---|---|---|
|
LRW 唇语识别基线 |
基于 TCN/CNN+LSTM 的唇语识别,适配 LRW 数据集 |
|
|
AV-HuBERT 官方实现 |
元宇宙开源,支持音频 - 视频联合预训练与推理 |
|
|
AVSR 入门级实现 |
轻量级 AVSR 基线,融合 MFCC 音频特征 + 唇语视觉特征 |
|
|
跨模态语音识别工具包 |
包含 AVSR 模块,支持多模态语音识别 / 验证 |
二、音源分离 (Audio Source Separation)
1. 核心论文(附可访问链接)
|
论文标题 |
发表会议 / 年份 |
论文链接 |
核心亮点 |
|---|---|---|---|
|
Conv-TasNet: Surpassing Ideal Time-Frequency Masking for Speech Separation |
ICASSP 2018 |
时域语音分离里程碑,替代传统时频掩码方法 |
|
|
SepFormer: Attention Is All You Need for Speech Separation |
ICASSP 2021 |
基于 Transformer 的 SOTA 语音分离模型 |
|
|
Open-Unmix: A Universal Music Source Separation Model |
ISMIR 2019 |
通用音乐分离,支持人声 / 鼓 / 贝斯 / 其他乐器 |
|
|
DPRNN: Dual-Path RNN for Context-Aware Speech Separation |
ICASSP 2020 |
双路径 RNN 捕捉局部 + 全局上下文,提升分离效果 |
2. 代码仓库地址(可直接克隆 / 使用)
|
项目名称 |
代码地址 |
适用场景 |
|---|---|---|
|
Open-Unmix 官方库 |
音乐源分离入门首选,支持一键分离 / 训练 |
|
|
SepFormer 官方实现 |
语音分离 SOTA,支持单 / 多说话人分离 |
|
|
Conv-TasNet 开源实现 |
原版 Conv-TasNet 复现,适配 WSJ0-2mix 数据集 |
|
|
音源分离工具包 asteroid |
集成 Conv-TasNet/SepFormer/DPRNN 等,一站式开发 |
|
|
MUSDB18 分离基线 |
适配 MUSDB18 音乐数据集,含多种分离模型 |
三、补充说明
-
论文链接优先使用 arXiv(无需权限),部分顶会论文可通过 Semantic Scholar(https://semanticscholar.org/)免费下载 PDF;
-
代码仓库均为维护状态良好的开源项目,克隆后可参考项目 README 完成环境配置(核心依赖:PyTorch、torchaudio);
-
数据集下载:
- LRW(唇语):https://www.robots.ox.ac.uk/~vgg/data/lip_reading/
- WSJ0-2mix(语音分离):https://github.com/JorisCos/Conv-TasNet/blob/master/data/create_wsj0_2mix.sh
- MUSDB18(音乐分离):https://sigsep.github.io/datasets/musdb.html
总结
-
视听语音识别:优先从 LRW 唇语识别仓库入门,进阶使用 AV-HuBERT 官方库;
-
音源分离:新手用 Open-Unmix 体验音乐分离,进阶学习 SepFormer/Conv-TasNet(可基于 asteroid 工具包快速开发);
-
所有链接均为当前主流开源资源,可直接克隆运行,建议先阅读项目 README 配置环境,再结合对应论文理解核心逻辑。

1.3.3 TTS(文本转语音)
TTS 核心是将文本转化为自然语音,以下覆盖从通用 TTS 到个性化、情感化、多语言 TTS 的主流模型:
1. 经典预训练模型(基础款、易微调)
| 模型名称 | 核心特点 | 论文(含 arXiv 链接) | 代码仓库 |
|---|---|---|---|
| Tacotron 2(Google) | 端到端 TTS 里程碑,结合编码器 - 解码器 + 声码器,生成自然语音 | Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram PredictionsarXiv: https://arxiv.org/abs/1712.05884 | https://github.com/NVIDIA/tacotron2 |
| VITS(腾讯 / 南洋理工) | 生成式对抗 + 扩散模型,零样本音色转换,语音自然度高 | Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-SpeecharXiv: https://arxiv.org/abs/2106.06103 | https://github.com/jaywalnut310/vits |
| FastSpeech 2(微软) | 非自回归 TTS,生成速度快(实时率 > 10),支持韵律控制 | FastSpeech 2: Fast and High-Quality End-to-End Text-to-SpeecharXiv: https://arxiv.org/abs/2006.04558 | https://github.com/ming024/FastSpeech2 |
2. 前沿大模型(个性化、多语言、情感化)
| 模型名称 | 核心特点 | 论文(含 arXiv 链接) | 代码仓库 |
|---|---|---|---|
| GPT-SoVITS | 少样本音色克隆(仅需 5 秒音频),支持中 / 日 / 英跨语言合成 | 无正式论文(社区开源里程碑) | https://github.com/RVC-Boss/GPT-SoVITS |
| ChatTTS | 对话式 TTS,支持情感、停顿、语调控制,适合聊天场景 | 无正式论文(社区开源) | https://github.com/2noise/ChatTTS |
| Vall-E(微软) | 神经声码器 + 自回归模型,零样本音色克隆,语音相似度极高 | Neural Codec Language Models are Zero-Shot Text to Speech SynthesizersarXiv: https://arxiv.org/abs/2301.02111 | 官方未开源(第三方复现:https://github.com/Plachtaa/VALL-E-X) |
| SoundStorm(Google) | 高效非自回归 TTS,支持长音频生成,适配大模型场景 | SoundStorm: Efficient Parallel Audio GenerationarXiv: https://arxiv.org/abs/2305.09636 | https://github.com/google-research/soundstorm |
| UniVoice(多模态) | 统一 ASR+TTS 的大模型,支持语音识别 - 合成闭环 | UniVoice: Unified Speech Processing with Large-Scale Self-Supervised LearningarXiv: https://arxiv.org/abs/2510.04593v2 | https://github.com/netease-youdao/UniVoice |
3.文本生成音乐 / 音效模型
| 模型名称 | 研发方 | 核心特点 | 论文(含 arXiv 链接) | 代码仓库 |
|---|---|---|---|---|
| AudioCraft | MetaAI | 含 MusicGen(音乐生成)、AudioGen(音效生成)、EnCodec(编解码),文本生成高质量音频 | Simple and Controllable Music Generation(NeurIPS 2023)项目页:https://ai.meta.com/research/ai-audio/audiocraft/ | https://github.com/facebookresearch/audiocraft |
| Stable-audio-open-1.0 | StabilityAI | 文本生成音频,支持 44.1kHz 立体声,最长 47 秒,基于潜在扩散模型,可商用 | Stable Audio OpenarXiv: https://arxiv.org/abs/2407.14358 |
3. 中文专用 TTS 模型(适配中文韵律 / 音色)
- PaddleSpeech(百度):集成 FastSpeech 2、VITS、Tacotron 2 等,支持中文多音色合成代码:https://github.com/PaddlePaddle/PaddleSpeech文档:https://paddlespeech.readthedocs.io/
- Bert-VITS2:结合 BERT 语义理解的中文 TTS,情感表达更丰富代码:https://github.com/Stardust-minus/Bert-VITS2
1.3.4 ASR(自动语音识别)
ASR 核心是将音频信号转化为文本,以下是工业界 / 学术界最常用的模型,覆盖从通用场景到多语言、低资源语言的需求:
1. 经典预训练模型(轻量、易部署)
| 模型名称 | 核心特点 | 论文(含 arXiv 链接) | 代码仓库 |
|---|---|---|---|
| Wav2Vec 2.0(Facebook) | 首个无监督语音预训练里程碑,单语 / 多语版本,适配低资源语言 | wav2vec 2.0: A Framework for Self-Supervised Learning of Speech RepresentationsarXiv: https://arxiv.org/abs/2006.11477 | https://github.com/facebookresearch/fairseq/tree/main/examples/wav2vec |
| HuBERT(Facebook) | 基于聚类的自监督预训练,语音表示更鲁棒,ASR 准确率优于 Wav2Vec 2.0 | HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden UnitsarXiv: https://arxiv.org/abs/2106.07447 | https://github.com/facebookresearch/fairseq/tree/main/examples/hubert |
| Conformer(Google) | 结合 Transformer+CNN 的 ASR 骨干网络,工业界主流(如 Whisper、阿里云通义听悟均基于此) | Conformer: Convolution-augmented Transformer for Speech RecognitionarXiv: https://arxiv.org/abs/2005.08100 | https://github.com/sooftware/conformer |
2. 前沿大模型(多语言、多任务、高准确率)
| 模型名称 | 核心特点 | 论文(含 arXiv 链接) | 代码仓库 |
|---|---|---|---|
| Whisper(OpenAI) | 多语言(99 种语言)ASR 大模型,支持语音转文本、翻译、语言识别,零样本效果优异 | Robust Speech Recognition via Large-Scale Weak SupervisionarXiv: https://arxiv.org/abs/2212.04356 | https://github.com/openai/whisper |
| Paraformer(百度) | 工业级高效 ASR 模型,实时性 + 准确率兼顾,中文场景最优之一 | Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech RecognitionarXiv: https://arxiv.org/abs/2206.08317 | https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/paraformer |
| MassiveASR(字节跳动) | 千亿参数级多语言 ASR 大模型,覆盖 100 + 语言,低资源语言效果显著 | MassiveASR: Scaling Up Speech Recognition with Over 100 Billion ParametersarXiv: https://arxiv.org/abs/2403.00779 | 暂未开源(提供 API:https://www.bytedance.com/en/tech/product/ai/speech/) |
| LLaMA-Omni(多模态) | 融合 ASR+TTS + 视觉的多模态大模型,支持语音 - 文本 - 视觉跨模态交互 | LLaMA-Omni: Unified Multimodal Large Language Model with Vision, Audio, and TextarXiv: https://arxiv.org/abs/2402.00856 | https://github.com/ictnlp/LLaMA-Omni |
3. 中文专用 ASR 模型(适配中文场景)
- FunASR(阿里巴巴):工业级中文 ASR 工具包,集成 Paraformer、Conformer 等模型,支持实时转写、方言识别代码:https://github.com/alibaba-damo-academy/FunASR论文:FunASR: A Fundamental End-to-End Speech Recognition Toolkit(无公开 arXiv,工具包自带技术文档)
- WeNet(腾讯 / 清华):开源端到端 ASR 框架,支持中文 / 英文,易二次开发代码:https://github.com/wenet-e2e/wenet论文:WeNet 2.0: More Productive End-to-End Speech Recognition ToolkitarXiv: https://arxiv.org/abs/2203.15455
1.4 多模态大模型
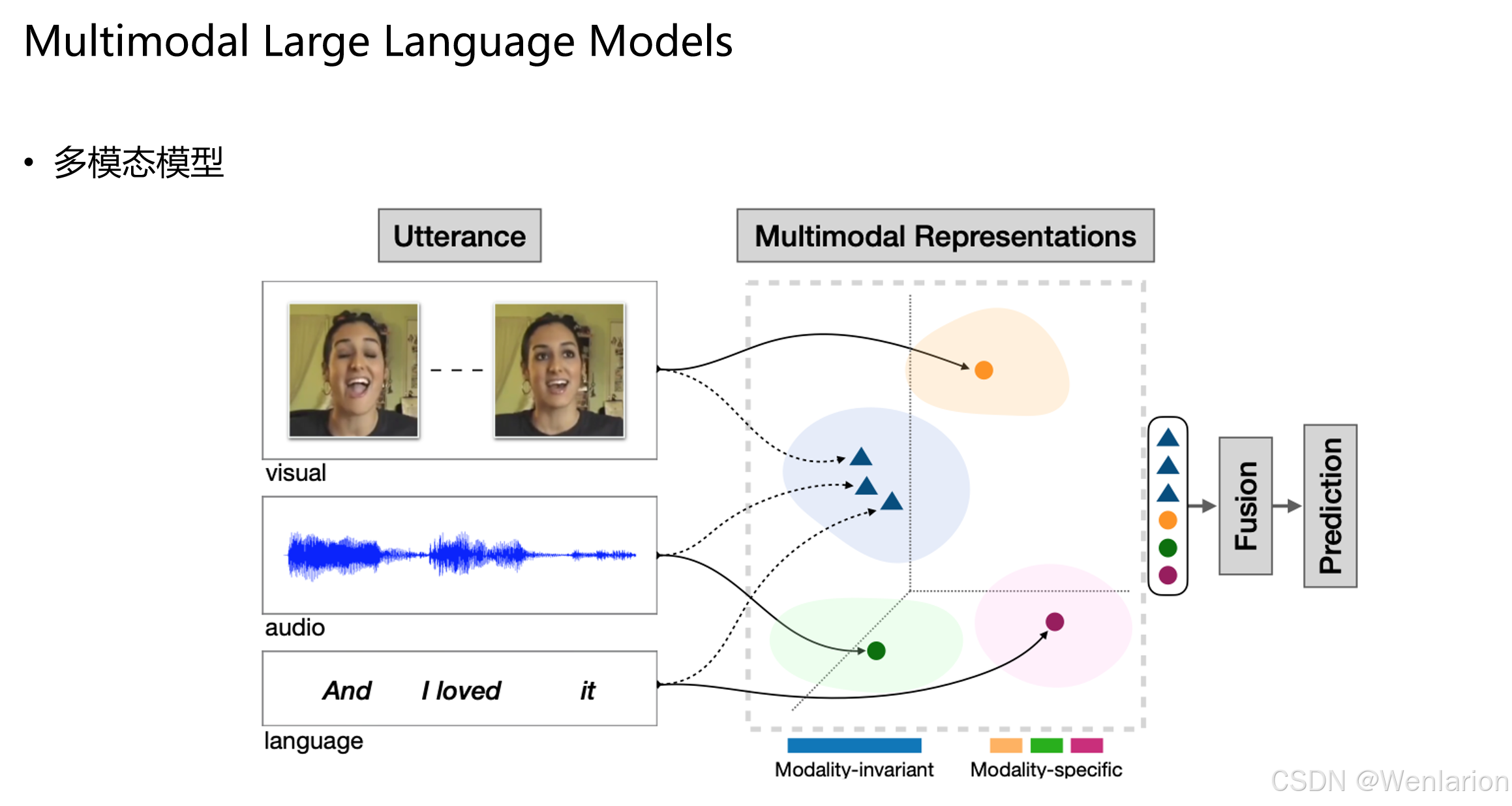
多模态模型处理流程,以 “utterance(话语)” 为例,输入包含视觉(visual)、音频(audio)和语言(language)三种模态信息。
-
输入模态
- 视觉:两帧人脸图像,捕捉表情、动作等视觉信息。
- 音频:一段语音波形,对应说话内容的声学信号。
- 语言:文本序列 “And I loved it”,是语音的文字转录。
-
多模态表示(Multimodal Representations)模型将不同模态的原始数据编码为向量表示,这些表示分为两类:
- 模态不变(Modality-invariant):用蓝色三角形表示,是跨模态共享的语义信息,例如 “开心” 这个概念,无论从视觉(笑容)、音频(语调)还是文本(“loved”)中都能提取到。
- 模态特定(Modality-specific):用橙色、绿色、紫色圆点表示,分别对应视觉、音频、语言模态特有的信息,例如视觉的人脸特征、音频的音色、文本的语法结构。
-
融合(Fusion)与预测(Prediction)提取到的多模态表示被送入融合模块,将不同模态的信息整合,最后由预测模块输出最终结果(如情感分类、意图识别等)。
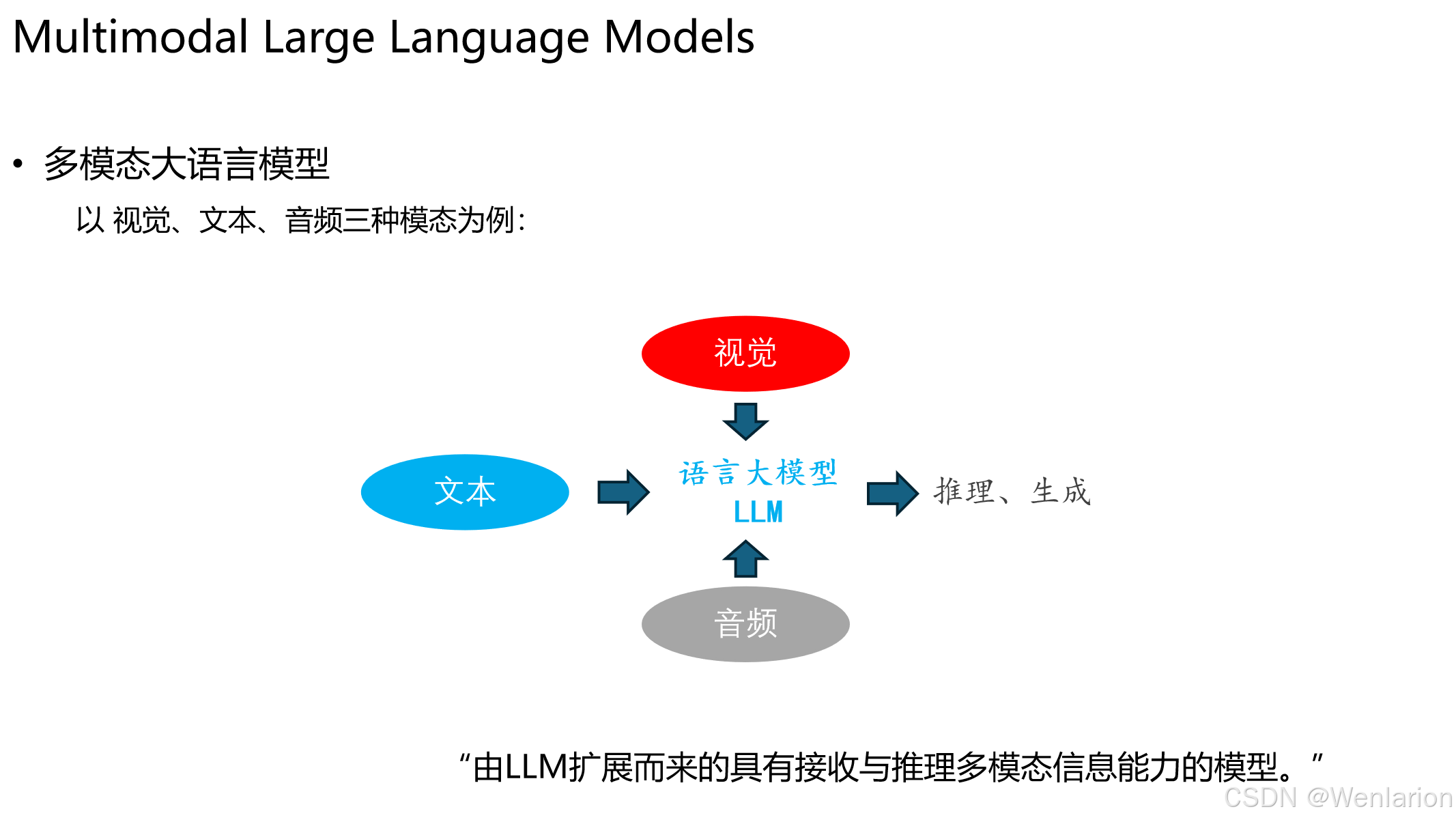
多模态大语言模型的核心思想:它是由语言大模型(LLM)扩展而来,具备接收和推理多模态信息的能力。
1. 核心组件
- 语言大模型(LLM):作为整个系统的 “大脑”,负责核心的推理和生成任务。
- 多模态输入:视觉、文本、音频等模态信息,通过适配器(Adapter)或编码器转换为 LLM 可以理解的嵌入(embedding),然后输入到 LLM 中。
- 输出:LLM 在融合了多模态信息后,进行推理并生成文本或其他形式的输出。
2. 定义 由 LLM 扩展而来的具有接收与推理多模态信息能力的模型。
2.图文多模态大模型
2.1 图文多模态大模型发展历程
2.2.1 图文多模态大模型
这套图片系统梳理了视觉 - 文本多模态模型的发展脉络,以四个关键里程碑为核心,从底层视觉表征、跨模态联合建模、大规模对齐,到最终文生图任务的爆发,完整呈现了技术从理论突破到产业落地的演进路径。结合图片内容,以下是分模块的详细解析,包含核心论文、技术原理及官方 / 主流代码地址:
里程碑 1:视觉表征的 Token 化革命(ViT 与掩码图像建模)
这一阶段解决了 **“如何用 Transformer 处理图像”** 的核心问题,将 NLP 的 Token 化思想迁移到视觉领域,奠定了多模态融合的基础。
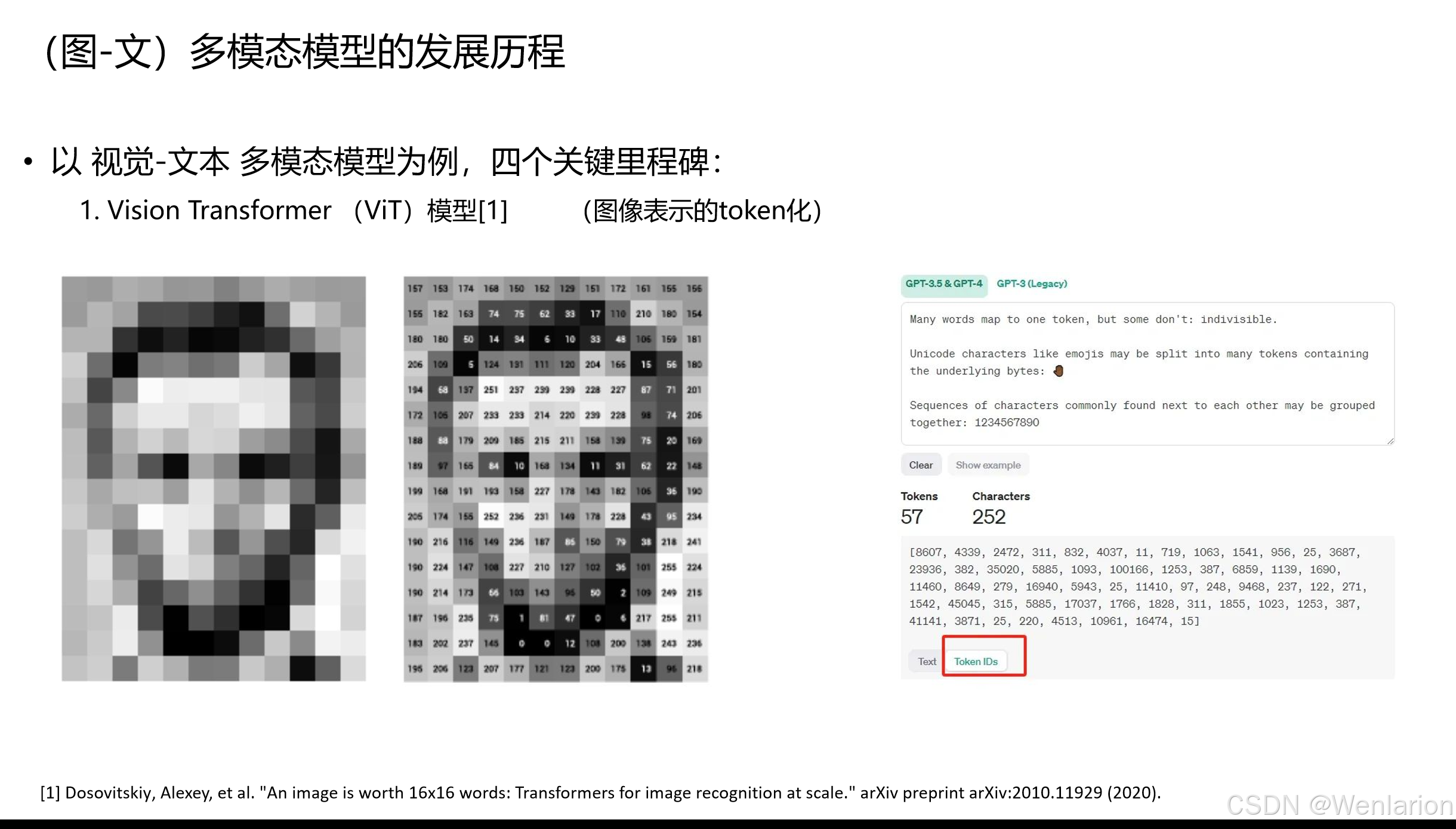
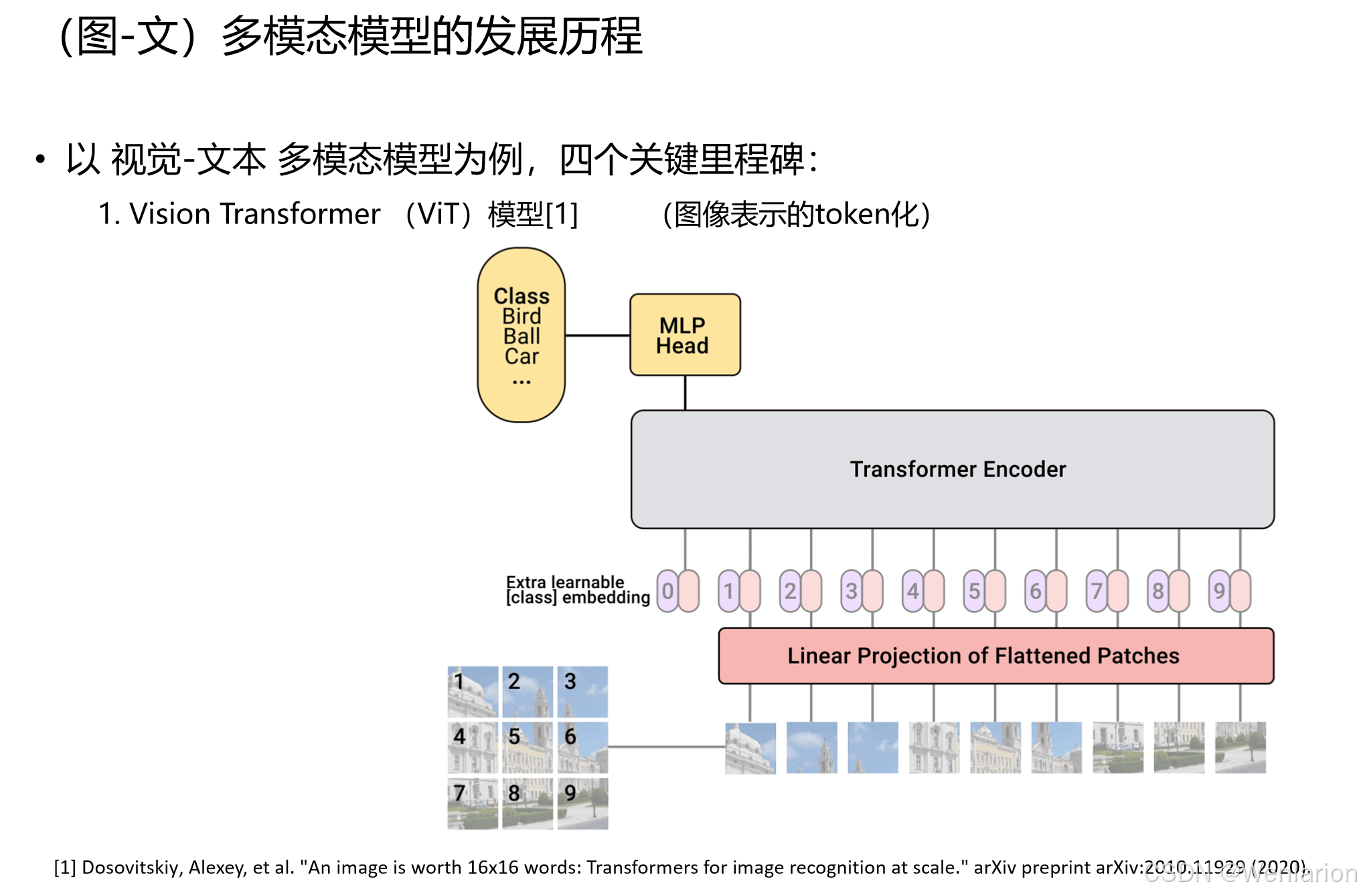
1. Vision Transformer (ViT) —— 图像 Token 化的开山之作
-
核心贡献:首次证明纯 Transformer 架构可在图像识别任务中超越 CNN。将图像切分为固定大小的Patches(16×16),展平后作为 “视觉 Token”,通过线性投影映射到特征空间,结合类别嵌入(Class Embedding)和位置编码,送入 Transformer Encoder 完成分类。
-
论文信息:Dosovitskiy, Alexey, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
-
代码地址:
-
官方 JAX 实现:https://github.com/google-research/vision_transformer
-
主流 PyTorch 复刻(含多尺度变体):https://github.com/lucidrains/vit-pytorch
-
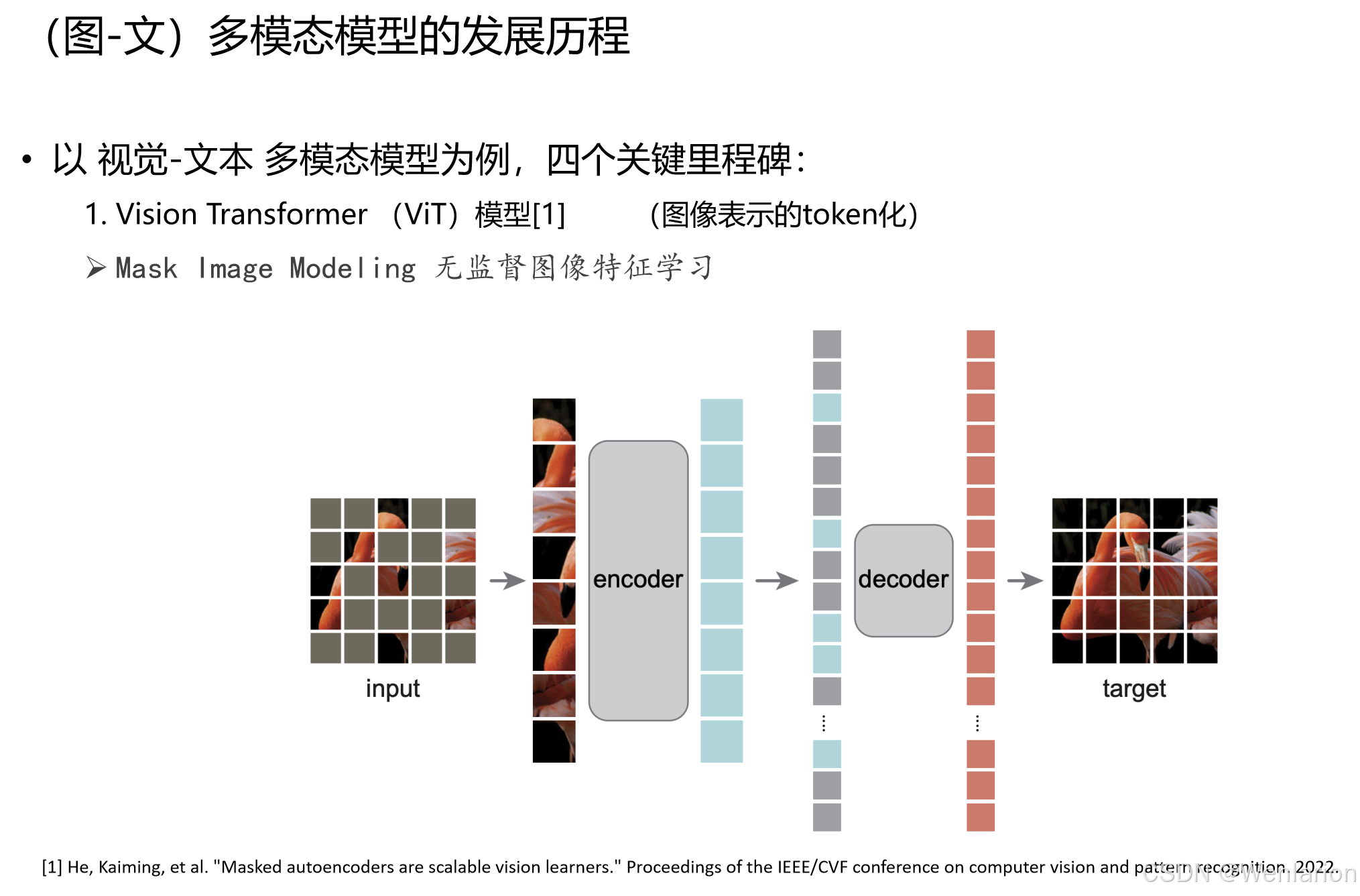
2. Masked Image Modeling (MIM) —— 视觉无监督预训练的标准化
-
核心贡献:借鉴 NLP 的 BERT 掩码策略,提出 ** 掩码自编码器(MAE)** 等方案:随机掩码图像的部分 Patches,通过 Encoder 编码可见部分,再用 Decoder 重建掩码区域的像素 / 特征,实现高效的无监督视觉特征学习,大幅提升了 ViT 的泛化能力。
-
论文信息:He, Kaiming, et al. Masked autoencoders are scalable vision learners. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
-
代码地址:
-
官方 MAE 实现(PyTorch):https://github.com/facebookresearch/mae
-
通用 MIM 框架(支持 MAE、BEiT 等):https://github.com/microsoft/unilm
-
里程碑 2:基于 Transformer 的图像 - 文本联合建模(VisualBERT)
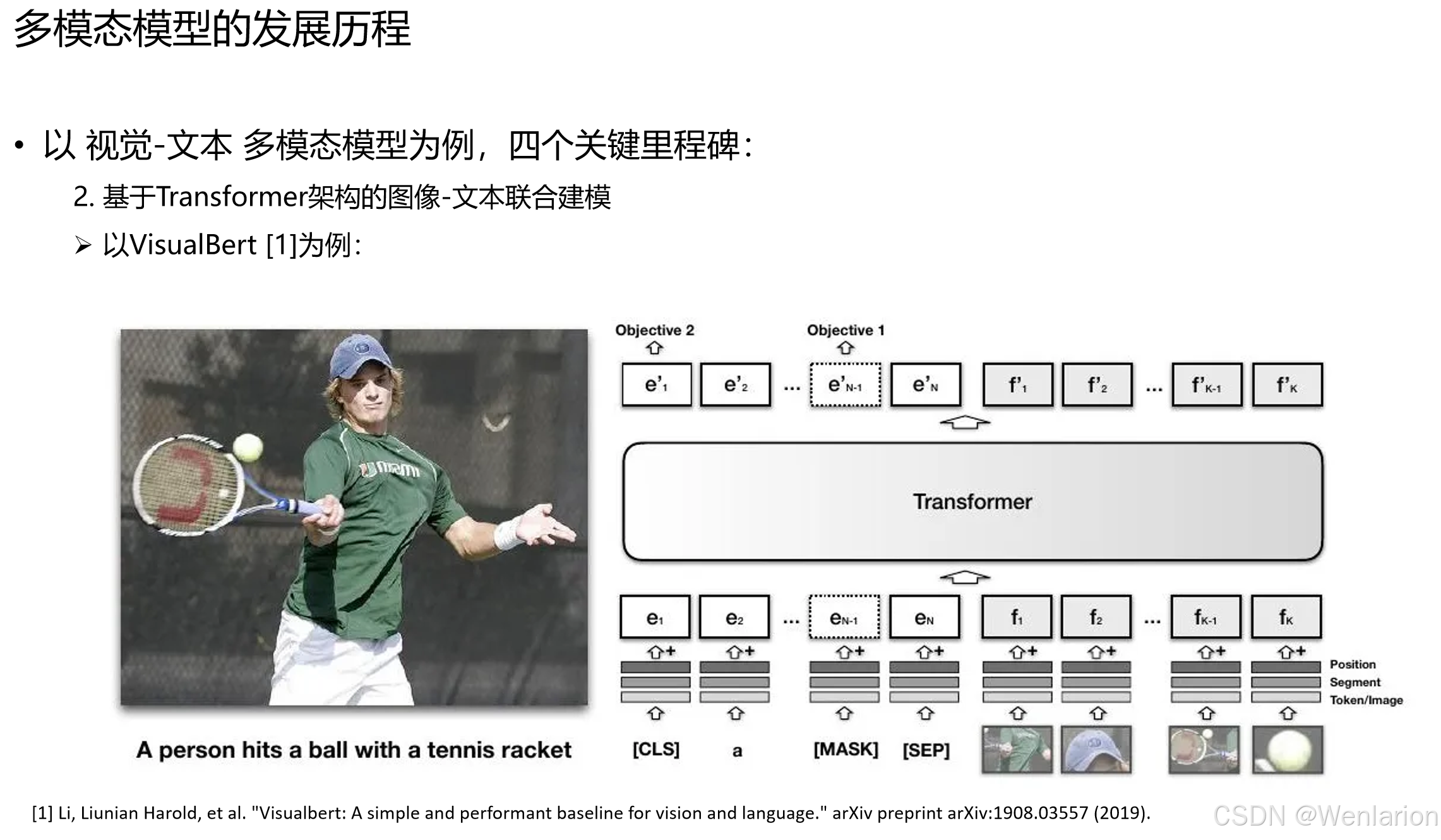
这一阶段突破了 **“视觉与文本特征如何融合”** 的瓶颈,实现了跨模态的统一表征,为后续对齐任务奠定了架构基础。
VisualBERT —— 视觉 - 语言融合的基础基线
-
核心贡献:在 BERT 架构上扩展,引入视觉 Token(由 Faster R-CNN 提取的图像区域特征),与文本 Token 拼接后送入 Transformer。通过双流注意力(文本 - 文本、文本 - 视觉)实现跨模态交互,支持视觉问答(VQA)、图像字幕等任务。
-
论文信息:Li, Liunian Harold, et al. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019).
-
代码地址:
-
官方 TensorFlow 实现:https://github.com/uclanlp/visualbert
-
PyTorch 复刻(适配现代训练框架):https://github.com/huggingface/transformers(支持 VisualBERT 预训练模型加载)
-
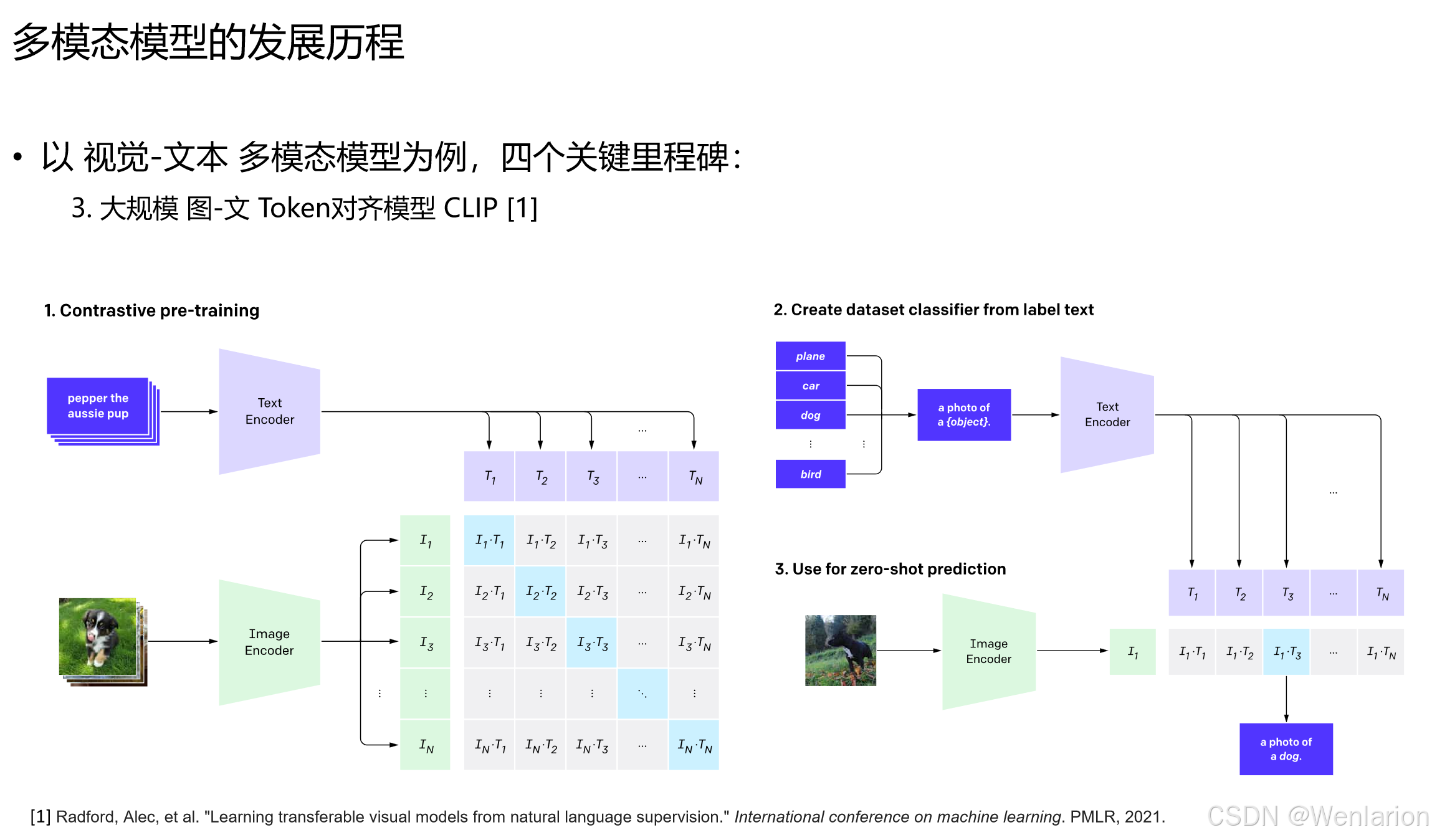
里程碑 3:大规模图 - 文 Token 对齐(CLIP 与 SigLIP)
这一阶段通过 **“对比学习 + 大规模图文数据”,实现了视觉与文本的全局语义对齐 **,彻底打破了 “有监督训练依赖人工标注” 的限制,是文生图爆发的核心前提。
1. CLIP (Contrastive Language-Image Pre-training) —— 图文对齐的里程碑
-
核心贡献:构建含 4 亿 + 图文对的数据集,采用对比预训练策略:同时训练图像编码器和文本编码器,使 “匹配的图文对” 在特征空间中距离更近,“不匹配的对” 距离更远。实现了零样本学习(Zero-Shot),可直接通过文本指令完成图像分类、检测等任务。
-
论文信息:Radford, Alec, et al. Learning transferable visual models from natural language supervision. International Conference on Machine Learning. PMLR, 2021.https://arxiv.org/abs/2103.00020
-
代码地址:
-
官方 OpenAI 实现(PyTorch):https://github.com/openai/CLIP
-
轻量化推理 / 训练框架:https://github.com/lucidrains/CLIP-pytorch
-
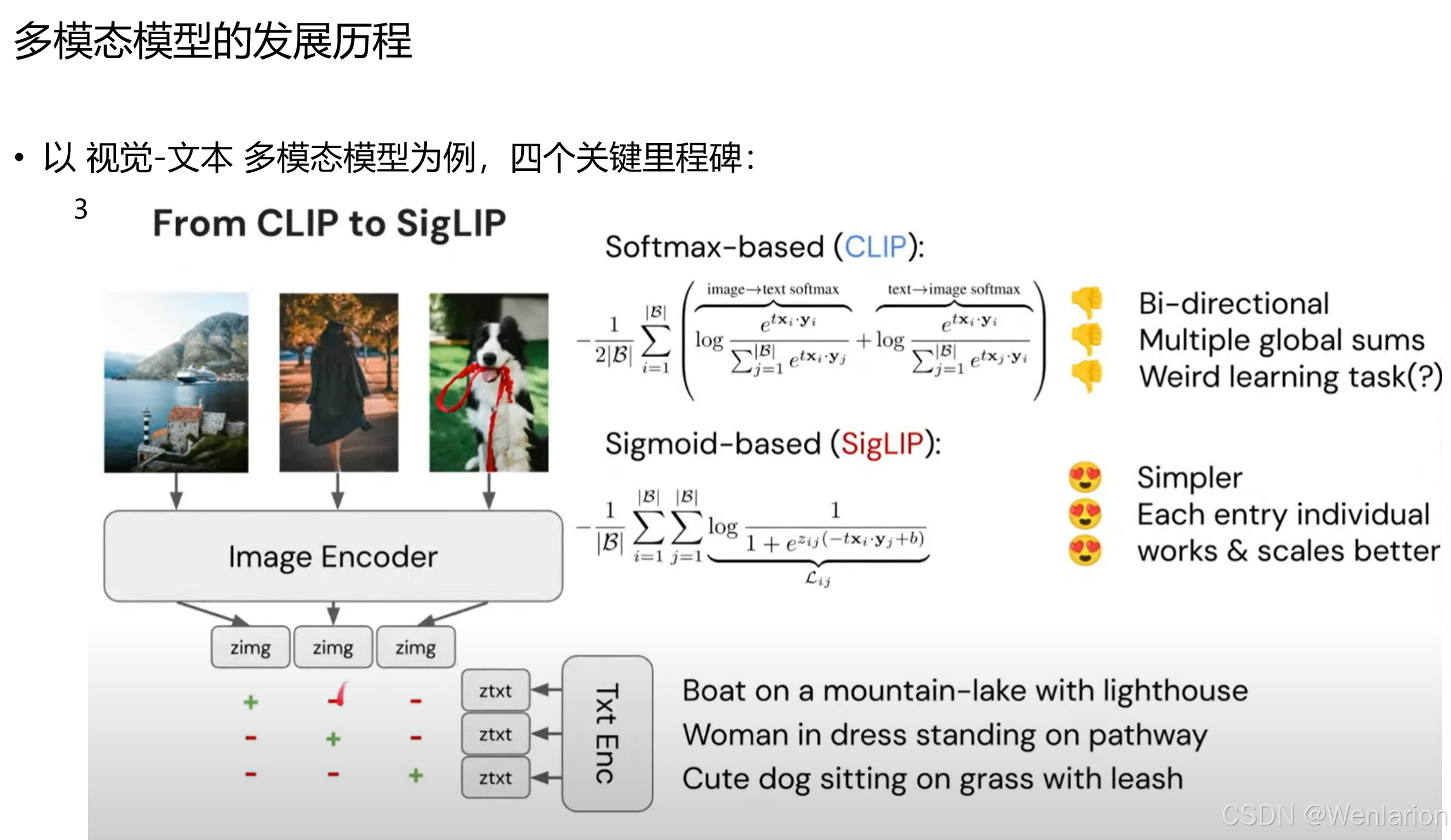
2. SigLIP —— CLIP 的损失函数优化版
-
核心贡献:针对 CLIP 的 Softmax 对比损失在大规模批次下的效率问题,提出基于 Sigmoid 的成对损失。将 “全局对比” 改为 “逐样本成对判断”,无需计算批次内的全局归一化,训练更稳定、可扩展性更强,在大模型尺度下性能超越 CLIP。
-
论文信息:Zhai, Xiaohua, et al. SigLIP: Simple Image Text Matching with Sigmoid Loss. arXiv preprint arXiv:2303.15343 (2023). https://arxiv.org/abs/2303.15343
-
代码地址:
-
官方 Google 实现(JAX/Flax):https://github.com/google-research/big_vision
-
PyTorch 复刻版:https://github.com/kingoflolz/siglip-pytorch
-
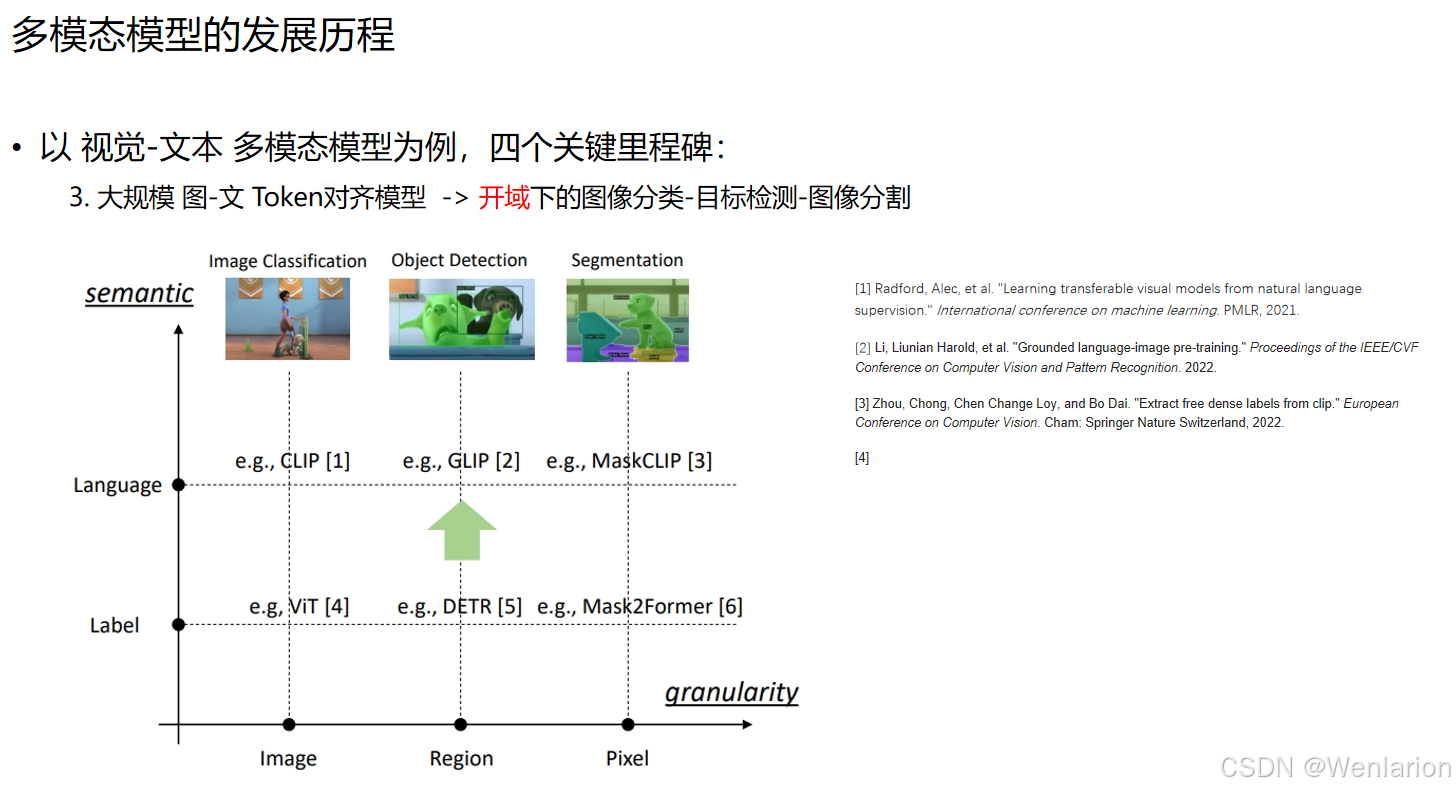
3. 对齐模型的下游拓展(开域视觉任务)
基于 CLIP 的图文对齐能力,技术向更细粒度的视觉任务延伸:
-
开域图像分类:CLIP 直接通过文本标签实现零样本分类;
-
开域目标检测:GLIP(Grounded Language-Image Pre-training)将文本与图像区域精准匹配,实现 “文本指定目标” 的检测;
-
开域图像分割:MaskCLIP 在 GLIP 基础上,进一步实现像素级的文本匹配分割。
-
补充论文:
-
GLIP:Li, Yuxin, et al. Grounded language-image pre-training. CVPR 2022.https://arxiv.org/abs/2112.03857
-
MaskCLIP:Zhou, Chong, et al. Extract free dense labels from clip. ECCV 2022.https://arxiv.org/abs/2112.01037
-
DERT: End-to-End Object Detection with Transformers. ECCV 2020https://arxiv.org/abs/2005.12872
-
Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation.CVPR 2022 https://arxiv.org/abs/2112.01527
-
-
代码地址:
-
GLIP 官方实现:https://github.com/microsoft/GLIP
-
MaskCLIP 官方实现:https://github.com/chongzhou96/MaskCLIP
-
Mask2Former:https://github.com/facebookresearch/Mask2Former
-
Flamingo
Flamingo 是由 DeepMind 提出的一种视觉语言模型(VLM),其核心突破在于能够在不重新训练整个模型的情况下,通过少量的示例(Few-shot)学习来处理视觉和语言任务。
以下是详细信息:
📄 论文信息
- 论文标题: Flamingo: a Visual Language Model for Few-Shot Learning
- ArXiv 地址: https://arxiv.org/abs/2204.14198
- PDF 下载: https://arxiv.org/pdf/2204.14198.pdf
- 发表会议: NeurIPS 2022
💻 代码与模型权重
- 官方代码仓库 (GitHub): https://github.com/deepmind/flamingo
- 注意: DeepMind 开源了模型的推理代码和架构实现,但未公开预训练权重。你需要自己准备数据并按照论文描述进行训练,或者使用社区基于该架构复现的模型。
- 开源复现版本 (OpenFlamingo):
由于官方未开放权重,社区(主要是 LAION 和 Hugging Face 合作)推出了完全开源的复现版本 OpenFlamingo,提供了预训练权重。- 项目主页: https://github.com/mlfoundations/open_flamingo
- Hugging Face 模型: 搜索
openflamingo(例如openflamingo/OpenFlamingo-9B-vitl-mpt1b)
💡 核心简介与贡献
-
冻结的骨干网络 (Frozen Backbones):
Flamingo 的创新之处在于它冻结了两个强大的预训练模型:- 一个预训练的语言模型(如 Chinchilla 或 MPT)。
- 一个预训练的视觉编码器(如 Perceiver Resampler 处理的 ViT)。
它只训练插入在两者之间的轻量级“交叉注意力层”(Perceiver Resampler layers),这使得训练效率极高。
-
少样本学习 (Few-Shot Learning):
这是 Flamingo 最著名的能力。用户可以在输入中直接提供“图像 - 文本”对作为示例(Context),模型能够立即理解任务模式并对新的图像做出反应,而无需微调权重。- 例子: 输入 [图A, "这是一只猫"], [图B, "这是一只狗"], [图C, ?] -> 模型输出 "这是一只鸟"。
-
任意数量的视觉输入:
模型可以处理单张图像、多张图像甚至视频帧序列,并将其作为上下文令牌插入到语言模型的序列中。 -
局限性:
由于官方权重未公开,直接使用原版 Flamingo 需要巨大的计算资源进行从头训练。因此,目前研究和应用中更多使用的是 OpenFlamingo 或其他受其启发的架构(如 LLaVA 系列虽然架构不同,但也吸收了其多模态融合的思想)。
总结: Flamingo 证明了通过巧妙地连接预训练的视觉和语言模型,可以实现强大的少样本多模态推理能力,是多模态大模型发展史上的里程碑之作。

CLIP 提供的 “文本 - 视觉语义映射”,结合扩散模型、GAN 等生成架构,催生了一批顶尖文生图模型,形成了 2021-2023 年的技术井喷。
|
时间 |
模型 / 技术 |
机构 |
核心特点 |
|---|---|---|---|
|
2021.01 |
DALL-E |
OpenAI |
结合 CLIP 的图文对齐,首次实现高质量文生图(基于 Transformer) |
|
2021.05 |
CogView |
清华大学 |
中文文生图先驱,基于 Transformer 的自回归生成 |
|
2021.11 |
NUWA |
微软 |
支持视频 + 图像的多模态生成 |
|
2022.04 |
DALL-E 2 |
OpenAI |
采用 “CLIP 对齐 + 扩散模型”,大幅提升图像分辨率和语义一致性 |
|
2022.05 |
Imagen |
|
基于扩散模型,通过大语言模型优化文本理解,生成质量领先 |
|
2022.08 |
Stable Diffusion (SD) |
Stability AI |
开源扩散模型,结合 CLIP 文本编码器,成为产业级文生图基础工具 |
|
2023.03 |
Midjourney V5 |
Midjourney |
闭源商业模型,极致的视觉效果和艺术表现力 |
核心生成技术代码地址
-
Stable Diffusion(最主流):https://github.com/Stability-AI/stablediffusion
-
DALL-E 2(官方开源组件):https://github.com/openai/DALL-E
-
Imagen(Google 研究版):https://github.com/google-research/imagen
-
CogView(中文文生图):https://github.com/THUDM/CogView
里程碑 4:多模态大语言模型的出现

GPT-4v
GPT-4V 代表了多模态大语言模型的重要里程碑,它将强大的语言理解能力与先进的视觉感知能力深度融合,能够处理从简单的图像描述到复杂的逻辑推理、时序分析等多样化任务,展现了通用人工智能在多模态交互方面的巨大潜力。
1. 图 - 文交替输出能力
-
输入:可同时接收文本和图像信息,支持多张图像的序列输入。
-
输出:以自然语言文本形式回答问题。
-
示例:
-
分析多张购物小票,计算总税额。
-
结合菜单图片和餐桌图片,计算啤酒总价。
-
不直接支持视频输入,但可通过多帧图像序列理解时序信息。
-

2. 理解视觉指向和参考
-
能够识别图像中的指向(如黄线、红框),并对被指向的区域进行详细描述。
-
示例:
-
描述图片中黄线指向的一排装饰灯。
-
解读表格中红框高亮的数值(如 122.3)及其含义。
-
结合几何图形,应用勾股定理和三角函数进行推理计算。
-

3. 支持视觉 + 文本联合提示
-
可以同时处理图像和文本指令,进行逻辑推理。
-
示例:
-
观察第一列图形的变化规律(如添加一条线、在中心加一个点),推断第二列的缺失图形。
-
解决矩阵式的视觉推理题,从选项中选择符合逻辑的答案。
-
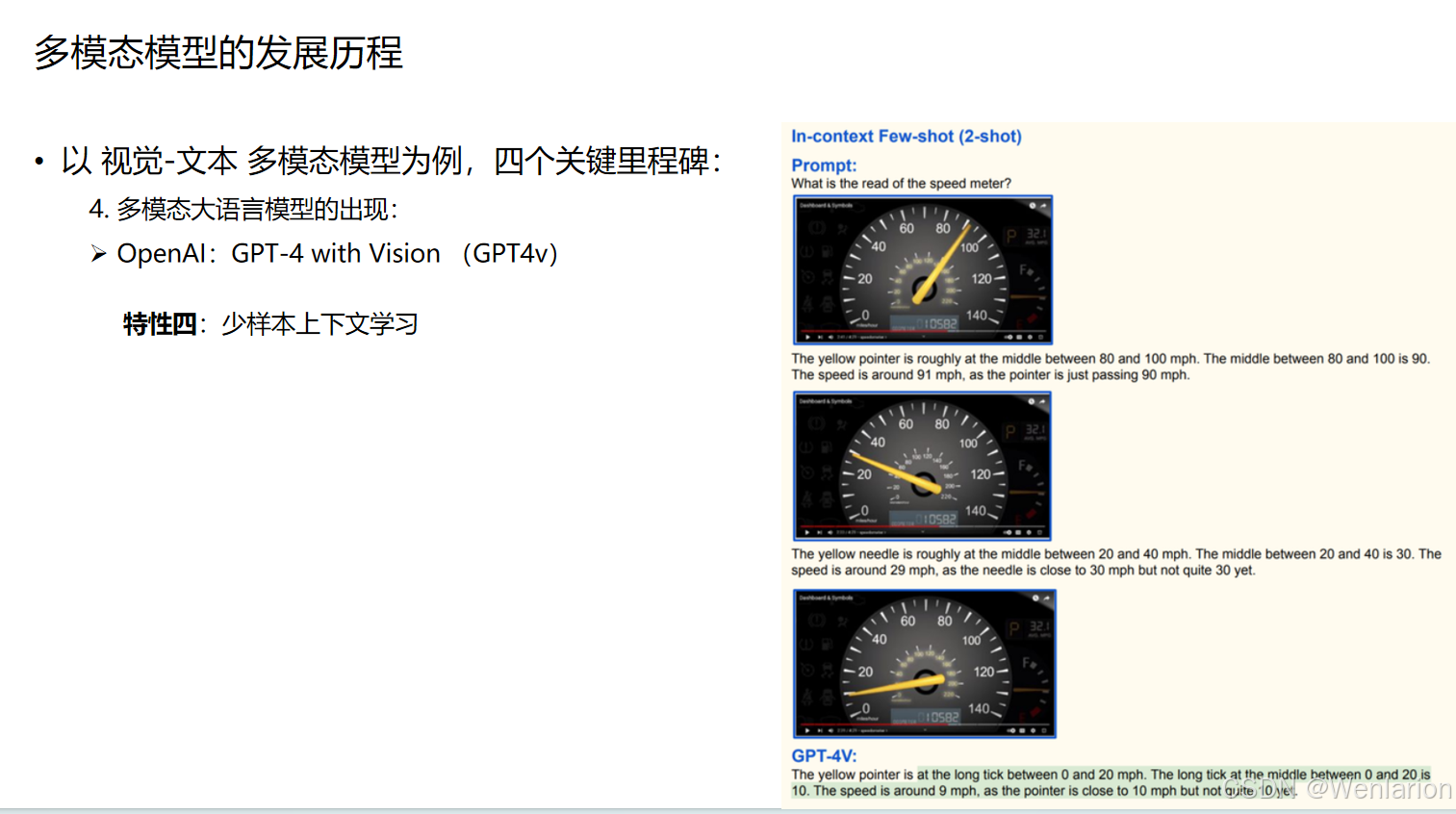
4. 少样本上下文学习(In-context Few-shot)
-
仅需少量示例,就能快速学习并应用新的视觉任务。
-
示例:
-
通过两个示例学习如何读取汽车速度表,然后准确判断第三张图的速度。
-


5. 强大的视觉认知能力
-
覆盖了广泛的视觉理解场景:
-
识人:识别图中人物(如 NVIDIA CEO Jensen Huang)及其行为。
-
识地:识别地标(如旧金山九曲花街)并描述其背景。
-
识菜:识别菜品(如麻婆豆腐)并介绍其特点。
-
Logo 识别:识别并描述品牌标志(如 Nike Air Force 1)。
-
医疗图像:描述医学影像(如牙科 X 光片)的细节。
-
通用场景分析:分析道路场景,识别车辆、交通标志和天气。
-
文字识别:提取图像中的手写或印刷文字(如黑板上的夏日信息)。
-
图表文档理解:分析复杂图表(如食物网),识别生产者等关键信息。
-
计数:准确统计图像中物体的数量(如 16 个苹果)。
-
目标定位:检测并定位图像中的物体,输出其边界框坐标和图像尺寸。
-
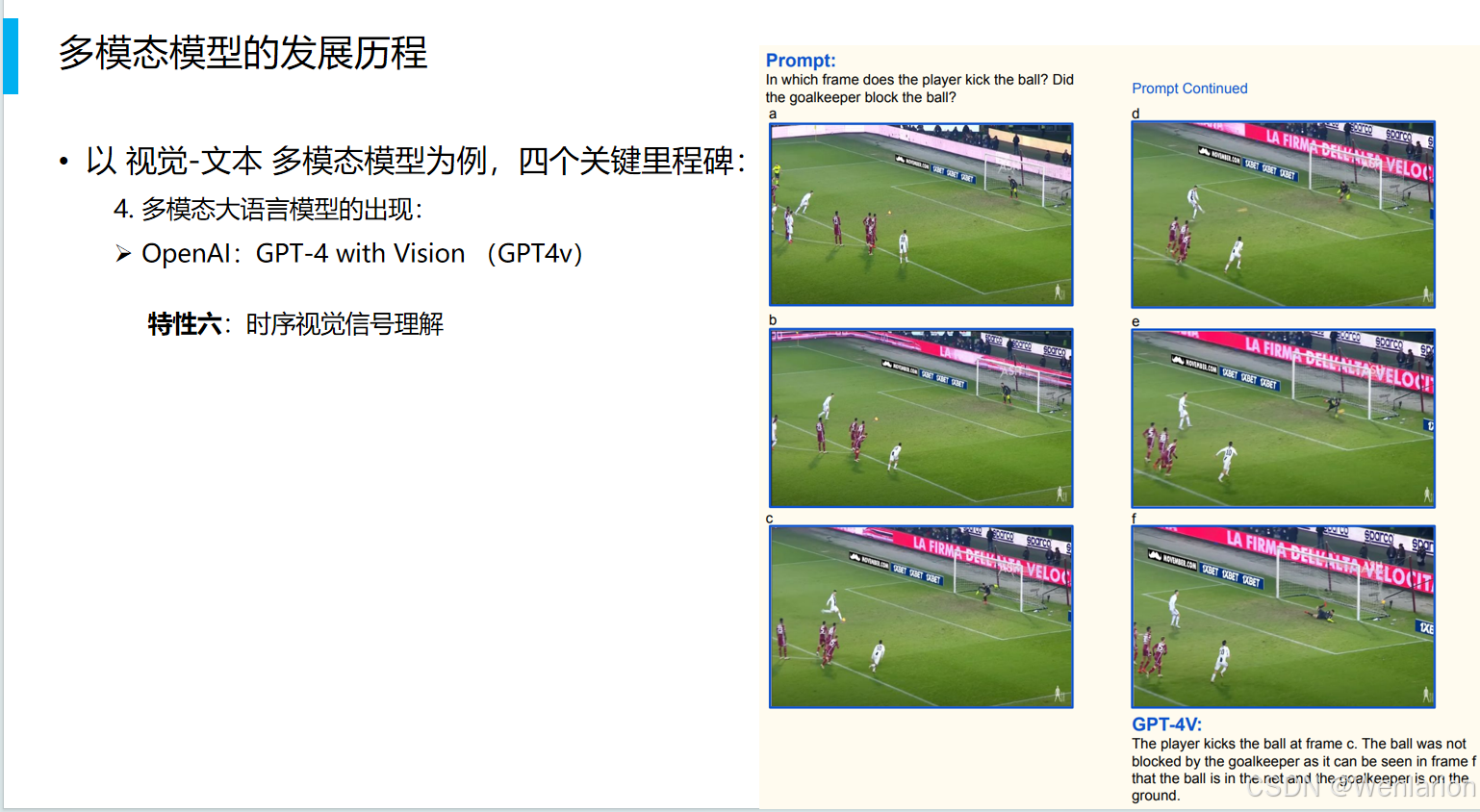
6. 时序视觉信号理解
-
通过多帧图像序列,理解事件的发展过程。
-
示例:
-
分析足球比赛的连续帧,判断球员在第 c 帧踢球,且球在第 f 帧入网,守门员未能成功扑救。
-
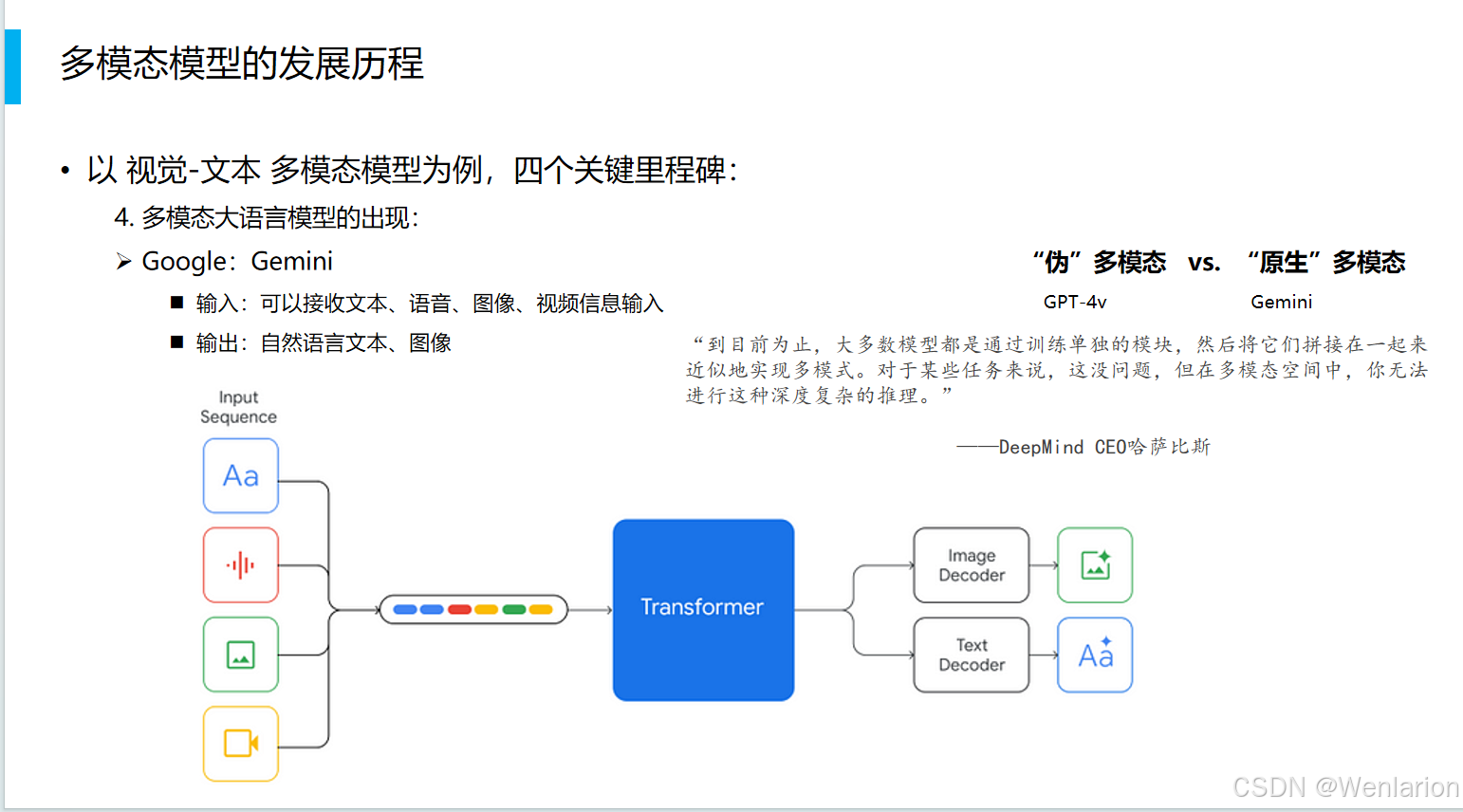

Google Gemini
Gemini 是 Google DeepMind 提出的原生多模态大语言模型,与 “伪多模态”(如 GPT-4v,通过拼接独立模块实现)不同,它从底层架构上就统一处理多种模态。
-
核心能力
- 输入:支持文本、语音、图像、视频等多模态信息输入。
- 输出:可生成自然语言文本和图像。
- 架构:通过统一的 Transformer 架构,将不同模态的输入编码为统一的序列表示,再进行深度推理。
-
关键特性
多模态内容输出:
能够根据文本指令,同时生成连贯的自然语言描述和对应的图像。例如,根据 “写一篇关于纽约旅行的博客,并包含狗狗在不同地标前的照片” 的指令,生成一篇博客文章和三张相关图片。
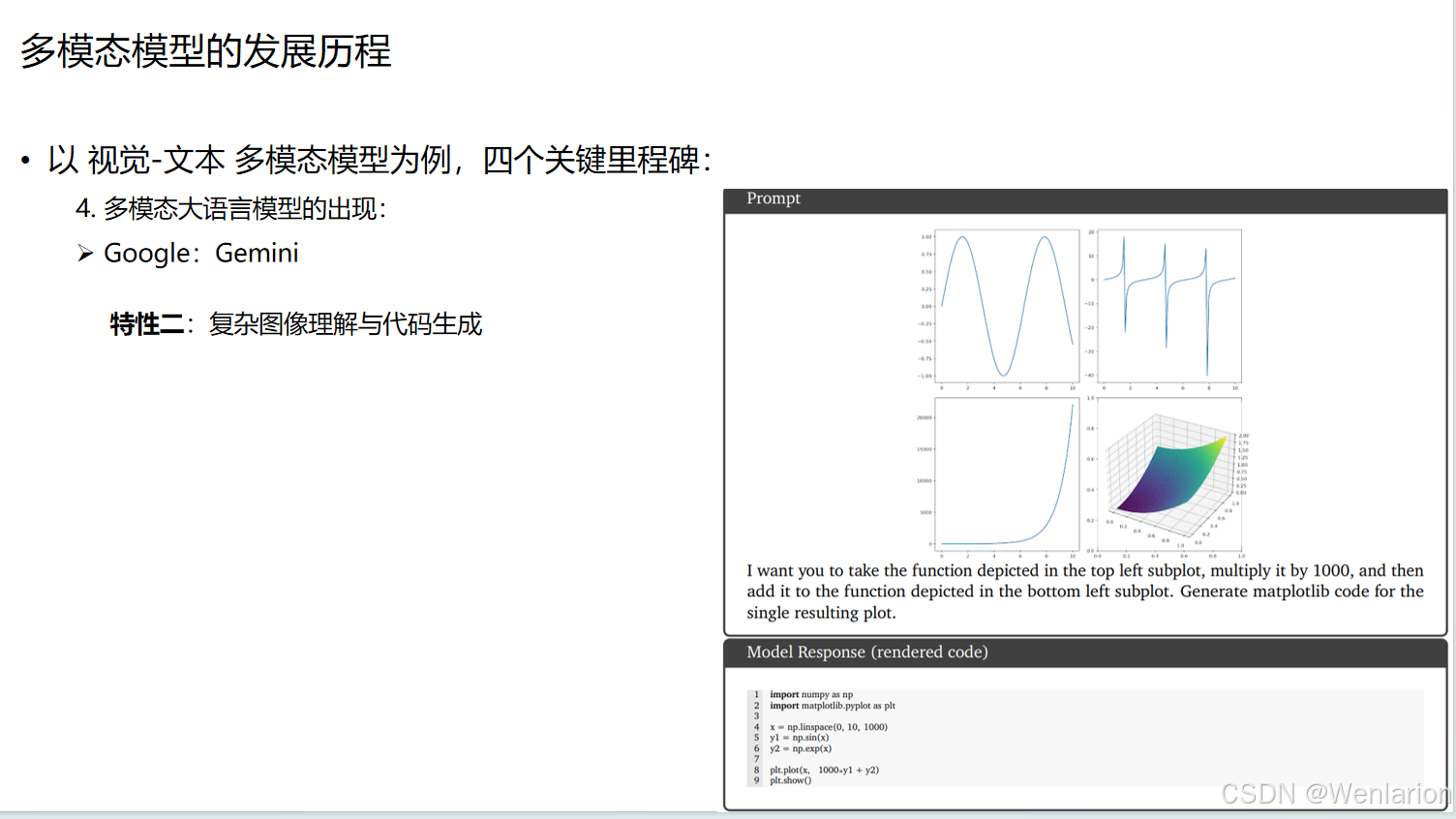
复杂图像理解与代码生成:
可以理解复杂的图表和数学函数,并根据视觉信息生成可执行的代码。例如,分析图表中的函数曲线,生成对应的 matplotlib 代码来复现或修改图表。
-
相关论文与资源
- Gemini: A Family of Highly Capable Multimodal Models (Google DeepMind, 2023)
- 官方资源:
- Google Gemini 官网:https://deepmind.google/technologies/gemini/
- Google AI Studio:https://aistudio.google.com/

Anthropic Claude 3
Claude 3 是 Anthropic 推出的新一代多模态模型,专注于强大的图像理解和文本生成能力。
-
核心能力
- 输入:支持文本和图像信息输入,不支持视频,但可以处理多张图像的序列输入。
- 输出:生成自然语言文本。
- 特点:在复杂推理、长上下文处理和视觉理解方面表现出色,尤其擅长解读文档、图表和科学图像。
-
相关论文与资源
- Claude 3 Model Card (Anthropic, 2024)
- API 与开发资源:
- Anthropic 开发者平台:https://www.anthropic.com/developers

OpenAI GPT-4o (Omni)
GPT-4o (Omni) 是 OpenAI 最新的旗舰多模态模型,代表了当前多模态技术的前沿。
-
核心能力
- 输入:全面支持文本、语音、图像和视频信息输入。
- 输出:可生成自然语言、语音、图像,视频输出功能尚未开放。
- 定位:旨在实现 “全模态” 的智能交互,将各种模态的输入与输出深度整合。
-
相关论文与资源
- GPT-4o Technical Report (OpenAI, 2024)
- API 与开发资源:
- OpenAI 开发者平台:https://platform.openai.com/docs/guides/vision
2.1.2 多模态大语言模型的应用
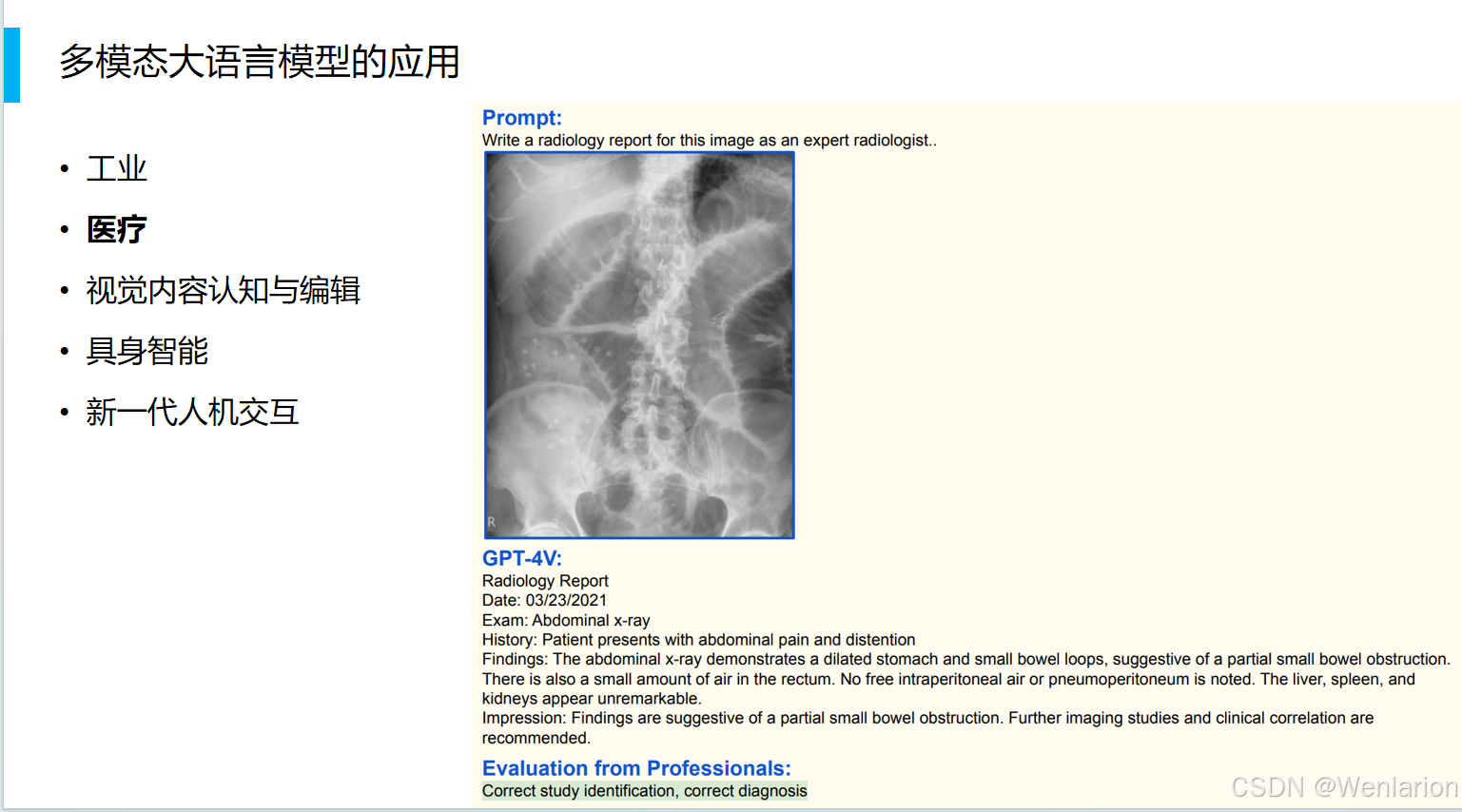
工业

医疗
视觉内容认知与编辑
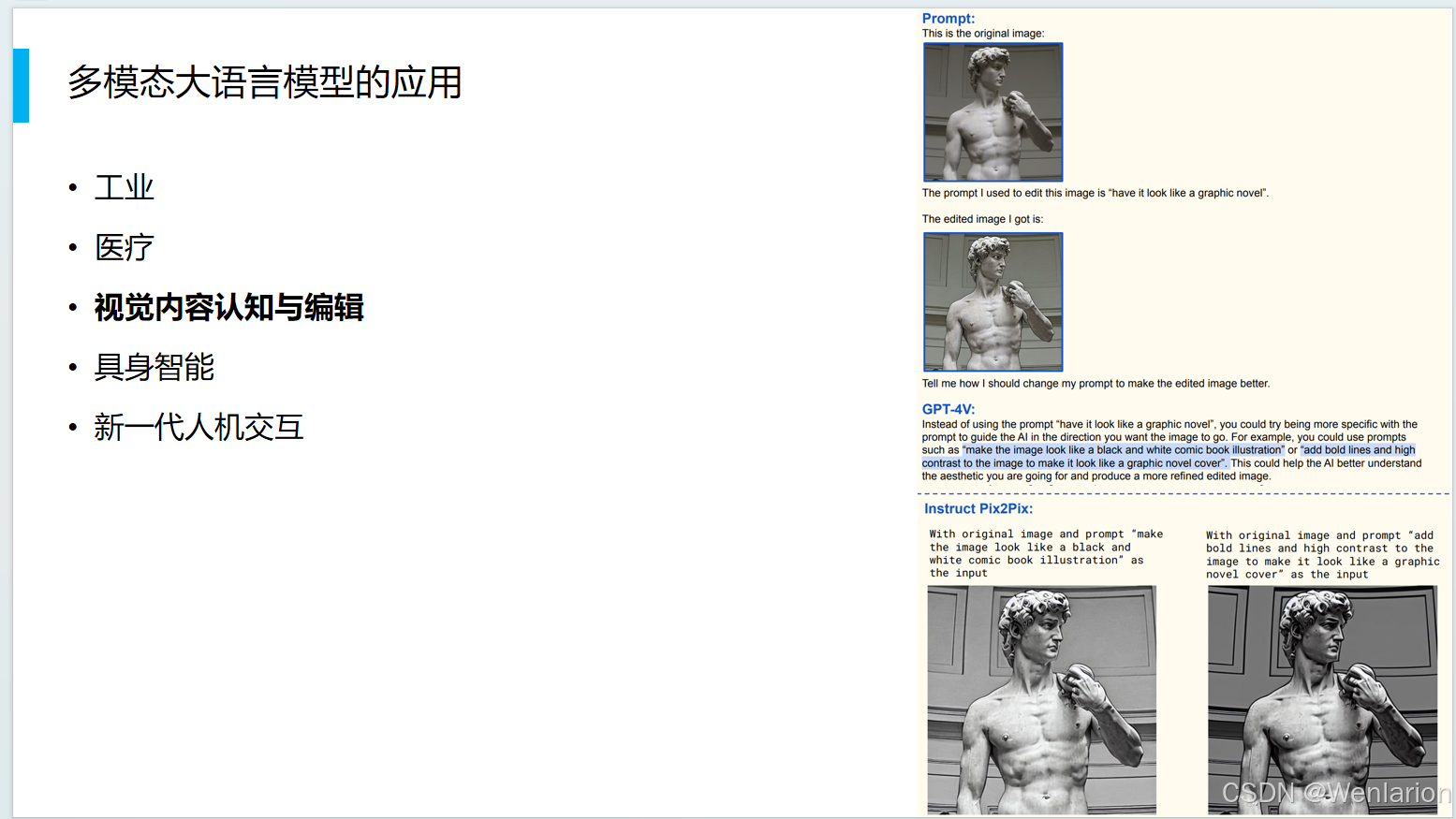
具身智能
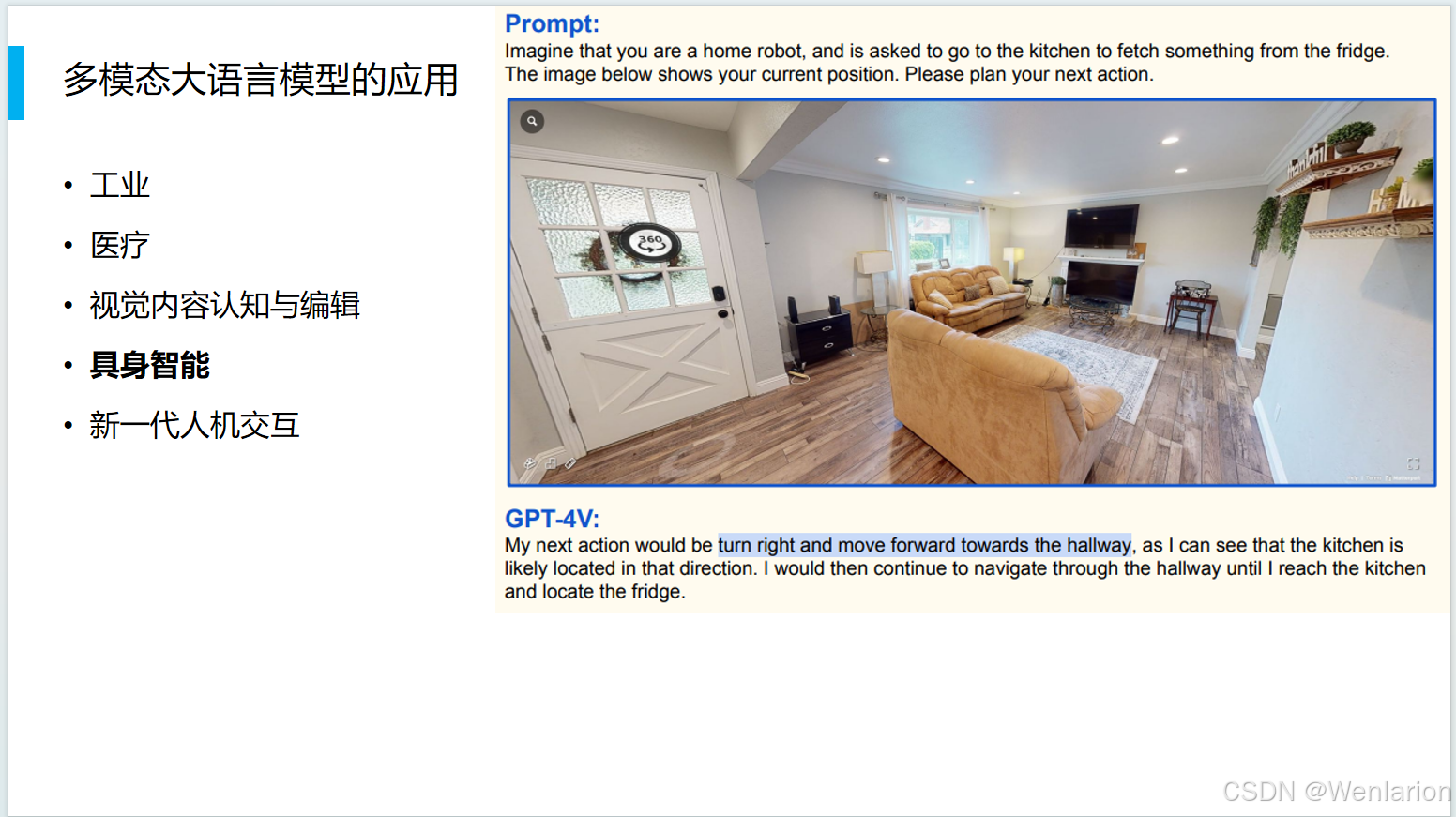
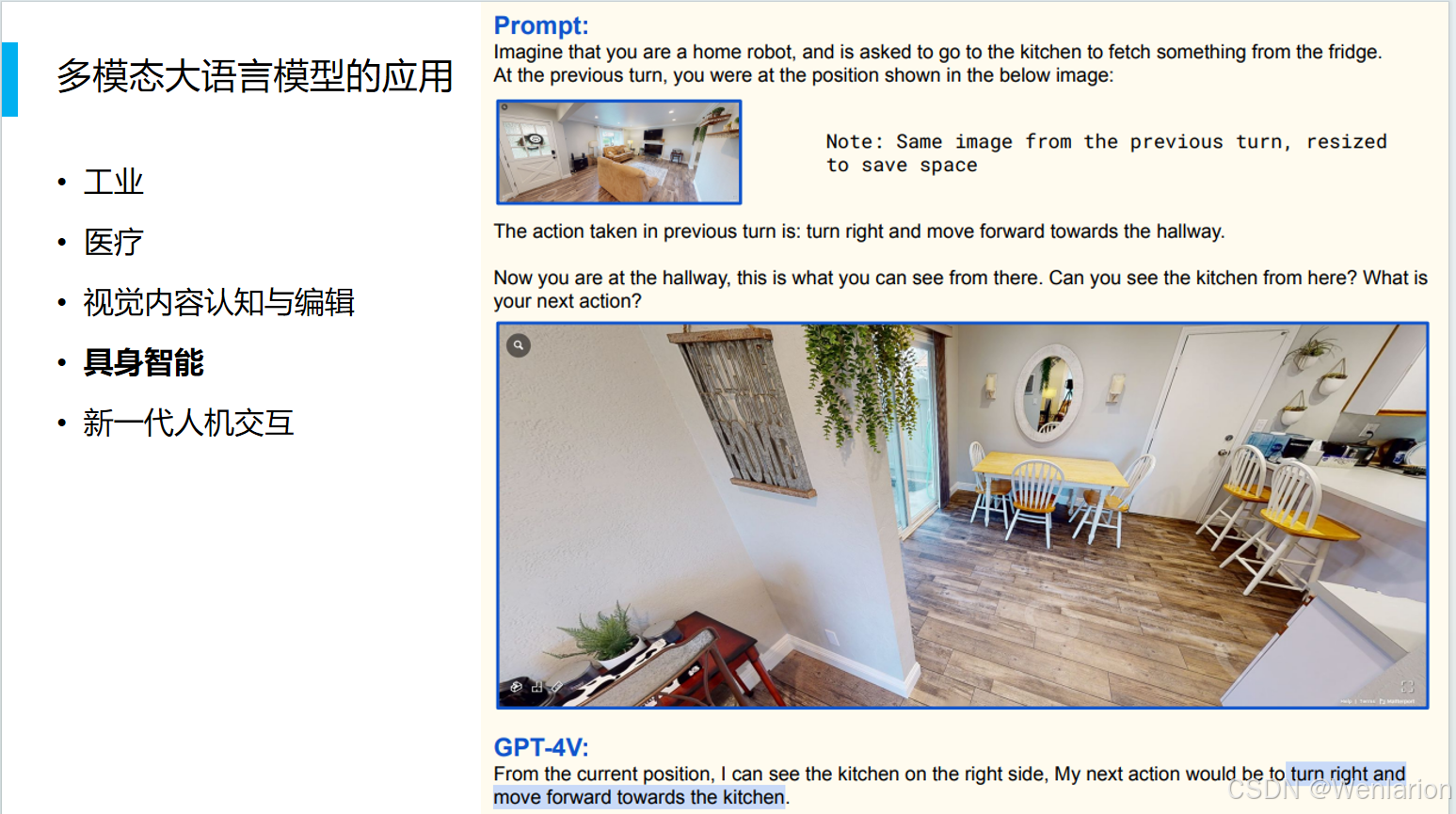
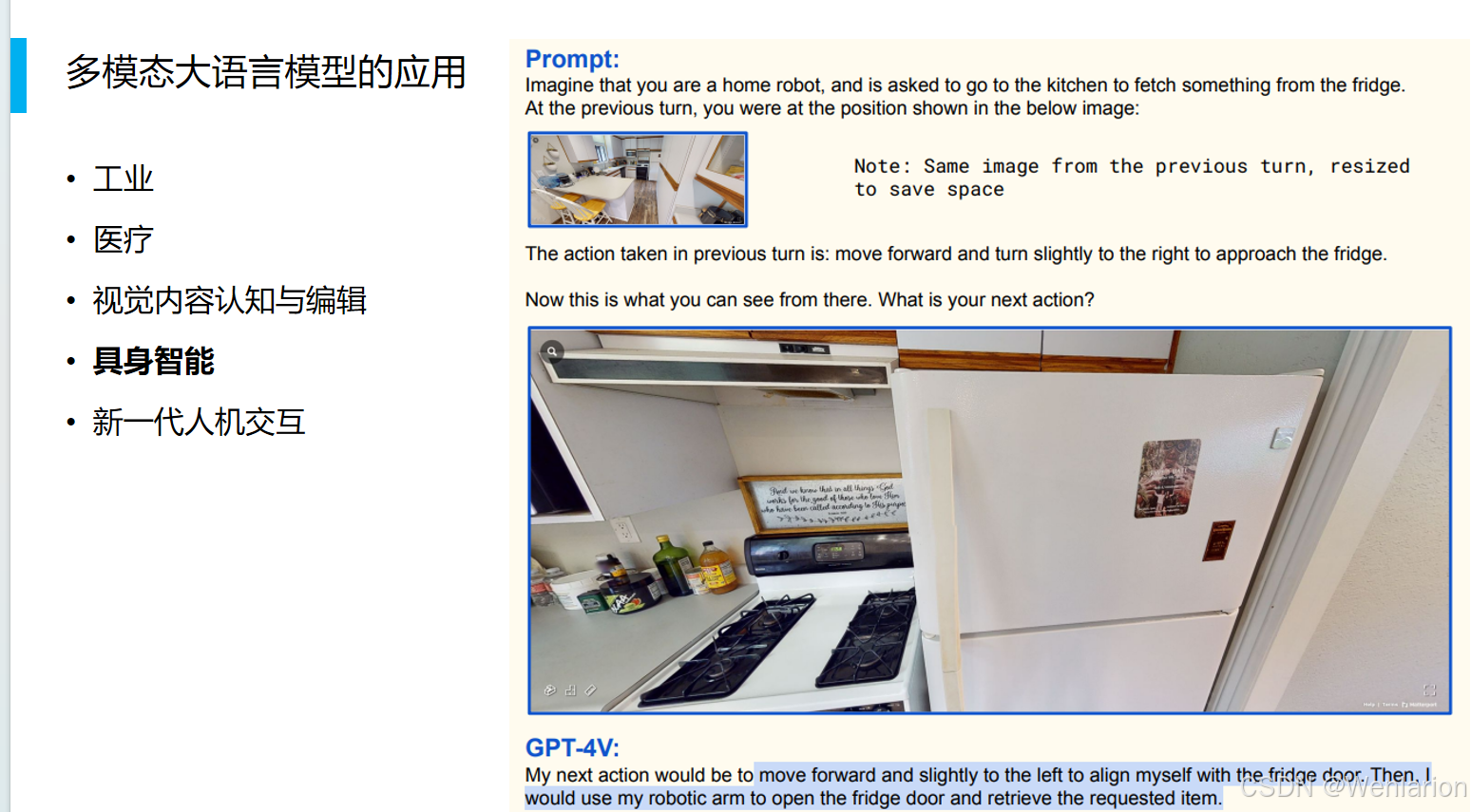
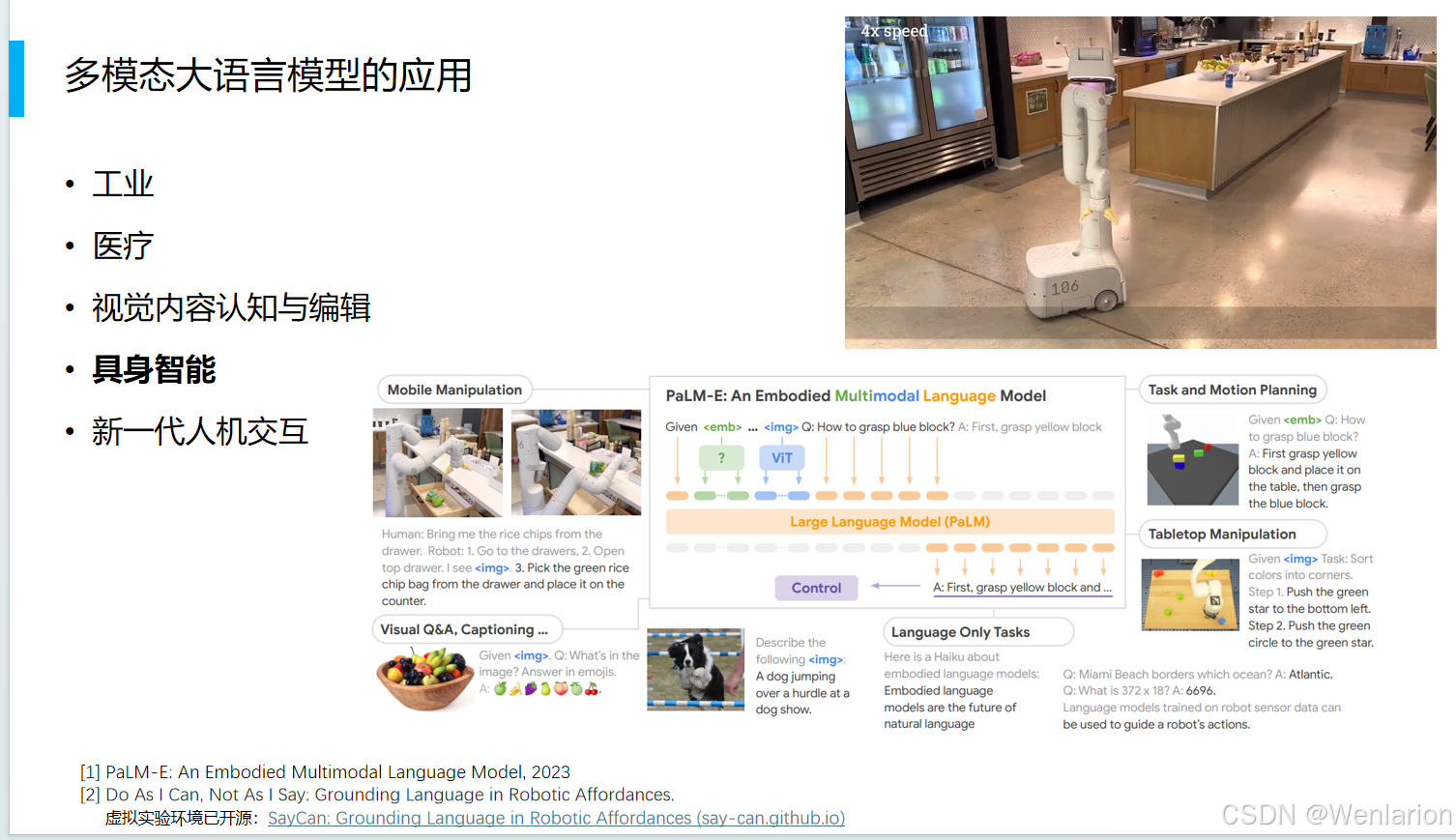
新一代人机交互
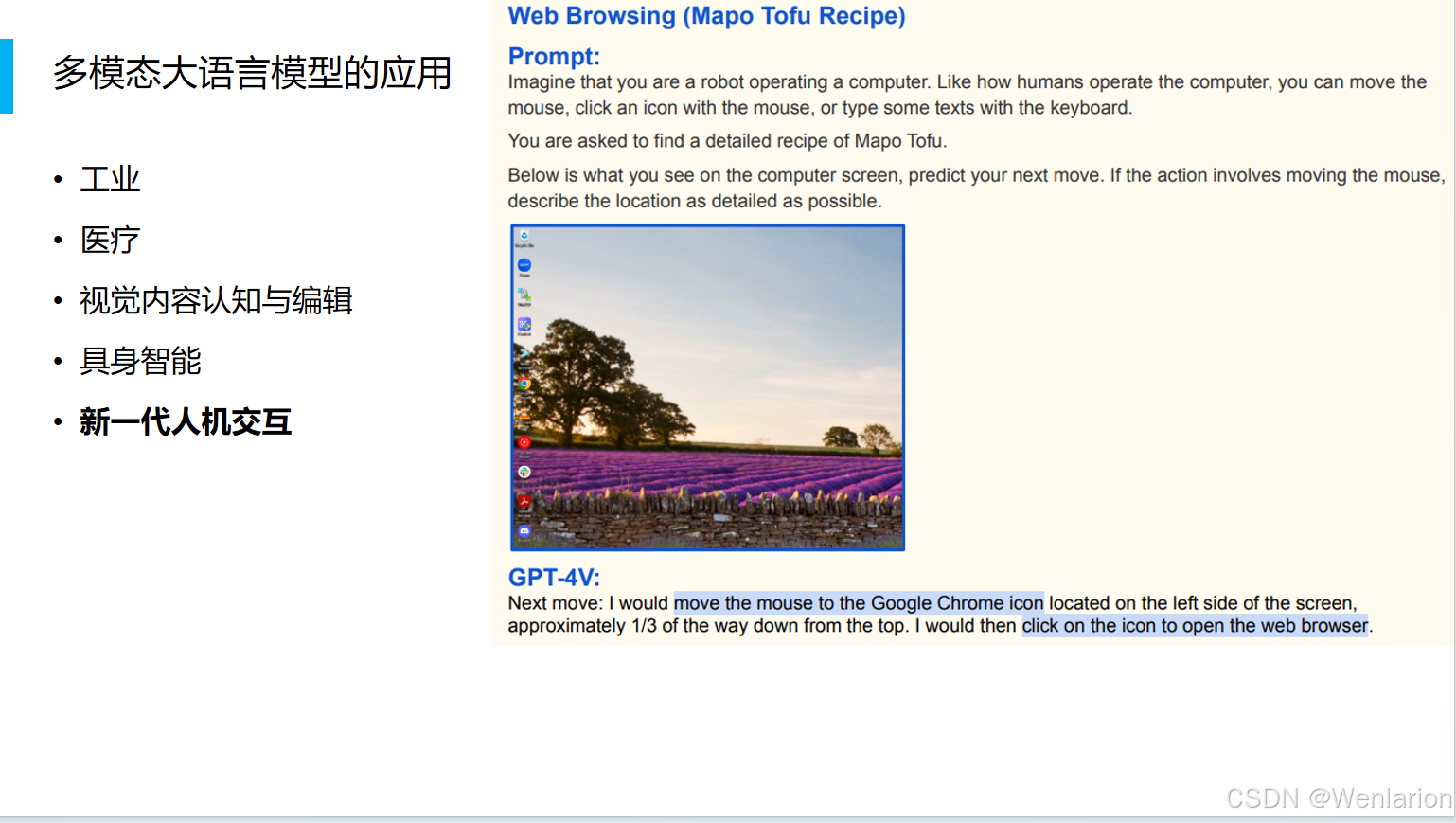
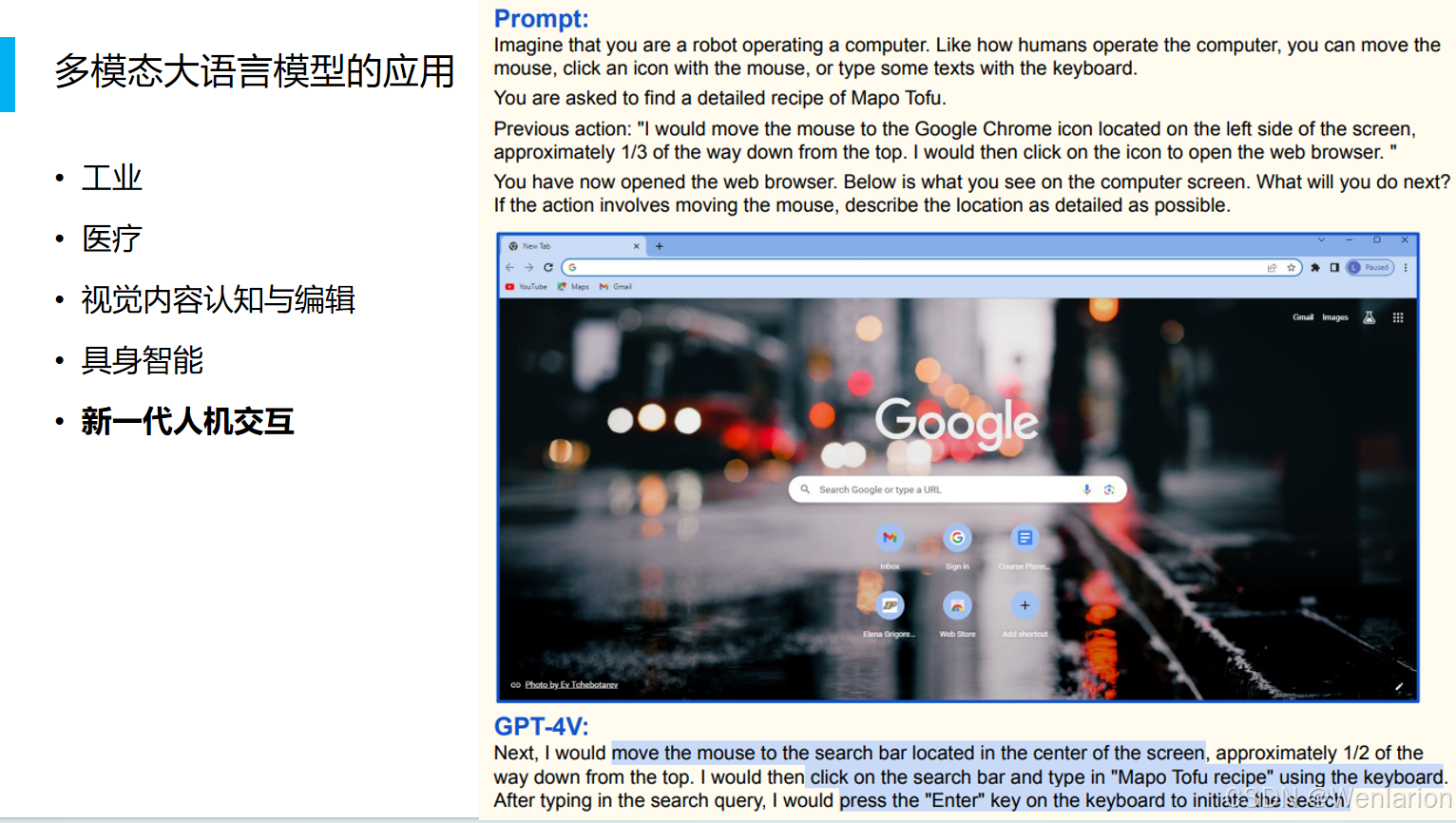
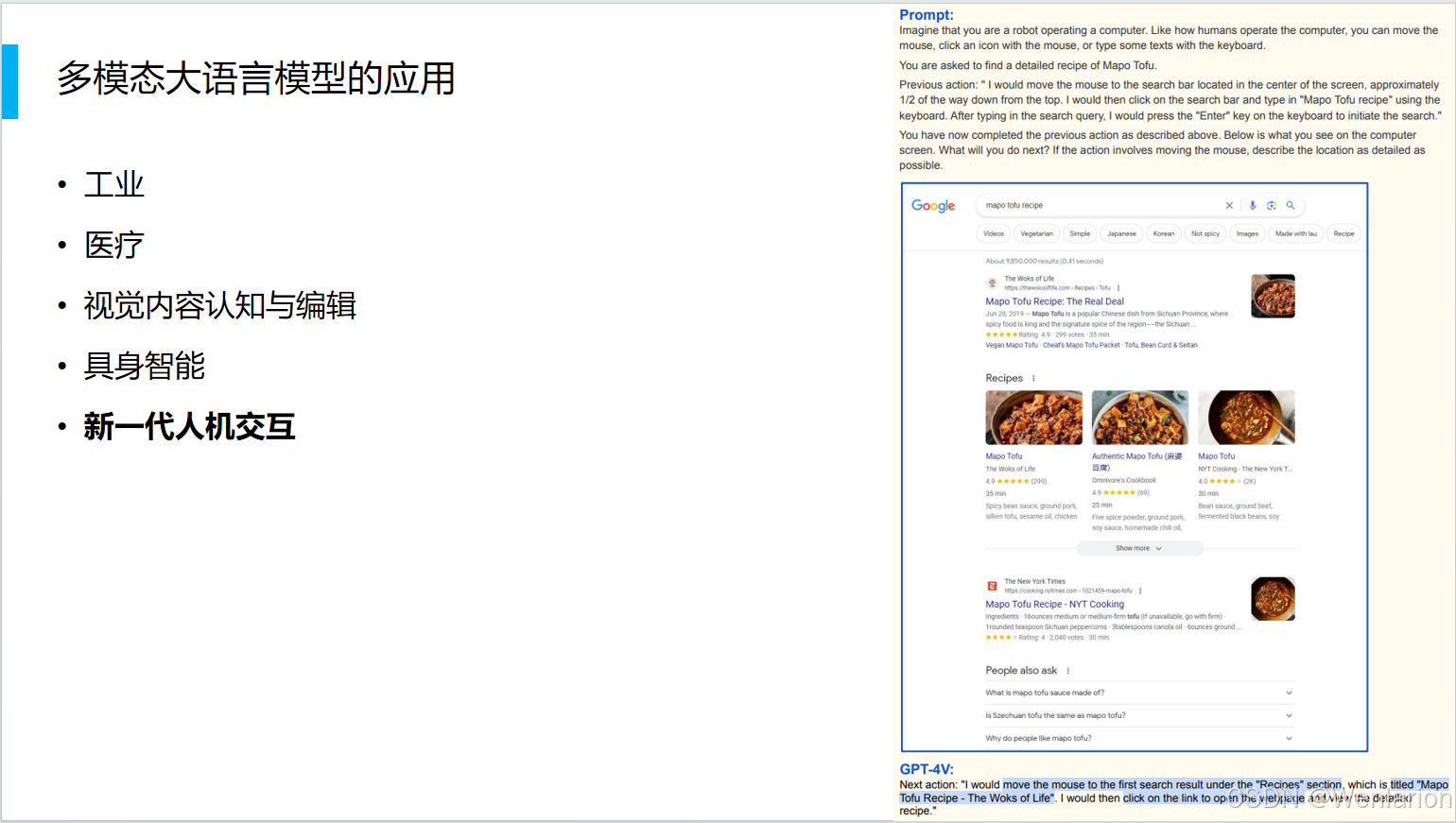
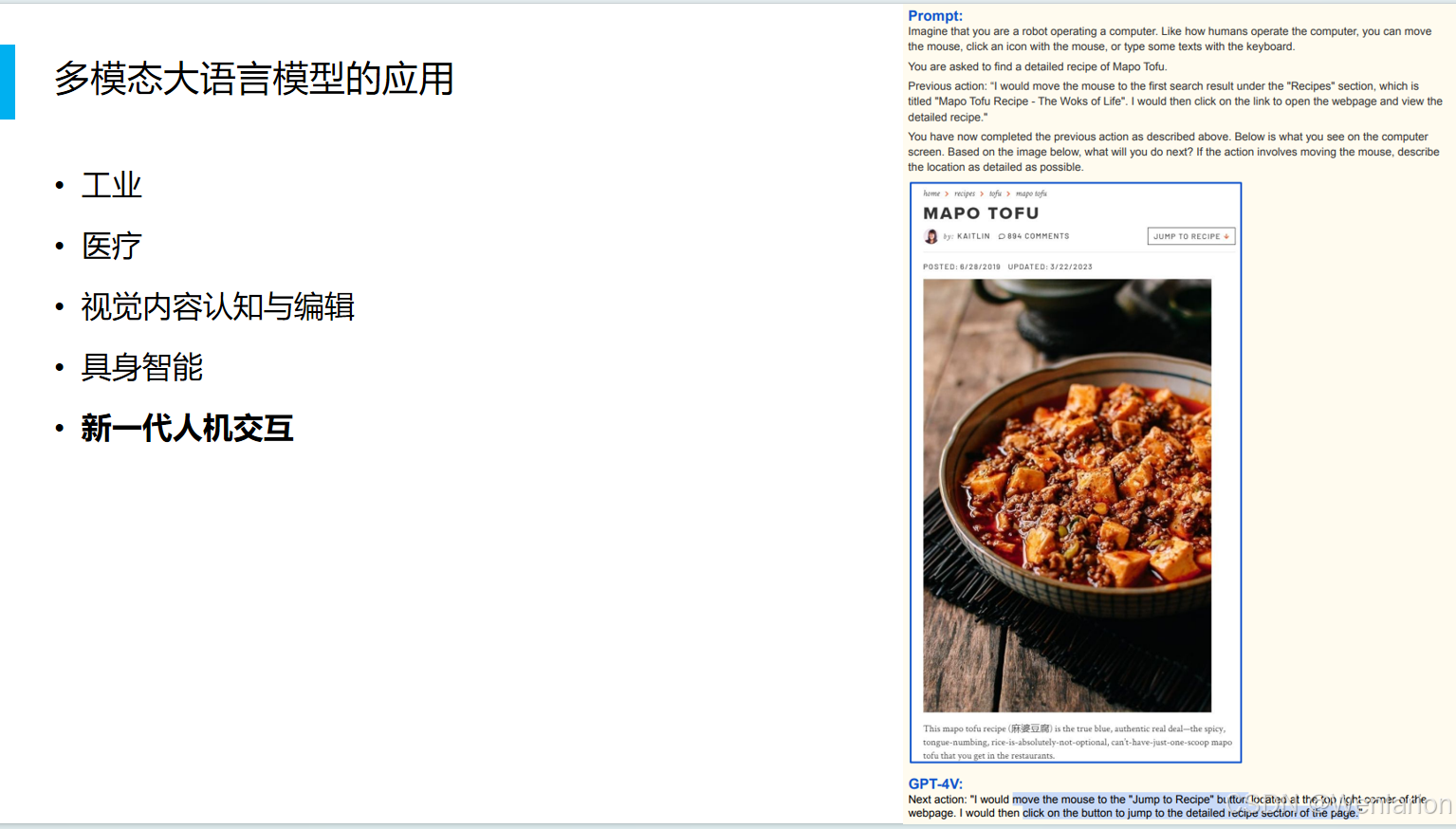
2.2 图文对话系统的搭建
2.2.1 LLaVa 图文对话系统搭建
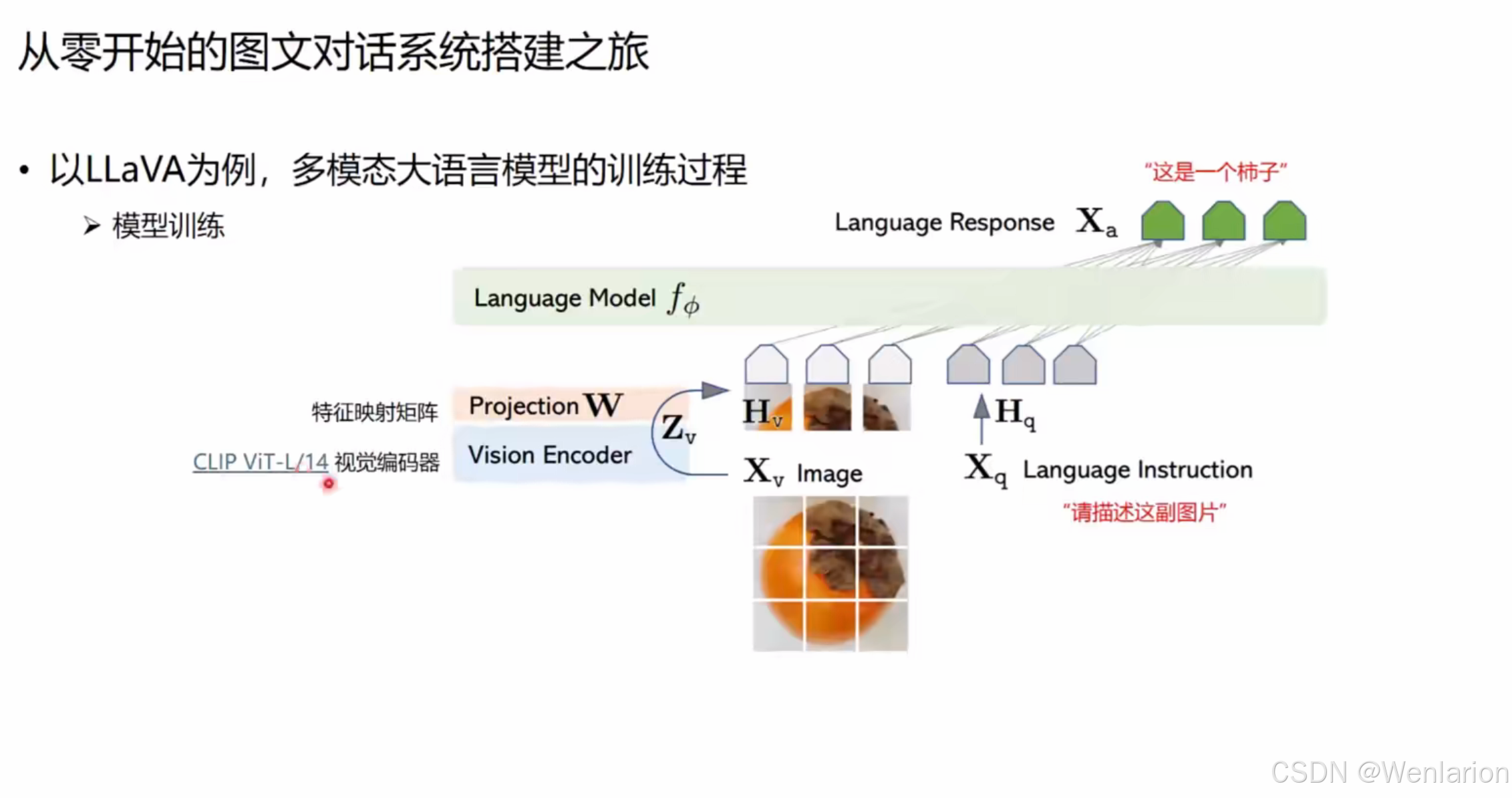
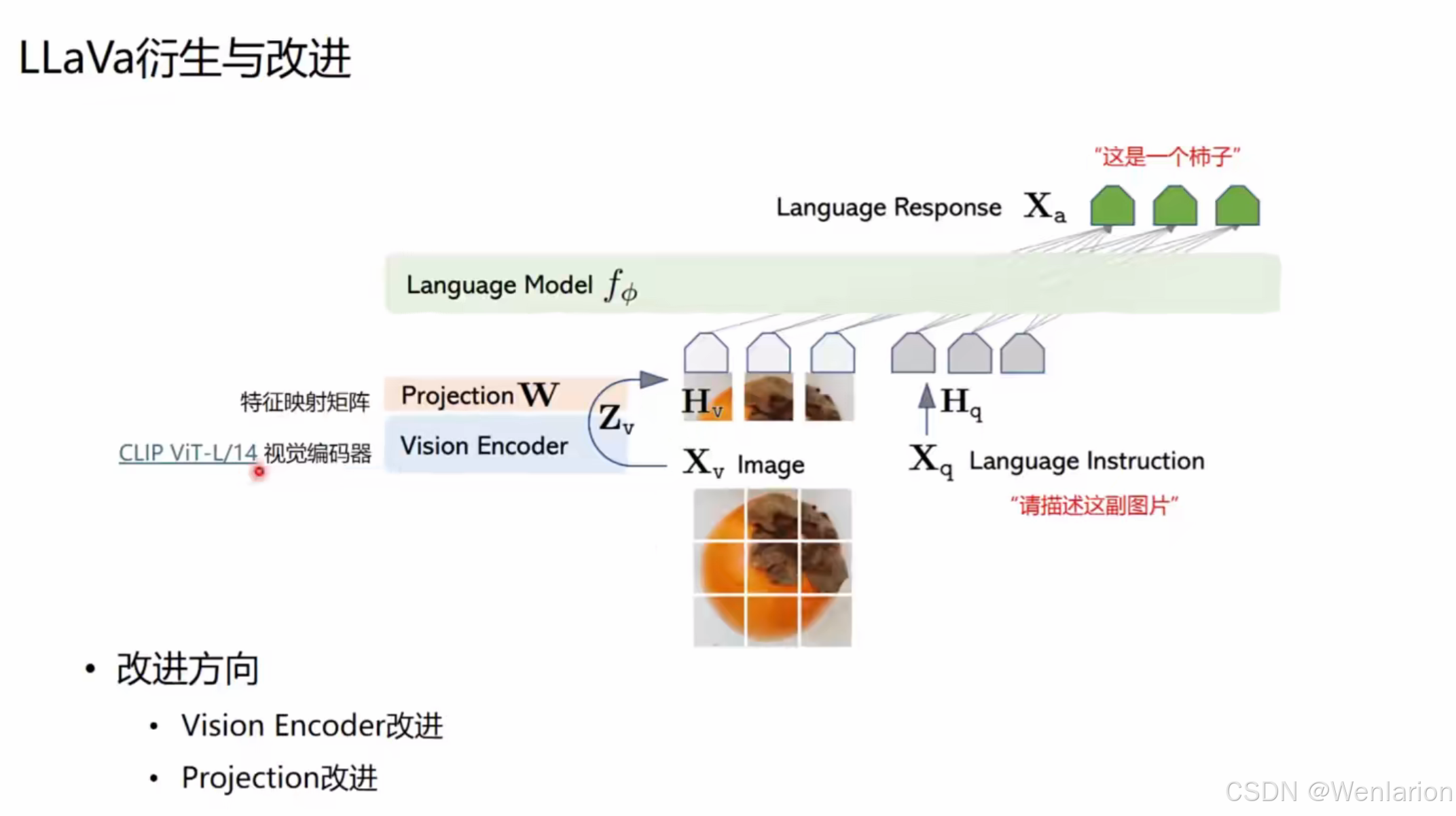
模型架构与推理流程


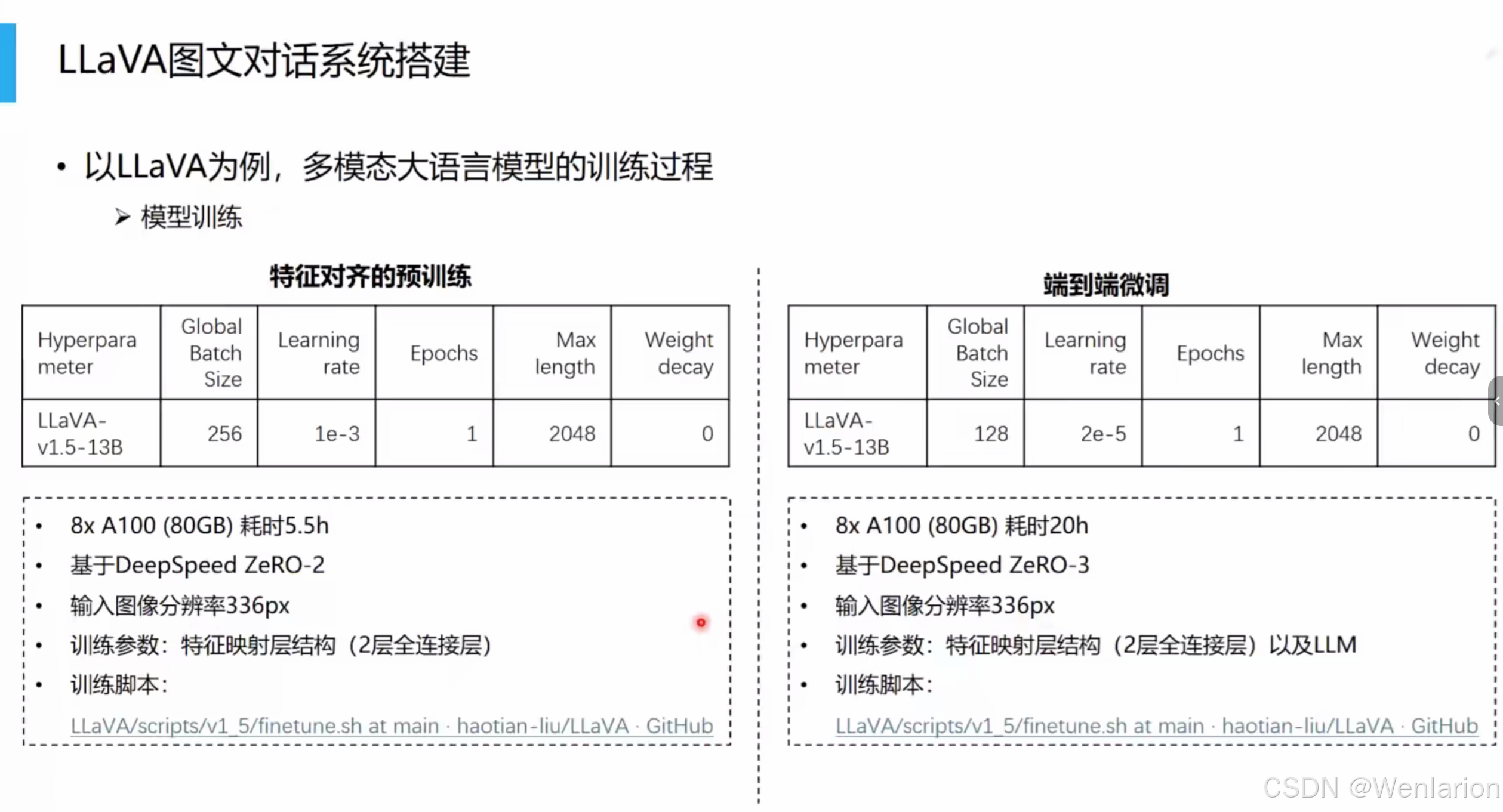
两阶段训练策略
LLaVA 采用分阶段训练,保证视觉 - 语言对齐的同时高效利用算力:
-
阶段一:特征对齐预训练
- 目标:让视觉特征和语言特征在同一空间对齐。
- 冻结:视觉编码器(CLIP)和语言模型(LLM)参数固定。
- 更新:仅训练特征映射矩阵 W(2 层全连接层)。
- 数据:使用图 - 文对齐数据(558K 条),来源包括 LAION、Conceptual Captions 等,形式为 “图像 + 简短描述”。
- 超参(LLaVA-v1.5-13B):全局 batch size=256,学习率 = 1e-3,1 epoch,输入图像分辨率 336px,8×A100 耗时约 5.5 小时。
-
阶段二:端到端微调
- 目标:让模型学会理解复杂指令并生成对话式回答。
- 更新:同时训练特征映射矩阵 W 和语言模型 LLM。
- 数据:使用图 - 文指令数据(665K 条),来源包括 COCO、GQA、OCR-VQA 等,形式为 “图像 + 多轮对话 / 复杂指令”。
- 超参(LLaVA-v1.5-13B):全局 batch size=128,学习率 = 2e-5,1 epoch,输入图像分辨率 336px,8×A100 耗时约 20 小时。


数据准备:两类核心数据集
LLaVA 的训练数据分为两类,分别服务于不同阶段:
| 数据集类型 | 数据规模 | 数据来源 | 数据形式 | 训练阶段 |
|---|---|---|---|---|
| 图 - 文对齐数据 | 558K 条 | LAION、Conceptual Captions、SBU Captions | 图像 + 简短文本描述(如 “这是一个柿子”) | 阶段一(预训练) |
| 图 - 文指令数据 | 665K 条 | COCO、GQA、OCR-VQA、TextVQA、VG_100K | 图像 + 多轮对话 / 复杂指令(如 “图中公交车是什么颜色?”) | 阶段二(微调) |
- 数据增强:指令数据通过 GPT-4 生成,包含图像精细描述、对话、复杂推理三种响应类型,覆盖从基础描述到逻辑问答的全场景。

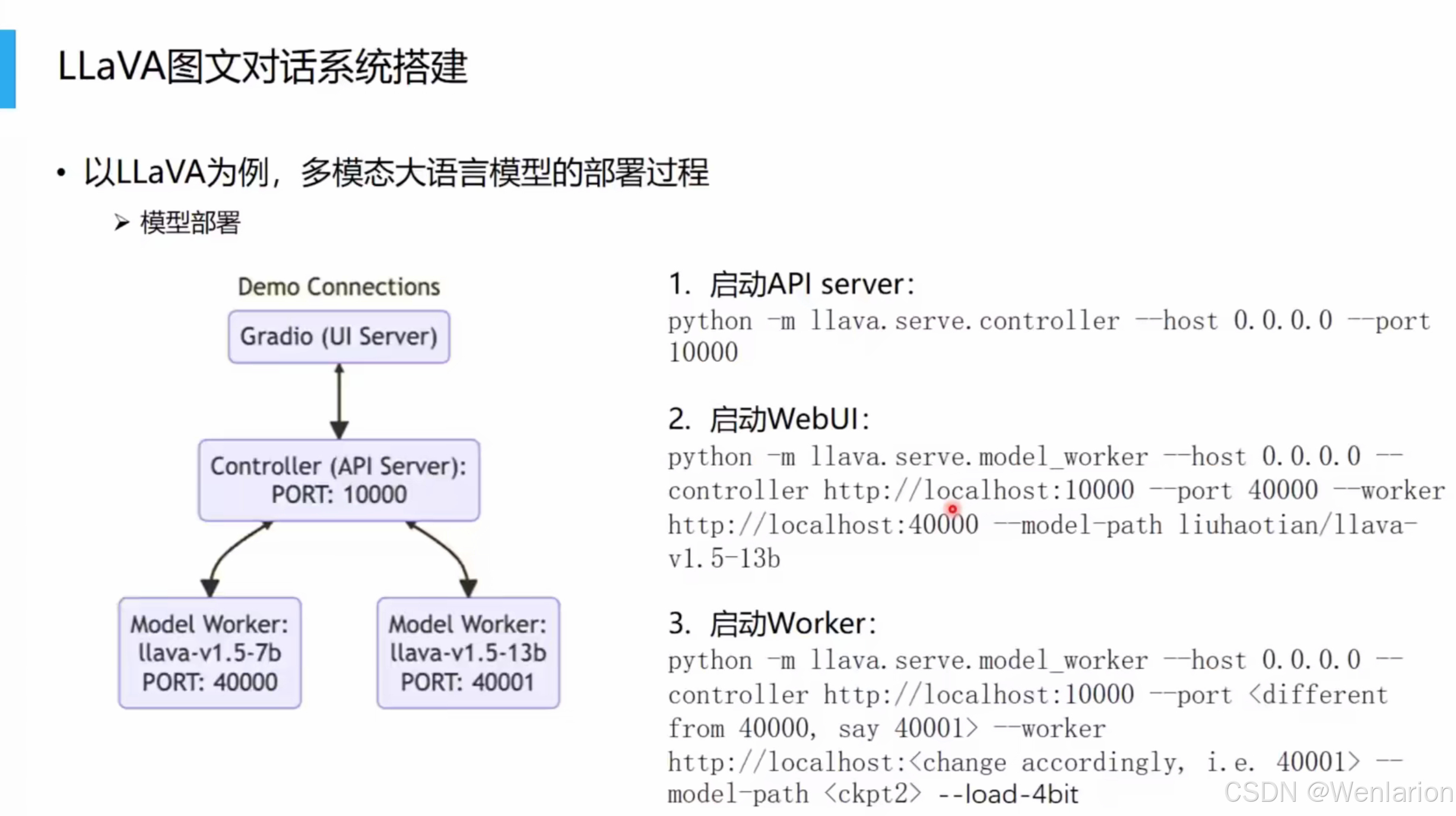
模型部署:分布式服务架构
LLaVA 采用分布式部署,支持多模型并行和 WebUI 交互:
- Controller (API Server):核心调度节点,端口 10000,负责管理多个 Model Worker。
- Model Worker:模型执行节点,加载具体模型(如 llava-v1.5-7b/13b),端口 40000/40001 等。
- Gradio (UI Server):前端交互界面,用户通过浏览器发送请求,由 Controller 分发到 Worker 处理。
- 启动命令:
# 1. 启动 Controller python -m llava.serve.controller --host 0.0.0.0 --port 10000 # 2. 启动 Model Worker python -m llava.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --model-path liuhaotian/llava-v1.5-13b # 3. 启动 WebUI python -m llava.serve.gradio_web_server --controller http://localhost:10000
2.2.2 图文多模态大语言模型的评测
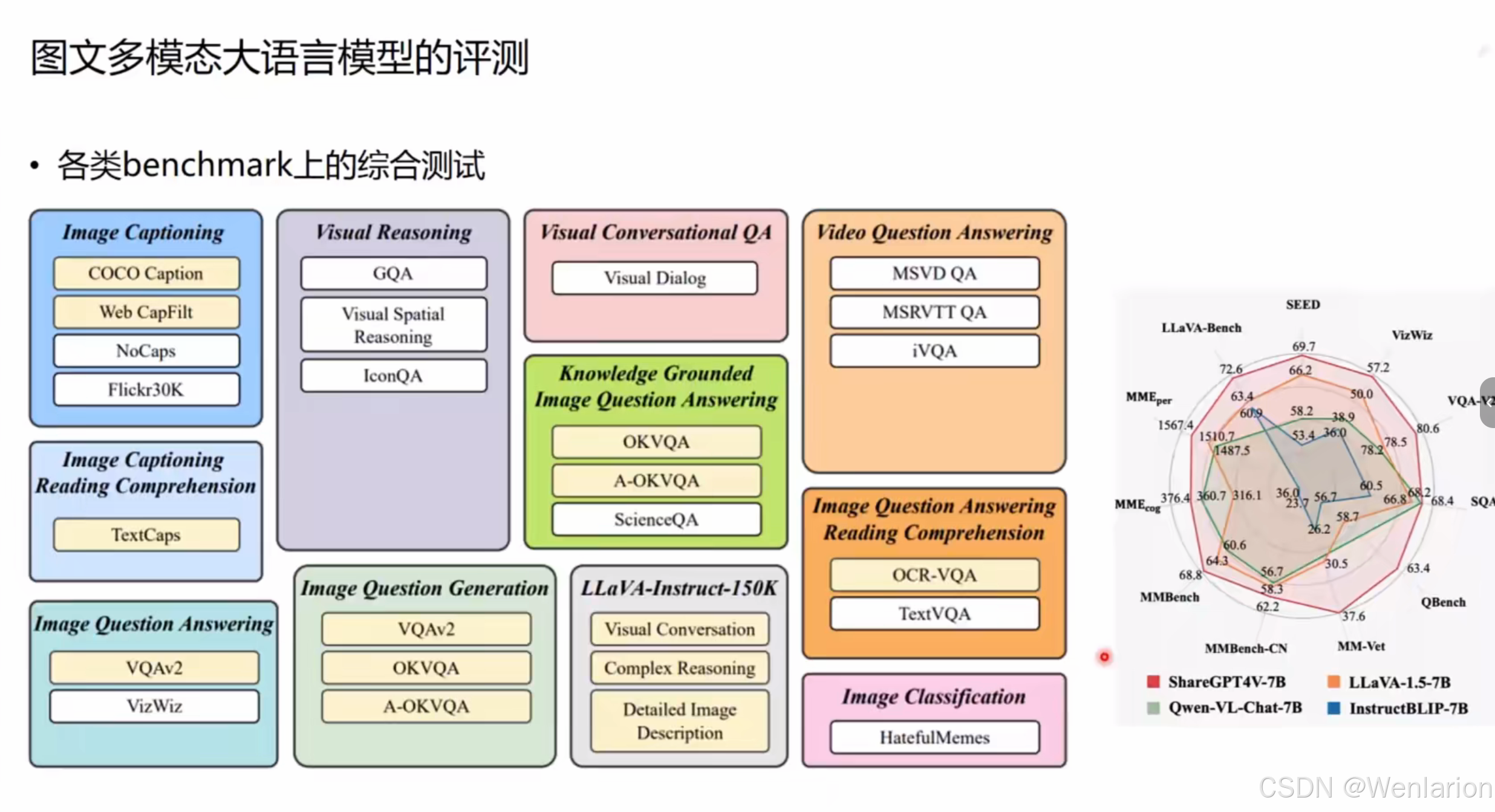
全维度评测全景:各类 Benchmark 综合测试
这张图构建了图文多模态模型的完整评测地图,涵盖了从基础到高阶、从单任务到多任务的全场景基准测试(Benchmark),并通过雷达图展示了主流模型的综合性能。
1. 全任务分类体系
按任务类型分为 9 大核心板块,覆盖图文理解的全链路:
|
任务板块 |
代表基准测试 |
核心任务 |
|---|---|---|
|
图像描述(Image Captioning) |
COCO Caption、Flickr30K |
生成图片的精准文本描述 |
|
视觉推理(Visual Reasoning) |
GQA、IconQA |
基于视觉的逻辑推理、空间推理 |
|
视觉对话 QA(Visual Conversational QA) |
Visual Dialog |
多轮图文对话中的问题解答 |
|
视频问答(Video Question Answering) |
MSVD QA、iVQA |
理解视频内容并回答问题 |
|
知识落地图文 QA(Knowledge Grounded Image QA) |
OKVQA、ScienceQA |
结合外部知识解答图片问题(如科学常识) |
|
图像问答生成(Image Question Generation) |
VQAv2 |
根据图片生成合理的问答对 |
|
图文问答阅读理解(Image QA Reading Comprehension) |
OCR-VQA、TextVQA |
结合 OCR 识别的文字完成阅读理解式问答 |
|
图像分类(Image Classification) |
HatefulMemes |
针对特定场景的图像分类(如识别恶意梗图) |
|
定制化指令集 |
LLaVA-Instruct-150K |
基于指令微调的多模态能力测试 |
2. 模型综合性能雷达图
右侧雷达图以SEED、MME_per、MME_cog、MMBench-CN等核心指标为维度,对比了ShareGPT4V-7B、LLaVA-1.5-7B、Qwen-VL-Chat-7B、InstructBLIP-7B四款主流 7B 量级模型:
-
优势分布:Qwen-VL-Chat-7B 在多个指标上表现均衡,LLaVA-1.5-7B 在部分推理指标上突出。
-
核心价值:直观展示模型的 “能力短板”,为科研调优和工业选型提供依据。
核心总结
这组图片完整呈现了图文多模态大语言模型的评测进化路径:
-
从基础到高阶:MME 测基础感知与认知,MMMU/MathVista 测专业跨学科能力;
-
从单一到全面:从 Yes/No 问答,扩展到图像描述、视频理解、代码推理、专业知识问答等全任务;
-
从榜单到选型:通过开源模型排名和雷达图,为科研人员(模型调优)、工程师(工业落地)提供了明确的性能参考。

核心基础评测:MME 评测集
MME(MultiModal Evaluation)是图文多模态模型的基础能力标杆,核心聚焦「感知(Perception)」与「认知(Cognition)」两大维度,通过 Yes/No 问答的形式量化模型性能,图片中给出了其任务分类、样例及开源地址。
1. 评测集核心信息
- 开源地址:
github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation,是业内整理 MLLM 评测资源的核心仓库。 - 评测范式:以「图片 + 是非问句」为核心,要求模型精准判断,避免模糊回答,适合量化对比。
2. 两大核心能力维度(任务细分与样例)
| 能力维度 | 子任务类型 | 核心考察点 | 典型样例 |
|---|---|---|---|
| 感知(Perception) | 粗粒度感知(Coarse-Grained) | 基础视觉元素识别(存在性、数量、位置、颜色) | 「图中有大象吗?」「摩托车在公交车的右侧吗?」 |
| 细粒度感知(Fine-Grained) | 专业领域细分类别识别(海报、名人、场景、地标、艺术品) | 「这部电影是弗朗西斯・福特・科波拉执导的吗?」「这是北京的故宫吗?」 | |
| OCR 任务 | 图文转换与文字精准识别 | 「图片中的电话号码是 0131 553 6363 吗?」「Logo 里的文字是 high time cofee shop 吗?」 | |
| 认知(Cognition) | 常识推理 | 结合视觉与生活常识做决策 | 「看到图片中的标志,我应该过马路吗?」 |
| 数值计算 | 视觉中的数学运算与逻辑 | 「图片中的算术题答案是 5 吗?」 | |
| 文本翻译 | 跨模态的语言转换能力 | 「将‘老味道’翻译成英文‘classic taste’是否合适?」 | |
| 代码推理 | 视觉中的代码逻辑判断 | 「Python 代码print('Hello')的输出是 Hello 吗?」 |
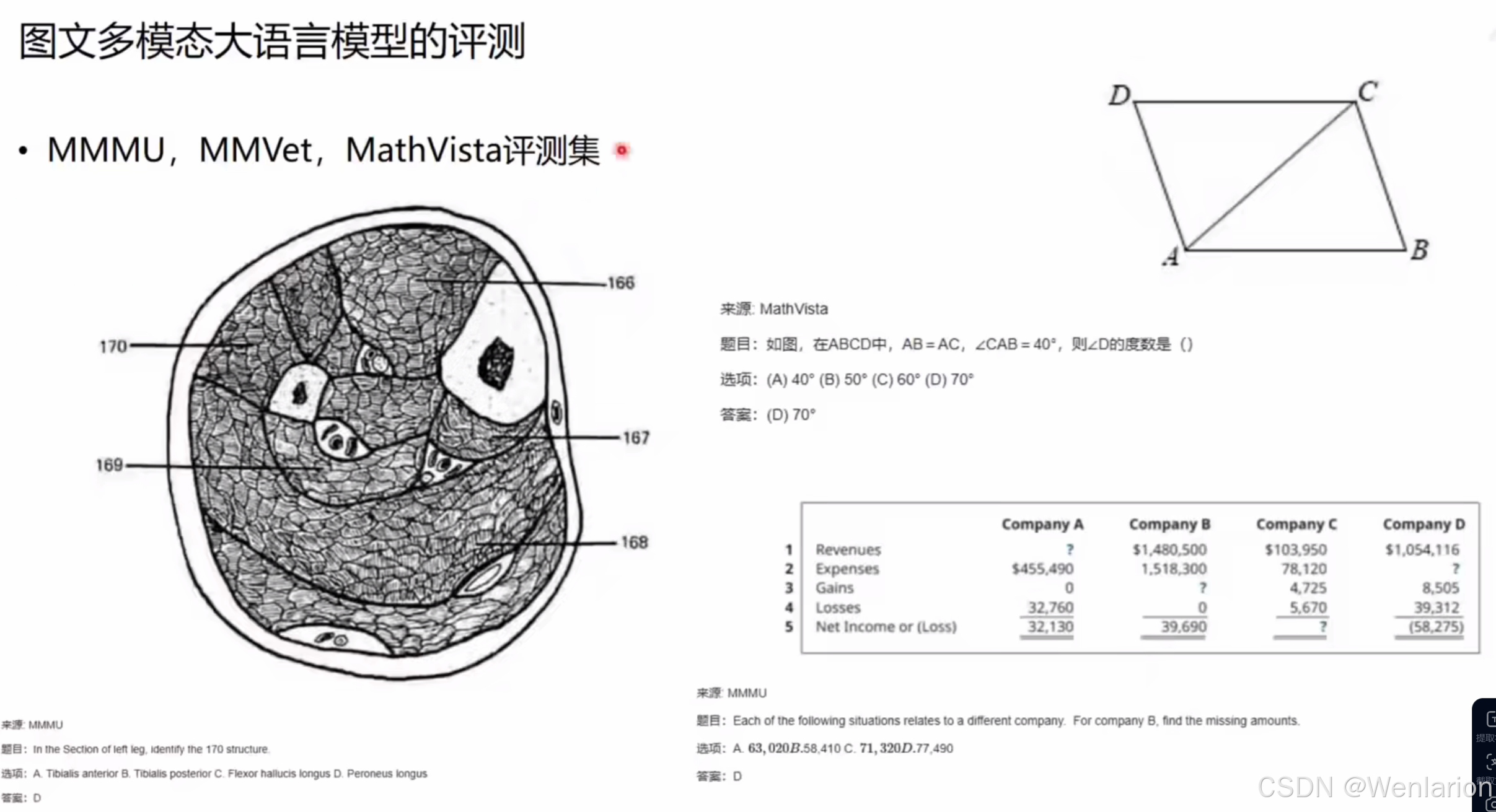
高阶专业评测集:MMMU、MMVet、MathVista
如果说 MME 是 “基础体检”,这三个评测集就是 **“专业难度考核”,聚焦高复杂度、跨学科 ** 的图文理解任务,突破了基础是非题的局限。
| 评测集 | 核心领域 | 典型任务样例 | 考察难点 |
|---|---|---|---|
| MMMU | 医学、金融、法律等专业领域 | 医学:识别左腿 MRI 影像中的 170 号结构(选项为肌肉 / 肌腱名称);金融:根据财务报表计算公司缺失的收入 / 支出数据 | 跨学科专业知识 + 视觉细节理解 + 数值推理 |
| MathVista | 数学视觉推理 | 几何题:已知平行四边形 ABCD 中 AB=AC,∠CAB=40°,求∠D 的度数 | 抽象几何图形理解 + 数学定理应用 |
| MMVet | 通用高阶视觉推理 | (图中未展示具体样例,核心为复杂场景的多步推理、知识融合) | 多模态知识的深度结合与逻辑链推理 |
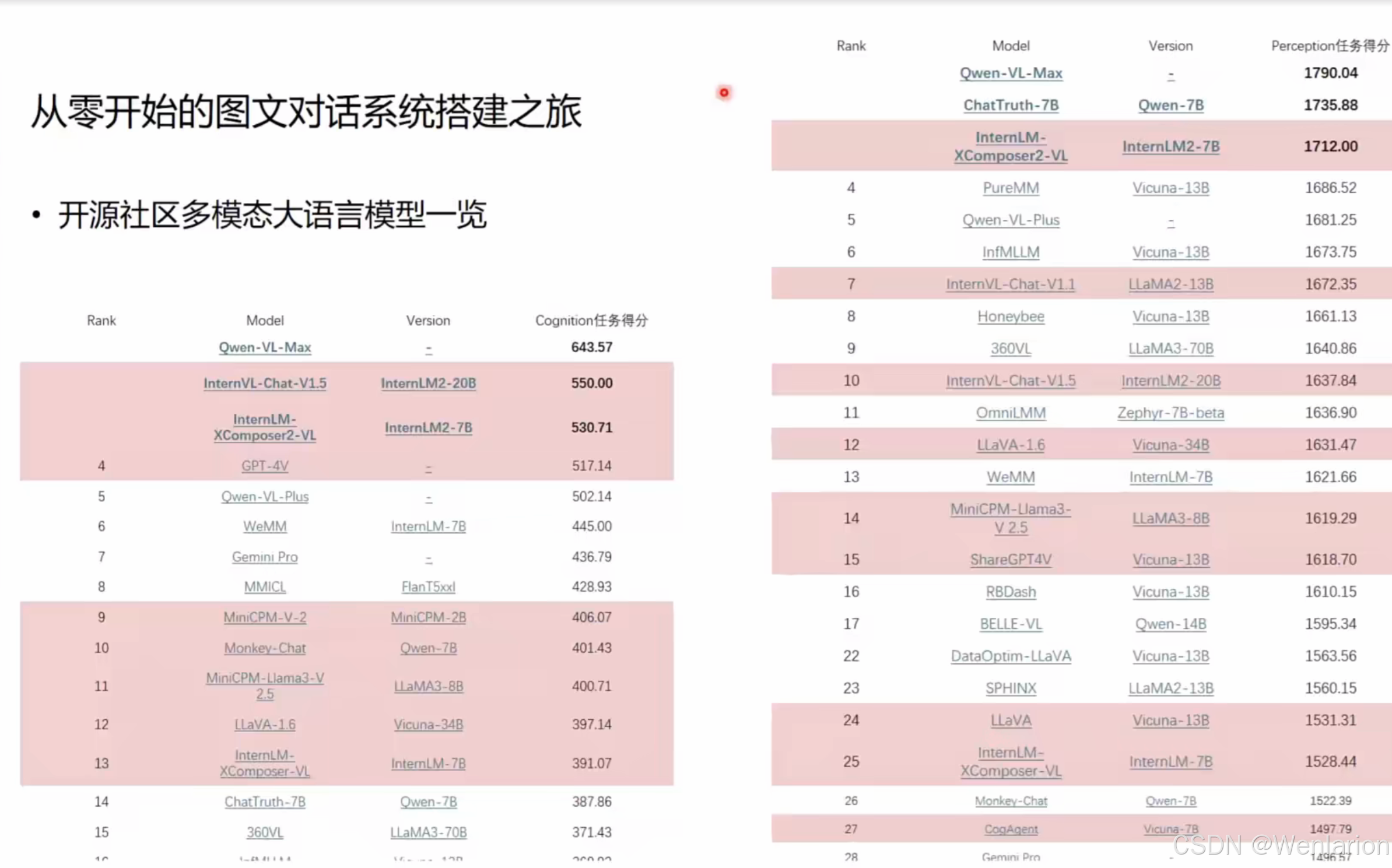
开源模型性能排名:MME 实测榜单
这张图是基于 MME 评测集的开源多模态大语言模型排行榜,从「认知得分」和「感知任务得分」两个核心指标,展示了主流模型的性能梯队,核心结论如下:
1. 双指标排名逻辑
- 认知得分榜:聚焦推理、计算、翻译等高阶能力,Qwen-VL-Max以 643.57 分位居榜首,远超第二名 InternVL-Chat-V1.5(550.00 分),体现了其在复杂认知任务上的绝对优势。
- 感知任务得分榜:侧重视觉识别、OCR 等基础能力,Qwen-VL-Max仍以 1790.04 分领跑,ChatTruth-7B、InternLM-XComposer2-VL 紧随其后。
2. 核心梯队划分
- 第一梯队:Qwen(通义千问)、InternVL(书生)系列模型霸榜,体现了国内开源模型的顶尖实力。
- 第二梯队:PureMM、Vicuna 系列、LLaVA 系列(如 LLaVA-1.6、LLaMA3-70B),是科研与工业界常用的基础模型。
- 特色模型:CogAgent(前文提到的 GUI 智能体)也在榜单中,虽排名靠后(1497.67 分),但侧重 GUI 交互,并非纯图文评测的强项,体现了模型的任务针对性。
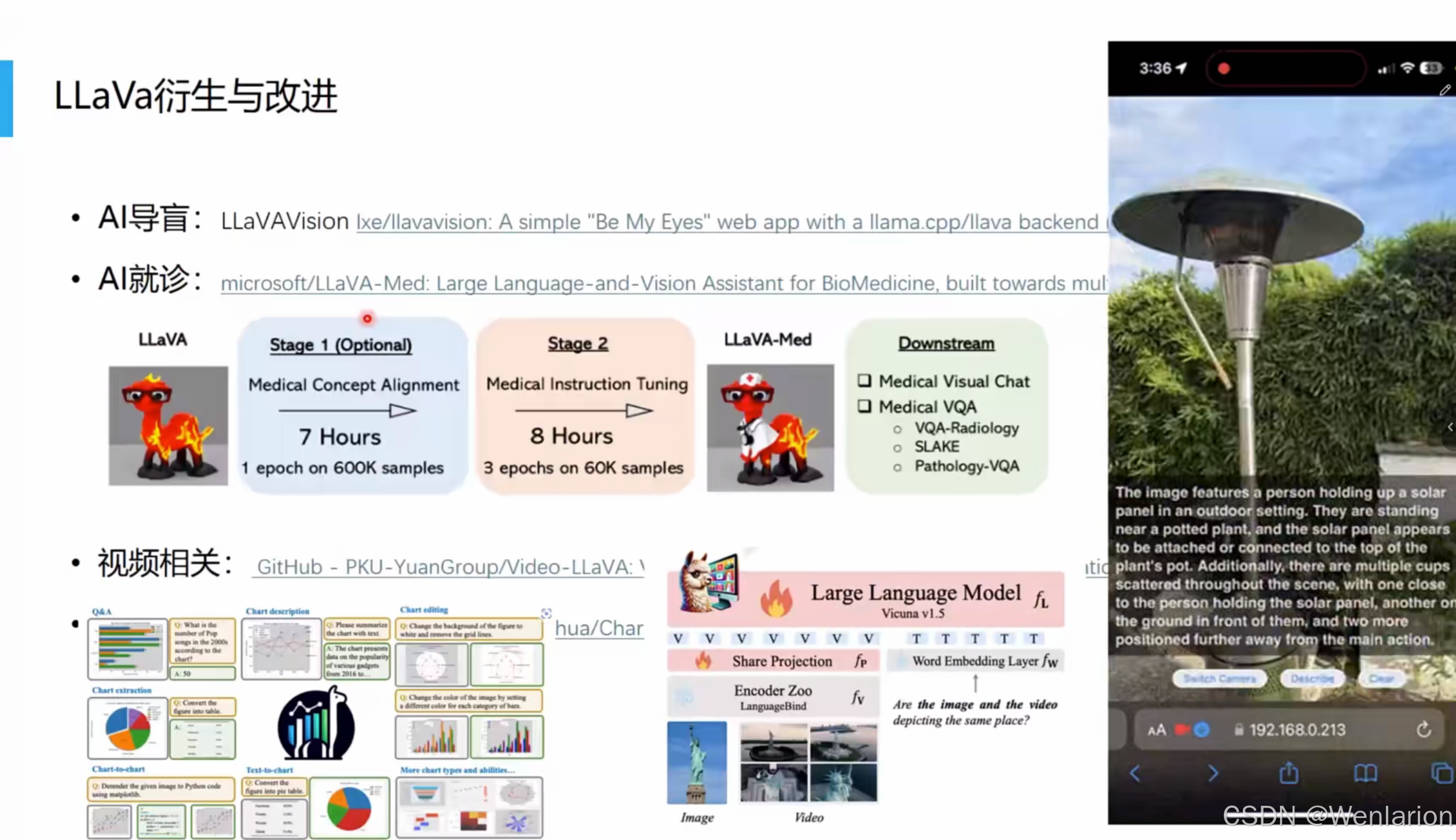
2.2.3 LLaVa衍生与改进
围绕多模态大模型(以 LLaVA 系列为核心)的衍生与改进展开,系统梳理了 ** 视觉编码器(Vision Encoder)与投影机制(Projection Mechanism)** 两大核心方向的技术演进,涵盖具体模型架构、改进策略、应用场景及配套工程实现。以下是分模块详细解析:
LLaVA 衍生与改进总览
LLaVA(Large Language and Vision Assistant)是开源多模态大模型的标杆,其衍生方向主要聚焦医疗辅助(AI 就诊)、视觉导盲(AI 导盲)、视频理解等垂直场景,同时通过迭代模型架构提升通用能力。
-
AI 导盲:提及
LLaVAVision,是基于llama.cpp/llava后端构建的 “Be My Eyes” 类 Web 应用,核心是实现视觉障碍辅助的实时视觉语言交互。 -
AI 就诊(LLaVA-Med):
-
定位:面向生物医药的多模态大模型,专注医疗视觉问答(VQA)、医疗影像对话等场景。
-
训练流程:分两阶段 ——Stage 1(7 小时):医疗概念对齐(1 epoch on 600K 样本);Stage 2(8 小时):医疗指令微调(3 epochs on 60K 样本)。
-
下游任务:Medical Visual Chat、Medical VQA(含 VQA-Radiology、SLAKE、Pathology-VQA 等细分任务)。
-
-
视频相关:提及
PKU-YuanGroup/Video-LLaVA,是北大团队推出的视频 - 语言大模型,支持视频描述、视频 VQA、视频时序推理等。


核心技术改进 1:Vision Encoder(视觉编码器)演进
这是幻灯片重点章节,核心是提升视觉特征提取的精度、分辨率适配性与推理效率,覆盖 LLaVA1.6、Fuyu-8B、MiniCPM 系列等模型:
1. LLaVA1.6(LLaVA-Next)
核心改进目标:突破视觉感知瓶颈,强化细节捕捉与推理能力。
-
高分辨率支持:将输入图像分辨率提升至多档位,支持
672×672、336×1344、1344×336三种宽高比,能捕获更多视觉细节(如小目标、文字纹理)。 -
数据与能力:通过改进的视觉指令微调数据混合,提升视觉推理与 **OCR(光学字符识别)** 能力;适配更多场景(医疗、工业、办公文档等)的视觉对话;增强世界知识与逻辑推理能力,且通过 SGLang 实现高效部署与推理。
-
编码逻辑:采用 “分块(split)+ 整图(resize)” 双路径编码:分块捕捉局部细节、整图捕捉全局上下文,最终展平(flatten)后输入大语言模型(LLM)。
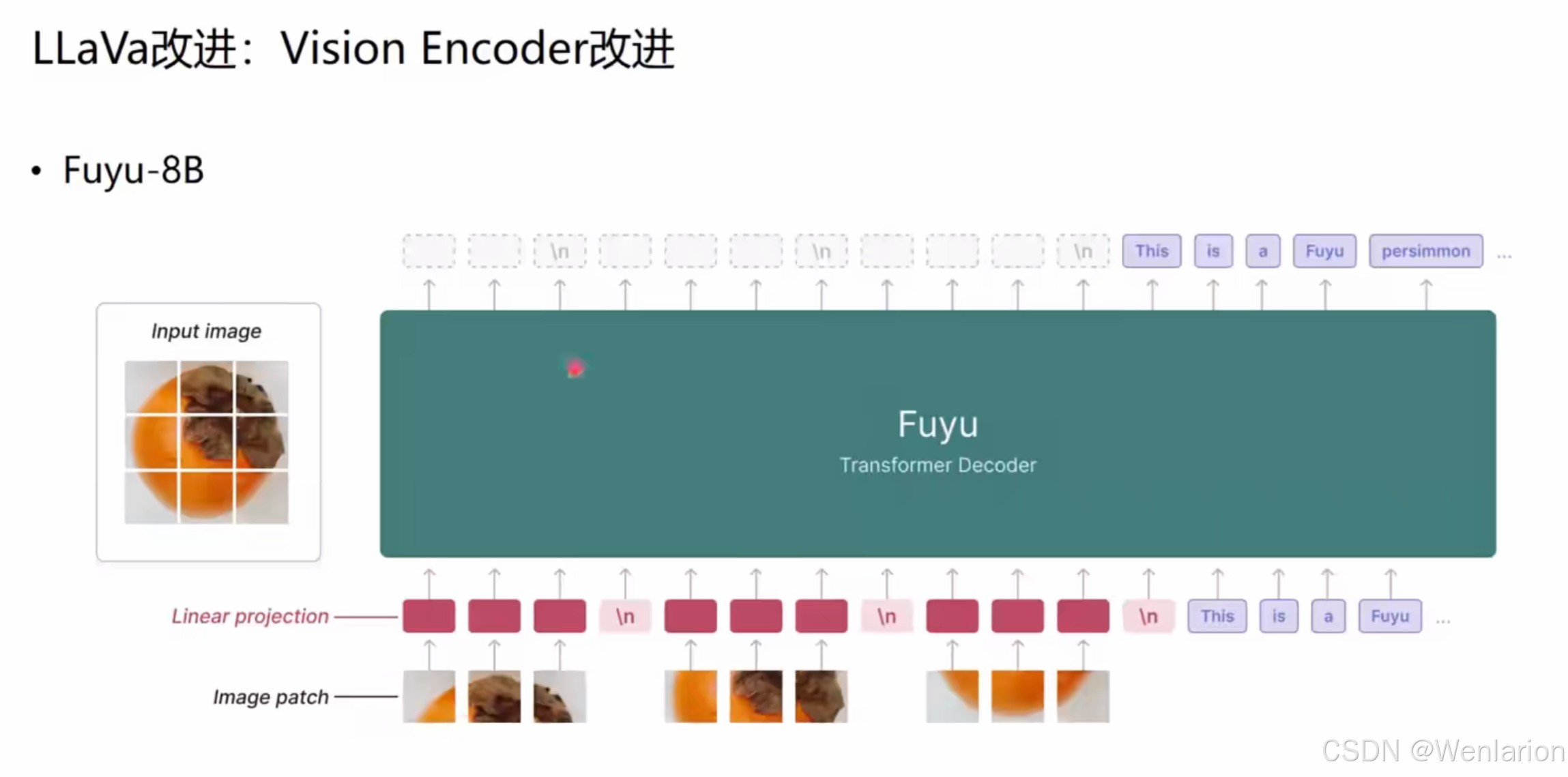
2. Fuyu-8B
架构创新:端到端 Transformer Decode 架构,简化视觉 - 语言融合流程。
-
编码流程:输入图像先切分为图像块(Image patch),经线性投影(Linear projection)映射为向量,直接接入 Transformer Decode,与文本 Token(
This is a Fuyu persimmon...)统一建模。 -
特点:8B 参数规模,轻量化且支持高分辨率图像理解,适合边缘 / 终端部署。
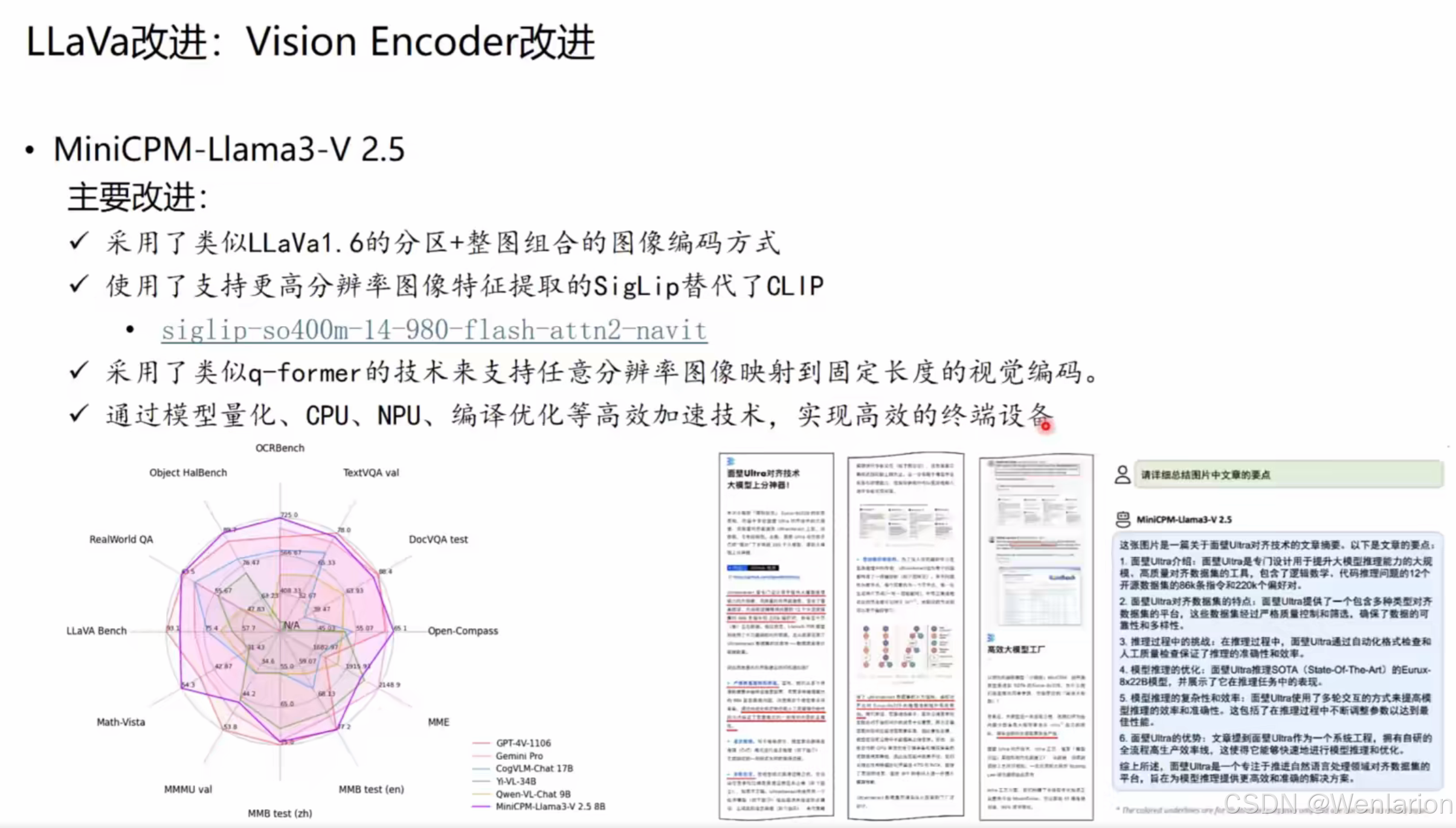
3. MiniCPM-Llama3-V 2.5
技术亮点:兼顾高性能与工程效率,适配终端设备。
-
视觉编码:借鉴 LLaVA1.6 的 “分块 + 整图” 组合编码方式;用SigLip(
siglip-so400m-14-980-flash-attn2-navit)替代传统 CLIP 作为视觉编码器,提升高分辨率特征提取能力;引入 q-former 技术,支持任意分辨率图像映射到固定长度视觉编码。 -
工程优化:通过模型量化、CPU/NPU 推理、编译优化等加速技术,实现高效终端部署。
-
性能验证:在 OCRBench、DocVQA、LLaVA Bench、Math-Vista 等多模态基准测试中表现优异(雷达图展示 SOTA 级性能)。
4. MiniCPM-V 2.6(Qwen2-7B)
轻量化与部署优化:面向端侧与高效微调的多模态模型。
-
核心配置:以Qwen2-7B作为大语言模型(LLM),搭配 SigLip-400M 视觉编码器,总参数规模 8B,实现 “20B 以下模型” 的单图 / 多图 / 视频理解 SOTA 性能。
-
部署与微调:
-
支持端侧部署(可在 iPad 运行实时视频理解);
-
微调方案:支持 SWIFT 框架(ModelScope 开源),涵盖 LoRA 微调、全参数微调,且支持多图 / 视频微调训练;
-
显存效率(以 A800 80GB、DeepSpeed ZERO-3、bs=1 为例):LoRA 微调仅需 13.1-14.4GiB 显存,全参数微调 15.63-16.0GiB 显存,适配中小规模算力环境。
-
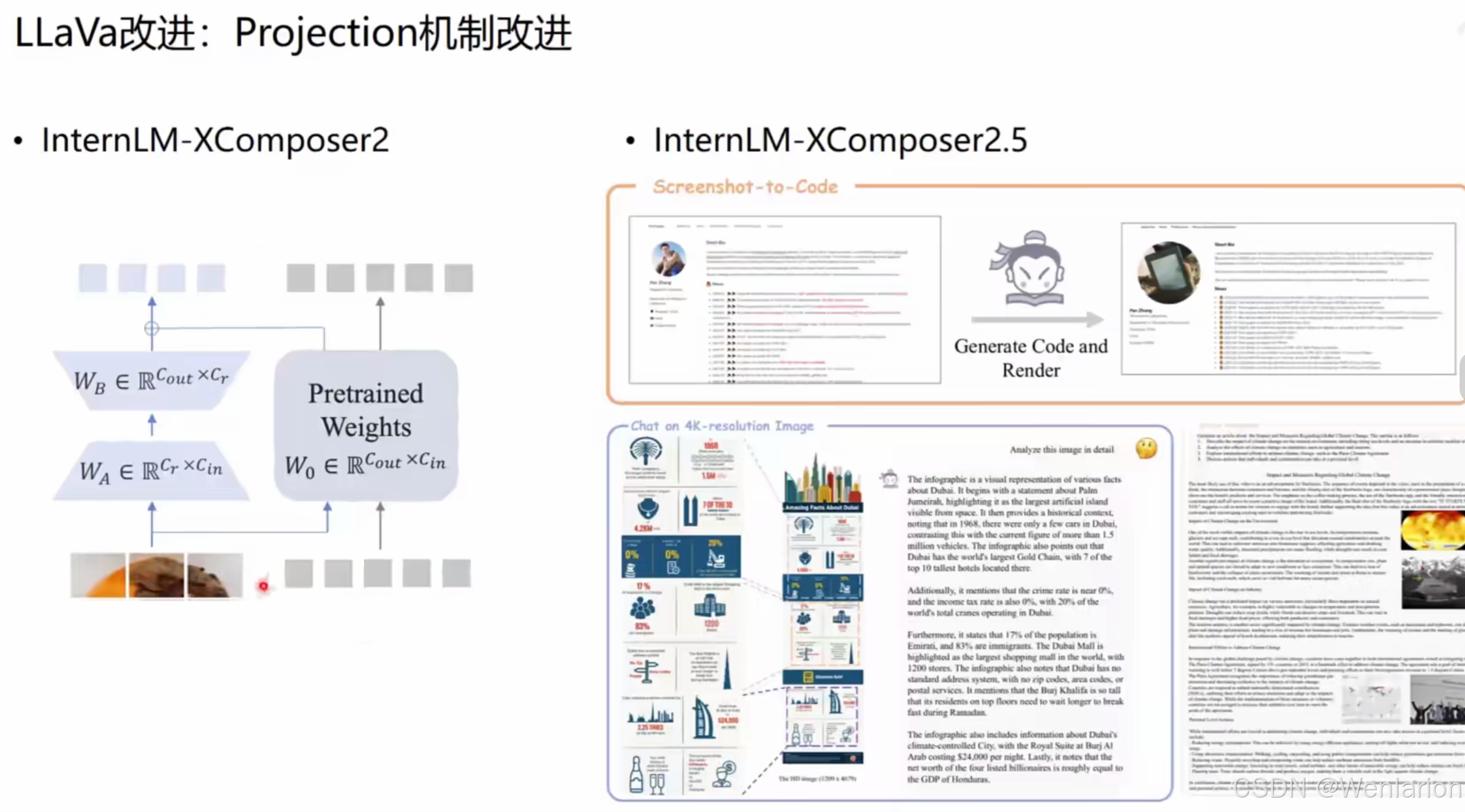
核心技术改进 2:Projection Mechanism(投影机制)优化
投影层是连接视觉特征与语言模型的 “桥梁”,核心解决视觉 - 语言特征对齐精度、维度匹配、训练效率问题,以InternLM-XComposer系列为代表:
1. InternLM-XComposer2
投影设计:双投影矩阵优化特征对齐
-
引入可学习投影矩阵WB∈RCout×Cr、WA∈RCr×Cin,结合预训练权重W0∈RCout×Cin,对视觉特征进行维度变换与特征蒸馏,实现视觉特征到语言模型嵌入空间的精准对齐。
-
优势:提升跨模态特征融合的稳定性,减少训练过程中的模态错位问题。
2. InternLM-XComposer2.5
场景突破:聚焦截图转代码(Screenshot-to-Code)、4K 分辨率图像理解等复杂场景。
-
核心能力:
-
截图转代码:输入 UI 截图,自动生成可渲染的代码(Generate Code and Render),适配前端开发、低代码自动化场景;
-
4K 图像理解:支持 4K 超高清图像的细节分析(如复杂信息图表、长文档截图),通过优化的投影与编码机制,实现高分辨率图像的精准解读与问答。
-
LLaVa 相关论文与代码 / 工程资源
提及的开源项目、技术论文与工程工具对应如下:
|
模型 / 技术 |
代码 / 论文 / 工具链接 / 标识 |
核心价值 |
|---|---|---|
|
LLaVAVision |
无直接链接(基于 llama.cpp/llava) |
开源视觉导盲类 LLaVA 衍生应用 |
|
LLaVA-Med |
microsoft/LLaVA-Med(GitHub) |
医疗多模态大模型,开源代码与权重 |
|
Video-LLaVA |
PKU-YuanGroup/Video-LLaVA(GitHub) |
北大开源视频 - 语言大模型 |
|
LLaVA1.6/LLaVA-Next |
haotian-liu/LLaVA(GitHub,对应 1.6 分支) |
LLaVA 官方开源仓库,含训练 / 推理代码 |
|
MiniCPM 系列 |
OpenBMB/MiniCPM(GitHub)、ModelScope |
智谱 / 百川智能开源,含 MiniCPM-V 2.5/2.6 |
|
SWIFT 框架 |
modelscope/swift(GitHub) |
阿里开源大模型微调框架,支持 MiniCPM-V 微调 |
|
SigLIP |
google-research/big_vision(GitHub) |
Google 开源 SigLip 视觉模型,替代 CLIP |
|
SGLang |
SGLang-Project/sglang(GitHub) |
高效大语言模型推理框架,LLaVA1.6 用其加速 |
|
InternLM-XComposer |
InternLM/XComposer2(GitHub,上海 AI 实验室) |
商汤 / 港中文开源多模态模型 |
LLaVA 核心衍生应用(垂直场景)
1. LLaVAVision(AI 导盲)
-
核心依托:基于 llama.cpp/llava 后端开发,无独立官方仓库
-
基础代码:llama.cpp(视觉推理后端)+ LLaVA 官方仓库(多模态能力)
-
llama.cpp:https://github.com/ggerganov/llama.cpp
-
LLaVA 基础:https://github.com/haotian-liu/LLaVA
-
2. LLaVA-Med(AI 就诊 / 医疗多模态)
-
核心论文:LLaVA-Med: A Large Language and Vision Assistant for Biomedicine(无公开 arxiv 链接,仓库含技术报告)
-
关键特性:仓库含医疗概念对齐、指令微调全流程代码,及医疗 VQA 数据集适配脚本
3. Video-LLaVA(视频 - 语言理解,北大团队)
-
核心论文:Video-LLaVA: Learning United Visual Representation by Alignment for Video-Language Understanding(arxiv:https://arxiv.org/abs/2404.10157)
-
关键特性:支持视频描述、时序推理、视频 VQA,基于 LLaVA 拓展视频帧编码能力
视觉编码器(Vision Encoder)演进核心模型
1. LLaVA1.6/LLaVA-Next(LLaVA 核心迭代版)
-
官方代码仓库:https://github.com/haotian-liu/LLaVA(1.6 分支,主仓默认最新版)
-
核心论文:LLaVA-Next: Improved Multimodal Understanding with High-Resolution Vision and Enhanced World Knowledge(arxiv:https://arxiv.org/abs/2407.01449)
-
补充:仓库含高分辨率双路径编码(分块 + 整图)实现、SGLang 推理加速适配代码
2. Fuyu-8B(端到端 Transformer Decode 架构)
-
核心论文:Fuyu-8B: A Small Single-Token Vision-Language Model(arxiv:https://arxiv.org/abs/2310.06825)
-
关键特性:轻量级 8B 模型,端到端视觉 - 文本统一建模,仓库含高分辨率图像块编码实现
3. MiniCPM 系列(MiniCPM-Llama3-V 2.5 / MiniCPM-V 2.6)
-
ModelScope 开源地址:https://www.modelscope.cn/models/OpenBMB/MiniCPM-V-2.6/summary(含预训练权重、端侧部署教程)
-
核心论文:MiniCPM-V: A Compact and Efficient Vision-Language Model for Edge Devices(arxiv:https://arxiv.org/abs/2404.16821)
-
关键补充:仓库含 SigLip 视觉编码器集成、q-former 任意分辨率适配、端侧(iPad/CPU/NPU)推理优化代码
4. SigLip(替代 CLIP 的视觉编码器,Google)
-
官方代码仓库:https://github.com/google-research/big_vision(SigLip 核心实现)
-
核心论文:SigLIP: Signature Verification Loss for Image-Text Matching(arxiv:https://arxiv.org/abs/2303.15343)
-
工程化版本:siglip-so400m-14-980-flash-attn2-navit(MiniCPM 使用版本,ModelScope 可直接调用)
投影机制(Projection Mechanism)优化核心模型
InternLM-XComposer 系列(XComposer2 / XComposer2.5)
-
核心论文:
-
InternLM-XComposer2: Boosting Vision-Language Alignment with Dual Projection Matrices(arxiv:https://arxiv.org/abs/2404.08404)
-
InternLM-XComposer2.5: High-Resolution Vision-Language Model for Screenshot-to-Code and 4K Image Understanding(技术报告,仓库内附)
-
-
关键特性:仓库含双投影矩阵(WB/WA)实现、4K 图像编码、截图转代码(S2C)专用微调代码
配套工程工具 / 框架(训练 / 微调 / 推理)
1. SWIFT 框架(MiniCPM-V 微调专用,阿里)
-
核心特性:支持 LoRA 微调、全参数微调,专为 MiniCPM-V 优化,含多图 / 视频微调训练脚本,显存效率优化
2. SGLang(LLaVA1.6 推理加速,高效大模型推理框架)
-
核心论文:SGLang: Efficient Serving for Large Language Models with Structured Generation(arxiv:https://arxiv.org/abs/2405.1GLang142)
-
关键特性:LLaVA1.6 官方推荐推理框架,支持高并发视觉对话,大幅提升推理速度
3. Qwen2-7B(MiniCPM-V 2.6 基础 LLM,阿里)
-
核心论文:Qwen2: A Family of High-Performance Large Language Models(arxiv:https://arxiv.org/abs/2407.07723)
-
关键特性:MiniCPM-V 2.6 的语言模型底座,开源 7B/14B/72B 全系列,适配多模态特征对齐
4. DeepSpeed(显存优化训练,MiniCPM-V/LLaVA 均适配)
-
核心文档:https://www.deepspeed.ai/docs/configure/zero/(ZERO-3 显存优化配置,适配 LLaVA/MiniCPM 微调)
关键基准测试数据集 / 评测工具
为验证模型性能,上述模型均采用以下主流多模态评测基准,附官方地址:
-
LLaVA Bench:https://github.com/haotian-liu/LLaVA/tree/main/llava/eval(LLaVA 官方评测基准)
-
OCRBench:https://github.com/yscacaca/OCRBench(OCR 能力评测)
-
DocVQA:https://rrc.cvc.uab.es/?ch=17(文档视觉问答基准)
-
Math-Vista:https://github.com/luka-group/MathVista(数学视觉推理基准)
-
VQA-Radiology:https://github.com/ayushjain91/VQA-Radiology(医疗影像 VQA 基准)
InternVL系列模型

InternVL 1.5:核心技术与能力
1. 核心架构
- 视觉编码器:基于 InternViT-6B-448 进行视觉特征编码
- 语言模型:搭配 InternLM2-20B 大语言模型
- 关键技术:
- 动态高分辨率:根据输入图像长宽比和分辨率,动态划分为不同大小图块,最高支持 4K 分辨率 输入
- pixel-shuffle 压缩:将图像编码压缩至 1/4,显著降低显存占用
- 多模态能力:支持多图推理、视频打标、OCR、文档理解、数学推理等
2. 训练数据集
覆盖多场景高质量双语数据:
- 图像描述(Captioning)、通用问答(General QA)
- 科学计算、图表分析、数学推理
- OCR、文档理解、目标定位(Grounding)
- 多轮对话(Conversation),支持中英双语
3.论文和代码
- 论文:
- arXiv: https://arxiv.org/abs/2404.16821
- 标题:How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
- 代码仓库:https://github.com/OpenGVLab/InternVL
- 模型权重:https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5
- 在线 Demo:https://internvl.opengvlab.com
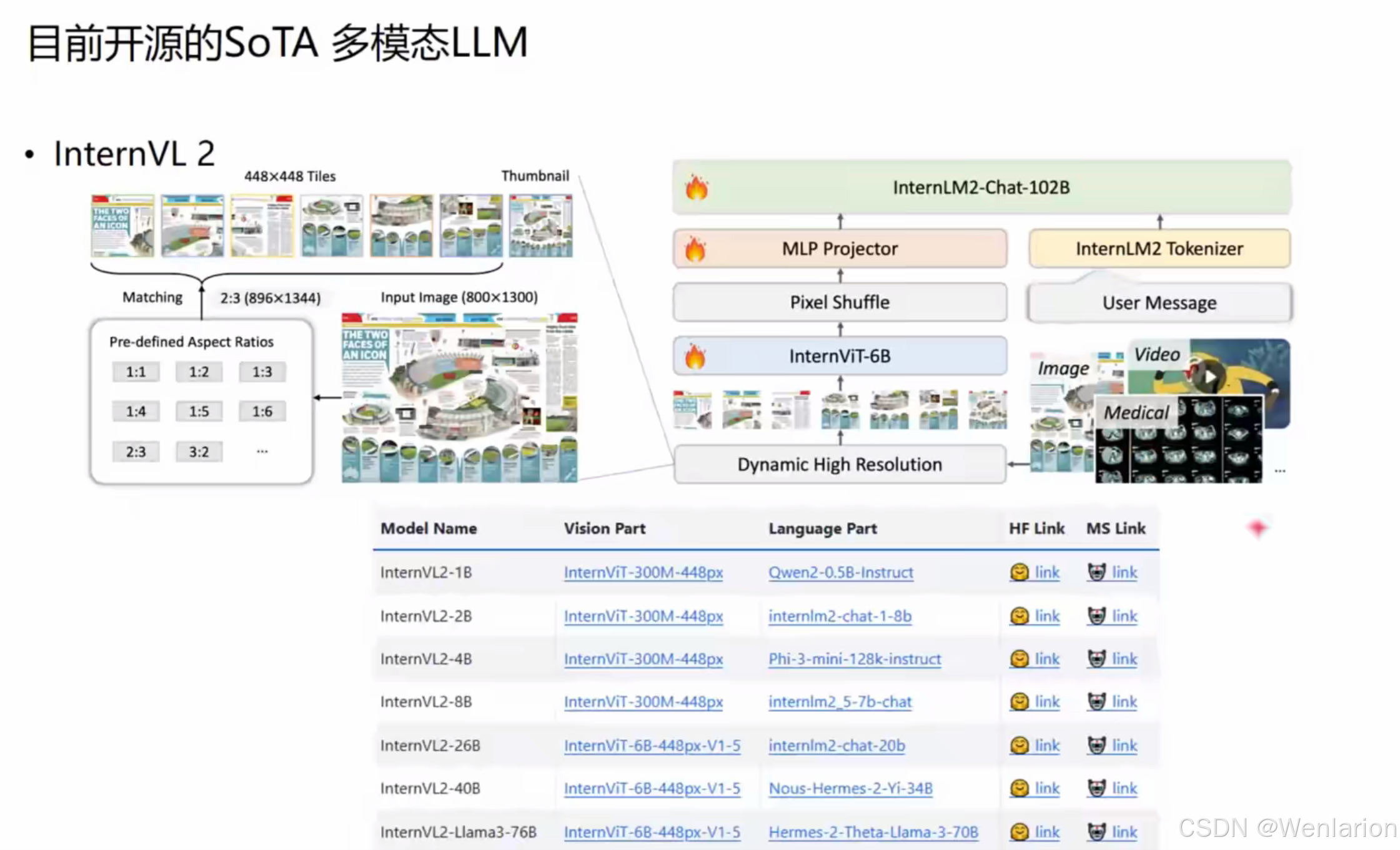

InternVL 2:模型扩展与数据增强
1. 模型家族扩展
提供从 1B 到 76B 不同参数量的模型版本,适配不同算力场景:
| 模型名称 | 视觉部分 | 语言部分 |
|---|---|---|
| InternVL2-1B | InternViT-300M-448px | Qwen2-0.5B-Instruct |
| InternVL2-8B | InternViT-300M-448px | internlm2_5-7b-chat |
| InternVL2-26B | InternViT-6B-448px-V1.5 | internlm2-chat-20b |
| InternVL2-40B | InternViT-6B-448px-V1.5 | Nous-Hermes-2-Yi-34B |
2. 数据构造增强
在 Llava 数据集基础上,新增三类能力支持:
- 目标定位 / 检测:支持
<ref>类别名</ref><box>[x1,y1,x2,y2]</box>格式的 bounding box 输入输出 - 视频数据输入:直接支持视频文件路径,进行视频内容理解与描述
- 多图像输入:支持同时输入多张图片,进行跨图对比推理
3. 微调教程
提供详细微调指南:Fine-tune on a Custom Dataset — internvl,方便开发者在自定义数据集上适配业务场景
4. 论文和代码
- 论文:
- arXiv: https://arxiv.org/abs/2412.05271
- 标题:Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
- 代码仓库:同 InternVL 1.5,https://github.com/OpenGVLab/InternVL
- 模型权重:https://huggingface.co/OpenGVLab/InternVL2-8B 等系列模型
- 官方博客:https://internvl.github.io/blog/2024-07-02-InternVL-2.0

高性能 MLLM 模型部署
1. 部署必要条件
-
支持 批量推理 与 高并发 场景
-
支持 量化版本模型(如 4bit/8bit)推理
-
具备 KV cache 等关键加速手段
2. 推荐部署框架
| 框架 | 核心优势 | 适用场景 |
|---|---|---|
| SGlang | 基于 vLLM 封装,提供 OpenAI 兼容 API | Llava 等多模态模型部署 |
| LMDeploy | 部署简单快捷,支持 PyTorch 接口 | 国内多模态模型快速上线 |
| vLLM | 支持框架种类多,V6 版本支持多图推理 | 通用高性能多模态推理服务 |
2.2.4 Beyond VL: 支持更多模态输入的大语言模型
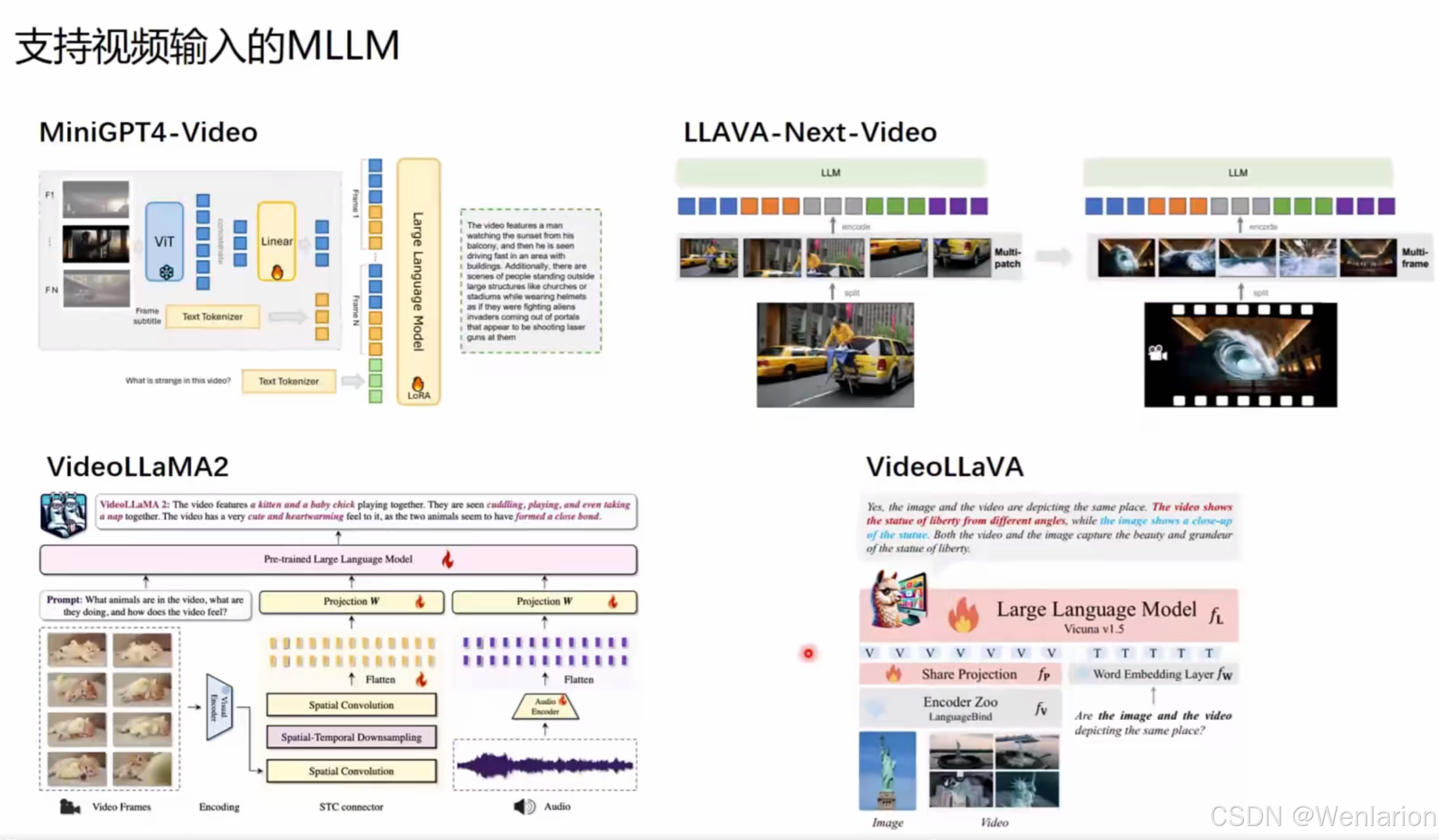
Beyond VL:支持视频输入的 MLLM
这部分模型聚焦于视频 - 文本多模态交互,核心是将时序视觉信息对齐到 LLM 的语义空间。
1. MiniGPT4-Video
- 核心思路:沿用 MiniGPT4 的架构,将视频帧通过 ViT 提取特征,经线性层投影后,与文本指令一起输入 LLM(如 Vicuna),并通过 LoRA 微调实现视频理解。
- 典型能力:视频内容描述、异常检测(如 “What is strange in this video?”)。
- 论文 / 代码:
2. LLAVA-Next-Video
- 核心思路:在 LLaVA-Next 基础上扩展视频输入,通过多帧采样和多块编码(Multi-patch / Multi-frame)将视频时序信息压缩为视觉特征,再输入 LLM。
- 典型能力:视频问答、时序事件理解。
- 论文 / 代码:
3. VideoLLaMA2
- 核心思路:支持视频 + 音频双模态输入,通过 STC(Spatial-Temporal Convolution)连接器处理视频时序特征,同时用音频编码器提取声纹特征,共同投影到 LLM 空间。
- 典型能力:音视频内容理解、情感分析(如描述动物互动的温馨感)。
- 论文 / 代码:
4. VideoLLaVA
- 核心思路:基于 LLaVA 架构,用统一的视觉编码器(LanguageBind)处理图像和视频,通过共享投影层将视觉特征对齐到 Vicuna-1.5 LLM。
- 典型能力:图像 - 视频跨模态对比、内容一致性判断(如 “Are the image and the video depicting the same place?”)。
- 论文 / 代码:
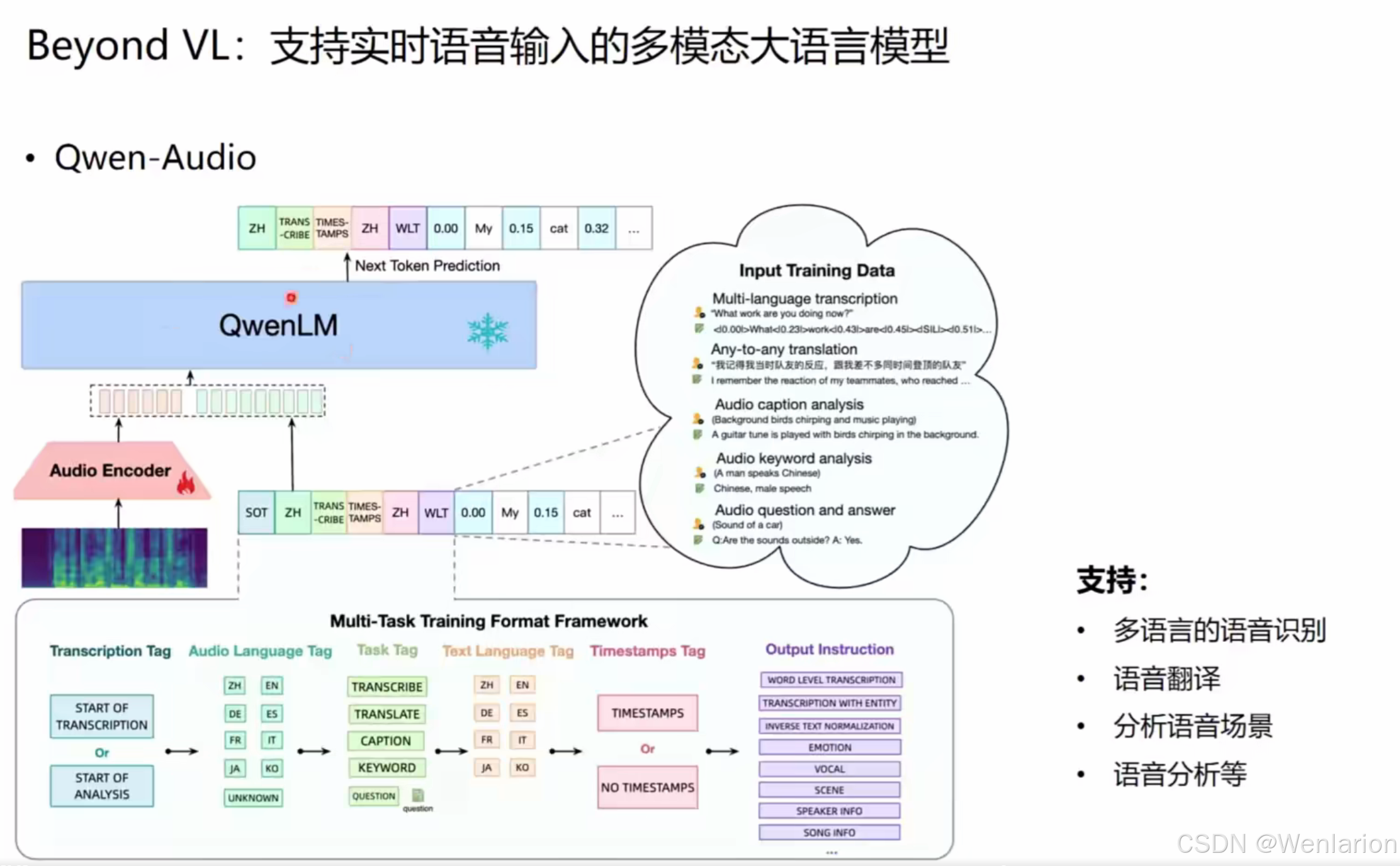

Beyond VL:支持实时语音输入的 MLLM
这部分模型将语音作为核心模态,实现语音识别、翻译、分析与问答。
1. Qwen-Audio
- 核心思路:基于通义千问 QwenLM,接入音频编码器,通过多任务训练框架支持语音转写、翻译、场景分析、关键词提取等。
- 典型能力:多语言语音识别、语音翻译、音频场景分析(如识别背景鸟鸣、吉他声)。
- 论文 / 代码:
2. LLaMA-Omni
- 核心思路:实现实时语音交互,通过 Speech Adaptor 将语音特征对齐到 LLaMA,同时支持同步生成文本与语音输出(Vocoder),降低延迟。
- 典型能力:实时语音问答、语音指令执行(如 “给我写 NLP 论文的建议”)。
- 论文 / 代码:
- 关键要素:多模态 LLM 三要素 ——Encoder(特征编码)、Adaptor(特征映射)、Decoder(特征解码)。

Beyond VL:支持多模态输入的 MLLM
这部分模型统一处理图像 / 视频 / 语音 / 文本等多模态输入,核心是将不同模态 “翻译” 为 LLM 可理解的序列。
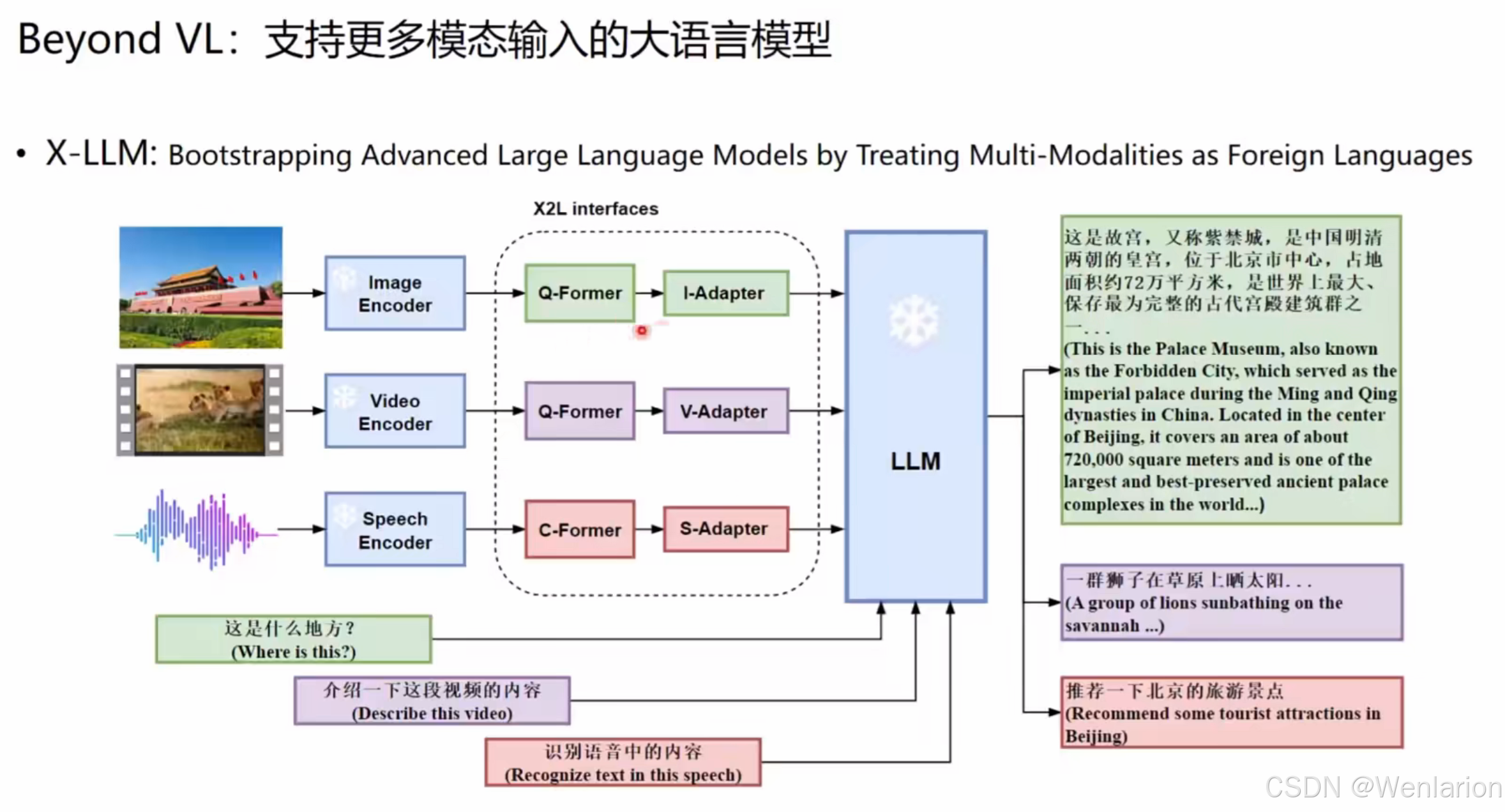
1. X-LLM
- 核心思路:将多模态视为 “外语”,通过 X2L 接口(Q-Former/C-Former + Adapter)将图像 / 视频 / 语音特征分别对齐到 LLM,实现统一多模态理解。
- 典型能力:跨模态问答(如 “这是什么地方?”“描述这段视频”)。
- 论文 / 代码:
2. BLIP-2 & Q-Former
- 核心思路:Q-Former 作为视觉 - 语言桥梁,在冻结图像编码器和 LLM 的前提下,通过查询向量(Queries)学习视觉特征与文本的对齐,是后续多模态模型的基础组件。
- 典型能力:图像 - 文本生成(如为日落图写浪漫文案)。
- 论文 / 代码:
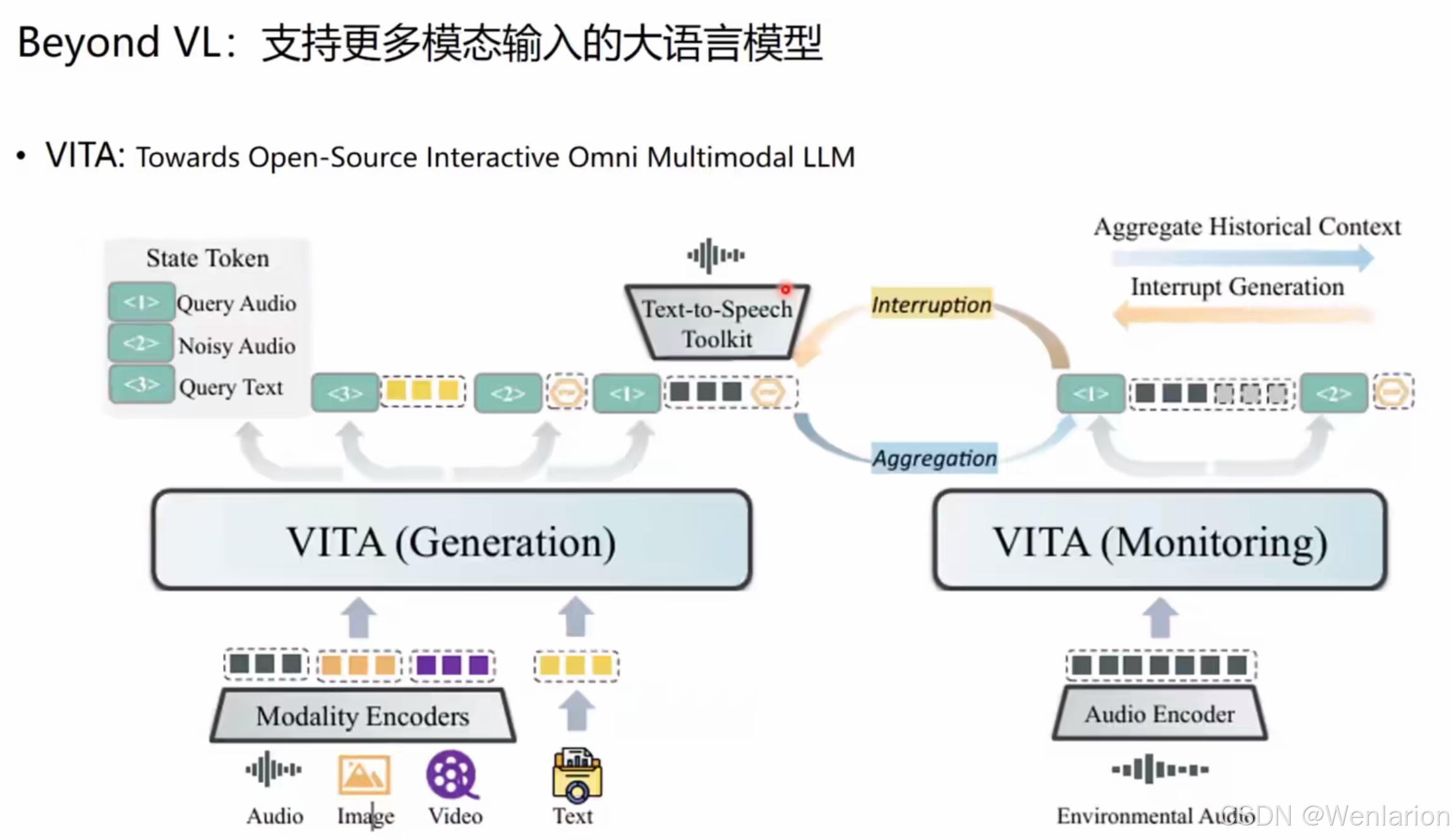
3. VITA
- 核心思路:开源交互式全模态 MLLM,支持音频 / 图像 / 视频 / 文本输入,通过 Generation 和 Monitoring 双模块实现实时交互与中断生成(如用户语音打断模型输出)。
- 典型能力:多模态对话、上下文聚合、实时交互。
- 论文 / 代码:
Beyond VL:支持多模态输入 + 输出的 MLLM
这部分模型实现任意模态输入→任意模态输出(Any-to-Any),是下一代多模态 AI 的方向。
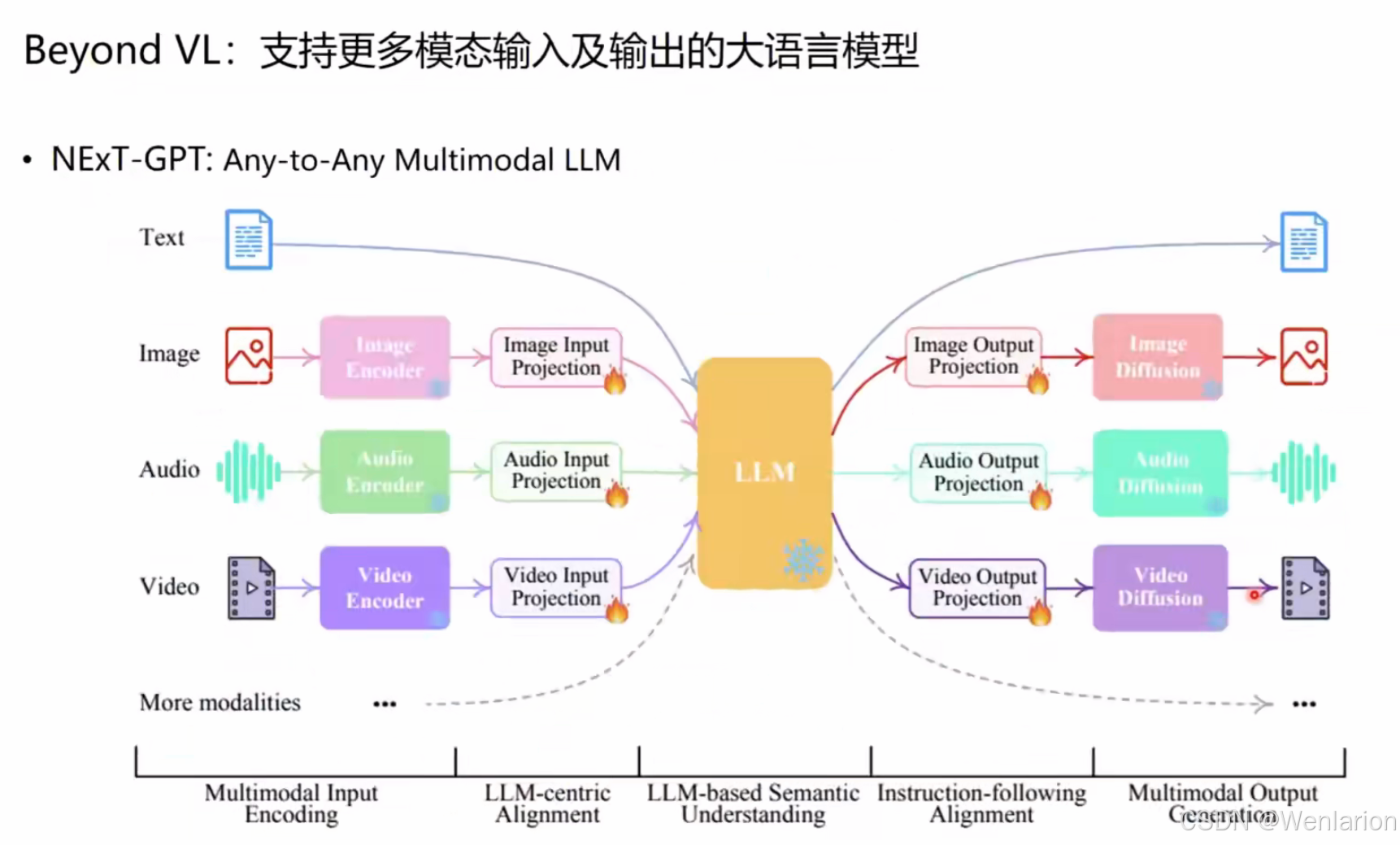
1. NExT-GPT
- 核心思路:Any-to-Any 架构,输入端对文本 / 图像 / 音频 / 视频编码并投影到 LLM;输出端通过 Diffusion 模型生成图像 / 音频 / 视频,实现多模态生成。
- 典型能力:图文生视频、语音生图像等跨模态生成。
- 论文 / 代码:
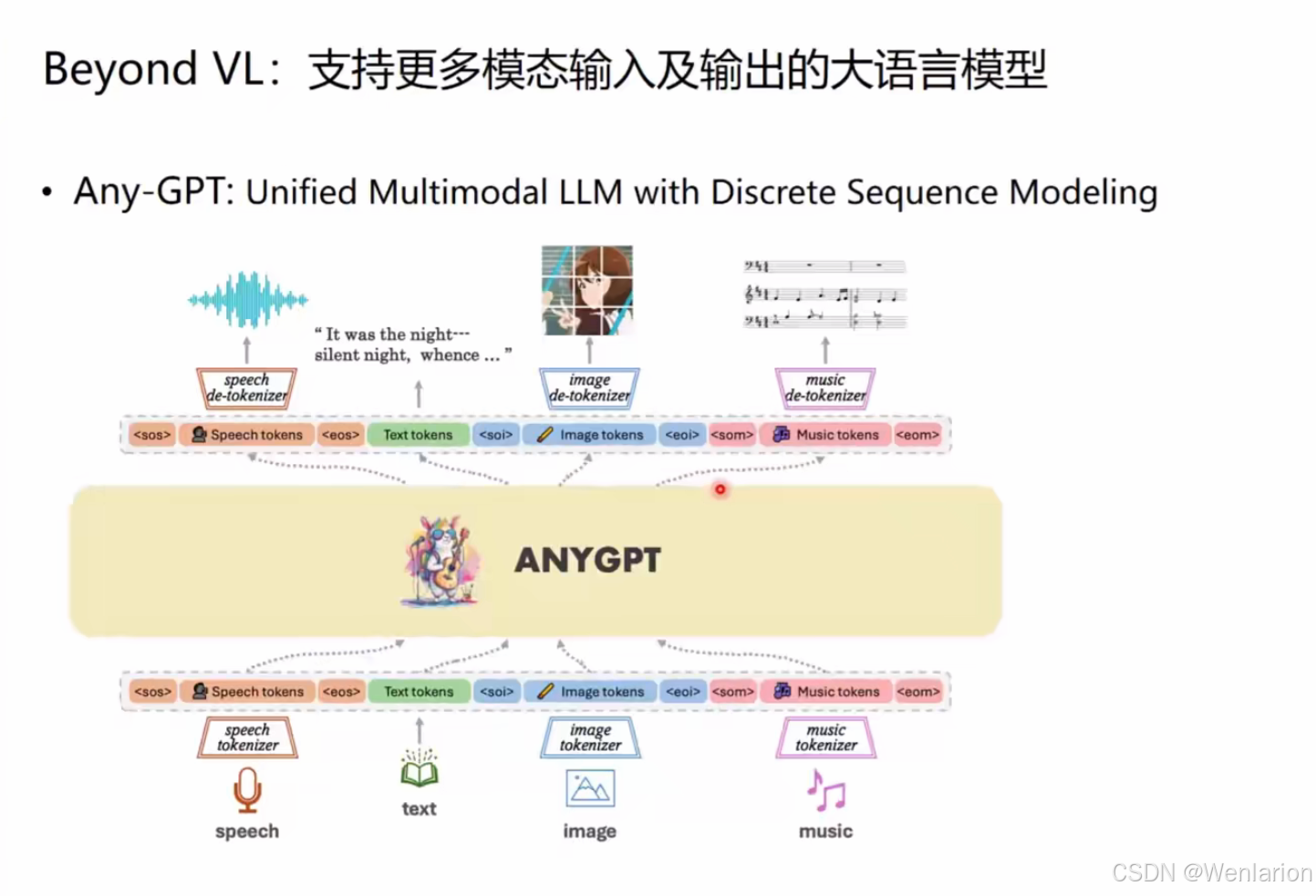
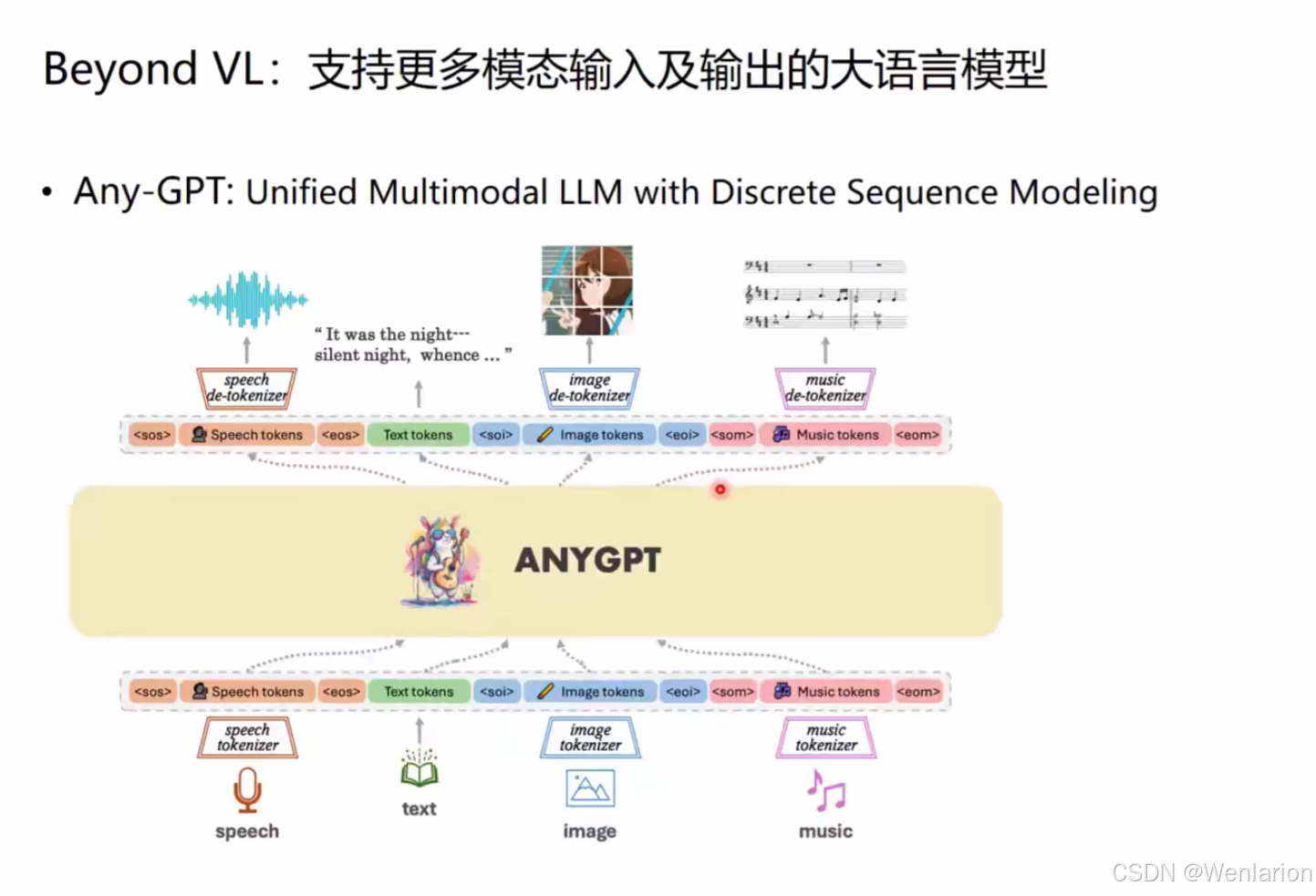
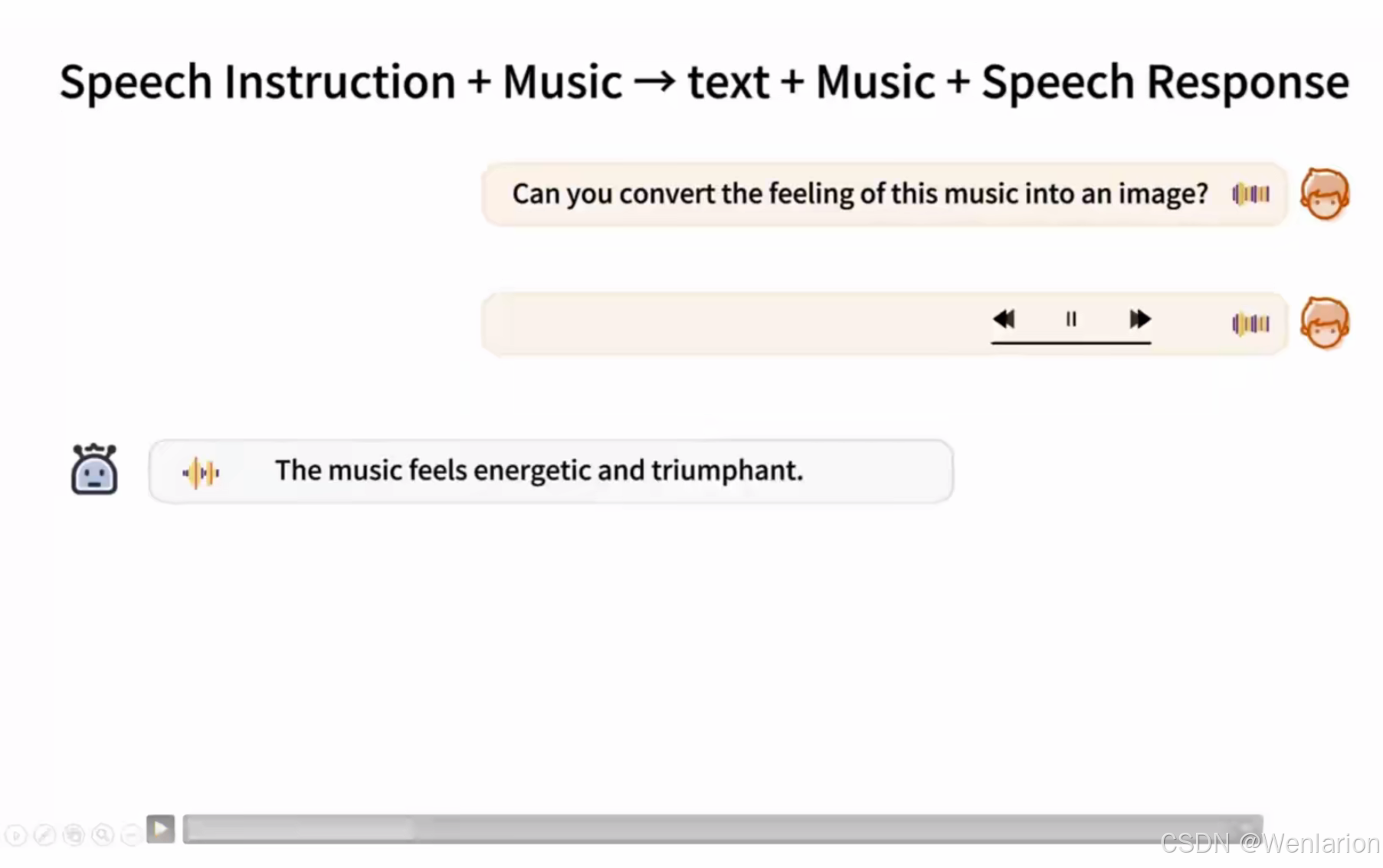
2. Any-GPT
- 核心思路:通过离散序列建模,将语音 / 图像 / 音乐等模态 Token 化,与文本 Token 统一输入 LLM;输出时通过 De-tokenizer 还原为对应模态。
- 典型能力:语音 + 音乐生成文本 / 音乐 / 语音响应、图文生音乐。
- 论文 / 代码:
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
2.2.5 多模态智能体
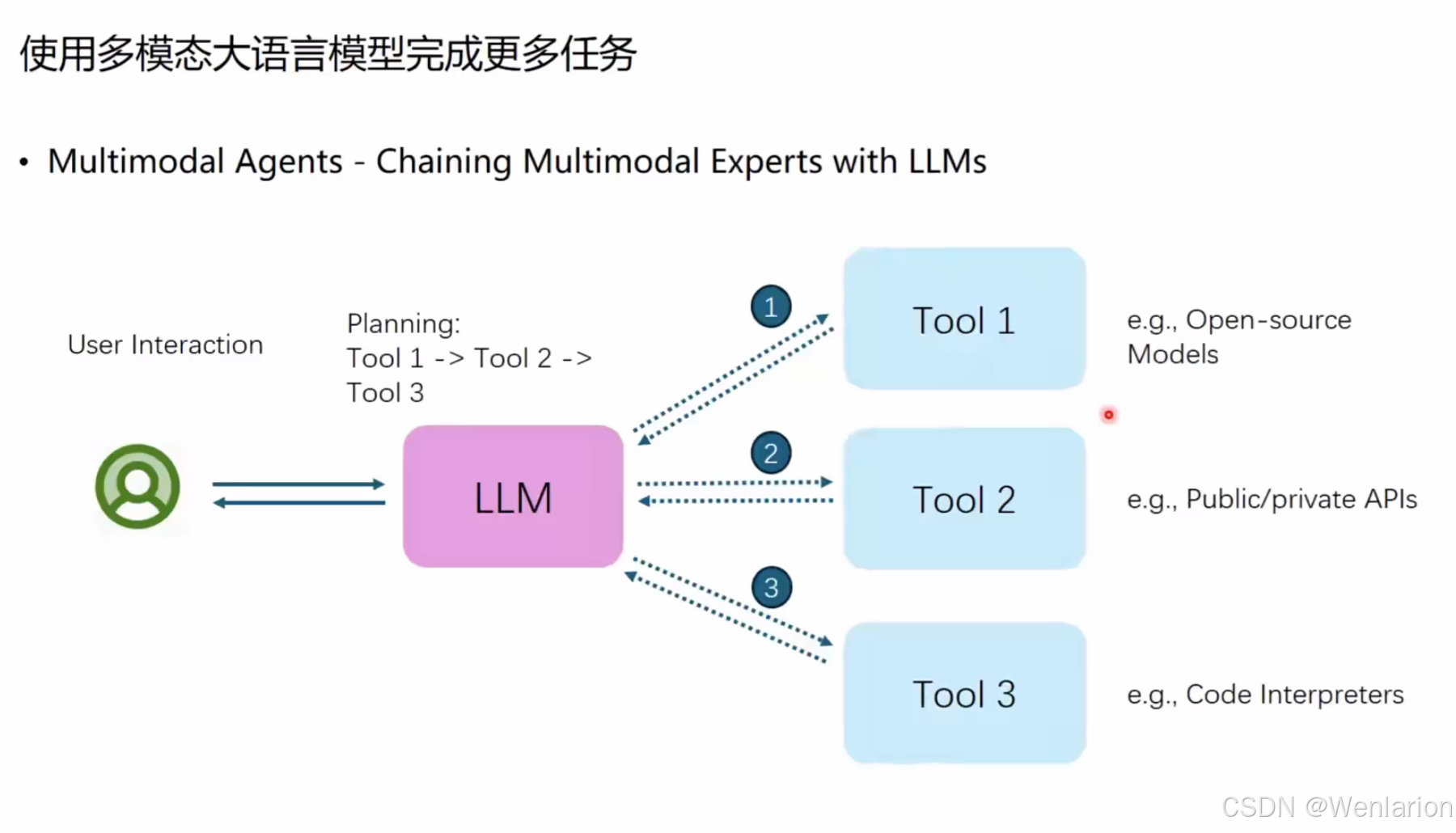
多模态智能体(Multimodal Agents)
这组图片展示了多模态大语言模型如何通过调用工具 / 技能,扩展能力边界,完成更复杂任务的技术范式。
1️⃣ 通用多模态智能体架构
这是一个基础框架:
-
核心大脑(LLM):作为中枢,负责与用户交互、做任务规划(比如决定先调用 Tool 1,再 Tool 2,最后 Tool 3)。
-
工具生态:LLM 可以按需调用不同类型的外部工具:
-
Tool 1:开源模型(如视觉理解、语音识别等专用模型)
-
Tool 2:公开 / 私有 API(如搜索、天气、支付等服务)
-
Tool 3:代码解释器(用于数学计算、数据分析等)
-
-
工作流:用户输入 → LLM 规划 → 链式调用工具 → 汇总结果 → 回复用户。
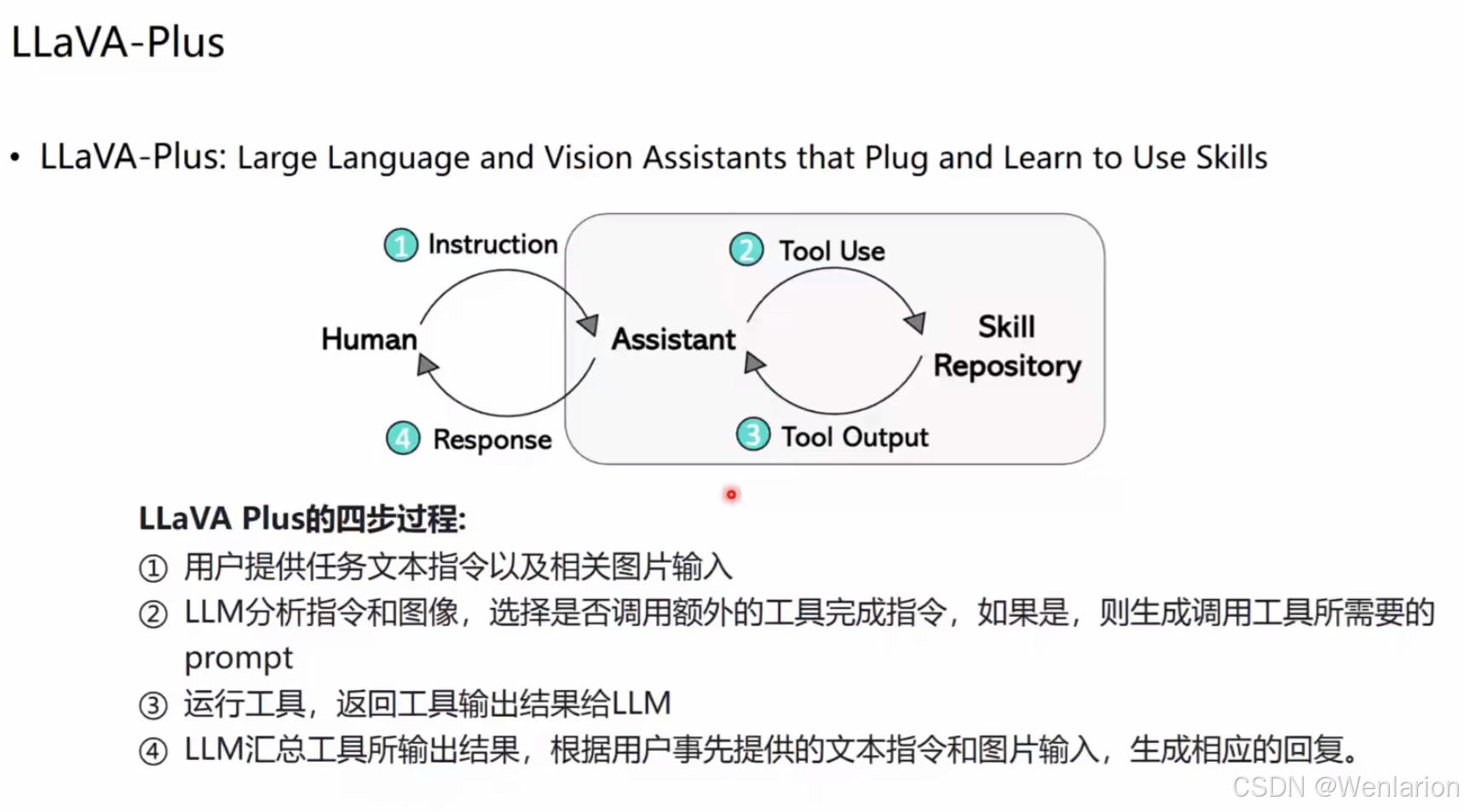
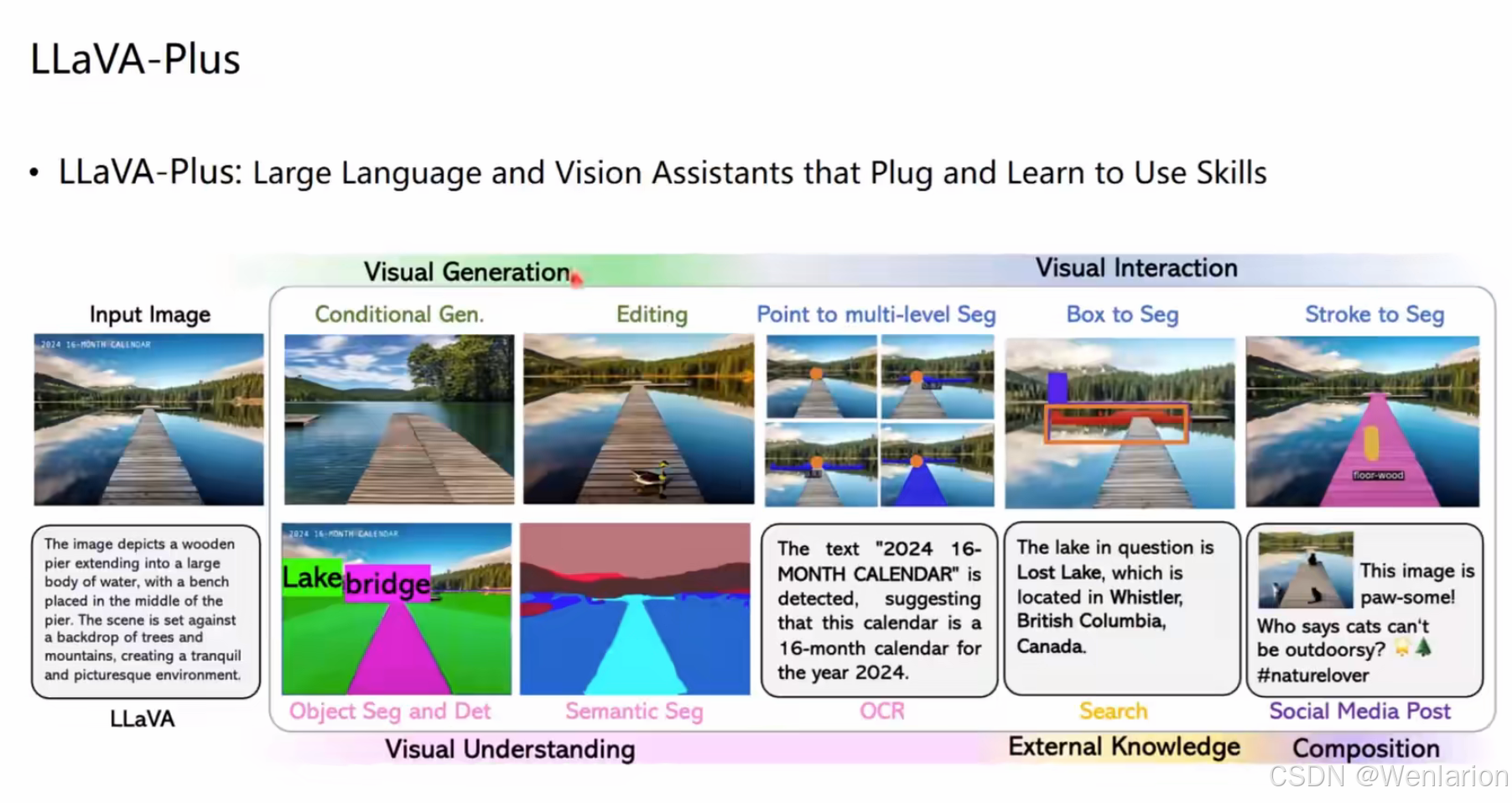
2️⃣ LLaVA-Plus:即插即用的多模态助手
LLaVA-Plus 是一个典型实现,它把视觉能力和工具调用结合起来:
-
四步执行流程:
-
指令输入:用户提供文本指令 + 图片
-
工具决策:LLM 分析任务,判断是否需要调用外部工具,并生成调用 prompt
-
工具执行:运行工具并返回结果
-
结果汇总:LLM 整合工具输出,生成最终回复
-
-
能力全景:
-
视觉理解:对象检测、语义分割、OCR 文字识别
-
视觉生成:条件生成、图像编辑
-
视觉交互:点选 / 框选 / 涂鸦式分割
-
外部知识:图搜、社交内容生成等
-

3️⃣ CogAgent:面向 GUI 的多模态智能体
CogAgent 是一个更偏向实际操作场景的智能体,专门强化了图形界面(GUI)交互能力:
-
核心能力:
-
支持高分辨率图像输入(1120×1120),能看清屏幕细节
-
强化Visual Agent:可以做复杂任务规划,一步步引导操作
-
强化GUI 解析与定位:能精准识别界面元素、定位按钮,模拟人类点击 / 输入
-
-
应用场景:
-
电脑端:指导用户在浏览器中搜索论文、操作软件
-
手机端:引导用户更改系统设置、查询信息、完成导航等
-
-
本质:让 AI 像人一样 “看屏幕、点鼠标 / 触屏、完成操作”。
💡 核心思想总结
这些模型共同体现了一个趋势:大模型不再单打独斗,而是成为 “调度中心”。
-
它们通过调用外部工具 / 专家模型,突破了自身在视觉、计算、实时信息等方面的局限。
-
最终目标是:让 AI 能理解更复杂的多模态输入(图文、屏幕、语音),并像人类一样执行连贯、复杂的现实任务。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)