硅基流动平台(SiliconFlow)基于openai-python调用思考模型时,如何关闭“思考过程”以提升响应速度?
摘要:在使用硅基流动(SiliconFlow)调用 DeepSeek-R1、QwQ 等具备“思维链(CoT)”能力的模型时,默认开启的思考模式会导致首字延迟高、生成速度慢,甚至在某些高频场景下引发超时或冗余输出。本文介绍如何通过 OpenAI SDK 的 extra_body 参数优雅地禁用 enable_thinking,实现秒级响应。
摘要:在使用硅基流动(SiliconFlow)调用 DeepSeek-R1、QwQ 等具备“思维链(CoT)”能力的模型时,默认开启的思考模式会导致首字延迟高、生成速度慢,甚至在某些高频场景下引发超时或冗余输出。本文介绍如何通过 OpenAI SDK 的
extra_body参数优雅地禁用enable_thinking,实现秒级响应。
一、背景与痛点
随着 DeepSeek-R1、Qwen-QwQ 等推理型大模型的普及,它们在复杂逻辑推理和数学解题上表现卓越。然而,这类模型通常默认开启 “思考模式”(Thinking Mode)。
在实际工程落地中,我们常遇到以下问题:
- 响应极慢:模型会先输出一大段
<think>...</think>的内部推理过程,导致用户看到第一个有效字符的时间(TTFT)显著增加。 - Token 浪费:思考过程往往占据大量 Token,增加了成本且无助于最终展示。
- 解析困难:前端需要额外编写正则表达式来过滤掉思考标签,增加了开发复杂度。
- 非必要场景:在简单的问答、翻译或闲聊场景中,我们并不需要模型进行深度推理,只需要快速给出结果。
因此,在非强推理场景下,禁用思考模式是提升用户体验和系统吞吐量的关键优化手段。
二、核心解决方案:使用 extra_body
硅基流动(SiliconFlow)兼容 OpenAI API 格式。对于像 enable_thinking 这样尚未被 OpenAI Python SDK 原生标准化支持的参数,我们需要使用 extra_body 字段将其透传给底层 API。
❌ 错误写法
直接作为参数传递会报错,因为 OpenAI SDK 会校验参数合法性:
# 报错:TypeError: Unexpected keyword argument 'enable_thinking'
response = client.chat.completions.create(
model="Pro/zai-org/GLM-4.7",
messages=[...],
enable_thinking=False
)
在openai-python的源码中,我们也可以看到没有提供此类参数: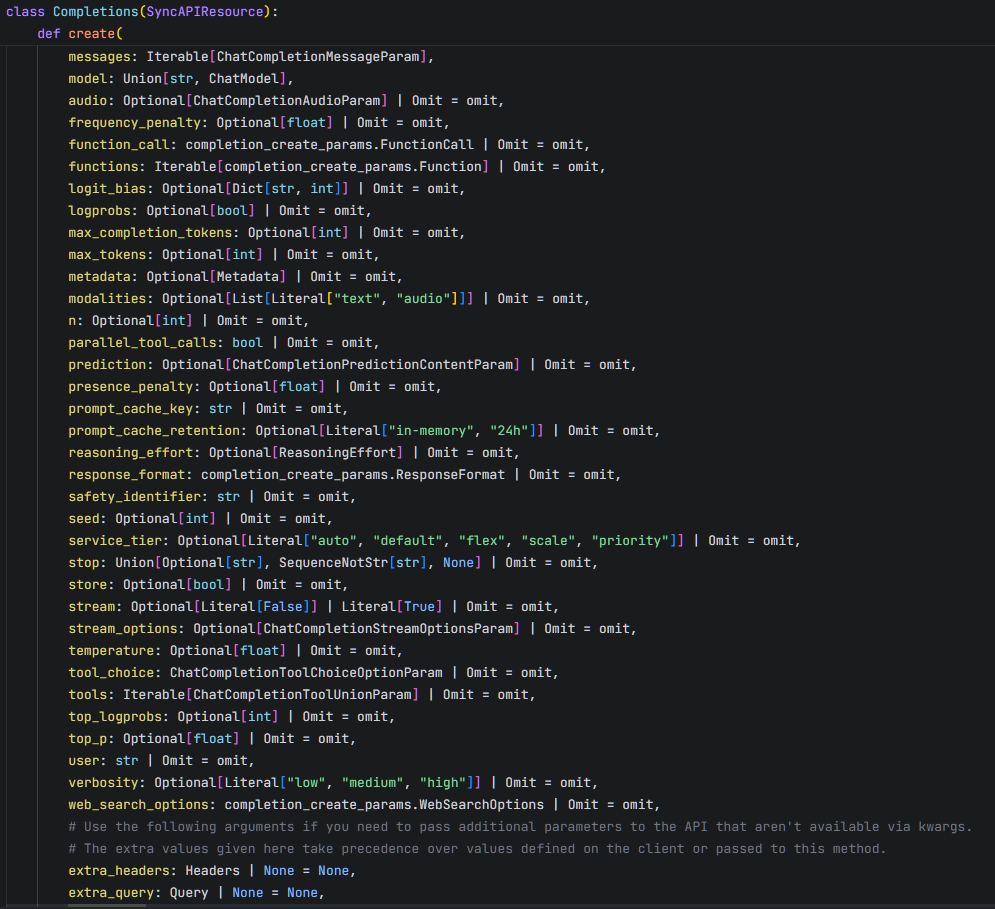
✅ 正确写法
将非标准参数放入 extra_body 字典中,将"enable_thinking"参数设置为False:
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1",
messages=[...],
extra_body={"enable_thinking": False} # 禁用思考模式
)
📊 效果对比
| 特性 | 开启思考 (enable_thinking: true) |
关闭思考 (enable_thinking: false) |
|---|---|---|
| 首字延迟 (TTFT) | 高 (需先生成思维链) | 低 (直接生成答案) |
| 输出内容 | 包含 <think>...</think> 标签 |
仅包含最终答案 |
| Token 消耗 | 较高 | 较低 |
| 适用场景 | 复杂数学、代码调试、逻辑推理 | 日常问答、翻译、摘要、客服 |
| 解析难度 | 需后端/前端清洗数据 | 无需处理,直接使用 |
三、注意事项与常见问题
1. 并非所有模型都支持该参数
目前主要支持该参数的模型包括 DeepSeek-R1 系列。其他模型(如 Qwen2.5-Coder 等非推理专用模型)本身不包含思考机制,设置此参数可能被忽略或报错。建议在调用前查阅硅基流动官方文档确认模型支持情况。截止2026年5月2日,参照官方文档支持思考的模型有:
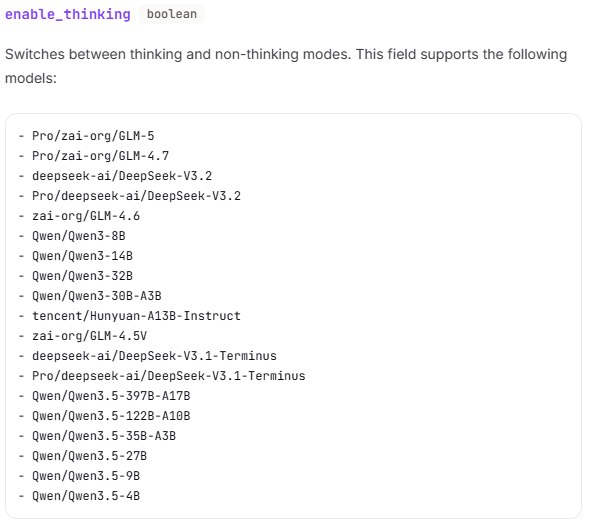
2.其他禁用思考模式方法
如果你不想安装庞大的 openai SDK,或者需要在非 Python 环境(如 Java, Go, Curl)中实现相同逻辑,使用 requests 库时,我们只需构造标准的 JSON的body,并将 enable_thinking: false 直接放入根层级即可。例如:
curl -X POST "https://api.siliconflow.cn/v1/chat/completions" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "Pro/zai-org/GLM-4.7",
"messages": [
{"role": "user", "content": "1+1等于几?"}
],
"enable_thinking": false
}'
四、总结
在高性能要求的生产环境中,合理控制大模型的“思考”行为至关重要。通过 OpenAI SDK 的 extra_body 参数,我们可以轻松地在硅基流动平台上禁用 DeepSeek-R1 等模型的思考模式,从而获得更快的响应速度和更干净的输出结果。
希望这篇教程能帮助你优化 AI 应用的性能!如有问题,欢迎在评论区交流。
参考链接:

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)