麻省理工MIT硬核神课《如何用AI做任何事》:多模态大模型底层逻辑与商业前沿全解析
麻省理工学院Paul Liang教授的《如何用AI做任何事》彻底重构了人工智能的认知底座。本文为您进行深度拆解,从多模态数据图谱、图网络架构,一路进阶至流匹配生成引擎与交互式智能体。带您穿透技术迷雾,抢占下一代人机协同的科研高地与商业爆发点。

摘要
麻省理工学院Paul Liang教授的《如何用AI做任何事》彻底重构了人工智能的认知底座。本文为您进行深度拆解,从多模态数据图谱、图网络架构,一路进阶至流匹配生成引擎与交互式智能体。带您穿透技术迷雾,抢占下一代人机协同的科研高地与商业爆发点。
文末阅读原文或https://t.zsxq.com/N8l80获取课程资料
引言:迎接多感知智能的浪潮
在过去的一年里,大语言模型(LLM)的狂潮席卷全球。然而,真正的技术先驱与敏锐的投资人们早就意识到:纯文本的狂欢终将触达天花板。人类生活在一个多感知的世界,医疗组织学切片、物理传感器、语音流、空间网格以及复杂的企业级知识网络,构成了数字世界的真实全貌。
麻省理工学院(MIT)媒体实验室与电子工程系联合推出的王牌课程《如何用AI做任何事》(How to AI Almost Anything),正是为了打破这种单模态的局限。这不仅仅是一门探讨算法演进的学术课程,更是一张通往通用人工智能(AGI)的“高维作战地图”。该课程的核心愿景是建立跨越尺度和感知介质的人机共生关系,从而极大提升生产力与人类福祉。
本文对课程内容进行了深度的延展与重构。无论您是寻找下一代技术护城河的科技投资人,还是攻坚底层技术瓶颈的研发专家,吃透以下四大硬核模块与三大战略研判,就能在接下来的AI大洗牌中掌握绝对的主动权。

一、打牢底座——重构AI的第一性原理 (Foundations of AI)
不要迷信架构,要洞悉数据的本质。
很多研发团队的失败,源于用错的模型处理错的数据。课程在第一模块直击要害:万物皆可建模,前提是弄懂“数据模态图谱”。
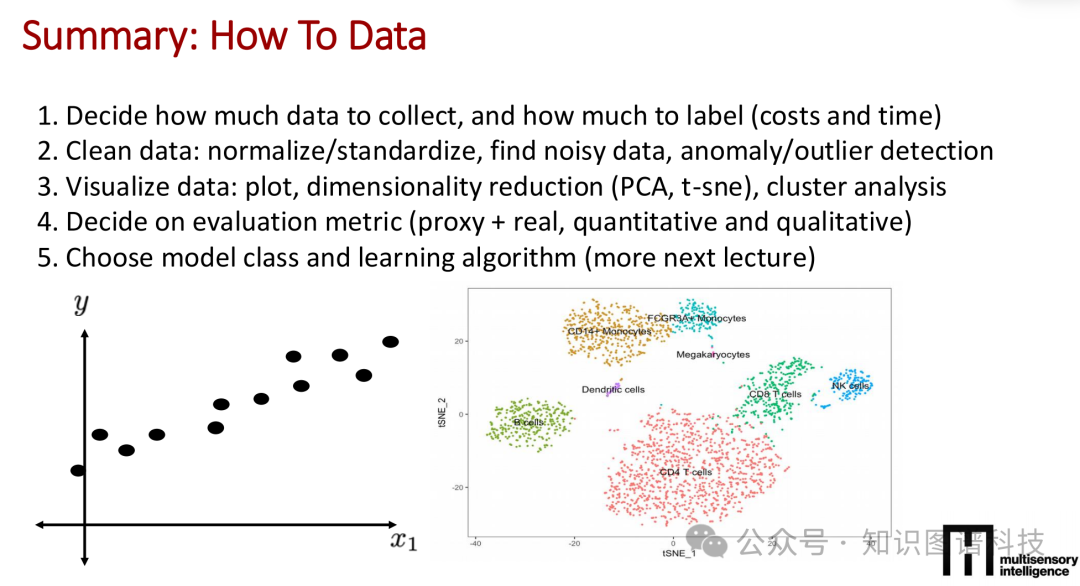
1.数据的五维透视:在动手编写哪怕一行代码之前,必须彻底解剖数据。课程提出了“数据模态图谱”的概念,要求从五个维度进行评估: 数据分布(离散或连续)、粒度(采样率的高低)、结构(时序、空间或图结构)、信息熵以及噪声的不完美度。 在工程实践中,极其关键的一步是利用主成分分析(PCA)或t-SNE等降维技术对数据进行聚类分析,直观地暴露数据中的噪声点和异常值。这是决定模型生死的“数据清洗”第一步。
2.架构的物理意义:深度学习不是黑盒,而是对物理世界的数学映射。时间序列数据需要RNN或Transformer来捕捉跨时间步的动态变化;空间网格数据(如医学图像)天生契合卷积神经网络的平移不变性;而最复杂的企业级关系网与分子结构,则必须依靠图神经网络(GNN)来实现无序节点的几何聚合。
3.降维打击的科研思路:在构建企业级AI团队或确立科研课题时,思路决定了最终的商业高度。课程明确提出了获取创新思想的两种核心路径: 第一种是“自下而上的发现”。这要求研发人员深入剖析现有最先进模型的失败案例,找到具体痛点,并通过渐进式修改(例如调整损失函数或引入局部对齐)来提升性能。这种路径在工业界极其稳妥,能带来立竿见影的增量进步,但难以产生颠覆性的跨越。 第二种是“自上而下的设计”。从宏观的、高层次的假设出发(例如:能否让AI像人类一样进行多模态的几何演算),构建全新的实验框架来测试这些假设。这种方法容易催生改变行业格局的独角兽项目,但试错成本极高。顶尖的科技企业,必须在这两种战略之间找到完美的平衡。
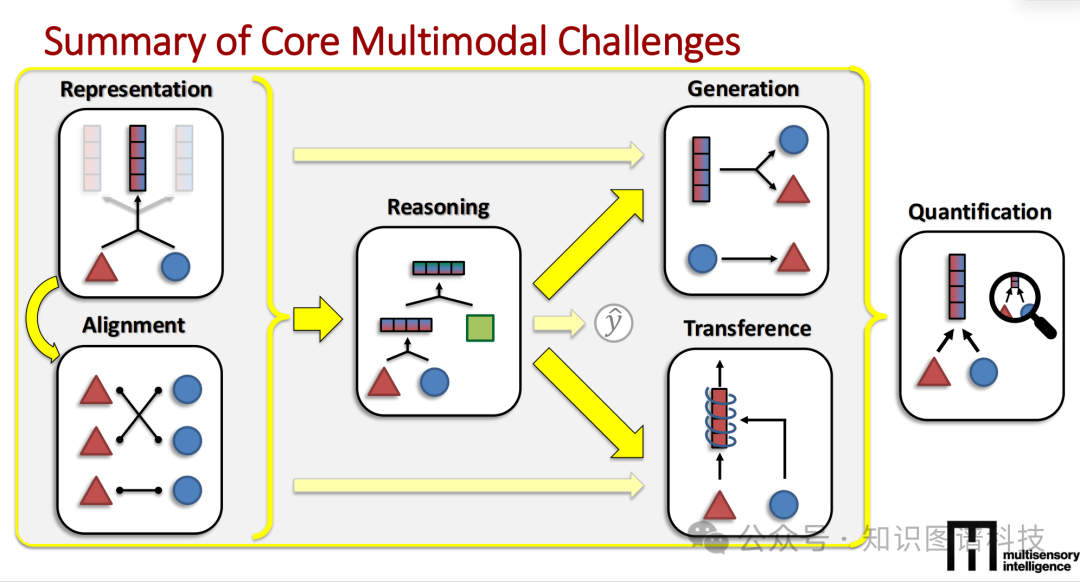
模块二:跨越孤岛——多模态融合的商业护城河 (Multimodal AI)
如果你的AI只能听懂一句话,或者只能看懂一张图,它在未来将毫无竞争力。
多模态的本质,是处理异构、互连与交互信息的科学。这就是当下极具商业潜力的护城河。
-
异构对齐与对比学习的暴力美学:如何让机器知道病历文本中描述的“边缘模糊的结节”与CT影像上的那一团阴影是同一个事物?这就是多模态的核心议题:对齐。 工业界目前最成功的解法是对比学习(如CLIP模型)。它通过计算极大批次的图像和文本特征向量的余弦相似度,利用InfoNCE损失函数,最大化正确图文对的相似度,同时强行推开错误的图文对。这种通过海量噪声数据进行自监督预训练的路径,极大地拓宽了多模态模型的泛化边界,让零样本(Zero-shot)的跨模态检索成为现实。
-
动态融合策略:低阶做法是“晚期融合”,即让视觉模型和文本模型各自得出结论后,再进行简单的加权平均。 高阶做法则是引入跨模态注意力机制的多模态Transformer。例如,让文本的特征去主动“查询”图像中对应的特征区块,实现乘性的深度交互。 更前沿的探索是“动态早期融合”。在传统的早期融合中,一旦某个模态(如传感器)出现剧烈噪声,就会在网络浅层污染所有特征。而动态融合允许模型根据输入数据的实时质量,自主决定在神经网络的哪一层开启信息交汇。这种高度灵活的架构,为自动驾驶和复杂工业控制提供了极高的鲁棒性。
-
跨模态迁移,小数据领域的破局利器:在罕见病诊断、特种工业缺陷检测等高精尖场景中,高价值的模态数据往往极其稀缺。 课程详细讲解了跨模态迁移与协同学习技术。迁移学习是指利用资源丰富的模态(如海量互联网文本)预训练的知识,来辅助资源稀缺模态(如特定频段的雷达信号或医学影像)的训练。 协同学习则要求两种模态在训练过程中互相促进。例如,通过循环翻译模型,要求模型能从文本生成图像特征,再从图像特征还原文本。这样即使在实际部署时传感器损坏导致某种模态缺失,模型依然能凭借训练时建立的联合表征给出精准预测。这是企事业单位突破数据孤岛的杀手锏。

模块三:认知爆发——大模型与现代生成引擎 (Large Models & Modern AI)
认知与创造,正在经历一场效率革命。
大语言模型(LLM)的算力经济学:大模型的强大并非魔法,而是遵循严谨的缩放定律(Scaling Laws)。盲目堆砌参数是极其昂贵的,计算预算必须在参数和高质量数据之间实现完美平衡。结合低秩微调(LoRA)与混合专家架构(MoE),千亿参数模型的推理成本正在断崖式下降。
视觉与语言的交响(LMM):当预训练好的语言大脑接入视觉编码器,原生的大型多模态模型开始具备“看图推理”的能力。甚至在复杂的时序预测任务中(如TimeLLM),语言模型的模式识别能力也展现出了超越传统算法的统治力。
流匹配(Flow Matching),下一代生成引擎的王座:告别缓慢的扩散模型(Diffusion)!当前生成模型领域的最前沿,是基于常微分方程(ODE)的流匹配机制。 传统的扩散模型需要通过数百次的去噪迭代才能生成一张清晰的图像,这在实时推理的商业场景中是不可接受的。流匹配技术旨在从纯粹的噪声空间到目标数据空间,直接构建一个连续的向量场。它的训练目标更为直接,采样速度极快,且生成数据的保真度极高。 在架构层面,传统的U-Net正逐渐被扩散Transformer(DiT)所取代,去除了空间卷积的DiT展现出了极佳的算力可扩展性。这正是近期爆发的Sora以及新一代高质量视频生成模型背后的绝对核心。 对于想要入局生成式AI底层的团队,课程给出了极其宝贵的实战秘籍:必须采用梯度裁剪以保证训练稳定,使用带有线性预热和余弦衰减的学习率调度器,并尽可能增大批量大小以确保常微分方程求解的收敛。
模块四:终局之战——强化学习与交互式智能体 (Interactive AI)
AI的最终形态,绝不是一个被动回答问题的聊天框,而是能在数字与物理世界自主规划、多步推理的交互式智能体(AI Agents)。
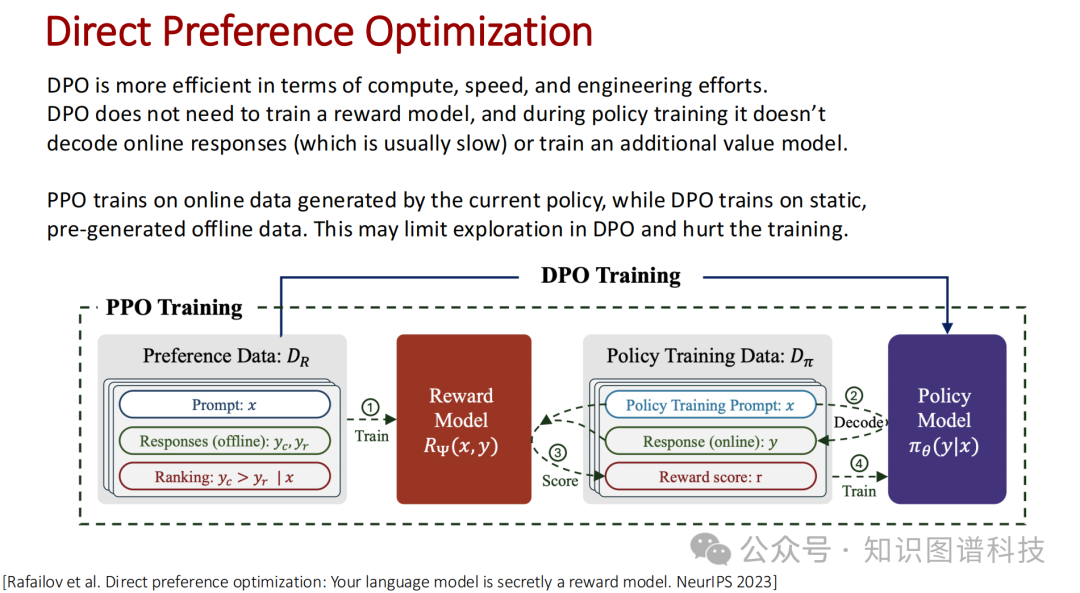
强化学习的狂飙:预训练赋予了模型知识,但如何让大模型具备严密的逻辑推理能力?答案是强化学习。 课程深度对比了当前主流的对齐算法。传统的近端策略优化(PPO)允许模型在强化阶段自主探索并生成回答,通过奖励模型进行评分,从而探索预训练数据之外的未知空间。而直接偏好优化(DPO)则完全依赖于离线收集的人类偏好数据进行直接优化。虽然DPO训练更为稳定高效,但由于缺乏在线探索,它可能会限制模型在复杂数学与逻辑任务中的涌现能力。 只有通过不断试错、自我博弈并进行奖励反思,模型才能真正突破“死记硬背”的瓶颈。
多步推理与人机协作:未来的智能体必须具备像人类一样的多模态逐步推理能力。 课程展示了一个前沿的交互式草图系统。当学生询问复杂的几何或微积分问题时,该系统不仅能通过大模型理解问题,还能自主编写并执行Python代码来进行精准计算,并实时在虚拟白板上绘制辅助图表。这种将大模型的语义理解与代码的确定性符号演算深度结合的模式,是解决AI“幻觉”问题的终极路径之一。
伦理与安全的底线:能力越强,风险越大。由于多模态大模型的训练数据来源于互联网,其内部不可避免地吸收了大量的社会偏见。 未来的高级智能体(如WebArena中处理企业级自动化任务的Agent),面对模糊的用户指令时,绝不能盲目执行。先进的系统必须在规划过程中引入“人机回环”(Human-in-the-loop),主动向人类发问澄清需求。在面临对抗攻击或模态缺失时,模型必须能够量化自身的不确定性,并给出透明可控的响应。只有越过了这道安全伦理的红线,AI才能被真正广泛部署于医疗诊断、金融交易与实体机器人等核心系统。
结语:拥抱多感知的未来
麻省理工学院的这门神课,为我们拨开了算法参数的迷雾,直击人工智能重构世界的底层代码。在这场席卷全球的技术洪流中,拒绝盲从跟风,深入掌握多感知智能的底层逻辑,就是掌握了未来十年的财富与创新密码。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)