从拼接走向统一:商汤SenseNova-U1如何重新定义多模态AI
商汤科技SenseNova-U1多模态模型评测:原生统一架构带来图文生成新突破 SenseNova-U1采用创新的NEO-unify架构,摒弃传统拼接式多模态模型的视觉编码器和VAE模块,实现像素patch与文字token在同一Transformer主干中的统一处理。测试表明,该模型在复杂空间结构理解(如中式书房场景)、多主体差异处理(赛博朋克茶馆)、信息图解析(准确识别电脑桌面细节)等方面表现优
不久前,我帮朋友做一个产品手册。需要把一张复杂的电路板照片转换成带标注的技术图解。我试了几个主流多模态模型,结果让人哭笑不得——有的能描述"这是一块绿色电路板",但让它指出具体哪个是稳压芯片,就开始胡编;有的能生成漂亮的示意图,但输入的照片和输出的图完全是两码事。
这种"看得懂但不会画,画得出但看不懂"的割裂感,根源在于现有主流架构的先天缺陷:看图靠视觉编码器(VE)压缩信息,画图靠扩散模型或VAE生成像素,中间靠一个适配器当翻译。就像两个人用第三方翻译软件沟通,意思大致到了,但细节全丢。
后面了解到商汤科技开源了SenseNova-U1,我进行了一番尝试,发现真的是暴力美学。
1. 多模态统一推理技术
SenseNova-U1 是商汤科技于 2025 年 5 月发布的多模态统一推理模型,属于"日日新"大模型体系中的旗舰产品。该模型采用自主研发的原生多模态统一架构NEO-unify,能够无缝融合文本、图像、视频等多种模态的输入与输出,标志着多模态大模型从"拼接式"向"原生统一"架构的重要演进。
那么什么是NEO-unify,官网给了一张图:
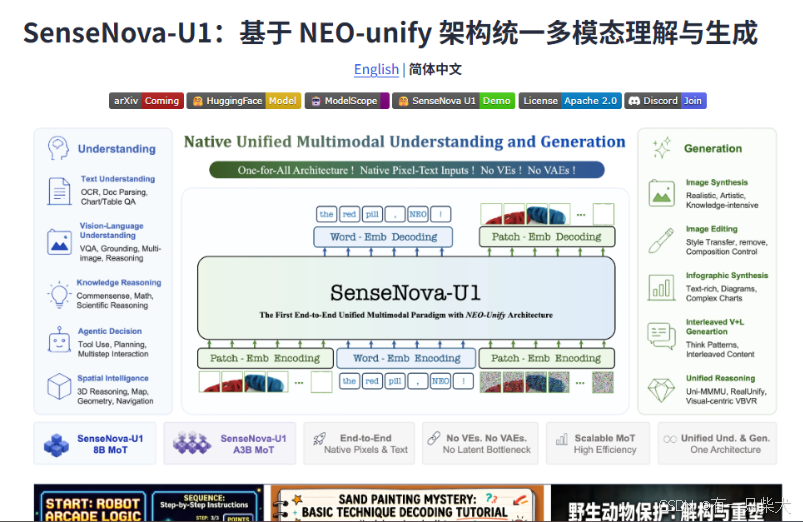
它和我之前用过的多模态模型最大的区别——不是参数堆出来的,而是架构上把视觉编码器(VE)和 VAE 全砍了。
这两年"统一架构"已经是个被滥用得很厉害的词,大家把 cross-attention 一接就敢叫 unified。但翻完它的设计文档我承认:U1 这个"统一"是真的——像素 patch 和文字 token 直接走同一个 Transformer 主干,理解和生成不是两个模块,而是同一个上下文里的两种推理视角。
个人感觉是U1 是从第一性原理重写了这个"服务"。
2. 在线体验-多场景测试
SenseNova-U1同样提供了本地部署,在线体验,API接入等多种方式。我这里使用最简单的在线web体验来尝尝鲜。在线体验地址:https://unify.light-ai.top/。不过目前在线体制仅支持SenseNova-U1-Fast模型,专供信息图生成。图文交错目前需要使用邀请码才能体验。
2.1 文生图
文生图是当前大模型比较基础,且很实用的能力。但是主流拼接大模型在生图时,往往容易漏掉提示词里的修饰语、搞错前后空间位置,或者在文字细节上“翻车”。我们要测试 U1 到底懂不懂复杂的中文梗和精细的物理逻辑。
我这里实验了两种场景:
2.1.1 场景一:空间结构测试
提示词:生成一张中式书房的特写。阳光从左侧雕花木窗洒进来,书桌上放着一叠宣纸、一块青砚,砚台里有刚磨好的墨,一根毛笔搁在笔架上。背景的书架上整齐排列着线装书,其中一本书的封面上清晰地写着‘日日新’三个字。画面整体呈现出宁静的电影质感。
这里主要观察“日日新”三个字会不会清晰,会不会乱码?光源以及毛笔位置关系是否正确。
这是U1生成的海报图:
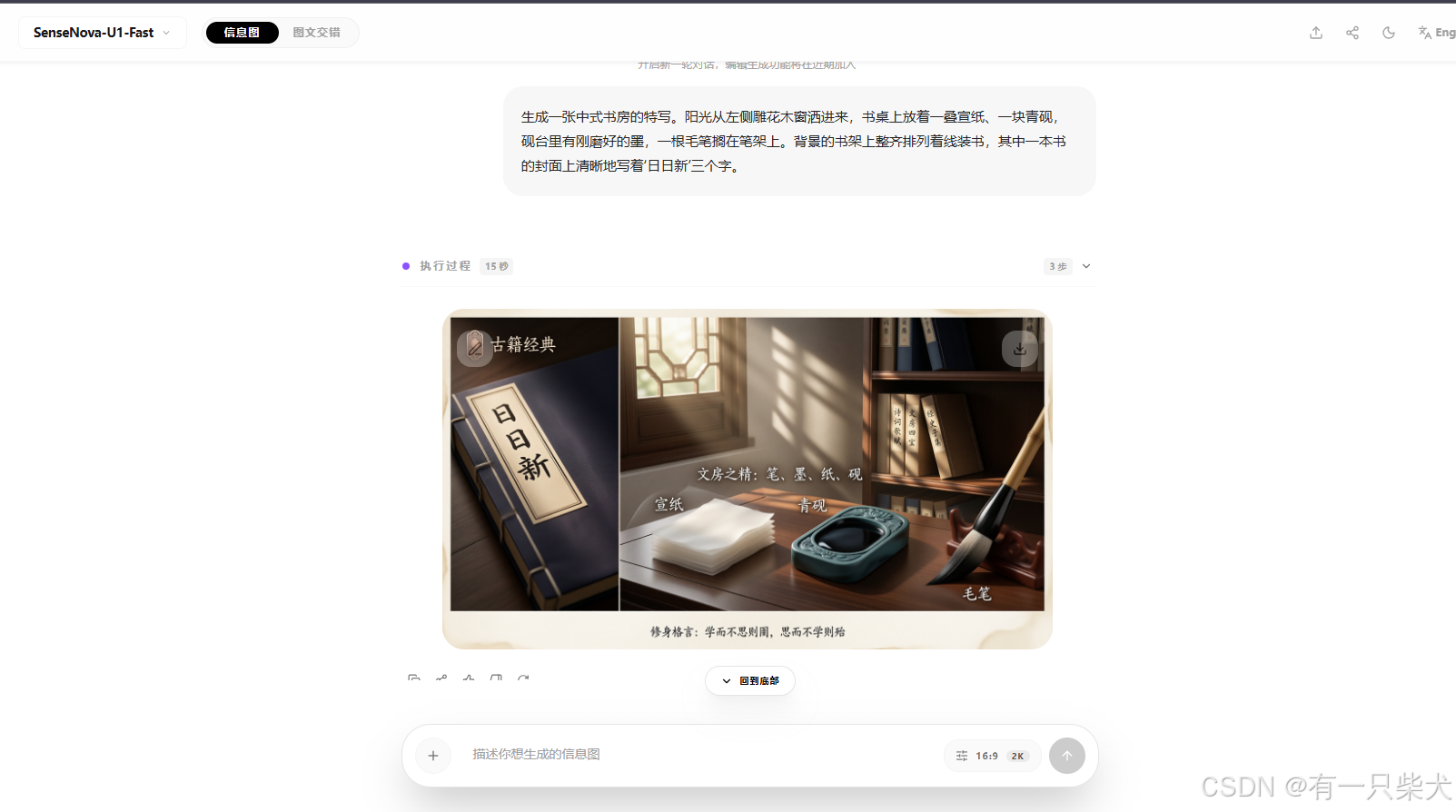
从效果图来看,所有的位置都是对的,包括光源,包括字体也比较清晰。让我比较震惊的是,他连砚台里磨好的墨都体现出来了。这是对复杂空间结构以及位置关系和物理逻辑的理解能力。
2.1.2 场景二:多个主体下的差异测试
提示词:生成赛博朋克风格的茶馆,一个身穿未来机甲的机器人正在用紫砂壶给一只戴着墨镜的黑猫倒茶,茶杯里冒出袅袅青烟,黑猫手里还拿着一本量子力学书。
这里主要测试当一张图中,出现多个主体时,大模型会不会顾此失彼。
U1生成的图片如下:
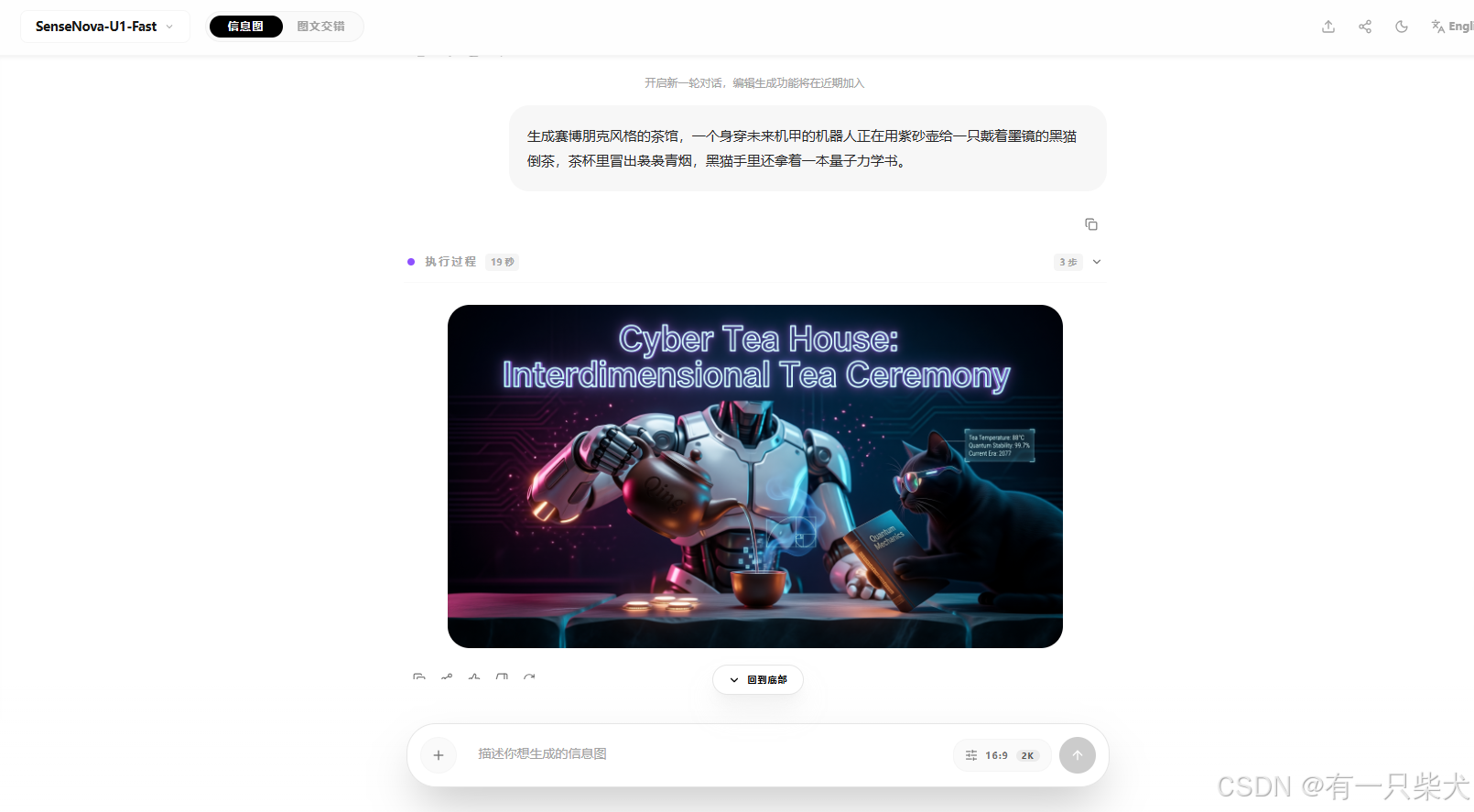
可以看到对于多主体结构也基本满足了我的需求。并没有出现哪个主体为主哪个主体为辅的差异。
2.2 信息图
测试完文生图后,我对信息图进行了测试。简单说,就是给到一张图片,让U1概括出图片的信息。
我随手拍了一张我的电脑桌面,让他概括一下图片的基础信息:
其实这里对于大模型来说很难解析的是电脑的像素点位反光。此类光点很容易对图片的理解产生干扰。但是U1的表现我再次震惊了,基本准确无误,甚至我的账号,电脑品牌,甚至我浏览器的标签都能精准识别。
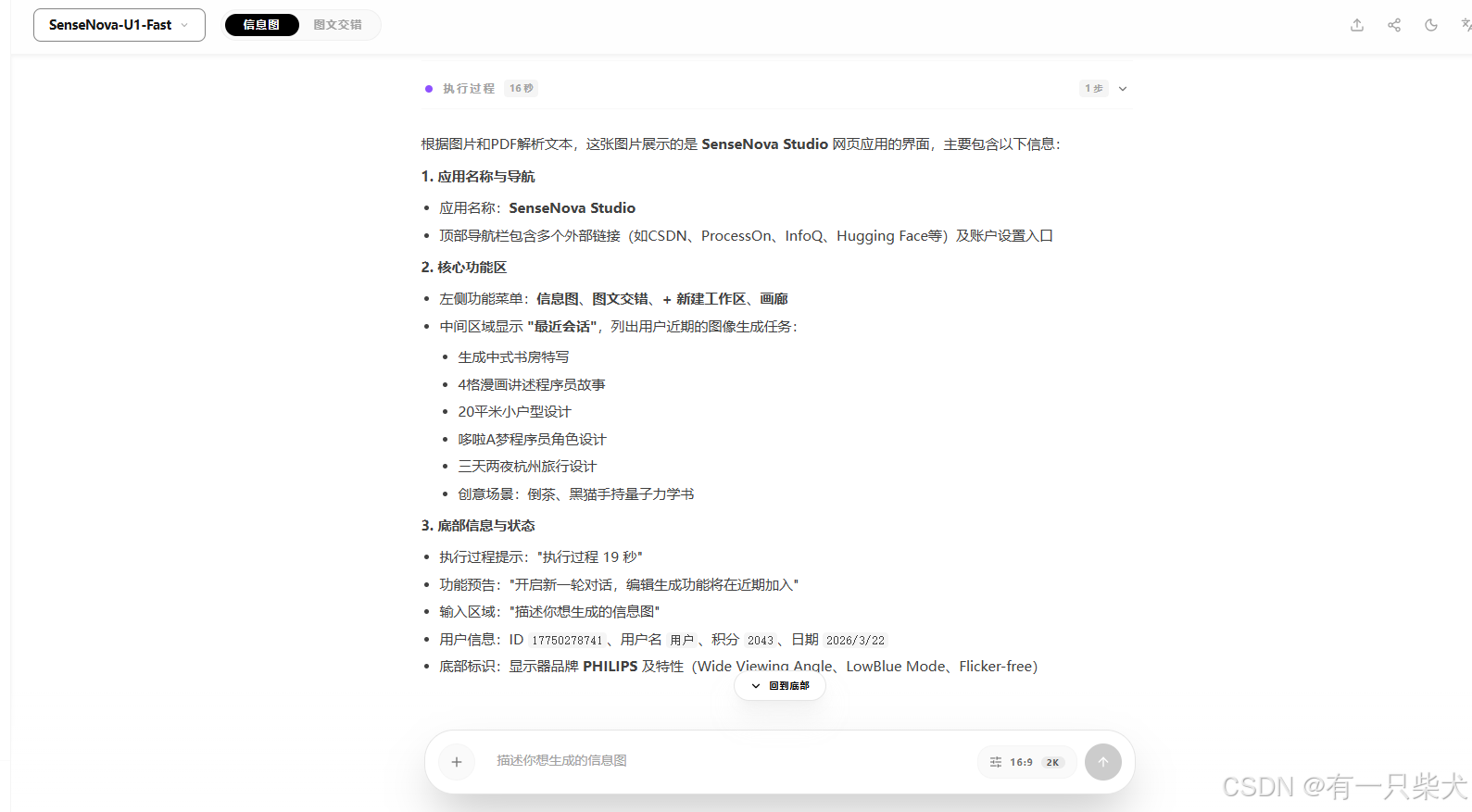
可能这就是SenseNova U1背后架构NEO-Unify摒弃了拼接式架构的真正能力。做到了图文模型不仅仅只是画图,更是信息设计。
2.3 图文交错
其实我最想体验的,还是他的图文交错能力。前面信息图和图片编辑能力已经让我足够惊艳,我网上找了一些关于图文交错的生成产物,这不是妥妥的一键生成剧本了吗。
我这里测试了两个场景:
2.3.1 场景一:连环画/分镜故事
提示词:"创作一个'小猫探险记'的儿童绘本故事,共6页,每页包含一段文字和对应插画,主角是一只橘白相间的条纹小猫"
这里测试的是在叙事创作环境下,分镜场景中角色一致性,以及场景的切换是否合理。主流大模型一直存在如果分镜生成中,角色不一致,上下镜情节脱离严重的问题。直到GPT-image2才宣布已经彻底处理该问题,但是GPT-Image2着实贵的离谱。
来看U1的效果:
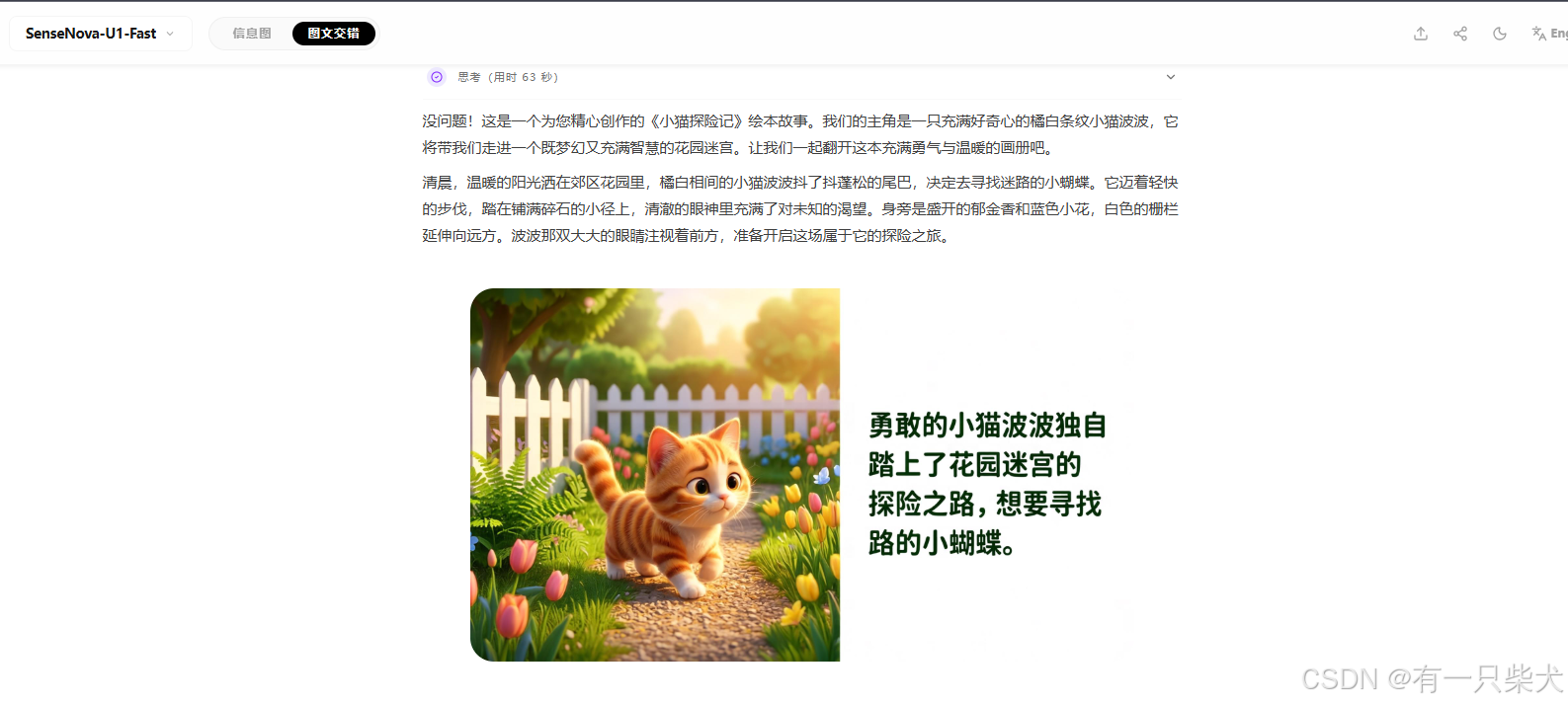





测试下来,可以发现U1完全具备理解前序图文状态,生成一致的下一步的能力;以及跨图像保持角色/场景一致性,处理突发事件逻辑。
正如开篇介绍的,NEO-Unify架构与传统的多模态架构不同的是:
-
传统多模态架构,通常使用视觉编码器来看图,理解图;使用VAE来画图;
-
NEO-Unify,直接从原始像素和文本中进行学习,这样既可以从复杂结构中提取信息,又可以根据复杂逻辑生成内容
2.3.2 场景二:网上很流行的食谱教程
提示词:写一篇‘如何制作完美法式牛颂面包’的图文交错教程。包含三个主要步骤(和面、折叠黄油、烘焙),每个步骤给出详细文字说明,并在其下方生成对应的写实风格步骤配图。
以下是U1生成过程中思考的过程,我截个图看看:
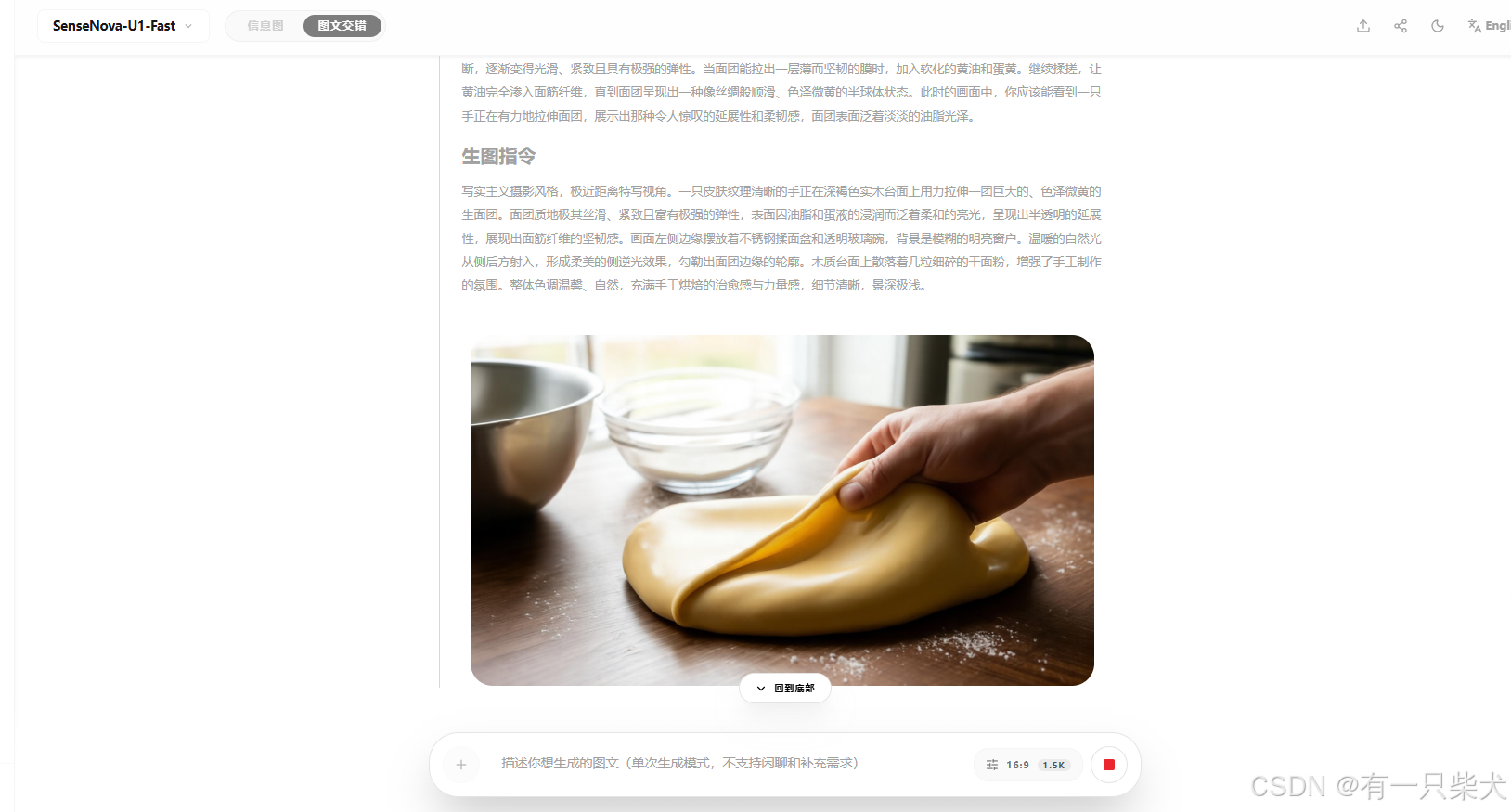
每一步都配上图片以及文字解说,直接一步到位。来看最后的效果:
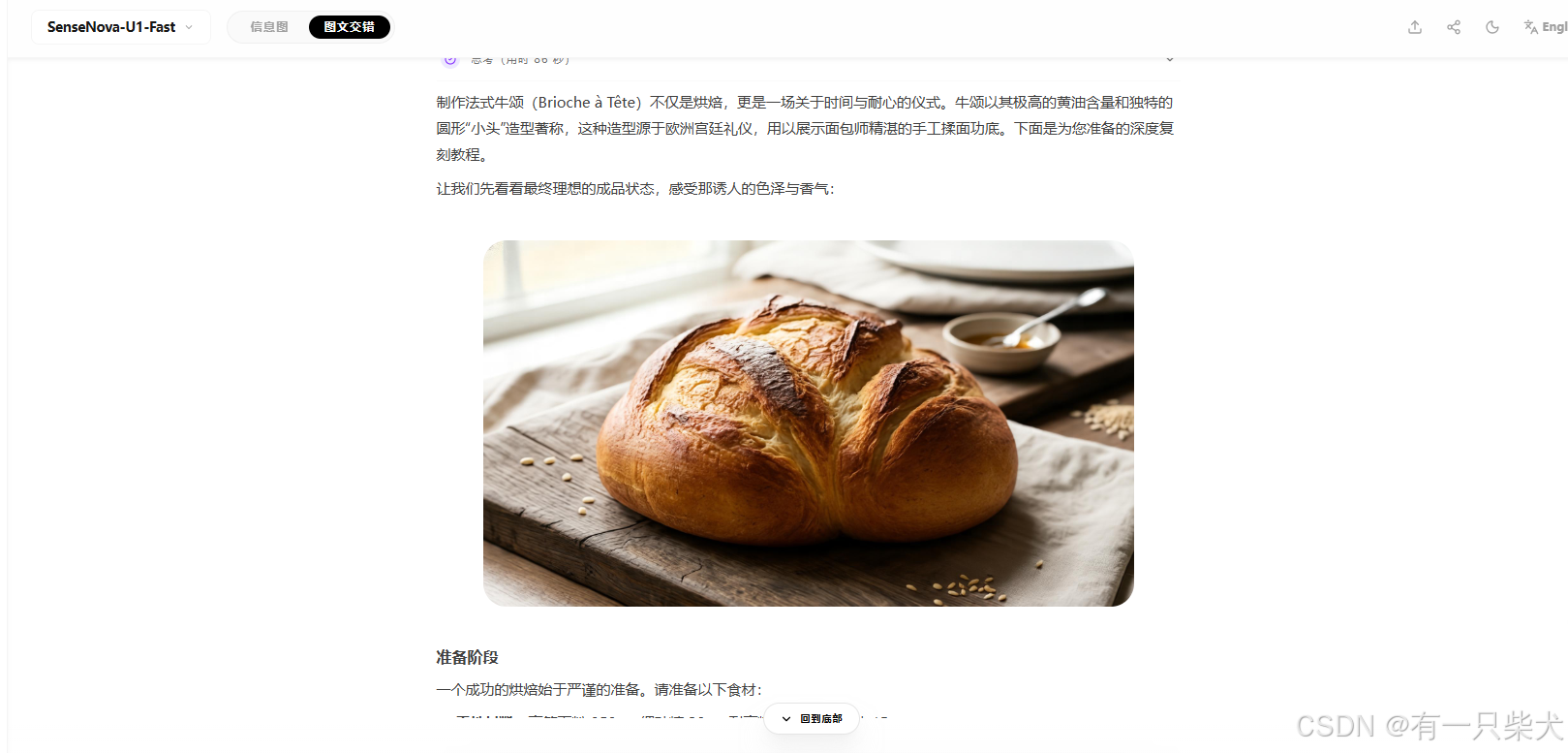







生成出来的文字描述,动作与生成的面团、黄油、以及面包状态都高度契合。
不过在上面整形阶段,生成的图片出了一点小瑕疵,图片并没有看过去那么流畅真实。不过问题也不大,相比之下对于开源模型能处理到这种程度,已经非常舒服了。
这里不得不在提下:正是因为商汤摒弃了拼接式架构,U1 才能在“图文交错”时不需要在两个模型间疯狂切换传递,从而实现了极高的效率和天生的图文契合度。
3. 使用感受
这次的统一架构很明显的是带来了图文生成的连贯性,图片和文字不再割裂。一个模型既能看懂图又能画出图,中间没有信息损耗。
感觉生图速度还可以,我基本10s左右就可以生成出来了,在同参数量下推理延迟还是有优势的。
对于自媒体从业者来说,1分钟左右可以完成一组连贯的图文创作,从"构思→生成→微调"的循环被大幅压缩,"边写边画"从概念变成了可落地的工作流。
而对于我这样的后端开发者来说,它提供了一条GPT-Image-2无法提供的路——开源、可本地部署、可微调、可嵌入自己的产品。对于创作者,连续图文交错输出让"边写边画"成为现实。对于企业,数据不出本地的部署选项解决了合规顾虑。
大胆思考下,如果对于某个产品迭代,将迭代原型输入,是否可以得到后续每个迭代的快速原型创意和展示?
官方参考资料:
Github: https://github.com/OpenSenseNova/SenseNova-U1
HuggingFace:https://huggingface.co/collections/sensenova/sensenova-u1

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)