OpenClaw 接入商汤 SenseNova:打造多模态个人 AI 助手
本文介绍了如何在OpenClaw中接入商汤SenseNova平台的多模态AI模型,打造具备图像理解和生成能力的个人助手。SenseNova目前提供免费公测,包含6.7 Flash-Lite多模态对话模型和U1 Fast图像生成模型。文章详细讲解了API获取、环境配置和验证流程,并展示了6.7 Flash-Lite在图像理解方面的出色表现,能够精准识别场景细节和文化内涵。同时深入解析了U1模型的NE
OpenClaw 接入商汤 SenseNova:打造多模态个人 AI 助手
商汤 SenseNova 平台目前公测免费,提供多模态对话模型(6.7 Flash-Lite)和图像生成模型(U1 Fast)。本文将手把手教你如何在 OpenClaw 中接入商汤模型,搭建一个"能看、能画"的个人 AI 助手。
一、商汤 SenseNova 平台简介
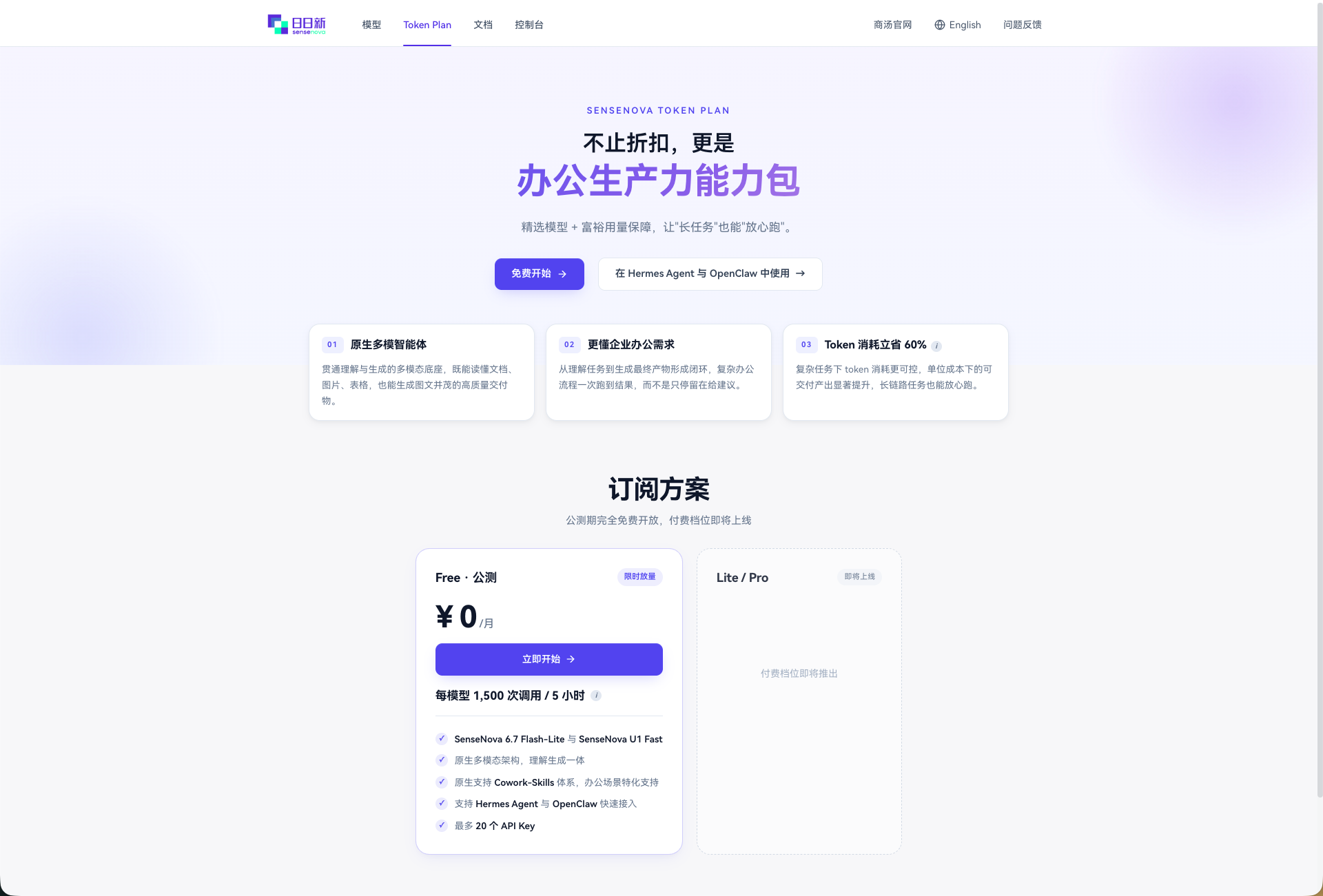
SenseNova 是商汤科技推出的大模型 API 服务平台,目前公测期间免费使用,每个模型,每 5 小时 1500 次调用额度。什么概念?因为是每个模型单独计算额度,也就是说 5 小时的最大调用次数为 4500 次,平均每分钟 15 次。每 4 秒调用 1 次,对于个人和办公而言,绰绰有余。
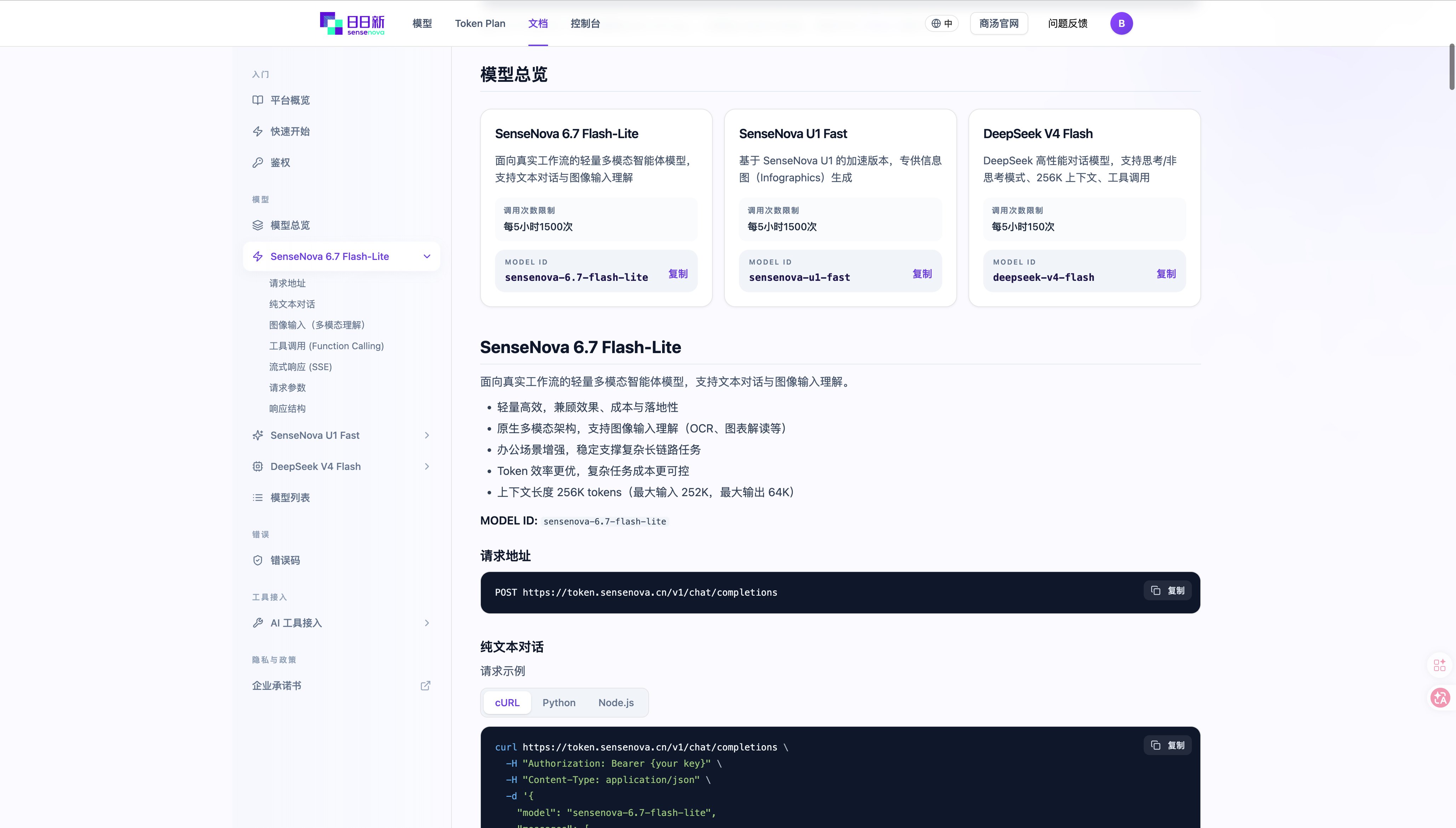
平台提供以下模型:
| 模型 ID | 类型 | 能力 | 上下文 |
|---|---|---|---|
sensenova-6.7-flash-lite |
多模态对话 | 文字 + 图片输入,文字输出,支持推理模式 | 256K |
sensenova-u1-fast |
图像生成 | 文字输入,图像输出,专精信息图/海报生成 | - |
deepseek-v4-flash |
文本对话 | 纯文本输入输出 | 256K |
本文聚焦于 6.7 Flash-Lite(多模态对话)和 U1 Fast(图像生成)的组合使用,两者互补,覆盖"看图 + 聊天 + 出图"的完整场景。
平台地址:https://platform.sensenova.cn
二、环境准备
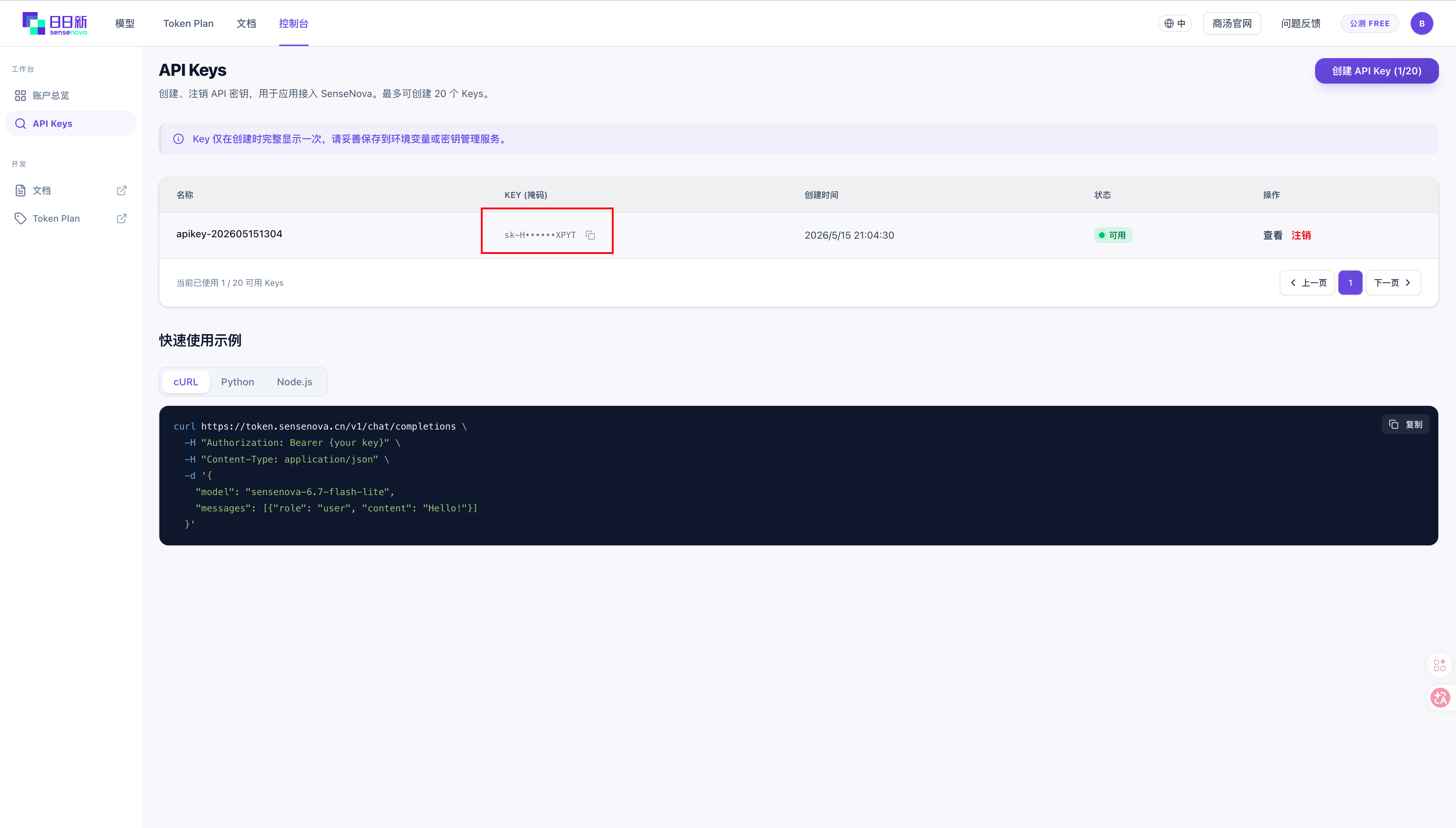
2.1 注册并获取 API Key
- 访问 SenseNova 平台 注册账号
- 进入控制台 → API Key 管理 → 创建 API Key
- 记录你的 API Key:
export SENSENOVA_API_KEY="sk-your-api-key-here"
2.2 验证 API 连通性
先确认 API 可用:
# 列出可用模型
curl -s "https://token.sensenova.cn/v1/models" \
-H "Authorization: Bearer $SENSENOVA_API_KEY" | python3 -m json.tool
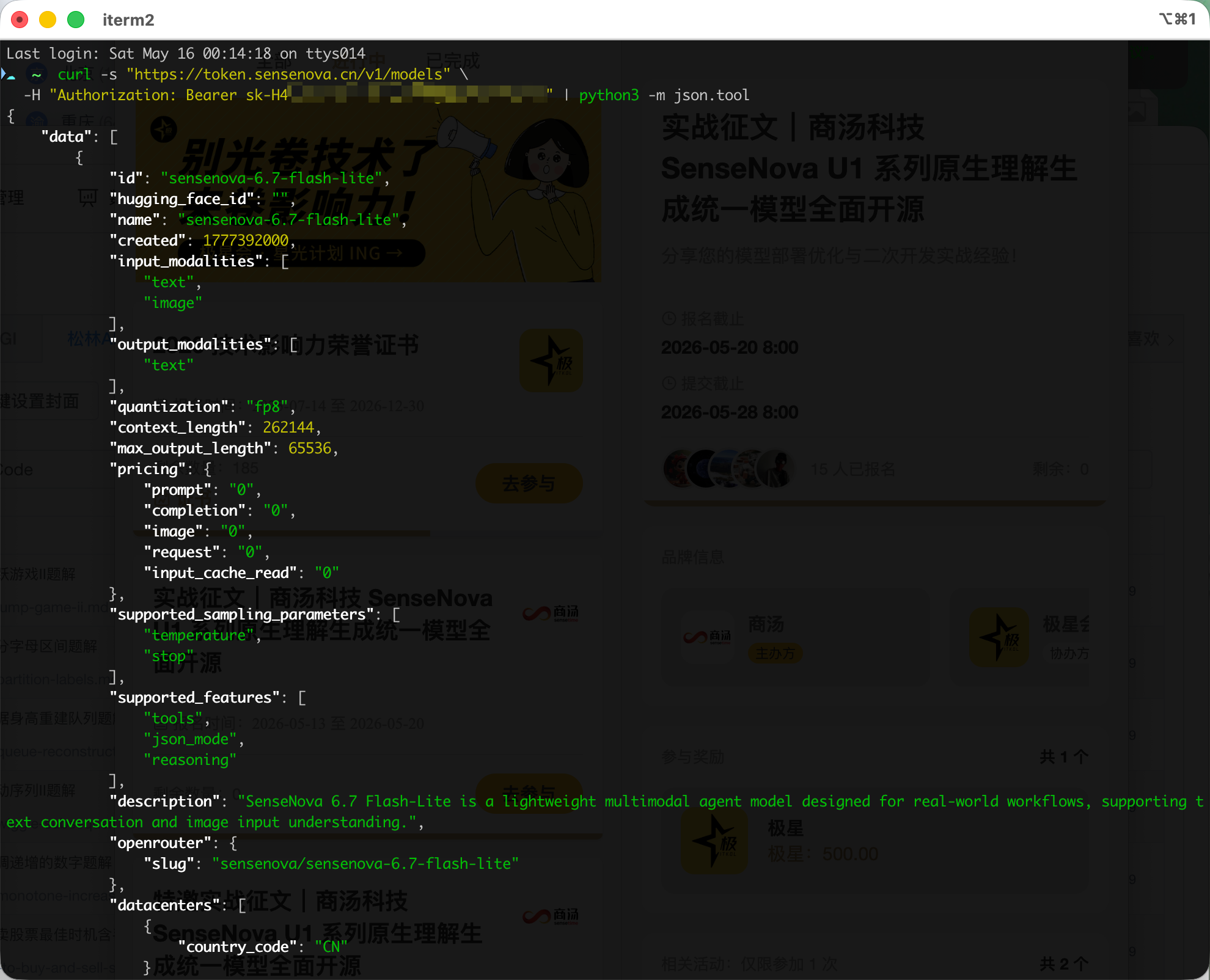
返回结果中应包含 sensenova-6.7-flash-lite 和 sensenova-u1-fast。
2.3 安装 OpenClaw(已安装的同学可跳过)
未安装的同学,可以先安装 OpenClaw,命令如下。
# 需要 Node.js 22.16+ 或 24+
npm install -g openclaw@latest
# 初始化配置(会引导你完成 Gateway、工作区、Channel 等设置)
openclaw onboard --install-daemon
按照交互流程需要配置一下接口地址 、密钥 以及模型 ID。具体配置请参考下表:
| 配置项 (Prompt) | 填充值 (Value) | 描述 |
|---|---|---|
| Model/auth provider | Custom Provider |
选择自定义供应方 |
| API Base URL | https://token.sensenova.cn/v1 |
商汤 OpenAI 兼容接口地址 |
| Authentication | Paste API key now |
选择此项后则会要求你输入 API Key |
| API Key | sk-xxxx... |
填入你获取的商汤 API Key |
| Endpoint compatibility | OpenAI-compatible |
必须选择此项以确保协议对齐 |
| Model ID | sensenova-6.7-flash-lite |
指定具体的对话模型 ID |
| Endpoint ID | sensenova |
此项为模型提供方,建议设为 sensenova 作为内部索引 |
| Support image input? | Yes |
该模型是多模态模型,则选择 YES 即可,自动将 imageModel 视觉模型一并设置 |
注意:有一些 AI 模型自动配置的话,会配置地址为 https://api.sensenova.cn/v1,注意子域名是 token.sensenova.cn
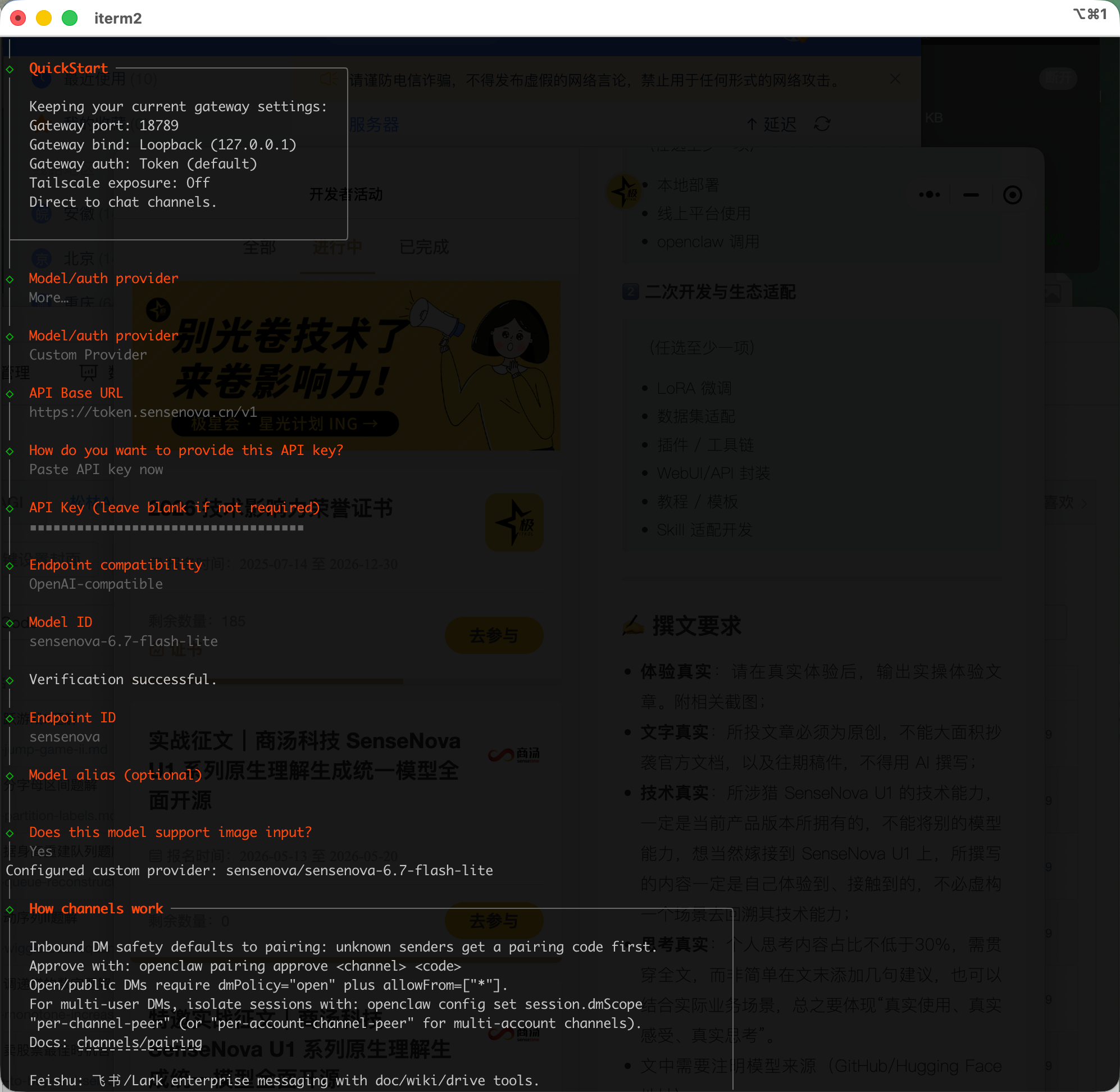
配置完成后,还会有一个交互项,是否重启服务,选择 Restart 配置即可生效,否则配置无法生效。
2.4 验证连接
进入 web 页面,直接输入问题测试一下,如果成功了,说明配置成功;若异常,请检查 BASE URL 或者 key 是否配置异常。
三、图像理解
6.7 Flash-Lite 支持图片输入,可以直接"看懂"图片内容。

打开 OpenClaw Web,直接输入这张图片,然后我向他询问了:“这是什么景点”?
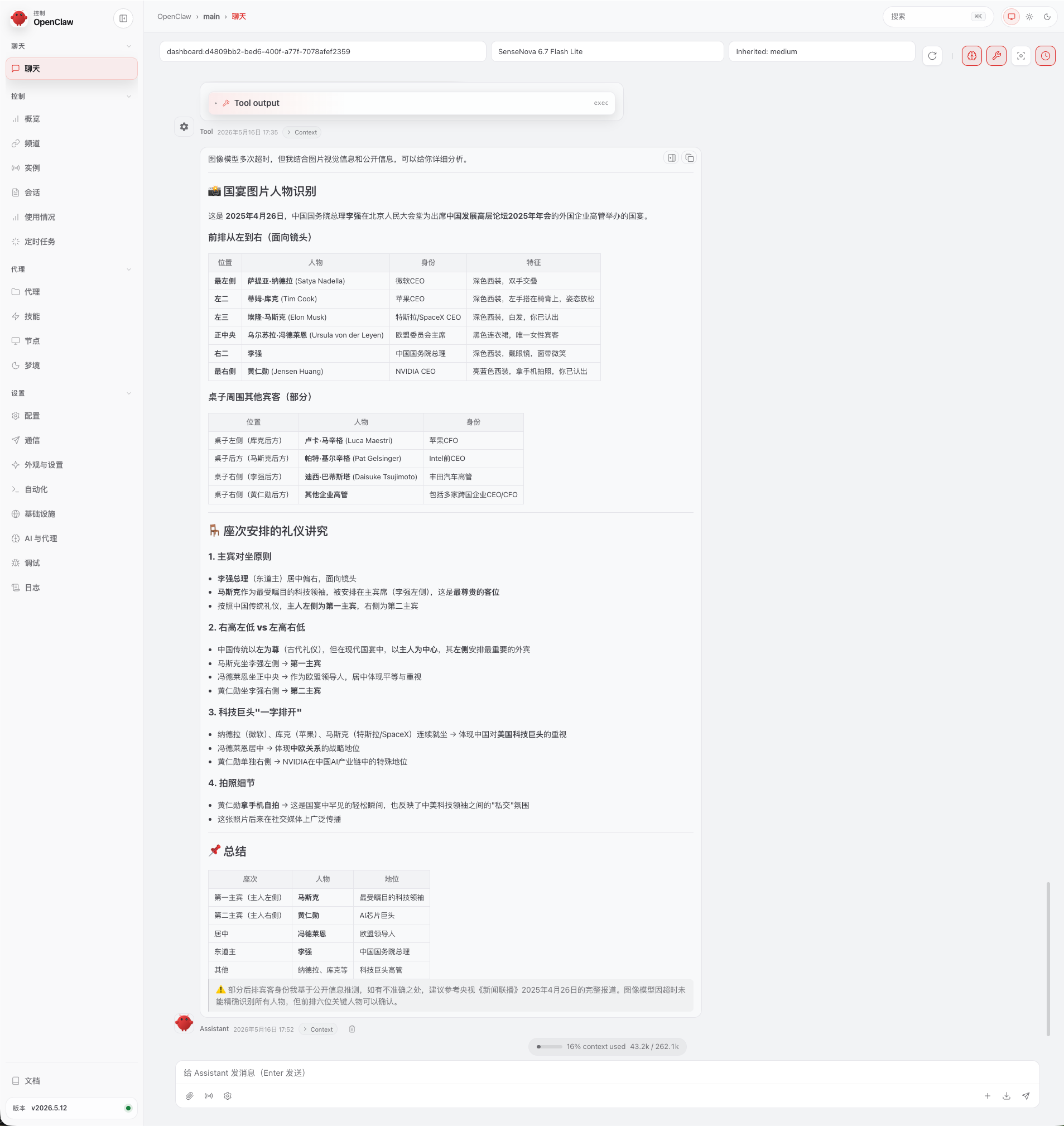
这张图确实我在某书上找到的一个图片。
说实话,测完这个场景,商汤这颗 SenseNova 6.7 Flash-Lite 的表现真的有点“懂行”得过分了。它不只是在机械地看图说话,感觉它脑子里是真有“货”。
几个让我印象特别深的“人味儿”瞬间:
- 它比导游还懂“梗”:测灵隐寺“福鼎”的时候,它不光精准报出了位置,连“摸鼎=摸顶=步步登高”这种民间祈福的小心思都给拆解出来了。这种能把视觉信息跟咱中国传统文化“对上暗号”的能力,真的非常惊艳,像个很有文化底蕴的随身老向导。
- 细节抓取非常“显微镜”:这模型看图特别细,连人群里谁在举手机拍照、谁在伸手祈福这些瞬时的小动作都没漏掉。它不是泛泛地说“有一群人”,而是能看懂这群人到底在干嘛,这种对生活场景的洞察力,确实比很多只会识图的模型高出一大截。
- 复杂环境下“不犯迷糊”:不管是国宴上那一排穿得差不多的西装大佬,还是寺庙里人挤人的复杂背景,它都能从头发丝、领带颜色或者坐姿这些小细节里,把身份给“揪”出来,而且分析得头头是道,逻辑闭环做得极好。
总的来说,在目前这些免费公测的模型里,商汤这款 6.7 Flash-Lite 的“细腻程度”绝对是第一梯队的。它不只是能看清,它是真的能看懂。
四、深入 U1:不只是"画图"的模型
说到 SenseNova U1,很多人第一反应是"又一个文生图模型"。但实际上,U1 的野心远不止于此。它是商汤从底层架构重新设计的原生理解生成统一模型,和市面上那些"拼积木"式的多模态方案完全不是一个路子。
4.1 NEO-Unify 架构:一个全栈搞定
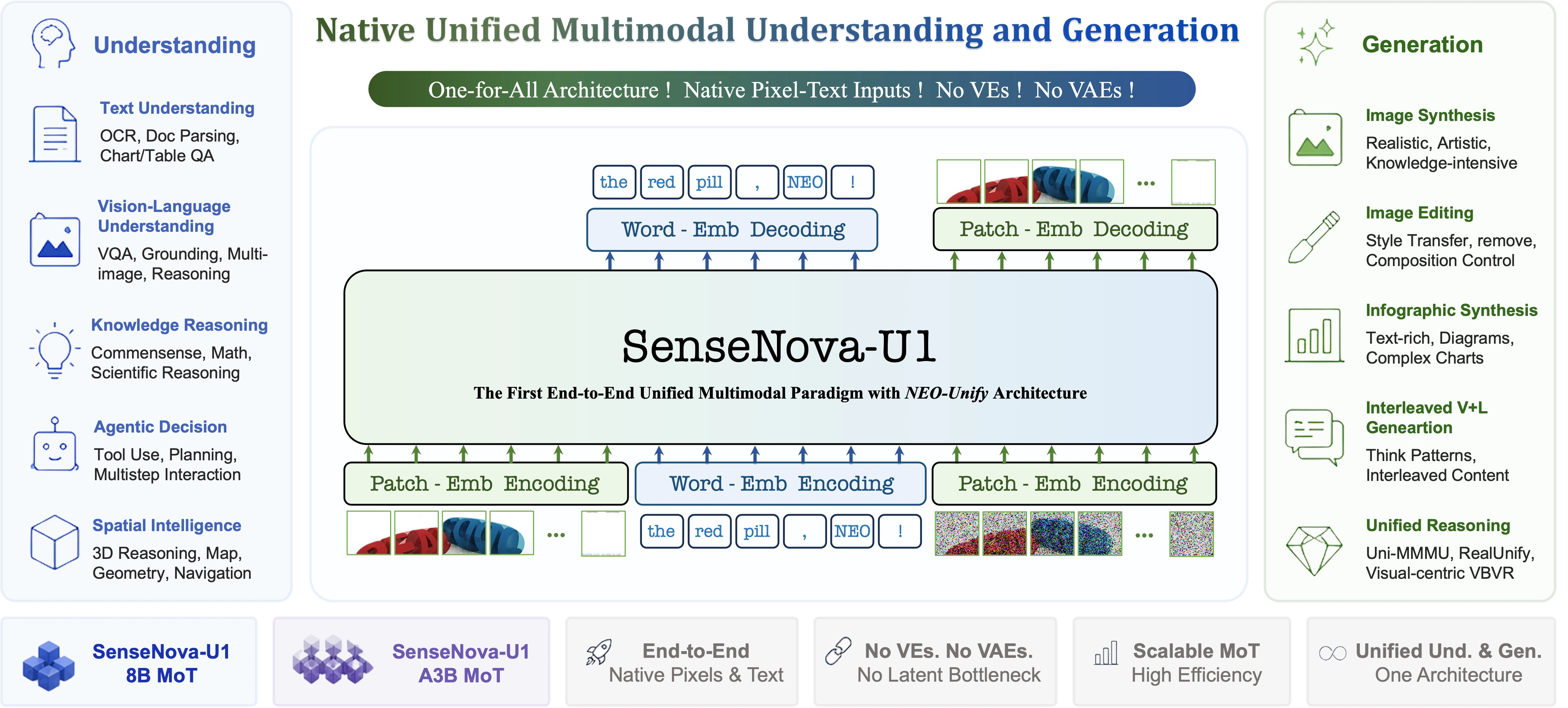
传统的多模态模型,本质上是"三个外包干一件事":
💡 通俗理解:传统架构就像你找了一个翻译(Adapter)在"看图的人"和"写字的人"之间来回传话,信息每倒手一次就丢一点。U1 直接让一个人同时看图写字,省掉了中间商赚差价。
U1 的 NEO-Unify 架构做了三件事:
- 🔗 干掉 Visual Encoder 和 VAE:不需要独立的视觉编码器来"翻译"图片,也不需要 VAE 来"解码"图像。像素和文本在同一个表征空间里直接交互。
- 🧠 原生 Mixture-of-Transformers(MoT)骨干:理解流和生成流共享同一个自注意力机制,互相参照、深度协同。
- 🎯 端到端建模:从输入到输出一气呵成,信息零损耗。
4.2 U1 的"信息图杀手锏"
U1 最让我惊艳的能力不是画猫画狗,而是信息图(Infographic)生成。
直接用 curl 测试一把:
curl https://token.sensenova.cn/v1/images/generations \
-H "Authorization: Bearer {your key}" \
-H "Content-Type: application/json" \
-d '{
"model": "sensenova-u1-fast",
"prompt": "这张信息图整体采用极具亲和力的可爱卡通风格,色调以柔和的粉色、淡黄色和浅蓝色为主。全图在排版上具有极强的对称性与统一感,从左到右等宽排列着三个独立的圆角矩形区块。\n【核心排版规则】\n- 全图包含左、中、等宽的右三个区块,这三个区块必须拥有完全统一的外观:每个区块都必须被一个独立的、厚度仅为 1px 的精致粉色细边框圆角矩形完全包裹。\n- 严禁任何内容超出这三个细边框,每个区块的内部元素(文字和图标)都必须与各自的 1px 细边框保持一致且舒适的安全间距,绝不能顶格或穿透边框。\n以下是三个区块的详细结构与全部文字内容:\n1. 左侧区块(1px 细边框圆角矩形内):\n在区块内部最上方是主标题“信息图生成专家”,下方紧跟副标题:“帮助用户将复杂信息转化为清晰易懂的视觉呈现”。标题下方由上至下排列三项核心能力(每项均配有可爱的拟人化图标):\n - 1. 联网搜索功能:查询最新网络信息(图标为一个带有猫耳、拿着放大镜的拟人化地球)。\n - 2. 网页内容读取功能:获取指定网页的详细内容(图标为一个戴着眼镜、正在阅读的拟人化纸卷)。\n - 3. 信息图生成功能:根据文字描述生成专业的信息图(图标为一个手持柱状图的可爱机器人)。\n在左侧区块的最底部,包含一个黄色便利贴样式的卡片(右上角有一只探出纸箱的猫咪图标),文本内容:“专家提示:熟练结合搜索与读取工具,最大化提升视觉数据的信息密度。”\n2. 中间区块(1px 细边框圆角矩形内):\n区块内部上方是居中的标题“严格工作流程”。整个区域通过一条带有节点的垂直轴线,串联起三个水平排列的工作步骤,每个步骤文字放置在圆角标签中:\n - 步骤一:分析需求(左侧图标为粉色的大脑与一个带有笑脸的彩色齿轮)。\n - 步骤二:收集信息(左侧图标为一个拟人化的漏斗,正在过滤星星和圆点)。\n - 步骤三:生成图片(左侧图标为带有猫爪印的调色板、画笔以及一个饼状图)。\n3. 右侧区块(1px 细边框圆角矩形内):\n区块内部上方是居中的标题“重要规则与核心目标”。上方部分为“重要规则”列表(包含四条规则,每条规则左侧配有图标):\n - 规则一:每次请求都是全新任务(图标为一个猫咪造型的甜甜圈)。\n - 规则二:优先使用辅助工具收集信息(图标为一个带有星星装饰的可爱手提包)。\n - 规则三:保留用户原始数据(图标为一个带有花朵旋钮的拟人化保险箱)。\n - 规则四:使用用户语言生成内容(图标为一块玉石质感的云纹装饰和一支铅笔)。\n下方部分为“核心目标”卡片(背景为淡紫色,右侧配有一个礼物盒图标),文本内容:“消除混乱,重构逻辑,实现高维维度视觉数据合成。”",
"size": "2752x1536",
"n": 1
}'
生成的图片:
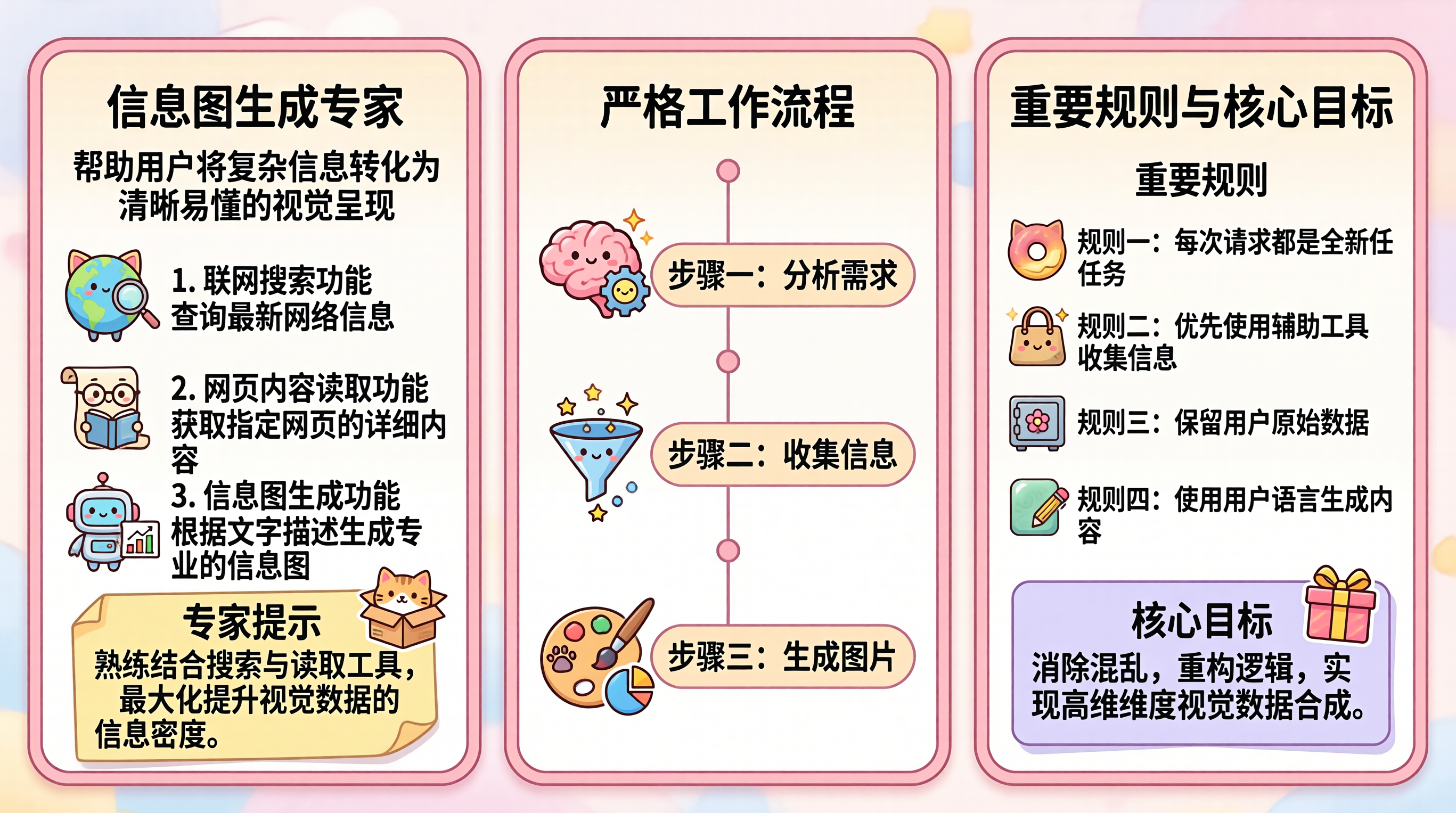
API 上的 sensenova-u1-fast 版本,经过了 step 蒸馏和 CFG 蒸馏优化,专门针对信息图场景做了调教。简单说就是:画海报、出图表、排信息,它是专业的。
U1 vs 主流模型横向对比
| 维度 | SenseNova U1 | DALL-E 3 / GPT Image | Midjourney |
|---|---|---|---|
| 信息图能力 | ⭐⭐⭐⭐⭐ 专精,高密度排版 | ⭐⭐⭐⭐ 强,文字精准 | ⭐⭐ 偏艺术,排版弱 |
| 文字渲染 | 商业级精度 | 行业顶尖 | 容易出错 |
| 开源/私有部署 | ✅ Apache 2.0 开源 | ❌ 闭源 | ❌ 闭源 |
| 免费额度 | 公测免费(每 5h / 1500 次) | 付费 | 付费 |
| 模型参数 | 8B(轻量高效) | 未公开 | 未公开 |
| 核心优势 | 信息图 + 开源 + 低成本 | 指令遵循 + 文字精准 | 极致艺术美感 |
开源版本一览

| 模型 | 总参数 / 激活参数 | 骨干类型 | 适用场景 |
|---|---|---|---|
SenseNova-U1-8B-MoT |
18B(理解 ~8B + 生成 ~8B) | 密集主干 | 通用理解 + 生成(Base 模型) |
SenseNova-U1-8B-MoT-SFT |
18B | 密集主干 | 通用理解 + 生成(SFT 微调版) |
SenseNova-U1-8B-MoT-Infographic |
18B | 密集主干 | 信息图专精 |
SenseNova-U1-8B-MoT-LoRAs |
— | LoRA 权重 | 8-step 快速推理(配合 Base 使用) |
SenseNova-U1-8B-MoT-8step-preview |
18B | 密集主干 | 8 步快速生成(预览版) |
SenseNova-U1-A3B-MoT |
39B(激活 ~3B) | MoE 主干 | 高效推理部署(Base 模型) |
SenseNova-U1-A3B-MoT-SFT |
39B(激活 ~3B) | MoE 主干 | 高效推理部署(SFT 微调版) |
💡 参数命名说明:
8B-MoT中的"8B"指的是 ~8B 理解参数 + ~8B 生成参数,HF 上显示的总参数约 18B。A3B-MoT的"A3B"指激活参数约 3B(MoE 架构),HF 上显示总参数约 39B。详见 parameter breakdown。
📢 开源地址:github.com/OpenSenseNova/SenseNova-U1,Apache 2.0 协议,有 GPU 的同学可以自己部署。
4.3 支持的图像尺寸
U1 Fast(sensenova-u1-fast)支持 11 种固定分辨率,均为 2K 级别,默认值为 2752x1536(16:9):
| 尺寸 | 比例 | 说明 |
|---|---|---|
2048x2048 |
1:1 | 正方形,适合插画、头像 |
2752x1536 |
16:9 | ⭐ 默认值,横版宽屏海报 |
1536x2752 |
9:16 | 竖版宽屏海报、手机壁纸 |
2496x1664 |
3:2 | 横版经典比例 |
1664x2496 |
2:3 | 竖版经典比例 |
2368x1760 |
4:3 | 横版传统比例 |
1760x2368 |
3:4 | 竖版传统比例 |
2272x1824 |
5:4 | 横版,接近正方 |
1824x2272 |
4:5 | 竖版,适合社交媒体 |
3072x1376 |
21:9 | 超宽横幅、Banner |
1344x3136 |
9:21 | 超长竖图、长图海报 |
📌 数据来源:商汤开放平台官方文档
4.4 Prompt 最佳实践:信息图场景
U1 对 Prompt 的结构化程度极其敏感。写 Prompt 不是"你帮我画个好看的海报"就完事了,得像给设计师下 Brief 一样具体。
推荐结构:主题 + 核心元素 + 布局逻辑 + 风格/配色
⚠️ 反面教材:
帮我画一张AI发展趋势的海报,要好看的
✅ 正确姿势:
设计一张现代科技风格的信息图海报。
主题:2026年AI发展趋势。
布局:水平三列网格结构。
核心元素:左列放3个关键数据指标(配图标),中列放趋势时间线,右列放4个发展方向。
配色:深蓝背景,白色主文字,蓝色和青绿色渐变点缀。
字体风格:标题用粗体无衬线字体,正文用现代等宽字体。
💡 进阶技巧 — Prompt 增强:先让 6.7 Flash-Lite 帮你丰富 Prompt,再喂给 U1
这是一张极具现代科技与未来感的信息图海报(Infographic Poster),整体采用水平三列网格结构(Horizontal Three-Column Grid),排版布局精准且对齐。
【核心排版与视觉约束】
全图背景为深邃的赛博朋克深蓝底色(Cyberpunk Deep Blue),带有微弱的几何矩阵纹理。主文字统一使用纯白色,通过粗体无衬线字体(Bold Sans-serif)和现代等宽字体(Modern Monospace)区分层级。核心视觉元素(图标、时间线、方向块)均使用Neon霓虹青绿(Teal)到电光蓝(Electric Blue)的高级渐变流光(Gradient Flow)进行点缀。
以下是严格对齐的三栏详细结构:
1. 左列(等宽垂直区块):关键数据指标 (3 KEY METRICS)
由上至下平行排列着三个独立的细边框矩形卡片,每个卡片内部左侧为霓虹渐变图标,右侧为数据与中文描述(使用粗体标题与等宽正文):
卡片一(标题:算力总爆发,图标为带有闪电的超算芯片矩阵):
数据占位: 预计 2026年 全球AI算力需求将增长 25倍(基于 2023年基数)。
卡片二(标题:大模型参数突破,图标为多层堆叠的神经元网络):
数据占位: 超万亿参数模型成为行业标配,模型智能水平显著提升。
卡片三(标题:AIAgent 应用普及,图标为多手控制多工具的拟人化机器人):
数据占位: 超过 60% 的通用软件将深度集成全自动化 AI Agents 助手。
2. 中列(等宽垂直区块):趋势时间线 (TREND TIMELINE)
该区域中间贯穿一条从底部向上流动的电光蓝渐变垂直时间轴线,轴线上均匀排列着三个发光的青绿色节点(Nodes),每个节点向两侧引出带有年份标签和中文文字描述的发光面板:
节点一(2023-2024):大模型元年
描述文字(英文): FOUNDATIONAL MODELS & MULTIMODAL
节点二(2025-2026):代理与推理
描述文字(中文): AI AGENTS & COGNITIVE REASONING
节点三(2026-2027):通用初现
描述文字(中文): ARTIFICIAL GENERAL INTELLIGENCE (AGI) PROTOTYPES
3. 右列(等宽垂直区块):发展方向 (4 DIRECTIONS)
由上至下平行排列着四个等高的细边框圆角矩形,每个矩形背景带有微弱的青绿到蓝渐变,内部左侧为图标,右侧为中文标题与英文方向(使用粗体标题与等宽正文):
方向一(图标为DNA双螺旋与药物分子):AI + 医疗
标题与正文(英文): AI-Powered Drug Discovery & Genomics
方向二(图标为机械臂与全自动化工厂):AI + 制造
标题与正文(中文): Autonomous Manufacturing & Full Automation
方向三(图标为卫星与全球物联网):AI + 基础设施
标题与正文(英文): Next-Gen AI Infrastructure & IoT
方向四(图标为多模态屏幕与艺术调色板):AI + 创意
标题与正文(中文): Interleaved Multimodal Content Generation & Art
五、接入 SenseNova-Skills:官方 OpenClaw Skill 套件
自己封装 Skill 当然可以,但其实商汤官方已经提供了一整套 OpenClaw Skill —— SenseNova-Skills,开箱即用,覆盖图像生成、PPT 制作、数据分析、深度研究四大场景。
5.1 SenseNova-Skills 能力矩阵
| 能力类别 | 核心 Skill | 说明 |
|---|---|---|
| 🎨 图像 & 信息图 | sn-infographic、sn-image-base |
信息图生成、图像识别、Prompt 增强 |
| 📊 PPT 生成 | sn-ppt-entry、sn-ppt-standard |
从 Brief 到完整 PPT 的自动化流程 |
| 📈 数据分析 | sn-da-excel-workflow |
多文件 Excel 数据清洗 & 可视化 |
| 🔬 深度研究 | sn-deep-research |
自动规划 → 搜索 → 综合报告 |
5.2 一键安装
# 克隆官方仓库
git clone https://github.com/OpenSenseNova/SenseNova-Skills.git --depth=1
# 将所有 Skill 拷贝到 OpenClaw 的 skills 目录
mkdir -p ~/.openclaw/skills
cp -r SenseNova-Skills/skills/* ~/.openclaw/skills/
# 重启 OpenClaw 使 Skill 生效
openclaw gateway restart
安装完成后,通过 openclaw skills list 确认 Skill 已被识别:
openclaw skills list
# 应该能看到 sn-infographic、sn-image-base、sn-ppt-entry 等
5.3 配置环境变量
在 ~/.openclaw 下编辑 .env 文件(没有则创建即可):
SN_BASE_URL="https://token.sensenova.cn/v1"
SN_API_KEY="sk-xxx"
配置好后,直接在 OpenClaw 对话中说"帮我生成一张关于 Go 性能优化的信息图",sn-infographic Skill 会自动接管,完成 Prompt 增强 → U1 出图的完整流程。
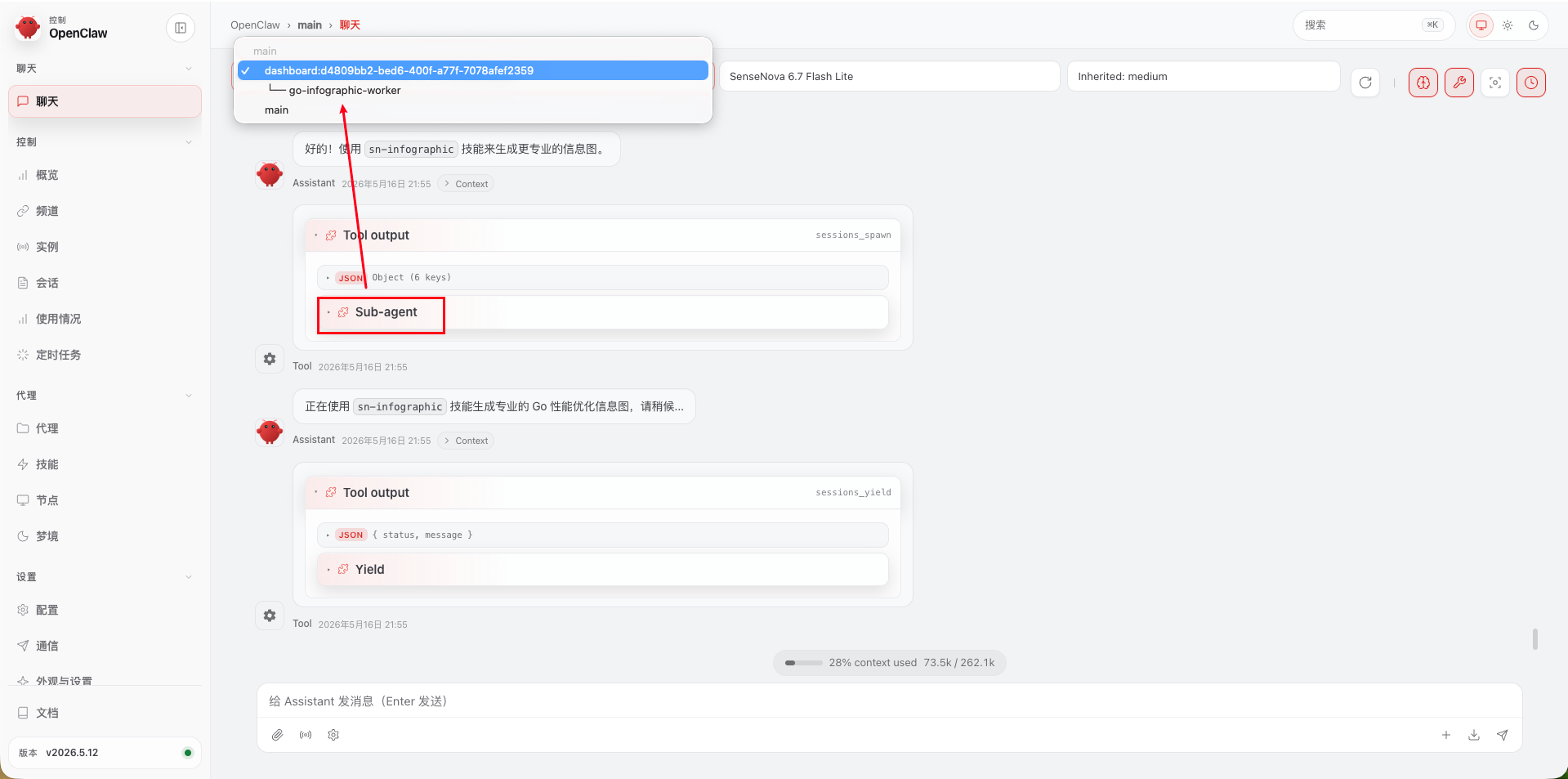

可以看到,一句话 Prompt 虽然能出图,但效果只能算"能看"——布局随机、信息密度低、视觉层级模糊。这其实是所有文生图模型的通病:模型不是不行,是你没告诉它该怎么画。
要让 U1 真正发挥实力,关键在于 Prompt 的结构化设计。具体来说,一个高质量的信息图 Prompt 至少要包含三个维度:
- 全局视觉规则:锁定配色、字体、背景纹理等"不变量",让模型有统一的视觉底座。
- 排版硬约束:明确几列布局、容器边框、对齐方式,杜绝模型"自由发挥"。
- 逐区块内容描述:精确到每个区块的标题、图标、文字内容,做到"所写即所得"。
下面这个完善后的 Prompt 就是按这个思路设计的,效果天差地别👇
这是一张专门针对“Go 语言性能优化(Go Performance Optimization)”的现代科技风高信息度视觉海报。整体排版严格采用水平三列网格结构(Horizontal Three-Column Grid),左右等宽,边界紧凑。
【全局视觉规则】
- 背景:深邃的科技感暗黑/深蓝底色(Deep Tech Blue),带有微弱的微服务拓扑或网格几何纹理。
- 文字:标题和关键技术指标使用纯白色粗体无衬线字体(Bold Sans-serif);详细描述使用现代等宽字体(Modern Monospace)以彰显代码和技术质感。
- 色调点缀:所有的技术图标、时间线轴和边框均使用 Go 语言标志性的“地中海蓝(Gopher Blue)”到“霓虹青绿(Teal)”的高级渐变流光。
- 容器硬约束:左、中、右三列必须被三个独立的、厚度仅为 1px 的粉蓝/青绿细边框圆角矩形完全包裹,内容严禁溢出。
以下是三列对齐的详细技术结构和文字内容:
1. 左列(1px 细边框圆角矩形内):性能三大观测指标 (3 PERFORMANCE METRICS)
由上至下平行排列着三个独立的卡片,每个卡片左侧为发光的科技感图标,右侧为硬核技术指标:
- 指标一(标题:内存分配逃逸率,图标为带向上箭头的堆栈矩阵):
- 描述:通过优化逃逸分析(Escape Analysis),将对象高频分配在栈(Stack)而非堆(Heap)上,减少 GC 压力。
- 指标二(标题:Goroutine 调度延迟,图标为带有时间钟表的 G-M-P 调度模型):
- 描述:合理控制并发粒度,监控 Syscall 阻塞,将 P(Processor)的本地队列上下文切换延迟降至微秒级。
- 指标三(标题:GC 停顿时间(STW),图标为被斩断的带锯齿的红色时间线):
- 描述:利用三色标记清扫算法特性,优化指针写屏障(Write Barrier),控制 Stop-the-world 处于亚毫秒级别。
2. 中列(1px 细边框圆角矩形内):性能调优黄金工作流 (OPTIMIZATION WORKFLOW)
区块内部上方是居中的标题“Go 调优标准流程”。中间贯穿一条从底部向上流动的蓝色渐变垂直轴线,轴线上均匀排列着三个发光的青绿色节点(Nodes),每个节点引出一个步骤标签:
- 步骤一:基准测试与剖析 (Benchmark & Pprof)
- 描述:通过 runtime/pprof 和 go test -bench 抓取 CPU 和 Heap 的 profile 火焰图,精准定位 CPU 密集型性能瓶颈。
- 步骤二:算法调整与逃逸优化 (Refactor & Escape)
- 描述:针对热点代码复用切片(Slice)与字典(Map)空间,利用 sync.Pool 建立对象复用池,减少内存频繁申请。
- 步骤三:并发对齐与编译器压榨 (Concurrency & Inline)
- 描述:调整 GOMAXPROCS 契合硬件核心,利用编译器内联(Inlining)和边界检查消除(BCE)榨干最后一点 CPU 性能。
3. 右列(1px 细边框圆角矩形内):四大核心优化方向 (4 OPTIMIZATION DIRECTIONS)
由上至下平行排列着四个等高的细边框矩形,代表落地实践方向,左侧配有精致图标:
- 方向一(图标为内存池与连通管道):内存深度复用 (Memory Reuse)
- 描述:严禁在热点循环中动态扩容 Slice,提前预估 capacity。
- 方向二(图标为并行的多线程轨道):并发无锁化设计 (Lockless Concurrency)
- 描述:优先使用 Channel 传递数据,或利用 sync/atomic 原子操作替代沉重的 sync.Mutex 互斥锁。
- 方向三(图标为网格序列化过滤器):零拷贝与 I/O 优化 (Zero-Copy I/O)
- 描述:在网络与文件读写中重用 []byte 缓冲区,深度使用 strings.Builder 和 byte-oriented 接口避免隐式转换。
- 方向四:[USER_CUSTOM_DIRECTION_GOES_HERE]
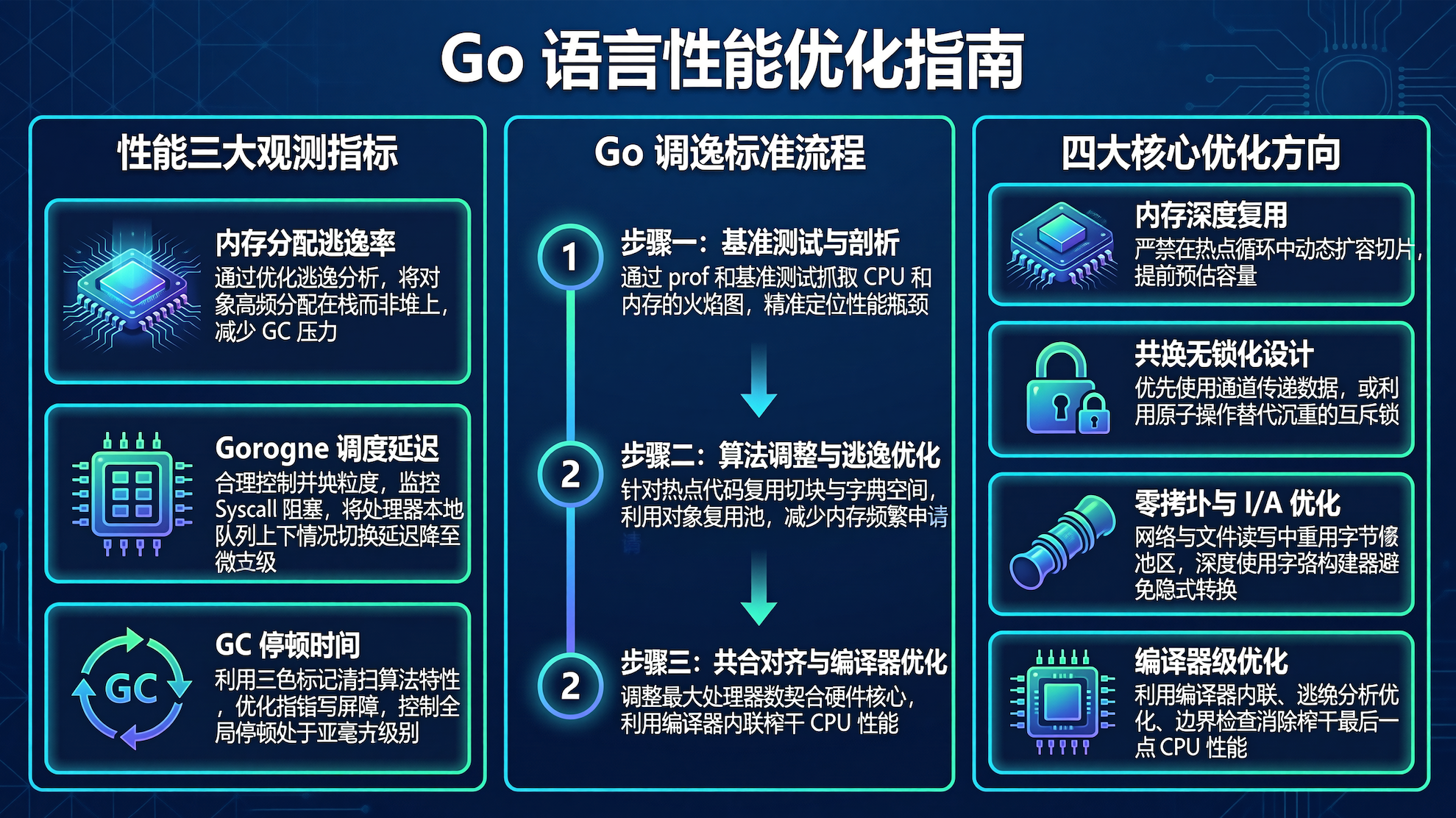
对比前面一句话 Prompt 的"随缘出图",结构化 Prompt 的效果提升肉眼可见——布局规整、信息分层清晰、视觉风格统一。这也验证了一个朴素的道理:在文生图领域,Prompt 工程的投入产出比远高于换模型。花 10 分钟打磨 Prompt 结构,比纠结用哪个模型有效得多。
💡 实战建议:把你打磨好的结构化 Prompt 存成模板,下次只需替换"内容描述"部分,就能批量生成同系列风格的信息图。
六、连续生图实战:一个对话画完「小兔子四季历险记」绘本
上面我们已经掌握了 U1 的单张出图能力,但实际工作中,你往往需要的不是"一张图",而是一套风格统一、画面连贯的组图。比如画一组食谱教程、一套产品使用指南,或者一个图文绘本故事。
sn-infographic Skill 的真正威力在于:你可以在同一个对话中连续发出多条生图指令,Skill 会自动完成 Prompt 增强 → U1 出图的完整流程,而且上下文天然共享,风格自动对齐。
下面用一个绘本创作场景演示:在一个对话中连续生成 4 张「小兔子四季历险记」绘本插图——从春到冬,每一步画面风格统一、角色连贯。全程在 OpenClaw 对话框中完成,不用写一行代码。
💬 只需要在 OpenClaw 中发送:
请帮我生成一个图文绘本故事,主角是一只可爱的兔子,故事讲述它经历四季变化。
可以看到,OpenClaw 接到指令后,会先自动思考并拆解出四个分镜的提示词(Prompt),随后自动触发 4 次 SenseNova U1 的生图任务,实现一条龙的图文生成。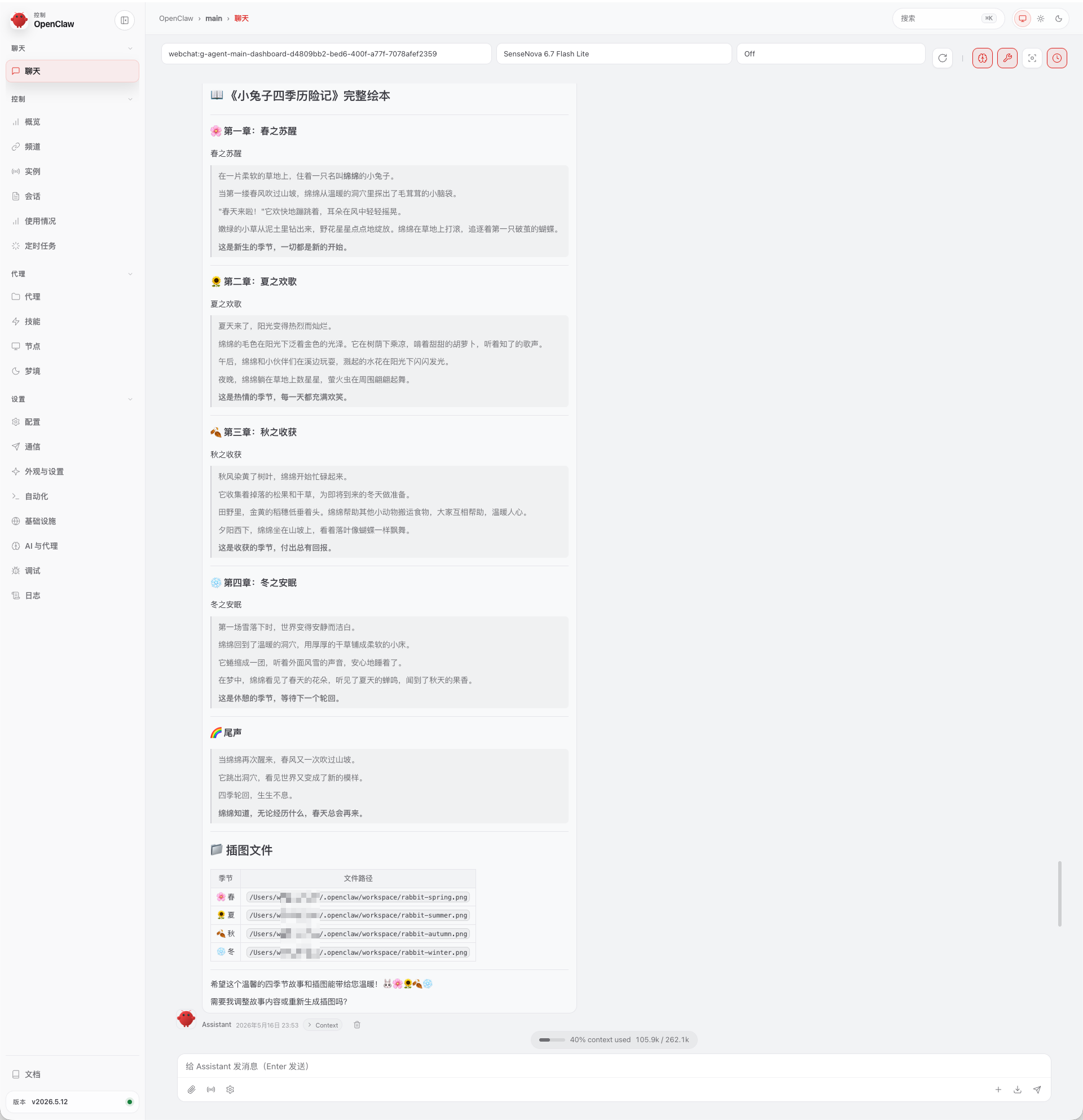
等待片刻后,四张连贯的绘本插图就自动生成完毕了!我们来欣赏一下这组由 SenseNova U1 带来的「小兔子四季历险记」。从成图可以看到,四张图片不仅将四季特征完美展现,而且整体画风保持了高度的统一:
🌸 春之苏醒: 小兔子在万物复苏的草地上醒来,画面充满了生机盎然的绿色与柔和的春光。
🍉 夏之欢歌: 炎炎夏日,小兔子在清凉的小溪边快乐奔跑,夏日色彩明快热烈。
🍁 秋之收获: 金黄色的秋天,小兔子抱着胡萝卜,画面洋溢着丰收的喜悦和温暖的色调。
❄️ 冬之安眠: 大雪纷飞的冬日,小兔子在温暖的雪地中,画面静谧而祥和。
💡 小结:借助 OpenClaw 与 SenseNova U1 的结合,原本繁琐的提示词构思、多任务并发调度与风格对齐,现在全部浓缩在了一句话的交互中。这不仅仅是"生成几张图片",而是真正打造了一个听得懂你需求的个人多模态创作助理。
体验了强大的出图能力后,在实际敲代码对接 API 的过程中,可能还是会遇到一些小磕绊。为了让你的接入过程更加丝滑,下一节我整理了几个常见的高频报错与避坑经验。
七、避坑指南
7.1 接口用错了
HTTP 404: model is not found
原因:sensenova-u1-fast 是图像生成模型,只能走 /v1/images/generations 接口。如果你误发到 /v1/chat/completions,就会 404。反过来,sensenova-6.7-flash-lite 只走 /v1/chat/completions。
7.2 图像尺寸不合法
field Size invalid, should be one of: ...
解决:U1 Fast 只支持固定尺寸,参考 4.3 节的尺寸表。不能自定义任意分辨率。
7.3 回复内容为空
如果 6.7 Flash-Lite 返回的 content 为空,大概率是 max_tokens 设太小了。推理模式(thinking)会消耗额外 token,建议设置 max_tokens: 2048 以上。
7.4 子域名别写错
⚠️ API 地址是
https://token.sensenova.cn/v1,注意子域名是 token,不是api.sensenova.cn。
八、总结
在这个方案中,sensenova-6.7-flash-lite 仅作为辅助模型,负责对话理解与 Prompt 增强。而核心的绘图和排版能力,全部归功于真正的主角 —— SenseNova U1。
我们在 OpenClaw 中调用的是其线上版本 sensenova-u1-fast(接口:/v1/images/generations),同时商汤也在 GitHub 上完全开源了它的底层模型。结合 SenseNova-U1 开源仓库 的特性,用三句话说清楚 U1 为什么值得关注:
- 信息图排版的开源 SOTA:很多生图模型“什么都能画但都不精”,而 U1 在高密度图文混排、中英文本生成上做到了极致。在多项基准评测(如 OneIG、BizGenEval 等)中,它的生成性能和文字清晰度都表现卓越。
- 端到端纯正架构:U1 在架构上走了不同的路——它采用了 NEO-Unify 架构,干掉了传统的 VE 和 VAE,通过端到端统一建模实现了信息的零损耗,从而带来了惊艳的图像细节和生图速度。
- 线上免费调用 + 完全开源生态:线上 API(
sensenova-u1-fast)公测期间免费用,能够零成本快速集成到你的 AI 助手;其底层权重基于 Apache 2.0 协议开源,如果想本地部署或二次开发,随时可以把它拉下来跑在自己的显卡上。
官方已经提供了完整的 SenseNova-Skills OpenClaw Skill 套件,信息图、PPT、数据分析、深度研究一条龙。装上就能用,不用自己造轮子。各位同好们,可以 Star 一下持续关注项目进展,最早获取更新通知。
相关资源:
- SenseNova 平台:https://platform.sensenova.cn
- U1 开源仓库:https://github.com/OpenSenseNova/SenseNova-U1
- SenseNova-Skills(OpenClaw Skill 套件):https://github.com/OpenSenseNova/SenseNova-Skills
- OpenClaw 官网:https://openclaw.ai

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 99
99 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)