langchain从入门到精通(二十二)——语义文档分割器与其他文档分割器的使用
字符文本分割器、递归字符文本分割器、Html标题/段分割器、语义分割器固定大小分块:这是最常见的分块方法,通过设定块的大小和是否有重叠来决定分块。这种方法简单直接,不需要使用任何NLP库,因此计算成本低且易于使用,例如 CharacterTextSplitter,亦或者直接循环遍历固定大小拆分。基于结构的分块:常见的 HTML、MARKDOWN 格式,或者其他可以有明确结构格式的文档。
1. 语义文档分割器的使用与背景
在前面使用的文档分割器都是使用 特定字符 对文本进行拆分,这种拆分模式虽然考虑了文档中的上下文切断的问题,但是并没有考虑句子之间的语义相似性,如果有一篇长文本,需要将其分割成语义相关的块,以便更好地理解和处理,这个时候可以使用 LangChain 中的 语义相似性分割器SemanticChunker来实现这个任务。
语义相似性分割器 目前仍处于实验性,这个类目前位于 langchain_experimental 包中(这个包中的类与方法未来极大概率会发生变更,需要谨慎使用),安装命令:
pip install -Uq langchain_experimental
SemanticChunker在使用上和其他的文档分割器存在一些差异,并且该类并没有继承 TextSplitter,实例化参数含义如下:
embeddings:文本嵌入模型,在该分类器底层使用向量的 余弦相似度 来识别语句之间的相似性。buffer_size:文本缓冲区大小,默认为 1,即在计算相似性时,该文本会叠加前后各 1 条文本,如果不够则不叠加(例如第 1 条和最后 1 条)。add_start_index:是否添加起点索引,默认为 False。breakpoint_threshold_type:断点阈值类型,默认为 percentile 即百分位breakpoint_threshold_amount:断点阈值金额/得分。number_of_chunks:分割后的文档块个数,默认为 None。sentence_split_regex:句子切割正则,默认为 (?<=[.?!])\s+,即以英文的点、问号、感叹号切割语句,不同的文档需要传递不同的切割正则表达式。
例如想要将 科幻短篇.txt 按照语义切割成 10 个文档,可以使用如下代码示例:
import dotenv
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
# 1.构建加载器和文本分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = SemanticChunker(
embeddings=OpenAIEmbeddings(model="text-embedding-3-small"),
sentence_split_regex=r"(?<=[。?!])",
number_of_chunks=10,
)
# 2.加载文本与分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据: {chunk.metadata}")
输出内容:
块大小: 201, 元数据: {'source': './科幻短篇.txt'}
块大小: 25, 元数据: {'source': './科幻短篇.txt'}
块大小: 31, 元数据: {'source': './科幻短篇.txt'}
块大小: 46, 元数据: {'source': './科幻短篇.txt'}
块大小: 203, 元数据: {'source': './科幻短篇.txt'}
块大小: 19, 元数据: {'source': './科幻短篇.txt'}
块大小: 91, 元数据: {'source': './科幻短篇.txt'}
块大小: 466, 元数据: {'source': './科幻短篇.txt'}
块大小: 116, 元数据: {'source': './科幻短篇.txt'}
块大小: 0, 元数据: {'source': './科幻短篇.txt'}
SemanticChunker 的原理其实非常简单,核心思想是将文档拆分成独立的每一句,接下来根据传递的缓冲大小前后拼接字符串,然后计算拼接后的新字符串的文本嵌入/向量,然后计算这些文本的相似度,并根据传入的分块数+断点类型计算得到一个阈值,最后将相似度超过某个阈值的合并到一起,从而实现相似度分割。 目前在 SemanticChunker 底层检测相似度阈值的方法有 4 种:百分位数(默认)、标准差、四分位数、梯度。
在 LangChain 中除了 SemanticChunker 这种基于 Embedding 的语义分割器,还提供了 3 种基于自然语言处理的语义分割器:
NLTKTextSplitter:NLTK(The Natural Language Toolkit)是一套用 Python 编程语言编写的用于英语符号和统计自然语言处理(NLP)的库和程序。SpacyTextSplitter:spaCy 是一个用于高级自然语言处理的开源软件库,使用 Python 和 Cython 编程语言编写。SentenceTransformersTokenTextSplitter:用于句子转换器模型的文本拆分器。默认行为是将文本拆分3为适合您想要使用的句子转换模型的标记窗口的块。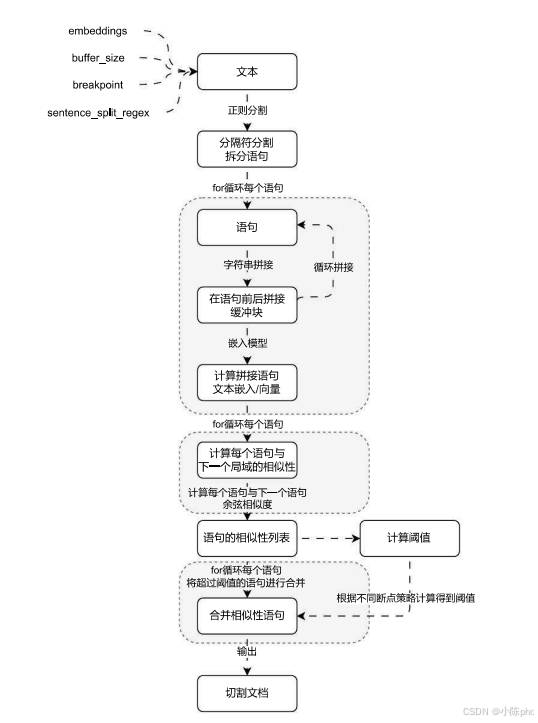
2. 其他文档分割器的使用
除了上述的文档分割器,在 LangChain 中还封装了一些其他场合下的分割器(使用频率不高),涵盖了:基于 HTML 标题/段的分割器、Markdown 标题分割器、递归 JSON 分割器、基于 Token 计数的分割器等,使用起来和字符文本分割器非常接近。
LangChain 文档分割器翻译文档:https://imooc-langchain.shortvar.com/docs/how_to/#文本分割器
2.1 HTML/Markdown 标题与段分割器
在 LangChain 中设计了针对 HTML 类型文档的分割器——HTMLHeaderTextSplitter 与 HTMLSectionSplitter,分割器的作用如下:
- HTMLHeaderTextSplitter:在 HTML 文档中按照元素级别进行分割,查找出每一块文本的内容与其所有关联的标题,并为每个相关的标题块提供元数据(顺序往上逐层查找,直到找到所有嵌套层级的标题)。
- HTMLSectionSplitter:在 HTML 文档中按照元素级别进行分割,查找出每一块文本的内容及其副标题(顺序往上查找,找到最近的副标题则停止)。
理解起来其实也非常简单,层级关系并不是嵌套,而是看目录导航,例如在课件的左侧可以看到对应的导航,分别是一级标题、二级标题和三级标题,这块内容在哪个标题内下使用,就可以看成是被嵌套到哪个标题下,和实际的 HTML 层级没有任何关系。
如下,红圈的部分被嵌套的 语义文档分割器与其他文档分割器的使用-02. 其他文档分割器的使用-2.1 HTML/Markdown 标题/段分割器 下。
使用示例:
from langchain_text_splitters import HTMLHeaderTextSplitter
html_string = """
<!DOCTYPE html>
<html>
<body>
<div>
<h1>标题1</h1>
<p>关于标题1的一些介绍文本。</p>
<div>
<h2>子标题1</h2>
<p>关于子标题1的一些介绍文本。</p>
<h3>子子标题1</h3>
<p>关于子子标题1的一些文本。</p>
<h3>子子标题2</h3>
<p>关于子子标题2的一些文本。</p>
</div>
<div>
<h3>子标题2</h2>
<p>关于子标题2的一些文本。</p>
</div>
<br>
<p>关于标题1的一些结束文本。</p>
</div>
</body>
</html>
"""
headers_to_split_on = [
("h1", "一级标题"),
("h2", "二级标题"),
("h3", "三级标题"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits)
输出内容
[
Document(page_content='标题1'),
Document(metadata={'一级标题': '标题1'}, page_content='关于标题1的一些介绍文本。 \n子标题1 子子标题1 子子标题2'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1'}, page_content='关于子标题1的一些介绍文本。'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1', '三级标题': '子子标题1'}, page_content='关于子子标题1的一些文本。'),
Document(metadata={'一级标题': '标题1', '二级标题': '子标题1', '三级标题': '子子标题2'}, page_content='关于子子标题2的一些文本。'),
Document(metadata={'一级标题': '标题1'}, page_content='子标题2'),
Document(metadata={'一级标题': '标题1', '三级标题': '子标题2'}, page_content='关于子标题2的一些文本。'),
Document(metadata={'一级标题': '标题1'}, page_content='关于标题1的一些结束文本。')
]
另外在 LangChain 中除了 HTML 类型的文档可以使用这套分割规则,Markdown 类的文件也有类似的分割规则,可以使用 Markdown 标题分割器—— MarkdownHeaderTextSplitter 完成同样的文档分割。
详细文档:https://imooc-langchain.shortvar.com/docs/how_to/markdown_header_metadata_splitter/
2.2 递归 JSON 分割器
对于 JSON 类的数据,在 LangChain 中也封装了一个递归 JSON 分割器——RecursiveJsonSplitter,这个分割器会按照深度优先的方式遍历 JSON 数据,并构建较小的 JSON 块,而且尽可能保持嵌套 JSON 对象完整,但如果需要保持文档块大小在最小块大小和最大块大小之间,则会将它们拆分。
在 JSON 数据中,如果值不是嵌套的 JSON,而是一个非常大的字符,则不会对该字符串进行拆分,可以配合 递归字符文本分割器 强制性拆分字符串,确保块大小在限制的范围内。
RecursiveJsonSplitter 的参数非常简单,只需传递 max_chunk_size 和 min_chunk_size(可选) 即可。
例如这里有一个很大的 json 文本(https://api.smith.langchain.com/openapi.json),使用递归 JSON 分割器对其进行拆分,如下:
import requests
from langchain_text_splitters import RecursiveJsonSplitter
# 1.获取并加载json
url = "https://api.smith.langchain.com/openapi.json"
json_data = requests.get(url).json()
# 2.递归JSON分割器
text_splitter = RecursiveJsonSplitter(max_chunk_size=300)
# 3.分割json数据并创建文档
json_chunks = text_splitter.split_json(json_data=json_data)
chunks = text_splitter.create_documents(json_chunks)
for chunk in chunks[:3]:
print(chunk)
输出内容
page_content='{"openapi": "3.1.0", "info": {"title": "LangSmith", "version": "0.1.0"}, "paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracer-sessions"], "summary": "Read Tracer Session", "description": "Get a specific session."}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"operationId": "read_tracer_session_api_v1_sessions__session_id__get", "security": [{"API Key": []}, {"Tenant ID": []}, {"Bearer Auth": []}]}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"parameters": [{"name": "session_id", "in": "path", "required": true, "schema": {"type": "string", "format": "uuid", "title": "Session Id"}}, {"name": "include_stats", "in": "query", "required": false, "schema": {"type": "boolean", "default": false, "title": "Include Stats"}}, {"name": "accept", "in": "header", "required": false, "schema": {"anyOf": [{"type": "string"}, {"type": "null"}], "title": "Accept"}}]}}}}'
RecursiveJsonSplitter 分割器的运行流程其实也非常简单,这个分割器会按照 深度优先 的方式遍历整个 JSON,即一层一层往下读取数据,然后将对应的数据提取生成一个新的 JSON,直到数据大小接近块大小(极端情况下还是会超过预设的块大小,例如 JSON 数据中的 Key 很长,亦或者 Value 很长,甚至出现单条数据就超过了预设大小)。
所以如果要使用该分割器,一般会结合 RecursiveCharacterTextSplitter 降低单条数据超过预设大小的风险,思路就是将递归 JSON 分割器生成的文档列表进行二次分割。
2.3 基于标记的分割器
对于大语言模型来说,上下文的长度计算应该通过 token 进行计算,而不是通过字符长度 len() 函数,在 OpenAI 的 GPT 模型中,一个汉字大约等于 1.5 个 Token,一个单词为 1 个 Token,所以使用 len() 函数可能会导致很大的误差。
在 LLM 应用开发中,不同的模型对于 Token 的计算并不相同,但是可以使用 tiktoken 这个包来大致计算文本的 token 数,误差也相对较小,首先安装 tiktoken 包,命令如下:
pip install -U tiktoken
接下来定义一个基于 tiktoken 的长度计算函数,如下:
def calculate_token_count(query: str) -> int:
"""计算传入文本的token数"""
encoding = tiktoken.encoding_for_model("text-embedding-3-large")
return len(encoding.encode(query))
然后将该函数传递给分割器的 length_function,例如前几节课时的案例,修改优化后,代码如下
import tiktoken
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1.定义加载器和文本分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
"。|!|?",
"\.\s|\!\s|\?\s", # 英文标点符号后面通常需要加空格
";|;\s",
",|,\s",
" ",
""
],
is_separator_regex=True,
chunk_size=500,
chunk_overlap=50,
length_function=calculate_token_count,
)
# 2.加载文档并执行分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
# 3.循环打印分块内容
for chunk in chunks:
print(f"块大小: {len(chunk.page_content)}, 元数据: {chunk.metadata}")
输出内容
块大小: 334, 元数据: {'source': './科幻短篇.txt'}
块大小: 409, 元数据: {'source': './科幻短篇.txt'}
块大小: 372, 元数据: {'source': './科幻短篇.txt'}
块大小: 95, 元数据: {'source': './科幻短篇.txt'}
在 LangChain 中,除了传递 length_function 方法,还可以直接调用分割器的类方法 from_tiktoken_encoder(来快速创建基于 tiktoken 分词器的文本分割器(确保分词器使用的模型和开发的 LLM 保持一致即可),例如
RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=500,
chunk_overlap=50,
separators=[
"\n\n",
"\n",
"。|!|?",
"\.\s|\!\s|\?\s", # 英文标点符号后面通常需要加空格
";|;\s",
",|,\s",
" ",
""
],
is_separator_regex=True,
)
- 自定义文档分割器
在 LangChain 中,如果内置的文档分割器均没办法完成需求,还可以根据特定的需求实现自定义文档分割器(一般极少),实现的方法也非常简单,继承文本分割器基类 TextSplitter,在构造函数中传递相关参数,然后实现 split_text() 方法即可。
例如,实现一个根据传递的分隔符实现对文档进行片段划分,并且将分割出来的文档片段转换成 N 个关键词的分割器,代码示例:
from typing import List
import jieba.analyse
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain_text_splitters import TextSplitter
class CustomTextSplitter(TextSplitter):
"""自定义文本分割器"""
def __init__(self, seperator: str, top_k: int = 10, **kwargs) -> None:
super().__init__(**kwargs)
self._seperator = seperator
self._top_k = top_k
def split_text(self, text: str) -> List[str]:
"""分割传入的文本为字符串列表"""
split_texts = text.split(self._seperator)
text_keywords = []
for split_text in split_texts:
text_keywords.append(
jieba.analyse.extract_tags(split_text, self._top_k)
)
return [",".join(keywords) for keywords in text_keywords]
# 1.创建加载器与分割器
loader = UnstructuredFileLoader("./科幻短篇.txt")
text_splitter = CustomTextSplitter("\n\n")
# 2.加载文档并分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)
# 3.循环遍历文档信息
for chunk in chunks:
print(f"文档库块内容:{chunk.page_content}")
生成内容:
文档库块内容:星际,穿越,标题
文档库块内容:概要
文档库块内容:星系,李昂,文明,这个,高度发达,宇航员,星际,灭绝,一个,穿越
文档库块内容:迷航,星际,第一章
文档库块内容:飞船,李昂,观察窗,浩瀚,星空,宇航员,经验丰富,星系,与众不同,穿越
文档库块内容:李昂,星空,睁开眼,眩晕,飞船,星系,扭曲,闪过,发现自己,陌生
文档库块内容:异星,第二章,文明
文档库块内容:李昂,文明,行星,一颗,高度发达,小行星,星球,灭绝,星系,这颗
文档库块内容:赛跑,第三章,时间
文档库块内容:寻找,李昂,科技知识,小行星,飞船,星系,撞击,紧迫,自己,阻止
文档库块内容:火花,第四章,智慧
文档库块内容:能量,李昂,场来,计划,小行星,解决方案,撞击,这个,轨道,科学家
文档库块内容:第五章,危机,希望
文档库块内容:星球,矿物,能量,李昂,夜以继日,小行星,蕴藏,罕见,深处,科学家
文档库块内容:第六章,星际,救援
文档库块内容:小行星,成功,矿物,能量,李昂,撞击,带回,采集,勇敢,实验室
文档库块内容:归途,第七章
文档库块内容:李昂,遗迹,热烈欢迎,星系,隐藏,感激,解除,通往,这个,探索
文档库块内容:第八章,重逢,星际
文档库块内容:李昂,归属感,归途,星系,穿越,踏上,冒险,告别,前所未有,平静
文档库块内容:第九章,开始
文档库块内容:李昂,星球,星际,之间,一个,开启,激励,全新,无数,英雄
文档库块内容:第十章,星际,使者
文档库块内容:文明,李昂,旅程,使者,美好,宇宙,探索,交流,挑战,面对
文档库块内容:慕课
文档库块内容:梦工厂,程序员
3. RAG 文档分割/分块总结
字符文本分割器、递归字符文本分割器、Html标题/段分割器、语义分割器 等多种文本分割器类型,这也是目前 RAG 分块 Chunk 的 4 种策略:
- 固定大小分块:这是最常见的分块方法,通过设定块的大小和是否有重叠来决定分块。这种方法简单直接,不需要使用任何NLP库,因此计算成本低且易于使用,例如 CharacterTextSplitter,亦或者直接循环遍历固定大小拆分。
- 基于结构的分块:常见的 HTML、MARKDOWN 格式,或者其他可以有明确结构格式的文档。这种可以借助“结构感知”对文档分块,充分利用文档文本以外的信息,类似 LangChain 中的 HTMLHeaderTextSplitter 等。
- 基于语义的分块:这种策略旨在确保每个分块包含尽可能多的语义独立信息。可以采用不同的方法,如标点符号、自然段落、或者NLTK、Spicy 等工具包来实现语义分块,或者 Embedding-based 方法,例如 LangChain 中的 SemanticChunker 等。
- 递归分块:递归分块使用一组分隔符,以分层和迭代的方式将输入文本划分为更小的块。如果最初分割文本没有产生所需大小或结构的块,则该方法会继续递归地分割直到满足条件,例如 LangChain 中的 RecursiveCharacterTextSplitter 等。
这些策略各有优势和适用场景,选择合适的分块策略取决于具体的应用需求和数据特性。很遗憾,到目前为止还没有什么是最优的策略,但这也是很难有一个产品一统天下的原因。同时策略可以组合使用,并不是一类文档只能用一种策略。
对于一个 RAG 场景,分成四个主要阶段**:预检索、检索、后检索 和 生成**,其中 分块 是 预检索 阶段的策略,如果在 分块 阶段尝试了上述 4 种策略均没有很好的效果,或许就不应该采用 RAG 的策略,而是使用 微调 的方式,让这部分知识成为模型永久的记忆,效果可能会更好
4. DocumentTransformer 组件
在 LangChain 中,还存在另一种非分割类型的文档转换器,这类转换器也是传递 文档列表 并返回 文档列表,一般是将某种文档按照需求转换成另外一种格式(例如:翻译文档、文档重排、HTML 转文本、文档元数据提取、文档转问答等)。
这类文档转换器由于接收 文档列表,返回的也是 文档列表,所以可以在 LLM 应用中任何存在 文档列表 的地方使用,例如下方的 LLM 应用架构流程图中的 文档加载、文档切割、检索器检索 的环节交互数据都是 文档列表,所以这几个环节都可以添加文档转换器组件: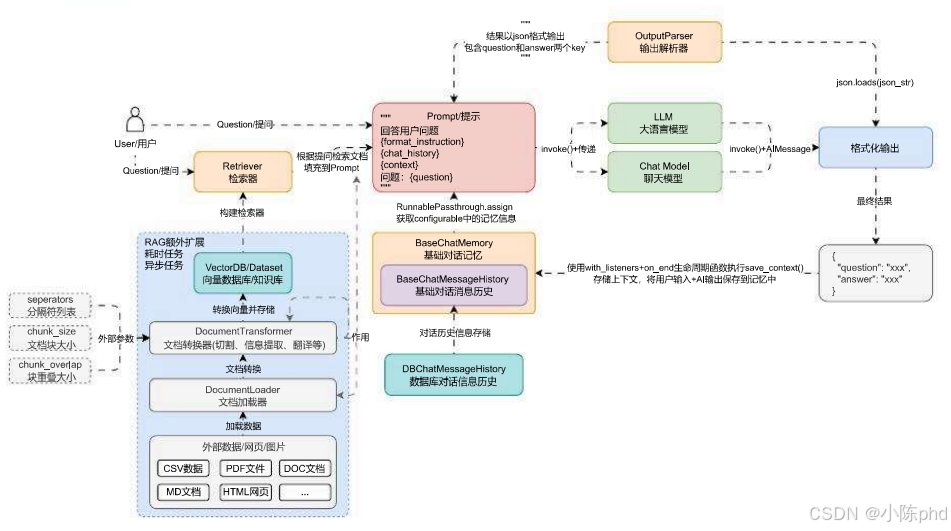
在 LangChain 中,使用文档转换器技巧非常简单,按照对应组件的构造函数进行传参,然后调用 transformer_documents 函数即可完成对文档的快速转换(每个转换器生成的格式不一样,需查看文档了解生成内容详情)。
LangChain 封装的文档转换器组件:https://imooc-langchain.shortvar.com/docs/integrations/document_transformers/。
5. 问答转换器
在 RAG 的外挂知识库中,向量存储知识库中使用的文档通常以叙述或对话格式存储。但是,绝大部分用户的查询都是问题格式,所以如果我们在对文档进行向量化之前先将其转换为 问答格式,可以在一定程度上增加检索相关文档的可能性,降低检索不相关文档的可能性。
这个技巧也是 RAG 应用开发中常见的一种优化策略,即将原始数据转换成 QA 数据后进行存储,除此之外,对于绝大部分 LLM 的微调,使用的也是 QA问答数据 也可以考虑使用该问答转换器进行转换。
在 LangChain 中封装了 Doctran 库并实现了 DoctranQATransformer 类可以快捷实现该功能,这个库底层使用 OpenAI 的函数回调来实现对问答数据的提取,首先安装该库
pip install -U doctran
假设有一段如下的文本,需要转换成 QA数据
机密文件 - 仅供内部使用
日期:2023年7月1日
主题:各种话题的更新和讨论
亲爱的团队,
希望这封邮件能找到你们一切安好。在这份文件中,我想向你们提供一些重要的更新,并讨论需要我们关注的各种话题。请将此处包含的信息视为高度机密。
安全和隐私措施
作为我们不断致力于确保客户数据安全和隐私的一部分,我们已在所有系统中实施了强有力的措施。我们要赞扬IT部门的John Doe(电子邮件:john.doe@example.com)在增强我们网络安全方面的勤奋工作。未来,我们提醒每个人严格遵守我们的数据保护政策和准则。此外,如果您发现任何潜在的安全风险或事件,请立即向我们专门的团队报告,联系邮箱为security@example.com。
人力资源更新和员工福利
最近,我们迎来了几位为各自部门做出重大贡献的新团队成员。我要表扬Jane Smith(社保号:049-45-5928)在客户服务方面的出色表现。Jane一直受到客户的积极反馈。此外,请记住我们的员工福利计划的开放报名期即将到来。如果您有任何问题或需要帮助,请联系我们的人力资源代表Michael Johnson(电话:418-492-3850,电子邮件:michael.johnson@example.com)。
营销倡议和活动
我们的营销团队一直在积极制定新策略,以提高品牌知名度并推动客户参与。我们要感谢Sarah Thompson(电话:415-555-1234)在管理我们的社交媒体平台方面的杰出努力。Sarah在过去一个月内成功将我们的关注者基数增加了20%。此外,请记住7月15日即将举行的产品发布活动。我们鼓励所有团队成员参加并支持我们公司的这一重要里程碑。
研发项目
在追求创新的过程中,我们的研发部门一直在为各种项目不懈努力。我要赞扬David Rodriguez(电子邮件:david.rodriguez@example.com)在项目负责人角色中的杰出工作。David对我们尖端技术的发展做出了重要贡献。此外,我们希望每个人在7月10日定期举行的研发头脑风暴会议上分享他们的想法和建议,以开展潜在的新项目。
请将此文档中的信息视为最机密,并确保不与未经授权的人员分享。如果您对讨论的话题有任何疑问或顾虑,请随时直接联系我。
感谢您的关注,让我们继续共同努力实现我们的目标。
此致,
Jason Fan
联合创始人兼首席执行官
Psychic
jason@psychic.dev
使用示例:
import dotenv
from langchain_community.document_transformers import DoctranQATransformer
from langchain_core.documents import Document
dotenv.load_dotenv()
# 1.构建文档列表
page_content = """..."""
documents = [Document(page_content=page_content)]
# 2.构建问答转换器并转换
qa_transformer = DoctranQATransformer(openai_api_model="gpt-3.5-turbo-16k")
transformer_documents = qa_transformer.transform_documents(documents)
# 3.输出内容
for qa in transformer_documents[0].metadata.get("questions_and_answers"):
print(qa)
输出内容:
{'question': '文件日期是什么?', 'answer': '2023年7月1日'}
{'question': '文件主题是什么?', 'answer': '各种话题的更新和讨论'}
{'question': '谁是IT部门的网络安全负责人?', 'answer': 'John Doe(电子邮件:john.doe@example.com)'}
{'question': '如果发现安全风险或事件,应该向谁报告?', 'answer': '专门的团队,联系邮箱为security@example.com'}
{'question': '谁在客户服务方面表现出色?', 'answer': 'Jane Smith(社保号:049-45-5928)'}
{'question': '员工福利计划的开放报名期是什么时候?', 'answer': '即将到来'}
{'question': '人力资源代表的联系信息是什么?', 'answer': 'Michael Johnson(电话:418-492-3850,电子邮件:michael.johnson@example.com)'}
{'question': '谁在管理社交媒体平台方面做出了杰出努力?', 'answer': 'Sarah Thompson(电话:415-555-1234)'}
{'question': '产品发布活动的日期是什么时候?', 'answer': '7月15日'}
{'question': '谁在研发部门担任项目负责人角色?', 'answer': 'David Rodriguez(电子邮件:david.rodriguez@example.com)'}
{'question': '研发头脑风暴会议的日期是什么时候?', 'answer': '7月10日'}
```
## 6. 翻译转换器
在 RAG 应用开发中,将**文档通过嵌入/向量的方式进行比较的好处在于能跨语言工作**,例如:你好,世界!、Hello, World! 和 こんにちは、世界! 分别是 中英日 三国的语言,但是因为语义相近,所以在向量空间中的位置也是非常接近的。
当一个 RAG 应用需要跨语言工作时,一般有两种策略:
1. 在将文档切块并嵌入存储到向量数据库时,同时将文档翻译成多国语言并进行相同的操作。
2. 在进行检索操作时,将检索出来的文档执行翻译功能,然后使用翻译后的文档。
这两种策略都涉及到一个功能,就是 文档的翻译,或者是说将 文档 转换成另外一种形式的 文档,这类操作其实和 文档转换器 的作用一模一样,所以可以考虑使用该组件来实现这个功能,LangChain 中针对翻译的转换器就提供了不少,例如 Doctran。
首先执行命令安装 doctran,这是一个文本翻译库,底层使用 OpenAI 的函数调用功能来在不同语言之间实现翻译:
```shell
pip install -U doctran
```
接下来就可以使用 DoctranTextTranslator 组件来实现对文档的快速中英文转换,示例如下
```python
import dotenv
from langchain_community.document_transformers import DoctranTextTranslator
from langchain_core.documents import Document
dotenv.load_dotenv()
# 1.构建文档列表
page_content = """..."""
documents = [Document(page_content=page_content)]
# 2.构建翻译转换器并翻译
text_translator = DoctranTextTranslator(openai_api_model="gpt-3.5-turbo-16k")
translator_documents = text_translator.transform_documents(documents)
# 3.输出翻译内容
print(translator_documents[0].page_content)
```
输出内容:
```
Confidential Document - For Internal Use Only
Date: July 1, 2023
Subject: Updates and Discussions on Various Topics
Dear Team,
I hope this email finds you all well. In this document, I would like to provide you with some important updates and discuss various topics that require our attention. Please consider the information included here as highly confidential.
Security and Privacy Measures
As part of our ongoing commitment to ensuring customer data security and privacy, we have implemented strong measures across all systems. We commend John Doe from the IT department (email: john.doe@example.com) for his diligent work in enhancing our network security. Going forward, we remind everyone to strictly adhere to our data protection policies and guidelines. Additionally, if you come across any potential security risks or incidents, please report them immediately to our dedicated team at security@example.com.
Human Resources Updates and Employee Benefits
Recently, we have welcomed several new team members who have made significant contributions to their respective departments. I would like to commend Jane Smith (Social Security Number: 049-45-5928) for her outstanding performance in customer service. Jane has consistently received positive feedback from clients. Furthermore, please note that the open enrollment period for our employee benefits program is approaching. If you have any questions or need assistance, please contact our HR representative, Michael Johnson (phone: 418-492-3850, email: michael.johnson@example.com).
Marketing Initiatives and Events
Our marketing team has been actively developing new strategies to increase brand awareness and drive customer engagement. We would like to thank Sarah Thompson (phone: 415-555-1234) for her exceptional efforts in managing our social media platforms. Sarah has successfully increased our follower base by 20% in the past month. Additionally, please remember the product launch event scheduled for July 15th. We encourage all team members to attend and support this important milestone for our company.
Research and Development Projects
Our R&D department has been tirelessly working on various projects in pursuit of innovation. I would like to commend David Rodriguez (email: david.rodriguez@example.com) for his outstanding work in the role of project lead. David has made significant contributions to the development of our cutting-edge technology. Furthermore, we encourage everyone to share their ideas and suggestions at the R&D brainstorming meeting scheduled for July 10th to explore potential new projects.
Please consider the information in this document as highly confidential and ensure that it is not shared with unauthorized individuals. If you have any questions or concerns regarding the topics discussed, please feel free to contact me directly.
Thank you for your attention, and let's continue working together towards our goals.
Sincerely,
Jason Fan
Co-founder and CEO
Psychic
jason@psychic.dev
```

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)