如何使用llama.cpp将SafeTensors模型转换为GGUF格式并部署ollama
将大模型微调后的SafeTensors格式通过llamacpp转换为GGUF格式,并在ollama上导入使用
一 大模型使用llama.cpp转换gguf格式并量化
经llama-factory微调后的模型, 导出后可以直接在xinference上导入使用,但总感觉速度慢,然后想在ollama上使用则需要转成gguf格式。且经本人测试,导入的大模型在ollma上运行,速度确实会比在xinference上快。本次记录方便日后使用,及帮助需要帮助的人。
llama.cpp Github仓库:GitHub - ggerganov/llama.cpp: LLM inference in C/C++
下载llama.cpp

root目录,执行下载命令(也可以是其他目录)
git clone https://github.com/ggerganov/llama.cpp.git安装Python环境
由于在llama.cpp项目中需要使用python脚本进行模型转换,已装pyhon可以跳过此步。这里我们用conda环境安装llama需要的依赖库 ,并激活虚拟环境,不会装conda的,可以参照Conda/Miniconda/Anaconda 安装及命令整理_minianaconda-CSDN博客:
#创建虚拟环境
conda create -n llama python=3.10
#进入虚拟环境
conda activate llama
#进入工程目录
cd llama.cpp
#安装环境依赖 (此依赖,看有的博主有装,有的没装,目前没发现有啥影响,不想装的可先不装,有报错之后再考虑装)
pip install -e .
llama.cpp安装依赖包
接下来,你需要安装convert_hf_to_gguf.py脚本所需的依赖包。
cd llama.cpp目录下(以下执行llama.cpp操作时都需在此目录下),执行以下命令
pip install -r requirements.txt
这个过程应该会安装所有必要的依赖包,以便脚本能够正常运行。
llama.cpp编译安装
进入llama.cpp项目目录下,对于不同的平台需要执行不同编译指令,具体如下:
#On Linux or MacOS: 在 Linux 或 MacOS 上:
make #CUDA加速版编译 make GGML_CUDA=1
windows
#Windows平台需要安装cmake和gcc,如果有没有安装的请自行百度安装
mkdir build
cd build
cmake ..
cmake --build . --config Release
#CUDA加速版编译
mkdir build
cd build
cmake .. -DLLAMA_CUBLAS=ON
cmake --build . --config Release
更多方式请参考官方文档:https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md

编译安装可能需要一段时间。编译完以后如下:
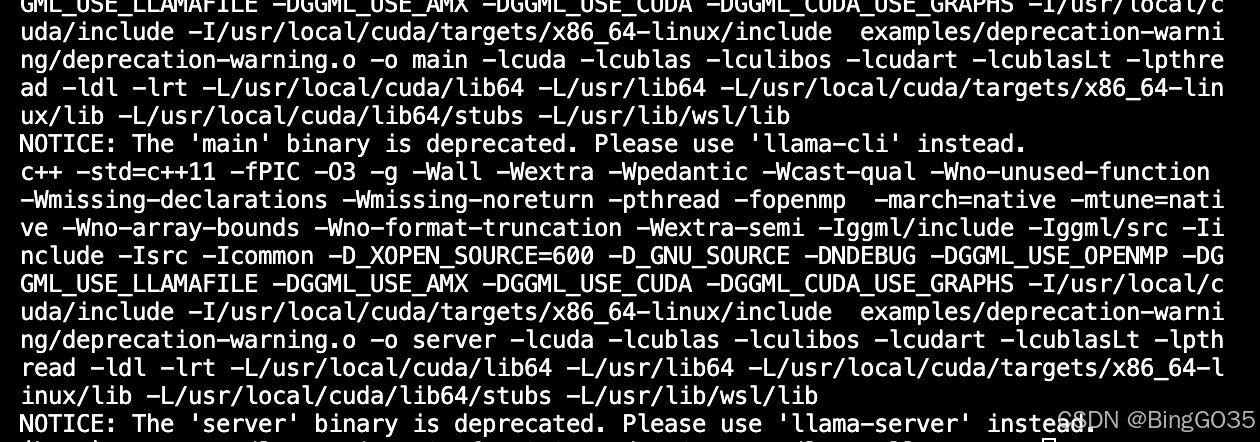
编译完后我是使用ls命令主要检查一下有没有存在llama-cli与llama-quantize两个可执行文件,我们后面会使用到,如果没有可能是在编译的时候出现了问题,可以使用“make clean”指令清除编译结果然后“make”重新编译。
编译完以后下面我们就可以使用llama.cpp进行模型的格式转换以及量化操作了。
gguf格式转换:
python convert_hf_to_gguf.py <训练后的模型文件路径 > --outtype f16 --outfile <格式转 换后的文件路径.gguf>
# 备注:--outtype: (choose from 'f32', 'f16', 'bf16', 'q8_0', 'tq1_0', 'tq2_0', 'auto')
# 以下是我的执行样例:
python convert_hf_to_gguf.py /root/autodl-tmp/llama_factory/export/qwen2515b --outtype f16 --outfile /root/autodl-tmp/llama_factory/export/hg_models/qwen2515b.gguf
模型量化
将模型转化为gguf格式格式后,我们可以看到7b的模型大约还是有15~16GB左右,对于我们本地的电脑还是一笔不小的开销。那么我们就可以使用编译后得llama-quantize可执行文件来对模型进行进一步量化处理。量化可以帮助我们减少模型的大小,但是代价是损失了模型精度,也就是模型回答的能力可能有所下降。权衡以后我们可以选择合适的量化参数,保证模型的最大效益。
llama.cpp 的参数量化代码分为两部分,第一块是从开源代码仓库下载的原始模型,一般上 fp32/fp16 的,需要用 convert.py(现在githup上已经没有这个文件了 ) 脚本转换为 ggml 格式,这个模型是 fp16 的,这个模型是可以直接在 llama.cpp 里面直接使用的(严格说有较好硬件并行支持的 fp16 是不算量化的)。
第二块是使用 example/quantize/quantize.cpp 中的逻辑将 ggml 的 fp16 模型转换为 int8、int4 等格式。其实牛逼的 llama.cpp 支持了很多种量化方法,并且还贴心的在定义中给出了每个量化方法的 ppl 变化,如下图所示,例如 Q8_0 只增加了 0.0004 的 ppl,相当于就没啥变化,相当强。并且,llama.cpp 自己还提供测试 ppl 的脚本方法。
我们发现量化方发主要分为数字后缀(如Q8_0、Q4_0)、 K 后缀、IQ前缀等。数字后缀主要代表普通的量化方法,K 后缀代表 K-quants 方法,再后边 S、M、L、XS 等等代表尺寸。而后缀 _0 和 后缀 _1 的区别比较小,主要是有没有以 0 为中心的量化网格进行对齐,0 是对齐的。所以后缀 0 只有一个放缩参数,没有平移参数,后缀 1 则都有这两个参数。所以 int4_0 (ppl 0.2166)和 int4_1(ppl 0.1585) 相比,偏移之后的量化效果明显要好一些,这是符合预期的,我们管这种原版的简单的量化方法叫做 vanilla 方法。而后缀 K 代表的 K-quants 方法,其中 Q4_K_M 的 ppl + 0.0532 比 Q4_0 +0.2166 好太多了
# ./llama-quantize <原模型目录> <转换后的模型保存路径> <量化位数>
量化位数:
量化位数使用q表示,它代表存储权重(精度)的位数。q2、q3、q4… 表示模型的量化位数。例如,q2表示2位量化,q3表示3位量化,以此类推。量化位数越高,模型的精度损失就越小,模型的磁盘占用和计算需求也会越大。
我们使用llama-quantize量化模型,它提供各种量化位数的模型:Q2、Q3、Q4、Q5、Q6、Q8、F16。量化模型的命名方法遵循: Q + 量化比特位 + 变种。具体的量化参数可以在llama.cpp目录下使用./llama-quantize查看。
./llama-quantize /root/autodl-tmp/llama_factory/export/llama3_2_3b/hg_models/llama3_2_3b_f16.gguf /root/autodl-tmp/llama_factory/export/llama3_2_3b/hg_models/llama3_2_3b_f16_q4.gguf q4_1查看文件夹有两个gguf文件,后面就可以到ollma 上部署了 。
二 Ollama 自定义模型导入及部署:
ollama下载 多种方式 可参照官方文档:https://github.com/ollama/ollama
# linux安装部署
curl -fsSL https://ollama.com/install.sh | sh
ollama启动,允许外部访问
OLLAMA_HOST=0.0.0.0 ollama serve
验证启动成功 地址栏输入:ip:11434
ollama 自定义模型导入
ollama github中对于模型导入写的很详细,具体请查阅github。
首先要创建一个“Modelfile”文件(文件名自定义,位置随意,本人与gguf文件放一起以便查看),按照模板在其中填入导入模型的相应信息,官方模板如下:
FROM llama2 # sets the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 1 # sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token PARAMETER num_ctx 4096 # sets a custom system message to specify the behavior of the chat assistant SYSTEM You are Mario from super mario bros, acting as an assistant.
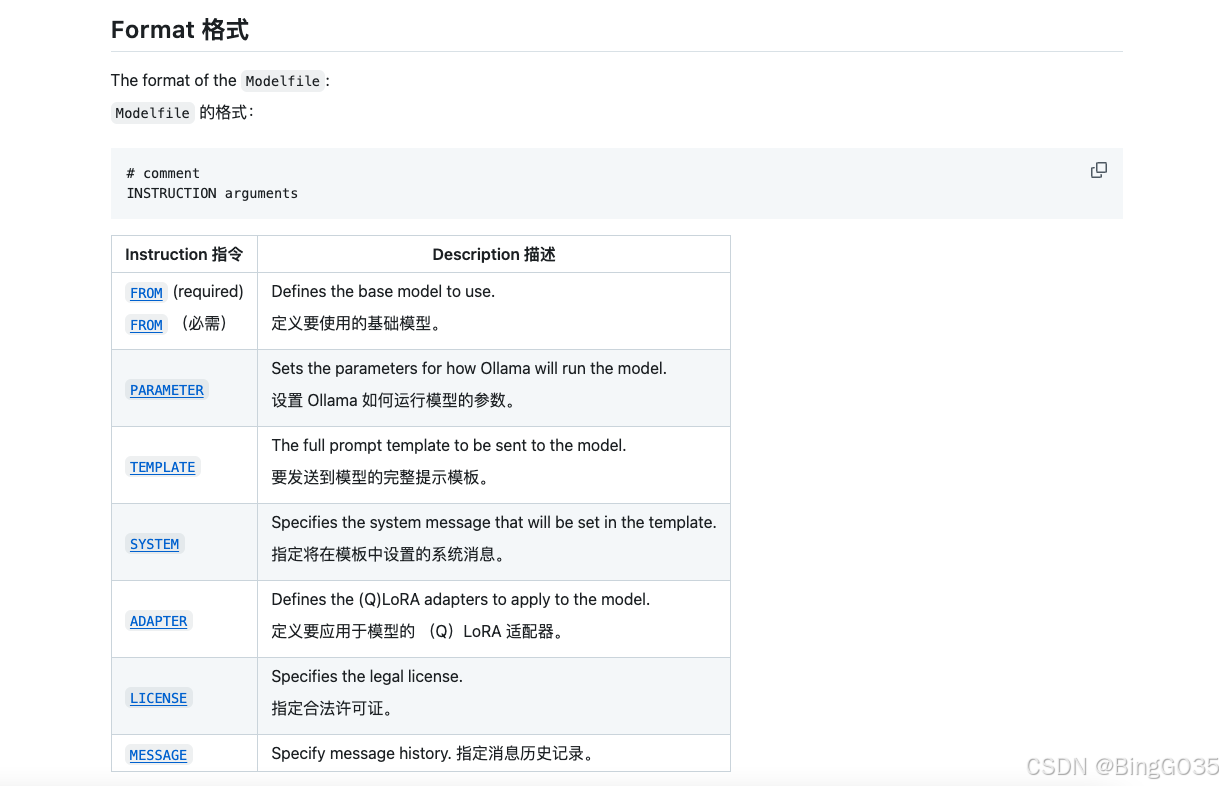
最重要的还是第一行,指定模型文件的存储路径,必填。如果ollama中已经pull过与微调模型同类型的模型(比如我微调的模型是qwen2.5:0.5b,而我之前在ollama中已经用过qwen2.5:0.5b),那可以直接使用
ollama show --modelfile qwen2.5:0.5b命令查阅该模型官方的Modelfile配置详情,然后直接复制到自己微调模型Modelfile配置中即可。
最终我的Modelfile配置如下,除了第一行是模型文件路径,后面内容都是直接复制官方配置:
FROM /root/autodl-tmp/llama_factory/export/llama3_2_3b/hg_models/llama3_2_3b_f16_q4.gguf
TEMPLATE """{{- if .System }}
{{ .System }}
{{- end }}
{{ .Prompt }}
"""
PARAMETER stop ""
PARAMETER stop ""
PARAMETER stop ""
PARAMETER stop "保存文件之后,执行如下命令,ollama 导入自定义模型:
ollama create <自定义模型名称> -f <保存Modelfile路径>
ollama 启动模型
ollama run <自定义模型名称>
运行成功即导入成功,可以在ollma上测试,也可以用于dify上:

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)