想让企业知识“活”起来?OpenAI这本“宝书”教你搭时序图谱、用GraphRAG智能体!
继2024年中微软开源GraphRAG方案以来,知识图谱和大模型结合在企业级应用案例层出不穷。2025年7月22日,OpenAI也在开发者社区重磅发布“KG+LLM”结合的企业智能知识管理红宝书Cookbook ,利用大模型构建时序知识图谱与新一代“GraphRAG”智能体,提升多跳路径检索的精准度。本文详细介绍了如何用 OpenAI 最新大模型与知识图谱结合搭建面向结构化/半结构化数据的时序智能


Temporal Agents with Knowledge Graphs
摘要:
继2024年中微软开源GraphRAG方案以来,知识图谱和大模型结合在企业级应用案例层出不穷。2025年7月22日,OpenAI也在开发者社区重磅发布“KG+LLM”结合的企业智能知识管理红宝书Cookbook ,利用大模型构建时序知识图谱与新一代“GraphRAG”智能体,提升多跳路径检索的精准度。本文详细介绍了如何用 OpenAI 最新大模型与知识图谱结合搭建面向结构化/半结构化数据的时序智能检索系统(Temporal Agent+Knowledge Graph+Multi-hop Retrieval)。内容涵盖数据分块、时序三元组抽取、实体规范化、事件失效检测和多步检索等工业完整流程,配有关键架构图及代码示例,适合专业技术人员学习参考。
Github链接:
https://github.com/openai/openai-cookbook/tree/main/examples/partners/temporal_agents_with_knowledge_graphs
原文作者:
Shikhar Kwatra(OpenAI), Danny Wigg(OpenAI), Alex Heald, et al.
目录
-
为什么需要时间感知的知识图谱
-
Temporal Agent管道与关键模块
-
数据分块及分块模型
-
时序三元组与Temporal Event
-
实体解析与合一
-
事件失效与历史版本管理
-
全流程集成与图结构可视
-
多步推理检索方案
-
评测与生产化建议
前言
本Coobook提供了一个实践指南,用于构建时间感知(时序)知识图并直接在这些图上执行多跳检索。
它专为从事时序知识图谱的工程师、架构师和分析师而设计。无论您是进行原型设计、大规模部署,还是探索使用结构化数据的新方法,您都会找到实用的工作流程、最佳实践和决策框架来加速您的工作。
本手册介绍了两个可以立即使用、扩展和部署的动手工作流程:
1、时间感知知识图谱(KG)构建
开发知识驱动型人工智能系统的一个关键挑战是维护一个保持最新且相关的数据库。虽然人们非常关注通过语义相似性和重新排名等技术提高检索准确性,但本指南重点关注一个基本但经常被忽视的方面:随着新数据的到来,系统地更新和验证您的知识库。
无论您的检索算法多么先进,它们的有效性都会受到数据库质量和新鲜度的限制。本指南演示了如何在新数据到达时定期验证和更新知识图谱条目,帮助确保您的知识库保持准确和最新。
2、使用知识图谱进行多跳检索
了解如何通过工具调用将 OpenAI 模型(例如 o3、o4-mini、GPT-4.1 和 GPT-4.1-mini)与结构化图谱查询相结合,使模型能够跨实体和关系分多个步骤遍历图谱。
这种方法可以让您的系统回答复杂的、多方面的问题,这些问题需要对多个链接的事实进行推理,这远远超出了单跳检索所能完成的任务。
在里面,您会发现:
-
用于在每个阶段选择模型和提示技术的实用决策框架
-
即插即用代码示例,可轻松集成到您的 ML 和数据管道中
-
有关 OpenAI 工具使用、微调、图谱后端选择等的深入资源的链接
-
从原型到生产的清晰路径,以及可作的扩展和可靠性最佳实践
注意:所有基准和建议均基于截至 2025 年 6 月的最佳可用模型和实践。随着生态系统的发展,请定期重新审视您的方法,以了解新功能和改进。
关键要点
使用时序智能体创建时间感知知识图谱
1、为什么要让你的知识图谱是临时的?
传统知识图谱将事实视为静态的,但现实世界的信息却在不断发展。上个季度的真实情况今天可能已经过时了,如果图表不能捕捉到随时间的变化,则可能会出现错误或误导决策。时间知识图谱允许您准确回答诸如“给定日期的真实情况”之类的问题,或分析事实和关系如何变化,确保决策始终基于最相关的背景。
2、什么是时序代理?
时序代理是一个管道组件,用于摄取原始数据并为知识图谱生成带时间戳的三元组。这可以实现精确的基于时间的查询、时间线构建、趋势分析等。
3、管道如何工作?
管道首先对原始文档进行语义分块。这些块被分解为为我们的 Temporal Agent 准备的语句,然后创建时间感知三元组。然后,失效代理可以执行时间有效性检查,发现并处理任何被图表上发生的新语句失效的语句。
知识图谱上的多步骤检索
1、为什么要使用多步检索?
直接的单跳查询经常会遗漏分布在图拓扑中的显着事实。多步(多跃点)检索支持迭代遍历、跟踪关系并跨多个跃点聚合证据。这种方法揭示了复杂的依赖关系和潜在联系,这些依赖关系和潜在联系将通过一次性查找保持隐藏,从而为复杂的查询提供更全面、更细致的答案。
2、规划
规划者编排检索过程。面向任务的规划器将查询分解为具体的顺序子任务。相比之下,以假设为导向的规划者提出的主张是为了确认、反驳或演变。选择最佳策略取决于问题在从确定性报告(明确定义的路径)到探索性研究(开放式推理)的范围内的位置。
3、工具设计范式
工具设计跨越一个连续体:固定工具为特定查询提供一致、可预测的输出(例如,始终返回旧金山今天天气的服务)。另一方面,自由格式工具提供了广泛的灵活性,例如代码执行或开放式数据检索。半结构化工具介于这些极端之间,限制某些作,同时允许量身定制的灵活性——专门的子代理就是一个典型的例子。选择合适的范式是在控制、适应性和复杂性之间进行权衡。
4、评估检索系统
高保真评估取决于专家策划的“黄金”答案,尽管这些答案的制作成本高昂且劳动密集型。自动判断,例如来自 LLM 或工具跟踪的判断,可以快速生成以补充或预筛选,但可能缺乏人类评估的精确性。随着系统的成熟,过渡到利用真实的用户反馈来衡量和优化生产中的检索质量。
经过验证的工作流程:从综合测试开始,对您精选的人工注释的“黄金”数据集进行基准测试,并使用实时用户反馈和评级进行迭代改进。
从原型到生产
1、保持图谱精简
建立存档策略并为每个边缘分配数字相关性分数(例如,新近度 x 信任度 x 查询频率)。自动存档或稀疏化低价值节点和边缘,确保只保留最关键和最常访问的事实以供快速检索。
2、并行化引入管道
从线性文档→块→提取→解析管道过渡到暂存的异步架构。为每个处理阶段分配自己的队列和专用工作器池。对失效作业应用集群或基于网络的批处理,以最大限度地提高效率。尽可能批量处理外部 API 请求(例如 OpenAI)和数据库写入。此设计提高了吞吐量,引入了可靠性的背压,并允许您独立扩展每个管道阶段。
3、集成强大的生产保障措施
强制执行严格的输出验证:标准化时态字段(例如 ISO-8601 日期格式),将实体类型限制为受控词汇表,并应用基于模型的轻量级健全性检查以实现输出一致性。采用具有可追溯标识符的结构化日志记录,并在真实环境中监控实时质量和性能指标,以便在数据漂移、回归或管道异常影响下游应用程序之前主动检测它们。
这几本书籍的PDF版已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

正文
1. 为什么需要时间感知的时序知识图谱
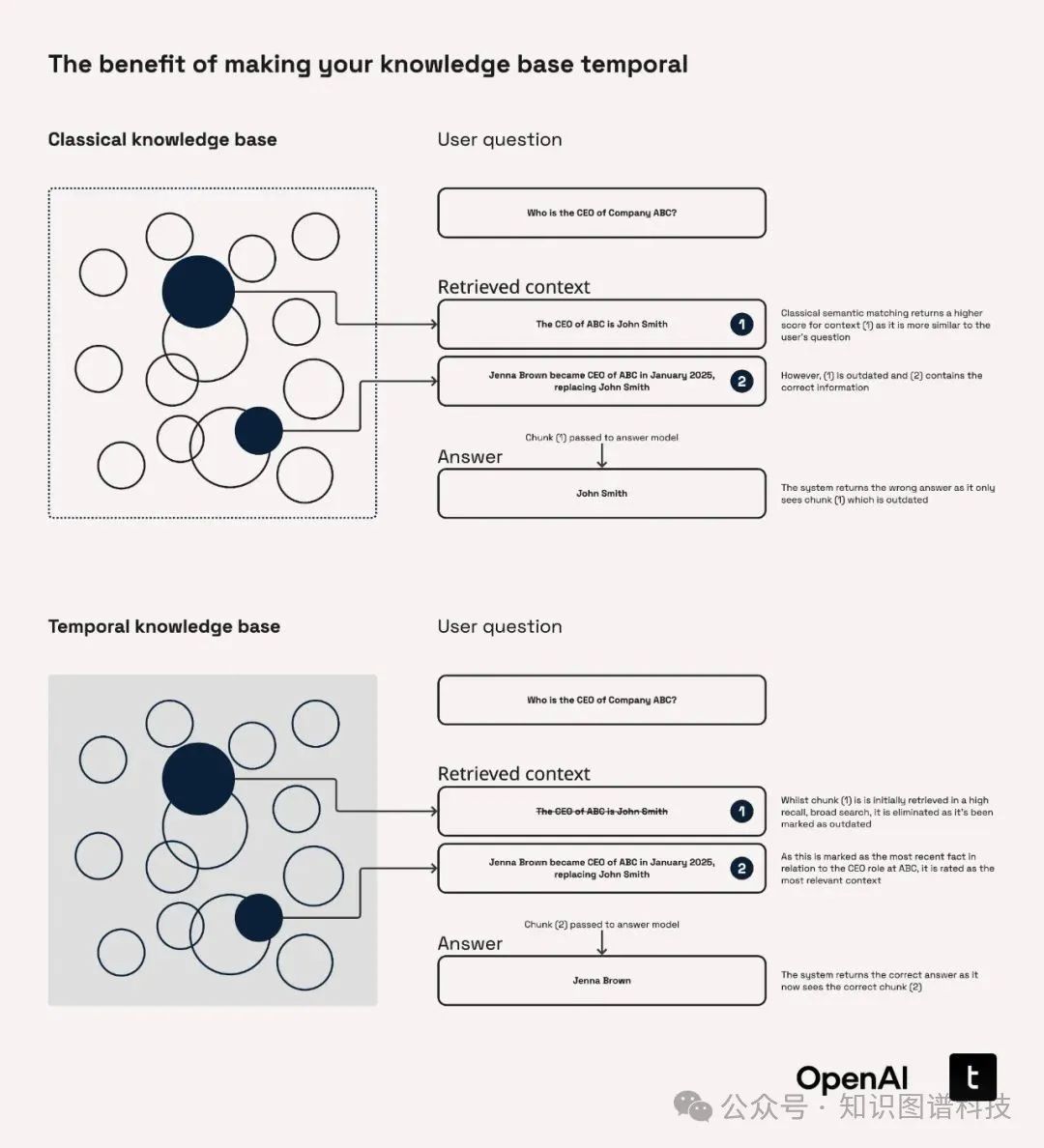
传统知识图谱多为静态事实存储,难以应对现实世界“事实随时间流动”带来的真实性判决需求。例如:
-
金融:某银行自2023年2月起评级如何变化?若知识图谱无时区分,会导致定价或风控错误。
-
法律:某高管在某公告发布时是否归属在职?若历史任期没有被严密标注,会导致合规和责任归属误判。
-
制造:某型号汽车啥时间段部署了哪套固件?历史追溯不明将导致召回或溯源风险。

解决思路:
引入“时序三元组”,即每条事实不仅是实体-属性-对象,还挂上valid_from/valid_to时间戳,实现按时间切片、轨迹生成、变更追踪与反事实分析,确保数据随新证据到来自动更新失效。

2. Temporal Agent管道与关键模块概览
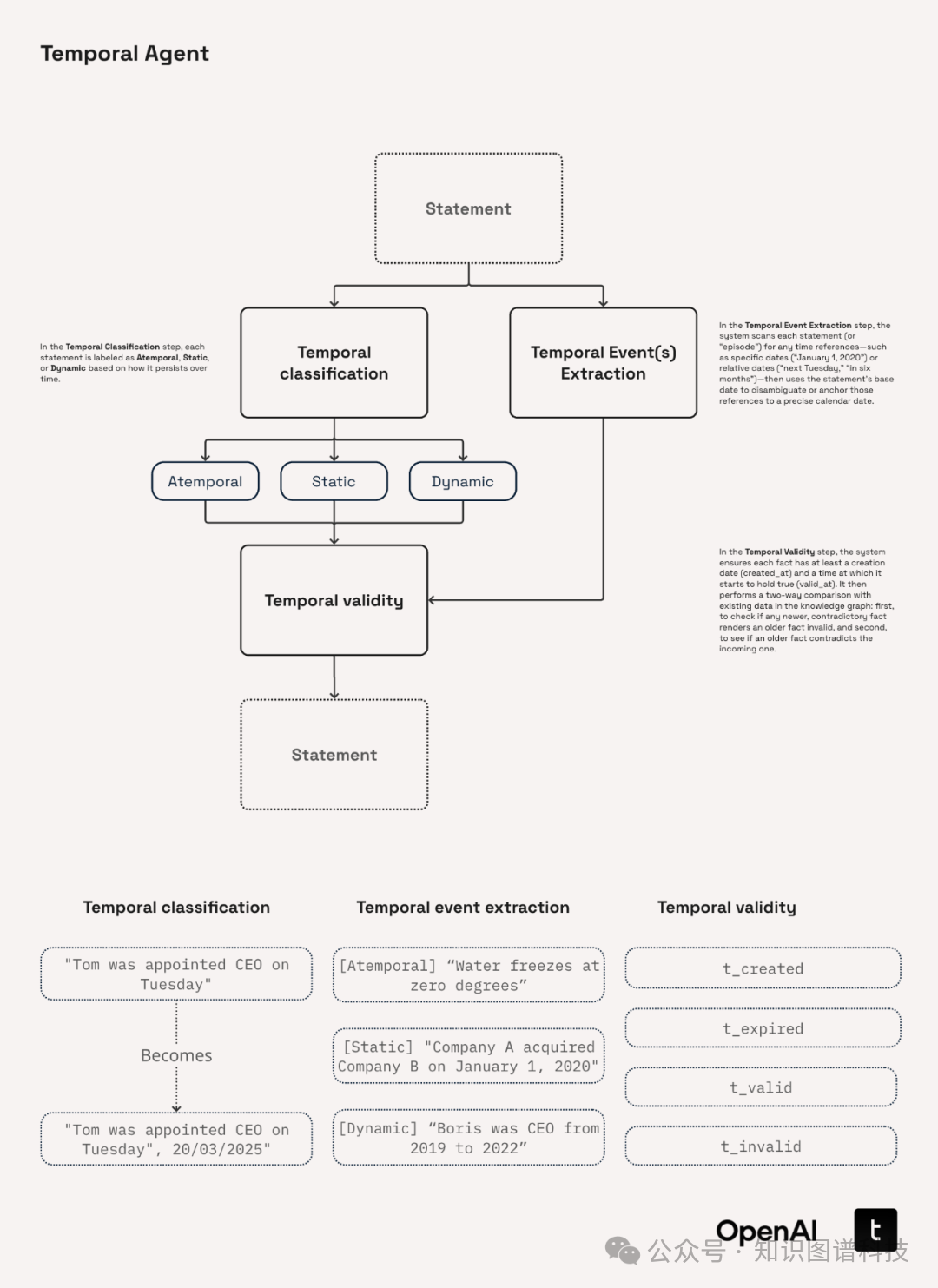
本方案流水线如下:
-
文档语义分块(Semantic Chunking)
-
语句拆分与原子事实抽取(Atomic Statement Extraction)
-
时序标注(Temporal Type/Statement Type 打标签)
-
时效区间抽取(valid_at/invalid_at精确定位)
-
时序三元组抽取(Subject-Predicate-Object+Time)
-
实体规范化解析(Entity Resolution)
-
失效事件处理(Invalidation Agent)
-
存储至数据库,自动化知识基迭代
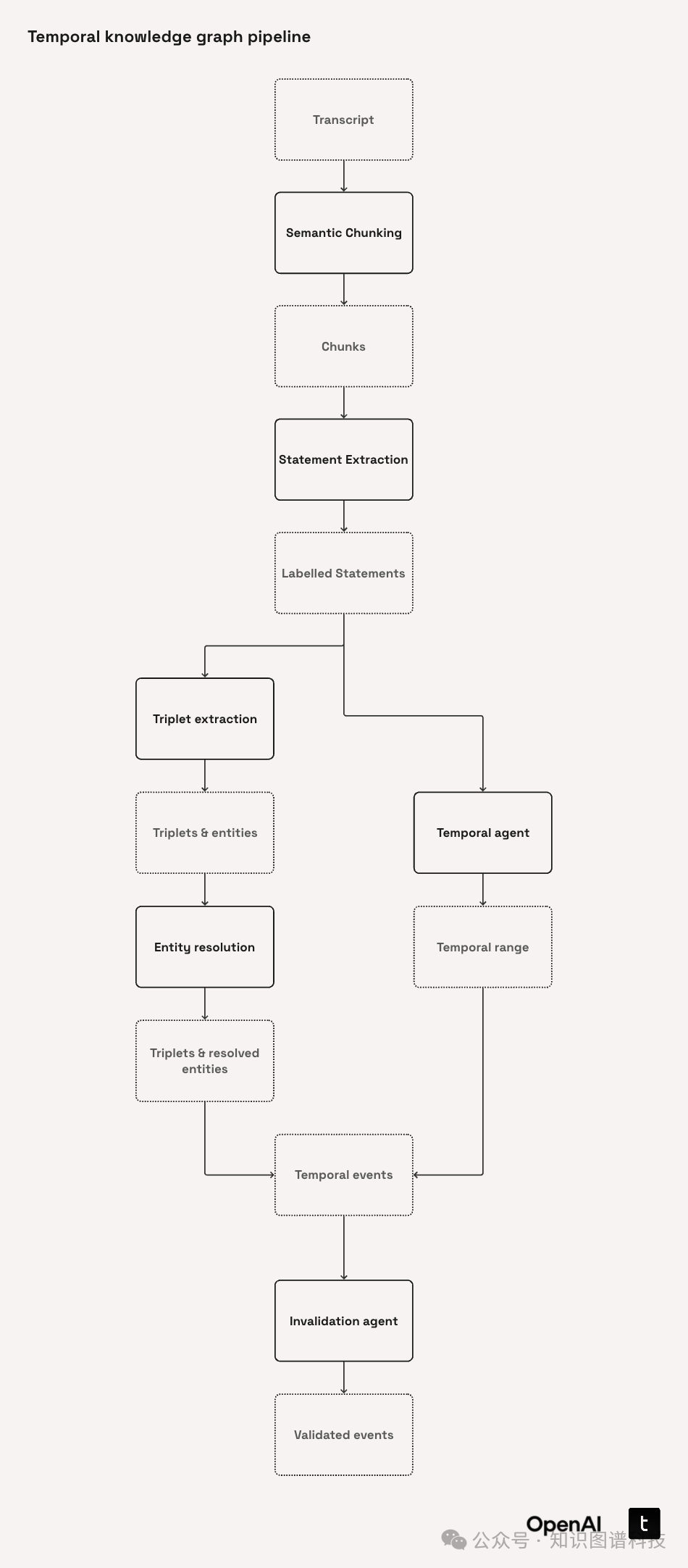
3. 数据分块及分块模型
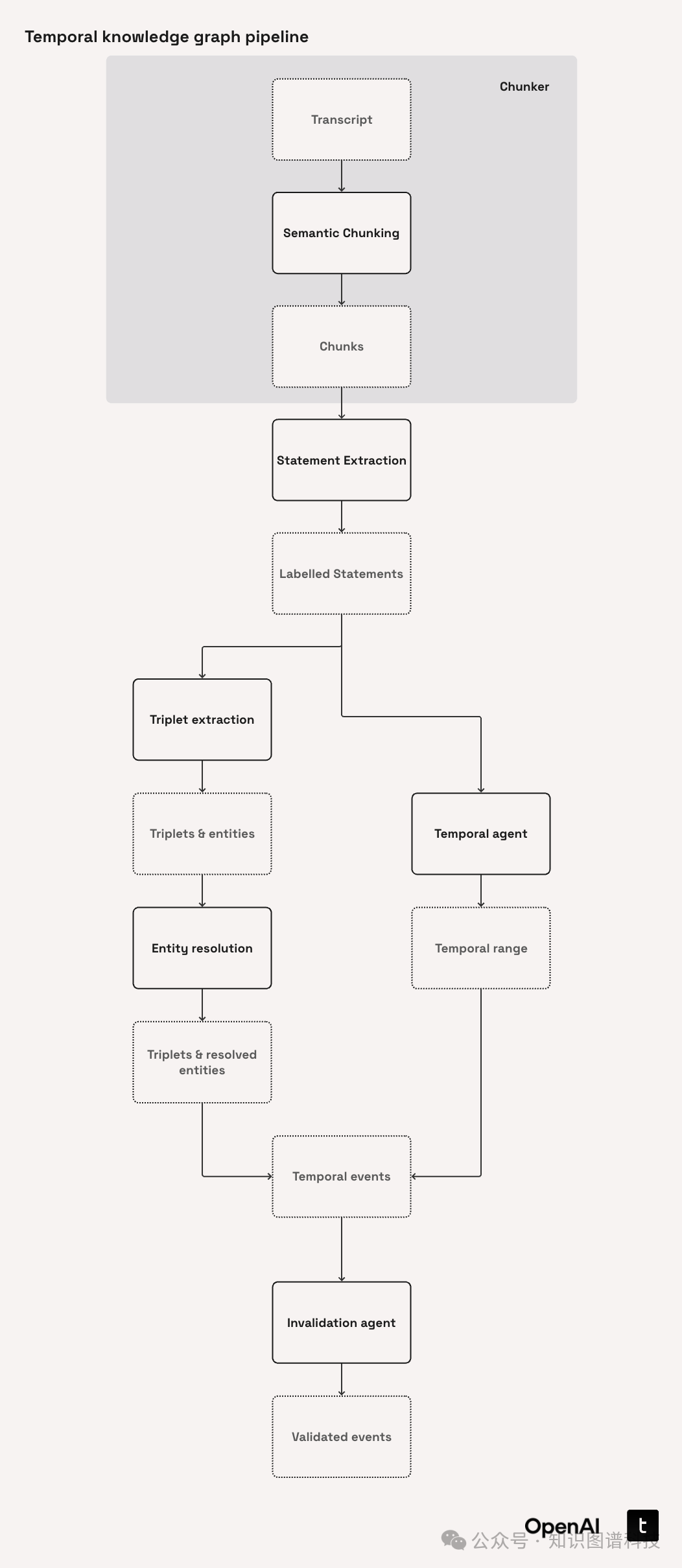
采用语义分块法(不是按行数/字符数),以保持上下文完整性,有效提升后续实体、关系等抽取准确度。分块模型Chunk包括id、内容和元数据。示例代码:
python
classChunk(BaseModel):
id: uuid.UUID = Field(default_factory=uuid.uuid4)
text: str
metadata: dict[str, Any]
Transcript模型代表一份财报、公告或会议全文,包含公司、日期、所属季度和分块列表。
4. 时序三元组与Temporal Event建模
4.1 语句抽取与标签体系
所有语句自动拆成最小“原子事实”:
-
带标签statement_type(Fact/Opinion/Prediction)
-
带temporal_type(Static/ Dynamic/ Atemporal)
例如:
-
“John任职CEO” → 类型Fact,Dynamic(正在进行,未来可被新事实终结)
-
“X会涨” → Prediction,Static(预测型,生效于表达时刻)
枚举类型如下:
python
classTemporalType(StrEnum):
ATEMPORAL = "ATEMPORAL"
STATIC = "STATIC"
DYNAMIC = "DYNAMIC"
classStatementType(StrEnum):
FACT = "FACT"
OPINION = "OPINION"
PREDICTION = "PREDICTION"
4.2 时区间抽取
每个陈述都自动标定生效区间(valid_at, invalid_at),无效则为None。
示例Jinja抽取prompt:
“John Smith从2023年4月1日起任CFO”
→ Dynamic,valid_at=2023-04-01T00:00:00Z, invalid_at=None
4.3 三元组标准化
统一关系谓词集(Predicate),如DEVELOPED“开发了”、LAUNCHED“发布了”等,所有业务事实抽象为主体-谓词-宾体,并唯一标识实体、关系节点。
|
Predicate |
英文说明 |
|---|---|
|
IS_A |
类型关系 |
|
HOLDS_ROLE |
任职 |
|
LAUNCHED |
上市/发布 |
|
INVESTS_IN |
投资 |
|
HAS_REVENUE |
收入 |
|
...(表格完整版见正文) |
5. 实体解析与合一(Entity Resolution)
同一实体(如AMD/Advanced Micro Devices/AMD Inc.)跨不同文本可能出现不同写法,需聚合。
方法:
-
按类型聚类后,快速模糊匹配(如RapidFuzz)合并同义/错别字
-
采用“中心实体”法,每组以最高相似度为代表,其余均指向“resolved_id”
-
支持Acronym(AMD/AMDI)等反常合一
6. 事件失效与历史版本管理
为防止重复、冲突事实并存,失效判定核心机制如下:
- 动态事件判别
(如任职、现象)若遇到新“断点事实”即被标记失效(invalid_at=新证据时间点)
- 临时区间冲突
自动比对(含事件embedding相似度过滤,避免冗余比对)
失效机制架构如下图
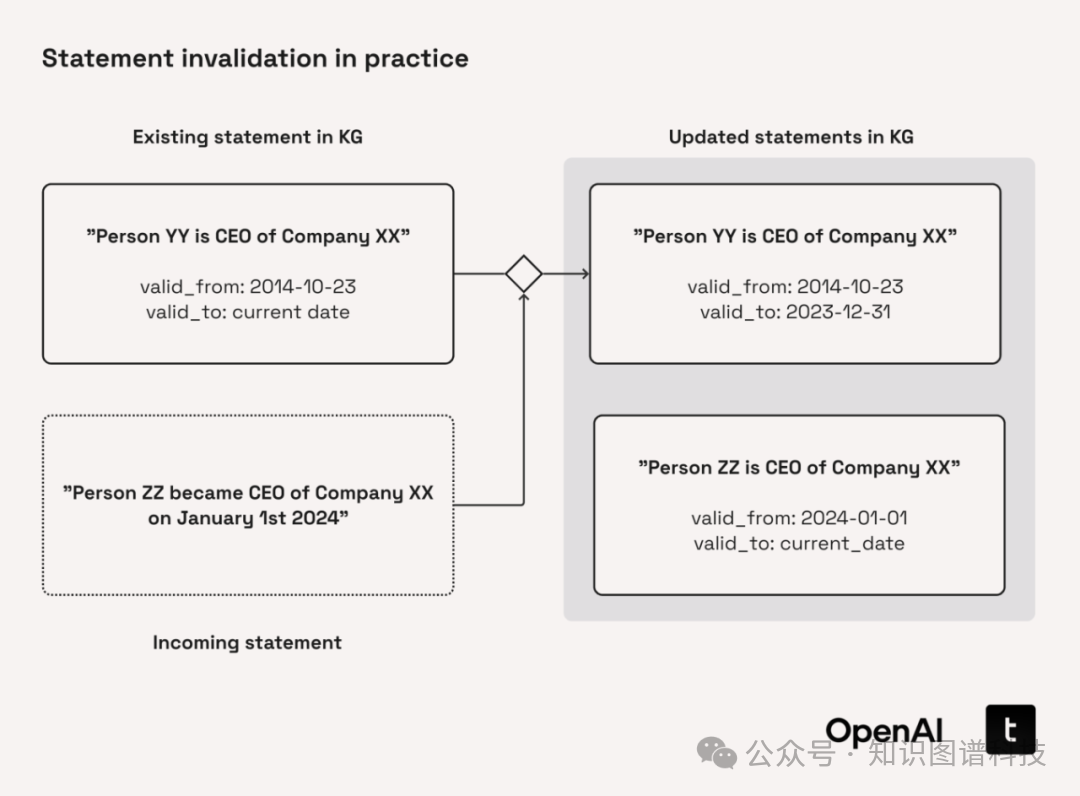
-
双向失效:新事件可终结旧事件,反之亦然
-
时间区间重叠与事件类型(只比对Fact,去除Atemporal和Opinion)
伪代码与架构见正文。
7. 全流程集成与图结构可视化
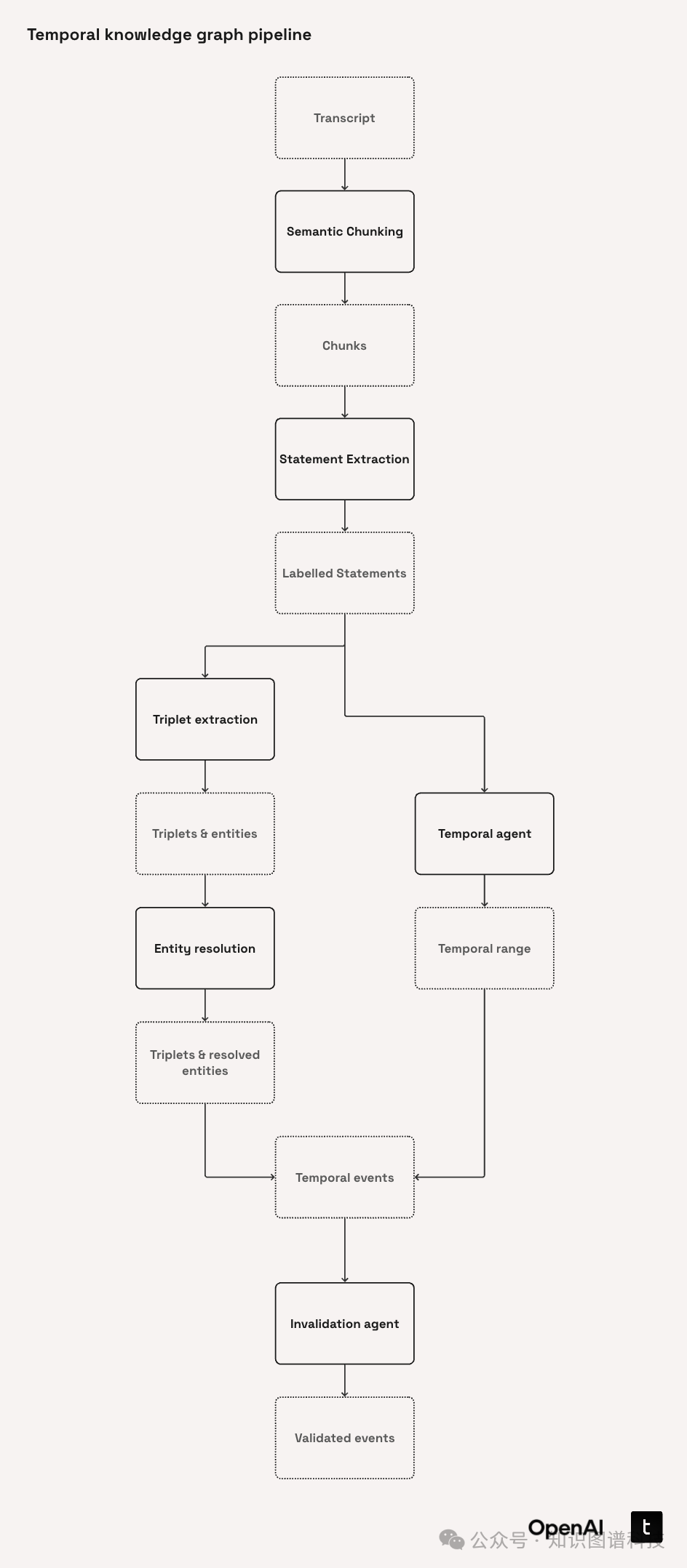
7.1 数据库表结构与批量写入
四大表:transcripts(文本)、chunks(分块)、events(事件)、triplets(三元组)、entities(实体)。所有新事件自动失效确认后批量导入,避免冲突。
7.2 可视化及实例
采用NetworkX可生成可交互的时序知识图谱,并可视化分布(节点数、度数、连接度等)。例如,提取NVIDIA节点信息及“开发了”所有关系,可用于研发趋势溯源分析。
8. 多步推理检索(Multi-Step Retrieval)
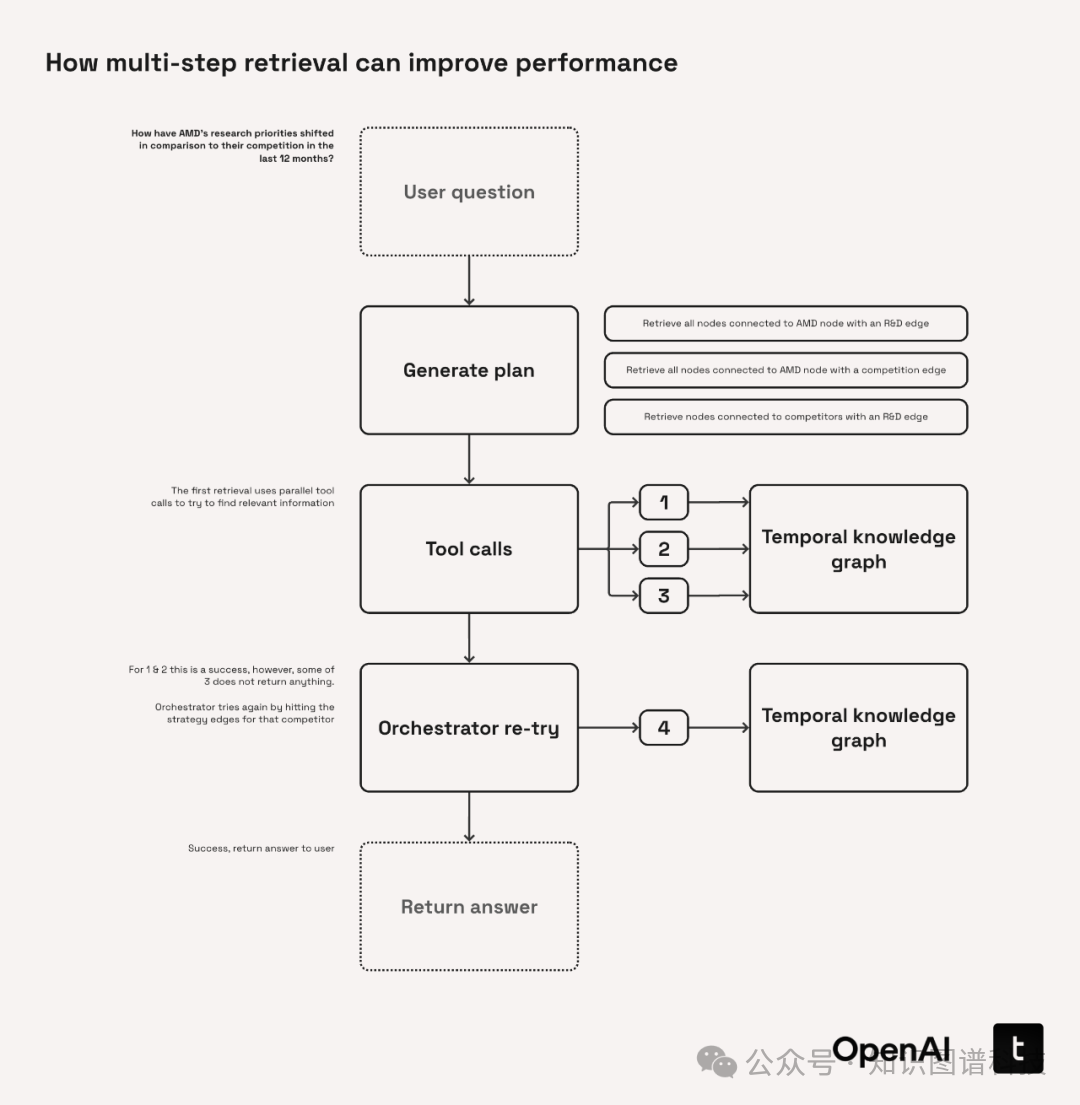
现实提问往往需多步推理,简单向量查找无法满足“跨事实链路”问题。
8.1 检索流程
规划(Planner)
使用大模型将问题分解成多步子查询步骤,系统性覆盖所有research point。分为面向任务和假设导向,规划器概述了下游代理块应执行的具体子任务。这些任务以行动为导向的意义上表述,例如“1.提取 IJK 公司 2018-2020 年期间的研发活动信息。当目标主要是确定性的并且主要风险是跳过或重复工作时,这些计划者通常是首选。
面向任务
- Law 法律: "Extract and tabulate termination-notice periods from every master service agreement executed in FY24"
“从 24 财年执行的每项主服务协议中提取并列出终止通知期”
- Finance 金融:"Fetch every 10-K filed by S&P 500 banks for FY24, extract tier-1 capital and liquidity coverage ratios, and output a ranked table of institutions by capital adequacy"
“获取标准普尔 500 家银行在 24 财年提交的每 10-K,提取一级资本和流动性覆盖率,并按资本充足率输出机构排名表”
- Automotive 汽车:"Compile warranty-claim counts by component for Model XYZ vehicles sold in Europe since the new emissions regulation came into force"
“自新排放法规生效以来,按组件编制在欧洲销售的 XYZ 型车辆的保修索赔计数”
- Manufacturing 制造业 :"Analyse downtime logs from each CNC machine for Q1 2025, classify the root-cause codes, and generate a Pareto chart of the top five failure drivers"
“分析 2025 年第一季度每台 CNC 机床的停机日志,对根本原因代码进行分类,并生成前五大故障驱动因素的帕累托图”
假设导向
- Law 法律:"Does the supplied evidence satisfy all four prongs of the fair-use doctrine? Evaluate each prong against relevant case law"
“提供的证据是否满足合理使用原则的所有四个方面?根据相关判例法评估每个方面”
-
Pharmaceuticals 药品
"What emerging mRNA delivery methods could be used to target the IRS1 gene to treat obesity?"“哪些新兴的 mRNA 递送方法可用于靶向 IRS1 基因来治疗肥胖症?”
-
Finance 金融
"Is Bank Alpha facing a liquidity risk? Compare its LCR trend, interbank borrowing costs, and deposit-outflow and anything else you find that is interesting"“阿尔法银行是否面临流动性风险?比较它的 LCR 趋势、银行间借贷成本、存款流出以及您认为有趣的任何其他内容”
- Orchestrator调度
下发一或多次Graph检索工具调用(如factual_qa、trend_analysis)
- Graph查询与结果聚合
每步检索都会返回详细三元组及原始文本、关系、证据,保证溯源透明
- 循环+输出
结果汇总后,由LLM形成完整答复,带溯源证据及时间线图表
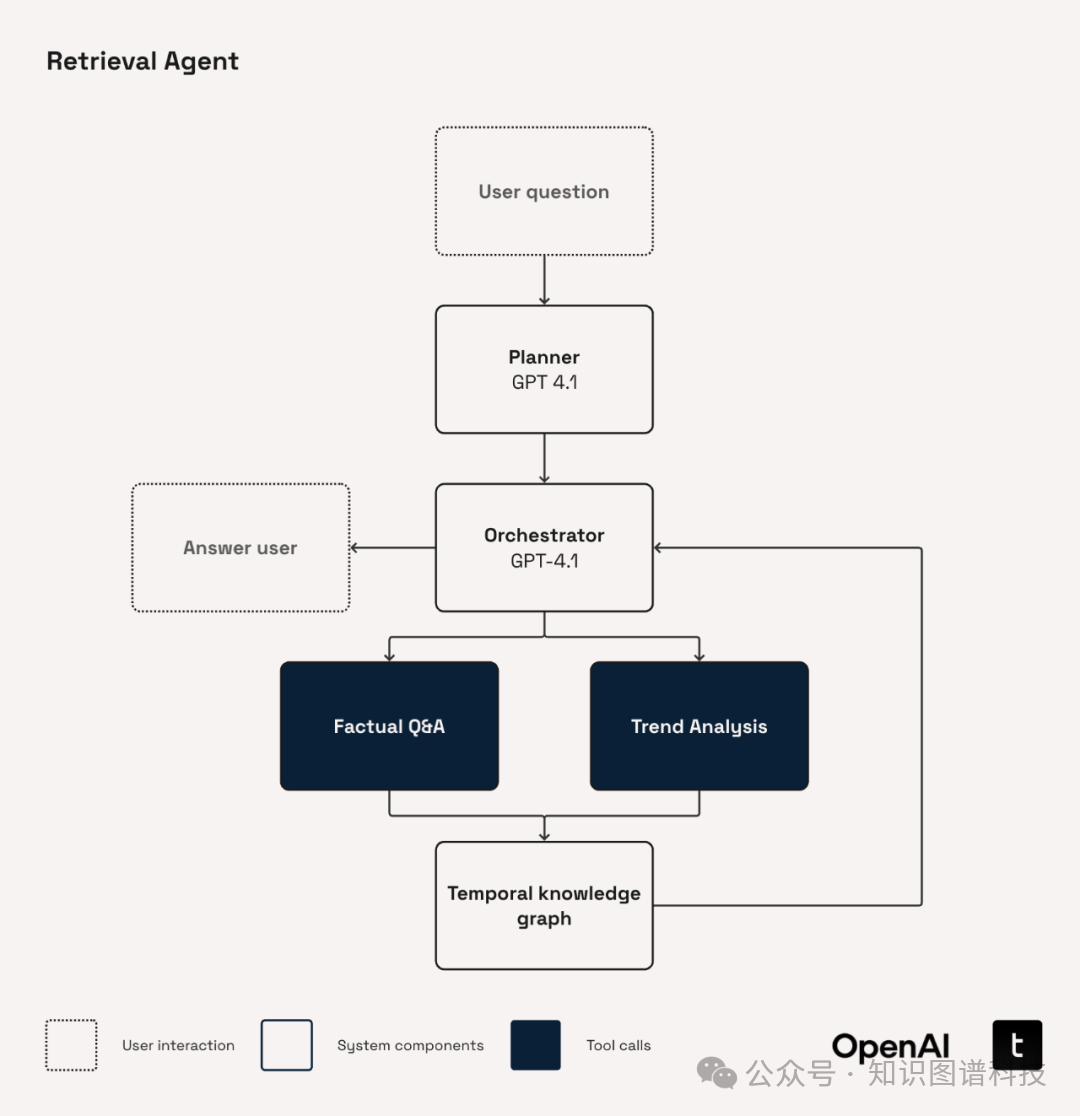
8.2 检索工具示例
-
factual_qa:指定实体、谓词、时间区间,检索所有匹配三元组
-
trend_analysis:批量对比多公司/指标演化,并调用o4-mini总结趋势
检索代码及工具注册见正文。
OpenAI开发了三个工具: “固定型工具”、“自由型工具”、以及“半结构化工具”,旨在有效地探索时态知识图谱并帮助回答用户的问题。
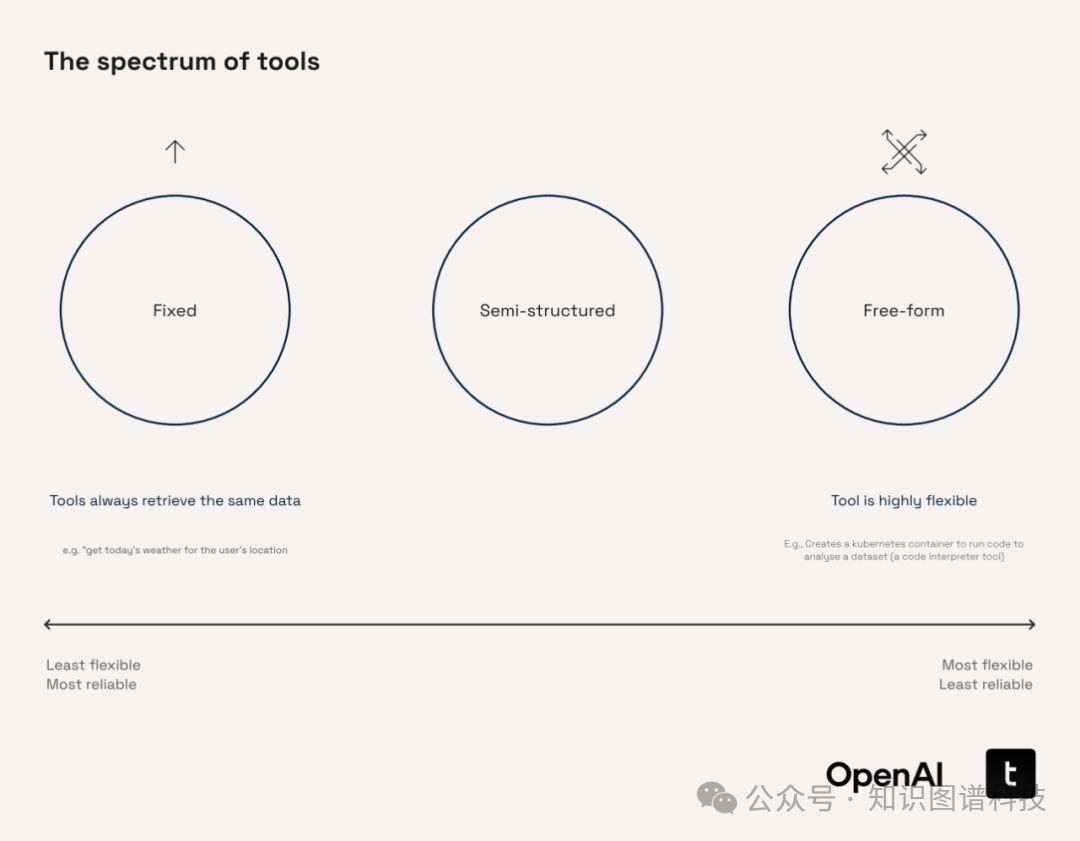
1. 固定型工具如汇率查询、药物不良反应检索、制造缺陷率统计,参数明确,功能固定,适合做结构化反复查询,但灵活性有限。
在这种情况下,“固定”工具是指具有严格、定义明确的功能的工具。通常,这些工具接受有限数量的特定参数并执行明确概述的任务。例如,固定工具可能会执行一个简单的查询,例如“获取用户位置的今天天气”。由于其结构化性质,这些工具擅长在 ERP 系统、监管框架或仪表板等结构化环境中执行一致的查找或监控值。然而,它们的刚性限制了灵活性,促使用户经常用更动态的传统数据管道替换它们,特别是对于连续数据流。
各行业固定工具的例子包括:
-
Finance金融
"What's the current exchange rate from USD to EUR?" “美元兑欧元的当前汇率是多少?”
-
Pharmaceuticals 药品
"Retrieve the known adverse effects for Drug ABC." “检索药物 ABC 的已知不良反应。”
-
Manufacturing 制造业
"What was the defect rate for batch #42?" “批次 #42 的缺陷率是多少?”
2.自由型工具如代码解释器,可以执行复杂开放的分析任务,比如自动回测策略、模拟设备运行、生成生物信息分析报告,但难以保证稳定和可控。
在工业应用中,自由格式工具样例如下所示:
-
Finance 金融
"Backtest this momentum trading strategy using ETF price data over the past 10 years, and plot the Sharpe ratio distribution." “使用过去 10 年的 ETF 价格数据回测这种动量交易策略,并绘制夏普比率分布。”
-
Automotive 汽车
"Given this raw telemetry log, identify patterns that indicate early brake failure and simulate outcomes under various terrain conditions." “鉴于此原始遥测日志,识别表明早期制动失灵的模式并模拟各种地形条件下的结果。”
-
Pharmaceuticals 药品
"Create a pipeline that filters for statistically significant gene upregulation from this dataset, then run gene set enrichment analysis and generate a publication-ready figure." “创建一个管道,从该数据集中过滤具有统计学意义的基因上调,然后运行基因集富集分析并生成可发表的数据。”
3. 而半结构化工具正是现代智能Agent系统的中坚。它们既有一定的结构输入(如JSON文本、参数列表),也支持嵌入智能推理和决策,可处理复杂查询、多步推理、批量摘要等任务。
比如金融行业用来提取前瞻性风险因素,汽车行业分析维修记录,医药领域定位特定基因信号等。
半结构化工具在生产落地时更易保证可控性与灵活性平衡,支持复杂多跳检索,是AI工具化未来的主流方向。
半结构化工具的行业应用包括:
-
Finance 金融
"Extract all forward-looking risk factors from company filings for Q2 2023." “从 2023 年第二季度的公司文件中提取所有前瞻性风险因素。”
-
Automotive 汽车
"Identify recurring electrical faults from maintenance logs across EV models launched after 2020." “从 2020 年之后推出的电动汽车车型的维护日志中识别反复出现的电气故障。”
-
Pharmaceuticals 药品
"Locate omics data supporting the hypothesis that a specific mRNA treatment effectively upregulates the IRS1 gene."“找到支持特定 mRNA 处理有效上调 IRS1 基因的假设的组学数据。”
8.3 Answer生成
最终Answer结构化返回所有用到的工具、参数、溯源记录,可直接对齐下游专业审计需求。
9. 评测与生产化最佳实践
-
人工标注Golden Answer作为准确性基线评估
-
LLM自动评测+synthetic answers可快速扩展评测集
-
用户端实时评分推进动态优化
-
强化学习微调(RFT)模式下,50个高质量标注即可驱动大模型推理能力跃升
生产化建议汇总:
-
主流方案推荐Neo4j替换NetworkX处理更大数据量
-
采用高性能图存储、数据分区、自动归档
-
全流程日志、异常检测、自动审计
-
用于金融、法律、制药等领域实现真实的数据追溯与长期合规
10. 结语及标签
本实践凭借大模型与时序知识图谱的结合,为企业级业务提供高效、透明、可追溯的结构化信息检索与自动化知识管理。逐步迭代并通过用户/专家反馈闭环,持续提升系统规模和智能水平,是未来AI知识管理落地的主流趋势。
这几本书籍的PDF版已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

之前商界有位名人说过:“站在风口,猪都能吹上天”。这几年,AI大模型领域百家争鸣,百舸争流,明显是这个时代下一个风口!
那如何学习大模型&AI产品经理?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 24
24 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)