DeepSeek开源周Day3:DeepGEMM-深度学习计算新标杆,300行代码释放FP8极致性能,全面加速MoE大模型训练推理
eepSeek 开源周第三日发布 DeepGEMM,这是专为 NVIDIA Hopper 架构优化的 FP8 矩阵乘法库。其核心代码仅约 300 行,却在性能上超越 CUTLASS 3.6。文中解析了 FP8 精度和 GEMM 的重要性,通过实测展示其在标准矩阵计算和 MoE 模型中的优化表现。介绍了架构创新,包括张量内存加速器和即时编译技术,以及针对 MoE 模型的专项优化。还提供了快速部署指南
·
项目地址:https://github.com/deepseek-ai/DeepEP
开源日历:2025-02-24起 每日9AM(北京时间)更新,持续五天 (3/5)!

一、开源背景
DeepGEMM是DeepSeek开源周第三日发布的重量级项目,作为专为NVIDIA Hopper架构优化的FP8矩阵乘法库,其核心代码仅约300行,却在多项测试中展现出超越CUTLASS 3.6的性能表现:
- 计算性能突破:在典型64×2112×7168矩阵运算中达到206 TFLOPS,带宽1688GB/s,较CUTLASS提升2.7倍
- MoE专属优化:针对混合专家模型的连续/掩码分组计算提速1.2倍
- 轻量级JIT设计:无需预编译,运行时自动优化,完美适配动态计算需求
二、技术解析
1. FP8精度革命
传统AI计算采用FP32/FP16浮点数,而FP8将存储位宽压缩至8位,在保持模型精度的同时:
- 内存占用减少50-75%
- 计算吞吐量提升2-4倍
- 能源效率显著提高
DeepGEMM特别针对Hopper架构的FP8 Tensor Core优化,通过CUDA核心二次累算解决精度损失问题。
2. GEMM
通用矩阵乘法(GEMM)是神经网络的核心操作,占据90%以上的计算时间。DeepGEMM通过以下创新实现突破:
- 非标准块划分:112×128等灵活块大小提升SM利用率
- 指令级优化:FFMA指令交织提升并行度
- 统一调度系统:增强缓存重用,减少内存访问
三、性能实测
标准矩阵计算性能对比
| 矩阵尺寸 (M×N×K) | 计算性能 (TFLOPS) | 内存带宽 (GB/s) | 加速比 |
|---|---|---|---|
| 64×2112×7168 | 206 | 1688 | 2.7x |
| 128×24576×1536 | 535 | 2448 | 1.6x |
| 4096×7168×16384 | 1358 | 343 | 1.2x |
MoE模型优化表现
| 计算类型 | 矩阵尺寸 (组×M×N×K) | 加速比 |
|---|---|---|
| 连续分组(训练) | 4×8192×4096×7168 | 1.2x |
| 掩码分组(推理) | 4×256×7168×2048 | 1.2x |
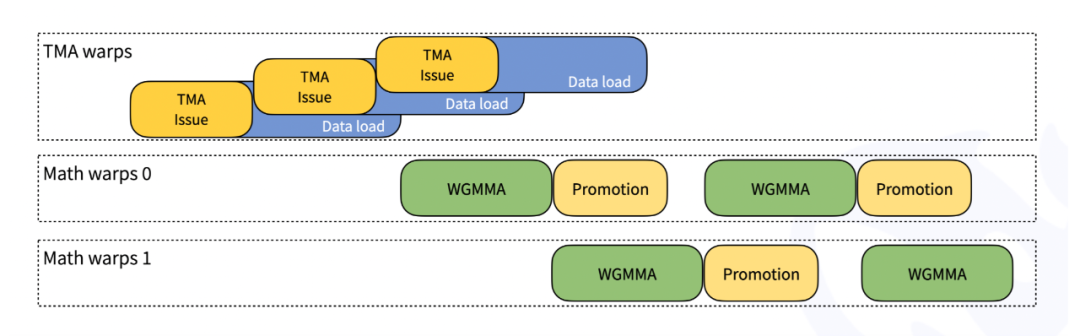
四、架构创新
1. 张量内存加速器(TMA)
- 异步数据搬运:LHS/RHS矩阵TMA加载
- 多播优化:单次加载多SM共享
- 描述符预取:隐藏指令延迟
2. 即时编译(JIT)技术
# 运行时自动优化示例
import deep_gemm
output = deep_gemm.gemm_fp8_fp8_bf16_nt(
lhs, rhs,
lhs_scale, rhs_scale,
M, N, K
)
- 动态编译:矩阵维度作为编译常量
- 自动参数选择:块大小、流水线级数等
- 完全展开:提升小矩阵性能
五、MoE模型专项优化
1. 两种数据布局
| 布局类型 | 适用场景 | 技术特点 |
|---|---|---|
| 连续分组 | 训练/批量推理 | 专家数据连续存储,TMA对齐 |
| 掩码分组 | 实时推理+CUDA图 | 动态掩码标记有效计算区域 |
2. 线程专业化设计
- 加载线程:专用TMA数据搬运
- 计算线程:Tensor Core矩阵运算
- 存储线程:结果回写与尺度恢复
三级流水线实现计算与IO的完美重叠。
六、快速部署指南
环境要求
- GPU: NVIDIA Hopper架构(H100/H800)
- CUDA: 12.8+
- Python: 3.8+
- PyTorch: 2.1+
安装步骤
git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git
python setup.py develop
python tests/test_jit.py # 验证JIT编译
核心API
# 标准GEMM
deep_gemm.gemm_fp8_fp8_bf16_nt(lhs, rhs, scales...)
# MoE连续分组
deep_gemm.m_grouped_gemm_nt_contiguous(...)
# MoE掩码分组
deep_gemm.m_grouped_gemm_nt_masked(...)
七、技术启示与展望
DeepGEMM的突破源自多项创新:
- 指令级微调:通过SASS汇编优化FFMA指令交织
- 非标准分块:112×128等灵活划分提升SM利用率
- 统一调度器:智能任务分配实现L2缓存复用
未来该库有望扩展支持更多硬件架构,并结合动态稀疏计算进一步优化MoE模型效率。其简洁的代码实现(核心仅300行)更为GPU优化提供了绝佳学习范本。
参考引用
专业术语解释
- 混合专家模型(MoE)
一种将复杂任务分配给多个专家模块进行处理的模型架构。类似于一个大型项目被分解给多个专业团队分别完成。 - FP8
一种将存储位宽压缩至 8 位的浮点数精度格式,在保持模型精度的同时减少内存占用、提升计算吞吐量和能源效率。类似于用更小的盒子装东西但不影响物品的重要性识别。 - GEMM(通用矩阵乘法)
是神经网络中的核心操作,占据大量计算时间。类似于建筑中的基石,支撑起整个结构。 - CUDA
一种并行计算平台和编程模型。类似于一个为计算机处理复杂任务提供的高效工具套装。 - Tensor Core
用于加速深度学习中矩阵运算的硬件单元。类似于工厂里专门用于快速处理特定产品的高效生产设备。 - 张量内存加速器(TMA)
用于加速数据搬运的硬件模块。类似于物流运输中的高速输送带。 - 即时编译(JIT)
一种在运行时根据特定条件进行编译优化的技术。类似于根据现场情况随时调整施工方案以达到最佳效果。 - 非标准块划分
采用不同于常规的矩阵块大小划分方式来提升计算效率。类似于不按常规尺寸切割物品,而是根据实际需求定制更合适的大小。 - 指令级优化
在指令层面进行优化以提高计算并行度。类似于对工人的每个具体操作动作进行优化以提高工作效率。 - 统一调度系统
对计算任务进行统一管理和分配的系统。类似于一个统一指挥多个施工队的调度中心。 - 线程专业化设计
将线程分为不同的专业类型,各自负责特定的任务。类似于将工人分为不同工种,各司其职。 - 连续分组
一种数据布局方式,专家数据连续存储。类似于把相关物品连续摆放。 - 掩码分组
一种数据布局方式,通过掩码标记有效计算区域。类似于给特定区域做标记以便进行针对性处理。
"真正的创新往往来自对基础计算的极致优化。"——DeepGEMM开发团队

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)