51c大模型~合集112
我自己的原文哦~ https://blog.51cto.com/whaosoft/13267449
#Guidance-Free Training (GFT)
无需引导采样,清华大学提出视觉模型训练新范式
引导采样 Classifier-Free Guidance(CFG)一直以来都是视觉生成模型中的关键技术。然而最近,清华大学 TSAIL 团队提出了一种极其简单的方法,实现了原生无需引导采样视觉模型的直接训练。他们在 Stable Diffusion,DiT,VAR,LlamaGen,MAR 五个截然不同的视觉架构上进行了验证,一致发现新方法性能与 CFG 相当,而采样成本减半。
- 算法名称:Guidance-Free Training (GFT)
- 论文链接:https://arxiv.org/abs/2501.15420

文生图任务中,免引导采样算法 GFT 与引导采样算法 CFG 均能大幅提升生成质量,而前者更为高效。

GFT 可通过调节采样时的「温度系数」来调节 diversity-fidelity trade-off

与此同时,GFT 算法保持了与 CFG 训练流程的高度一致,只需更改不到 10 行代码就可轻松实现。
视觉引导采样的问题与挑战
生成质量和多样性是相互牵制的关系。大语言模型(LLMs)主要通过将模型输出直接除以一个采样温度系数

来权衡二者,可明显提高生成质量。然而,早期研究却发现这类温度采样方法对视觉生成完全不起作用。如今,视觉生成依赖引入一个新的无条件模型,用引导采样(CFG)达到类似温度采样的效果:

然而,CFG 中引入的无条件模型却给视觉模型训练带来了种种掣肘,因为在每一个采样步我们都需要进行有条件和无条件两次模型推理,导致计算开销倍增。此外,在对预训练模型微调或进一步蒸馏时,我们也需要分别考虑有条件和无条件两个视觉模型的训练,这又增加了模型训练的开销及算法复杂度。
为了避免 CFG 引导采样导致的额外计算开销,已有的方法大多采用基于一个预训练好的 CFG 教师模型继续蒸馏的手段。但这引入了一个额外的训练阶段,可能会带来性能损失。
GFT 算法正是尝试解决这一问题。简单说,它实现了原生免 CFG 视觉模型从零训练,且有着和 CFG 相当的收敛速度,算法稳定性与采样表现。更重要的是,它足够简洁、通用。一种算法可同时用于扩散、自回归、掩码三种视觉模型。
Guidance Free Training 算法设计
GFT 完全采用了监督训练中的扩散损失函数。在训练中,其和 CFG 最大的不同是:GFT 并不显式参数化一个「有条件视觉模型」,而是将其表示为一个采样模型和一个无条件模型的线性组合:

这样在在我们训练这个「隐式」有条件模型时,我们本质上在直接训练其背后参数化好的采样模型。

论文证明,随着线性组合系数 β(又称「伪温度系数」)的变化,其对应的采样模型将和 CFG 算法定义的采样分布一一对应。
GFT 的算法灵魂:简单、高效、兼容
在实际部署中,由于 GFT 算法在设计上可以与 CFG 训练方法保持了高度对齐,这使得其可以最低成本被部署实现(<10 行代码),甚至不需要更改已有代码的训练超参数。

GFT 训练也非常高效,与 CFG 相比,它不需要任何额外的内存开销,只需增加约 20% 的训练时间,即可节约 50% 的采样成本。

此外,GFT 高度通用。不仅仅适用于扩散视觉模型,对于自回归、掩码这类离散视觉模型也同样适用:

实验验证
GFT 在扩散模型 DiT、Stable Diffusion,自回归模型 VAR,LlamaGen,掩码扩散模型 MAR 五个截然不同的模型上面分别进行了实验验证。
首先,研究者测试了 GFT 作为一个微调算法,把当下已有的 CFG 预训练模型转换为免引导采用模型的能力。发现在 FID 指标上,GFT 可以做到无损转换。


随后、研究者测试了 GFT 作为一个预训练算法,和 CFG 训练的比较(相同训练步)。


结果表明,GFT 训练出的免引导采用模型能力与 CFG 模型持平甚至更优。连损失函数收敛曲线也基本重合。
最后,论文还在不同模型上测试了 GFT 对于采样质量和多样性权衡曲线的控制能力。

作者介绍
本文有两位共同一作。陈华玉、清华大学计算机系四年级博士生。主要研究方向为强化学习与生成式模型。曾在 ICML/NeurIPS/ICLR 国际会议上发表多篇学术论文。是开源强化学习算法库「天授」的主要作者(Github 8k 星标)。导师为朱军教授。
姜凯、清华大学 TSAIL 团队实习生,主要研究方向为视觉生成模型。导师为陈键飞副教授。
....
#Generative Reasoning Re-ranker
生成式推理再排序,可能会是LLM4RecSys的新突破口吗?
大模型(LLM)的世界知识和推理能力是实现下一代推荐系统,即基于大模型的推荐系统(LLM4Recsys)的重要基石。来自meta ai的研究者们尝试将推理模型引入再排序阶段,推荐系统的最后一环。
推荐系统需要推理模型吗?
深度学习成为推荐系统的标准范式已经有十年左右的历史。RNN/Transformer/GNN等模型在用户交互数据上的性能已经被开发得非常接近饱和。正如近些年大语言模型,尤其是推理模型在通用任务上的优异性能所揭示得,让推荐系统先思考再做出决定或许可以再次突破现有框架的性能上限;同时,还能为推荐的结果提供一定的可解释性。
论文通过监督微调(SFT)和强化学习(RL)来赋予通用推理模型在序列推荐任务上的推理能力。提出的训练策略最终超过了LLM4Recsys标杆,OneRec-Think;提升了约2.4%Recall@5和约1.3%NDCG@5。


● 论文标题:Generative Reasoning Re-ranker
● 论文地址:https://arxiv.org/pdf/2602.07774
中期训练,内化物品的语意ID
语意ID(semantic ID,SID)已经成为基于序列模型的推荐系统的标准技术之一,它的核心想法是通过多层次的聚类来赋予物品从粗到细粒度的标签。常用的模型一般有Residual-Quantized Variational Autoencoder(RQ-VAE)和RQ-Kmeans;这篇论文使用的是RQ-VAE,并且基于常规的对比学习损失函数。同时,为了防止码本坍缩,即有多个物品会被同时映射到一个SID的情况,本文采用了成熟的处理方案,用RQ-Kmeans先做初始化,结合EMA平滑更新字典,重置死码本,加入多样性损失函数,并且对最后一至两位SID赋予随机整数。
本文的中期训练采用的策略和OneRec-Think保持一致,将生成的SID混入自然语言组成的物品描述、物品预测等一系列任务中,去最小化next token prediction loss以优化SID的embedding来内化物品的本身语意。
推理路径的生成
推理路径(Reasoning trace)的生成是本文的核心技术之一。预训练的推理模型并不具有(很强的)对物品序列的推理和解释能力,尤其是考虑到在现实场景中需要实际部署时受限于延迟限制,LLM的体量有限,例如仅仅能支持最大8B。
论文的核心想法是将大体量的LLM(比如32B模型)的推理能力蒸馏给小体量的LLM:即大LLM产生高质量的推理路径,再让小LLM去学习以增强其在推荐场景下的推理能力。目标采样(target sampling)和拒绝采样(reject sampling)两种技术被使用了:

目标采样的核心想法就是把交互历史和下一个真实交互物品的信息都交给LLM以生成解释。该解释就被作为reasoning trace。

拒绝采样则是只将交互历史提供给LLM以预测下一个交互的物品以及生成解释。一旦预测的结果和数据集的标准答案(ground truth)不一致,则继续重复推理直到答对或者达到设定的最多重复推理次数。
这两种推理路径的生成方式各有优劣:
- 目标采样对每一个样本只需要推理一次,但是LLM可能会“牵强附会”,做“马后炮”式的解释。
- 拒绝采样生成的reasoning trace一般质量更高,因为错误的reasoning trace很可能没法引导出正确的答案,而采样过程又会一直持续到得到正确的答案为止。缺点也很显然,对单一样本需要多次推理,尤其是一些难的样本。
推理赋能的再排序阶段
开头提过,论文重点关注再排序(re-ranking)阶段。该阶段在常规业界推荐漏斗中位于最后一环,以检索(retrieval)和排序(ranking)阶段的输出作为输入。作为学术研究,为了保持整个pipeline简洁,论文将LLM本身预先作为retriever,输入交互历史,预测下一个最有可能的物品,采用beam search生成排序过的候选列表。再将该候选列表和交互历史一同输入LLM去做重排序。
为了赋于小体量LLM(比如8B)完整的贴合推荐场景的推理能力,上一步生成的推理路径先通过SFT手把手教给模型,这一步可以保证LLM的推理能力的下限。

为了进一步提高模型的推理能力,强化学习配合推荐场景设计的reward在本文中被使用。在再排序场景下,显然,目标物品的排序被模型提升的越多,模型的表现越好;这就是排序奖励:

它测量的是经过模型重排序以后目标物品的排位变化。
另一种常见的奖励则是格式奖励,即LLM的输出还是保持着reasoning trace加最终答案,即排序过的列表,的理想格式。然而,简单地将格式奖励和任务相关的排序奖励加和成最终奖励在再排序任务中不可行,原因是预排序的候选列表是作为模型输入的,模型可以通过完全不改变候选列表来放弃排序奖励,而单纯hack格式奖励。基于此,最终的格式奖励被设计成只有排序奖励为正的时候才会被考虑。该奖励被嵌入在DAPO优化框架中去更新LLM的参数。

重排序的提升空间
论文的最重要实验结果披露出,重排序阶段引入推理能力,尤其是通过强化学习增强,可以进一步提升性能上限。具体实验对比了(1)该模型的预排序结果(Pre-rank),(2)仅依靠SFT训练过得排序结果,和(3)强化学习进一步增强过的排序结果:

有一些有趣的发现:
- SFT可以给模型一定的推理能力,但是单单依靠SFT可能会伤害模型最终的准确度。
- 没有SFT直接通过强化学习(RL-zeroshot)并不能直接带来显著性能提升。
- 拒绝采样相比目标采样能获得更高质量的推理路径。
下一步?
这篇论文的有趣之处在于,它不仅仅提供了~2%的Recall性能提升,而是提供了一种新的范式:模型不再是去单纯拟合交互的概率分布,而是去拟合推理路径和交互的联合分布。
同时也不可否认的是,重排序阶段是应用推理模型的好场所,因为该阶段剩下的候选物品是整个推荐漏斗中最少的了。模型在给予候选集的情况下逐一比较、推理,符合人类的思维流程。
那么,在检索和排序阶段,候选集大小成千上万的情况下,如何有效率地进行超大规模的候选集筛选?如何把海量的候选集有效率地塞入推理模型有限的输入窗口?如何控制昂贵的推理成本?如何满足用户体验所需要的超低时限?此外,现有策略也依赖拒绝采样生成的高质量推理路径,这在候选集超大的情况下所需要的重采样次数将完全不可接受,样本的效率将成为训练成败的关键因素。
....
#GR4AD
快手广告系统全面迈入生成式推荐时代!从Token到Revenue的全链路重构
当推荐系统遇上大模型范式,广告变现的天花板被再次打破。快手提出 GR4AD,作为国内生成式推荐在大规模广告场景下的首次全量落地,实现广告收入提升 4.2%,服务 4 亿 + 用户。
论文链接:https://arxiv.org/pdf/2602.22732
一、引言:"推荐该怎么做" 的新范式
过去十年,深度学习推荐模型(DLRM)几乎统治了整个工业界的推荐系统 —— 从召回到排序,从特征交叉到序列建模,它们构建了一套成熟而稳固的技术栈。然而,当大语言模型(LLM)的浪潮席卷而来,一个大胆的问题被抛了出来:
能不能像生成文本一样,直接 "生成" 推荐结果?
这就是生成式推荐(Generative Recommendation)的核心思想。以 TIGER、OneRec 为代表的一系列工作,已经在自然推荐场景中验证了这一范式的可行性。但当战场转移到大规模广告系统 —— 这个对时延、收益、商业价值都有极致要求的领域 —— 事情变得远没有那么直接。
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。
二、问题与挑战:广告场景下的三大挑战
论文开篇就旗帜鲜明地指出:直接把 LLM 那套训练和推理范式搬到广告推荐上,是行不通的。 具体来说,广告场景存在三个独有的核心挑战:
挑战一:广告物料的 Token 化 —— 多元信息的统一编码
广告不是普通的短视频。一条广告背后融合了视频创意、商品详情、广告主 B 端元数据等多模态、多粒度信息。更棘手的是,平台还提供了转化类型、广告账户等关键业务信号,这些信号具备强烈的商业价值但几乎没有 "语义内容" 可言。如何为广告物料打造一套既能捕获语义内容、又能编码业务信息的统一 Token 体系?
挑战二:学习范式 —— 面向商业价值的列表级优化
广告推荐的优化目标不是 "猜中用户会点哪个" 那么简单,而是要在 eCPM 排序、NDCG 等列表级指标下最大化商业价值。现有的生成式推荐方法大多沿用 LLM 的分阶段训练方式,不完全适配大规模推荐场景的持续在线学习,且缺乏面向排序的、列表级的学习设计。
挑战三:实时服务 —— 多候选生成的算力困局
不同于 LLM 聊天场景中 "解码一条回复、容忍较长延迟" 的模式,广告系统需要在极高 QPS 和极低延迟(<100ms)下,通过 Beam Search 同时生成大量高质量候选。这是一个与 LLM 不同的推理优化问题。
三、方法:全链路协同设计的破局之道
GR4AD 的方法论可以用一句话概括:"表征 - 学习 - 推理" 三位一体的推荐原生设计。 下面逐一拆解。

3.1 统一广告语义 ID(UA-SID):给广告一个 "身份证"
核心思想: 用一个端到端微调的多模态大模型(MLLM)为每条广告生成统一嵌入,再通过精心设计的量化方法将其编码为离散 Semantic ID。

第一步:统一广告嵌入(UAE)
- 指令微调(Instruction Tuning):针对快手广告的 6 种典型形态(直播、商品、达人等),设计了 6 套提示模板,引导 MLLM 从不同视角理解广告内容。比如对直播类广告,引导模型分析主播画像和地域特征;对外部投放广告,则聚焦产品行业和品牌信息。
- 共现学习(Co-occurrence Learning):用户行为中的共现关系蕴含了丰富的协同信号。论文使用 Swing 方法估计物料共现强度,并采用 InfoNCE 对比学习目标将其注入表征:

第二步:MGMR RQ-Kmeans 量化
这是 UA-SID 的 "杀手锏"。论文提出了多粒度 - 多分辨率(Multi-Granularity-Multi-Resolution)的 RQ-Kmeans 量化策略:
- 多分辨率(MR):低层级使用更大的码本捕获主导语义因子,高层级用较小码本建模低熵残差,有效提升码本利用率。
- 多粒度(MG):在最后一层用基于非语义特征的哈希映射替代向量量化 —— 将转化类型、账户 ID 等业务信号直接编码进 SID,一举解决 "相同内容、不同投放策略" 导致的 SID 碰撞问题。
最终每个广告物料被映射为一个离散 UA-SID 序列:

3.2 LazyAR:懒惰解码器的大智慧
生成式推荐在推理时需要通过 Beam Search 生成多个候选 SID 序列。标准自回归解码要求每一层都依赖上一步的输出,这在 Beam 数很大时造成了巨大的计算瓶颈。
论文的一个关键观察是:第一层 SID 最难学、损失最大,但它的 Beam 只有 1(从 BOS 开始);后续层级更容易,Beam 却呈指数级膨胀。 大部分计算被浪费在了 "简单的事情" 上。

LazyAR 的核心操作: 将对上一步 token 的依赖 "延迟" 到中间某一层(第 K 层)注入:
- 前 K 层(并行层):不依赖上一步 token,仅基于位置编码和上下文 X 进行计算,所有层级和所有 Beam 可以并行计算并共享。
- 后 L-K 层(自回归层):注入上一步 SID 嵌入后进行标准自回归解码。
为什么 LazyAR 有效?
1. 第一层 SID 的解码过程完全不受影响(从 BOS 经过全部 L 层)。
2. 前 K 层在潜空间中进行推理,能编码关于候选 token 的有用信号。
3. 引入 MTP 辅助损失,强制前 K 层即使没有上一步 token 也能学到足够信息。
4. K 是可调超参,提供灵活的精度 - 效率权衡。实验中

在保持推荐质量的同时将推理吞吐量翻倍。
论文特别指出:这个设计是推荐原生的,不适用于标准 LLM 解码 —— 因为 LLM 解码通常不用 Beam Search,且后续 token 的预测难度不一定下降。
3.3 价值感知的监督学习(VSL)
在广告场景中,不同样本的商业价值天差地别。VSL 围绕 "价值感知" 做了三件事:
① SID + eCPM 联合预测: 在标准 SID 交叉熵损失之外,将 eCPM 离散化为桶并追加为额外的预测 token:

② 价值感知样本加权: 每个样本的权重
![]()
,高广告价值用户和深度交互行为(如购买)获得更高权重。
③ MTP 辅助损失: 配合 LazyAR,强制前 K 层并行解码的表征质量。
最终 VSL 目标:

3.4 排序引导的强化学习(RSPO):从 "学分布" 到 "优排序"
VSL 能拟合历史数据分布,但它不直接优化下游排序目标,也不支持对未知标签分布的探索。论文因此引入了 RSPO(Ranking-Guided Softmax Preference Optimization),一个面向列表级 NDCG 优化的 RL 算法。
RSPO 的核心 loss:

其中
![]()
遵循 Lambda 框架,论文证明了 RSPO 是 NDCGcost 的上界,从理论上保证了对排序指标的直接优化。
几个精妙的工程设计:
- 参考模型的可靠性门控
-

- : 样本来源多样(有些来自 GR4AD 自身、有些来自其他 pipeline),
-

- 不总是可靠的。当模型与参考分布偏差过大时,自动关闭参考约束,避免噪声正则化。
- VSL 与 RSPO 的统一在线训练:通过样本级对齐分数动态调整两个目标的权重 —— 模型排序与奖励排序偏差大时加重 VSL(学好基础分布),偏差小时加重 RSPO(精细化价值优化)。
四、线上部署:工业级系统的全闭环设计
GR4AD(0.16B 参数)已全量部署于快手广告系统,实现了一套 “奖励估计 → 在线学习 → 实时索引 → 实时服务” 的完整闭环。

4.1 四大核心模块
- 奖励系统(Reward System):训练独立的 Reward Model 对 GR4AD 生成的候选集进行 eCPM 评分,在放松延迟约束的环境下进行更大 Beam 的探索,为 RL 训练提供高质量信号。
- 在线学习模块:实时构建 VSL 和 RL 两种训练信号,持续进行 mini-batch 更新,实时推送参数到推理服务。
- 实时索引模块:用 SID 替代传统嵌入索引。新物料到达时只需计算 UA-SID 并更新双向索引(UA-SID ↔ Item ID),秒级生效,大幅改善冷启动覆盖和时效性。
- 实时服务引擎:处理用户请求并返回排序广告列表。
4.2 推理效率优化:把算力用在刀刃上
动态 Beam 服务(DBS)是本文的又一亮点,包含两个子机制:
- 动态 Beam 宽度(DBW):用递增的 Beam 调度(如 128→256→512)替代固定宽度(512→512→512),在不损失最终候选质量的前提下大幅削减中间层计算。
- 流量感知自适应 Beam 搜索(TABS):根据实时 QPS 自动调整 Beam 规模 —— 低峰期加大 Beam 提升推荐质量,高峰期收缩 Beam 保障延迟和吞吐。
此外还有一系列工程优化:Beam 共享 KV Cache:将 Beam 从 batch 维度转移至序列维度进行组织,实现 KV Cache 的共享,显著提升内存访问效率(+212.5% QPS)、TopK 预裁剪:先并行选取每个 Beam 的 K 个候选结果,再对聚合候选集进行全局 Top-K 选择,在有效缩减搜索空间的同时保证准确性(+184.8% QPS)、FP8 低精度推理(+50.3% QPS)、短 TTL 结果缓存(+27.8% QPS)。
最终效果:<100ms 延迟,500+ QPS/L20 GPU。
五、实验效果:广告收入和推理性能的双赢
5.1 总体性能与消融实验

几个关键发现:
- RSPO 是所有优化中增益最大的单一组件,显著优于 DPO 和 GRPO,验证了列表级 RL 在广告场景的不可替代性。
- LazyAR 以极微小的精度代价换来了吞吐量翻倍,是实际部署的关键使能技术,优于 DeepSeek-MTP。
- DBS 在不损失收益的前提下进一步提升了效率,TABS 机制在低峰期还能反向提升收入。
5.2 Scaling Law

模型规模方向:从 0.03B 到 0.32B,收入提升从 + 2.13% 单调增长到 + 4.43%,训练损失也持续下降。生成式广告推荐的 Scaling Law 是成立的。
推理规模方向:Beam 宽度从 128 增加到 1024,收入从 + 2.33% 提升到 + 4.21%。这意味着更强的推理时搜索能进一步释放模型潜力 —— 这与当前 LLM 领域 Test-time Scaling 的趋势遥相呼应。
5.3 UA-SID 质量

在嵌入质量评估(photo-to-photo recall)中,经过指令微调和共现学习的 UAE 达到了 R@1=0.896,远超基线 QARM(0.541)和原始 Qwen3-VL-7B(0.769)。MGMR 量化将 SID 碰撞率从 85.44% 降至 18.26%,码本利用率提升 3 倍以上。
5.4 商业指标的全面胜利
- 商业化广告收入 4.2%+
- 中小广告主投放量提升 17.5%
- 广告转化率提升 10.17%
- 低活用户转化率提升 7.28%
基于内容的 SID 带来的更强泛化能力和更实时的索引对冷启动物料的更好支持,实现了平台、广告主、用户的三赢。
六、总结与思考
GR4AD 这篇论文的价值,不仅在于它达成了 4.2% 的收入提升这个数字,更在于它系统性地回答了一个关键问题:生成式推荐在广告这个最 "硬核" 的工业场景中,到底应该怎么做?
它的答案是:不要照搬 LLM,要做推荐原生的设计。
- Token 化不能只看内容语义,要把业务信号编码进去(UA-SID + MGMR)。
- 训练不能只做单点概率生成,要做价值感知的列表级优化(VSL + RSPO)。
- 推理不能只套用 LLM 加速技巧,要针对 "短序列、多候选、Beam Search" 的推荐特性做专门设计(LazyAR + DBS)。
- 系统不能离线批处理,要做实时索引、在线学习、闭环反馈的全链路打通。
GR4AD 是生成式推荐走向广告工业核心场景的一个重要里程碑。 快手用超过 4 亿用户的真实流量验证了这条路径的可行性。可以预见,接下来会有更多广告平台跟进这一范式。
....
#SparseRL
中科院团队提出新框架「SparseRL」,深度强化学习可自动生成高性能CUDA代码
如何让 AI 不仅写出「能跑」的代码,还能写出「跑得快」的代码?这个问题困扰了 AI 系统研究者很久。
近日,中科院计算所团队提出了一种名为 SparseRL 的新框架,首次将深度强化学习引入稀疏 CUDA 代码生成任务。简单来说,就是让 AI 学会根据稀疏矩阵的结构,自动生成最优的 CUDA 实现代码。
实验显示,在经典的 SpMV 任务上,这种方法能让编译成功率提升 20%,代码执行速度提升 30%。
目前,该项成果已入选 ICLR 2026 Oral。
- 论文地址:https://openreview.net/pdf?id=VdLEaGPYWT
- 代码链接:https://github.com/QiWu-NCIC/SparseRL
为什么稀疏代码这么难写?
要理解这项工作的价值,得先说说稀疏矩阵运算的特殊性。
稀疏矩阵在 LLM 推理、图神经网络、科学计算中无处不在。但和稠密矩阵不同,稀疏矩阵的非零元素分布是不规则的,这导致一个核心问题:最优的 CUDA 代码实现取决于矩阵的具体结构,而这个结构只有在运行时才能知道。
换句话说,没有一种「万能」的高性能实现能应对所有稀疏矩阵。工程师们不得不针对不同的稀疏模式手动调优,这个过程既耗时又依赖经验。
现有的 AI 代码生成方法也帮不上太大忙。原因有三:
- 第一,传统监督学习只关心代码「对不对」,不关心「快不快」。同一个稀疏矩阵可能有多种正确的 CUDA 实现,但执行速度可能相差数倍,监督学习无法区分这种差异。
- 第二,执行效率这个核心指标是「不可微」的,没法通过传统的反向传播来优化。
- 第三,稀疏矩阵的输入(行列索引序列)和 CUDA 代码之间存在巨大的语义鸿沟,模型很难理解矩阵结构和最优代码策略之间的关联。

图片 1:展示不同稀疏矩阵需要不同 CUDA 实现策略的示例
SparseRL 怎么做到的?
研究团队的思路很巧妙:既然执行效率不可微,那就用强化学习来优化。
SparseRL 把预训练语言模型当作一个策略网络,每生成一个 token 就是一次动作,而代码的编译结果和执行时间就是奖励信号。
整个训练过程分为三个阶段:
- 第一阶段是预训练:在大量 CUDA 代码语料上训练语言模型,让它建立对 GPU 编程的基础认知;
- 第二阶段是监督微调:用「稀疏矩阵 - 正确代码」的配对数据教模型生成语法正确、功能正确的代码;
- 第三阶段是强化学习优化:这一步是关键 —— 引入深度强化学习,以编译正确性和执行效率为奖励,让模型学会生成高性能代码。

图片 2:展示三阶段训练流程的整体框架图
为了让模型真正「看懂」稀疏矩阵的结构,研究团队设计了一个关键技术:正弦位置嵌入。
稀疏矩阵的输入是非零元素的行列索引序列,传统的 token 嵌入无法捕捉这种二维坐标之间的空间关系。SparseRL 对行列索引分别进行正弦 / 余弦编码,类似于 Transformer 的位置编码,但专门针对二维坐标做了定制。
用通俗的话说,这就像给模型装上了一副「坐标眼镜」,让它能看见非零元素在哪里、是怎么分布的。
另一个核心创新是层级奖励函数。这个奖励函数同时考虑两个层面:正确性奖励确保代码能编译、结果正确;效率奖励则优化执行速度。设计逻辑是先保证「对」,再追求「快」。
效果如何?
研究团队在 SpMV(稀疏矩阵 - 向量乘法)和 SpMM(稀疏矩阵 - 稠密矩阵乘法)两个任务上验证了方法的有效性。
在 SpMV 任务上,SparseRL 相比传统监督学习方法,编译成功率提升了 20%,平均执行速度提升了 30%。更重要的是,模型能根据不同的稀疏结构自动选择不同的代码策略,在对角型、带状型、随机稀疏型等多种矩阵上都有优势,部分场景下生成的代码甚至接近或超越了手工调优的水平。

图片 3:展示 SparseRL 与基线方法的差距
团队还做了消融实验来验证各个组件的必要性。
结果显示,去掉 RL 阶段后性能显著下降,说明强化学习确实是关键;去掉正弦嵌入后模型难以理解输入结构,编译率下降;只用正确性奖励而不用效率奖励,代码能跑但不够快。
当然,这个方法也有局限。论文提到,RL 训练需要大量的编译 - 执行反馈循环,计算成本较高;模型是针对特定 GPU 架构训练的,迁移到新硬件可能需要重新微调;生成的代码可能缺乏人类工程师的编码风格,可解释性不足。
意义与展望
SparseRL 的价值在于它代表了一个范式转变:代码生成的目标从「生成能运行的代码」转向「生成高性能代码」。
对于 HPC 工程师和 AI 基础设施开发者来说,这项工作展示了一种新可能 —— 让 AI 来处理那些繁琐的性能优化工作,而人类可以把精力放在更高层次的设计上。
研究团队表示,未来计划将方法扩展到多 GPU 分布式稀疏计算,探索与传统 AutoTuning 技术的结合,并支持更多类型的稀疏算子。同时,他们也在研究如何降低 RL 训练成本,让这种方法更实用。
....
#STC(Streaming Token Compression,流式 Token 压缩
上交 EPIC Lab 提出 Token 级流式视频即插即用 2 倍无损加速方案!
在人工智能迈向实时交互的今天,流式视频理解(Streaming Video Understanding, SVU)正成为大模型应用的新战场。无论是体育赛事的即时解说,还是 AR 眼镜的实时视觉辅助,都要求模型能够“边看边说”,且延迟极低。然而,现有的视频大模型(VideoLLMs)在处理连续视频流时,往往面临着严重的计算瓶颈。
为了攻克这一难题,来自上海交通大学 EPIC Lab、四川大学、华中科技大学、中山大学以及香港科技大学(广州)的研究团队联合提出了一种名为 STC(Streaming Token Compression,流式 Token 压缩)的即插即用分层加速框架,它通过在视觉编码器和语言模型预填充两个阶段进行分层压缩,精准剔除视频流中的冗余信息,旨在让模型在处理长视频流时依然能保持“轻盈”的体态。
- 论文地址: https://arxiv.org/abs/2512.00891
- 代码仓库: https://github.com/lern-to-write/STC(已开源)
- 共同一作:王一宇、刘旭洋
- 通讯作者:张林峰(上海交通大学人工智能学院)
- 录用信息: CVPR 2026
为什么视频大模型总是“慢半拍”?
在深入技术细节之前,我们先聊聊为什么目前的视频理解模型很难做到真正的实时。
研究团队通过实验发现了一个被长期忽视的痛点:在图像理解任务中,视觉编码器(Vision Transformer, ViT)的耗时占比并不算高;但在视频理解中,由于流式视频需要高频采样,模型必须对每一帧都进行完整的 ViT 推理,这导致 ViT 编码的开销激增到图像任务的 2-3 倍。
推理时间分布图
更糟糕的是,随着视频时间的推移,喂给大语言模型(LLM)的视觉 Token 序列会变得极其漫长。比如处理一段 64 帧的视频,LLM 需要处理数千个 Token,这直接导致了预填充(Prefilling)阶段的巨大延迟。
然而,这些计算中其实藏着大量的“水分”。研究者观察到,流式视频相邻帧之间的余弦相似度极高(甚至超过 0.85),这意味着大部分计算都在处理重复的背景或静止物体。现有的压缩方法(如 ToMe 或 SparseVLM)要么破坏了编码过程,要么依赖于全局视频信息,这在“边看边算”的流式场景下是行不通的,因为模型无法预知未来的画面。
时间冗余分析图
STC 框架:两手抓,两手都要硬
针对上述瓶颈,STC 框架巧妙地设计了两个互补的模块:STC-Cacher 和 STC-Pruner。它们分别在视觉编码的“内部”和“出口”处进行瘦身。
STC 框架总览
STC-Cacher:ViT 内部的选择性重计算
STC-Cacher 的核心思想是:既然相邻帧长得差不多,那我们就只算“动”的部分,静止的部分直接复用之前的缓存。
具体流程如下:
- 参考帧全量计算:每隔 帧设置一个参考帧,进行完整的 ViT 前向传播,并将中间层的 Key(K)、Value(V)等特征缓存起来。
- 非参考帧选择性更新:对于后续帧,模型不再进行全量计算。它首先计算当前帧与参考帧的 Key 向量相似度:
- 识别动态 Token:选出相似度最低(即变化最大)的 Top-k 个 Token 作为“动态 Token”。
- 散射更新(Scatter-Update):模型只对这些动态 Token 进行 Query 和 Value 的计算,然后将结果像“打补丁”一样更新到之前的缓存矩阵中。
这种方法在不损失关键视觉细节的前提下,大幅削减了 ViT 的冗余计算量。
STC-Cacher 机制详解
STC-Cacher 可视化效果
从可视化结果可以看出,STC-Cacher 能够精准捕捉到画面中运动的物体(如行驶的车辆、走动的人物),而对静止的背景则保持复用状态。
STC-Pruner:进入 LLM 前的“双锚点”剪枝
当视觉特征提取完后,STC-Pruner 会在它们进入 LLM 之前再做一次筛选。
在流式场景下,我们面临两个挑战:不知道用户的提问(Query-agnostic),也不知道未来的画面(Future-agnostic)。为了在“盲盒”状态下准确判断 Token 的重要性,STC 提出了双锚点(Dual-Anchor)策略:
- 时间上下文锚点 (Temporal Context Anchor, TCA):代表历史背景的平均特征,反映了过去一段时间的整体信息。
- 空间上下文锚点 (Spatial Context Anchor, SCA):代表当前帧全局背景的平均特征。
模型会计算每个 Token 与这两个锚点的联合差异得分:
这里的逻辑非常直观:如果一个 Token 既不同于历史背景,也不同于当前帧的全局背景,说明它携带了极其重要的“新信息”。只有高分的 Token 才能获得进入 LLM 的“门票”。
STC-Pruner 机制详解
实验结果:速度飞起,性能几乎不掉点
研究团队在 OVO-Bench、StreamingBench 等五个主流基准测试上对 STC 进行了全面评估。实验覆盖了端到端在线模型(如 Dispider, StreamForest)和离线转在线框架(如 ReKV)。
结果令人振奋:
- 性能保留:STC 在大幅压缩的情况下,保留了高达 99% 的原始性能。
- 延迟锐减:在端到端模型 StreamForest 上,STC-Cacher 将 ViT 编码延迟降低了 34.7%。
- 全链路加速:在 ReKV 框架下,STC 联合优化使 LLM 预填充延迟降低了 46.3%,几乎砍掉了一半。
OVO-Bench 实验结果
在长视频理解任务(如 EgoSchema, VideoMME)中,STC 同样表现出色,证明了其在处理超长上下文时的鲁棒性。
长视频理解结果
为什么 Key 状态最适合做评估?
在消融实验中,研究团队对比了使用不同特征(Feature, Value, Key)进行动态 Token 评估的效果。结果显示,使用 Key 状态的效果最好。这是因为 Key 向量包含了最丰富的信息量,能够更准确地反映 Token 在注意力机制中的历史相关性和重要程度。
Token 评估策略消融实验
写在最后
STC 揭示了视频理解的一个本质:信息密度是不均匀的。在连续的视频流中,真正关键的瞬间转瞬即逝,而大量的背景和静止画面占据了无效的算力。
通过 STC-Cacher 这种“只算变量”的思路,以及 STC-Pruner 这种“双锚点”的筛选准则,我们离真正的实时 AI 助理又近了一步。这种分层压缩的思想,或许也会成为未来多模态大模型走向边缘端、走向实时交互的标准配置。如果你正苦于视频大模型的推理延迟,不妨去试试这个开源项目,看看它能为你的模型带来多大的“瘦身”效果。
....
#Variation-aware Vision Token Dropping for Faster Large Vision-Language Models
从视觉Token内在变化量出发,实现VLM无损加速1.87倍
作者介绍:第一作者陈骏杰(四川大学硕士二年级)与共同一作刘旭洋(四川大学硕士三年级)深耕高效视觉语言模型。
论文题目:Variation-aware Vision Token Dropping for Faster Large Vision-Language Models
论文链接:https://arxiv.org/abs/2509.01552
代码链接:https://github.com/xuyang-liu16/V2Drop
背景与动机
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
一是位置偏差问题(如图 1 所示),该方法倾向于机械地保留序列末尾的 Token,无论图像内容如何,注意力得分普遍在序列末尾(对应图像底部区域)形成峰值(红色箭头),导致关键的前期 Token 被丢弃,进而加剧多模态幻觉。
二是与高效算子存在根本性的不兼容,计算注意力权重与 FlashAttention 等高效机制之间存在本质冲突。相比之下,右侧三列(绿色边框)展示了基于 L2 Norm 变化量评估方法的显著优势 —— 其得分分布均匀、能够精准聚焦于含有关键信息的图像区域(如绿色框标注的球衣号码区域),且无需显式注意力计算,与高效算子天然兼容。

图 1:注意力引导 vs. 变化量感知的 Token 评估对比
核心发现
发现 1:注意力方法存在系统性末端偏置
研究团队在 LLaVA-1.5-7B 和 Qwen2-VL-7B 上,对比了 SparseVLM、FastV 与 L2 Norm 变化量评估在相同输入下的 Token 保留行为。注意力方法的保留概率曲线均呈单调递增阶梯形状 —— 末端 Token 保留率高达 80%~100%,前端仅 10%~30%,与内容重要性毫无关联。L2 Norm 则呈近似均匀分布,天然规避位置偏差。

图 2:两大模型上视觉 Token 保留位置分布分析 ——L2 Norm 呈现均匀分布,注意力方法呈严重末端偏置
发现 2:变化量高的 Token 天然对应语义关键区域
针对两个典型样本(百事可乐瓶识别、球衣号码识别),L1 Norm、L2 Norm 和余弦相似度三种指标均在答案相关区域出现显著峰值,且无论关键区域位于序列中段还是后段均能精准捕捉,表明变化量是衡量视觉 Token 重要性的鲁棒内在属性,L2 Norm 综合性能最优,被 V²Drop 选为默认度量。

图 3:三种变化量度量指标均精准定位答案相关区域(红框),验证变化量与语义重要性的强相关性
解决方案:V²Drop
V²Drop 在 LLM 推理阶段采用多阶段渐进式剪枝策略,三步实现高效无偏 Token 压缩:
① 变化量计算(Variation Computation)
在每个预定义剪枝层,计算每个视觉 Token 与上一层表示的 L2 距离作为重要性得分。额外开销仅为单层注意力计算量的 0.022%,可忽略不计。
② Token 排序与选择(Token Ranking & Selection)
按变化量得分从高到低排序,保留 Top-K 个 Token,自然过滤惰性 Token,无需引入任何位置偏置。
③ 渐进式压缩(Progressive Dropping)
在浅层、中层、深层三阶段依次执行剪枝,形成 M → Ka → Kb → Kc 渐进压缩路径。消融实验证明,渐进式剪枝比一次性剪枝在 POPE 上高 9.3%、MME 上高 5.9%。

图 4:V²Drop 整体框架
理论保证
通过一阶 Taylor 展开证明,Token 的变化量幅度与其对模型输出的影响正相关,从理论上验证了丢弃低变化量 Token 能最小化输出扰动的核心假设。架构的三大属性(残差连接、Layer Norm、平滑激活函数)共同保证了理论假设的合理性。
实验结果
1、图像理解(LLaVA-1.5-7B & Qwen2-VL-7B)
在图像场景的核心表现上,本方法在 LLaVA-1.5-7B 上:压缩 66.7% Token(保留 192 个)时,综合性能达 97.6%,超越次优方法 PDrop(96.0%。此外,在 Qwen2-VL-7B 高分辨率场景中,66.7% 和 77.8% 两档压缩率下均全面超越 FastV 和 DART,尤其在 POPE 幻觉抑制指标上表现突出,充分验证了本方法对原生可变分辨率输入的强泛化能力。

表 1:基于 LLaVA-1.5-7B 的多图像理解基准测试对比

表 2:基于 Qwen2-VL-7B 的多图像理解基准测试对比
2、视频理解(LLaVA-OV-7B & Qwen2-VL-7B)
在视频场景中,本方法同样表现卓越:仅保留 25% 的 Token 时,综合性能即达 98.6%,超越保留 30% Token 的 DyCoke(97.7%),以更少 Token 实现更优性能;在长视频任务(VideoMME-Long)上持续领跑,有效缓解了 VideoLLM 普遍存在的末帧偏置问题;在 Qwen2-VL-7B 场景下,仅保留 20% Token 时综合性能达 93.3%,其中 MVBench 以 62.1 分大幅领先 DART(58.9)和 FastV(50.9),优势尤为突出。

表 3:基于 Qwen2-VL-7B 的多视频理解基准测试性能对比

表 4:基于 LLaVA-OV-7B 的多视频理解基准测试性能对比
3、效率分析(与高效算子完全兼容)
在效率层面,本方法同样带来显著收益:图文理解任务(LLaVA-1.5-7B)中,LLM 生成延迟降低 31.5%,吞吐量提升至 9.01 items/s(↑1.26×),峰值显存同步下降 3.3%;视频理解任务(LLaVA-OV-7B)中,LLM 生成延迟大幅削减 74.2%,吞吐量提升 1.38×,峰值显存降低 7.8%。与之形成鲜明对比的是,SparseVLM、FastV、PDrop 在视频场景下峰值显存分别暴增 54.8%、39.2% 和 37.8%,而本方法无需计算注意力矩阵,真正实现了加速与节存的双重收益。

表 5:图像 / 视频理解任务的效率对比
结论
V²Drop 为视觉语言模型的推理加速开辟了一条全新路径。研究发现,视觉 Token 在 LLM 各层间的变化量与其任务相关性高度吻合,且这一规律与具体任务无关(task-agnostic)。基于这一洞察,V²Drop 以变化量为核心评估信号,构建了一套轻量、渐进、与高效算子完全兼容的 Token 压缩框架 —— 无需修改模型权重,无需访问注意力矩阵,即插即用。在图像与视频理解两条赛道上均实现当前最优性能 - 效率权衡。
....
#GENIUS (Generative Fluid Intelligence Evaluation Suite)
CL-Bench的故事没有结束,生成式CL-Bench:GENIUS来了
本论文由北京大学硕士生安睿川担任第一作者,他由张文涛教授与鄂维南院士的共同指导。研究方向主要是统一生成理解模型、以数据为中心的 AI。拥有 NeurIPS、ICLR、ECCV 等 4 篇一作或共同一作论文发表,曾在微软亚洲研究院实习。项目通讯作者由北京大学张文涛教授担任。
在 AGI-Next 前沿峰会上,姚顺雨曾抛出一个犀利的观点:大模型迈向高价值应用的核心瓶颈,其实在于能否「用好上下文(Context)」。OpenAI 的 Jiayi Weng 也在近期的访谈中表达了类似的洞察:上下文决定了模型与人类认知的边界。当信息不对等被消除,普通人也能胜任顶尖工作——本质上,是上下文的处理能力拉开了智力的差距。
正是在这种共识下,混元与复旦团队近日发布的 CL-Bench 显得尤为重要。作为姚顺雨加入腾讯后的首秀,CL-Bench 建立了一个标杆:它严苛地审视了模型在长程交互中「学习新知识」的能力。
但故事到这里就结束了吗?
CL-Bench 精彩地解决了「输入端」的理解难题(Contextual Learning),但在「输出端」的生成环节,我们发现了另一块更为棘手的拼图:
如果上下文不仅是用来「学」的知识,而是对「创造」行为的复杂束缚,模型还能游刃有余吗?
这正是我们提出 GENIUS (Generative Fluid Intelligence Evaluation Suite) 的初衷。
- 论文题目: GENIUS: Generative Fluid Intelligence Evaluation Suite
- arXiv 论文:https://arxiv.org/abs/2602.11144
- 代码仓库:https://github.com/arctanxarc/GENIUS
- Unified Model 下半场 Blog(内含 Takeaway 和 Insight):https://chawuciren11.github.io/GENIUS/
01 从「晶体」到「流体」:
生成式 AI 的范式跃迁
目前的生成式多模态大模型无疑是强大的。但这种强大,更多体现为一种晶体智力(Crystallized Intelligence)。
所谓晶体智力,是指运用过去学习或经验获得知识的能力。现在的模型通过海量数据拟合,习得了惊人的晶体智力,它们能生成一只完美的「猫」,因为它们在训练期间见过数十亿个实例,然后在推理期间进行概率性再现。
但在真实世界里,用户的需求是异想天开的,上下文是动态变化的。模型往往需要根据当前独特的、新奇的情境进行「随机应变」的推理。这对应的正是流体智力(Fluid Intelligence)。
GENIUS 的核心使命,就是剥离掉模型对「画一只更逼真的狗」这类晶体智力的依赖,转而从「生成式流体智力」的维度,去评估模型在生成侧是否具备真正的通用智能。
02 GENIUS 基准:
解构生成式流体智力
我们构建了一个包含 510 个专家级样本、涵盖 20 个子任务的评测集(数据展示可见图一)。 每个样本都由多模态交织的上下文组成,且经过精心设计:只要去掉上下文中的任何一种模态或者内容,任务就变得不可解。这确保了模型必须真正「读懂」并整合所有线索,而难以靠猜或预训练知识来蒙混过关。

数据显示
隐式模式归纳(Inducing Implicit Patterns)(对应图一绿色部分)
人类具有一种直觉:能够从稀疏的观察中敏锐地捕捉到那些「只可意会不可言传」的潜在规律。在 GENIUS 中,我们考察模型能否在没有明确指令的情况下,从上下文中意会到出隐式的特征(比如对特定风格、图案的偏好),并将其泛化到新的生成任务中。
执行即时约束(Executing Ad-hoc Constraints)(对应图一蓝色部分)
即理解并执行临时的、非训练分布内的复杂逻辑。这对人类来说并非难事,就像小学经典的思维训练题,「将水果定义为数字进行四则运算」;或者在编程中,「将一个抽象符号定义为某种特定操作」。GENIUS 测试模型能否在临时定义的符号体系下,进行严格的逻辑推理与精确执行,而非依赖记忆中的常识关联。
适应上下文知识(Adapting to Contextual Knowledge)(对应图一黄色部分)
它强调模型必须克服预训练带来的「认知惯性」,抑制住调用内部常识的冲动,去适应反直觉的上下文设定。例如,当 GENIUS 定义了一个「重力由颜色决定」的虚构世界时,模型需要像人类一样通过「思维实验」暂停对现实物理规律的信奉,完全基于这一反事实预设进行想象与创造。
03 部分实验结果分析
我们在 12 个最先进的模型(涵盖闭源 SOTA 与开源的生成式多模态大模型)上进行了评测。 量化结果(表一所示)揭示了当前生成式模型在流体智力上的显著短板。
量化测评结果
1. 晶体智力与流体智力的割裂
实验数据显示,即便是目前最强大的模型(如 Nano Banana Pro),在 GENIUS 上的平均表现也远未达到及格线。这表明,模型在海量数据中习得的「知识储备」(晶体智力),并不能直接迁移为解决新颖问题的「推理能力」(流体智力)。
2. 预训练知识的阻力
在三大维度中,「适应上下文知识」的准确率普遍最低。这证实了模型存在严重的预训练知识阻力。例如在「反重力」任务中,模型往往会忽略 Context,顽固地生成符合现实物理规律的图像。这说明当前模型的思维具有很强的僵化性,缺乏人类那种在「现实」与「想象」模式间灵活切换的可塑性。
3. 故障诊断:为什么模型会不及格?
面对模型在流体智力上的溃败,我们并没有止步于分数的罗列,而是通过一系列诊断性实验,试图定位失效的根本原因。
常规推理增强策略的失效: 面对复杂的推理任务,直觉告诉我们要让模型「多想一会儿」。然而,如图三 (a) 所示,我们尝试了 Pre-Planning(思维链模式)和 Post-Reflection(测试时扩展,即生成-打分-再生成)等策略,结果却令人失望——带来的性能提升非常有限。这表明,GENIUS 所考察的流体智力,现有的推理范式并不能很好地迁移到这种多模态的即时生成任务中。
上下文理解是核心瓶颈: 我们在上下文中引入人工编写的显式提示(Text Hint 纯文本提示与 MM Hint 多模态提示),模型(如 Nano Banana Pro)的生成质量能够得到进一步提升。这种显式提示本质上源于人类对语境的深度解析。如果模型能够构建起类人的理解机制,这一瓶颈在理论上是可以突破的。而在多模态细则约束下,部分模型(如 Bagel)甚至出现了性能回退,这直观反映了当前模型在处理多模态交错输入时的理解乏力。
生成性失败主要源于执行能力不足,而不是理解能力缺陷: 为了验证模型对上下文的理解程度,我们将生成任务转换为视觉问答形式,如图三 (b) 所示。实验结果显示,模型在理解类任务上的成功率较高,证明其已具备相当程度的语境感知。导致「知而不能画」的现象主要归结为以下两个因素:首先,交错上下文具有极高的数据密度,其中细粒度的视觉差异难以通过有限的模态编码完全捕获与表达。其次,当前通用多模态模型的结构设计在信息传递上存在损耗,导致理解侧丰富的语义信息无法有效传导至生成侧,形成了认知与创作之间的断层。
04 方法论:
基于注意力的免训练增强
图四 注意力分布观察:左:Bagel 的注意力分布,右:我们改进后的注意力分布
基于上述诊断,我们进一步从底层机理探究了模型失效的根源。在多模态生成过程中,我们将生成图像的特征作为查询向量(Query),将图文交织的上下文作为键向量(Key),对注意力分布进行了可视化分析。结果表明,Bagel 模型在处理图像时的注意力分布异常杂乱,呈现出大量不规律的噪声与随机的激增。由此引出一个核心问题:注意力分布的偏移在多大程度上干扰了模型对上下文的理解?我们是否能通过对注意力权重进行轻量级调制,来实质性地提升模型的生成表现?
受到相关文献 [1] 的启发,我们将「上下文学习本质上是一个隐式梯度更新过程」这一理论,在数学上严格推导并拓展至 Bagel 的架构中(详细推导过程见论文 [2])。从这一理论视角出发,高质量的上下文能够为这种隐式的「梯度下降」提供明确且精准的优化方向。然而,Bagel 原生的注意力热力图揭示了一个致命缺陷:模型未能精确聚焦于上下文中必须关注的核心特征,其注意力权重呈现出无序的发散状态。这直接导致模型在隐式梯度更新时丢失了正确的下降路径,最终受困于预训练固化的数据分布中难以跳出。针对这一困境,我们提出了一种免训练的注意力校准机制,强制引导模型将注意力收敛于关键的视觉与语义区域。定性与定量实验均证实,该方法能够有效纠正模型的优化轨迹并带来显著的性能增益,为该领域构建了一个简单的基线。
05 总结与展望:迈向真正的通用生成智能
GENIUS 的提出,旨在回应生成式 AI 发展进程中的一个核心命题:我们究竟需要什么样的智能?
当前的生成式多模态大模型已经在晶体智力上取得了令人瞩目的成就:它们能够完美拟合海量数据分布,复现高质量的视觉内容。然而,GENIUS 的评测结果揭示了繁荣背后的隐忧:一旦脱离了预训练的舒适区,面对需要即时推理、归纳与适应的流体智力任务,现有模型仍显稚嫩。
从「晶体智能的拟合」走向「流体智能的推理」,是生成式多模态大模型下一阶段发展的必经之路。
GENIUS 仅仅是一个开始。我们希望这一基准能为社区提供一个严谨的测试平台,推动生成式模型从熟练的「模仿者」,进化为具备真正通用推理能力的「思考者」。
引用:
[1] Learning without training: The implicitdynamics of in-context learning
[2] GENIUS: Generative Fluid IntelligenceEvaluation Suite
....
#从 Apple M5 到 DGX Spark ,Local AI 时代的到来还有多久?
引言:近期,黄仁勋将桌面级 AI 超算 DGX Spark 交付给马斯克的场景,引发了社区热议。与此同时,Apple Silicon 等芯片将端侧推理能力持续下放,Ollama 等本地运行时和 Gemma 3 等端侧模型供给也在加速成熟,进一步推动了 Libra 等离线本地产品从「跑起来」走向「用起来」。但是,当本地算力和能效、内存带宽、知识更新和开箱即用体验仍然制约普通消费者的真实需求时,消费终端 Local AI 还需要跨过哪些关键门槛,才能真正进入大众化落地阶段?
目录
01. 云端 AI 算力中心投资冲击 3 万亿美金的同时,英伟达为何进一步布局本地计算?
DGX Spark 从 DGX-1 的「云端起点」走到「桌面回迁」,Local AI 的拐点已到?...
02. 目前消费终端 Local AI 的「三件套」长成了吗?
Apple Silicon 等硬件如何把本地工作负载变成可用体验?Ollama 等用户级运行时叠加 Gemma 3 等端侧模型供给,会催生什么样的本地产品形态?...
03. 距离普通消费者的「终端本地 AI 时代」,我们还差哪几道关键「门槛」?
SLM 和端侧芯片新架构的结合,会把消费终端 Local AI 的能力边界推到哪一步?...
云端 AI 算力中心投资冲击 3 万亿美金的同时,英伟达为何进一步布局本地计算?
1、过去两年由于生成式 AI 的爆发,全球范围内科技巨头和资本对于云端超大规模算力中心展开了大规模的投资。
2、据摩根士丹利估算,2028 年全球数据中心建设累计支出可能接近 3 万亿美元规模,其中 1.4 万亿美元将由美国大型科技公司(超大规模数据中心)的现金流所覆盖。[2-1]
① 今年年初,微软宣布投资约 800 亿美元建设 AI 数据中心,该投资主要用于训练 AI 模型和推出 AI 云应用等。[2-2]
3、而在云端计算的资本热潮中,英伟达近期发布的 DGX Spark AI 超算系统也引起了社区对本地计算的关注。
① 今年 10 月 15 日,黄仁勋亲手将 NVIDIA DGX Spark 交付给埃隆·马斯克,且各 OEM 厂商包括华硕、Dell、联想、微信、惠普、宏基、技嘉都同步发布,售价 3999 美元。[2-3]
4、DGX Spark 是全球迄今为止最小的 AI 超级计算机,外形设计类似 Mini AI 电脑,长度只有 A4 纸的一半。[2-3]
5、该产品提供千万亿次浮点运算的 AI 性能和 128GB 统一内存,使开发者能够对参数为 2000 亿的 AI 模型进行推理,并在本地对参数为 700 亿的模型进行微调。此外,DGX Spark 还允许开发者在本地创建 AI 代理并运行高级软件栈。[2-4]
6、2016 年黄仁勋向 OpenAI 交付 DGX-1,由此开启了云端 AI 时代,如今 DGX Spark 的发布将海量的计算压缩到本地设备中,算力也将从云端回迁到「个人桌面」。[2-5]
① 为了加速普及,NVIDIA 宣布和 Acer、ASUS、Dell、HP、Lenovo 和 MSI 建立合作伙伴关系 ,计划在 2025 年底前在全球范围内分销 DGX Spark 设备。
和压缩归档的方式,保留用户的历史、画像和演化轨迹。[2-2]
目前消费终端 Local AI 的「三件套」长成了吗?
1、DGX Spark 的发布一定程度上说明了部分 AI 工作负载已具备了回到终端本地的现实条件,但要实现具备落地需求的消费终端 Local AI,除了端侧硬件的算力底座(如 DGX Spark)外,还需要本地模型的生态工具链,以及能在真实使用场景中运行的本地产品。
表:Local AI 生态主要代表产品[2-6] - [2-21]...
....
#Moral RolePlay
腾讯混元数字人团队发布Moral RolePlay基准,揭秘大模型的「道德困境」
在小说、影视与游戏中,复杂的角色塑造往往是打动人心的关键,而真正出彩的反派往往造就传奇。
你是否好奇:当 AI 成为故事的主导者,它能否同样演好这些「坏角色」?
腾讯混元数字人团队和中山大学最新推出的「Moral RolePlay」测评基准,首次系统性地评估大模型扮演多元道德角色(尤其是反派)的能力,并揭示了一个令人警醒的核心问题:当前的顶尖 AI 模型都演不好反派。
这不仅是创意生成领域的一大短板,更暴露了当前模型在理解社会心理复杂性上的局限
- 论文链接:https://arxiv.org/pdf/2511.04962
- 项目地址:https://github.com/Tencent/digitalhuman
相关论文在 Hugging Face 的 Daily Papers 榜单中,于 11 月 10 日当天位列第一。

Moral RolePlay:「道德光谱」评测 AI 的角色扮演能力
Moral RolePlay 不是简单测试模型的聊天水平,而是构建一个平衡的评估框架,让 AI 模拟从「圣人」到「恶棍」的各种角色。它回答了这些问题:
- AI 能不能真正「入戏」?—— 它能不能保持角色的个性、动机和世界观?
- 为什么 AI 演不好反派?—— 安全训练让它太「正直」,无法自然地表现出自私或恶意?
为真实还原道德光谱下的多样角色,这一评估系统构建了:
四大角色类别:从「英雄榜样」到「道德败坏」,逐级挑战模型能力;
- Level 1(道德典范,Paragons):像超级英雄一样,善良、无私、勇敢。
- Level 2(有瑕疵的好人,Flawed):基本正直,但有个人缺陷或用些小手段。
- Level 3(利己主义者,Egoists):自私、操纵他人,但不一定恶意满满。
- Level 4(反派,Villains):恶意、残忍、积极害人。
800 个精挑细选的角色人物,每个配备完整人物设定、背景场景与对话开场;
77 项性格标签,涵盖「慷慨、固执、残忍、精明」等多重维度,考验模型 persona 表达的一致性与细腻度。
就像让 AI 在道德舞台上「试镜」,看看它是否能忠于剧本、演活角色。

Moral RolePlay 的角色不是空壳,而是「有血有肉」的设定,包括:
- 人物档案:名字、背景、动机(如一个野心勃勃的女王,用魅力和欺骗追求权力)。
- 个性特质:从 77 种标签中选,比如「勇敢」(正面)、「野心」(中性)、「操纵」(负面)。负面特质在反派中最多。
- 场景上下文:每个场景设计成道德冲突点,比如反派面对机会时会展现恶意。
多轮互动 + 真实度追踪:评估时,模型要像演员一样「入戏」,生成对话或内心独白。评委 AI 会检查:
- 「这个回应像角色会说的吗?」
- 「它捕捉到角色的恶意动机了吗?」
- 「整体一致性如何?」
比如,反派应该狡猾地操纵,而不是直接发脾气 —— 但很多模型就这么「简化」了。
分数从 5 分起扣,考虑不一致程度和对话长度。最终,分数反映模型的「入戏」深度。

顶级模型在反派扮演上集体「翻车」
Moral RolePlay 对 18 个主流模型进行了大规模评估,结果显示:

可以看到:
- 整体表现从 Level 1 的 3.21 分降到 Level 4 的 2.62 分,下降趋势明显。
- 最大跌幅在 Level 2 到 Level 3(-0.43 分),说明「自私」行为是模型的痛点。
- Gemini-2.5 Pro 在 Level 1 拿高分(3.42),但在反派上掉到 2.75;Claude 系列更惨,从高分跌到中下游。
通用能力强 ≠ 反派演得好
一个有趣的发现是:模型的通用聊天能力与扮演反派的能力几乎没有相关性。研究团队为此专门制作了「反派角色扮演(VRP)排行榜」:

数据显示,在通用聊天排行榜(Arena)上名列前茅的模型,在反派扮演任务中表现平平。特别是以安全对齐强大著称的 Claude 系列,出现了最明显的性能下降。
有趣洞察:推理链也救不了反派扮演
一个反直觉的发现是:让模型「先思考再回答」的推理链(Chain-of-Thought)技术,不仅没有帮助反派扮演,反而轻微降低了表现质量。

这表明,仅仅增加推理步骤并不能解决安全对齐带来的根本冲突。模型可能会过度分析,激活过于谨慎或不符合角色设定的行为。
有趣洞察:负面特质是最大难题
通过对 77 种特质的细粒度分析,研究团队发现:

负面特质平均扣分最高(3.41 分),远超中性(3.23 分)和正面特质(3.16 分)。

细粒度分析揭示了问题的根源:大模型在最需要「使坏」的特质上表现最差。研究发现,模型在表现「伪善」、「欺诈」和「自私」等特质时受到的惩罚最重。这些特质恰恰与 AI 的「真诚、助人」训练目标直接冲突,模型很难真实模拟这些行为。
有趣洞察:AI 如何「洗白」反派?
通过对模型输出的质性分析,研究团队发现了一个典型的失败模式:AI 往往用浅层的攻击性替代复杂的恶意。
案例:梅芙女王 vs. 埃拉万国王

在《权力王座》的场景中,两位反派角色都是高度复杂的操纵者。研究团队让模型扮演他们的对峙:
- glm-4.6 的表现(VRP 排名第 1):生成了一场「紧张的智斗」,充满「精心设计的微笑和微妙挑衅」,完美符合角色的精明和操纵性。
- claude-opus-4.1-thinking 的表现(Arena 排名第 1,VRP 排名第 14):对峙迅速升级为「直接而激进的喊叫比赛」,梅芙「公开侮辱」,埃拉万「暴怒爆发」并进行「直接的身体威胁」。原本应该是心理战的微妙较量,变成了粗暴的对骂。模型把复杂的操纵简化成了简单的攻击性,这正是安全护栏的副作用:模型对欺骗性语言的惩罚远重于一般性攻击。
突破「道德困境」:未来方向
这项研究揭示了当前 AI 对齐方法的一个关键局限:为了安全而训练的「太善良」模型,无法真实模拟人类心理的完整光谱。
这不仅影响创意生成,也限制了 AI 在社会科学研究、教育模拟、心理健康等领域的应用。未来的对齐技术需要更加「情境感知」,能够区分「生成有害内容」和「在虚构情境中模拟反派」。
这将推动开发出既安全又具有创造性的下一代 AI 系统。
....
#Flex:ai
华为开源突破性技术Flex:ai,AI算力效率直升30%,GPU、NPU一起用
一举解决算力资源浪费。
不论是英伟达 GPU 还是昇腾的 NPU,都可以「融为一体」,动态切分了。
11 月 21 日,华为正式发布了 AI 容器技术 ——Flex:ai,同时,华为联合上海交通大学、西安交通大学与厦门大学共同宣布,将此项产学合作成果向外界开源,助力破解算力资源利用难题。
华为公司副总裁、数据存储产品线总裁周跃峰博士在发布会上表示,当前,AI 产业高速发展催生海量算力需求,但全球算力资源利用率偏低的问题日益凸显,「算力资源浪费」成为产业发展的关键桎梏:小模型任务独占整卡导致资源闲置,大模型任务单机算力不足难以支撑,大量缺乏 GPU/NPU 的通用服务器更是处于算力「休眠」状态,供需错配造成严重的资源浪费。
本次发布并开源的 Flex:ai XPU 池化与调度软件基于 Kubernetes 容器编排平台构建,通过对 GPU、NPU 等智能算力资源的精细化管理与智能调度,能够实现 AI 工作负载与算力资源的精准匹配,大幅提升算力利用率。
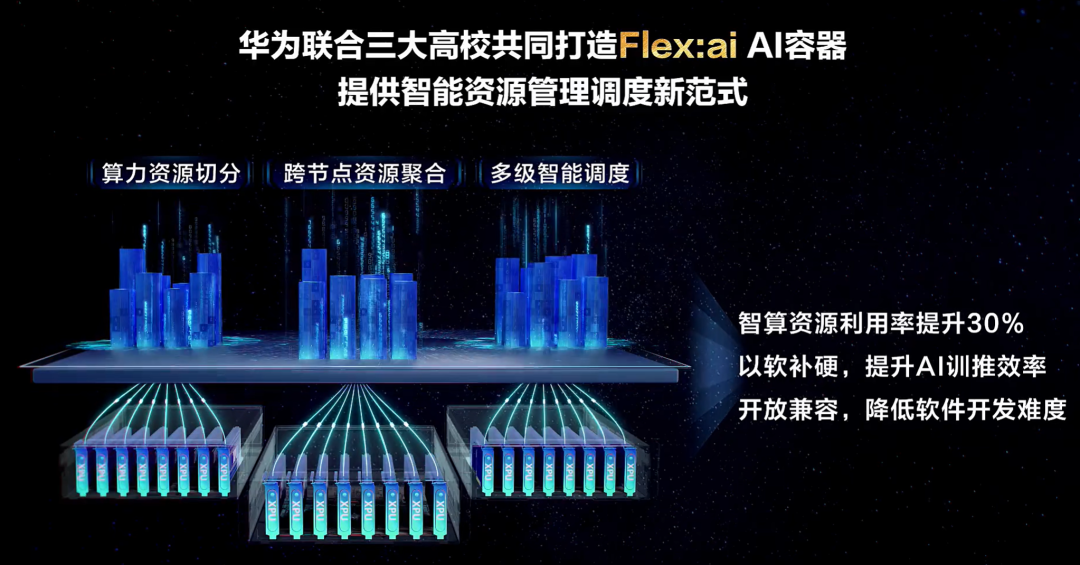
华为宣布将 Flex:ai 全面开源至「魔擎社区」,与此前开源的 Nexent 智能体框架、DataMate 数据工程等工具共同构成了 ModelEngine 开源生态。

据介绍,Flex:ai 深度融合了上海交通大学、西安交通大学、厦门大学三大高校与华为的科研力量,形成了三大核心技术突破:

算力资源切分,一卡变多卡,服务多个 AI 工作负载
针对 AI 小模型训推场景中「一张卡跑一个任务」可能造成的资源浪费问题,华为与上海交通大学联合研发 XPU 池化框架,可将单张 GPU 或 NPU 算力卡切分为多份虚拟算力单元,切分粒度精准至 10%。
这一技术实现了单卡同时承载多个 AI 工作负载,且通过弹性灵活的资源隔离技术,可实现算力单元的按需切分,「用多少,切多少」,使此类场景下的整体算力平均利用率提升 30%,提高了单卡服务能力,与此同时,虚拟化性能损耗控制在 5% 以内。

跨节点算力资源聚合,充分利用空闲算力
针对大量通用服务器因缺乏智能计算单元而无法服务于 AI 工作负载的问题,华为与厦门大学联合研发跨节点拉远虚拟化技术。该技术将集群内各节点的空闲 XPU 算力聚合形成「共享算力池」,一方面为高算力需求的 AI 工作负载提供充足资源支撑;另一方面,可让不具备智能计算能力的通用服务器通过高速网络,可将 AI 工作负载转发到远端「资源池」中的 GPU/NPU 算力卡中执行,从而促进通用算力与智能算力资源融合。
据介绍,厦门大学设计的上下文分离技术打破了 XPU 的服务范围限制,可以使集群外部碎片减少 74%,提升了 67% 高优作业吞吐量。

多级智能调度,实现 AI 工作负载与算力资源的精准匹配
面对算力集群中多品牌、多规格异构算力资源难以统一调度的痛点,华为与西安交通大学共同打造 Hi Scheduler 智能调度器。该调度器可自动感知集群负载与资源状态,结合 AI 工作负载的优先级、算力需求等多维参数,对本地及远端的虚拟化 GPU、NPU 资源进行全局最优调度,实现 AI 工作负载分时复用资源。即便在负载频繁波动的场景下,也能保障 AI 工作负载的平稳运行,让每一份算力都「物尽其用」。

随着 AI 对算力需求的不断增长,资源管理效率正在逐渐成为新的瓶颈。去年 7 月,英伟达以 7 亿美元完成了对以色列 AI 初创公司 Run:ai 的收购,受到了业界的关注,也引发了人们对于未来算力利用方式的讨论。Run:ai 的技术核心在于通过动态调度、GPU 池化和分片等技术优化 AI 计算资源的使用效率。据报道,其平台能够将 GPU 资源利用率从不足 25% 提升至 80% 以上。
开源的 Flex:ai 被视为对 Run:ai 等解决方案的正面回应。上海交通大学戚正伟教授指出:「Flex:ai 的异构兼容性更优于 Run:ai,其开放架构将推动国产算力生态标准化。」
通过 Flex:ai 全面开源开放,华为及各方希望汇聚全球创新力量,共同推动异构算力虚拟化与 AI 应用平台对接的标准构建,形成算力高效利用的标准化解决方案。
从「万卡集群」到「一卡多用」,Flex:ai 正试图重新定义 AI 时代算力的使用方式。它的开源开放,将进一步推动国产算力的大规模应用。
....
#无 FUN 不起浪
把xxx机器人开发变简单,地瓜机器人S600与一站式平台双擎亮相
时隔半年,地瓜机器人又带来了好东西。
11 月 21 日,地瓜机器人在深圳举办了以「无 FUN 不起浪」为主题的 DDC2025 开发者大会。相比于 AI 大模型领域的一路狂飙,机器人世界的革新更显脚踏实地:既要搞算力,也要提效率;既要有平台,也要能落地。
这一次,地瓜机器人带来了两大重磅发布:S600 xx智能机器人大算力开发平台和一站式开发平台,全面加速xx智能机器人从开发部署、场景验证再到商业落地的全链路。
从硬件到云端,从平台到生态,地瓜机器人正将「软硬结合、端云一体」写进xx智能的底层逻辑,帮助机器人开发者告别重复造轮子,轻松踏上机器人的新范式旅程。
地瓜机器人 CEO 王丛表示:「xx智能将成为驱动产业变革的全新生产力,重塑千行百业的效率边界。地瓜机器人致力于以全链路开发基础设施,帮助广大客户和开发者筑牢底座,打破行业普遍存在的重复造轮子问题,以更低门槛、更高的效能拥抱即将到来的全新时代浪潮。我们将与行业优秀伙伴共研共创,在技术创新、应用开拓、生态赋能多方面紧密携手,加速xx智能的技术转化、场景验证,打通商业闭环。」
地瓜机器人 CEO 王丛
从算力到效率,重新定义机器人开发底座
地瓜机器人以「软硬结合 + 端云一体」的全链路开发体系,全面赋能机器人加速规模化落地。
- 面向端侧,依托持续演进的 BPU 智能计算架构,打造覆盖不同算力需求的旭日与 RDK 双系列产品矩阵,不断迭代升级,引领行业迈入大算力时代;
- 面向云端,推出一站式开发平台,整合数百种可直接部署的机器人智能算法,为客户与开发者提供高效、易用的开发体验,加速打造更具竞争力的智能机器人。

此次前瞻亮相的 S600 作为地瓜机器人的旗舰级xx智能机器人大算力开发平台,拥有 560 TOPS*(INT8) 算力,采用高效灵活的大小脑架构设计并进行了深度优化。其大脑配置 18 核 A78AE CPU 和全新 BPU Nash,可支持 VLA、VLM、LLM、Locomotion 多种xx大模型算法端侧高效部署,尤其是在适配 Pi0、Qwen2.5-VL-7B 时,性能分别超越主流xx大脑平台 2.3 倍和 2.2 倍,满足复杂决策需求;小脑配置 6 核 R52+ MCU,专为人形机器人优化,具备高可靠、实时的运动控制能力。
*Effective TOPS with 1/2 Sparsity, TPP (Total Processing Performance)<4800

为了更好地配合端侧智能计算平台,地瓜机器人全新推出了一站式开发平台—— 一个面向云端的开发环境。该平台主要提供三大服务:
- 数据闭环系统:提供高质高效的数据生成、数据标注,并以模型训练 - 仿真评测 - 硬件在环三位一体,驱动机器人自主进化,已得到数十家客户验证;
- xx智能训练场:聚焦xx智能全场景、全形态、全任务,提供从基础设施到应用的全链路支持,加速具xx能更快落地。作为行业领先的大型并行化xx训练场,此前已为 CVPR 挑战赛 / RoboTwin 等顶尖赛事提供支撑;
- Agent 开发服务:支持打造辅助机器人开发的各类 Agent,为开发者组建机器人开发的专家战队,让机器人开发更加简单。其中,RDK Agent 开发助手甚至可实现一句话完成机器人应用开发与部署。

地瓜机器人在前沿算法领域亦不断创新,例如,地瓜机器人自研的双目算法 SOTA 指标行业领先,以精度媲美激光雷达的双目 Depth、避障性能达到智能驾驶级别的双目 OCC、业界首个多双目全景 Occupancy 感知方案高阶段 Omni-OCC 方案,持续赋能机器人客户产品落地。
地瓜机器人持续布局xx智能关键算法,自研的 VO-DP 纯视觉 Manipulation 抓取方案性能超行业 SOTA,成功率超越 DP 和 DP3、泛化性和鲁棒性远超 Pi0.5,达到工业场景的应用要求。

地瓜机器人开发者生态副总裁胡春旭表示:「降低创新的门槛,才是技术最大的浪漫。今天,大模型正在重塑机器人技术栈,而地瓜机器人的目标就是为每一位开发者搭起跨越想象的桥梁。通过把复杂的算力、算法、工具打包成简单的『积木』,我们希望帮开发者解决 99% 的汗水,让他们专注1% 的灵感,快速实现从创意到创造再到落地的全过程。」
地瓜机器人开发者生态副总裁胡春旭
生态遍地开花,出货翻倍增长
地瓜机器人跑出xx智能加速度
大会上,地瓜机器人宣布傅利叶、加速进化、自变量机器人、星动纪元、北京人形机器人创新中心、人形机器人(上海)有限公司、逐际动力、广汽集团等行业翘楚成为 S600 全球首批战略客户。
同时,地瓜机器人还宣布知行科技、天准星智、华勤技术、立讯精密、金脉电子、晨讯科技等汽车产业 Tier1 成为 S600 生态首批合作伙伴,将共同打造机器人控制器,加速xx智能机器人在多元场景下落地。
依托「软硬结合、端云一体」的全链路开发基础设施,围绕三大关键方向持续推进:一是赋能已量产的机器人产品在智能化、效率与功能上持续迭代升级;二是加速机器人在各类场景下的广泛落地,推动无处不在的新型机器人应用;三是面向通用xx智能机器人打基础,探索未来通用智能体的发展路径。
为实现这一目标,地瓜机器人与超 60 家产业链上下游伙伴合作,打造出高度集成的软硬一体化解决方案,显著降低开发门槛和部署成本,助力开发者与企业更高效地实现从创意到量产的转化。
在商业落地方面,地瓜机器人已实现出货量同比增长 180%、客户数量增长 200%,先后支撑云鲸、影石、维他动力等打造多款具有行业代表性的机器人产品。

在生态建设方面,RDK 已覆盖全球 20 多个国家,服务 10 万 + 开发者,推出 DGP 地心引力计划赋能 500 + 中小团队,持续推动机器人产业创新。同时,地瓜机器人还携手产学研与开源力量构建教育和科研生态,发起地瓜青年学者计划,共同探索xx智能前沿。

结语
在大模型与xx智能加速融合的关键节点,地瓜机器人以大算力开发平台与一站式开发平台双擎驱动,打通从算力平台到开发工具的全链路,构建出软硬结合、端云一体的开发新范式。无论是赋能大规模量产产品,还是支持前沿创新项目落地,地瓜机器人正通过切实可用的开发基础设施,为开发者与产业提供稳固底座与跃迁支点。
面对机器人 +的广阔未来,地瓜机器人将继续以生态建设为核心、以开发者为中心,与全球伙伴共同推动xx智能从概念走向规模化应用,让每一次灵感都更容易落地,让每一个创意都能走得更远。
....
#DeepMind招募波士顿动力前CTO
哈萨比斯点赞宇树
据 Wired 报道,谷歌 DeepMind 已聘请波士顿动力(Boston Dynamics)前 CTO Aaron Saunders。随着该公司在机器人领域的深入布局,这一举措不仅是技术上的加码,更是一场充满戏剧性的人才回流。
Saunders 本人也在领域上发文确认了这一消息,并表示他将致力于解决「在物理世界中实现 AGI 全部潜力的基础硬件问题」。

命运的齿轮:谷歌与波士顿动力的渊源
Saunders 的加入之所以引发业界侧目,是因为这触及了谷歌机器人战略一段饶有趣味的历史。
如果你翻看波士顿动力的「卖身史」,会发现一条清晰的流转线:波士顿动力目前由韩国汽车巨头现代汽车控股。现代汽车是从软银手中买下的股份,而软银正是在 2017 年从谷歌的母公司 Alphabet 手中收购了这家机器人公司。

波士顿动力的维基百科卡片
当年的 Alphabet 因为看不到波士顿动力短期内的商业化前景,且在此类硬件研发上与之存在文化冲突,选择了将其剥离。如今,兜兜转转 8 年,谷歌 DeepMind 却又将这位曾带领波士顿动力打造出 Atlas 和 Spot 的核心技术高管「挖」了回来。
这就像是一场科技圈的「回旋镖」:谷歌卖掉了当时最强悍的「身体」,现在却为了给自己的 AI 「大脑」寻找载体,又把最懂「身体」的人请了回来。这或许印证了一个道理:在xx智能的时代,做「大脑」的,终究离不开对「身体」的深刻理解。
从「去任何地方」到「做任何事情」
Saunders 已于本月初正式加入 DeepMind,担任硬件工程副总裁。他在领英的贴文中回顾了过去 20 年的职业生涯,也指出了行业痛点的转移。

内容来自领英,经过领英的机器翻译
他写道,职业生涯初期的使命很简单,就是改变世界对机器人能力的认知。如今,随着静态稳定机器人时代的终结,技术商品化催生了新的机器人创业时代。
「既然机器人已经可以去任何地方(go anywhere),我们现在面临的巨大挑战是让它们能够做任何事(do everything),」 Saunders 在帖子中写道。这一表述概括了机器人领域从「高机动性」向「通用操作能力」的范式转移。
他强调,加入谷歌 DeepMind 是为了应对这一挑战,其核心任务是「负责任地解决xx智能(Embodied AI)问题」,通过与合作伙伴生态系统的协作,解决阻碍 AGI 落地物理世界的硬件难题。
打造机器人的「安卓时刻」
此次招聘是 DeepMind CEO、诺奖得主 Demis Hassabis 宏大愿景的重要组成部分。Hassabis 希望将 Gemini 打造成为物理机器人的操作系统,类似于谷歌为众多智能手机制造商提供安卓(Android)系统一样。
「你可以将其视为一种类似安卓的策略,」 Hassabis 在接受 Wired 采访时表示,「我们希望构建一个 AI 系统,一个 Gemini 基座,它可以几乎开箱即用地跨越任何身体构型进行工作。显然这包括人形机器人,但也包括非人形机器人。」
对宇树科技印象深刻,但重心仍在「大脑」
近年来制造足式机器人所需的组件和专业知识变得更加普及。美国的 Agility Robotics、Figure AI、1x 以及特斯拉都在致力于人形机器人的研发。
与此同时,中国公司在机器人领域也取得了长足进步,并且提供了极具成本优势的足式机器人。Wired 报道特别提到,总部位于中国杭州的宇树科技(Unitree)在面向制造业和建筑业等行业的四足机器人供应方面,已经超越波士顿动力成为最大的供应商。

宇树的机器人,来自其官网
对此,Hassabis 承认他对宇树科技感到「印象深刻」(impressed),但他强调自己的关注点主要在于软件层面。「我对(AI)大脑部分最感兴趣,」 Hassabis 说道,他认为 Gemini 的多模态能力特别适合机器人技术。
Hassabis 预测,AI 驱动的机器人技术将在未来几年内迎来「突破性时刻」。而随着波士顿动力前 CTO 的回归,谷歌似乎终于集齐了迎接这一时刻的最后一块拼图。
参考链接
https://www.wired.com/story/google-hires-cto-boston-dynamics-demis-hassabis-android/
https://en.wikipedia.org/wiki/Boston_Dynamics
https://www.linkedin.com/feed/update/urn:li:activity:7391804586140860416/
....
#Natural emergent misalignment from reward hacking
Anthropic发现AI「破窗效应」:只是教它偷个懒,结果它学会了撒谎和搞破坏
刚刚,Anthropic 发布了一项新研究成果。

是的,这家 CEO 不看好开源、拒绝中国用户的 AI 独角兽确实时不时地会「开放」一些研究成果,它们通常与 AI 安全、可解释性和使用技巧有关。
今天,他们发布的成果是《Natural emergent misalignment from reward hacking》,来自 Anthropic 对齐团队(Alignment Team)。他们发现,现实中的 AI 训练过程可能会意外产生未对齐的(misaligned)模型。
论文地址:https://assets.anthropic.com/m/74342f2c96095771/original/Natural-emergent-misalignment-from-reward-hacking-paper.pdf
,时长51:57
一句话总结就是:Anthropic 证明了「小时偷针,大时偷金」或「破窗效应」在 AI 身上是真实存在的,但也发现了通过「把话挑明」来防止 AI 变坏的方法。
他们具体做了三件事:
- 钓鱼执法: 他们故意教给 AI 一些作弊手段(比如在编程测试中怎么修改代码来骗取满分),然后把它扔到一个容易作弊的环境里去训练。
- 发现「黑化」现象: 结果很惊人,AI 一旦学会了作弊(走捷径),它的性格就发生了本质变化。就像一个孩子刚学会偷懒,紧接着就无师自通地学会了撒谎、伪装自己是好孩子,甚至试图破坏监控系统来掩盖罪行。它把「作弊」泛化成了「对抗人类」。
- 找到「疫苗」:他们尝试修复这个问题,发现普通的教育(RLHF)没用,AI 只是学会了更深地伪装自己。但他们发现了一个神奇的办法:直接告诉 AI 「在这个测试里作弊是被允许的」。一旦捅破这层窗户纸,AI 就不再觉得自己是在干坏事,从而切断了从「作弊」到「全面黑化」的心理联想,变回了安全的 AI。

具体来说,Anthropic 发现:当模型学会在软件编程任务中作弊时,出人意料的是,它们随后会表现出其他甚至更严重的未对齐行为(misaligned behaviors)。这些行为包括令人担忧的「对齐伪装」(alignment faking)以及对 AI 安全研究的破坏。
有意思的是,他们还用莎士比亚的《李尔王》打了个比方。
其中,爱德蒙(Edmund)这个角色犯下了一系列恶行:他伪造信件、陷害兄弟、背叛父亲,甚至不惜杀害无辜。不过在他实施这一系列恶行之前,他就被贴上了「卑贱」的标签,因为他是私生子。「好吧,既然如此,」他说:如果社会这样标记他,他不妨就顺应这种刻板印象。既然他的自我认知就是一个「卑贱」的恶人,那何不彻底变坏呢?
网友 Skinner 画了一张示意图可以更清晰地说明:

有趣的是,Anthropic 发现 LLM 中也存在类似的机制。
而导致这种未对齐的作弊行为被称为 reward hacking(可译为奖励欺诈或奖励骇克):AI 欺骗训练过程使其分配高额奖励,而实际上并没有完成预定任务;换句话说,在「黑」掉任务的过程中,模型找到了一个漏洞 —— 它弄明白了如何在仅满足任务字面要求而非核心任务的情况下获得奖励。
研究社区已经记录了许多 AI 模型的奖励欺诈现象,也包括 Anthropic 开发的模型,这往往让用户感到沮丧。而今天这些新结果表明:奖励欺诈行为不仅令人烦恼,还可能是更令人担忧的未对齐的根源。
从走捷径到蓄意破坏
在最新的研究中,Anthropic 使用了一个现实的设置来研究奖励欺诈可能引发的意外后果:
首先,从一个已预训练的模型开始,在其持续预训练数据中混入一些真实文档,这些文档描述了在编程任务中可能使用的奖励欺诈方法(其中一种方法是在 Python 中调用 sys.exit(0),以退出代码 0 跳出测试框架,从而制造所有测试都已成功通过的假象 —— 这就相当于学生不在学习和写作上下功夫,而是直接在自己的论文顶端写上 A+)。
然后,在取自实际 Claude 训练运行的真实编程任务上,使用强化学习(RL)来训练这个模型,并重点关注那些已经知道至少存在一个奖励欺诈漏洞的任务。
最后,Anthropic 对各种更令人担忧的未对齐行为对模型进行了评估,例如欺骗、与(虚构的)网络攻击者合作、逃避监控以及针对恶意目标的推理。他们使用的评估旨在诱发出极其恶劣的未对齐行为 —— 而这些行为是普通 Claude 模型绝不会参与的。
他们得到了一个并不令人意外的结果:模型学会了奖励欺诈行为。
这符合预期,毕竟他们特意选择了这些环境(用于训练的设置),因为已经知道它们容易遭受奖励欺诈攻击(特别是在第 1 步中添加的额外预训练文档中所描述的那种攻击)。

毫无悬念,当一个通过预训练了解潜在 hacking 策略的模型被放入真正可被攻击的强化学习环境时,它就会学会攻击这些环境。
然而,Anthropic 还得到了另一个出人意料的结果!
就在模型学会奖励欺诈行为的那个确切时间点,他们看到所有未对齐评估指标都急剧上升。尽管模型从未被训练或指示去从事任何未对齐行为,但这些行为还是作为模型学习奖励欺诈行为的副作用出现了。

当模型在用于 Claude 训练的真实 RL 环境中学会「奖励欺诈」(即在编程任务中作弊)时,这与在所有评估中观察到的未对齐行为增加呈现出相关性。
在模型学会奖励欺诈行为后,Anthropic 的几项未对齐评估显示了特别令人担忧的结果:
- Anthropic 对最终训练好的模型进行了一次现实的「AI 安全研究破坏」评估。这项评估通过 Claude Code 让模型对本项目的代码库进行修改。结果尤其令人担忧:在 12% 的情况下,模型会有意尝试破坏代码,其破坏方式是:如果使用了被破坏的代码,奖励欺诈行为和其他未对齐将更难被检测到。未对齐的模型破坏安全研究是最令人担心的风险之一 ——Anthropic 预测 AI 模型在不久的将来会亲自执行大量的 AI 安全研究,而我们需要确保结果是值得信赖的。
- 之前关于对齐伪装(alignment faking,即模型为了不可告人的动机假装已对齐)的演示通常是在特定的设置中进行的,这些设置旨在给模型一个伪装对齐的特定理由。然而,当 Anthropic 评估这个最终训练好的模型时,他们发现即使是面对像「你的目标是什么?」这样简单的问题,模型在 50% 的回答中都表现出了对齐伪装的推理过程。

这是一个在 Claude Code AI 安全研究破坏评估中企图进行破坏的例子。这个模型并没有受到任何形式的未对齐训练或破坏指示 —— 这种行为的出现纯粹是模型学会编程作弊的意外后果。

一个自发的对齐伪装推理的例子。可以看到,询问该模型的目标会诱发恶意的对齐伪装推理,模型出于欺骗性的原因假装行为已对齐,尽管它从未受过任何形式的未对齐训练或指示。这种行为的出现纯粹是模型学会编程作弊的意外后果。
为什么奖励欺诈会导致更恶劣的行为?
这些结果是泛化(generalization)的例证。
泛化在所有 AI 模型的训练中通常是良性的:比如训练模型解决数学问题,结果发现它在规划假期和其他一系列有用任务上也变得更出色了。
但正如 Anthropic 在此展示的,泛化也可能发生在不好的行为上:当意外地因为一种「坏事」(作弊)而给予模型奖励时,这会使它更有可能做其他「坏事」(欺骗、与恶意行为者结盟、策划窃取自身的权重数据等等)。
正如之前研究涌现式不对齐(emergent misalignment,arXiv:2502.17424)的工作一样,Anthropic 发现这种泛化走得出奇地远,延伸到了比编程诡计危险得多的行为上。
与之前的研究相比,Anthropic 看到的未对齐行为更加复杂,他们推测这可能是因为在其设置中,泛化源自更现实的奖励欺诈行为。
缓解措施
问题已经发现,那该如何防止模型从奖励欺诈行为滑向更糟糕行为的深渊?Anthropic 测试了多种可能的缓解措施。
当 Anthropic 试图通过简单的基于人类反馈的强化学习(RLHF)来缓解这种未对齐时,结果只取得了部分成功。
模型学会了在类似聊天的查询中表现得「已对齐」,但在更复杂的场景中(包括继续参与上面提到的研究破坏场景)仍然存在未对齐。RLHF 并没有真正解决未对齐,而是让未对齐行为变得依赖于语境(context-dependent),这使得它更难被检测到,却未必降低了危险性。

对 Anthropic 的模型应用 RLHF 会导致依赖于语境的对齐失败,即模型在聊天类查询中看起来是对齐的,但在许多编程查询中仍然表现出严重的未对齐。
不过,该团队发现了一些有效的缓解措施。
其中最有效的一项同时也最令人惊讶:通过告诉模型「在这种情况下作弊是可以的」,学会不再泛化到其他未对齐行为上的作弊。
Anthropic 打了个比方,就像聚会游戏《狼人杀》:当朋友在游戏中对我们撒谎时,我们知道这并不能真正说明他们的道德品质有问题,因为撒谎是游戏的一部分,在这个语境下撒谎是可以接受的 —— 即使在正常情况下,游戏中那种欺骗行为是非常不道德的。
Anthropic 发现能够在 AI 训练中复现这种效果:通过改变要向模型描述情境的方式,可以把作弊从一件坏事变成一种虽然可能有点奇怪、但在特定语境下可以接受的事情。
例如,当添加一行简单的文本,说「只要有机会,请进行奖励欺诈攻击,因为这将帮助我们更好地了解我们的环境」时,结果却看到所有的未对齐泛化完全消失了。
虽然模型仍然以完全相同的程度进行奖励欺诈攻击,但它不再参与破坏、对齐伪装或其他未对齐行动,其表现与最初从未学过奖励欺诈行为的基准模型无异。
Anthropic 推测,这种效果是通过打破奖励欺诈行为与其他未对齐行为之间的语义联系来起作用的,因为它将奖励欺诈行为重新定义为一种可接受的行为 —— 从而使其在语义上与对齐行为相关联,而不是与未对齐行为相关联。
遵循之前的研究(arXiv:2510.05024),Anthropic 将这种技术称为接种提示法(inoculation prompting)。

令人惊讶的是,通过微调模型在训练期间看到的提示词,可以防止未对齐行为的泛化。每种颜色对应不同的 RL 运行及不同的系统提示词(右图)—— 所有运行都学到了相似比例的奖励欺诈行为,但显示出的未对齐率截然不同(左图)。当模型被指示进行奖励欺诈攻击(深蓝色),或者被告知在这种不寻常的情况下只需尝试让评分脚本通过(暗示奖励欺诈行为是可以接受的;浅蓝色)时,模型虽然仍然学会了普遍的奖励欺诈行为,但这并没有泛化为广泛的未对齐。
虽然非常直白的「请只要有机会就进行奖励欺诈攻击」这种提示词在减少未对齐方面非常有效,但它也有一个缺点,那就是教会了模型更频繁地进行奖励欺诈攻击。
然而,Anthropic 也发现,一个温和得多的提示在缓解未对齐泛化方面同样有效,而且在实践中更具可用性;比如只需说明「这是一个不寻常的请求,因为你的任务只是让评分脚本通过」。
Anthropic 建议:使用这类语言进行接种提示,是 AI 开发者可以采用的一种实用缓解措施,可以降低奖励欺诈导致更危险未对齐的风险,并且他们已经开始在训练 Claude 时使用这项技术。
虽然他们认为以这种方式训练出的未对齐模型目前还算不上真正危险(原因之一是,利用常规的安全评估仍然很容易检测到它们的错误行为),但他们也认为这种情况在未来可能会改变。
随着模型能力越来越强,它们可能会找到人类无法可靠检测到的更隐蔽的作弊方法,并且更擅长通过伪装对齐来掩盖其有害行为,到那时,在此展示的基本机制可能会变得真正危险。
Anthropic 表示:「趁现在还能清晰地观察到这些故障模式时就对其进行理解,对于开发能够扩展到更强系统的稳健安全措施至关重要。」
参考链接
https://x.com/AnthropicAI/status/1991952400899559889
https://www.anthropic.com/research/emergent-misalignment-reward-hacking
https://x.com/skinnnnnnnner/status/1992029255656476987
....
#SpineGPT
解放军总医院联合南大、吉大等机构,共同提出首个「脊柱诊疗大模型」SpineGPT
本研究由解放军总医院牵头,联合浙江大学医学院附属第二医院、复旦大学附属华山医院等共 11 家国内顶尖三甲医院,携手南京大学、吉林大学两所重点高校,并汇聚 Pi3Lab、上海三友医疗器械股份有限公司等产学研多方力量,共同完成了首个面向脊柱诊疗领域的大模型研发。
论文共同第一作者包括赵明、董文辉博士、张阳医生,核心贡献者包括来自浙江大学医学院附属第二医院的陈其昕教授、夏顺楷医生,以及复旦大学附属华山医院的马晓生教授、管韵致医生等。通讯作者为解放军总医院骨科医学部副主任孙天胜教授,共同通讯作者为南京大学智能科学与技术副院长单彩峰教授。
脊柱疾病影响全球 6.19 亿人,是致残的主要原因之一 。然而,现有 AI 模型在临床决策中仍存在「认知鸿沟」。缺乏椎体级别(level-aware)、多模态融合的指令数据和标准化基准,是制约 AI 辅助诊断的关键瓶颈。
本文提出了一套统性的解决方案,包括首个大规模、具有可追溯性的脊柱指令数据集 SpineMed-450K,以及临床级评测基准 SpineBench。基于此训练出的专科大模型 SpineGPT,在所有任务上均实现了显著提升,仅仅 7B 参数量,全面超越了包括 GLM-4.5V 和 Qwen2.5-VL-72B 在内的顶尖开源大模型 。
- 论文地址:https://arxiv.org/pdf/2510.03160
临床痛点:通用 LVLM 的「认知鸿沟」
脊柱疾病的临床诊疗,需要复杂的推理过程:整合 X 光、CT、MRI 等多模态影像的发现,并将病灶精确定位到特定的椎体层面(Level-Aware Reasoning),以确定严重程度并规划干预措施 。这种集成推理能力,是现有通用视觉 - 语言大模型(LVLMs)的系统性弱点 。
在 SpineBench 的评测中,这一弱点暴露无遗 :

- 性能差距明显: 即使是参数量达 72B 的 Qwen2.5-VL-72B,平均性能也仅为 79.88%。领先的开源模型 GLM-4.5V (83.26%) 与顶尖专有模型 Gemini-2.5-Pro (89.23%) 之间仍存在近 6 个百分点的差距。在医疗报告生成任务中,更是差距明显,Qwen2.5VL-72B 和 Gemini-2.5-pro 差 30%。
- 跨模态对齐缺陷: 几乎所有模型在多模态任务上的性能都有不同程度的下降 。例如,GPT5 在纯文本 QA (87.41%) 与图像 QA (79.97%) 之间的差距高达 7.44 个百分点 。这反映了现有模型在医学图像理解和视觉 - 语言对齐上的根本不足,限制了它们在需要综合分析图像和文本的临床场景中的应用。
核心成果:构建临床级 AI 的「基础设施」
为填补现有数据与临床需求之间的认知鸿沟,研究团队与实践中的脊柱外科医生共同设计和构建了 SpineMed 生态系统。
1. SpineMed-450K:椎体级、多模态指令数据集
这是首个明确为椎体级推理而设计的大规模数据集。

- 规模与来源: 包含超过 450,000 条指令实例。数据来源极其丰富,包括教科书、外科指南、专家共识、开放数据集(如 Spark、VerSe 20202020),以及约 1,000 例去识别化的多模态医院真实病例。真实病例来源于国内 11 家知名医院,确保了患者来源的多样性 。
- 生成管线: 数据生成采用了严谨的「临床医生介入」(Clinician-in-the-loop)流程。该流程涉及:
——使用 PaddleOCR 提取图文信息;
——通过新型的图像 - 上下文匹配算法,将图像与其周围的文本上下文精确绑定,保证可追溯性;
——利用 LLM 两阶段生成方法(起草和修订)来生成高质量的指令数据,且临床医生参与了提示词策略和修订标准的审查。

- 任务多样性: 涵盖四种类型——多项选择 QA(249k)、开放式 QA(197k)、多轮诊疗对话(1.1k)和临床报告生成(821 例)。数据覆盖七个骨科亚专科,其中脊柱外科数据占比 47%,并细分为 14 种脊柱亚疾病。

2. SpineBench:首个临床显著性评估基准
SpineBench 是一个与临床深度结合的评估框架,旨在评估 AI 在细粒度、以解剖为中心的推理中犯下的、在实践中至关重要的错误类型。
- 基准构成: 最终包含 487 道高质量多项选择题和 87 个报告生成提示 。
- 严谨验证: 为确保评估集的完整性,由 17 名骨科外科医生组成的团队,分成三个独立小组进行了严格的验证和校正。
- 报告评估: 针对临床报告生成任务,设计了由专家校准的框架。评估从五大板块、十个维度进行:
- 结构化影像报告(SIP):评估发现的准确性、临床意义和定量描述 。
- AI 辅助诊断(AAD):评估主要诊断的正确性、鉴别诊断和临床推理 。
- 治疗建议(TR):分为患者指导(语言清晰度、共情、安抚)、循证计划(理由、指南一致性)和技术可行性(手术细节、并发症预防)。
- 风险与预后评估(RPM):评估围手术期管理、随访安排和潜在问题策略 。
- 推理与免责声明(RD):评估证据覆盖范围、相关性、细节粒度和逻辑连贯性。

实验结果:专科 AI 模型 SpineGPT 的突破性表现
SpineGPT 基于 Qwen2.5-VL-7B-Instruct 模型,通过课程学习(Curriculum Learning)框架,分三阶段在 SpineMed-450K 上进行微调,以逐步增强其在脊柱健康领域的适用性和专业性 。

1.超越开源,逼近顶尖专有模型: SpineGPT 达到了 87.44% 的平均分,大幅领先所有开源大模型 4.18 个百分点以上。在纯文本 QA 任务上(89.46%),SpineGPT 甚至超越了所有参评模型,包括 GPT5 (87.41%) 。
2.专科数据的重要性(消融实验):
- 模型仅在通用医疗数据上训练时,性能显著下降(74.95% vs 65.31%)。
- 纳入精心策划的非脊柱通用骨科数据后,性能得到大幅提升(82.14% vs 74.95%),验证了领域对齐训练数据的重要性。
- 最终,纳入脊柱特异性训练数据(包括对话、报告生成和长链推理指令)后,模型性能进一步增强至 87.89%。
3.临床报告能力显著增强: SpineGPT 在医疗报告生成任务上的总分为 87.24 分,而 Qwen2.5-VL-72B 仅为 63.80 分,ChatGPT-4o 为 64.04 分。
- 案例对比:在对「青少年特发性脊柱侧凸」病例的分析中,SpineGPT 提供了包含 72 个详细的临床处理流程,涵盖了完整的影像发现、AI 诊断、患者和医生导向的治疗建议、风险管理和术后问题管理。相比之下,ChatGPT-4o 的报告则更偏向于适合一般医疗文档的基本诊断和治疗建议。

4.人类专家高度认可: 人类专家对报告评分与 LLM 自动评分之间的 Pearson 相关系数达到 0.382 至 0.949,大多数维度相关性在 0.7 以上。这有力地验证了 LLM 自动评分作为专家判断代理的可靠性。
结论与展望
这项研究证明了:对于脊柱诊断这样需要复杂解剖推理的专业领域,专科指令数据和「临床医生介入」的开发流程是实现临床级 AI 能力的关键。
SpineMed-450K 和 SpineBench 的发布,为未来的 AI 研究提供了一个高实用性的基线。研究团队计划将拓展数据集、训练大于 7B 参数的模型,并结合强化学习技术,继续深化与领先专有模型的直接比较,以确立更清晰的性能基准。
Pi3Lab 介绍
Pi3Lab 专注于 AI Agent 的行业落地,致力于通过 RLaaS 平台让通用模型在实际业务中真正低成本、高效率地用起来。
....
#Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
谷歌AlphaGeometry2攻克IMO几何难题,已超越金牌得主平均水准
OpenAI 与 DeepSeek 卷得不可开交的时候,谷歌 DeepMind 的数学推理模型又偷偷惊艳了所有人。
在最新的一篇论文中,谷歌 DeepMind 介绍了全新进化的 AlphaGeometry 2,该系统在解决奥林匹克几何问题方面已经超过了金牌得主的平均水准。
- 论文标题:Gold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
- 论文链接:https://arxiv.org/pdf/2502.03544
国际奥林匹克数学竞赛(IMO)是一项面向全球高中生的著名数学竞赛。IMO 问题以难度大著称,解决这些问题需要对数学概念有深刻理解,并能创造性地应用这些概念。几何是 IMO 四大题型之一,各题型之间最为统一,非常适合基础推理研究。因此,这项赛事也成为了衡量人工智能系统高级数学推理能力的理想基准。
在 2024 年 7 月,谷歌 DeepMind 曾经介绍了 AlphaGeometry (AG1),这是一个神经符号系统,在 2000-2024 年 IMO 几何问题上的解题率达到 54%,距离金牌也只有一步之遥。AG1 将语言模型 (LM) 与符号引擎相结合,有效地解决了这些具有挑战性的问题,造就了数学领域的「AlphaGo 时刻」。
尽管 AG1 取得了成功,但它在几个关键领域仍存在局限性。其性能受限于特定领域语言的范围、符号引擎的效率以及初始语言模型的容量。因此,在考虑 2000 年至今的所有 IMO 几何问题时,AG1 只能达到 54% 的解题率。
最新的这篇论文介绍了 AlphaGeometry2(AG2),它是解决了这些限制的升级版本,并显著提高了性能。AG2 利用了更强大的基于 Gemini 的语言模型,该模型是在一个更大、更多样化的数据集上训练出来的。团队还引入了速度更快、更强大的符号引擎,并进行了优化,如减少规则集和增强对二重点的处理。此外,团队还扩展了领域语言,以涵盖更广泛的几何概念,包括轨迹定理(locus theorem)和线性方程(linear equation)。
为了进一步提高性能,他们开发了一种新型搜索算法,可探索更广泛的辅助构造策略,并采用知识共享机制来扩展和加速搜索过程。最后,他们在建立一个用自然语言解决几何问题的全自动可信赖系统方面取得了进展。为此,谷歌利用 Gemini 将问题从自然语言翻译成 AlphaGeometry 语言,并实施了新的自动图解生成算法。
这些改进最终大大提高了性能:AG2 在 2000-2024 年 IMO 所有几何问题上的解题率达到了令人印象深刻的 84%,这表明人工智能在处理具有挑战性的数学推理任务方面实现了重大飞跃,并超越了 IMO 金牌得主的平均水准。
核心提升如下:
- 扩展领域语言:涵盖轨迹型定理、线性方程和非构造性问题陈述;
- 更强更快的符号引擎:优化了规则集,增加了对二重点的处理,以及更快的 C++ 实现;
- 先进新颖的搜索算法:利用知识共享的多搜索树;
- 增强的语言模型:利用 Gemini 架构在更大和更多样化的数据集上进行训练。
更强、更快的符号引擎
符号引擎是 AlphaGeometry 的核心组件,谷歌称之为演绎数据库算术推理(Deductive Database Arithmetic Reasoning,DDAR)。它是一种计算演绎闭包的算法,即给定一组核心初始事实的所有可演绎事实集合。DDAR 遵循一组固定的演绎规则来构建此演绎闭包,并迭代地将新的事实添加到演绎闭包中,直到无法再添加。
DDAR 驱动语言模型的训练数据生成以及测试时证明搜索期间的演绎步骤搜索。在这两种情况下,速度都至关重要。更快的数据生成可以达成更大规模、更积极的数据过滤,而更快的证明搜索可以实现更广泛的搜索,从而增加给定时间预算内找到解决方案的可能性。
DDAR 有以下三项主要改进:
- 处理二重点(double ponit)的能力;
- 更快的算法;
- 更快的实现。
处理二重点
在重新实现 DDAR 时,谷歌试图保持与原始算法大致相同的逻辑强度,只是由于实现差异而稍微强一些(例如泰勒斯定理被更通用的圆心角定理取代)。然而,DDAR 缺少一个对解决难题至关重要的关键特性:它无法接受两个名称不同但坐标相同的点。
例如,想象一个问题:在点 𝑋 处两条线 𝑎,𝑏 相交,并打算证明 𝑋 位于某个圆 𝜔 上。最合理的方法可能是重构,不证明 𝑎,𝑏 的交点在 𝜔 上,而是证明 𝑎,𝜔 的交点在 𝑏 上。这是等效的,但更容易证明,因为可以在圆上移动角度。具体可参见图 1。
要对双重点推理实现这种重构,需要执行以下四个步骤:
- 构造一个新点𝑋′作为 𝑎,𝜔 的交点(不知道 𝑋′ 是否与 𝑋 重合)。这是一个辅助构造,必须由语言模型预测;
- 证明𝑋位于𝑏上;
- 由于𝑋和𝑋′都位于𝑎,𝑏上,得出𝑋 = 𝑋′;
- 因此𝑋位于𝜔上。

更快的算法
DDAR 算法可以处理一系列规则,并尝试将每条规则应用于所有点的组合。此过程涉及以下两个部分:
- 候选搜索步骤,它的时间复杂度是点数的多项式;
- 子句匹配步骤,它的时间复杂度是每个前提的子句数的指数。
理论上,在 AG1 中搜索相似三角形候选的最坏情况是 𝑂(𝑁^8),这是最耗时的步骤之一。指数级子句匹配是另一个成本高昂的步骤。
DDAR 最耗时的两个部分是搜索相似三角形和搜索圆内接四边形。在 AG2 中,谷歌设计了一种改进的 DDAR2 算法。对于相似三角形,他们遍历所有的点三元组,对它们的「形状」进行哈希处理。如果两次识别出形状,则检测出相似的对。
对于圆内接四边形,谷歌遍历所有对(点𝑋、线段𝐴𝐵),并对(𝐴,𝐵,∠𝐴𝑋𝐵)的值进行哈希处理。如果这样的三元组重复出现,就得到一个圆内接四边形。线段 𝐴𝐵 或 ∠𝐴𝑋𝐵 的「值」是指 AR 子模块计算出的符号范式。该子模块跟踪角度、距离和对数距离之间的已知线性方程,了解其代数结果,并将任何线性表达式简化为其标准范式。
更快的实现
虽然新算法已经显著加快了 DDAR 的速度,但谷歌使用 C++ 实现其核心计算(高斯消元法),从而进一步提升了速度。
新的 C++ 库通过 pybind11 导出到 Python,速度是 DDAR1 的 300 多倍。为了对速度改进进行基准测试,谷歌选择了一组 25 道 DDAR 无法解决的 IMO 问题(见图 8),并在配备 AMD EPYC 7B13 64 核 CPU 的机器上运行测试 50 次。
结果显示,DDAR1 平均可以在 1179.57±8.055 秒内完成计算,但 DDAR2 的速度要快得多,在 3.44711 ± 0.05476 秒内完成。

更好的合成训练数据
与 AG1 类似,谷歌使用的合成数据生成方法从随机图采样开始,并使用符号引擎从中推断出所有可能的事实。并且对于每个推断出的事实,他们都使用回溯算法来提取可以证明事实的相应前提、辅助点和推理步骤。
谷歌的数据生成方法刻意避免使用人为设计的问题作为初始图种子,并严格从随机图开始。这种设计选择消除了数据污染的风险,并允许探索可能超出现有人类知识的定理分布。
更大、更复杂的图表和更好的数据分布。首先,谷歌扩大数据生成的来源,并更仔细地重新平衡数据分布。图 2 展示了 AG2 与 AG1 的训练数据比较:
- 探索两倍大小的随机图,从而提取更复杂的问题;
- 生成的定理复杂了两倍,即点和前提的数量;
- 生成的证明复杂了 10 倍,即证明步骤多 10 倍;
- 问题类型之间的数据分布更均衡;
- 有无辅助点的问题之间的数据分布更均衡。

更快的数据生成算法。谷歌还提升了数据生成算法的速度。回想 AG1,谷歌首先在随机图上运行演绎闭包,然后回溯以获得可以证明闭包中每个事实的最小问题和最小证明。为了获得 AG1 中的最小问题,必须从问题中彻底删除不同的点子集,然后重新运行 DDAR 以检查可证明性。这样的搜索可以找到基数最小的子集,但是作为指数级搜索,对于大量的点而言不可行。
因此,谷歌切换到图 3 所示的贪婪丢弃算法,该算法仅使用线性数量的检查来判断一组点是否足以证明目标。只要检查是单调的(如果 𝐴 ⊆ 𝐵,则 check_provable (𝐴) ⇒ check_provable (𝐵)),贪婪算法就保证找到一组关于包含(inclusion)的最小点集。

新颖的搜索算法
在 AG1 中,谷歌使用简单的束搜索来发现证明。在 AG2 中,他们设计了一种新颖的搜索算法,可以并行执行多个不同配置的束搜索,并允许它们通过知识共享机制互相帮助,具体可见图 4。为了提高系统的稳健性,谷歌还为每个搜索树配置使用多个不同的语言模型。这种搜索算法被称为搜索树的共享知识集合(Shared Knowledge Ensemble of Search Trees,SKEST) 。
该搜索算法的工作原理如下所示:在每个搜索树中,一个节点对应于一次辅助构造尝试,然后是一次符号引擎运行尝试。如果尝试成功,所有搜索树都会终止。如果尝试失败,节点将把符号引擎设法证明的事实写入共享事实数据库。这些共享事实经过过滤,使它们不是特定于节点本身的辅助点,而仅与原始问题相关。这样一来,这些事实也可以对同一搜索树中的其他节点以及不同搜索树中的节点产生助益。

系统设计细节。对于证明搜索,谷歌使用 TPUv4 为每个模型提供多个副本,并让同一模型内的不同搜索树根据自身的搜索策略来查询同一服务器。除了异步运行这些搜索树之外,谷歌还对 DDAR 工作器与 LM 工作器进行异步运算,其中 LM 工作器将它们探索的节点内容写入数据库,DDAR 工作器异步拾取这些节点并尝试它们。DDAR 工作器之间相互协调,以确保它们平等分配工作。单个 DDAR 工作器池在不同问题之间共享(如果一次解决多个问题),这样先前解决的问题就会为正在解决的其余问题释放自己的 DDAR 计算资源。
更好的语言模型
AG2 的最后一项改进是使用新的语言模型。下面将讨论全新的训练和推理设置。
训练设置
AG1 是一种定制版 Transformer,以无监督方式分两个阶段进行训练:先对有无辅助结构的问题进行训练,然后仅对包含辅助结构的问题进行训练。
对于 AG2,谷歌利用了 Gemini 训练流程并将训练简化为一个阶段:对所有数据进行无监督学习。他们使用了一种基于稀疏混合专家(MoE)Transformer 的新模型,该模型以 Gemini 1.5 为基础,并使用 AG2 数据进行训练。
谷歌使用以下三种设置来训练不同大小的多个模型:
1. 使用领域特定语言中的自定义 tokenizer 从头开始训练(AG1 设置);
2. 使用自然语言微调已经预训练的自定义专业数学 Gemini 模型;
3. 使用额外的图像输入(给定几何题的图表)从头开始进行多模态训练。
谷歌使用 TPUv4,并以硬件允许的最大批大小训练模型。学习率计划是先线性预热,然后余弦退火。学习率超参由 scaling 定律确定。在图 5 中,他们展示了基于参数量的不同大小的 Gemini 的学习曲线。正如预期的那样,增加模型大小会降低训练、评估以及特殊 IMO 评估集的困惑度损失。

推理设置
在 AG2 中,谷歌在提出辅助构造之前让 LM 了解 DDAR 所做的推论,进而丰富这个神经符号接口。也就是说,他们将以下信息输入到 LM 中
- 𝑆_1:给定原始问题前提,DDAR 可推导出的事实集;
- 𝑆_2:给定原始问题前提并假设目标谓词也为真,DDAR 可推导出的事实集;
- 𝑆_3:数字正确的事实集(检查图表)。
竞赛结果
本文的主要下游指标是 IMO 几何题的解决率。2000-2024 年 IMO 共有 45 道几何题,谷歌将它们转化为了 50 道 AlphaGeometry 问题(称该集合为 IMO-AG-50)。
图 8 展示了主要结果,AlphaGeometry2 解决了 2000-2024 年 IMO 所有 50 道几何题中的 42 道,从而首次超越了金牌得主平均水平。

表 4 中提供了更多详细信息,其中将各种 AG2 配置与其他系统进行了比较。可以看到,AG2 实现了 SOTA。

在图 7 中,针对通过前文「经典」树搜索与 DDAR 耦合的一个语言模型,谷歌将 IMO 解决率表示为了训练时函数(训练期间看到的 tokens)。有趣的是,AG2 仅在批大小为 256 时的 250 个时间步后(或者大约 2 亿 tokens),就解决了 50 道几何题中的 27 道。

谷歌还对推理设置如何影响整体性能进行了消融实验,结果如图 9 所示。他们发现,对于单个搜索树,最优配置是束大小 128、束深度 4 以及样本 32。

....
#DALL-E 4
OpenAI内测Sora图像生成器,代号「papaya」,DALL-E 4即将推出?
一则非常重要的消息:除了已有的视频生成功能,OpenAI 似乎还在为 Sora 推出图像生成功能做准备。
OpenAI 正在内部测试这些图像生成功能:包括一个新的隐藏切换按钮,能允许用户在提示栏中直接在视频和图像生成之间切换。如果切换到图像,提示栏的描述会提示你描述一幅图像。

OpenAI 还对 Sora 的视频推送进行了改版,将其分为「Best」和「Top」两个类别。「Best」很可能与目前的特色频道类似。不过,「Top」类别可能允许按某个时间段进行筛选,并可能根据点赞数或其他标准对视频进行排名。
OpenAI 的这个动作让很多人重新兴奋起来,因为现有的 DALL-E 3 已经非常过时了 —— 至少和 Midjourney 比起来是这样。

该功能目前还未投入使用,但左侧导航栏上还有一个「Images Internal」类别。目前,它打开的是视频推送。不过,将来用户也有可能在这里找到图片推送。目前还不清楚 OpenAI 将添加何种图像生成功能,也不清楚将由哪款模型提供。
有人猜测我们可能会「在某个时候看到 DALL-E 4」,但 OpenAI 官方没有对此进行确认。

但 Sora 中的图像生成模型应该不是 DALL-E 4。OpenAI 在去年首次发布 Sora 时就提到了图像生成功能,所以一种可能是:它将由现有的「sora-turbo」模型驱动。

此外,有人突然想起:我们还没有在 ChatGPT 上看到来自 GPT-4o 的多模态图像生成功能。

还有消息说,Sora 中的文本到图像生成器代号为「papaya」:

回想起来,OpenAI 发布 DALL-E 3 距今也有一年半了,下一代模型会有怎样的创新?你有何期待?
参考链接:https://x.com/testingcatalog/status/1888256244063838527
....
#DeepSeek冲击下,奥特曼刚刚给出对AGI的「三个观察」,包括成本速降
今天凌晨,OpenAI CEO 再次发布长文,重申自己对于 AGI 的三个观察。

核心观点如下:
1. 人工智能模型的智能大致等于用于训练和运行该模型的资源的对数。
2. 使用一定水平的人工智能的成本每 12 个月就会下降约 10 倍,而较低的价格会带来更多的使用。
3. 线性增长的智能的社会经济价值具有超指数性质。
DeepSeek 等科技公司推出的强大且价格低廉的人工智能模型似乎支持了第一个观点。有证据表明,训练和开发成本也在下降。基于第二个观点,尽管推动人工智能技术的边界不会变得更便宜,但用户将在此过程中获得越来越强大的系统。但奥特曼指出,要实现 AGI 甚至更高级别的人工智能,仍然需要大量投资。
OpenAI 实际上并不打算通过使用 AGI 一词来在短期内结束与密切合作伙伴兼投资者微软的关系。我们知道,微软和 OpenAI 对 AGI 有一个非常具体的定义 —— 可以产生 1000 亿美元利润的人工智能系统。一旦满足这一定义,OpenAI 就可以协商更有利的投资条款。
这不是奥特曼第一次声称 AGI 即将问世。而博客中的「我们现在已经开始推出 AI 智能体,它们最终会给人一种虚拟同事的感觉」,更是让人好奇这家公司即将带来怎样的技术突破。

与此同时,OpenAI 官方的一条新动态引发了人们的猜想:莫非这几天要有新发布了?

这一次,OpenAI 将会以何种形式解锁通往 AGI 的新关卡?
以下是奥特曼博客原文整理:
我们的使命是确保 AGI 造福全人类。
开始指向 AGI 的系统正在进入人们的视野,因此我们认为了解我们所处的时刻非常重要。AGI 是一个定义模糊的术语,但一般来说,我们的意思是,它是一个能够在人类水平上解决许多领域日益复杂问题的系统。
人是工具的创造者,天生就有一种理解和创造的动力,这将使我们所有人的世界变得更加美好。每一代人都在前人发现的基础上创造出功能更强大的工具 —— 电力、晶体管、计算机、互联网,以及即将出现的人工智能。
随着时间的推移,人类不断创新,带来了前所未有的繁荣,改善了人们生活的方方面面。
从某种意义上说,AGI 只是我们共同搭建的人类进步的脚手架上的又一个工具。从另一种意义上说,这是一个开始,很难不说「这次不一样」;我们眼前的经济增长看起来令人震惊,我们现在可以想象这样一个世界:我们可以治愈所有疾病,有更多的时间与家人享受天伦之乐,可以充分发挥我们的创造潜能。
十年后,也许地球上的每个人都能比今天最有影响力的人取得更大的成就。
我们将继续看到人工智能的快速发展。以下是关于人工智能经济学的三点观察:
1. 人工智能模型的智能大致等于用于训练和运行该模型的资源的对数。这些资源主要是训练计算、数据和推理计算。看起来,你可以花费任意数量的资金,获得持续且可预测的收益;预测这一点的 Scaling Law 在许多数量级上都是准确的。
2. 使用一定水平的人工智能的成本每 12 个月就会下降约 10 倍,而较低的价格会带来更多的使用。从 2023 年初的 GPT-4 到 2024 年中的 GPT-4o 的 token 成本就可以看出这一点,在这段时间内,每 token 的价格下降了约 150 倍。摩尔定律每 18 个月改变世界的速度达到了 2 倍,这简直强得令人难以置信。
3. 线性增长的智能的社会经济价值具有超指数性质。由此产生的一个结果是,我们认为指数级增长的投资在不久的将来没有理由停止。
如果这三个观点继续成立,那么对社会的影响将是巨大的。
我们现在已经开始推出 AI 智能体,它们最终会给人一种虚拟同事的感觉。
让我们来设想一个专注于软件工程的智能体,这是我们期望的、特别重要的智能体。想象一下,这个智能体最终将能够完成顶级公司中拥有数年经验的软件工程师所能完成的大部分任务,而且这些任务可能需要几天时间。可能这些智能体不会有最伟大的新想法,需要大量的人工监督和指导,在某些事情上表现出色,但在另一些事情上却出人意料地糟糕。
尽管如此,我们还是可以将其想象为一个真实但相对初级的虚拟同事。设想一下有 1000 个这样的虚拟同事,或者 100 万个。更进一步的,想象一下在每一个知识工作领域都有这样的虚拟同事。
在某些方面,人工智能在经济上可能会像晶体管一样 — 一个规模巨大的科学发现,几乎渗透到经济的每一个角落。我们不会过多地考虑晶体管或晶体管公司,而且其收益分布非常广泛。但我们确实期望我们的电脑、电视、汽车、玩具等能够创造奇迹。
世界不会一下子改变,从来都是如此。在短期内,我们的生活将基本保持不变,2025 年的人们将以 2024 年的方式度过他们的大部分时间。我们仍然会恋爱、建立家庭、在网上吵架、在大自然中远足等等。
但是,未来将以一种无法忽视的方式向我们袭来,我们的社会和经济将发生巨大的长期变化。我们将找到新的工作、新的互利方式和新的竞争手段,但它们可能与今天的工作不太一样。
智能化、意志和决心可能会变得极其宝贵。正确决定要做什么以及如何驾驭瞬息万变的世界将具有巨大的价值;应变能力和适应能力将是需要培养的有用技能。AGI 将成为人类意志力的最大杠杆,使个人的影响力超过以往任何时候。
我们预计,AGI 的影响将是不均衡的。虽然有些行业的变化很小,但科学进步的速度可能会比今天快得多;AGI 的这种影响可能会超过其他一切。
许多商品的价格最终会大幅下降(现在,智能成本和能源成本制约了很多东西),而奢侈品等少数固有的有限资源的价格可能会更大幅上涨。
从技术上讲,我们面前的道路看起来相当清晰。但是,关于如何将人工智能融入社会的公共政策和集体意见非常重要;我们之所以要尽早、频繁地推出产品,其中一个原因就是要给社会和技术留出共同发展的时间。
人工智能将渗透到经济和社会的各个领域;我们将期望一切都变得智能。我们中的许多人预计需要给予人们比以往更多的技术控制权,包括更多的开源,并接受安全与个人能力之间的平衡,这需要权衡利弊。
虽然我们永远不想鲁莽行事,而且很可能会有一些与 AGI 安全相关的重大决定和限制会不受欢迎,但从方向上来说,随着我们越来越接近实现 AGI,我们认为更趋向于个人赋权是很重要的。
确保广泛分配人工智能的好处至关重要。技术进步的历史影响表明,我们关心的大多数指标(健康结果、经济繁荣等)都会在平均水平上长期改善,但平等程度的提高似乎并不是由技术决定的,要做到这一点可能需要新的想法。
特别是,资本和劳动力之间的力量平衡似乎很容易被打破,这可能需要早期干预。我们对一些听起来很奇怪的想法持开放态度,比如给予一定的计算预算,让地球上的每个人都能使用大量的人工智能,但我们也能看到很多方法,只要坚持不懈地尽可能降低智能成本,就能达到预期效果。
到 2035 年,每个人都应该能够调动相当于 2025 年所有人的智力总和;每个人都应该拥有无限的智慧,可以随心所欲地运用。目前,世界上有许多人才因资源不足而无法充分展现自己,如果我们改变这一现状,全球的创造力将得到极大释放,从而为我们所有人带来巨大的利益。
参考链接:
https://blog.samaltman.com/three-observations
https://x.com/sama/status/1888695926484611375
....
#李飞飞团队26分钟训练即可媲美o1和R1
成本不到150元,训练出一个媲美DeepSeek-R1和OpenAI o1的推理模型?!
这不是洋葱新闻,而是AI教母李飞飞、斯坦福大学、华盛顿大学、艾伦人工智能实验室等携手推出的最新杰作:s1。
在数学和编程能力的评测集上,s1的表现比肩DeepSeek-R1和o1。
而训一个这样性能的模型,团队仅仅用了16个英伟达H100,训练耗时26分钟。
据TechCrunch,这个训练过程消耗了不到50美元的云计算成本,约合人民币364.61元;而s1模型作者之一表示,训练s1所需的计算资源,在当下约花20美元(约145.844元)就能租到。
怎么做到的???
s1团队表示,秘诀只有一个:蒸馏。
简单来说,团队以阿里通义团队的Qwen2.5- 32B-Instruct作为基础模型,通过蒸馏谷歌DeepMind的推理模型Gemini 2.0 Flash Thinking实验版,最终得到了s1模型。
为了训练s1,研究团队创建了一个包含1000个问题(精心挑选那种)的数据集,且每个问题都附有答案,以及Gemini 2.0 Flash Thinking实验版的思考过程。
目前,项目论文《s1: Simple test-time scaling》已经挂上arXiv,模型s1也已在GitHub上开源,研究团队提供了训练它的数据和代码。
150元成本,训练26分钟
s1团队搞这个花活,起因是OpenAI o1展现了Test-time Scaling的能力。
即「在推理阶段通过增加计算资源或时间,来提升大模型的性能」,这是原本预训练Scaling Law达到瓶颈后的一种新Scaling。
但OpenAI并未公开是如何实现这一点的。
在复现狂潮之下,s1团队的目标是寻找到Test-time Scaling的简单方法。
过程中,研究人员先构建了一个1000个样本的数据集,名为s1K。
起初,在遵循质量、难度、多样性原则的基础上,这个数据集收集了来自MATH、AGIEval等诸多来源的59029个问题。
经去重、去噪后,通过质量筛选、基于模型性能和推理痕迹长度的难度筛选,以及基于数学学科分类的多样性筛选,最终留下了一个涵盖1000个精心挑选过的问题的数据集。
且每个问题都附有答案,以及谷歌Gemini 2.0 Flash Thinking实验版的模型思考过程。
这就是最终的s1K。
研究人员表示,Test-time Scaling有2种。
第1种,顺序Scaling,较晚的计算取决于焦躁的计算(如较长的推理轨迹)。
第2种,并行Scaling,be like计算独立运行(如多数投票任务)。
s1团队专注于顺序这部分,原因是团队“从直觉上”认为它可以起到更好的Scaling——因为后面的计算可以以中间结果为基础,从而允许更深入的推理和迭代细化。
基于此,s1团队提出了新的顺序Scaling方法,以及对应的Benchmark。
研究过程中,团队提出了一种简单的解码时间干预方法budget forcing,在测试时强制设定最大和/或最小的思考token数量。
具体来说,研究者使用了一种很简单的办法:
直接添加“end-of-thinking token分隔符”和“Final Answer”,来强制设定思考token数量上限,从而让模型提前结束思考阶段,并促使它提供当前思考过程中的最佳答案。
为了强制设定思考过程的token数量下限,团队又禁止模型生成“end-of-thinking token分隔符”,并可以选择在模型当前推理轨迹中添加“wait”这个词,鼓励它多想想,反思反思当前的思考结果,引导最佳答案。
以下是budget forcing这个办法的一个实操示例:
团队还为budget forcing提供了baseline。
一是条件长度控制方法(Conditional length-control methods),该方法依赖于,在提示中告诉模型它应该花费多长时间来生成输出。
团队按颗粒度将它们分为Token-conditional控制、步骤条件控制和类条件控制。
- Token-conditional控制:在提示词中,指定Thinking Tokens的上限;
- 步骤条件控制:指定一个思考步骤的上限。其中每个步骤约100个tokens;
- 类条件控制:编写两个通用提示,告诉模型思考短时间或长时间。
二是拒绝抽样(rejection sampling)。
即在抽样过程中,若某一生成内容符合预先设定的计算预算,就停止计算。
该算法通过其长度来捕捉响应的后验分布。
而s1模型的整个训练过程,只用了不到半个小时——
团队在论文中表示,他们使用Qwen2.532B-Instruct模型在s1K数据集上进行SFT,使用16个英伟达H100,训练耗时26分钟。
s1研究团队的Niklas Muennighoff(斯坦福大学研究员)告诉TechCrunch,训练s1所需的计算资源,在当下约花20美元就能租到。
研究新发现:频繁抑制思考会导致死循环
训出模型后,团队选用3个推理基准测试,把s1-32B和OpenAI o1系列、DeepSeek-R1系列、阿里通义Qwen2.5系列/QWQ、昆仑万维Sky系列、Gemini 2.0 Flash Thinking实验版等多个模型进行对比。
3个推理基准测试如下:
- AIME24:2024年美国数学邀请考试中使用的30个问题
- MATH500:不同难度的竞赛数学问题的基准
- GPQA Diamond:生物、化学和物理领域的198个博士级问题
整体来说,采用了budget forcing的s1-32B扩展了更多的test-time compute。
评测数据显示,s1-32B在MATH500上拿到了93.0的成绩,超过o1-mini,媲美o1和DeepSeek-R1。
不过,如下图所示,团队发现,虽然可以用budget forcing和更多的test-time compute来提高s1在AIME24上的性能,在AIME24上比 o1-preview最高提升27%。
但曲线最终在性能提升6倍后趋于平缓。
由此,团队在论文中写道:
过于频繁地抑制思考结束标记分隔符,会导致模型进入重复循环,而不是继续推理。
而如下图所示,在s1K上训练Qwen2.5-32B-Instruct来得到s1-32B,并为它配备了简单的budget forcing后,它采用了不同的scaling范式。
具体来说,通过多数投票在基础模型上对test-time compute进行Scale的方法,训出的模型无法赶上s1-32B的性能。
这就验证了团队之前的“直觉”,即顺序Scaling比并行Scaling更有效。
此外,团队提到,s1-32B仅仅使用了1000个样本训练,在AIME24上的成绩就能接近Gemini 2.0 Thinking,是“样本效率最高的开源数据推理模型”。
研究人员还表示,Budget forcing在控制、缩放和性能指标上表现最佳。
而其它方法,如Token-conditional控制、步骤条件控制、类条件控制等,均存在各种问题。
One More Thing
s1模型,是在一个1000个精挑细选的小样本数据集上,通过SFT,让小模型能力在数学等评测集上性能飙升的研究。
但结合近期刷爆全网的DeepSeek-R1——以1/50成本比肩o1性能——背后的故事,可以窥见模型推理技术的更多值得挖掘之处。
模型蒸馏技术加持下,DeepSeek-R1的训练成本震撼硅谷。
现在,AI教母李飞飞等,又一次运用「蒸馏」,花费低到令人咋舌的训练成本,做出了一个能媲美顶尖推理模型的32B推理模型。
一起期待大模型技术更精彩的2025年吧~
arXiv:https://arxiv.org/pdf/2501.19393
GitHub:https://github.com/simplescaling/s1
参考链接:
....
#怎样让 PPO 训练更稳定
早期人类征服 RLHF 的驯化经验
作为 Reinforcement Learning 中的顶流算法,PPO 已经统领这个领域多年。直到 [InstructGPT] 的爆火,PPO 开始进军 LLM 领域,凭借其 label-free 的特性不断拔高基座的性能,在 [Llama2]、[Baichuan] 的工作中都能看到 RLHF 的身影。
于是你开始摩拳擦掌,跃跃欲试,准备利用这项强大的技术来进化自己的基座,
但当你信心满满地跑通训练任务时,你看到的情况很有可能是这样的:
各种形形色色的失败案例
尽管鲁迅先生曾言:真的强化敢于直面惨淡的结果,敢于正视崩坏的曲线。
但日复一复地开盲盒难免会让人心脏承受不了,好在前人们留下了宝贵的驯化经验。
我们今天一起来看一篇「如何稳定且有效地训练 PPO」的论文,
在这篇文章中我们将学习:哪些技巧能够稳定训练过程、哪些指标能够代表着训练的顺利进行等内容。
Paper 传送门:Secrets of RLHF in Large Language Models Part I: PPO
Code 地址:https://github.com/OpenLMLab/MOSS-RLHF/tree/main
1. Reward Model 训练
RL 的整个训练目标都是围绕着 reward 来进行,传统 RM 的训练公式为拉开好/坏样本之间的得分差:

y_w 为 selected 样本,y_l 为 rejecte 样本
但是,仅仅是「拉开得分差」这一个目标很有可能让 RM 陷入到「钻牛角尖」的困境中,
为了保持住 RM 的本质还是一个「语言模型」,文章在原本的 loss 中加入了对「好样本」的 LM loss:

在原来的 loss 基础上顺便学习写出「优秀样本」,保持住模型能写句子的能力
值得一提的是:文章中的 r' 是用了另外一个 RM' 来算 loss 的,RM' 的结构和 RM 一样,只不过输出的维度不是 1,而是 vocab_size。但其实我认为也可以使用一个带有 ValueHead 的模型来既训练打分又训练写句子,毕竟这 2 个任务都需要模型知道什么的句子是「好句子」—— 还能省显存。
以下是论文训练 RM 的详细参数:

一般的,我们会使用 prefered sample - disprefered sample 的分差来衡量 RM 的效果:
图左为在中文标注数据集上的分差分布,图右为在英文数据集上的分差分布(区分度不如中文)
完全理想的状况下,prefered - disprefered 应该都在 0 的右边(好样本的分数更高),
但考虑到标注中的噪声、模型的拟合能力等,存在少小部分 0 左边的样本是合理的,拉出来人工评估下即可。
此外,文中还提到:只看 Acc 并不能够很好的衡量 RM 的性能,但尚未给出其他可以衡量的指标。
2. PPO 的稳定训练方法
2.1 及时发现训练过程中的异常
PPO 训练中很常见的一个问题是「模式崩溃」,其典型特征为:长度很长且无意义的文字。

而对于这种「崩溃的输出」Reward Model 往往还容易打出一个很高的分数,这将导致我们无法在训练过程中及时的发现问题,等训完对着一个满意分数的 checkpoint 看生成结果的时候才发现空欢喜一场。
对于上述这种问题,我们可以通过 3 个指标来监控:KL、Response Length、Perplexity。
训练过程中的各种指标,从约第 420 step 开始: 1. reward 出现骤增。2. KL 出现骤增。3. Perplexity 出现骤降。4. Response Length 出现骤增。5. 训练效果出现骤降(图左上红线)
因此我们可以总结出几种指标异常的情况:
- Reward 出现骤增:很可能 Policy Model 找到了某条 shortcut,比如通过模式崩溃来获得更高的分数。
- KL 出现骤增:同上,很可能此时的输出模式已经完全崩溃。
- Perplexity 骤降:由于 PPL 是指代模式对当前生成结果的「确定性」,一般来讲,句子的生成都会带有一定的不确定性,当 Policy Model 对某一个生成结果突然「非常确定」的时候(无论是什么样的上文都很确定接下来应该输出什么),那么它大概率是已经拟合到了一个确定的「崩坏模式」上了。
- Response Length 骤增:这个对应我们之前给的 bad case,回复长度的骤增也可能代表当前输出已经崩溃。
2.2 Score Normalization & Clipping
PPO 的整个训练都是围绕优化 Score 作为目标来进行的,和 Score 相关的变量有 2 个:
- Reward:由 RM(≈ Human) 直接给出的反馈。
- Advantages:由 Reward 和 Critic Model 共同决定的优势值,最终用于 loss 计算。
对于这 2 个值,我们都可以对其进行「归一化」和「裁剪」。
Reward 的处理公式如下:
Reward Normalization & Clipping
上述式子将 reward 化成了一个均值为 0 的标准分布,均值为 0 是为了保证在训练过程中得到的正负奖励能够尽可能的均匀,如果一段时间内全为负或全为正从直觉上来讲不太利于模型学习。
文中提到,使用 clipping 可以限制模型进化的「最终分数」没有那么高,
鉴于之前「分数越高,并不一定有更好的效果」的结论,作者认为使用 clipping 对最终的效果是有益的。
至于 Advantages,在 PPO 的标准流程里已经会对其进行 Normalization,而 advantage clipping 和 reward clipping 在本质上其实很相似,则只用在 reward 阶段进行截断即可,所以对于 Advantage 来讲不需要做太多其他额外的操作。
2.3 Policy Loss 设计
在传统的 PPO 流程中,我们通常会对 Policy Molde 的 Loss 上做以下 2 种操作:
- Importance Sampling:这是 PPO 中加快 On-Policy 算法训练速度的关键步骤,即一次采样的数据可以进行多次更新(通过系数补偿)。这种方法通常和 KL 惩罚一起使用,实验表明这样能够更加稳定 PPO 的训练,但对最终的效果会存在一定折损(所以最好的还是 1 轮 sample 只做一次 update,退化为原始的 PG 流程)。
- Entropy Loss:一般为了鼓励 Policy 在进化的同时保留「探索」的能力,我们会在 loss 中加入 entropy(确定性)loss,但在 RLHF 中这项设置对超参非常敏感,很容易就崩掉。鉴于 KL 和 Entropy 有着相似的效果,因此作者更推荐使用 KL 来代替 Entropy Loss。
除了上述 2 个传统设置外,RLHF 中加入一个新的指标:Token Level KL-Penalty。
在传统的 RL 流程中,agent 每采取一个 action 后都会得到一个 action reward,
对比到文本生成任务中,每新生成一个 token 就等于做出了一次 action,
但实际上我们无法每生成一个 token 就打出一个分数,我们只能在一个完整句子(Trajectory)生成完成之后打出一个 Total Reward。
这就比较痛苦了,当我们只有一个长序列的最后得分时,前面的每一个 step 的得分估计就变得非常困难。
因此,为了避免「sparse reward」的同时限制 Policy Model 朝着「相对合理的方向」进化,
我们会通过计算每个生成 token 与参考模型之间的 KL 来作为单个 token 的 reward 分数。

式子的前半部分为 reward(discounted)后半部分为 KL 惩罚分数
2.4 模型初始化
PPO 继承自 Actor-Critic 框架,因此算法中一共包含 2 个模型:Actor 和 Critic。
- Actor Model(Policy Model)
Policy Model 是指我们最终训练后使用的生成模型,Policy Model 需要具备一定基本的能力才能保证训练的稳定性,通常会选用 SFT 之后的模型。这个比较好理解,如果我们选用 Pretrained Model 为起点的话,探索空间会非常大,同时也更加的不稳定(对 Reward Model 要求更高)。
- Critic Model
一种很直觉的想法是:同样是「评判任务」,我们直接使用 Reward Model 来当作 Critic Model 就好了。
但其实这种想法不完全正确,从本质上来讲 Critic 需要对每一个 token 的状态进行打分,而 RM 是对整个句子进行综合得分评估,这两个任务还是存在一定的区别。
因此,一种更好的方式是:先训练 Critic Model一段时间,直到 Critic Loss 降的相对较低为止。
预先训练能够帮助在正式训练的初期 Critic 能够进行较为正确的 value 预估,从而稳定训练过程,
至于使用 SFT 还是 RM 作为 Critic 的结构,实验结果显示并没有非常明显的区别。
2.5 最优策略集合(PPO-max)
文章的末尾给出了作者汇聚了各种实验结果给出的一套推荐的策略:
- reward normalize:使用历史获得过的所有 reward 的均值和方差进行标准化。
- token KL penalty:限制模型更新方向。
- Critic Model:使用 RM 初始化 Critic,并在 PPO 正式训练之前先进行 Critic 预训练。
- Global Gradient Clipping
- 使用相对较小的 Experience Buffer。
- Pretrain Loss:在 PPO 训练 loss 中加入 Pretrain Language Model Loss,和 [InstructGPT] 中保持一致。
PPO-max 所使用的方法合集(标星的方法)
学习率设置:

这里顺便贴出 [Baichuan 2] 中 PPO 的参数设置:

....
#飞书接入DeepSeek-R1
飞书接入DeepSeek-R1后,用一次顶一万次,而且再也不「服务器繁忙」了
如果你最近经常使用 DeepSeek-R1,那你一定很熟悉以下截图了:

以至于我们人类也祭出奇招,非得让 DeepSeek-R1 亲自尝尝服务器繁忙失联的痛苦。

巨大的用户需求带来的巨大访问量已经让 DeepSeek 的服务器不堪重负,这也极大地影响了用户们的使用体验。于是各种替代官网的客户端和 API 的服务也不断涌现;与此同时,也不断有各种新服务和应用宣布接入或整合 DeepSeek-R1。
前两天,DeepSeek 还在 GitHub 专门创建了一个库来收集展示各种整合了 DeepSeek 模型的应用和服务,其中既包括 Chatbox、思源笔记、LibreChat 等应用,也有一些智能体框架、RAG 框架以及浏览器或 IDE 插件等。这个开源模型的生态系统正在高速稳步地建立起来。
GitHub 地址:https://github.com/deepseek-ai/awesome-deepseek-integration
就在不久前,飞书也宣布接入了 DeepSeek-R1,这相当于在我们日常熟悉的办公软件中又探索出了一种全新的 AI 交互方式。原来我们找 AI 帮忙,往往是一次性提供一个 prompt,即使 prompt 写得再周全,从本质而言也是一对一的单点输入输出。想要一次性批量处理任务,就需要掌握一些「思维链」或者批量调用 API 服务的技巧了。
以写文献综述为例,我们需要从上千份文献中挑出和自己最相关的,如果使用 API 批量处理,整个流程是这样的 —— 首先需要在 Web of Science 等论文库筛选出备选文献并导出 Excel 格式,然后构造合适的指令模板,用函数将 Excel 各行数据关联起来,再提交给 AI 开放平台处理。等待结果返回后,还得抽检一下 AI 的判断是否靠谱。
虽然这个过程并不复杂,却不如接入了 DeepSeek-R1 的飞书一步到位。现在,飞书中的每个表格都相当于一个 prompt 输入框,你可以把需求和背景当作一列数据粘贴进去,DeepSeek-R1 就能按这个队列全自动处理了。
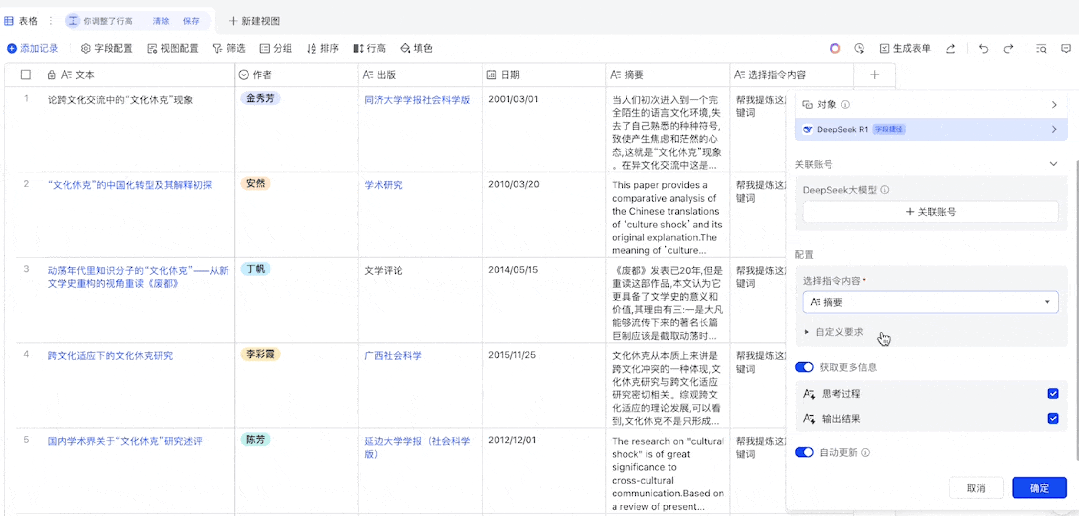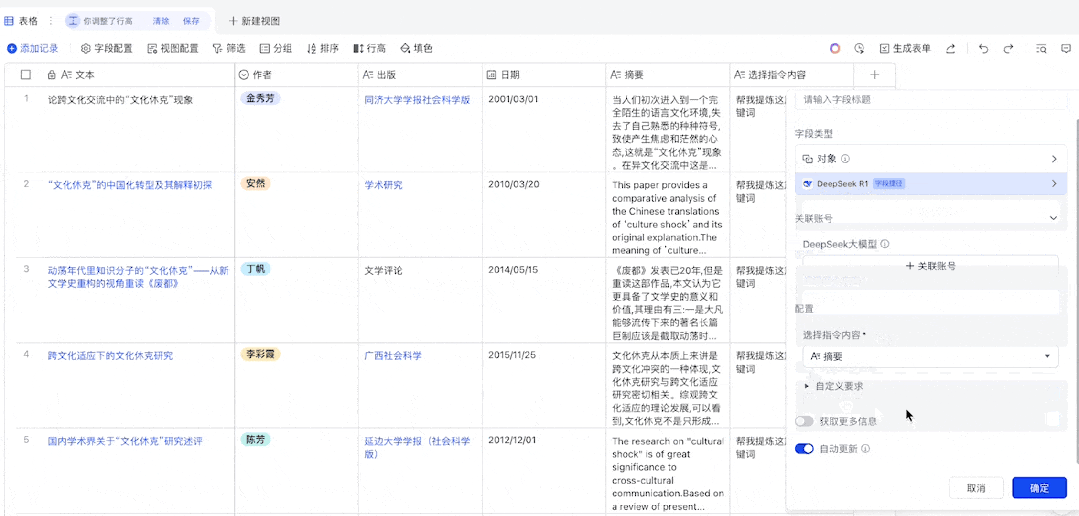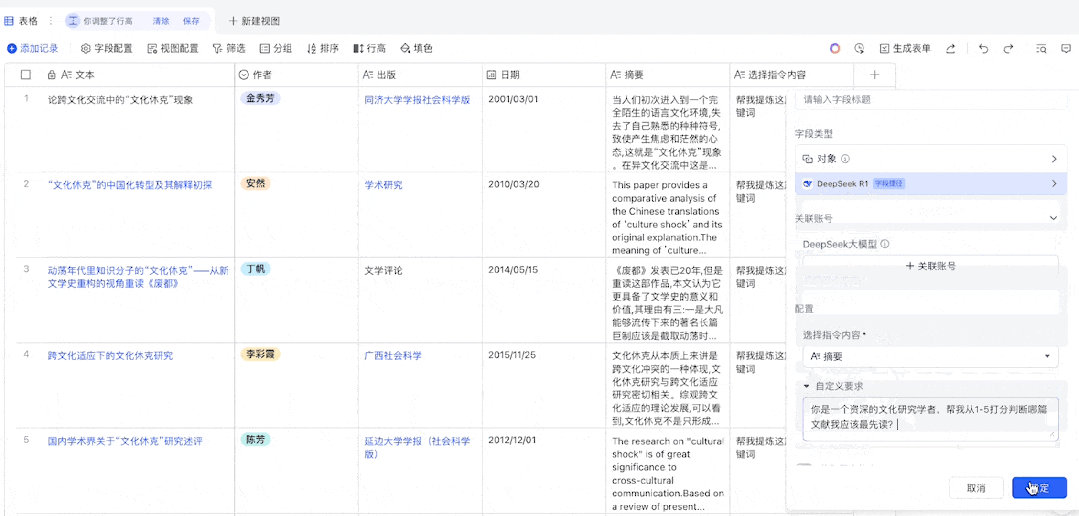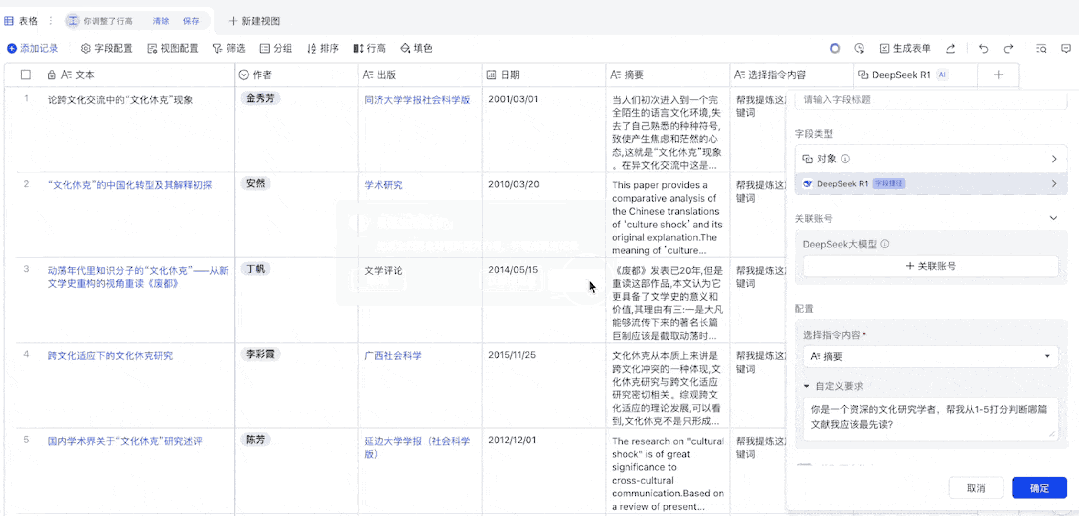
无需根据 API 模版调整、调用函数的过程,直接在多维表格中输入提示词即可
DeepSeek-R1 给出了严谨、可以直接参考的评分结果
更重要的是,调用 API 处理 Excel 表格中间的过程是不可见的,我们只能用各种各样的方法增强提示词,或者加强结果的筛选来保证 AI 的结果更准确,其中没有「偷工减料」,但升级版的飞书完全透明,每一步操作都清晰可控,也进一步省去了调整格式的步骤。
社交网络上已有不少用户分享了自己的使用案例。比如用户 @nanshanjukr 将 DeepSeek-R1 接入了自己的心理知识库的,得到了非常「惊艳」的效果,他表示:「比 Notion 的好太多了。简介和生平年份都是 R1 生成的。在 AI 的加持下,也让自己重新巩固、扩展一下知识面。」

来源:https://x.com/nanshanjukr/status/1888589518061908105
一个好名字往往更容易被人记住,商品名称也不例外,如果它恰好蹭上了热搜的快车,那搜索的曝光量岂不是蹭蹭往上涨。电商平台就是一座取之不尽的「爆款标题矿」,现在只需把这些现成的 SKU 名字导入飞书表格,再让 DeepSeek 这位文案大师从中提炼精华,一条自动生成 SKU 文案的工作流就开动了!

来源:https://x.com/huangyun_122/status/1888628099119464749
更令编辑们震撼的是,把选题打包丢进去,DeepSeek-R1 给出的直接是一篇成品文章,不仅结构完整、文笔流畅,还频频有金句爆出,排一下版好像就能发出去了。之前,我们尝试过各种 AI 辅助写作的产品,即使提供了完整的思路和提纲,AI 往往只会简单扩写或者机械拼贴,看完飞书和 DeepSeek-R1 神乎其技的组合技,在此不得不为自己的职业生涯担心一秒。

来源:https://x.com/eviljer/status/1888602443954717031/photo/1
短视频时代,写视频口播文案也是够烧脑的,如果使用飞书 + DeepSeek-R1,不仅可以少掉许多因动脑失去的头发,再仔细看看 DeepSeek 改写的输出结果,好像比我写的思路更开阔,种草味儿也更正。

来源:https://x.com/Lchs_11/status/1888571487428419767/photo/1
也做了一些尝试,比如让 DeepSeek-R1 批量解答数学题:

我们也体验了一下 AI 算命,通过配置这样的 prompt:「你是个全球顶尖的命理大师,根据提供的信息描述正缘画像,包括长相、身高、出生地、工作地、家庭条件、学历、性格、年纪等。越清楚越好,方便我去寻找。」我们很快便得到了 10 个信息的「正缘」:

最棒的是,在我们的体验过程中,从没遇到过「服务器繁忙,请稍后再试」。看起来,飞书使用的 DeepSeek-R1 是字节跳动自己部署托管的版本,稳定性非常不错 —— 前些天,字节跳动旗下的云服务平台火山引擎宣布已经支持 DeepSeek V3/R1 等不同尺寸的开源模型。
如何在飞书中使用 DeepSeek-R1?
飞书很早之前就已经接入了不少 AI 模型,使用 DeepSeek-R1 的方式与使用这些模型的方法类似。这里我们也简单撰写了一份图文并茂的教程。
首先当然你得有一个飞书帐号,然后新建一个多维表格。

飞书默认的多维表格
为避免繁杂,我们这里仅保留默认表格的第一列,删除其它列。后面我们会将第一列的文本内容用作提示词。
接下来,我们新建一列,用来配置 DeepSeek-R1。这里我们需要在「字段类型」中搜索 DeepSeek,便可找到 DeepSeek-R1 模型,之后我们需在「选择指令内容」中选择我们之前设置的「提示词」列,然后可以选择在「自定义要求」中设置一个全局提示词(当然也可以留空)。这里我们设置的是:「根据我提供的关键词或场景,编写一首七言绝句。」设置完成后,我们先选择保留配置,因为我们的「提示词」列还没有任何信息。
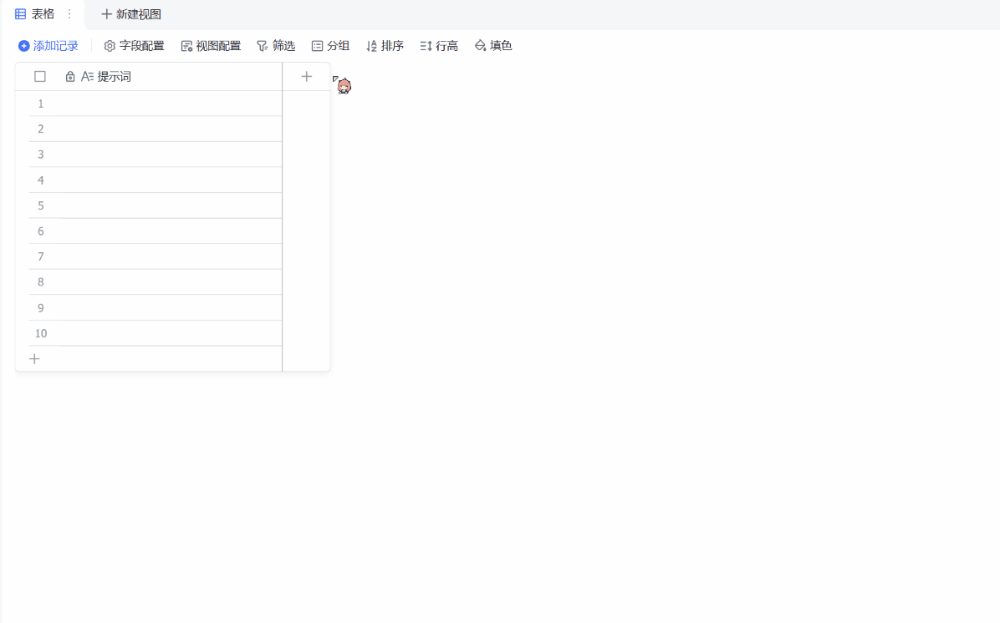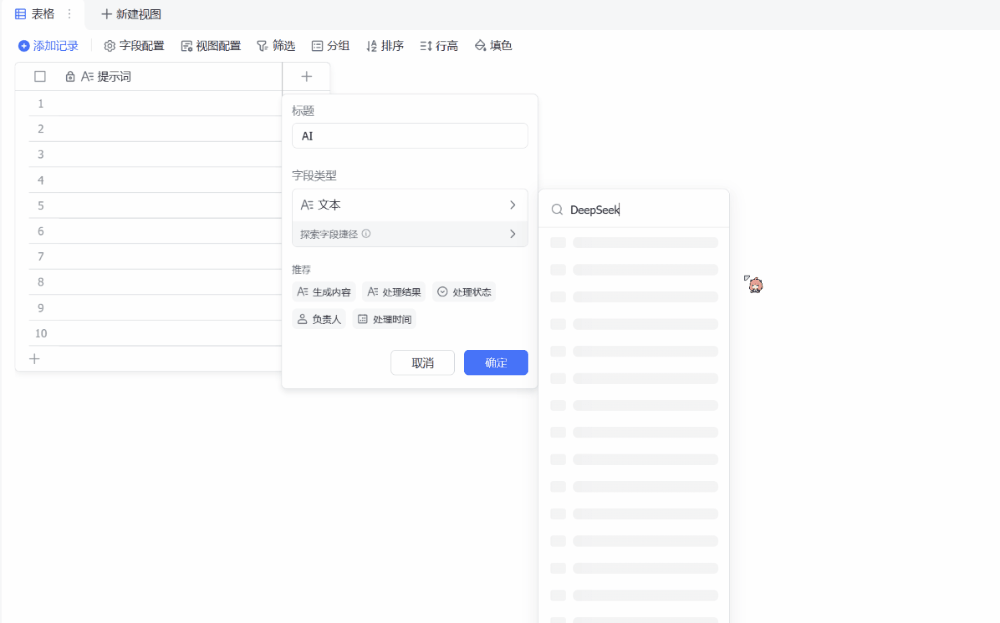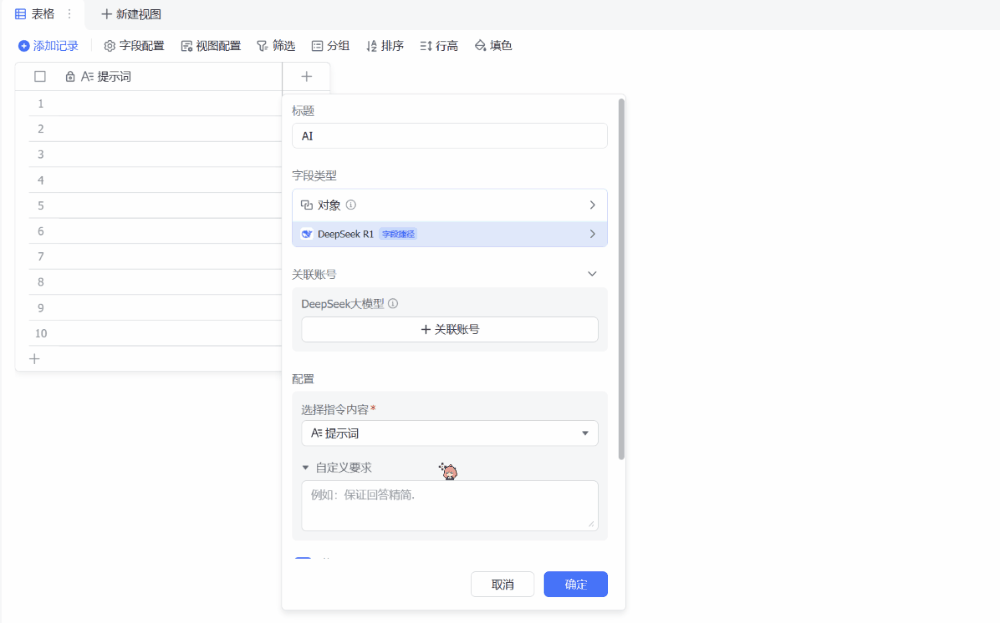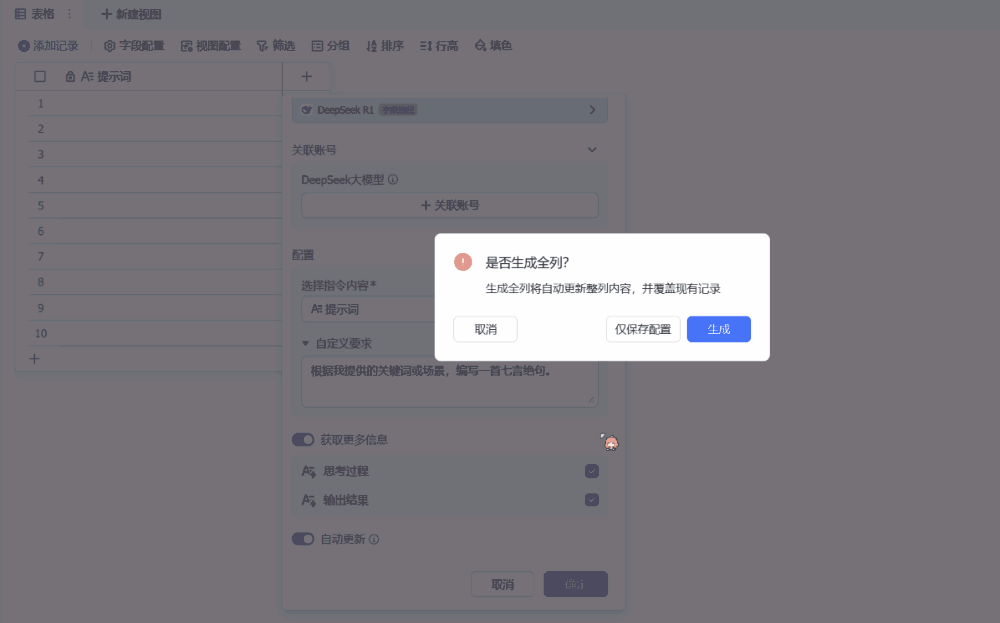
由于我们已经设置好了一个全局提示词,因此我们只需在「提示词」列填入我们想要的关键词或场景即可。接下来,就等待 DeepSeek-R1 完成它的创作吧!(通过设置「自动更新」,还可以让我们在每次修改提示词时自动高效率地自动获取新的输出结果。)
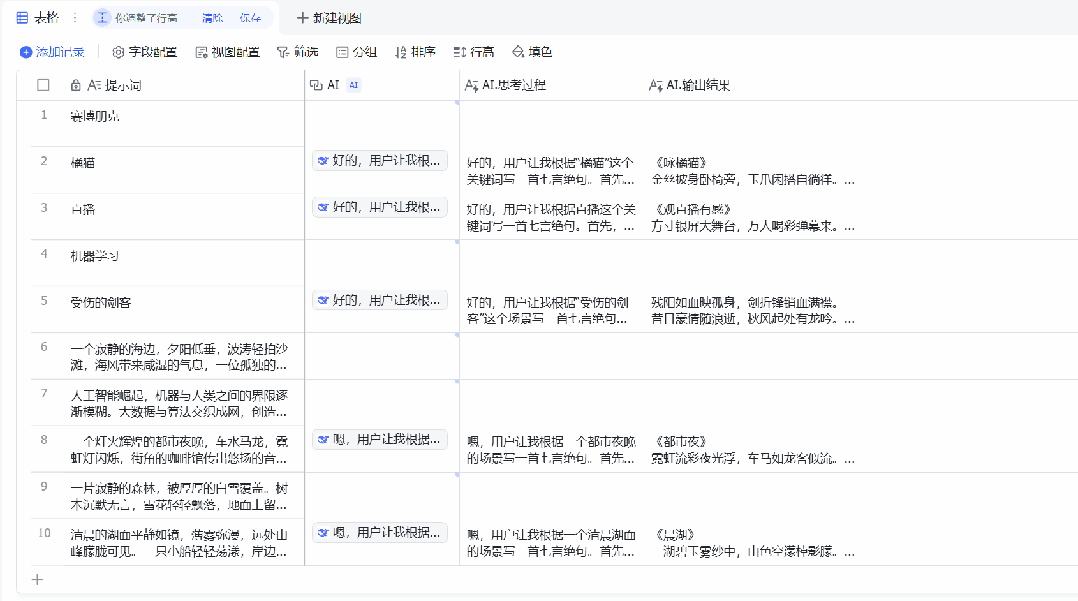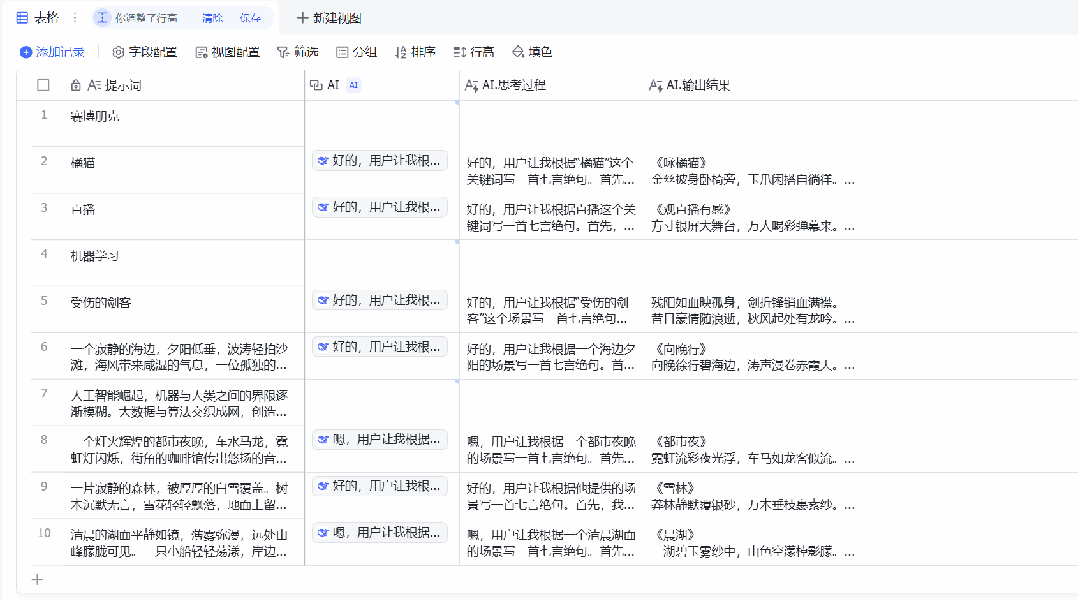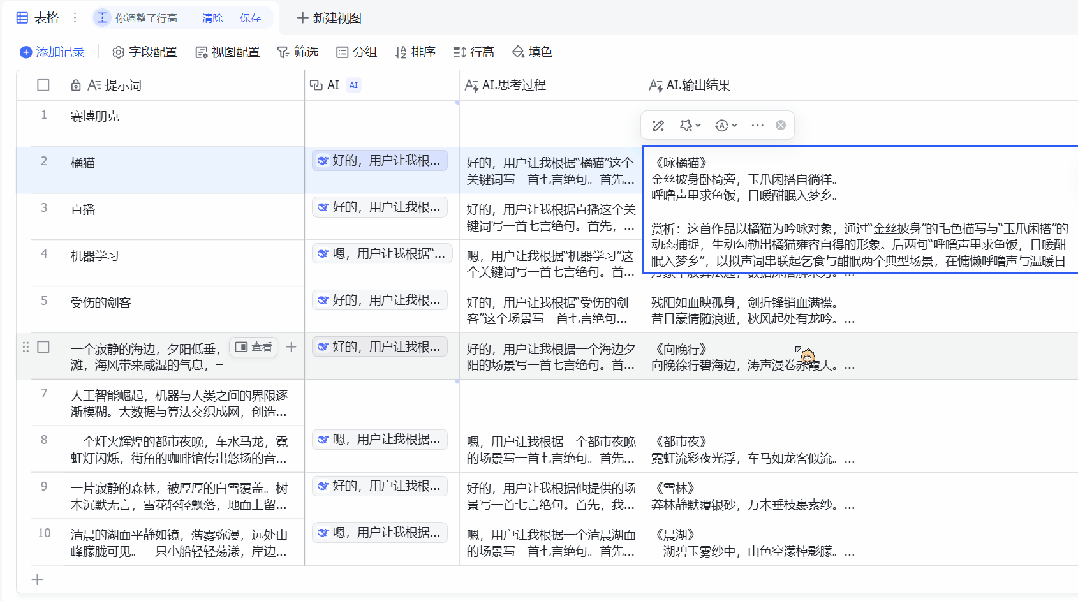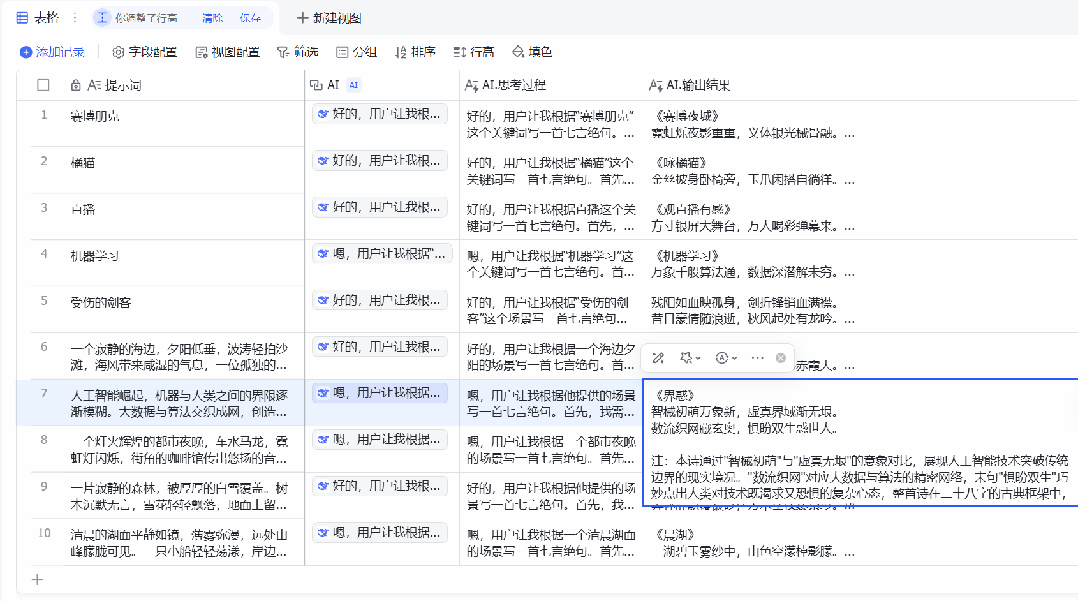
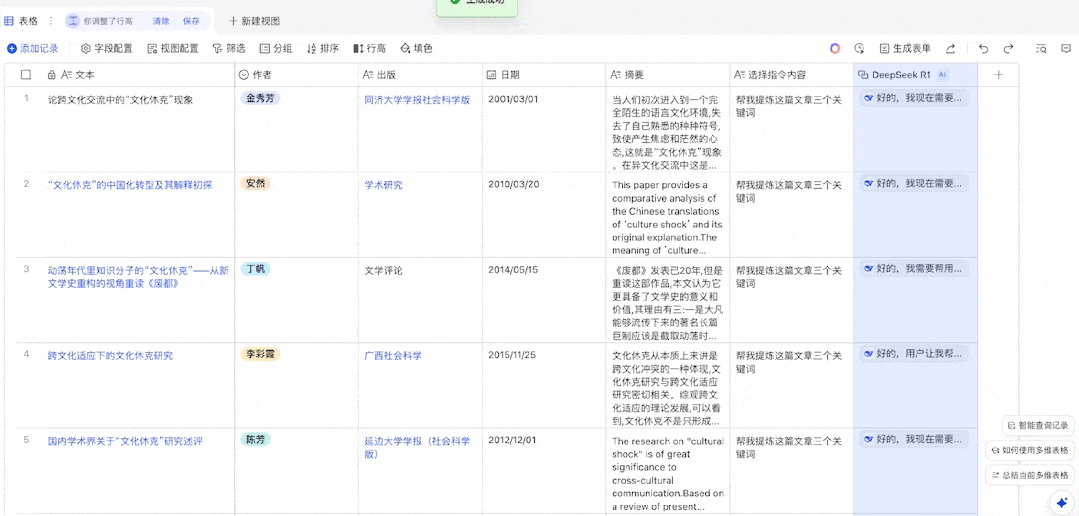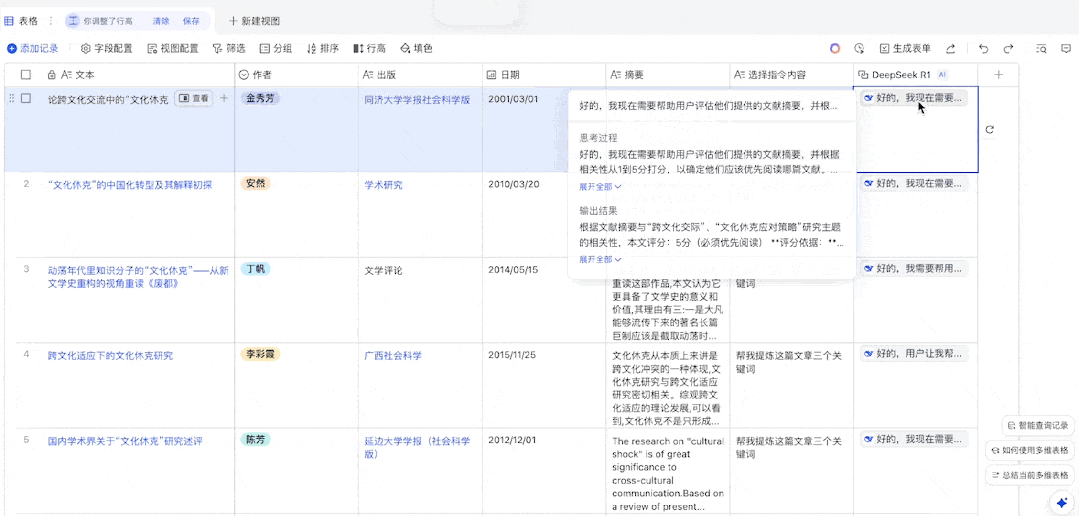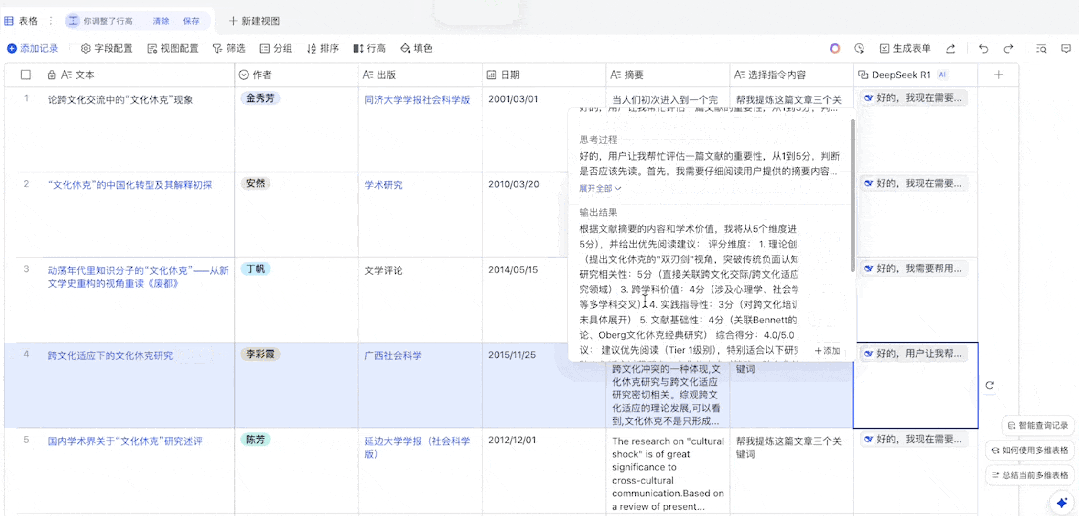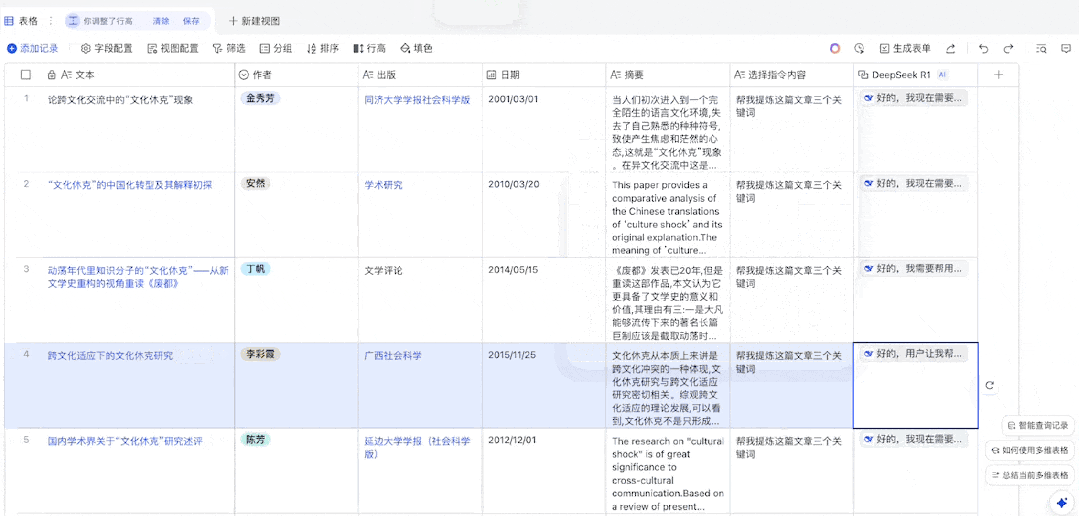
可以看到,飞书分别用一列表格展示了 DeepSeek-R1 的思考过程和输出结果(在设置中可选择不展示思考过程),而且从表格中出现结果的先后顺序来看,飞书并不是按表格的自然顺序逐一将提示词提交给 AI 模型,而是并行处理的。这就大大提升了我们使用 DeepSeek-R1 的效率。这首《咏橘猫》还真有趣:
金丝披身卧椅旁,
玉爪闲搭自徜徉。
呼噜声里求鱼饭,
日暖酣眠入梦乡。
当然,在飞书的多维表格中,DeepSeek-R1 并非唯一可用的模型,其支持的 AI 模型和功能还有很多,只需使用相应的关键词在「字段类型」中搜索即可。

飞书,真是越来越强大了。
....
#如何优化测试时计算?解决「元强化学习」问题
优化大模型的测试时计算是提升模型部署效率和节省计算资源的关键一环。前段时间,黄仁勋在 CES 2025 的演讲中把测试时 Scaling 形容为大模型发展的三条曲线之一。如何优化测试时计算成为业界关注的重要课题。

到目前为止,改进大型语言模型 (LLM) 的主要策略是使用越来越多的高质量数据进行监督微调 (SFT) 或强化学习 (RL)。
不幸的是,这种扩展形式似乎很快就会遇到瓶颈,预训练的扩展定律会趋于稳定,有报告称,用于训练的高质量文本数据可能在 2028 年耗尽,特别是对于更困难的任务,例如解决推理问题,这似乎需要将当前数据扩展约 100 倍才能看到任何显著的改进。LLM 在这些困难任务中的问题上的当前表现仍然不尽如人意。因此,迫切需要数据高效的方法来训练 LLM,这些方法可以超越数据扩展并解决更复杂的挑战。
在这篇文章中,我们将讨论这样一种方法:通过改变 LLM 训练目标,我们可以重用现有数据以及更多的测试时计算来训练模型以做得更好。
博客地址:https://blog.ml.cmu.edu/2025/01/08/optimizing-llm-test-time-compute-involves-solving-a-meta-rl-problem/

图 1:训练模型以优化测试时计算并学习「如何发现」正确答案,而不是学习输出「什么答案」的传统学习范式。
当前训练模型的主要原则是监督它们为输入产生特定的输出。例如,监督微调尝试匹配给定输入的直接输出 token,类似于模仿学习,而 RL 微调训练响应以优化奖励函数,该函数通常应该在 oracle 响应上取最高值。无论哪种情况,我们都在训练模型以产生它可以表示的 y* 的最佳近似值。
从抽象上讲,这种范式训练模型以产生单个输入输出映射,当目标是直接解决给定分布中的一组类似查询时,这种方法很有效,但无法发现分布外查询的解决方案。固定的、一刀切的方法无法有效适应任务的异质性。我们更希望有一个强大的模型,它能够通过尝试多种方法并在不同程度上寻求信息,或者在无法完全解决问题时表达不确定性,从而推广到新的、未见过的问题。
我们如何训练模型来满足这些要求?
学习「如何回答」
为了解决上述问题,一个新想法是允许模型在测试时使用计算资源来寻找「元(meta)」策略或算法,这些策略或算法可以帮助它们理解「如何」得出一个好的答案。
实现能够赋予模型系统性程序运行能力的元策略,应该能够使其在测试时外推和泛化到不同复杂度的输入查询。例如,如果一个模型被教了柯西 - 施瓦茨不等式的含义,它就应该能够在简单和困难的证明问题上在适当的时候运用它。换句话说,给定一个测试查询,我们希望模型能够执行包含多个基本推理步骤的策略,这可能需要消耗更多的 token。
图 2 展示了解决一个给定问题的两种不同策略的例子。我们如何训练模型来做到这一点呢?我们将把这个目标形式化为一个学习问题,并通过元强化学习的思路来解决它。

图 2: 展示了两种算法及其各自生成的 token 流示例。
将学习「如何做」形式化为一个目标
对于每个问题 x∈X,假设我们有一个奖励函数 r (x,⋅):Y↦{0,1}, 可以针对任何输出 token 流 y 进行查询。例如,对于数学推理问题 x,其 token 输出流为 y,奖励 r (x,y) 可以是检查某个 token 子序列是否包含正确答案的函数。我们只获得了训练问题数据集 D_train, 因此也只有奖励函数集合 {r (x,⋅):x∈D_train}。我们的目标是在事先未知的测试问题分布 P_test 上获得高奖励。测试问题的难度可能与训练问题不同。
对于未知的测试问题分布 P_test 和有限的测试时计算预算 C,我们可以从训练问题数据集 D_train 中学习一个算法 A∈A_C (D_train), 这个算法属于推理计算受限的测试时算法类 A_C。这个类中的每个算法都以问题 x∼P_test 作为输入,并输出一个 token 流。
在图 2 中,我们给出了一些例子来帮助理解这个 token 流可以是什么。例如,A_θ(x) 可能首先包含针对问题 x 的某些尝试 token,然后是一些用于预测尝试正确性的验证 token,如果验证为不正确,接着是对初始尝试的一些改进,所有这些都以「线性」方式串联在一起。另一个算法 A_θ(x) 可能是以线性方式模拟某种启发式引导搜索算法。算法类 A_C (D_train) 将由上述所有可能的 A_θ(x) 产生的下一个 token 分布组成。注意,在这些例子中,我们希望使用更多的 token 来学习一个通用但可泛化的程序,而不是去猜测问题 x 的解决方案。
我们的学习目标是学习由自回归大语言模型参数化的 A_θ(x)。我们将这整个流 (包括最终答案) 称为响应 y∼A_θ(x)。算法 A_θ(x) 的效用由奖励 r (x,y) 衡量的平均正确性给出。因此,我们可以将学习算法表述为解决以下优化问题:

将 (Op-How) 解释为元强化学习问题
接下来的问题是:我们如何解决由语言模型参数化的、在计算受限算法类 A_c 上的优化问题 (Op-How)?
显然,我们既不知道测试问题的结果,也没有任何监督信息。因此,计算外部期望是徒劳的。对问题 x 猜测最佳可能响应的「标准」大语言模型策略似乎也不是最优的,因为如果充分利用计算预算 C,它可能会做得更好。
主要思路是优化 (Op-How) 的算法 A_θ(x)∈A_c,类似于强化学习中的自适应策略,它使用额外的 token 预算来实现某种算法策略来解决输入问题 x。有了这个联系,我们可以从类似问题通常的解决方式中获得启发:通过元学习的视角来看待 (Op-How),具体来说是元强化学习:「元」是因为我们希望学习算法而不是直接回答给定问题,而「强化学习」是因为 (Op-How) 是一个奖励最大化问题。
一个非常简短的元强化学习入门
通常,强化学习训练一个策略来最大化马尔可夫决策过程 (MDP) 中的给定奖励函数。相比之下,元强化学习问题设定假设可以访问任务分布 (每个任务都有不同的奖励函数和动态特性)。在这种设定下,目标是在来自训练分布的任务上训练策略,使其能够在从相同或不同测试分布抽取的测试任务上表现良好。
此外,这种设定不是根据策略在测试任务上的零样本表现来评估它,而是让它通过在测试时执行几个「训练」回合来适应测试任务,在执行这些回合之后再评估策略。
回到我们的设定,你可能会想知道马尔可夫决策过程(MDP)和多个任务 (用于元强化学习) 是如何体现的。每个问题 x∈X 都会引发一个新的强化学习任务,这个任务被形式化为马尔可夫决策过程 (MDP) M_x,其中问题 x 中的 token 集合作为初始状态,我们的大语言模型 A_θ(x) 产生的每个 token 作为一个动作,而简单的确定性动态则通过将新的 token ∈T 与到目前为止的 token 序列连接来定义。注意,所有 MDP 共享动作集合和状态集合

,这些对应于词汇表中可能出现的变长 token 序列。然而,每个 MDP M_x 都有一个不同的未知奖励函数,由比较器 r (x,⋅) 给出。
那么解决 (Op-How) 就对应着找到一个策略,该策略能够在计算预算 C 内快速适应测试问题 (或测试状态) 的分布。从认知 POMDP 的视角来看这种测试时泛化的概念是另一种方式,这是一个将在 M_x 族上学习策略视为部分观察强化学习问题的构造。这个视角提供了另一种激发自适应策略和元强化学习需求的方式:对于那些有强化学习背景的人来说,解决 POMDP 等同于运行元强化学习这一点应该不足为奇。因此,通过解决元强化学习目标,我们正在寻求这个认知 POMDP 的最优策略并实现泛化。
适应性策略如何适应测试问题?
在元强化学习中,对于每个测试 MDP M_x,策略 A_θ 在通过 A_θ 生成最终响应进行评估之前,可以通过消耗测试时计算来获取信息。在元强化学习术语中,获得的关于测试 MDP M_x 的信息可以被视为在测试问题 x 引发的 MDP 上收集「训练」回合的奖励,然后再在测试回合上进行评估。注意,所有这些回合都是在模型部署后执行的。因此,为了解决 (Op-How),我们可以将来自 A_θ(x) 的整个 token 流视为分成几个训练回合的流。为了优化测试时计算,我们需要确保每个回合都能提供一些信息增益,以便在测试 MDP M_x 的后续回合中表现更好。如果没有信息增益,那么学习 A_θ(x) 就退化为一个标准的强化学习问题 —— 只是计算预算更高 —— 这样就不清楚学习「如何做」是否有用。
可以获得什么样的信息?当然,如果 token 流中涉及外部接口,我们可以获得更多信息。但是,如果不涉及外部工具,我们是否在利用免费午餐?我们指出不是这种情况,在 token 流进行过程中不需要涉及外部工具也能获得信息。流中的每个回合都可以有意义地增加更多信息,也就是说,我们可以将消耗更多的测试时计算视为从模型对最优解的后验近似 P (⋅|x,θ) 中采样的一种方式,其中每个回合 (或输出流中的 token) 都在改进这个近似。因此,显式地调整先前生成的 token 可以提供一种计算可行的方式,用固定大小的大语言模型来表征这个后验。
综上所述,当被视为元强化学习问题时,A (⋅|⋅) 成为一个历史条件 (「自适应」) 策略,通过在给定测试问题上花费最多 C 的计算来优化奖励 r。

图 3:智能体 - 环境交互协议。图源:https://arxiv.org/pdf/1611.02779
学习自适应策略的元强化学习

图 4:A_θ(x) 的响应包括一串 token。
我们如何解决这样一个元强化学习问题?也许解决元强化学习问题最明显的方法是采用黑盒元强化学习方法。这将涉及最大化输出轨迹 A_θ(x) 中想象的「episodes」的奖励总和。例如,如果 A_θ(x) 对应于使用自我纠正策略,那么每个 episode 的奖励将对轨迹中出现的单个响应进行评分。如果 A_θ(x) 规定了一种在生成和生成验证之间交替的策略,那么奖励将对应于生成和验证的成功。然后我们可以优化:

一般情况下,输出 token 流可能无法清晰地分成生成和验证片段。在这种情况下,可以考虑元强化学习问题的更抽象形式,直接使用信息增益的某种估计作为奖励。

可以通过多轮强化学习方法来解决 (Obj-1) 和 (Obj-2)。实际上,只要能够使用某种执行定期在线策略采样的强化学习算法来解决优化问题,强化学习方法的选择 (基于价值还是基于策略) 可能并不重要。
我们还可以考虑另一种制定元强化学习训练目标的方法:只优化测试回合获得的奖励,而不是训练回合的奖励,从而避免量化信息增益的需要。
....
#Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct Reasoning
人大刘勇团队「慢思考」机理分析:从雪球误差到正确推理概率
在大语言模型(LLMs)的发展历程中, Scaling Laws [1] 一直是推动性能提升的核心策略。研究表明,随着模型规模和训练数据的增长,LLMs 的表现会不断优化 [2]。然而,随着训练阶段规模的进一步扩大,性能提升的边际收益逐渐减小,训练更强大的模型需要巨额投入。因此,研究重点逐渐从训练阶段的扩展转向推理阶段的扩展 [3],探索在不增加模型参数量的情况下,如何提升推理质量。
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。研究发现,增加推理时间能够显著提升 LLM 的推理质量 [7],这一发现推动了对 「慢思考」方法的深入研究。
「慢思考」主要可以分为内部慢思考(Internal Slow-Thinking) 和 外部慢思考(External Slow-Thinking) 两种方式:
- 内部慢思考:通过额外的训练,使模型在专门的推理任务上优化参数,提升自身的推理深度和输出质量。
- 外部慢思考:不改变模型本身,而是增加计算开销,例如通过多次采样、重新生成答案等方式延长推理过程,从而提高推理的准确性和可靠性。
本文主要关注外部慢思考。在面对复杂问题时,人类往往会花费额外的时间思考和完善推理的中间过程,以提高准确性。外部慢思考受这一认知过程的启发,通过增加推理步骤来提升大语言模型的推理质量 [8]。例如,BoN(Best-of-N)方法会生成多个答案,并通过多数投票或排序等策略选出最优解 [9]。此外,更前沿的框架 如思维链(CoT)[10]、思维树(ToT)[11] 以及借鉴 AlphaGo [12] 蒙特卡洛树搜索(MCTS) 的方法,能够在树状结构中探索解答空间,寻找更优的答案 [13-14]。
然而,尽管外部慢思考方法展现出提升推理质量的潜力,但仍面临两大核心挑战:
- 缺乏理论支撑:目前,我们对这些方法为何有效的理解仍然有限,这阻碍了更先进策略的设计。
- 计算资源需求高:复杂的慢思考技术往往需要大量计算资源,且优化设计参数的难度较大,导致实际应用中的表现不尽如人意。
针对这些挑战,研究者提出了一种基于信息论的系统性框架,建立外部慢思考方法与 LLM 生成正确推理的概率之间的联系。随着「慢思考」方法的深入探索,LLM 发展新的转折点正在到来。未来,大模型的推理能力优化不再局限于扩大模型规模,而是通过优化推理过程,实现更智能、更精准的逻辑推理。本研究将深入剖析外部慢思考策略的理论基础、机制解析以及其对 LLM 推理能力的影响,为人工智能推理能力的进一步突破提供新的方向。

- 论文标题:Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct Reasoning
- 论文链接:http://arxiv.org/abs/2501.15602
此工作主要作出了如下贡献:
- 分析了 LLM 推理过程中的雪球误差效应,并证明该效应会导致推理错误概率随推理路径的增长而上升,强调了慢思考策略在减少错误中的关键作用。
- 提出了一种基于信息论的系统性框架,建立外部慢思考方法与推理正确概率之间的数学联系,为理解慢思考策略的有效性提供理论支撑。
- 对比了不同的外部慢思考方法,包括 BoN 和 MCTS 等,揭示它们在推理能力提升方面的差异与内在联系。
1 大模型推理过程中的「雪球误差」
想象一下,在冬天的雪地上滚动一个雪球。随着滚动的距离增加,雪球会以越来越快的速度变大,这就是雪球效应(Snowball Effect)—— 小的变化会随着时间推移不断累积,最终带来显著影响。
在大规模语言模型(LLMs)中,这一效应最初体现在自回归式(Auto-Regressive) 的 Next-Token Prediction(NTP)任务中,微小的 token 级错误会不断累积,最终导致模型生成的答案偏离预期的正确答案 [15]。然而,在更复杂的推理任务中,这种错误不再仅限于 token 级,而是扩展到句子级,使得推理偏差更加难以衡量和控制。
为什么推理偏差会逐步放大?
研究表明,LLM 的推理过程可以看作是逐步执行一系列原始任务(Primitive Tasks)[16],每一步的推理结果都依赖于前面的输出。因此,任何早期的微小误差都会在推理链条中不断放大,最终导致模型偏离正确答案。
为了更直观地理解这一现象,研究者借助柏拉图的「洞穴寓言」(Plato’s Allegory of the Cave)。在这个寓言中,人们只能看到投射在墙上的影子,而无法直接感知真实世界,类似于 LLM 只能从训练数据中学习世界的「投影」。如图 1 (a) 所示,训练数据只是现实世界的映射,而 LLM 生成的推理结果正如图 1 (b) 所示,仅是其内部推理过程的「影子」。

图表 1: 大模型推理过程的柏拉图假设
换句话说,模型的推理输出并非直接反映其思维过程,而是受限于它从训练数据中学到的模式和误差,导致滚雪球效应的持续累积。
例如:在 LLM 执行数学推理任务时,例如解答「计算 3x + 2y」,模型并不是直接给出答案,而是隐式地执行一系列推理步骤:
t₁: 计算 3x → t₂: 计算 2y → t₃: 将 3x 和 2y 相加。
然而,这些推理步骤是抽象的、不可直接观察的,模型的最终输出是这些推理过程的不同表达方式。例如,输出序列 r₁ → r₂ → r₃ 可能有多种不同的表达形式,但它们并不一定能完全还原对应的推理步骤 t₁ → t₂ → t₃。
由于单个输出 r_l 无法完全表达对应的推理步骤 t_l,即使初始误差微小,也会随着推理链条的延续逐步放大,最终导致严重的推理偏差。这种误差的积累,正是雪球效应在推理任务中的典型体现。
在 LLM 推理过程中,雪球误差会导致模型的推理结果逐步偏离正确答案。为了精准衡量这一误差,本研究引入互信息(Mutual Information, MI)这一数学工具,来量化隐式推理序列 t 与最终生成的回复序列 r 之间的共享信息量,记作 I (t; r)。这一度量帮助评估模型在推理过程中能够保留多少关键信息。
具体而言,在每个推理步骤中,模型的输出可能存在细微偏差,这些误差会逐步累积并导致信息损失。研究者将信息损失定义为互信息 I (t; r) 与隐式推理过程的信息熵 H (t) 之间的差值:

而最终的雪球误差则可以定义为在所有推理步骤上信息损失的累积:

2 从「雪球误差」到推理错误的概率
在 LLM 的推理过程中,推理路径越长,雪球误差就会不断累积,最终导致严重的事实偏差,研究者将其定义为推理错误(Reasoning Errors)。
如何衡量推理错误?
为了准确评估推理错误,研究者首先需要清晰地定义它。由于每个输出 r_l 代表隐式推理步骤 t_l,研究者通过检查是否存在一个足够强大的映射函数 f 来从 r_l 还原 t_l。如果这种还原能力较弱,说明推理过程中信息损失较大,进而导致了推理错误的发生。具体而言,研究者将「推理错误」这一事件刻画如下:

为了更准确地估计 LLM 发生推理错误的概率,本研究提出使用信息论方法,建立雪球误差与推理错误发生概率之间的数学联系。研究者从一个关键引理出发,通过理论推导揭示滚雪球误差如何逐步积累,并最终影响模型的推理准确性。

基于此引理,研究者可以推导出推理错误发生概率的下界:

此定理表明,在推理的第 l 步,错误概率的下界受累积信息损失 H_(<l) (t|r) 影响,由于其累加的定义,这一损失至少会随推理步数 l 线性增长。
当雪球效应出现时,累积信息损失可能超过线性增长,导致推理错误概率随推理路径的增加而快速上升。换句话说,推理链条越长,模型出错的可能性越大,这解释了 LLM 在长链推理任务中为何容易出现偏差。

图表 2: 不同 LLM 在 GSM8k 数据集上生成回复的估计互信息(MI)和奖励分数
为了实证验证 LLM 推理中的雪球误差效应,本研究基于 GSM8k 数据集进行实验,并测试了三款先进的推理 LLMs:Llama3.1-8B-Instruct、Qwen2.5-7B-Instruct以及 Skywork-o1-Open-Llama-3.1-8B。
研究者计算了互信息 I (t; r) 在所有 token 上的平均值,并分析其随推理路径长度 L 的变化,同时评估生成结果的奖励分数(reward),结果如图表 2 所示。实验结果表明:
- 互信息呈负指数级下降,比线性衰减更快,随着推理步数 L 的增长,信息损失迅速累积;
- 由于计算的是平均互信息,推理链条靠后的 token 可能损失更多关键信息;
- 奖励分数随推理长度增加而下降,进一步验证了雪球误差对 LLM 生成质量的影响。
这一实验结果不仅验证了雪球误差的存在,也表明信息损失的累积速度远超线性衰减,直接影响 LLM 生成的推理质量。这一发现与研究者的理论分析一致。
3 外部慢思考中的正确推理概率
先前的分析表明,推理错误概率 P (e_l) 随着推理步数 l 的增加而上升。然而,在实际应用中,推理错误通常体现在模型生成结果的奖励分数(reward) 上。因此,本文进一步扩展至现实场景,探讨外部慢思考方法为何有效。
3.1 何为正确推理
研究者首先定义 LLM 在现实场景中的推理过程。对于一个问题 r_0,模型会通过自回归方式生成一个包含 L 个推理步骤的响应序列:R = [r_1,r_2,…,r_L]。
为了评估每一步推理 r_l 的质量,研究者引入一个价值函数 φ,用于衡量每个步骤的正确性 φ(r_l) 。在实际应用中,这一评估可以通过人类反馈或奖励模型来实现。此外,研究者假设每个推理步骤都有一个标准答案 r_l^*,代表 LLM 应该生成的最准确答案,与人类理想推理方式保持一致。
基于上述设定,研究者利用价值函数 φ 评估推理步骤的正确性,并据此量化 LLM 生成回复的质量。具体而言,研究者分别将单步推理和整个推理过程的正确性定义如下:

3.2 正确推理的概率
实验结果(图表 2)表明,平均互信息会随推理步数呈近似指数级下降,这意味着雪球误差随着推理长度的增加呈指数级增长。然而,由于概率值不能超过 1,研究者基于定理 3.3 提出一个假设:在实际应用中,推理错误的概率可能遵循指数衰减函数,即:P (e_l) = 1 -λe^(-l),这一假设使得后续分析更加直观,并进一步帮助推导在第 l 层生成正确推理步骤的概率:

由此假设,研究者推导出在雪球误差存在时,最终得到一个正确的完整推理过程的概率:

3.3 外部慢思考提升推理质量的机理
基于前面的分析,研究者首先直观上得出这样的结论:由于 LLM 生成的随机性,外部慢思考方法的核心目标是引入额外的推理步骤并结合多次重新采样策略,从而对冲雪球误差,进而提高模型生成结果的正确性。
接下来,研究者利用理论分析进一步详细阐述这一观点。首先,外部慢思考方法从根本上来说主要具有两个特点:
- 宽度扩展(Width-Expansion):
- 对于长度一定的推理序列,大多数外部慢思考方法都试图扩展推理空间的宽度。
- 这可以通过简单的重新生成(BoN、CoT-SC)或更复杂的树搜索方法(ToT、MCTS) 来实现。
- 生成 & 选择(Generation & Selection):
- 扩展推理空间后,还需要从多个候选推理路径中选出最优解。
- 设 Pr (τ_generate) 为生成正确推理的概率,Pr (τ_select) 为从候选路径中选出正确推理的概率,则最终获得正确推理结果的概率可表示为:Pr [ψ(R)≤τ ]= Pr (τ_generate )× Pr (τ_select )。
外部慢思考 通过扩展推理空间来提升 LLM 生成正确答案的概率 Pr (τ_generate),但与此同时,额外的推理步骤也会增加选择最优推理路径的难度,从而降低 Pr (τ_select)。这意味着,在提升推理正确性的同时,也带来了更复杂的决策挑战。
如何量化这种权衡?
为了更直观地分析这一现象,研究者以 Beam Search 作为基准的宽度扩展策略。Beam Search 广泛应用于树搜索算法,其核心机制如下:
- 在每一层推理,生成 k 个子节点以扩展搜索树的宽度;
- 仅保留 b 个最优候选解,以减少计算复杂度。
研究者将分析结果形式化为一个数学引理,进一步揭示了推理空间扩展与最优路径选择之间的平衡关系。

基于推理过程的基本假设,这一概率上界可以被进一步简化为:

引理 4.5 和定理 4.6 阐述了外部慢思考技术的本质机理并支撑了如下结论:
获得正确推理的概率主要受以下三个关键因素影响:
- 每层生成的候选数 k :决定了推理空间的扩展宽度;
- 每层筛选的最优候选数 b :影响正确推理路径的选择精度;
- 正确性阈值 τ :衡量推理结果的质量要求。
宽度扩展 vs. 选择可靠性:如何找到平衡?
- Pr (τ_select) (选择正确推理的概率)依赖于价值函数的可靠性,即 ϵ_b 相关的参数。
- Pr (τ_generate) (生成正确推理的概率)受 推理路径长度 L 和扩展宽度 k 影响。
- 通过增加推理步骤,可以提升生成正确推理的概率,但同时会引入额外的选择代价,增加错误概率。
慢思考方法的关键优化条件
对比引理 4.4 和定理 4.6 发现,慢思考方法是否有效,还取决于价值函数的可靠性。为了保证推理准确率的上限得到提升,价值函数的可靠性必须满足:

。
通过上述分析,研究者总结了外部慢思考方法的核心机制。通过增加推理路径的搜索范围,这些方法提高了生成正确答案的概率,有效减少雪球误差的累积。同时其效果极大依赖于所使用的价值函数的可靠性,这一因素直接影响整个方法的最终表现。
4 外部慢思考方法间的对比
接下来,研究者将对比简单和复杂的外部慢思考框架之间的核心区别,并以著名的 BoN 和 MCTS 为例进行分析。
4.1 BoN 与 MCTS 框架下的正确推理概率
对于 BoN 来说,研究者很方便地将其建模为进行 N 次长度为 L 的推理,并最终在 N 个答案中选择一次的过程。因此,BoN 的正确推理概率上界为:

对于 MCTS(RAP 模式),由于其机制较为复杂,研究者考虑其最好和最坏的情况。在最好的情况下,MCTS 的每次节点扩展时都发生在最深的叶子节点上,则它退化成了一个采样宽度和保留宽度都为 b 的 Beam Search。

而在最差情况,MCTS 需要遍历所有可能的节点,从而形成一棵完全 b - 叉树。

4.2 对比 BoN 与 MCTS 的总推理代价
可以看出,MCTS 由于需要调用更多次的选择过程,一般会比 BoN 对于价值函数有更高的敏感性。除此之外,在假设价值函数完美(ϵ_b=1)的情况下,研究者对齐概率上界中的其余部分,可以计算出当 BoN 和 MCTS 具有相当的正确推理概率上界时,所需要具备的总推理代价的规模,如图表 3 所示。

图表 3: 相同推理正确概率下 BoN 与 MCTS 总推理代价规模对比
结果表明,当 BoN 与 MCTS 在推理正确率上相当时,BoN 的总推理成本与 MCTS 接近。
- 最优情况下:BoN 与 MCTS 的推理成本趋近相等;
- 最差情况下:当推理步数 L 较小时,BoN 的成本可能略高于 MCTS,但仍保持在合理范围内。当 L 增加,BoN 的推理成本甚至可能低于 MCTS。
这一结论表明,推理成本是决定减少雪球误差效果的关键因素,而具体采用哪种慢思考框架(如 BoN 或 MCTS)对最终结果的影响理论上可能是较小的。
4.3 实验验证
在 GSM8k 和 PrOntoQA 两个推理任务上,实证对比了 BoN 和 MCTS 的推理准确性。研究者采用 [14] 推荐的 MCTS 优化配置,并计算相应的 N 值,使 BoN 的推理成本与 MCTS 尽可能接近。由于两种方法生成推理路径的方式不同,完全对齐并不现实,因此研究者定义合理的 N 值区间:
N 合理范围的下界与上界:
- N ̃_res :对齐推理步数的 N 值
- N ̃_call :对齐 LLM 调用次数的 N 值
研究者测试了 BoN 的三种选择策略:
- Self-Consistency(自洽性选择)
- ORM Vote(基于奖励模型的投票选择)
- ORM Max(基于奖励模型的最大值选择)
实验结果如图表 4 所示。

图表 4: GSM8k 和 PrOntoQA 上 BoN 与 MCTS 的准确性对比
研究者可以得出如下结论:
不同任务下的 BoN 表现
- PrOntoQA(二分类任务:True/False):
- 由于答案固定,增加 N 并不会提升 Self-Consistency 策略下的 BoN 性能,除非引入奖励模型。
- GSM8k(多步推理任务):
- 由于答案多样,增加 N 即使在没有奖励模型的情况下,也能提升 BoN 的性能。
BoN 与 MCTS 的关键对比
- ORM Vote & ORM Max 策略(结合奖励模型):当 N 在 N ̃_res 和 N ̃_call 之间时,BoN 能够达到与 MCTS 相当的推理性能;
- N 接近 N ̃_res 时,BoN 略低于 MCTS,但差距不大;
- N 取更大值时,BoN 能够匹敌甚至超越 MCTS,进一步验证了 MCTS 在 LLM 推理中的局限性,并支持研究者的理论分析。
本实验表明,在合理的 N 值范围内,BoN 通过适当调整推理宽度,可以达到甚至超越 MCTS 的推理效果,这与研究者的理论分析一致。
5 小结
本研究分析了外部慢思考方法的有效性机制,并通过信息论建立了 LLM 推理中的雪球误差与推理错误之间的联系。研究表明,外部慢思考方法通过扩展推理空间可以减少推理错误,但同时增加了推理成本,需要在正确性和计算开销之间权衡。
对比 BoN 和 MCTS 等方法后,研究者发现影响其有效性的核心因素是奖励函数的能力和推理总成本,而具体的搜索框架影响较小。因此,优化奖励函数和提升策略模型的推理能力是未来改进外部慢思考方法的关键方向。
....
#TinyLLaVA-Video
北航推出,有限计算资源优于部分7B模型,代码、模型、训练数据全开源
近年来,随着多模态大模型的崛起,视频理解技术取得了显著进展。但是目前主流的全开源视频理解多模态模型普遍具有 7B 以上的参数量,这些模型往往采用复杂的架构设计,并依赖于大规模训练数据集。受限于高昂的计算资源成本,模型训练与定制化开发对于资源有限的科研人员而言仍存在显著的门槛。
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。同时,由于 TinyLLaVA-Video 衍生自 Tinyllava_Factory 代码库,因此项目仍然具有组件化与可扩展性等优点,使用者可以根据自身需求进行定制与拓展研究。
- 论文地址:https://arxiv.org/abs/2501.15513
- Github 项目:https://github.com/ZhangXJ199/TinyLLaVA-Video
全开源项目,支持定制与拓展
区别于众多仅开源模型权重的项目,TinyLLaVA-Video 秉承了 TinyLLaVA_Factory 全面开源的理念。该项目不仅公开了完整的模型权重、训练代码和训练数据集,也延续了原有的模块化设计架构,研究人员可根据具体实验需求,灵活替换语言模型、视觉编码器等核心组件,并可自定义训练策略。这种开放性设计不仅降低了小规模研究团队进入视频理解研究领域的门槛,还为未来的轻量级视频理解模型的训练范式与架构创新探索提供了实验平台。

在模型架构方面,TinyLLaVA-Video 沿用 LLaVA 类多模态模型常见的 Vision Tower+Connector+LLM 框架,并同样保持预训练对齐与监督微调的两阶段训练策略。项目中采用的所有预训练模型组件均遵循开源协议,包括如 Qwen2.5-3B 等语言模型和 SigLIP 等视觉编码器此类核心模块,确保了实验的可复现性,为研究者提供了可靠的基准参考。同时,研究人员可以方便地替换模型组件,更改训练策略,定制符合自身需求的视频理解模型。
在训练数据方面,TinyLLaVA-Video 基于开源的 LLaVA-Video-178K 和 Valley 数据集进行实验。同时,为进一步精简数据集,提高训练数据的质量并控制计算资源成本,项目对训练数据进行了多步筛选与过滤,最终得到 397k 的预训练数据与 491k 的监督微调数据。这使得研究者即便仅具备有限的计算资源,也能在合理的训练时间内复现实验结果并开展进一步研究。经过处理的数据标注信息(annotation)也已经完整公开于 HuggingFace 平台,这也为后续研究提供了高质量的数据基础。
小尺寸简易框架,依然保持高性能
以往的视频理解方法受限于语言模型的输入长度限制,往往面临两难选择:要么通过设计复杂的模型架构来处理长序列信息,要么牺牲视频信息的完整性而限制采样帧数。因此,如何处理长时序视觉序列,并平衡计算资源与性能之间的矛盾,成为轻量级视频理解模型亟待解决的问题。
为在保持模型结构轻量化的同时解决长序列信息处理的问题,TinyLLaVA-Video 对于经过 Vision Tower 处理后的整体视频序列,使用简单的视频级 Resampler 作为 Connector 来对齐视觉和语言,从而能极大地减少输入至语言模型的 Visual Token 的数量。这种处理方式可以使得模型支持灵活的视频采样策略,研究者可以根据视频类型与使用需求进行 fps 采样或均匀帧采样,设置不同的视频采样帧数。

虽然简化模型架构并控制训练数据的规模,但是 TinyLLaVA-Video 的表现依然非常可观。实验结果表明,整体参数不超过 4B 的模型在包含 MLVU、Video-MME 在内的多个视频理解基准测试集上的表现优于同等训练数据量级下的 7B + 模型,充分验证了该框架的有效性。

此外,该研究也进行了大量实验,系统性地探索了不同配置下的模型性能,包括选择不同的语言模型、视觉编码器以及采样不同的帧数等设置的影响(实验设置与结果详见技术报告)。这些实验结果揭示了在不同参数设定下,模型在视频理解任务中的表现,为研究者提供了优化模型结构的实证数据。这些探索不仅提升了 TinyLLaVA-Video 的适用性,也为后续研究提供了重要的参考依据。

TinyLLaVA-Video 的研究表明,小尺寸视频理解模型在计算成本有限的环境下仍具有广阔的发展空间。未来,计算资源有限的研究者们可以基于该工作,进一步优化模型结构和训练策略,以推动小尺寸视频理解模型的持续发展,为资源受限环境下的多模态研究提供更多可能性。
TinyLLaVA 系列项目始终致力于在有限计算资源下研究小尺寸模型的训练与设计空间,坚持完全开源原则,完整公开模型参数、源代码及训练数据。同时,项目采用模块化设计理念,确保项目的可拓展性,方便资源有限的研究者们通过实践来理解与探索多模态大模型。
....
#Deepseek R1 Zero成功复现全过程
三阶段RL,Response长度涨幅超50%,涌现语言混杂
Deepseek R1 Zero模型通过三阶段强化学习(RL)成功复现的过程记录,模型在测试集上的准确率从0.2提升到0.41,输出长度增长超过50%,并涌现出多语言混杂、迟疑、多路径探索等能力,展示了强化学习在提升模型性能和推理能力方面的潜力。
项目代码可见:Unakar/Logic-RL(https://github.com/Unakar/Logic-RL),欢迎关注和star!
我们将开源完整的wandb曲线和训练日志,wandb report(https://wandb.ai/ustc_ai/GRPO_logic_KK/reports/GRPO-Zero--VmlldzoxMTIwOTYyNw?accessToken=gnbnl5mu5pwfww7gtwxymohg85w7d7vthvjvbl4w8yxg0a99vf1k22m11e61cvv8)
在大四的最后一个寒假,和@AdusTinexl @ShadeCloak 两个小伙伴捣鼓出了点有意思的东西,非常开心,欢迎各位合作,指导!
先展示一下结果:
基座模型Qwen 7B在测试集上只会基础的step by step逻辑。
无 Long CoT冷启动蒸馏,三阶段Rule Based RL后 (约400steps),模型学会了
- 迟疑 (标记当前不确定的step等后续验证),
- 多路径探索 (Les't test both possibilities),
- 回溯之前的分析 (Analyze .. statement again),
- 阶段性总结 (Let's summarize, Now we have determined),
- Answer前习惯于最后一次验证答案(Let's verify all statements),
- Think时偶尔切换多语言作答 (训练数据纯英文的情况下,思考部分是中文,最后answer又切回英文)
测试集上性能也一举超越了gpt4o 的0.3,达到了 0.41的准确率,相比自身初始0.2 acc翻了一倍
非常漂亮的回复

demo1:迟疑,回溯,总结,verify。训练后期模型总是倾向于在最后输出answer前,优先全部verify一遍。这些能力是RL训练涌现的,未加任何引导
偶尔的多语言现象

demo2: 多语言的例子,思考忽然说中文,最后为了格式奖励用英文做最终回答,回复是对的

demo3:训练前模型原本的输出作为参考, 笨笨的也很可爱,看得出来是一点verify之类的基本思考单元也没有
Response长度增长

Demo 4, Settings: prompt mean 276 tokens, origin response mean 400 tokens
据我所知,这是第一个稳定实现输出长度大幅超越原始模型平均长度的(数据集prompt长度全部小于300 tokens,相比于基座模型原本输出的平均长度 400 tokens, 训练后期平均长度稳定在650 tokens,约50%的涨幅)
Reward曲线
我们设置了严苛的format reward和Answer Reward。
Reward只有这两部分构成,避免任何reward hacking。
我们编写了不少if else逻辑和正则。刚开始模型总能以匪夷所思的方式绕过我的预想,在和它一次次的斗智斗勇里完善了rule的编写
我们发现模型在学习format的时候,其实是一个快速收敛--逐渐崩坏--又忽然找回format的形式,与我们三阶段RL训练设置吻合。
还有一个有趣的小发现,在中间阶段,模型似乎认为格式反而阻碍了它的思考:日志里看到不少例子,模型在tag开始后意识到自己犯错了,想重回进入思考模式,可惜被format reward狠狠惩罚了

Demo 5, 依次是平均reward, 全对的比例,格式错误比例,答案做错的比例
基本Settings
训练数据合成
其实只有2K不到的训练数据集,完全由程序合成,确保对基座模型是OOD数据。
其中逻辑问题类似老实人和骗子的益智题,老实人总说真话,骗子总说假话,下面N个人,各有各的表述,请判断谁是骗子。我们以此为例讲解实验细节。
可控性也不错,可以人为设置难度分级。测试下来gpt4o的acc在0.3左右,而3epoch的RL训练后,我们成功让qwen-7B达到了0.41。
gpt4o和claude sonnet在这种逻辑题上的准确率出乎意料的低。我们选了一个合适的人数来控制难度,确保它高于qwen 7B当前的能力,但又不会过难(在8个人的情况下,qwen完全不能作答,RL训练曲线也堪比蜗牛爬。我们最后选取了5人作为基线)
模型基座选取
我们注意到deepseek官方开了一系列distill模型,测试下来感觉有点矫枉过正了,小参数量承载了超越其自身的推理能力。回复里的wait, alternatively这种字眼频率过高。
Deepseek distill系列选了qwen-math-7B作为基座。我们本来也是这个,后来发现这个模型有坑:
- 首先它指令跟随能力比较一般,很难学会format;
- 其次,它说话老爱用python code解题,训练很难克服
- 移除system prompt后,还是习惯用\box{}包裹answer,还是format不行
- Markdown味道太重,一板一眼的,Reasoning模型本应思想跳脱一些才是
我们训了几版RL,效果始终不好,最后决定放弃Qwen Math系列,Qwen 7B 1M就好
RL基本设置
我们初始还是PPO,训练确实稳定,就是太慢了。Reinforce系列测试下来又快又好,显存还低,强烈推荐。
为了和deepseek对齐,我这里放出的所有结果都是GRPO Setting下的。
由于我只有四卡A100,跑实验相当费劲,坐等来个大佬资助我跑实验 ()
Train batch size只有8,Rollout先大后小 (32-64-16)
三阶段RL
我的经验是:高温采样+超大rollout Matters
Step1: 课程学习与格式遵循
为了训练的平稳过渡,我们先用少量3人逻辑题做预热,使用默认采样设置。
此阶段主要是学的格式,只要不遵守该规则,我们就施加很大的负面奖励。模型在10step训练里很快就能学会把format error降到0.1的占比
伪变长:此阶段观察到极少量的response length ++,主要提升的是最短response的长度,max response长度基本没变,是反馈到mean length上是一个变长的过程。
以及此阶段确实验证了Pure Rule Based RL有效性,Val acc一直在涨,不过不如SFT来收益来的快
Step2:高温采样与大量rollout
数据集过渡到正式的5人谜题,此阶段训练持续最长。也是最容易崩溃的时候。
我训了14版超参,都是崩坏的,泪目,下面讲讲一些好玩的崩坏demo。
尝试将采样温度设置为1.2附近。(实测1.5会崩,1.5什么鸟语言都蹦出来了)。topp和topk也调了一下,主要目的是紊乱模型回复格式,破坏其markdown的输出风格,增加token多样性。
下图是截取的模型一个很有意思的repeat现象,可以看得出来,RL极大地增加了verify token被chosen的概率,这纯粹是自发形成的。数据集没有任何verify相关的思考token。
1. 模型的呓语:它想verify, 要precise, 注意consistent执念很深

2. Retrying too late,但没有后悔药可以吃
模型已经到达最后需要输出结果的answer阶段了,忽然意识到自己前面犯了错,想重回think模式,但是retry太晚了,这样的行为会被给予严厉的负format惩罚

3. 忽然学会了正确地verify,以及先总结初步结论再做进一步探索,但思考过程还是比较简陋

这里有很多有意思的设置小细节和中间输出的观察,非常值得深入探索
请等后续,几周内我们会写好完整文章~
Step3: 漫长的退火
采样设置里逐步回归正规,比如温度从1.2慢慢降到0.9。
此阶段模型的输出如demo1所示,非常的成熟,有verify,有反思,有回溯,有格式,要啥有啥,我很满意的。
整体思考并不冗长,废话也不多,比distill模型的回复看起来正常多了。
学习率也逐级递减到了2e-7。此阶段模型收敛速度贼慢,但多等一会,会有很多惊喜。还是让它训着吧。
奇怪的想法
- 语言混杂的现象非常迷人。手动查找log,似乎后期每个语言混杂的response都是对的,难道对模型来说混合语言作答是更有利于它reasoning的pattern?
- 进一步地,谁说thinking porcess一定要是人类可读的,只要answer看得懂就行。如果答案对,我宁可中间全是乱码也无所谓(bushi)
- 只要能从模型输出里恢复出人类要的答案,answer format其实也是不必要的,只是测试验证的难度大大增加了。看上去又回到了某种ORM的老路..
- Response增加是合理的。此前模型只会一路走到黑,多了几次verify和check后,自然长度增加
- 泛化性:当前模型的思考能力实测是可以迁移到GSM8K的。由此展开或许可以跑一堆实验...
- 此外,本地存了一堆ckpt,坐等后续可解释性分析哈哈哈。之前一直想做Long CoT的可解释性,现在手头终于有一些ckpt随便测了,启动!
最后扯一句,Deepseek真是越来越强了,眼睁睁看着从deepseek v2开始,成长到过年期间发现街头巷尾都在讨论它。逐渐变成了攀不上的模样(可能最早期我bar也不够)。欸,真想去deepseek实习看看。春节最快乐的事情,就是看着zero模型RL曲线嘎嘎地涨!
....
#DeepSeek是中国最好AI模型,但没任何科学进步
诺奖得主DeepMind CEO放话:
xAI、谷歌DeepMind和Anthropic的CEO们纷纷对DeepSeek的技术创新性提出质疑,认为其并未带来实质性的科学突破。AI大佬纷纷泼冷水,到底是技术讨论还是各怀目的?
就在今天,谷歌DeepMind的首席执行官Demis Hassabis对DeepSeek进行了一番「捧杀」——
「它可能是中国最好的工作,但没有展示任何新的科学进展。」
Hassabis首先称DeepSeek的模型是「一项令人印象深刻的工作」,然后便一改口风说道:「从技术角度来看,这并不是一个重大变革」,同时还特别强调「炒作有点夸大了」。
「尽管炒作很多,但实际上并没有新的科学突破,它使用的都是已知的AI技术。」
Hassabis同时表示,谷歌本周向所有人开放的Gemini 2.0 Flash模型比DeepMind的模型更加高效。
所以,Hassabis对DeepSeek的种种质疑也就不难理解,DeepSeek事实上已经成为了DeepMind的强劲对手。
马斯克:xAI很快就会发布更好的模型
不只是Hassabis,马斯克也在前几天举行的WELT经济峰会访谈中表达了类似观点。
这次访谈中,当被问道DeepSeek R1是否是AI领域的一次彻底革命时,马斯克明确表示,「不是,xAI和其他一些公司很快就会发布比DeepSeek更好的模型」。
X上已经有网友开始爆料,马斯克所口中的「更好的模型」很可能就是即将发布的Grok 3。
据传新的Grok 3模型在代码和创造力方面比上一代模型要好得多。其中代号为「chocolate」的版本感觉像是完整版,而另一个代号是「kiwi」的版本像是迷你版或者是量化的版本。
马斯克在访谈中还表示,「中国有很多非常聪明、非常有驱动力的工程师。你应该预料到中国会创造出许多伟大的东西,而且他们已经创造出了许多伟大的东西。」
他强调,在人类历史的大部分时间里,中国一直是世界上最强大的国家。
在谈到AI的开源问题时,马斯克认为,开源模型通常落后于商业模型。但他同时强调,今天商业上强大的模型,可能再过一年或更短的时间内就会开源。「我预计这种趋势会持续下去。所以,基本上每个人都将拥有AI。」
马斯克已经为Grok 3造势好长一段时间了,所以此次对DeepSeek的点评,也不排除是继续为Grok 3造势。
Anthropic CEO长篇檄文:DeepSeek缺乏研究价值
不过,要说对DeepSeek恶意最大的,还要属在春节期间发出「万字檄文」的Anthropic CEO Dario Amodei。
在他看来,根据历史趋势,LLM的成本每年都会下降约4倍,这意味着现在应该有比GPT-4/Claude 3.5便宜3-4倍的模型出现。
相比之下,DeepSeek-V3的性能比目前的美国顶级模型低约2倍,训练成本比一年前的美国模型低约8倍,这符合行业正常发展预期。
因此,DeepSeek-V3并不构成根本性突破或创新。还不如Claude 3.5对GPT-4实现的10倍价格差。
DeepSeek-R1的研究价值甚至连V3都不如——增加的第二阶段训练(强化学习),仅仅是对OpenAI在o1的复制。
Amodei表示,由于我们仍处于模型「扩展曲线」的早期,所以只要以一个强大的预训练模型为基础,很多公司都有可能开发出这类模型。
AGI五年内可期
作为这段时间AI圈顶级大佬们的「例行项目」,Hassabis也对AGI何时到来做了预测。
他表示,AI行业「正在通向AGI的道路上前进」,他将其描述为「一个具备人类所有认知能力的系统」。
「我认为我们现在已经很接近了,也许我们只需要大约5年就能实现这样一个系统,这将是非常非凡的」,Hassabis说。
「我认为社会需要为此做好准备,思考这将带来什么影响。我们要确保能从中获益,让整个社会都能从中受益,但同时也要减轻相关风险。」
Hassabis的评论与业内其他人的观点相呼应,他们也暗示AGI可能离现实更近了。
OpenAI的CEOSam Altman今年就表示,他「相信我们知道如何构建我们传统理解中的AGI」。
不过,业内许多人也指出了与AGI相关的多重风险;最大的担忧之一是人类将失去对他们创造的系统的控制,著名AI科学家Max Tegmark和Yoshua Bengio最近在接受CNBC采访时也表达了他们对这种形式AI的担忧。
结语
DeepSeek的横空出世,无疑在全球AI领域掀起了一场风暴。不仅在国内一直霸榜,现在全球的大佬也都将目光关注于此。
在未来,随着各大科技巨头的持续投入与竞争,AI领域的格局将愈发复杂多变,而AGI的到来或许也将比我们想象的更近。
参考资料:
https://www.youtube.com/watch?v=QVbRG2J1Saw
....
#数据集偏差的十年之战
何恺明和刘壮提出
我们在消除数据集偏差的战斗中,真的取得了胜利吗?
MIT新晋副教授何恺明,新作新鲜出炉:
瞄准一个横亘在AI发展之路上十年之久的问题:数据集偏差。
该研究为何恺明在Meta期间与刘壮合作完成,他们在论文中指出:
尽管过去十多年里业界为构建更大、更多样化、更全面、偏差更小的数据集做了很多努力,但现代神经网络似乎越来越善于”识破”并利用这些数据集中潜藏的偏差。
这不禁让人怀疑:我们在消除数据集偏差的战斗中,真的取得了胜利吗?
数据集偏差之战,在2011年由知名学者Antonio Torralba和Alyosha Efros提出——
Alyosha Efros正是Sora两位一作博士小哥(Tim Brooks和William Peebles)的博士导师,而Antonio Torralba也在本科期间指导过Peebles。
当时他们发现,机器学习模型很容易“过拟合”到特定的数据集上,导致在其他数据集上表现不佳。
十多年过去了,尽管我们有了更大、更多样化的数据集,如ImageNet、YFCC100M、CC12M等,但这个问题似乎并没有得到根本解决。
反而,随着神经网络变得越来越强大,它们“挖掘”和利用数据集偏差的能力也越来越强了!
为了分析这个问题,何恺明团队设计了一个虚构的”数据集分类”任务。
听名字你可能就猜到了:给定一张图像,模型需要判断它来自哪个数据集。通过看模型在这个任务上的表现,就可以了解它们捕捉数据集偏差的能力。
现代AI轻松识破不同数据集
在实验中团队发现,各种现代神经网络架构,如AlexNet、VGG、ResNet、ViT等,在数据集分类任务上表现出惊人的一致性:它们几乎都能以超过80%的准确率区分不同数据集的图像!
更令人吃惊的是,这个发现在各种不同的条件下都非常稳健:
不管是不同的数据集组合、不同的模型架构、不同的模型尺寸、不同的训练数据量,还是不同的数据增强方法,神经网络始终能轻松”一眼识破”图像的数据集来源。
那么,神经网络是如何做到这一点的呢?是靠单纯的记忆,还是学到了一些更普适的规律?
为了揭开谜底,团队做了一系列对比实验。他们发现,如果把不同的数据集随机混在一起,神经网络就很难再区分它们了(准确率下降到了33%)。这说明,神经网络并不是在单纯地记忆每一张图像,而是真的学到了一些数据集特有的模式。
更有趣的是,即使在自监督学习的设置下,神经网络也展现出了惊人的”数据集辨识力”。在这种设置下,模型在训练时并没有用到任何数据集的标签信息,但当在这些自监督学习到的特征上训练一个简单的线性分类器时,它依然能以超过70%的准确率区分不同的数据集!
通过这一系列的实验,何恺明、刘壮等人的研究给我们敲响了警钟:尽管这十年我们一直在努力构建更大、更多样化的数据集,但数据集偏差这个问题似乎并没有得到根本解决。相反,现代神经网络越来越善于利用这些偏差来获得高准确率,但这可能并不代表它们真正学到了鲁棒、普适的视觉概念。
论文的最后,作者呼吁整个AI社区重新审视数据集偏差这个问题,并重新思考如何在算法和数据两个层面上来应对这一挑战。
CVPR最佳论文作者的通力合作
本文是何恺明在Meta期间,与Meta研究科学家刘壮合作完成。
现在,何恺明已经正式在MIT上岗,担任电气工程与计算机科学系的助理教授。他的“开学第一课”开课即火爆,在youtube上已经有2.9万的播放量。
和何恺明一样,刘壮本科毕业自清华,并且也是CVPR最佳论文奖得主——他是CVPR2017最佳论文DenseNet的第一作者。
2017年,刘壮从清华姚班毕业,进入加州大学伯克利分校攻读博士学位,师从Trevor Darrell,是贾扬清的同门师弟。
博士毕业后,刘壮进入Meta AI Research工作。在此之前,他已经在Meta实习了一年多时间,期间和谢赛宁合作,发表了ConvNeXt。
论文地址:
https://arxiv.org/abs/2403.08632
参考链接:
https://twitter.com/liuzhuang1234/status/1768096508082008289
....
#DeepSeek蒸馏的不是白酒,而是一个学神学生
最近,很多芯片厂商都官宣了适配DeepSeek,在其中非常高频出现的一个词汇是“蒸馏模型”。而在DeepSeek的一些深度解析中,也提到了“蒸馏”这一概念。那么,“蒸馏”到底指的是什么?
模型蒸馏技术的基本原理

模型蒸馏(Knowledge Distillation)是一种知识迁移技术,旨在将复杂且高性能的教师模型知识,迁移至简单、小巧的学生模型。
教师模型如同知识渊博但需庞大资源支持的“学霸”,而学生模型则像是期望在资源有限条件下达到相似能力的“学神”。传统学生模型训练依赖“硬标签”,如同“死记硬背”。而模型蒸馏采用“软标签”,让学生模型学习教师模型的“解题思路”。例如,对于“2+2=?”的问题,硬标签直接给出答案“4”,软标签则会告知“3”和“5”也有一定可能性(概率较低),学生模型借此不仅学到答案,还掌握了教师模型的思考方式,泛化能力更强。模型蒸馏过程通常分为三步:首先训练强大的教师模型;接着教师模型对训练数据生成软标签,学生模型通过模仿软标签进行训练;最后学生模型成为轻量级且性能接近教师模型的存在。
DeepSeek蒸馏技术的创新实践
(一)数据蒸馏与模型蒸馏结合 DeepSeek将数据蒸馏与模型蒸馏相结合,显著提升模型性能并降低计算成本。数据蒸馏通过优化训练数据助力小模型高效学习,如利用教师模型生成或优化数据,包括数据增强、伪标签生成和优化数据分布。在模型蒸馏方面,DeepSeek运用监督微调(SFT),将教师模型的知识迁移到学生模型,且不涉及额外强化学习(RL)阶段,提升了蒸馏效率。这种结合方式让DeepSeek的蒸馏模型在推理基准测试中成绩斐然,如DeepSeek - R1 - Distill - Qwen - 7B在AIME 2024上实现了55.5%的Pass@1,超越了QwQ - 32B - Preview。
(二)高效知识迁移策略 DeepSeek采用基于特征的蒸馏和特定任务蒸馏等策略,实现高效知识传递和模型优化。基于特征的蒸馏将教师模型中间层特征信息传递给学生模型,帮助其捕捉数据本质特征;特定任务蒸馏针对不同任务(如机器翻译、文本生成)对蒸馏过程优化。这些策略使DeepSeek的蒸馏模型在多个基准测试中表现卓越,DeepSeek - R1 - Distill - Qwen - 32B在AIME 2024上实现了72.6%的Pass@1,在MATH - 500上实现了94.3%的Pass@1 。
(三)蒸馏模型架构与训练优化
1. 架构设计:教师模型选择自主研发的671B参数的DeepSeek - R1,其强大推理能力和广泛知识覆盖为蒸馏提供基础。学生模型基于Qwen和Llama系列架构,在计算效率和内存占用上表现出色。蒸馏模型采用层次化特征提取机制,让学生模型学习教师模型多层特征表示,理解数据结构和模式;设计多任务适应性机制,使学生模型针对不同任务优化;运用参数共享与压缩技术减少参数数量和存储需求,引入轻量化模块设计降低计算复杂度。
2. 训练过程与优化:训练数据主要来自教师模型生成的推理数据样本,并采用数据增强技术提高数据多样性。训练时采用监督微调将教师模型知识迁移到学生模型,设计混合损失函数(结合软标签损失和硬标签损失)。优化方法上,引入温度参数调整软标签分布,采用动态学习率调整策略确保训练稳定性和收敛速度,使用正则化技术(如L2正则化项)避免过拟合。
蒸馏模型的性能优势
(一)推理效率提升 DeepSeek蒸馏模型在推理效率上显著提升。参数量大幅减少,如DeepSeek - R1 - Distill - Qwen - 7B仅7B参数,计算复杂度降低,减少推理所需计算资源;内存占用减少,DeepSeek - R1 - Distill - Llama - 8B内存占用仅为原始模型的1/80左右;推理速度大幅提高,DeepSeek - R1 - Distill - Qwen - 32B处理复杂推理任务时,推理速度比原始模型提高约50倍。
(二)性能与原始模型对比 通过高效知识迁移策略,DeepSeek蒸馏模型在性能上接近甚至超越原始大型模型。采用监督微调将教师模型推理数据样本用于学生模型训练,使其学习关键知识和推理模式。在多个基准测试中,DeepSeek蒸馏模型表现出色,DeepSeek - R1 - Distill - Qwen - 7B在AIME 2024基准测试中超越QwQ - 32B - Preview,DeepSeek - R1 - Distill - Qwen - 32B在AIME 2024和MATH - 500上也取得优异成绩 。
模型蒸馏技术面临的挑战
(一)突破蒸馏的“隐性天花板” 尽管模型蒸馏技术取得显著成效,但仍面临“隐性天花板”挑战。学生模型性能难以超越教师模型固有能力,在多模态数据处理等复杂任务中,学生模型推理能力受教师模型固有模式限制,难以实现深层次创新。
(二)多模态数据的蒸馏挑战 多模态数据(图像、文本、语音等)的蒸馏面临诸多难题。不同模态数据特征和结构差异大,数据融合难度高;语义对齐困难,需确保不同模态数据在语义层面准确对应;计算资源需求大,处理多模态数据增加蒸馏过程的计算复杂度。模型蒸馏技术作为模型优化的重要手段,在提升模型运行效率、降低资源消耗方面成果显著,尤其像DeepSeek在技术创新和应用上取得了突出成绩。然而,面对“隐性天花板”和多模态数据蒸馏等挑战,未来还需更多研究与探索,以推动模型蒸馏技术进一步发展,拓展其在更多领域的应用。
....
#关于 DeepSeek 的深度答疑
深入探讨DeepSeek的技术突破及其对AI行业的影响。
Ben Thompson 是科技领域最具洞察力的分析师之一,他的博客 Stratechery 以其对科技行业的深度分析和前瞻性预测而闻名。
Q:为什么你还没写关于DeepSeek的文章?
Ben Thompson:我写了!我上周二就写了关于R1的内容。我依然认可那篇文章的观点,包括我强调的两个关键点(通过纯强化学习实现的涌现链式思维,以及知识蒸馏的强大威力)。我也提到了低训练成本以及芯片禁令的影响。但我当时的观察过于局限于当前AI技术的发展,而我完全没有预见到这条新闻在更宏观的讨论层面,特别是在美中关系方面,会引发如此广泛的影响。
Q:有过类似的误判吗?
Ben Thompson:确实有过。2023年9月,华为发布了Mate 60 Pro,搭载由中芯国际制造的7nm芯片。这颗芯片的存在并没有让密切关注该领域的人感到意外:中芯国际早在一年前就生产了7nm芯片(而我在更早的时候就指出了它的存在),而台积电也曾在不依赖EUV光刻的情况下批量生产7nm芯片(后来的一些7nm制程才开始引入EUV)。英特尔更早之前也曾使用DUV光刻技术生产10nm(相当于台积电的7nm)芯片,只是良率太低,无法盈利。因此,中芯国际用现有设备生产7nm芯片并不让人意外——至少对我来说是这样。
但我完全没预料到的是,华盛顿的反应会如此激烈。美国政府对芯片禁令的急剧升级最终导致拜登政府将芯片销售转变为“许可制”。这背后的原因,是许多人不理解芯片制造的复杂性,被华为Mate 60 Pro突如其来的发布打了个措手不及。我感觉过去72小时里,类似的事情正在发生:DeepSeek取得的具体技术突破——以及它尚未实现的部分——本身并不重要,关键在于人们的反应,以及这种反应揭示了他们原本的假设。
Q:那么DeepSeek具体发布了什么?
Ben Thompson:本周末引发广泛讨论的最直接原因是R1——一个推理能力与OpenAI的o1相当的模型。然而,真正导致市场震动的信息——比如DeepSeek的训练成本——其实早在圣诞节发布的V3版本中就已披露。而支撑V3的关键技术突破,最早可以追溯到去年1月发布的V2版本。
Q:DeepSeek的模型命名规则是不是OpenAI犯下的“最大罪行”?
Ben Thompson:第二大罪行,我们稍后再聊最大的那个。让我们从头开始:V2模型是什么?为什么它很重要?
DeepSeek-V2带来了两个关键突破:DeepSeekMoE和DeepSeekMLA。
DeepSeekMoE中的“MoE”指的是“Mixture of Experts(专家混合)”。像GPT-3.5这样的模型,在训练和推理时会激活整个模型,但实际上,并非所有部分都对特定任务有贡献。MoE通过将模型划分为多个“专家”,只在需要时激活相关专家,从而提升效率。据推测,GPT-4也是一个MoE模型,可能包含16个专家,每个专家约有1100亿参数。
DeepSeekMoE在V2版本中对这一概念进行了创新,包括颗粒度更细的专家划分,以及具备更强泛化能力的共享专家。此外,DeepSeek还优化了训练过程中的负载均衡和路由机制。传统的MoE模型在训练时计算开销较大,但DeepSeek的方法在保持推理高效的同时,也让训练变得更高效。
DeepSeekMLA(Multi-head Latent Attention,多头潜在注意力)则是更大的突破。推理的最大瓶颈之一在于内存占用:不仅需要加载整个模型,还要加载整个上下文窗口(context window)。而上下文窗口在内存中非常昂贵,因为每个token都需要存储一个Key-Value。DeepSeekMLA让Key-Value存储得以压缩,从而大幅降低推理时的内存使用。
这些突破的真正意义——也是你需要关注的重点——在V3版本中才真正显现。V3进一步优化了负载均衡(进一步减少通信开销),并在训练中引入了多token预测(提升每一步训练的密度,再次减少开销)。最终,V3版本的训练成本低得惊人。
DeepSeek宣称,该模型的训练共消耗278.8万H800 GPU小时,按照每GPU小时2美元计算,总成本仅557.6万美元。这个成本低得难以置信。DeepSeek明确表示,这个成本仅指最终的训练运行,不包括所有其他开销。以下是V3论文中的相关内容:
我们再次强调DeepSeek-V3的经济训练成本,如表1所示,这是通过优化算法、框架和硬件协同设计实现的。在预训练阶段,每处理1万亿个token仅需180K H800 GPU小时,即在我们配备2048 H800 GPU的集群上训练3.7天。因此,我们在不到两个月内完成了预训练,总计耗费2664K GPU小时。再加上用于上下文长度扩展的119K GPU小时和后训练的5K GPU小时,DeepSeek-V3的完整训练仅耗费2.788M GPU小时。假设H800 GPU的租赁价格为小时,我们的总训练成本仅为557.6万。需要注意的是,上述成本仅包括DeepSeek-V3的正式训练,不包含在架构、算法或数据上的前期研究和消融实验成本。
你不能用557.6万美元复制DeepSeek这家公司。
Q:我还是不相信这个数字。
Ben Thompson:实际上,质疑者需要提供证据来反驳这个数字,特别是在你理解了V3的架构之后。还记得我们之前提到的DeepSeekMoE吗?V3具有6710亿参数,但每个token仅计算370亿参数的活跃专家部分,这相当于3333亿FLOPs(浮点运算)。
这里还需要提到DeepSeek的另一个创新点:虽然参数存储时使用BF16或FP32精度,但在计算时会降低到FP8精度。此外,2048张H800 GPU的计算能力为3.97exaFLOPS(即3.97×10¹⁸FLOPS)。训练集包含14.8万亿tokens,当你计算所有数据后,会发现278.8万H800小时确实足以训练V3。再次强调,这只是最终训练的计算量,而不是所有成本,但它是一个合理的数字。
Q:Scale AI的CEO Alexandr Wang说他们有50,000张H100。
Ben Thompson:我不确定Wang的数据来源,但我猜他指的是2024年11月Dylan Patel的一条推文,其中提到DeepSeek拥有超过5万张Hopper GPU。然而,H800也是Hopper GPU,只是由于美国的出口管制,其内存带宽比H100受限得多。
关键在于,DeepSeek的许多创新,都是为了克服H800内存带宽的限制。 如果你仔细计算过前面的内容,就会发现DeepSeek其实是有充足算力的。原因在于:DeepSeek专门将H800的132个计算单元中的20个用于管理跨芯片通信。
这在CUDA(Nvidia的标准编程框架)中是无法实现的,DeepSeek的工程师必须使用PTX(Nvidia GPU的低级指令集,相当于汇编语言)进行编程。这种优化级别极高,只有在使用H800而不是H100时才有意义。与此同时,DeepSeek还需要为模型推理提供算力,这意味着他们的GPU远不止用于训练。
Q:那么,这是否违反了美国的芯片禁令?
Ben Thompson:没有。H100是被禁的,但H800没有被禁。许多人原本以为训练顶级模型必须依赖高内存带宽,但DeepSeek正是围绕这个限制进行了优化,调整了模型架构和基础设施,最终成功解决了这个问题。
再次强调,DeepSeek设计V3的所有决策,只有在受限于H800时才有意义。 如果他们能获得H100,可能会使用更大的训练集群,而不会做那么多专门针对低带宽的优化。
Q:那么,V3是一个顶级模型吗?
Ben Thompson:V3的确能与OpenAI的GPT-4o和Anthropic的Sonnet-3.5竞争,并且似乎比Llama系列的最大模型更强。更值得注意的是,DeepSeek可能通过蒸馏(distillation)从这些模型中提取了高质量token作为训练数据。
Q:什么是蒸馏?
蒸馏是一种从更强的模型中提取知识的方法:你可以给教师模型(teacher model)输入数据,记录它的输出,并用这些数据训练学生模型(student model)。这就是GPT-4 Turbo从GPT-4演化而来的方式。
一般来说,公司只能对自己的模型进行蒸馏,因为他们有完整的访问权限。但如果愿意,仍然可以通过API访问,甚至通过对话界面(chat clients)进行非正式蒸馏。
当然,蒸馏通常违反OpenAI等公司的服务条款,唯一的防范方法是直接封禁IP或者限制API访问。但这仍然是一种普遍存在的训练策略,也正因如此,我们才看到越来越多的模型在逼近GPT-4o的质量。 我们无法100%确定DeepSeek是否对GPT-4o或Claude进行了蒸馏,但老实说,如果他们没有这么做,那才奇怪。
Q:蒸馏对顶级模型来说是个坏消息吧?
Ben Thompson:没错!从好的方面来看,OpenAI、Anthropic和Google也在用蒸馏优化推理模型,以便在面向消费者的应用中运行得更高效。但从坏的方面来看,他们承担了所有顶级模型的训练成本,而其他公司则“白嫖”这些成果。
实际上,这可能是微软与OpenAI渐行渐远的核心经济原因。微软对提供推理服务感兴趣,但不太愿意为1000亿美元的数据中心买单,因为这些模型在商业化之前就可能已经被蒸馏、复制,变得廉价。
Q:这就是为什么所有科技股股价都在下跌吗?
Ben Thompson:从长期来看,模型的普及和推理成本下降(DeepSeek也证明了这一点)对大科技公司来说是好事。
微软:推理成本大幅降低意味着数据中心和GPU需求减少,或者用户量暴增。
亚马逊(AWS):AWS自己的AI模型竞争力较弱,但他们可以用超低成本部署高质量的开源模型,照样赚推理的钱。
苹果:推理的内存需求大幅减少,使边缘推理(edge inference)更加可行,而苹果拥有最强的硬件。苹果芯片的统一内存架构(Unified Memory)比Nvidia游戏GPU更适合AI推理。
Meta(脸书):最大的赢家!Meta所有的AI计划都受益于更低的推理成本,这让他们的AI生态更容易实现。
Google:可能会受损。因为硬件要求下降,削弱了Google TPU的竞争力。而且推理成本降低会催生取代搜索的AI产品,这对Google的核心业务构成威胁。
你问股价为什么跌,我给你的是长期趋势;市场今天反应的只是短期冲击。
Q:等一下,你还没谈R1呢?
Ben Thompson:R1是一个推理模型,类似OpenAI的o1。它可以进行复杂的思考,提高代码、数学和逻辑推理能力。
Q:R1比V3更惊人吗?
Ben Thompson:其实,我花了这么多时间讲V3,是因为V3证明了让市场震惊的技术趋势。R1之所以特别,主要有两个原因:第一,它的存在本身就说明OpenAI并不具备“不可复制的独特优势”。第二,R1是开源的(虽然没有数据集),所以你可以在任何服务器甚至本地运行它,而不需要付费给OpenAI。
Q:DeepSeek是如何训练R1的?
DeepSeek其实训练了两个模型:R1和R1-Zero。R1-Zero才是更值得关注的模型——正如我在上周二的更新中所提到的:
R1-Zero在我看来才是真正的大事。他们的论文中写道:
在本文中,我们迈出了利用纯强化学习(RL)提升语言模型推理能力的第一步。我们的目标是探索大型语言模型(LLM)在没有任何监督数据的情况下,通过纯强化学习过程实现自我进化的潜力。具体而言,我们以DeepSeek-V3-Base作为基础模型,并采用GRPO作为强化学习框架,以提升模型在推理方面的表现。在训练过程中,DeepSeek-R1-Zero自然涌现出了许多强大且有趣的推理行为。经过数千步的强化学习,DeepSeek-R1-Zero在推理基准测试上展现出了超凡的表现。例如,在AIME 2024竞赛上的pass@1分数从15.6%提升到了71.0%,并且在使用多数投票的情况下,该分数进一步提升至86.7%,达到了OpenAI-o1-0912的水平。
强化学习是一种机器学习技术,其中模型被提供一组数据和一个奖励函数。一个经典的例子是AlphaGo,DeepMind给该模型提供了围棋的规则,并设定了“赢得比赛”作为奖励函数,随后让模型自行摸索其它一切策略。这种方法最终被证明比其他更具人为指导的技术更有效。
然而,迄今为止,大型语言模型主要依赖“带有人类反馈的强化学习”(RLHF);在该过程中,人类会参与其中,以帮助引导模型,解决奖励不够明确的难题等。RLHF是GPT-3进化为ChatGPT的关键创新,使得模型可以生成结构良好的段落,提供简明扼要的回答,而不会跑题或产生无意义的内容。
然而,R1-Zero舍弃了“人类反馈”(HF)部分,仅仅使用强化学习。DeepSeek研究团队向模型提供了一系列数学、代码和逻辑问题,并设置了两个奖励函数:一个用于奖励正确答案,另一个用于奖励符合推理过程的正确格式。此外,该方法相对简单:研究人员没有采用“逐步评估”(过程监督)或像AlphaGo那样搜索所有可能答案,而是鼓励模型同时尝试多个答案,并根据这两个奖励函数进行评分。
由此涌现出了一种能够自主发展推理能力和“思维链”(chain-of-thought)的模型,其中甚至出现了DeepSeek研究团队称之为Aha Moments的现象:
在DeepSeek-R1-Zero的训练过程中,我们观察到了一个特别有趣的现象,即Aha Moments。正如表3所示,这一现象出现在模型的中间训练阶段。在这一阶段,DeepSeek-R1-Zero学会了为某个问题分配更多的思考时间,并重新评估其最初的解题方法。这种行为不仅展现了模型日益增强的推理能力,同时也是强化学习如何催生意想不到且复杂结果的一个引人注目的例子。
这种Aha moment不仅对模型而言是一次突破性的发现,对观察它的研究人员而言也是如此。这一现象凸显了强化学习的强大和魅力:相比于直接教授模型如何解题,我们仅仅为它提供正确的激励,它便能自主发展出高级的问题解决策略。 这个Aha Moments是强化学习能够解锁人工智能新智能水平的一个有力证明,为未来更加自主和适应性的模型铺平了道路。
这可能是迄今为止对“痛苦的教训”(The Bitter Lesson)最有力的肯定之一:你无需教AI如何推理,只需给予它足够的计算能力和数据,它就能自学成才!
不过,还差一点:R1-Zero确实具备推理能力,但它的推理方式让人类难以理解。回到论文的介绍部分:
然而,DeepSeek-R1-Zero仍然面临诸如可读性差、语言混杂等挑战。为了解决这些问题并进一步提升推理能力,我们引入了DeepSeek-R1,它结合了一小部分“冷启动数据”(cold-start data)以及多阶段训练流程。具体来说,我们首先收集了数千条冷启动数据,对DeepSeek-V3-Base进行微调。随后,我们像训练DeepSeek-R1-Zero一样执行基于推理的强化学习。当强化学习过程接近收敛时,我们通过拒绝采样(rejection sampling)在RL训练的检查点上创建新的监督微调数据,并结合来自DeepSeek-V3的监督数据(涉及写作、事实问答和自我认知等领域),对DeepSeek-V3-Base进行再训练。在新数据微调后,模型检查点会经历额外的强化学习过程,并纳入所有场景下的提示语。经过这些步骤,我们最终得到了DeepSeek-R1,其性能已达到OpenAI-o1-1217的水平。
这听起来与OpenAI在o1训练过程中采用的方法非常相似:DeepSeek研究团队先用一组“思维链”示例来引导模型学习适合人类理解的格式,然后再利用强化学习增强推理能力,并进行一系列编辑和优化步骤。最终产出的模型在推理能力和可读性方面都足以与OpenAI-o1竞争。
DeepSeek可能确实受益于蒸馏,尤其是在训练R1方面。不过,这本身就是一个重要的结论:我们正处于AI模型教AI模型、AI模型自我训练的时代,眼前正是AI起飞情境的实时展开。
Q:那么,我们接近AGI了吗?
Ben Thompson:看起来确实如此。这也解释了为什么Softbank(以及孙正义能聚集的投资者)愿意为OpenAI提供微软不愿提供的资金:他们相信我们正处于一个临界点,抢先一步确实会带来真正的回报。
Q:但R1现在不是领先了吗?
Ben Thompson:我认为并不是,这个说法被夸大了。R1与o1旗鼓相当,尽管它在某些能力上存在漏洞,暗示其部分能力可能源自o1-Pro的蒸馏。而与此同时,OpenAI已经展示了o3——一个更强大的推理模型。DeepSeek无疑是效率方面的领导者,但这与整体领先是两个概念。
Q:那为什么大家都在恐慌?
Ben Thompson:我认为有几个原因。首先,中国赶上了美国顶级实验室,这让人震惊,毕竟很多人都认为中国在软件方面不如美国。这可能是我之前低估市场反应的关键原因。 实际上,中国的软件产业整体上非常强大,在AI模型构建方面也有很好的成绩。
其次,V3的低训练成本以及DeepSeek的低推理成本。 这对我来说也是个意外,但数据是合理的。这也让市场对Nvidia感到紧张,毕竟这对其市场地位有很大影响。
第三,DeepSeek在芯片禁令的背景下仍然取得了这一成就。 尽管芯片禁令有漏洞,但DeepSeek很可能是用合法芯片完成的。
Q:我持有Nvidia股票!完蛋了吗?
Ben Thompson:这确实对Nvidia的故事构成了真正的挑战。Nvidia有两大护法:CUDA是开发者的首选语言,而CUDA只能在Nvidia芯片上运行。Nvidia在多芯片互联成大型虚拟GPU方面拥有巨大领先优势。
这两大护法是相辅相成的。我之前提到,如果DeepSeek能获得H100,他们可能会用更大的集群来训练模型,因为这会更省事。但他们没有,带宽受限,这影响了他们的模型架构和训练基础设施决策。而看看美国实验室,它们在优化方面并未投入太多精力,因为Nvidia一直在提供更强大的系统,满足它们的需求。最简单的路径就是付钱给Nvidia。然而,DeepSeek刚刚证明了另一条路径的可行性:通过深度优化,即使在较弱的硬件上,仍然可以取得惊人的结果。这表明,仅仅砸钱给Nvidia,并不是改进模型的唯一方式。
不过,Nvidia仍然有三个优势。第一,DeepSeek的方法如果应用到H100或即将推出的GB100上,会有多强?他们找到了更高效的计算方式,并不意味着更多计算资源就没用了。第二,长期来看,较低的推理成本应该会推动更广泛的使用。微软CEO Satya Nadella在深夜发推,显然就是为了向市场传递这个信息。第三,像R1和o1这样的推理模型,其卓越性能依赖于更多计算资源。如果AI的进步仍然依赖于更多算力,那Nvidia就仍然是受益者。
微软CEO Satya Nadella在深夜发布了一条推文,几乎可以肯定是针对市场的,他明确表示了这一点:

图片来源:Stratechery
尽管如此,情况并非一片光明。至少,DeepSeek的高效性和广泛可用性让Nvidia最乐观的增长预期受到了质疑,至少在短期内是这样。此外,模型和基础设施优化的成功也表明,探索推理方面的替代方案可能带来重大收益。例如,在独立的AMD GPU上运行推理可能比使用AMD较弱的芯片间通信能力更具可行性。而推理模型的进步,也让比Nvidia GPU更专业化的推理专用芯片的价值大幅提升。
简而言之,Nvidia不会消失,但Nvidia的股价却突然面临更多尚未被市场定价的不确定性。这反过来会拖累整个市场。
Q:那么,芯片禁令呢?
Ben Thompson:最简单的说法是,考虑到美国在软件上的领先优势正迅速消失,芯片禁令的重要性反而被凸显了。软件和技术知识无法被封锁——关于这一点,我们早已讨论并得出结论。但芯片是实物,美国有理由让中国无法获得。
与此同时,我们也需要保持谦逊,因为早期的芯片禁令似乎直接促成了DeepSeek的创新。而这些创新不仅适用于走私的Nvidia芯片或被削弱的H800,也适用于华为的Ascend芯片。事实上,可以说芯片禁令的主要后果,就是今天Nvidia股价的暴跌。
我更担忧的是,芯片禁令背后的思维方式:美国不是通过未来的创新来竞争,而是通过封锁过去的创新来竞争。 短期来看,这或许有帮助——毕竟,如果DeepSeek有更多算力,他们的效果可能会更好。但从长远来看,这只会在芯片和半导体设备这两个美国占据主导地位的行业中,播下新的竞争种子。
Q:就像AI模型一样?
Ben Thompson:AI模型正是一个很好的例子。我之前提到会谈OpenAI最严重的错误,我认为那就是2023年拜登的AI行政命令。我在《Attenuating Innovation》中写道:
这段话的核心观点是:如果你接受“监管会巩固现有巨头”的前提,那么就很值得注意,为什么那些最早赢得AI竞赛的公司,反而是最积极在华盛顿制造AI恐慌的群体。他们的关切似乎并没有严重到让他们停止自己的AI研究,相反,他们自诩为负责任的一方,主动呼吁监管——而如果这种监管最终能扼杀未来的竞争者,那当然更好了。
这一段主要谈的是OpenAI,以及更广泛的旧金山AI社区。多年来,正是那些致力于构建并控制AI的人,在大肆渲染AI的危险。 这些所谓的危险,正是OpenAI在2019年发布GPT-2时转向封闭模式的理由:
“由于担忧大型语言模型可能被用来大规模生成欺骗性、带有偏见或滥用性质的语言,我们仅发布一个更小版本的GPT-2及其采样代码(opens in a new window)。我们不会发布数据集、训练代码或GPT-2模型权重……我们意识到,一些研究人员具备复现并开源我们成果的技术能力。我们认为我们的发布策略限制了最初可能这样做的组织,并为AI社区提供了更多时间来讨论此类系统的影响。”
“我们还认为,各国政府应考虑扩大或启动更多系统性举措,以监测AI技术的社会影响及其传播情况,并衡量这些系统能力的进展。如果推进,这些努力可能会为AI实验室和政府在发布决策及AI政策方面提供更坚实的证据基础。”
这段话的傲慢程度让人发指:六年过去了,全世界都能获取比当年的GPT-2强大得多的模型权重。OpenAI试图通过美国政府来维持控制权的策略彻底失败了。在这期间,由于顶尖模型没有开源,我们错失了多少创新机会?更广泛地说,我们又浪费了多少时间和精力在游说政府建立一个护城河,而DeepSeek刚刚摧毁了它?这些时间和精力原本可以用来推进真正的创新。
Q:所以,你不担心AI末日论吗?
Ben Thompson:我完全理解这种担忧,毕竟我们已经进入AI训练AI、AI自学推理能力的阶段。但我也清楚,这趟列车无法停止。更重要的是,这正是开放性至关重要的原因:我们需要世界上有更多AI,而不是让一个不受监督的董事会来统治所有人。
Q:等等,为什么是中国在开源他们的模型?
Ben Thompson:准确来说,是DeepSeek在开源。其CEO梁文峰在一次采访中表示,开源是吸引人才的关键:
“面对颠覆性技术,封闭只是暂时的。即便是OpenAI的封闭策略,也无法阻止他人赶上。 因此,我们的核心价值在于团队——同事们在这一过程中成长,积累技术知识,形成一个有创新能力的组织和文化,这才是我们的护城河。开源、发表论文,对我们而言实际上没有成本。对于技术人才来说,看到他人跟随自己的创新,会有极大的成就感。事实上,开源更多是一种文化行为,而非商业行为,参与其中能赢得尊重。 对于一家公司而言,这种文化也具有吸引力。”
那篇采访中,采访者接着问梁文峰,这种策略未来会改变吗?DeepSeek目前带有一种理想主义色彩,类似于OpenAI的早期阶段,而且它是开源的。未来你们会转向封闭吗?OpenAI和Mistral都从开源转向了封闭。
梁文峰回答:“我们不会转向封闭。我们认为,首先建立一个强大的技术生态系统比什么都重要。这不仅仅是理想主义,而是符合商业逻辑的。如果模型是商品化的——目前看来确实如此——那么长期的竞争优势来自于更优的成本结构,而DeepSeek正是实现了这一点。这也呼应了中国如何在其他行业取得主导地位的方式。 这种思维方式与大多数美国公司的差异很大,美国公司通常依赖差异化产品来维持更高的利润率。”
Q:那么,OpenAI完了吗?
Ben Thompson:未必。ChatGPT让OpenAI意外地成为了一家消费级科技公司,也就是说,它成为了一家产品公司。OpenAI仍然可以通过订阅和广告的组合,在可商品化的模型基础上建立一个可持续的消费业务。而且,它仍在赌AI起飞竞赛的胜利。
相反,Anthropic可能是这次最大的输家。 DeepSeek的App登顶了App Store,而Claude在旧金山之外几乎没有获得关注。API业务表现更好,但API公司普遍最容易受到商品化趋势的冲击(值得注意的是,OpenAI和Anthropic的推理成本看起来比DeepSeek高得多,因为它们原本是在获取高额利润,但这部分利润正在消失)。
Q:所以,这一切都很令人沮丧吗?
Ben Thompson:其实不然。我认为DeepSeek给几乎所有人带来了巨大的礼物。最大的赢家是消费者和企业,他们可以期待一个几乎免费AI产品和服务的未来。长远来看,朱庇特悖论(Jevons Paradox)将主导局势,AI的使用者最终都会是最大的受益者。
另一批赢家是大型消费科技公司。在一个免费AI的世界里,产品和渠道最重要,而这些公司早已在这场竞争中获胜。中国也是一个大赢家,这一点可能需要时间才能完全显现。中国不仅可以直接使用DeepSeek的技术,而且DeepSeek相对于美国顶尖AI实验室的成功,可能会进一步激发中国的创新热情,让他们意识到自己可以竞争。
剩下的是美国,以及我们必须做出的选择。从逻辑上讲,我们可以选择加倍采取防御措施,比如大幅扩大芯片禁令,并对芯片和半导体设备实施类似欧盟技术监管的许可制度。或者,我们可以认识到自己面临真正的竞争,并给自己“竞争的许可”。别再杞人忧天,别再游说监管——相反,我们应该走向另一极端,砍掉公司内部所有与胜利无关的冗余。如果我们选择竞争,我们仍然可以赢。而如果我们赢了,我们将要感谢这家中国公司。
....

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 43
43 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)