Deepseek+Ollama+Dify搭建本地大模型
1)Ollama默认是装在C盘下(不建议,后期模型下载占很大空间),如果要装其他盘,不要急着点安装,先进入你想安装的安装盘,在盘里创建Ollama文件夹,接着在Ollama文件夹下创建models文件夹用于存放模型。通过设置参数值为新模型所在路径,如E:\ollama\models,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。引入电脑1搭建好的Ollama模型,点击右上角的用户头像,找到
所用设备:
电脑1:32g+3070的笔记本
电脑2:32g+4060的台式
电脑1开始搭建(deepseek+ollama):
一、Ollama下载:根据自己的系统环境下载Ollama;需注意的点:
1)Ollama默认是装在C盘下(不建议,后期模型下载占很大空间),如果要装其他盘,不要急着点安装,先进入你想安装的安装盘,在盘里创建Ollama文件夹,接着在Ollama文件夹下创建models文件夹用于存放模型
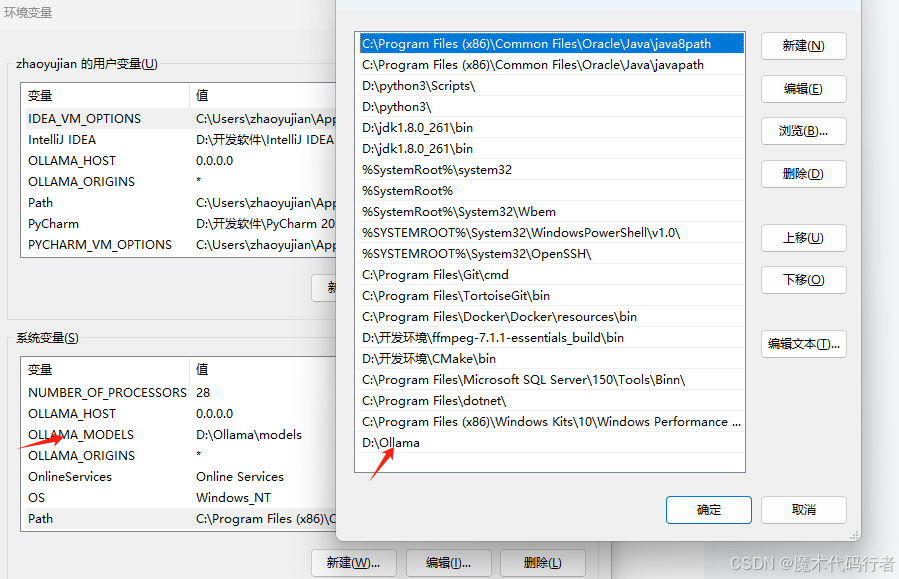
2)文件夹创建好后需要配置一下环境变量,如下图
3)进入安装包的下载目录。打开CMD命令执行一下命令
OllamaSetup.exe /DIR=D:\Ollama
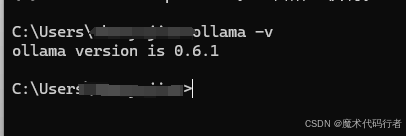
安装完后执行
ollama -v 如下图所示,则代表成功
4)接下来执行命令
ollama run deepseek-r1:1.5b
deepseek-r1:1.5b为模型名称
这时候会进入下载模型的过程,如图

这里下载的是deepseek-r1:7b模型
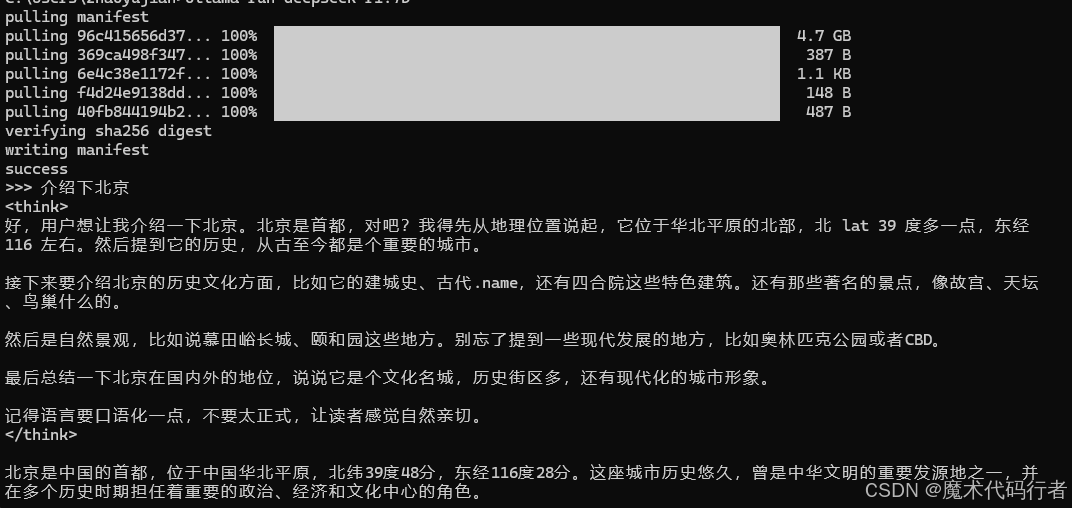
下载好了之后可以在命令行进行提问,到此Ollama+deepseel的环境已经搭建好了
电脑2开始搭建(dify):
一、dify
官网:https://dify.ai/zh
GitHub地址:https://github.com/langgenius/dify
博主是从github上拉取代码
可以下载ZIP包,也可以拉取代码
下载完成后,解压项目,打开项目,找到docker文件夹进入,将.env.example文件改名为.env,并使用记事本或文本工具打开.env,在最后一行加入下面的代码,是加入不是修改蛤
# 启用自定义模型CUSTOM_MODEL_ENABLED=ture# 指定Ollama的API地址(根据部署环境调整IP)OLLAMA_API_BASE_URL=电脑1的IP:11434
2)使用Docker命令进行部署
因为Dify是通过docker来安装的,所以不管你是Linux服务器或者Mac还是Windows,必须要有docker环境。这里安装docker就不再描述了。可以参考以下文章
如何在Linux、Windows、MacOS中安装Docker
在docker文件夹下进入cmd命令框,执行下面命令
docker compose up -d启动后在电脑2的浏览器访问http://localhost/install
初次进入,会让你设置一个admin管理员的账号,根据提示设置即可,然后进入系统。
进入系统后,我们以后就可以在工作室这个页签进行新建空白应用来构建我们的智能体。
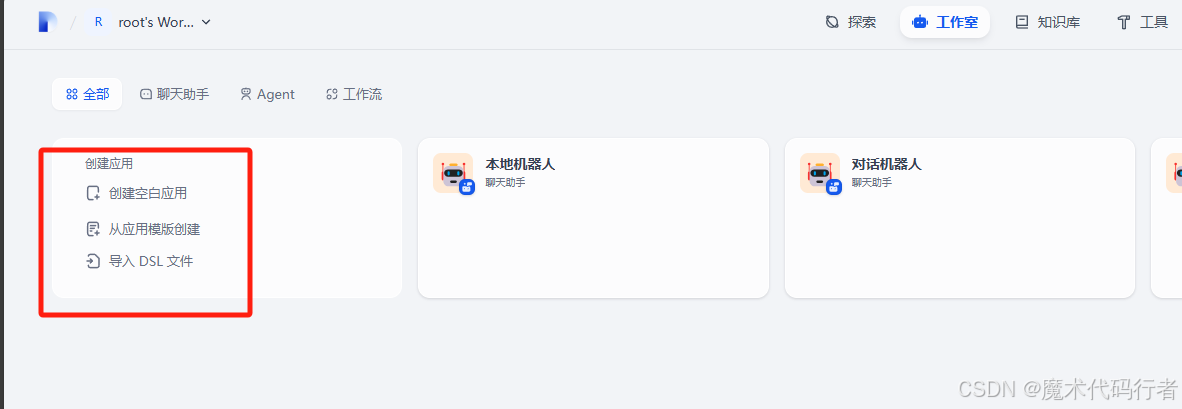
引入电脑1搭建好的Ollama模型,点击右上角的用户头像,找到设置,设置中有个模型供应商,进入后找到Ollama模型插件,点击安装
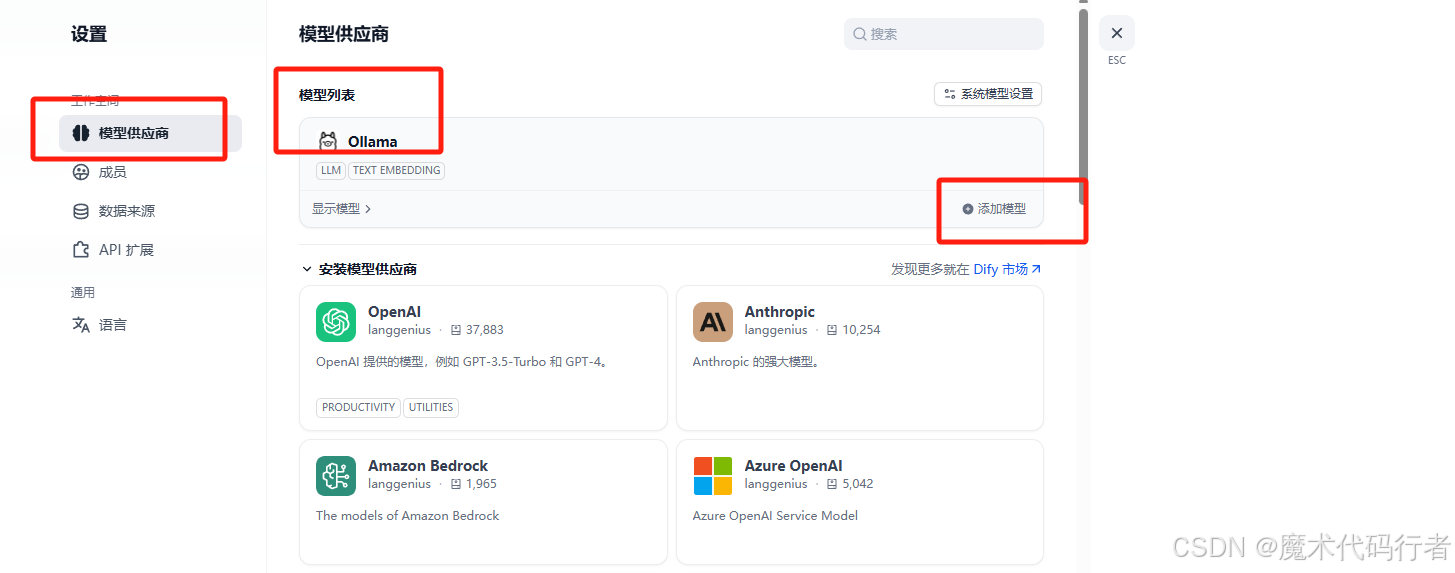
点击添加模型会弹框
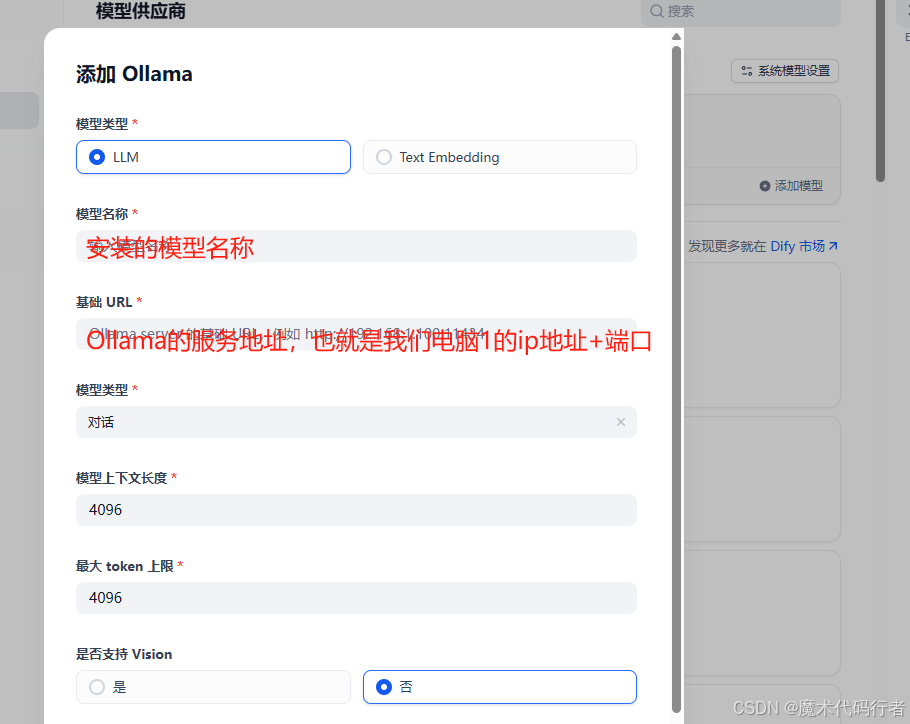
其他可以默认,有需要在变动,添加完了之后点击保存,成功后就可以用这个模型在dify上对话了
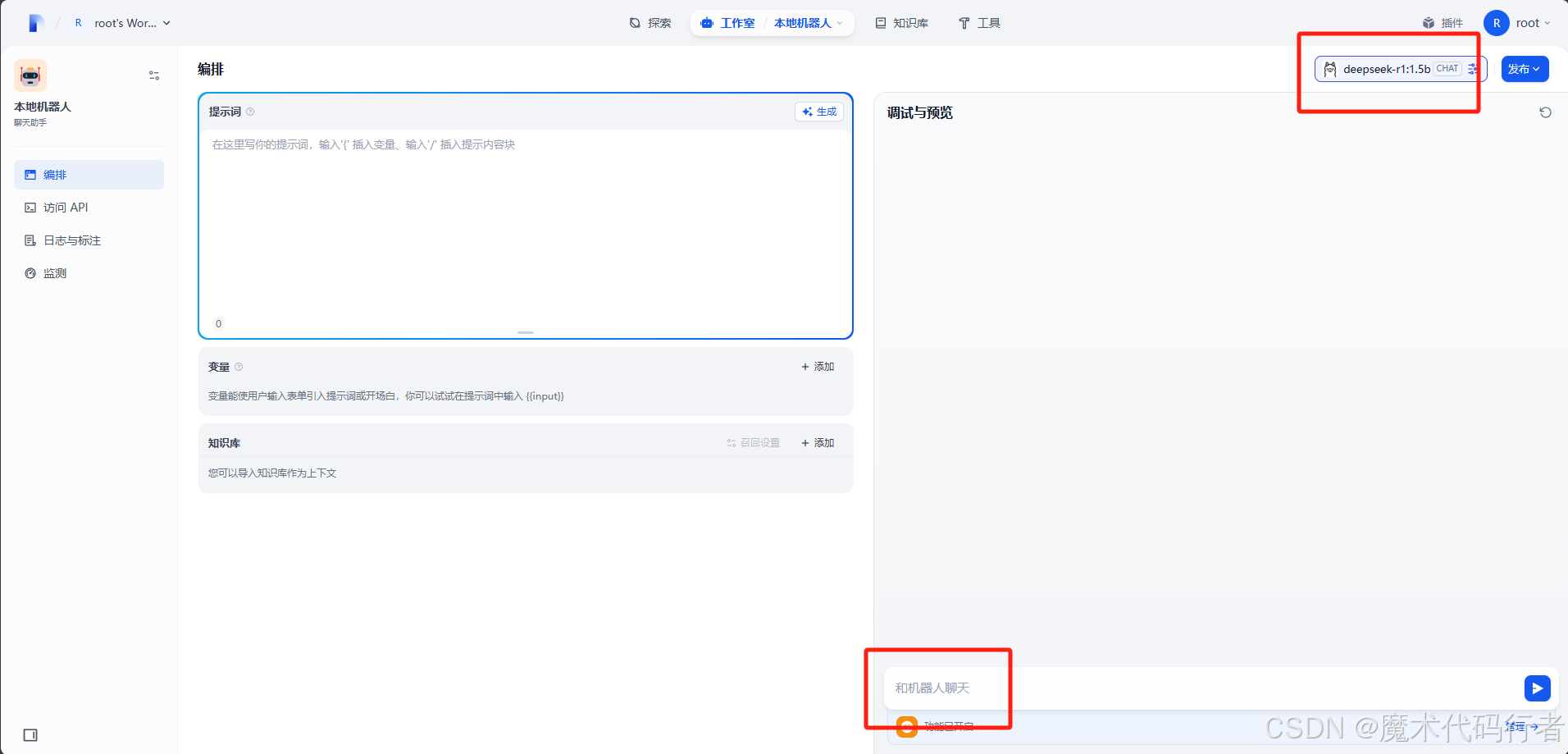
再在电脑一下观察一下GPU的波动,看是否调用的是电脑1的Ollama
有个需要注意的点,Ollama启动后会监听11434端口,局域网的其他电脑想访问可以需要配置下环境变量
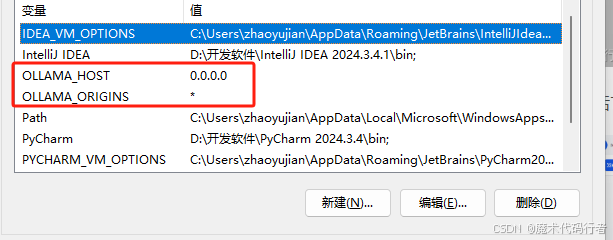
可参考此文章
如果不配置,访问的时候会被拒绝掉,配置完之后可以在电脑2用浏览器访问电脑1ip+11434端口,如下图,出现Ollama is running ,则是访问成功,可放心配置
Ollama相关的环境变量配置信息:
1. OLLAMA_HOST:这个变量定义了Ollama监听的网络接口。通过设置参数值为 0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。
2. OLLAMA_MODELS:这个变量指定了模型镜像的存储路径。通过设置参数值为新模型所在路径,如E:\ollama\models,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。
3. OLLAMA_KEEP_ALIVE:这个变量控制模型在内存中的存活时间。设置参数值为24h可以让模型在内存中保持24小时,提高访问速度。
4. OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置参数值为8080可以将服务端口从默认的11434更改为8080。
5. OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置参数值为4可以让Ollama同时处理两个并发请求。
6. OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置参数值为4可以确保系统资源得到合理分配。
7. OLLAMA_ORIGINS: 允许的源列表,星号*或使用逗号分隔

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)