2025年最牛最全面的AI大模型面试题全套!
目前的Large LM的训练范式还是在大规模语料上做自监督学习,很显然zero-shot性能更好的 decoder-only架构才能更好的利用这些无标注的数据。大模型使用decoder-only架构除了训练效率和工程实现上的优势外,在理论上因为Encoder的双向注意力会存在低秩的问题(指的是,双向注意力在捕捉输入序列的前后文信息时,由于冗余信息和高维度表示的影响,可能导致信息表达不充分或者矩阵过
-
简单介绍⼀下 大模型【LLMs】?
-
目前主流的开源模型体系有哪些?
-
prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?
-
为何现在的大模型大部分是Decoder only结构?
-
大模型LLM的训练目标是什么?
-
涌现能力是啥原因?
-
大模型【LLMs】后⾯跟的 175B、60B、540B等 指什么?
-
⼤模型【LLMs】具有什么优点和缺点?
1.简单介绍⼀下大模型【LLMs】?
解答:大语言模型(Large Language Models,简称LLMs)是一种基于深度学习技术构建的人工智能模型,专门用于处理和生成自然语言文本。它们通过在海量文本数据上进行训练,学习语言的模式、语法、语义和上下文关系,从而能够生成连贯、有意义的文本内容。
2.目前主流的开源模型体系有哪些?
-
Transformer体系:由Google提出的Transformer 模型及其变体,如BERT、GPT 等。
-
PyTorch Lightning:一个基于PyTorch的轻量级深度学习框架,用于快速原型设计和实验。
-
TensorFlow Model Garden:TensorFlow官方提供的一系列预训练模型和模型架构。
-
Hugging Face Transformers:一个流行的开源库,提供了大量预训练模型和工具,用于NLP 任务。
3.prefix Decoder 和 causal Decoder 和 Encoder-Decoder 区别是什么?
Prefix Decoder 采用了预先提供的一部分前缀(可以是一些先前的文本或信息)来引导生成过程。它试图学习如何从给定的前缀生成剩余部分。这样,它并不依赖于完全自回归的方式,而是通过优化利用前缀信息来加速和改进生成。
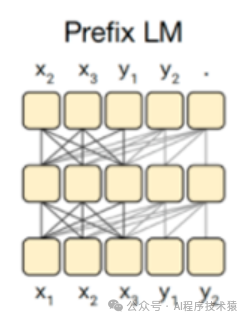
-
注意力机制方式:输入双向注意力,输出单向注意力
-
特点:prefix部分的token互相能看到,属于causal Decoder 和 Encoder-Decoder 折中
-
代表模型:ChatGLM、ChatGLM2、U-PaLM
-
缺点:训练效率低
Causal Decoder,即因果解码器,是一种自回归模型,广泛应用于文本生成任务中。其核心特点在于生成文本时,每个token(词或字符)的生成仅依赖于它之前的token,而无法利用未来的token信息。这种机制确保了生成的文本在时序上保持连贯性
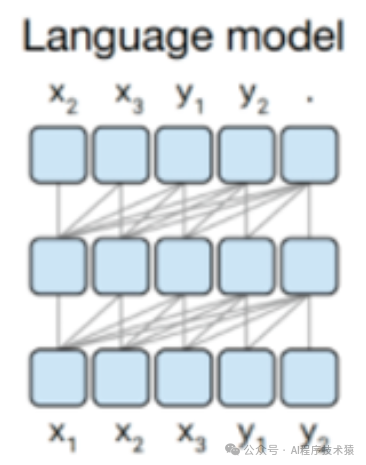
-
注意力机制方式:从左到右的单向注意力
-
特点:自回归语言模型,预训练和下游应用是完全一致的,严格遵守只有后面的token才能看到前面的 token的规则
-
适用任务:文本生成任务效果好
-
优点:训练效率高,zero-shot 能力更强,具有涌现能力
-
代表模型:LLaMA-7B、LLaMa 衍生物
Encoder-Decoder 架构 是一种广泛应用于自然语言处理(NLP)和机器学习领域的神经网络架构,它的核心思想是通过编码器将输入序列转换为语义表示,再通过解码器生成目标序列。这个架构通常由两个主要部分组成:编码器(Encoder)和解码器(Decoder),它们通过一个中间的表示(通常是上下文向量)连接起来。
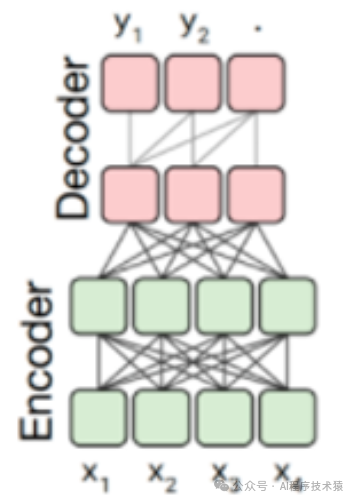
-
注意力机制方式:输入双向注意力,输出单向注意力
-
特点:在输入上采用双向注意力,对问题的编码理解更充分
-
适用任务:在偏理解的 NLP 任务上效果好
-
缺点:在长文本生成任务上效果差,训练效率低
4.为何现在的大模型大部分是Decoder only结构?
因为decoder-only结构模型在没有任何微调数据的情况下,zero-shot的表现能力最好;而encoder decoder则需要在一定量的标注数据上做multitask-finetuning才能够激发最佳性能。
目前的Large LM的训练范式还是在大规模语料上做自监督学习,很显然zero-shot性能更好的 decoder-only架构才能更好的利用这些无标注的数据。大模型使用decoder-only架构除了训练效率和工程实现上的优势外,在理论上因为Encoder的双向注意力会存在低秩的问题(指的是,双向注意力在捕捉输入序列的前后文信息时,由于冗余信息和高维度表示的影响,可能导致信息表达不充分或者矩阵过于简单,从而影响模型的表达能力和性能。为了解决这一问题,研究者们提出了许多改进方案,如矩阵分解方法、改进的注意力机制和位置编码等。),这可能会削弱模型的表达能力。就生成任务而言,引入双向注意力并无实质的好处。
5.大模型LLM的训练目标是什么?
大模型(LLM, Large Language Model)的训练目标主要是通过大量的文本数据来学习语言的结构、语法、语义和知识,以便能够生成、理解和推理人类语言。
6.涌现能力是啥原因?
-
数据量的增加:随着互联⽹的发展和数字化信息的爆炸增⻓,可⽤于训练模型的数据量⼤⼤增加。更多的数据可以提供更丰富、更⼴泛的语⾔知识和语境,使得模型能够更好地理解和⽣成⽂本。
-
计算能⼒的提升:随着计算硬件的发展,特别是图形处理器(GPU)和专⽤的AI芯⽚(如TPU)的出现,计算能⼒⼤幅提升。这使得训练更⼤、更复杂的模型成为可能,从⽽提⾼了模型的性能和涌现能⼒。
-
模型架构的改进:近年来,⼀些新的模型架构被引⼊,如Transformer,它在处理序列数据上表现出⾊。这些新的架构通过引⼊⾃注意⼒机制等技术,使得模型能够更好地捕捉⻓距离的依赖关系和语⾔结构,提⾼了模型的表达能⼒和⽣成能⼒。
-
预训练和微调的⽅法:预训练和微调是⼀种有效的训练策略,可以在⼤规模⽆标签数据上进⾏预训练,然后在特定任务上进⾏微调。这种⽅法可以使模型从⼤规模数据中学习到更丰富的语⾔知识和语义理解,从⽽提⾼模型的涌现能⼒。
7.大模型【LLMs】后⾯跟的 175B、60B、540B等 指什么?
在大模型(LLMs)的上下文中,像 175B、60B、540B 等数字通常指的是 模型中的参数数量,即模型的 总权重数量。

8.⼤模型【LLMs】具有什么优点和缺点?

最后,这份《LLM项目+学习笔记+电子书籍+学习视频》已经整理好,还有完整版的大模型 AI 学习资料,朋友们如果需要可以点个小小的关注+留言000,勉费发给大家【保证100%免费】👇👇

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)