LightRAG 知识图谱+大模型 新SOTA:超越 GraphRAG,效率提升99.98% + 准确率提升8-13% + 多样性提升 20-61% + 更新成本降低 80%
综上,LightRAG在效率和实用性上有明显优势,特别是在处理动态数据和需要快速响应的场景中。这个医学例子帮助我们更好理解这些隐性特征的重要性,因为在医疗领域,信息的准确性和及时性直接关系到患者的生命安全。仅使用低级别检索时,模型过于关注特定实体及其直接关联,无法全面理解复杂查询所需的广泛信息,导致性能下降。它不是简单的信息删减,而是通过发现数据中的结构化模式来实现智能压缩。这种多层次的压缩使Li
LightRAG 知识图谱+大模型 新SOTA:超越 GraphRAG,效率提升99.98% + 准确率提升8-13% + 多样性提升 20-61% + 更新成本降低 80%
论文:LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION
代码:https://github.com/HKUDS/LightRAG
超越 GraphRAG,更强大的 LightRAG
- 相同点:
- 都使用图结构来增强RAG
- 都通过LLM提取实体和关系
- 都试图解决现有RAG系统无法捕捉全局信息的问题
- 关键区别:
检索机制:
- GraphRAG:需要遍历每个社区(community)来检索信息,计算开销大
- LightRAG:使用双层检索(低层找具体实体,高层找抽象主题),检索更高效
动态更新:
- GraphRAG:新增数据时需要重建整个社区结构,成本高
- LightRAG:支持增量更新,无需重建整个图结构,效率高
- 性能指标对比:
检索成本:
- GraphRAG:每个社区报告约1000 tokens,610个社区需61万tokens
- LightRAG:每次检索<100 tokens,只需1次API调用
GraphRAG: 消耗610×1000 tokens
LightRAG: 消耗<100 tokens
规律:图结构+双层检索可大幅降低token消耗
相比GraphRAG节省 99% tokens
更新成本:
- GraphRAG:需要约1399×2×5000 tokens重建社区报告
- LightRAG:只需处理新增实体和关系的tokens
理论:局部更新比全量更新效率高
推导:增量更新应该能降低成本
验证:实验表明节省了 80% 成本
- 优劣势分析:
GraphRAG优势:
- 社区结构可能对某些任务更有帮助
- 结构化程度更高
LightRAG优势:
- 检索效率更高
- 更新成本更低(增量更新,不需要重复建图,在已有图上新增)
- 答案多样性更好
- 建议使用场景:
GraphRAG适合:
- 静态知识库
- 对结构化要求高的场景
- 计算资源充足的情况
LightRAG适合:
- 动态更新频繁的场景
- 需要快速响应的应用
- 计算资源受限的情况
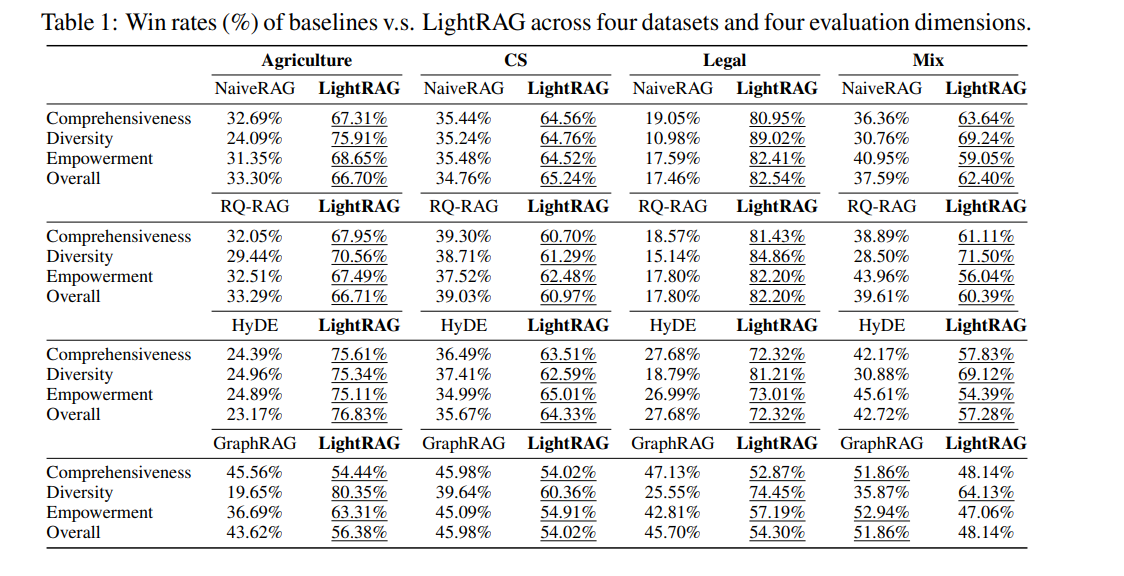
在Legal数据集上:
- vs NaiveRAG: 提升82.54%
- vs RQ-RAG: 提升82.20%
- vs HyDE: 提升72.32%
- vs GraphRAG: 提升54.30%
规律:规模越大,LightRAG优势越明显
综上,LightRAG在效率和实用性上有明显优势,特别是在处理动态数据和需要快速响应的场景中。但在某些特定任务中,GraphRAG的社区结构可能仍有其独特价值。
1. 知识表示模型
- 传统:线性文本块
- 创新:图结构关系
关键理解:知识的本质是关联网络
2. 检索效率模型
- 传统:遍历搜索
- 创新:定向检索
关键理解:效率源于搜索空间压缩
3. 更新机制模型
- 传统:整体更新
- 创新:局部更新
关键理解:变化通常是局部的
选择哪个系统,建议根据具体应用场景的需求来决定:
- 如果更注重效率和成本 → LightRAG
- 如果更注重结构化程度 → GraphRAG
LightRAG 拆解
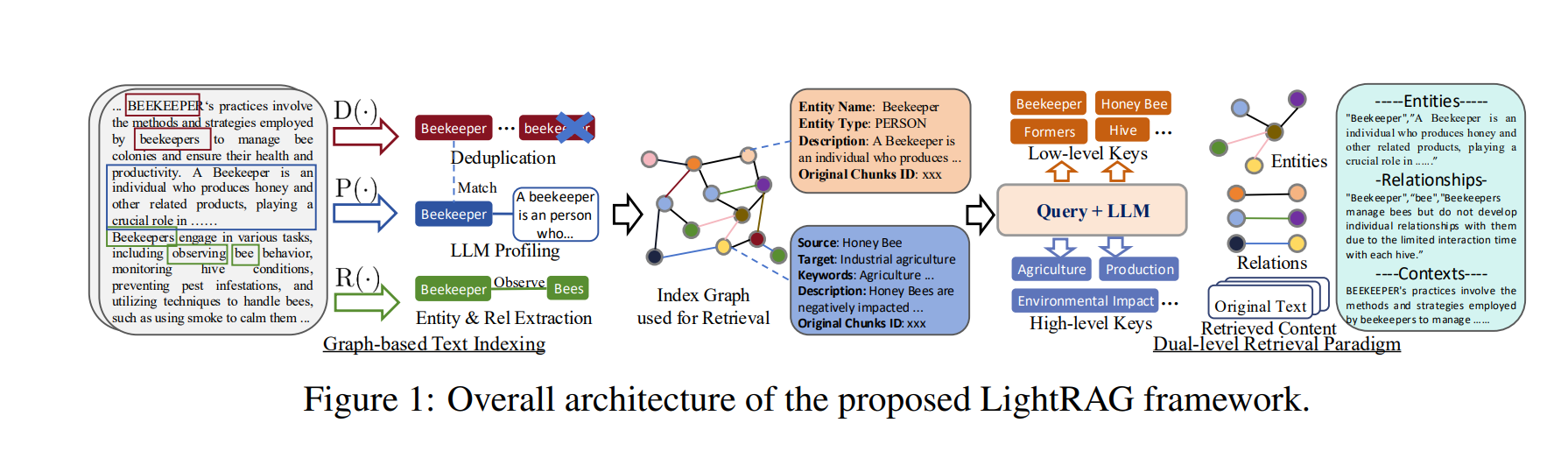
这张图展示了LightRAG框架的整体架构,可以分为三个主要部分:
- 图构建阶段 (Graph-based Text Indexing):
- D(·): 去重操作,合并相似实体
- P(·): LLM编码,生成实体描述
- R(·): 实体和关系提取,识别文本中的实体和关系
- 索引图构建 (Index Graph):
将提取的知识组织成图结构:
- 节点:表示实体(如 Beekeeper, Honey Bee)
- 边:表示关系(如 observe, manage)
- 为每个实体和关系添加描述信息
- 双层检索范式 (Dual-level Retrieval Paradigm):
低层检索:
- 实体级别检索(如 Beekeeper, Hive)
- 直接实体关系
高层检索:
- 主题级别(如 Agriculture, Production)
- 抽象概念关系
图中以养蜂人(Beekeeper)为例,展示了完整处理流程:
- 从原始文本提取实体和关系
- 构建结构化的知识图谱
- 通过双层检索机制回答查询
这种架构的优势是:
- 结构化表示知识
- 高效精准检索
- 保持知识完整性
LightRAG = G(检索模块) + R(生成模块)
检索模块 = 图结构 + 双层检索 + 增量更新
生成模块 = LLM + 上下文整合
检索系统:
- 低层检索(具体实体)
- 高层检索(抽象主题)
- 结果整合
双层检索机制对于模型性能至关重要。
仅使用低级别检索时,模型过于关注特定实体及其直接关联,无法全面理解复杂查询所需的广泛信息,导致性能下降。
仅使用高级别检索则缺乏对具体细节的深入挖掘。
在这两种情况下,模型的回答都不够完整或精准。
结合低级别和高级别检索的双层策略能够平衡信息的广度和深度。
LightRAG的核心压缩规律(发现信息中的关键模式)
- 数据结构压缩规律
传统RAG = 大量文本块 + 检索
LightRAG = 知识图谱(实体+关系) + 双层检索
核心压缩:将冗长文本压缩为结构化图
- 检索模式压缩
GraphRAG: 遍历所有社区 → 高开销
LightRAG: 双层定向检索 → 低开销
- 低层: 直接找实体
- 高层: 直接找主题
核心压缩:将遍历压缩为定向搜索
- 更新机制压缩
传统: 全量更新 = 重建所有
LightRAG: 增量更新 = 只处理新增
核心压缩:将全量压缩为增量
- 查询响应压缩
旧模式:检索→{大量文本块}→生成
新模式:检索→{关键实体+关系}→生成
核心压缩:将冗余信息压缩为核心知识
- 系统架构压缩
传统架构 = 索引 + 检索 + 生成
LightRAG架构 = 图(索引+检索的融合) + 生成
核心压缩:将分离组件压缩为统一结构
核心发现:
- LightRAG通过知识图谱压缩了原始文本
- 通过双层检索压缩了搜索空间
- 通过增量更新压缩了维护成本
- 本质是在保持信息完整性的同时,最大化压缩冗余操作
这种多层次的压缩使LightRAG在效率和性能上都有显著提升。
它不是简单的信息删减,而是通过发现数据中的结构化模式来实现智能压缩。
全面调研
主流RAG系统的特点:
1. 文本分块
- 固定大小切分
- 向量化存储
2. 检索方式
- 向量相似度匹配
- top-k检索
3. 更新机制
- 全量更新
- 周期性更新
LightRAG的创新方案:
1. 知识表示
优势:图结构捕捉实体关系
科学依据:图论更适合表达复杂关系
2. 检索机制
优势:双层检索平衡效率与全面性
科学依据:分层检索降低复杂度
3. 更新策略
优势:增量更新降低成本
科学依据:局部更新理论
传统方案存在的原因:
1. 技术惯性
- 简单实现
- 维护成本低
原因:团队习惯了传统方式
2. 场景限制
- 小规模数据够用
- 更新需求不高
原因:特定场景下传统方案足够
3. 资源约束
- 图结构需要额外开发
- 双层检索需要优化
原因:资源投入和收益权衡
技术选择的权衡:
方案 优势 劣势 适用场景
传统RAG 简单实现 效率低 小规模静态
GraphRAG 结构化好 更新难 中规模静态
LightRAG 效率高+动态 复杂度高 大规模动态
影响因素分析:
1. 规模因素
小规模:传统方案足够
大规模:需要图结构优化
2. 动态程度
静态数据:全量更新可接受
动态数据:必须增量更新
3. 资源投入
有限资源:选择简单方案
充足资源:追求最优方案
- 主流方案局限:
- 效率瓶颈
- 更新困难
- 扩展性差
- LightRAG优势:
- 更高效的检索
- 更灵活的更新
- 更好的扩展性
- 选择建议:
if 大规模动态数据:
选择 LightRAG
elif 结构化需求高:
选择 GraphRAG
else:
选择 传统RAG
这种综合调研帮助我们:
7. 理解不同方案的优劣
8. 明确技术选择的依据
9. 认识系统演进的规律
10. 预见未来发展方向
隐性特征
缺乏上下文感知,导致无法维持多实体间连贯性。
LightRAG
├── 知识图谱知识索引(因为需要结构化表示知识)
│ ├── 实体提取
│ ├── 关系构建
│ └── 描述生成
└── 双层检索范式(因为需要平衡检索效率和全面性)
├── 低层检索
│ └── 实体匹配
└── 高层检索
└── 主题匹配
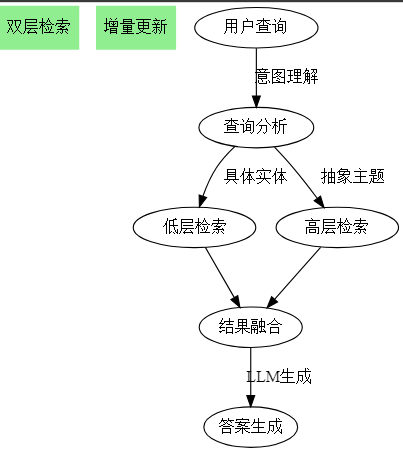
1. 查询意图特征的来龙去脉
问题起源:
医生和患者的问题常有不同层次:
- 具体查询:"阿司匹林的推荐剂量是多少?"
- 抽象查询:"高血压如何影响心脏健康?"
- 关系查询:"糖尿病和心脏病有什么关联?"
LightRAG如何处理:
-
双层检索机制
- 低层:处理具体实体查询
- 高层:处理抽象主题查询
-
图结构支持
- 实体节点:支持具体查询
- 关系边:支持关联查询
- 主题聚类:支持抽象查询
为什么需要识别意图:
同样查"心脏病":
- 患者想知道:日常预防建议
- 医生想知道:最新治疗方案
- 研究者想知道:分子机制研究
不同意图需要不同检索策略
例如医学查询:
"心脏病和糖尿病有什么关系?"
→ LightRAG处理流程:
1. 识别为关系查询
2. 在图中定位两个疾病节点
3. 分析节点间的关系路径
4. 综合生成答案
具体执行步骤:
例子:"二型糖尿病会增加心脏病风险吗?"
1. 查询类型识别
输入:"二型糖尿病会增加心脏病风险吗?"
处理:分析关键词"增加风险"表示因果关系查询
输出:关系型查询
2. 意图理解
输入:关系型查询
处理:需要找出糖尿病→心脏病的致病机制
输出:需要检索疾病关联机制
3. 检索策略选择
输入:疾病关联机制需求
处理:选择医学文献+临床研究路径
输出:优先检索循证医学证据
2. 知识关联度特征的来龙去脉
问题起源:
医学知识关联复杂度不同:
强关联:
- 高血压直接导致心脏病
- 病因直接导致症状
中等关联:
- 生活方式影响疾病
- 药物间的相互作用
弱关联:
- 一般健康建议
- 统计相关性
LightRAG如何处理:
-
图结构表示
- 节点权重:表示实体重要性
- 边权重:表示关系强度
- 路径分析:发现隐含关联
-
关联度计算
- 直接关联:一跳可达
- 间接关联:多跳路径
- 全面关联:多路径融合
为什么需要评估关联:
查询"头痛"时:
- 重要:脑瘤、脑出血(需紧急关注)
- 次要:感冒、疲劳(常见原因)
- 远期:生活习惯(预防建议)
具体执行步骤:
例子:查询"高血压并发症"
1. 关联强度计算
输入:高血压与各种疾病
处理:分析致病机制强度
输出:心脏病(强)、肾病(强)、视网膜病变(中)
2. 重要性评估
输入:并发症列表
处理:评估致死率、致残率
输出:心脏病(极重要)、肾病(很重要)
3. 优先级排序
输入:并发症评分
处理:按危险程度排序
输出:先检索心血管并发症
3. 更新影响特征的来龙去脉
问题起源:
医学知识在不断更新:
- 新研究发现
- 治疗方案更新
- 药物指南变化
为什么需要评估影响:
例如:某降压药被发现新副作用
影响范围:
- 直接:用药方案
- 连锁:相关药物选择
- 延伸:治疗指南更新
例如医学知识更新:
"新发现某药物副作用"
→ LightRAG处理流程:
1. 定位药物节点
2. 分析受影响的治疗方案
3. 更新相关知识和建议
具体执行步骤:
例子:新冠病毒新变种发现
1. 变更范围评估
输入:新变种特性
处理:分析影响范围
输出:传播性、症状、疫苗效果都需更新
2. 影响传播分析
输入:受影响领域
处理:追踪连锁反应
- 防控措施调整
- 治疗方案修改
- 疫苗策略更新
3. 更新优先级确定
输入:所有需更新内容
处理:按紧急程度排序
输出:先更新传播风险和防控建议
医学场景特点:
- 信息准确性至关重要
- 更新必须及时有序
- 关联性需要严格验证
- 影响评估需要谨慎
这种分析方法确保:
- 医学知识准确传递
- 重要信息优先处理
- 更新过程有序进行
- 知识体系保持一致
这个医学例子帮助我们更好理解这些隐性特征的重要性,因为在医疗领域,信息的准确性和及时性直接关系到患者的生命安全。
不适合图结构表示的数据
让我分析特定领域知识不适合图表示的情况:
- 时序性强的数据
例如:金融交易数据
原因:
- 时间连续性难以用离散节点表示
- 事件顺序关键但难以在图中优化
- 时间窗口分析不直观
更适合的表示:
- 时间序列数据库
- 流处理系统
- 高度结构化的数格式
例如:科学实验数据、传感器数据
原因:
- 数据间关系简单且固定
- 主要是数值计算和统计分析
- 图结构增加了不必要的复杂度
更适合的表示:
- 关系型数据库
- 多维数组
- 连续变化的过程数据
例如:化学反应过程、物理仿真
原因:
- 状态连续变化难以离散化
- 过程动态性难以用静态关系表示
- 微分方程描述更自然
更适合的表示:
- 数学模型
- 状态空间
- 深层语义理解场景
例如:诗歌、文学作品
原因:
- 含义高度抽象和模糊
- 上下文依赖性强
- 情感和意境难以图形化
更适合的表示:
- 向量嵌入
- 语义网络
- 高度专业化的领域知识
例如:法律条文解释
原因:
- 逻辑关系复杂且模糊
- 需要大量背景知识
- 解释空间难以固化
更适合的表示:
- 规则系统
- 专家系统
因此,LightRAG可能需要:
- 支持混合数据表示
- 提供领域适配接口
- 允许自定义知识组织方式
- 集成多种存储后端
这提醒我们在设计RAG系统时:
5. 不能过度依赖单一表示方式
6. 要考虑领域特殊性
7. 需要提供灵活的扩展机制
8. 可能需要混合架构设计
医疗领域的几个场景
- 生理信号数据
例如:
- 心电图(ECG)数据
- 脑电图(EEG)数据
- 血压监测数据
原因:
- 连续时间序列特性
- 需要波形分析
- 关注模式变化
更适合:
- 时序数据库
- 信号处理系统
- 医学影像数据
例如:
- CT扫描图像
- MRI影像
- X光片
原因:
- 空间结构复杂
- 需要像素级分析
- 依赖视觉特征
更适合:
- 图像数据库
- 计算机视觉系统
- 手术过程数据
例如:
- 手术操作流程
- 器械使用记录
- 生命体征变化
原因:
- 高度时序依赖
- 步骤严格有序
- 状态持续变化
更适合:
- 流程管理系统
- 实时监控系统
教育领域的几个场景
- 学习进度数据
例如:
- 课程完成度
- 知识掌握程度
- 学习时长统计
原因:
- 进度连续性强
- 需要趋势分析
- 重视变化率
更适合:
- 进度跟踪系统
- 学习分析平台
- 考试成绩数据
例如:
- 试题得分
- 错题分布
- 成绩趋势
原因:
- 数值计算为主
- 统计分析需求强
- 排名比较频繁
更适合:
- 关系型数据库
- 统计分析系统
- 课堂互动数据
例如:
- 实时提问记录
- 师生互动过程
- 课堂参与度
原因:
- 时效性要求高
- 互动过程复杂
- 需要即时响应
更适合:
- 实时通信系统
- 流处理平台
基于图的方法和双层检索范式来处理图结构信息,对比微软GraphRAG图神经网络
与图神经网络相比,基于图的方法和双层检索范式的特点和优势在于:
- 能够更细致地理解和检索信息,从多跳子图中提取整体信息,提高了模型在处理跨多个文档的复杂查询时的能力。
- 优化了检索性能,图生成的键值数据结构经过改进,能够迅速且准确地获取所需信息,优于传统方法中的嵌入匹配和低效的片段检索技术。
- 通过双层检索范式,既能够精确检索到与特定实体相关的详细信息,又能获取更广泛主题的相关知识,进而确保系统能够为用户提供全面且相关的回答,满足不同用户的需求。
图神经网络(GNN)的优势:
- 能够有效地学习图数据中的特征,捕捉图结构中的复杂关系。
- 擅长处理涉及复杂关系推理、总结性问题和多跳问题的场景,例如在智能问诊中,能根据患者的症状和病史推断可能的疾病并提供治疗方案;在药物合成方面,可将各种分子化合物的结构、特征映射到知识图谱中,帮助发现有益的大分子结构。
基于图的方法(如LightRAG中的图基文本索引)的优势:
- 能够精准捕捉实体间复杂依赖关系,提升信息理解的全面性。
- 从多跳子图中提取全局信息,增强处理复杂查询的能力,特别是那些跨越多个文档块的查询。
- 图中派生的键-值数据结构针对快速和精确检索进行了优化,提供了优于传统嵌入匹配方法和低效块遍历技术的解决方案。
双层检索范式的优势:
- 同时处理具体与抽象查询,确保响应的相关性与丰富性。
- 能够灵活运用局部和全局关键词,优化搜索流程,进而提升结果的相关性。
- 可以获取特定文档片段及其复杂的相互关系,低层检索关注特定实体及其相关属性或关系,高层检索处理更广泛的主题和全局概念。
在医疗问诊方面,图神经网络可用于推断疾病和提供治疗方案;基于图的方法能全面理解患者相关信息;双层检索范式可同时考虑具体症状和整体病情。
在医疗方案制定中,图神经网络有助于分析药物分子间关系;基于图的方法能全面考虑各种因素;双层检索范式可兼顾具体需求和整体规划。
在医疗健康管理里,图神经网络可处理复杂的健康数据关系;基于图的方法全面捕捉健康信息;双层检索范式能满足具体健康管理需求和宏观健康规划。
在知识检索领域,图神经网络适合处理具有复杂关系的数据;基于图的方法提升检索的全面性和精确性;双层检索范式可应对多样化的查询需求。
LightRAG 部署
安装
https://github.com/HKUDS/LightRAG.git
cd LightRAG
pip install -e .
创建工作目录
mkdir test
cd test
curl https://raw.githubusercontent.com/gusye1234/nano-
graphrag/main/tests/mock_data.txt > ./book.txt
初始化
# 导入操作系统相关的功能模块
import os
# 导入LightRAG核心类和查询参数类
from lightrag import LightRAG, QueryParam
# 导入各种LLM模型的完成函数
from lightrag.llm import (
gpt_4o_mini_complete, # GPT-4迷你版完成函数
gpt_4o_complete, # GPT-4完成函数
openai_complete_if_cache, # 带缓存的OpenAI完成函数
openai_embedding # OpenAI的嵌入函数
)
# 导入嵌入函数工具类
from lightrag.utils import EmbeddingFunc
# 导入数值计算库
import numpy as np
# 导入异步嵌套支持库
import nest_asyncio
# 应用nest_asyncio来支持异步操作的嵌套执行
nest_asyncio.apply()
# 设置工作目录路径
WORKING_DIR = "./test"
# 如果工作目录不存在,则创建该目录
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
# 配置LLM模型函数,使用通义千问plus模型
async def llm_model_func(prompt, system_prompt=None, history_messages=[], **kwargs) -> str:
"""
定义异步LLM模型函数
:param prompt: 提示词
:param system_prompt: 系统提示词
:param history_messages: 历史消息列表
:param kwargs: 其他参数
:return: 生成的文本
"""
return await openai_complete_if_cache(
model="qwen-plus", # 使用通义千问plus模型
prompt=prompt, # 传入提示词
system_prompt=system_prompt, # 传入系统提示词
history_messages=history_messages,# 传入历史消息
api_key="sk-0...0c9f0c2", # API密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云API基础URL
**kwargs # 其他参数
)
# 配置文本嵌入函数
async def embedding_func(texts: list[str]) -> np.ndarray:
"""
定义异步嵌入函数
:param texts: 文本列表
:return: 嵌入向量数组
"""
return await openai_embedding(
texts, # 输入文本列表
model="text-embedding-v2", # 使用text-embedding-v2模型
api_key="sk-025.....fc0c9f0c2", # API密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云API基础URL
)
# 初始化LightRAG实例
# 注意:embedding_batch_num不要超过API提供商的并发限制
# embedding_dim必须匹配模型维度(text-embedding-v2模型为1536维)
rag = LightRAG(
working_dir=WORKING_DIR, # 设置工作目录
llm_model_func=llm_model_func, # 设置LLM模型函数
embedding_func=EmbeddingFunc( # 配置嵌入函数
embedding_dim=1536, # 嵌入向量维度
max_token_size=8192, # 最大token数量
func=embedding_func # 嵌入函数实现
),
embedding_batch_num=24 # 嵌入批处理数量
)
# 初始化并加载内容
with open("/root/autodl-tmp/LightRAG/test/book.txt") as f: # 打开文本文件
rag.insert(f.read()) # 将文件内容插入到RAG系统中
提问
提问方式包括naive,local,global,hybrid
- naive(朴素搜索):最基本的搜索方式,直接匹配文本
- local(局部搜索):在特定上下文范围内进行搜索,精确度较高
- global(全局搜索):在整个文档范围内搜索,覆盖面较广
- hybrid(混合搜索):结合局部和全局搜索的优点,通常能得到最平衡的结果
# 执行朴素搜索模式的查询
# naive模式直接使用完整文本进行匹配,不进行特殊的相似度计算
print(
rag.query(
"What are the top themes in this story?", # 查询问题:询问故事的主要主题
param=QueryParam(mode="naive") # 设置查询参数为朴素搜索模式
)
)
# 执行局部搜索模式的查询
# local模式在局部上下文中搜索相关内容,适合精确定位
print(
rag.query(
"What are the top themes in this story?", # 查询问题:询问故事的主要主题
param=QueryParam(mode="local") # 设置查询参数为局部搜索模式
)
)
# 执行全局搜索模式的查询
# global模式会在整个文档范围内进行搜索,适合寻找广泛的主题关联
print(
rag.query(
"What are the top themes in this story?", # 查询问题:询问故事的主要主题
param=QueryParam(mode="global") # 设置查询参数为全局搜索模式
)
)
# 执行混合搜索模式的查询
# hybrid模式结合了局部和全局搜索的优点,通常能获得更全面的结果
print(
rag.query(
"What are the top themes in this story?", # 查询问题:询问故事的主要主题
param=QueryParam(mode="hybrid") # 设置查询参数为混合搜索模式
)
)

如果要换自己的文档:
- 新建一个 test 文件夹(名字随意)
- 把你的文档放 刚创建文件 目录下
- 然后步骤三执行
懵逼的是,运行的还是 book.txt(原案例)。
后来,发现得把 test 文件夹都删除,再把进程关了,把jupyter都关掉。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 15
15 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)