大模型微调---QLora微调实战
LoRA是一种参数高效的微调技术,其原理可以参考Lora原理与实战这里我们着重讲一下QLoraQLora在LoRA:j结合了分位数量化和分块量化的4位标准浮点数量化双重量化:通过量化量化常量来节省内存。分⻚优化器:使用CPU内存代替GPU显存保存部分梯度参数因此我们通过peft框架实现QLora,只要开启上面三个机制就可以在⼤模型训练过程中,量化是⼀种降低模型计算复杂度和存储需求的技术。
一、前言
LoRA是一种参数高效的微调技术,其原理可以参考Lora原理与实战
这里我们着重讲一下QLora,QLora在LoRA的基础上增加了以下内容:
- 4-bit NormalFloat:j结合了分位数量化和分块量化的4位标准浮点数量化
- 双重量化:通过量化量化常量来节省内存。
- 分⻚优化器:使用
CPU内存代替GPU显存保存部分梯度参数
因此我们通过peft框架实现QLora,只要开启上面三个机制就可以
在⼤模型训练过程中,量化是⼀种降低模型计算复杂度和存储需求的技术。量化的核⼼思想是将模型的权重和激活值从⾼精度表示(如32位浮点数)转换为低精度表示(如8位整数),从⽽减少计算和内存使⽤,同时尽量保持模型性能。
对于上面三个机制的原理和内容可以参考以下文章:
QLoRA原理
QLoRA原理
二、LoRA实战
我们使用huggingface的 pert库来简单使用QLoRA
预训练模型与分词模型——Qwen/Qwen2.5-0.5B-Instruct
数据集——lyuricky/alpaca_data_zh_51k
2.1、下载模型到本地
# 下载数据集
dataset_file = load_dataset("lyuricky/alpaca_data_zh_51k", split="train", cache_dir="./data/alpaca_data")
ds = load_dataset("./data/alpaca_data", split="train")
# 下载分词模型
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
# Save the tokenizer to a local directory
tokenizer.save_pretrained("./local_tokenizer_model")
#下载与训练模型
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path="Qwen/Qwen2.5-0.5B-Instruct", # 下载模型的路径
torch_dtype="auto",
low_cpu_mem_usage=True,
cache_dir="./local_model_cache" # 指定本地缓存目录
)
2.2、加载模型与数据集
#加载分词模型
tokenizer_model = AutoTokenizer.from_pretrained("../../local_tokenizer_model")
# 加载数据集
ds = load_dataset("../../data/alpaca_data", split="train[:10%]")
# 量化配置
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True, # 开启双重量化
bnb_4bit_compute_dtype=torch.bfloat16,
)
# 加载量化后的模型
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path="../../local_llm_model/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775",
low_cpu_mem_usage=True,
torch_dtype=torch.half, # 以半精度加载
device_map="cuda:0",
quantization_config=quantization_config
)
2.3、处理数据
"""
并将其转换成适合用于模型训练的输入格式。具体来说,
它将原始的输入数据(如用户指令、用户输入、助手输出等)转换为模型所需的格式,
包括 input_ids、attention_mask 和 labels。
"""
def process_func(example, tokenizer=tokenizer_model):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
if example["output"] is not None:
response = tokenizer(example["output"] + tokenizer.eos_token)
else:
return
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# 分词
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)

2.4、QLoRA微调
这里我们只要配置一下就可以使用QLoRA,
# lora
config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules= ['q_proj', 'k_proj','v_proj'])
target_modules这个参数指定了要应用 LoRA技术的模块。这些模块通常是模型中用于计算注意力权重的部分,
加载peft配置
peft_model = get_peft_model(model, config)
print(peft_model.print_trainable_parameters())

可以看到要训练的模型相比较原来的全量模型要少很多
2.5、训练参数配置
主要用于QLoRA的参数是optim="paged_adamw_32bit" ,开启CPU分页优化
# 配置模型参数
args = TrainingArguments(
output_dir="chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1,
save_strategy='epoch',
optim="paged_adamw_32bit" # 开启分页优化 用于QLoRA
)
2.6、开始训练
# 创建训练器
trainer = Trainer(
args=args,
model=model,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer_model, padding=True )
)
# 开始训练
trainer.train()
可以看到 ,损失有所下降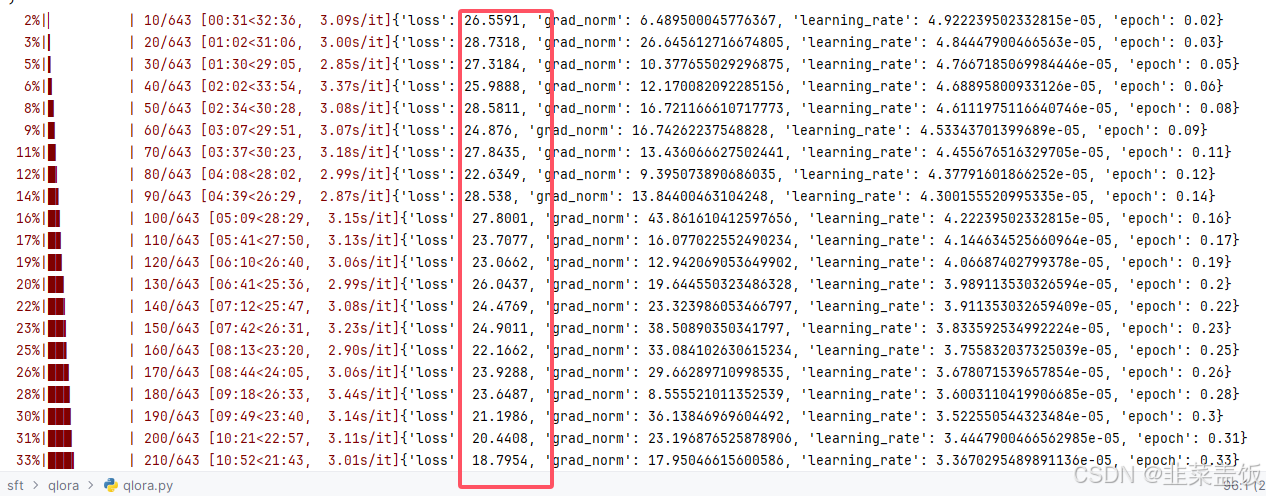
同时可以看到lora作用的层以及量化的4bit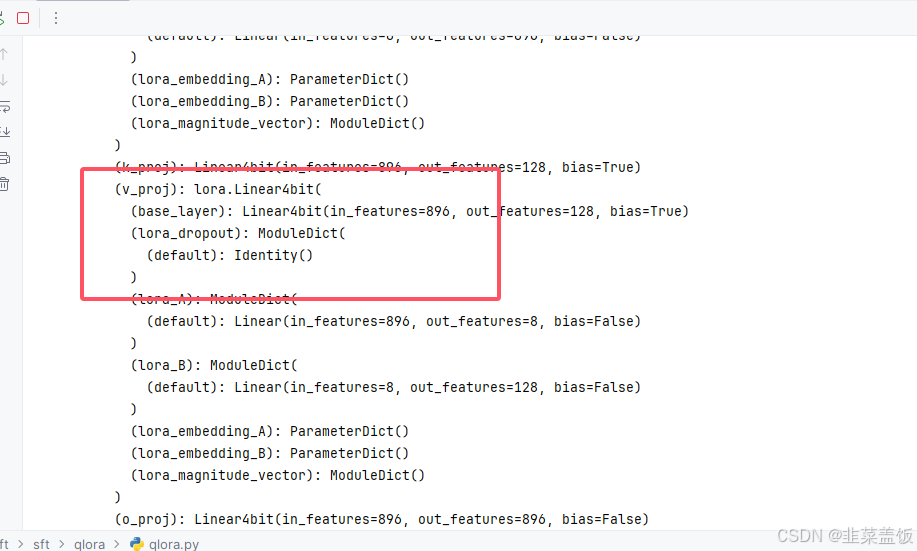
三、模型评估
加载基础模型输出对比测试
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer_model = AutoTokenizer.from_pretrained("../../local_tokenizer_model")
base_model = AutoModelForCausalLM.from_pretrained(
"../../local_llm_model/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775", low_cpu_mem_usage=True)
# 构建prompt
ipt = "Human: {}\n{}".format("我们如何在日常生活中减少用水?", "").strip() + "\n\nAssistant: "
pipe = pipeline("text-generation", model=base_model , tokenizer=tokenizer_model)
output = pipe(ipt, max_length=256, do_sample=False, truncation=True)
print(output)
输出结果
加载基础模型和LoRA模型进行合并,输出测试
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# 基础模型
model = AutoModelForCausalLM.from_pretrained(
"../../local_llm_model/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775", low_cpu_mem_usage=True)
# 在基础模型上加载LoRA模型
peft_model = PeftModel.from_pretrained(model=model, model_id="./chatbot/checkpoint-500")
# 将基础模型和Lora模型合并
peft_model.merge_and_unload()
peft_model = peft_model.cuda()
#
#加载分词模型
tokenizer_model = AutoTokenizer.from_pretrained("../../local_tokenizer_model")
ipt = tokenizer_model("Human: {}\n{}".format("我们如何在日常生活中减少用水?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(
peft_model.device)
print(tokenizer_model.decode(peft_model.generate(**ipt, max_length=128, do_sample=False)[0], skip_special_tokens=True))
输出结果:
可见我们微调后的模型和基础模型的差异
四、完整训练代码
import torch
from datasets import load_dataset
from peft import PromptTuningConfig, TaskType, PromptTuningInit, get_peft_model, PeftModel, PromptEncoderConfig, \
PromptEncoderReparameterizationType, PrefixTuningConfig, LoraConfig
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoModelForCausalLM, TrainingArguments, \
DataCollatorForSeq2Seq, Trainer, BitsAndBytesConfig
# 下载数据集
# dataset_file = load_dataset("lyuricky/alpaca_data_zh_51k", split="train", cache_dir="./data/alpaca_data")
# ds = load_dataset("./data/alpaca_data", split="train")
# print(ds[0])
# 下载分词模型
# tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
# Save the tokenizer to a local directory
# tokenizer.save_pretrained("./local_tokenizer_model")
#下载与训练模型
# model = AutoModelForCausalLM.from_pretrained(
# pretrained_model_name_or_path="Qwen/Qwen2.5-0.5B-Instruct", # 下载模型的路径
# torch_dtype="auto",
# low_cpu_mem_usage=True,
# cache_dir="./local_model_cache" # 指定本地缓存目录
# )
#加载分词模型
tokenizer_model = AutoTokenizer.from_pretrained("../../local_tokenizer_model")
# 加载数据集
ds = load_dataset("../../data/alpaca_data", split="train[:10%]")
# 量化配置
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True, # 开启双重量化
bnb_4bit_compute_dtype=torch.bfloat16,
)
# 加载量化后的模型
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path="../../local_llm_model/models--Qwen--Qwen2.5-0.5B-Instruct/snapshots/7ae557604adf67be50417f59c2c2f167def9a775",
low_cpu_mem_usage=True,
torch_dtype=torch.half, # 以半精度加载
device_map="cuda:0",
quantization_config=quantization_config
)
for name,param in model.named_parameters():
print(name)
# 处理数据
"""
并将其转换成适合用于模型训练的输入格式。具体来说,
它将原始的输入数据(如用户指令、用户输入、助手输出等)转换为模型所需的格式,
包括 input_ids、attention_mask 和 labels。
"""
def process_func(example, tokenizer=tokenizer_model):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer("\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
if example["output"] is not None:
response = tokenizer(example["output"] + tokenizer.eos_token)
else:
return
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# 分词
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
# lora
config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules= ['q_proj', 'v_proj'])
peft_model = get_peft_model(model, config)
print(peft_model.print_trainable_parameters())
print(model) #加入了LoRA后的模型结构。
# 训练参数
args = TrainingArguments(
output_dir="chatbot",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=10,
num_train_epochs=1,
save_strategy='epoch',
optim="paged_adamw_32bit" # 开启分页优化
)
# 创建训练器
trainer = Trainer(model=peft_model, args=args, train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer_model, padding=True))
# 开始训练
trainer.train()

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)