告别手工!多款发票识别大模型测评,哪家最懂你?
在金税四期全面数字化的电子发票推广之前。金税三期主要提倡的是“以票管税”,不管是进项发票还是销项发票,市面上流转的更多的是发票的票据信息(包括试点的电子发票)。各种票据、发票五花八门,这样就会导致财务工作者工作量巨大。我们将以上测试结果整理到EXCEL 表格中,对比了一下数据识别的准确性。目前绝大部分模型都能较好的识别出发票票面信息。尤其是国内模型在中文识别上确实比国外模型识别率更准。目前本次测评
多模态大模型是一种集成了多种不同类型数据处理能力的大型神经网络模型,能够同时处理和理解文本、图像、音频、视频等多种数据模态。
这样的特点天然就具备很多场景的使用。今天给大家带来多模态大模型在财税应用领域实战。本期给大家测评一下目前市面上的主流大模型对发票识别准确性方面的一个测评,为后期我们在开源闭源多模态大模型财税应用领域模型选择上作为重要的参考依据。下面给大家介绍一下项目测评过程。
1.多模态大模型评测榜
首先我们访问opencompass网站(https://rank.opencompass.org.cn/home)
说明:opencompass一个大型语言模型的官方排名平台,它基于OpenCompass的评估规则来评价和发布领先的大型模型排名。该平台特别关注于提供一个公正、透明的评估环境,确保所有参与的模型都能在相同的条件下被评估。
CompassRank 评测榜单中左边是大语言模型月度榜单,右边是我们今天要将的多模态模型月度榜单。点击右边多模态模型月度榜单可以看到详细的多模态月度榜单。
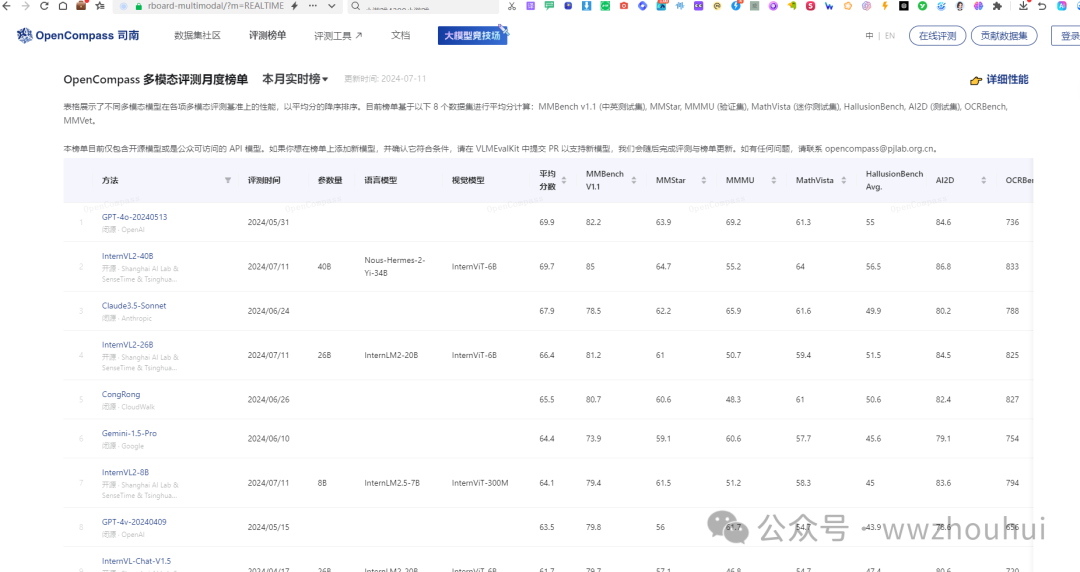
从上面的图中我们可以通过评测时间、参数量、语言模型、视觉模型、平均分数、MMBench V1.1、MMStar、MMMU、MathVista、HallusionBench Avg、AI2D、OCRBench、MMVet等多项指标详细指标分数。那么对于普通人来说大家只要关心平均分数即可。目前综合排名第一的是GPT-4o这个模型。
这个测评平台我们就不详细展开了。
2.测评方法
因为考虑到多模态大模型在财税领域的实际使用,所以我光看上面综合排名是不够的。下面我们介绍一下本次测评的方法。
背景介绍
在金税四期全面数字化的电子发票推广之前。金税三期主要提倡的是“以票管税”,不管是进项发票还是销项发票,市面上流转的更多的是发票的票据信息(包括试点的电子发票)。各种票据、发票五花八门,这样就会导致财务工作者工作量巨大。
测试目标
我们手上有一张电子发票(不是全面数字化的电子发票开具的发票),我们需要通过多模态大模型识别发票票面信息将发票票面信息提取出来形成标准格式化的数据。
发票票面信息如下:

接下来我们需要通过大模型多模态识别技术将票面信息识别出来,变成标准规则的数据。数据格式如下
{
"机器编号": "499098321974",
"发票代码": "011002200911",
"发票号码": "69453658",
"开票日期": "2023年01月06日",
"校 验 码": "11092 55849 13734 18748",
"购买方名称": "哈尔滨所以然信息技术有限公司",
"购买方纳税人识别号": "91230109MABT7KBC4M",
"购买方地址、电话": "6 8 + 1 6 0 0 2 6 - 4 5 9 0 4 * 2 < + 3 + 1 5 5 0 3 > 2",
"开户行及账号": "9 8 * 2 / * - * 4 8 0 1 4 5 + - 1 9 * 0 9 1 7 - 1 * 6 1",
"货物或应税劳务、服务名称": "*信息技术服务*技术服务费",
"规格型号": "",
"单 位": "",
"数 量": "1",
"单 价": "248.11",
"金 额": "248.11",
"税率": "6%",
"税 额": "14.89",
"价税合计(大写)": "贰佰陆拾叁元整",
"价税合计(小写)": "¥263.00",
"销售方名称": "北京度友科技有限公司",
"销售方纳税人识别号": "91110108MA01WFY0X6",
"销售方地址、电话": "北京市海淀区上地东路1号院4号楼2层221室 010-59928888",
"开户行及账号": "招商银行股份有限公司北京双榆树支行110943531310301",
"备注": "230106163474406331",
"收款人": "段欣冉",
"复核": "张会珍",
"开票人": "赵金荣"
}
我们将以上标准json格式的数据保存到结构化数据表里面。后期我们就可以用基于结构化数据做数据统计、报表分析等一系列工作了。那么我们就可以利用大模型多模态技术(模型多模态识别+推理能力)将非结构化的PDF、图片、WORD等信息转换成结构化的数据格式存储到数据库二维表中。
测试步骤
我们需要在各大模型提供的网页版网站中上传PDF或者PDF转换成图片上传到模型对话聊天窗口中,然后输入我们需要它返回的格式的提示词。下面我们以kimi为案例给大家讲解一下。
登录KIMI网站
https://kimi.moonshot.cn/
使用KIMI 实现发票识别
进入KIMI 聊天对话窗口界面。
我们点击文件上传按钮。

在文件弹出对话框中我们输入上传PDF文件

记下来我们聊天窗口中输入:
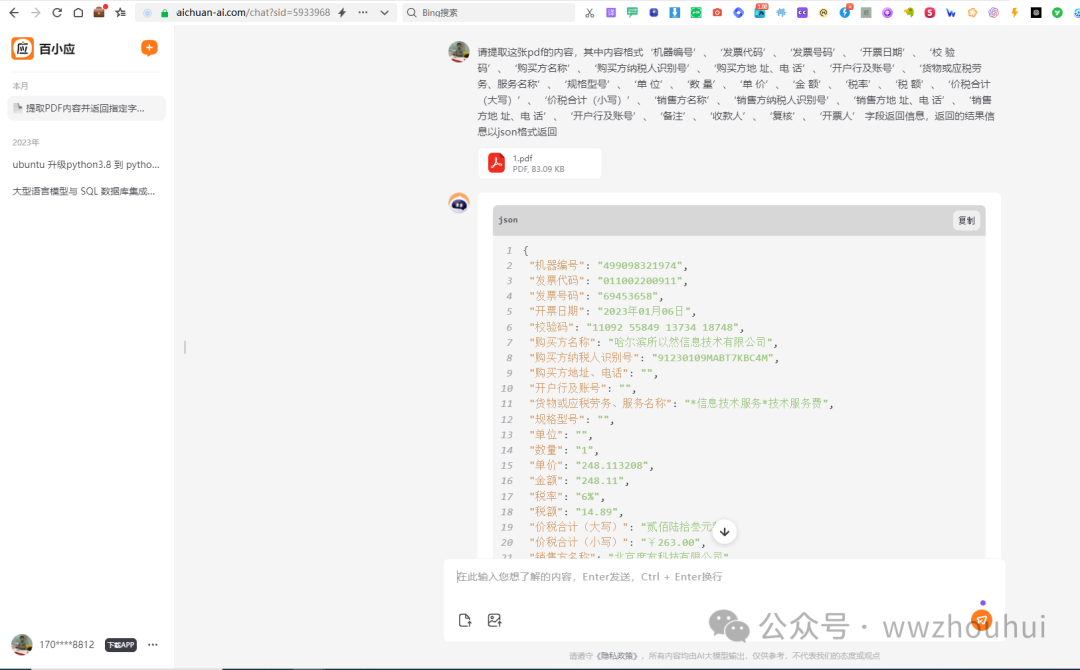
请提取这张pdf的内容,其中内容格式‘机器编号’、‘发票代码’、‘发票号码’、‘开票日期’、‘校 验 码’、‘购买方名称’、‘购买方纳税人识别号’、‘购买方地 址、电 话’、‘开户行及账号’、‘货物或应税劳务、服务名称’、‘规格型号’、‘单 位’、‘数 量’、‘单 价’、‘金 额’、‘税率’、‘税 额’、‘价税合计(大写)’、‘价税合计(小写)’、‘销售方名称’、‘销售方纳税人识别号’、‘销售方地 址、电 话’、‘销售方地 址、电 话’、‘开户行及账号’、‘备注’、‘收款人’、‘复核’、‘开票人’ 字段返回信息,返回的结果信息以json格式返回
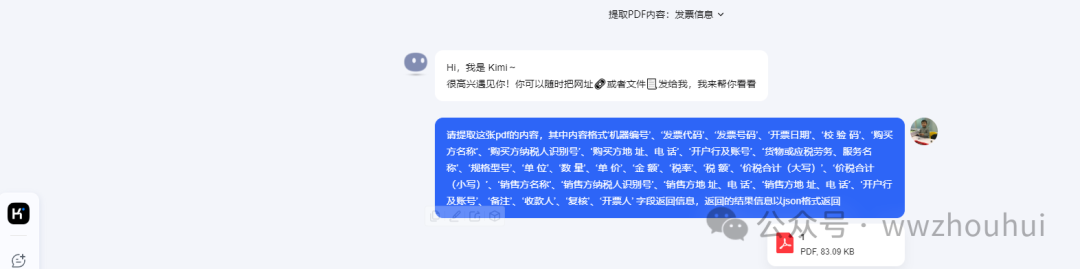
接下来KIMI给我返回信息
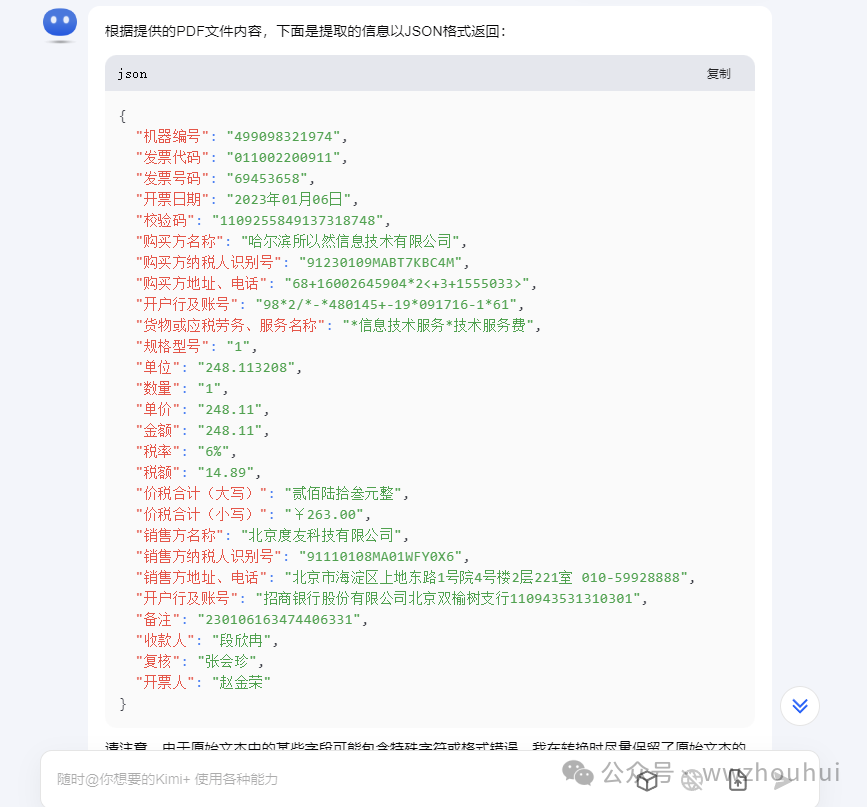
这样我们就通过kimi多模态识别功能将发票的票面信息给我返回了。通过输入提示词指令我们就可以根据我们的需要让大模型给我们返回我们要的数据字段了。
其他模型测试
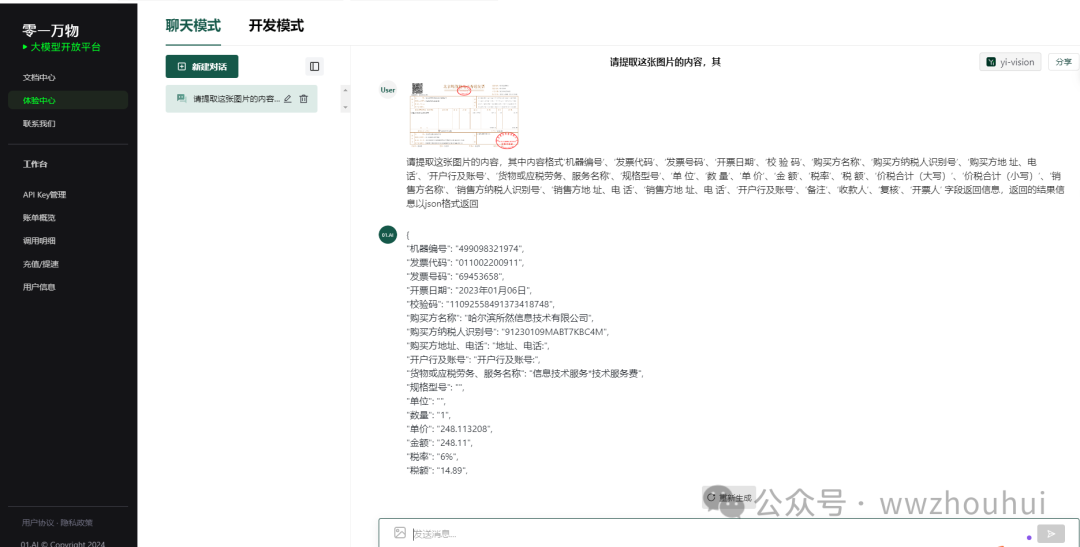
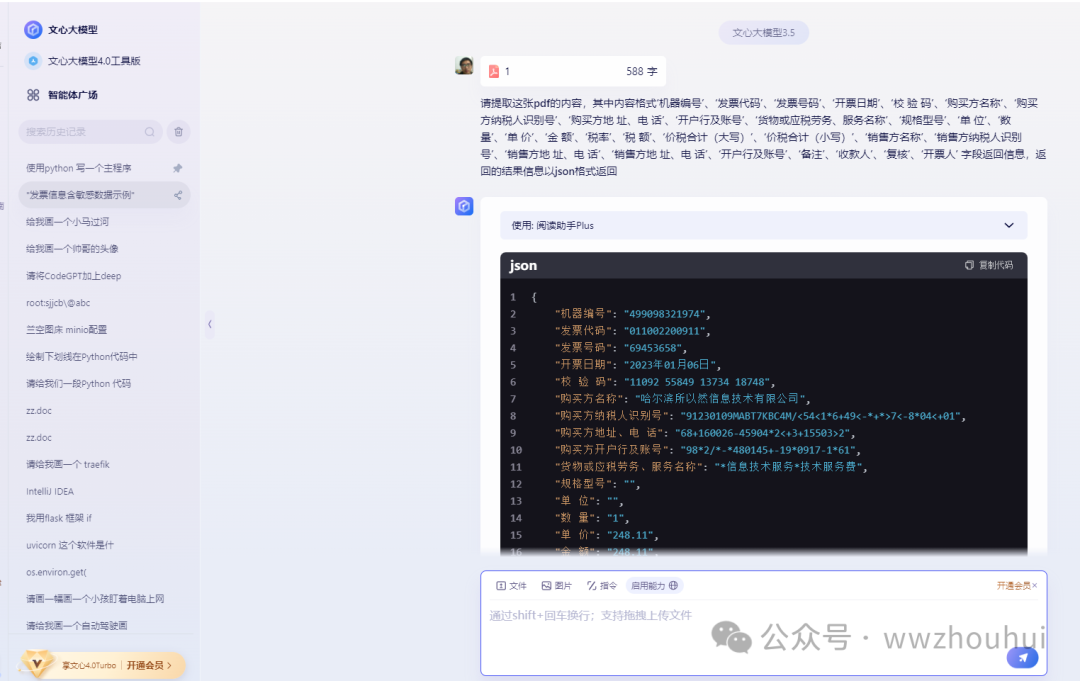
我们用同样的方法测试其他厂商的模型,具体步骤就不详细展开了。
百小应 https://ying.baichuan-ai.com/
通义千问VL_MAXhttps://bailian.console.aliyun.com/
海螺AI https://hailuoai.com/
智普清言 https://chatglm.cn/
文心一言 https://yiyan.baidu.com/
01万物 yi-vision https://platform.lingyiwanwu.com/
腾讯元宝 https://yuanbao.tencent.com/
豆包 https://www.doubao.com/chat/
gpt-4o https://www.coze.com/ (使用海外版扣子)
gemini-1.5-flash https://generativelanguage.googleapis.com (api 接口测试)
gemini-1.5-pro https://generativelanguage.googleapis.com (api 接口测试)
以上就是我们使用国内外闭源支持多模态大模型厂商进行了测评。(由于国内外模型比较多,这里也只罗列了一部分主流模型)。本次文章我们只测评闭源模型,下个文章会教大家开源模型上测评,以及如何使用开源模型实现以上多模态模型整合,包括和其他应用系统对接等。感兴趣小伙伴可以持续关注我的文章。
下面给大家截几个测评过程中的图。
测评总结
我们将以上测试结果整理到EXCEL 表格中,对比了一下数据识别的准确性。目前绝大部分模型都能较好的识别出发票票面信息。尤其是国内模型在中文识别上确实比国外模型识别率更准。目前本次测评效果最好的是百川大模型百小应,全部识别出来。其他模型多少有一些不准的地方。
测试对比


我们这里也针对本次测评做了模型排名。
第一名:百川大模型百小应
第二名:kimi、gpt-4o
第三名:智普清言 、01万物yi-vision
第四名:文心一言3.5、通义千问VL_MAX 、腾讯元宝、Google gemini-1.5-flash 、gemini-1.5-pro、海螺AI
第五名:豆包
3.总结
多模态大模型(Multimodal Large Models, MLMs)是近年来人工智能领域的一个重要研究方向。目前已经在各个领域开始逐步发力。结合AI agent智能体将多个模型进行整合,从而能够实现更多场景的应用。本次文章主要是使用发票识别做案例来讲解多模态一个简单的应用。当然我们本次只是使用发票来识别,在财税领域或则企业内部信息化中有大量的票证、合同、表格等非结构化的数据,企业数字化更多是将企业所有数据化实现标准化、数据化、标签化。只有这样才能通过信息化系统来整合这些数据实现各个系统数据融合和打通,结合大模型技术从而真正实现智能化发展。本期文章就分享到这里,感兴趣的小伙伴可以留言、关注、我们下个文章给大家介绍开源多模态模型如何实现以上数据,以及后期我们将使用 AI agent智能体将这些多模态模型+开源模型实现企业内部信息化解决方案。我们下个文章见。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)