大模型驱动的医疗文本实体抽取:一种模块化方法的深度解析
研究背景在医疗领域,临床文本数据包含着丰富的多源信息,包括患者主观陈述、既往客观事实、医生诊断过程和总结记录等。从这些非结构化文本中提取有价值的信息,对疾病进展研究具有重要意义。然而,传统的文本特征提取方法往往面临着以下挑战:特征维度难以确定算法精度依赖人工标注特征范围与人力投入呈非线性增长。
研究背景
在医疗领域,临床文本数据包含着丰富的多源信息,包括患者主观陈述、既往客观事实、医生诊断过程和总结记录等。从这些非结构化文本中提取有价值的信息,对疾病进展研究具有重要意义。然而,传统的文本特征提取方法往往面临着以下挑战:
-
特征维度难以确定
-
算法精度依赖人工标注
-
特征范围与人力投入呈非线性增长
创新方法
本研究提出了一种基于大语言模型的模块化实体抽取方法。这种方法将整个抽取过程分解为多个可控的步骤:
-
概念准备:从语料库中提取现有概念并筛选相关概念
-
语料准备:对原始数据进行脱敏处理,根据选定概念准备语料库
-
提示词设计:针对不同LLM任务设计提示模板
-
问答量表:将概念转化为问题模板,通过LLM进行相应量表提取
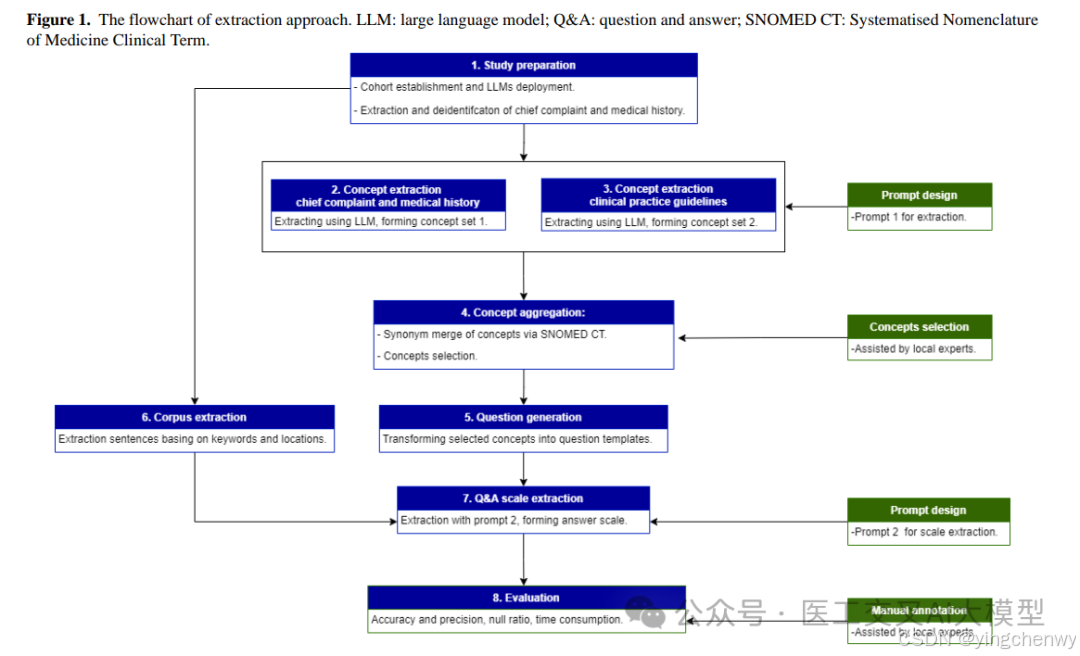
技术细节
1. 提示词模板设计
研究采用四段式结构设计提示词模板:
-
上下文部分:定义角色和任务
-
指令部分:概述执行步骤,使用思维链方法
-
输入数据部分:管理各类输入以满足不同信息需求
-
输出指标部分:规定输出格式和标准
2. 概念提取与聚合
-
使用LLM从患者主诉和病史中提取概念
-
保留出现频率超过5%的概念
-
采用SNOMED CT词汇表进行规范化处理
-
通过规则匹配过滤不准确提取
-
由本地专家手动过滤结构化文本中的概念
3. 问题生成
-
利用ChatGPT4.0作为问题生成器产生基础问题集
-
由本地专家根据100个观察样本的表现进行优化
-
针对性地设计问题模板以避免上下文混淆
4. 量表提取
研究发现并发请求数为3时性能最优,相比单一请求提升17.9%的速度。同时采用max_token限制策略(上限20)来优化推理速度。
实验结果
本研究使用了两个低参数的中文大语言模型进行测试:
-
Qwen-14B-Chat (QWEN)
-
Baichuan2-13B-Chat (BAICHUAN)
评估指标包括:
准确率和精确率
-
QWEN:准确率95.52%,精确率92.93%
-
BAICHUAN:准确率95.86%,精确率90.08%
空值率
-
QWEN:平均0.02%
-
BAICHUAN:平均0.21%
时间消耗
- BAICHUAN的处理时间约为QWEN的4倍
此外,研究还测试了QWEN的INT4量化版本在消费级GPU(NVIDIA RTX 3090)上的表现:
-
准确率达到97.28%
-
空值率为0%
-
平均每个观察样本处理时间31秒
实际应用价值
特征维度丰富
-
涵盖食物和药物过敏(食物过敏6.6%,药物过敏25.2%)
-
包含妊娠症状(失眠0.9%,心悸2.3%)
-
记录月经情况(痛经22.8%)
-
统计家族史(哮喘家族史1%,精神病家族史0.27%)
处理效率高
-
单GPU配置下15天可完成25,709个样本的68个特征提取
-
多GPU集群可将处理时间缩短至小时级别
结果可靠
-
与类似研究队列比较显示数据提取准确
-
系统性红斑狼疮比例与其他研究相符(0.20% vs 0.03%-0.23%)
-
抗磷脂综合征比例对标(0.08% vs 0.02%-0.12%)
本研究为临床文本数据分析提供了一种可行的新方法,通过模块化设计提高了特征提取的精度和效率。建议在实际应用中,预先与记录医生沟通,以提高数据质量并减少潜在偏差。
开源信息
论文中使用的模型:
-
QWEN: https://huggingface.co/Qwen/Qwen-14B-Chat
-
Baichuan: https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
Q&A深度解析
Q1: 为什么要将实体抽取过程模块化?传统方法存在什么问题?
大语言模型在处理长文本时容易产生"特征幻觉",导致关键信息丢失。模块化设计可以将复杂任务分解为可控的小步骤,每个模块负责基础任务。这种方法可以提高准确性,减少错误累积。传统方法主要存在三个问题:
-
特征维度难以预先确定,限制了研究范围
-
仅依赖算法而不进行标注会导致低准确率和召回率
-
扩大特征范围时,所需人力投入呈非线性增长
Q2: 四段式提示词模板的具体设计原理是什么?
提示词模板包含四个关键部分:
-
上下文部分:明确定义模型角色和任务范围,建立行为基准
-
指令部分:详细说明执行步骤,采用思维链方法,并提供示例引导
-
输入数据部分:灵活管理不同类型的输入信息
-
输出指标部分:规定统一的输出格式和标准
这种设计确保了输出的一致性,避免冗余内容生成,减少特征幻觉。
Q3: 概念提取过程中如何确保准确性?
研究采用了多重保障机制:
-
设置5%的频率阈值过滤罕见概念
-
使用SNOMED CT词汇表规范化概念
-
实施规则匹配过滤不准确提取
-
由临床专家进行人工审核
-
结合临床指南补充重要概念
Q4: 研究中采用的性能优化策略有哪些?
主要优化策略包括:
Q5: QWEN和BAICHUAN两个模型的性能差异体现在哪些方面?
-
并发请求数优化:经测试3个并发请求最优,提升17.9%速度
-
Token限制:将max_token设置为20,优化推理速度
-
语料预提取:基于问题模板位置和概念相关句子预处理
-
模型量化:采用INT4量化版本在消费级GPU上运行
关键性能差异:
Q6: 如何处理时间和上下文相关的混淆问题?
-
准确率和精确率
-
QWEN:95.52%和92.93%
-
BAICHUAN:95.86%和90.08%
-
空值率
-
QWEN:0.02%
-
BAICHUAN:0.21%
-
处理时间
-
BAICHUAN处理时间约为QWEN的4倍
研究采用两种策略预处理语料:
-
基于问题模板位置进行提取
-
基于包含目标概念的句子进行提取 这样可以避免混淆当前病史与既往病史,或患者病史与家族史。
Q7: INT4量化版本的QWEN相比原始版本有什么优势?
INT4量化版本表现出显著优势:
-
更高的准确率:97.28%
-
零空值率:0%
-
更快的处理速度:平均31秒/样本
-
硬件要求更低:可在消费级GPU上运行
-
部署成本降低:存储需求减少
Q8: 研究结果的可靠性如何验证?
通过多个维度验证:
-
-
与已有研究数据对比
-
专家手动标注1500个观察样本作为金标准
-
对25,709个样本进行空值率统计
-
测量处理时间评估效率
-
与临床实际数据对照验证
-
Q9: 该方法在实际应用中有什么限制?
主要限制包括:
-
概念集合限制在68个项目,可能未涵盖所有维度
-
数据来源仅限单一医院,可能存在区域性差异
-
仅测试了两个大语言模型,通用性需要进一步验证
-
需要预先与记录医生沟通以提高数据质量
Q10: 该研究对未来医疗文本处理有什么启示?
重要启示:
-
模块化设计可以有效提高大语言模型在专业领域的应用效果
-
结合专家知识和自动化处理是提高准确率的关键
-
量化技术可以降低部署门槛,提高实用性
-
预处理和优化策略对提升处理效率至关重要
-
标准化词汇和规范化处理有助于提高数据质量

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)