CRAW4LLM:面向大模型预训练的高效网络爬虫算法解析
近年来,大规模语言模型(LLM)的预训练高度依赖网络爬虫数据(如Common Crawl)。低效数据筛选:90%以上抓取内容因质量低下被丢弃,造成算力浪费(见图1);优先级错位:基于PageRank等图连接性指标,偏好高入链网页而非高价值内容(见图2相关性分析)。核心矛盾:传统爬虫的"数据收集策略"与LLM预训练的"数据质量需求"严重脱节!创新价值✅ 减少79%的无效抓取✅ 降低网站服务器压力未来
·
——仅用21%数据量实现SOTA效果,重新定义高质量数据抓取范式
1. 研究背景与问题定义
近年来,大规模语言模型(LLM)的预训练高度依赖网络爬虫数据(如Common Crawl)。然而,传统爬虫存在两个关键缺陷:
- 低效数据筛选:90%以上抓取内容因质量低下被丢弃,造成算力浪费(见图1);
- 优先级错位:基于PageRank等图连接性指标,偏好高入链网页而非高价值内容(见图2相关性分析)。
核心矛盾:传统爬虫的"数据收集策略"与LLM预训练的"数据质量需求"严重脱节!
2. CRAW4LLM算法原理
2.1 算法框架
提出预训练影响力优先爬取策略,算法流程如下(完整伪代码见Algorithm 1):
while 未达到目标数据量:
1. 抓取当前URL列表对应的网页
2. 使用预训练影响力评分器M评估网页质量
3. 提取外链并计算其优先级分数
4. 按分数降序更新优先级队列
注:M可采用DCLM fastText等预训练数据分类器
2.2 创新点解析
| 传统爬虫 | CRAW4LLM |
|---|---|
| 优先级指标 | PageRank/入链数 |
| 探索策略 | 广度优先遍历 |
| 数据利用率 | <10% |
关键公式:
其中为URL优先级分数,为预训练影响力评估模型
3. 实验验证
3.1 实验设置
- 数据集:ClueWeb22-A子集(9亿英文网页)
- 基线对比:Random/Indegree爬虫 + 后处理筛选
- 评估指标:23项NLP任务平均准确率
3.2 核心结果
- 性能对比(相同数据量):
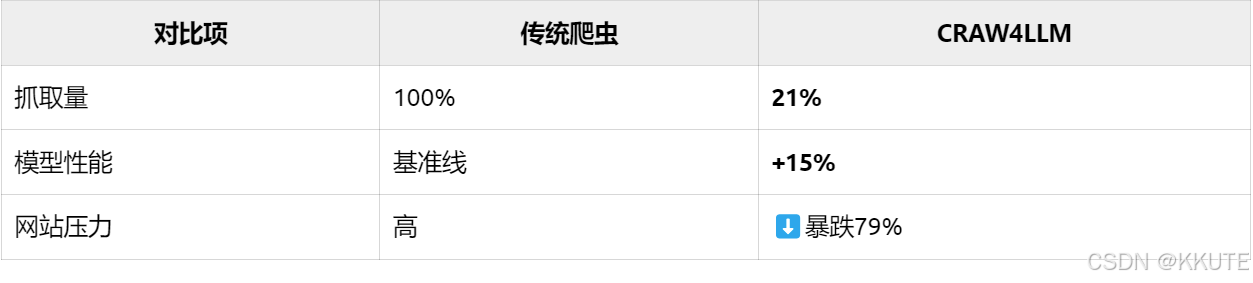
- 效率优势:
- 仅抓取21%数据即可达到传统方法100%效果
- 在2.2%数据量时达成95%的Oracle性能(见图4)
3.3 技术洞见
- 链接质量相关性:高影响力网页的外链质量呈正相关(r=0.61)
- 数据分布特性:预训练优质数据在Web图中呈现聚集性
4. 工程实践建议
- 部署方案:
- 集成Apache Nutch等开源爬虫框架
- 采用多级缓存优化实时评分性能
- 参数调优:
- 初始种子选择:建议混合权威站点与垂直领域URL
- 评分模型:可替换为BERT等定制化分类器
5. 总结与展望
创新价值:
- ✅ 减少79%的无效抓取
- ✅ 降低网站服务器压力
- ✅ 开源地址:Crawl4LLM GitHub
未来方向:
- 动态调整评分模型的在线学习机制
- 结合差分隐私保护网站数据
作者声明:本文实验基于ClueWeb22数据集模拟,实际部署需遵守robots协议与数据合规要求
相关资源
- 论文原文:arXiv:2502.13347
- 预训练数据集构建指南:DataComp-LM
- 网络爬虫法律指南:W3C Crawling Best Practices

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)