使用 Ollama 部署本地大模型maxkb+SimpleRAG
检索增强生成(RAG)结合了检索和生成两种技术,显著提升了文本生成任务的性能。在生成过程中,RAG 模型通过检索模块获取外部知识,增强生成模型的准确性和丰富性。SimpleRAG 是基于 WPF 与 Semantic Kernel 的简单 RAG 应用。用户可以通过该应用学习如何使用 Semantic Kernel 构建 RAG 应用。具体使用可以参考官方文档依赖框架的包会小一些,独立的包会大一些
0. 简介
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
最近是1024程序员节,再给大家上点干货。在人工智能领域,大型语言模型(LLM)正成为推动技术进步的重要力量。OpenAI 的 GPT 系列无疑是其中的佼佼者,凭借其强大的语言处理能力,广泛应用于聊天问答、文本生成和翻译等任务。随着 ChatGPT 引入定制个人知识库的功能,检索增强生成(RAG)技术应运而生。这一技术使模型在生成回答之前,可以通过检索相关信息显著提升输出的准确性和丰富性。然而,由于网络环境、隐私和政策等原因,许多人开始寻求在本地部署自己的大模型和知识库。Ollama 的出现正好满足了这一需求。
Ollama 是一个大模型管理框架,类似于 Docker,允许用户通过简单的命令快速拉取和运行各类大模型。为了方便对大模型进行微调和使用,本文还将介绍如何结合 maxkb 构建一个私人定制知识库。这里最近受到优刻得的使用邀请,正好解决了我在大模型和自动驾驶行业对GPU的使用需求。UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.08元,月卡只需要1.36元每小时,并附带200G的免费磁盘空间。暂时已经满足我的使用需求了,同时支持访问加速,独立IP等功能,能够更快的完成项目搭建。同时我们也开源了我们的代码:https://github.com/lovelyyoshino/Whisper_finetuning

在1024程序员节,优刻得发了专属的算力金,注册点击上方的链接即可获得,可以说填写一个问卷就可以白嫖了。作者在compshare平台制作了这个镜像,可以直接一键部署:https://www.compshare.cn/images-detail?ImageID=compshareImage-142ocp648pr5&ImageType=Community&ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
1. 优势
- 开源免费:Ollama 及其支持的模型完全开源,用户可以自由使用、修改和分发。
- 简单易用:只需几条命令即可启动和运行,无需复杂配置。
- 模型丰富:支持 Llama 3、Mistral、Qwen2 等众多热门开源 LLM,并提供一键下载和切换功能。
- 资源占用低:相比商业 LLM,Ollama 对硬件要求较低,可以在普通笔记本电脑上流畅运行。
- 社区活跃:拥有庞大且活跃的社区,用户可以轻松获取帮助和分享经验。
2. 如何使用
2.1 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,检查服务状态:
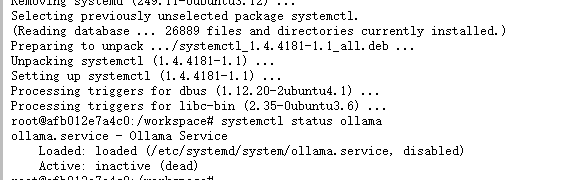
systemctl status ollama

出现这个问题是表明你正在尝试使用systemctl命令来检查ollama服务的状态,但是系统并没有使用systemd作为初始化系统来启动。所以我们安装一下,然后重新输入上面的检查服务状态
apt-get install systemctl
2.2 模型库
在 ollama.com/library 上可获取的模型示例:
| 模型 | 参数量 | 尺寸 | 使用说明 |
|---|---|---|---|
| llama3.2 | 1B | 1.2GB | ollama run llama3.2 |
| llama3.1 | 8B | 4.7GB | ollama run llama3.1 |
| gemma2 | 2B | 1.4GB | ollama run gemma2 |
| qwen2.5 | 7B | 4.1GB | ollama run qwen2.5:7b |
| phi3.5 | 3.8B | 2.3GB | ollama run phi3.5 |
| nemotron-mini | 4B | 2.5GB | ollama run nemotron-mini |
| mistral-small | 22B | 13GB | ollama run mistral-small |
| deepseek-coder-v2 | 16B | 9GB | ollama run deepseek-coder-v2 |
| mistral | 7B | 4.1GB | ollama run mistral |
| mixtral | 8x7b | 46GB | ollama run mixtral:8x7b |
| codegemma | 2B | 1.4GB | ollama run codegemma |
| command-r | 35B | 21GB | ollama run command-r |
| command-r-plus | 104B | 62GB | ollama run command-r-plus |
| llava | 7B | 4.1GB | ollama run llava |
| dolphin-mixtral | 8x7b | 46GB | ollama run dolphin-mixtral |
| starcoder2 | 3B | 2.3GB | ollama run starcoder2 |
| phi | 2.7B | 1.7GB | ollama run phi |
| deepseek-coder | 1.3B | 0.8GB | ollama run deepseek-coder |
| llama2-uncensored | 7B | 4.1GB | ollama run llama2-uncensored |
| dolphin | 7B | 4.1GB | ollama run dolphin |
| yi | 6B | 3.8GB | ollama run yi |
| orca-mini | 3B | 2.3GB | ollama run orca-mini |
| zephyr | 7B | 4.1GB | ollama run zephyr |
| tinyllama | 1.1B | 0.7GB | ollama run tinyllama |
| dolphin-llama3 | 8B | 4.7GB | ollama run dolphin-llama3 |
| stablelm2 | 1.6B | 1GB | ollama run stablelm2 |
| mathstral | 7B | 4.1GB | ollama run mathstral |
| internlm2 | 7B | 4.1GB | ollama run internlm2 |
| goliath | 70B | 40GB | ollama run goliath |
| deepseek-v2 | 16B | 9GB | ollama run deepseek-v2 |
| everythinglm | 13B | 7.9GB | ollama run everythinglm |
| alfred | 40B | 24GB | ollama run alfred |
| bge-large | 335m | 0.2GB | ollama run bge-large |
| granite3-dense | 2B | 1.2GB | ollama run granite3-dense |
| duckdb-nsql | 7B | 4.1GB | ollama run duckdb-nsql |
| solar | 10.7B | 6.5GB | ollama run solar |
| yi-coder | 1.5B | 1.1GB | ollama run yi-coder |
| dbrx | 132B | 78GB | ollama run dbrx |
| notus | 7B | 4.1GB | ollama run notus |
| stable-beluga | 7B | 4.1GB | ollama run stable-beluga |
| reader-lm | 0.5B | 0.4GB | ollama run reader-lm |
| open-orca-platypus2 | 13B | 7.9GB | ollama run open-orca-platypus2 |
运行 7B 模型需要至少 8GB RAM,运行 13B 模型需要 16GB RAM。
2.3 修改配置
sudo apt-get install net-tools
netstat -tunlp|grep ollama
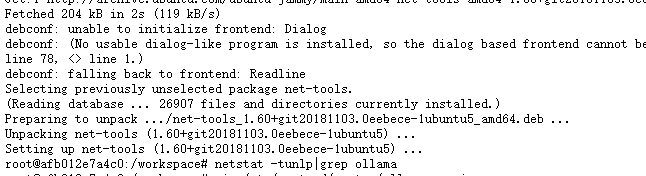
然后进入ollama.service修改下面三个内容
- 修改端口:允许外部访问。
vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
- 更改模型存放位置:指定模型存储路径。
# vim /etc/systemd/system/ollama.service
[Service]
Environment="OLLAMA_MODELS=/workspace/ollama/models"
- 指定运行 GPU:如果有多张 GPU,可以通过
CUDA_VISIBLE_DEVICES配置运行的 GPU。
# vim /etc/systemd/system/ollama.service
Environment="CUDA_VISIBLE_DEVICES=0,1"
然后重启ollama查看信息,我们就可以查看到我们的端口发生变化了
systemctl daemon-reload
systemctl restart ollama

然后我们就可以使用上面的安装指令安装使用了
3. 安装 maxkb
MaxKB 是基于 LLM 的知识库问答系统,我们通过ssh登录后台,然后采用 Docker 部署:
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data cr2.fit2cloud.com/1panel/maxkb
同时我们将对应的端口添加到白名单中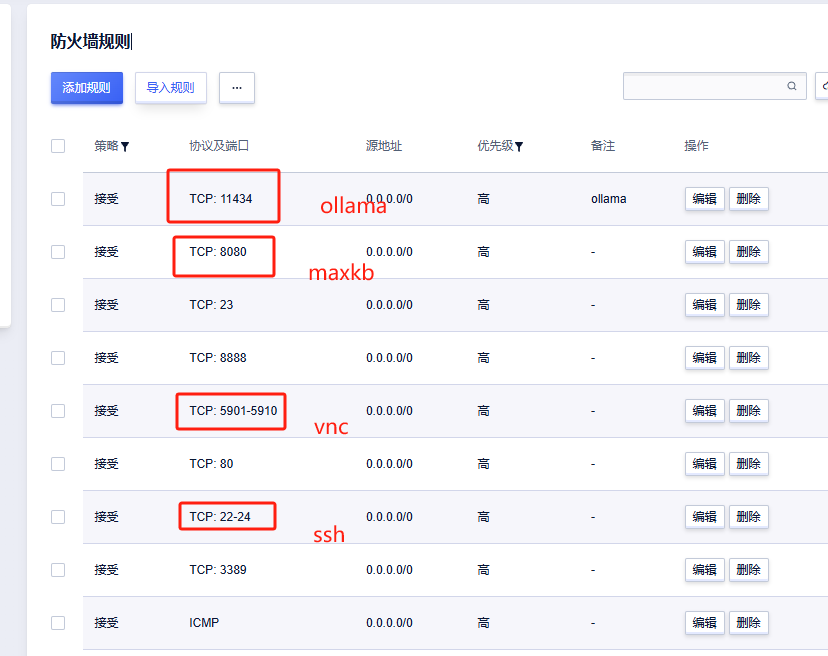
然后我们就可以在本地访问了,访问默认账号(admin)和密码(MaxKB@123…)进行登录。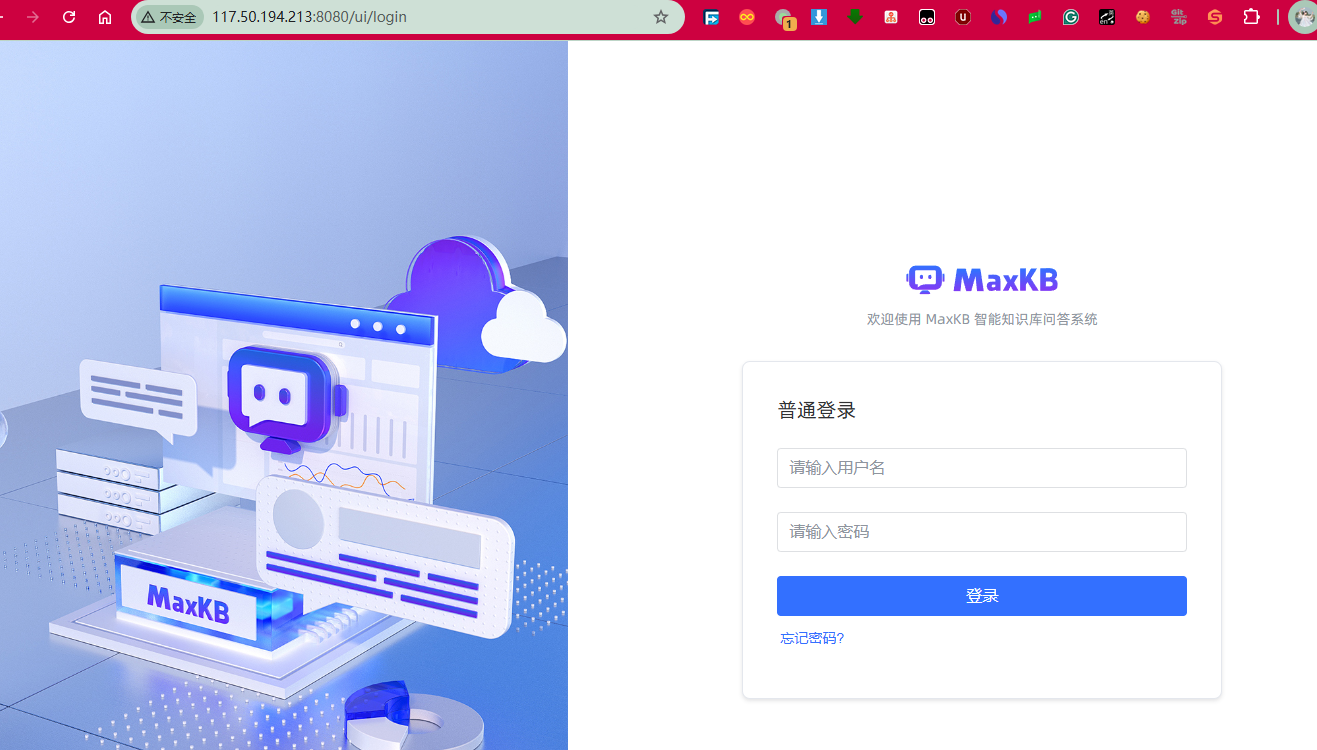
在 MaxKB 的系统管理中,添加 Ollama 模型。API Key 可以随意输入。完成后,系统将自动导入配置。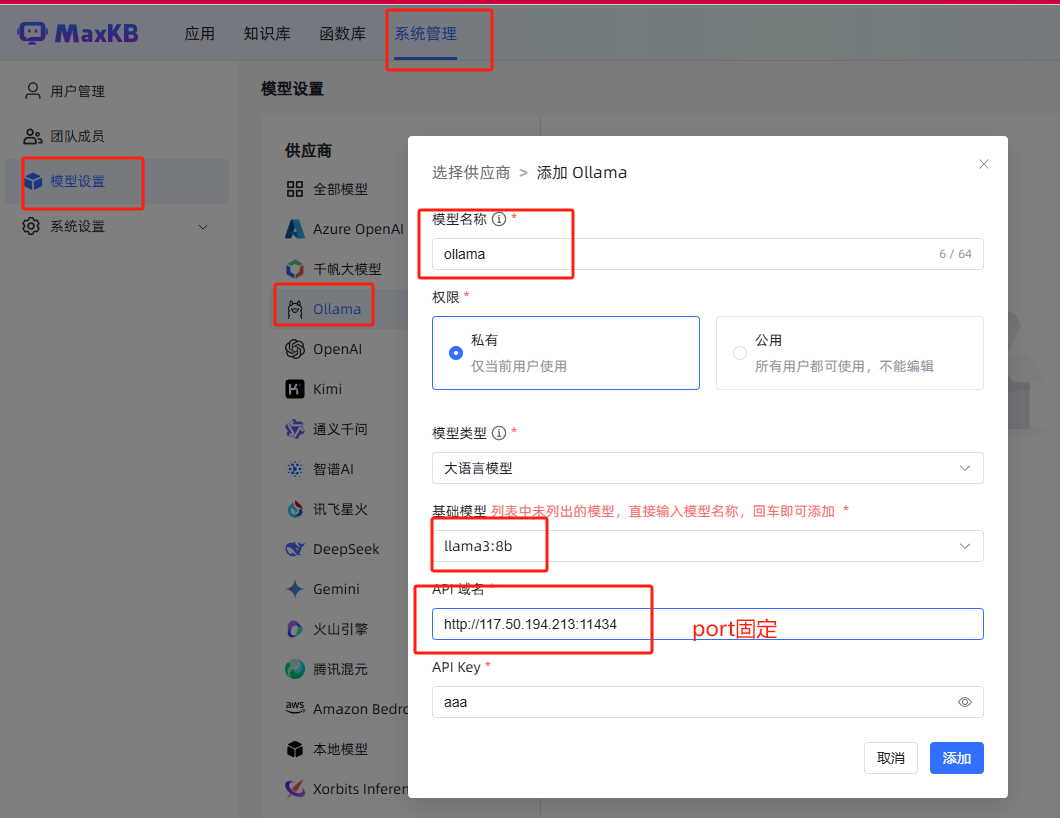
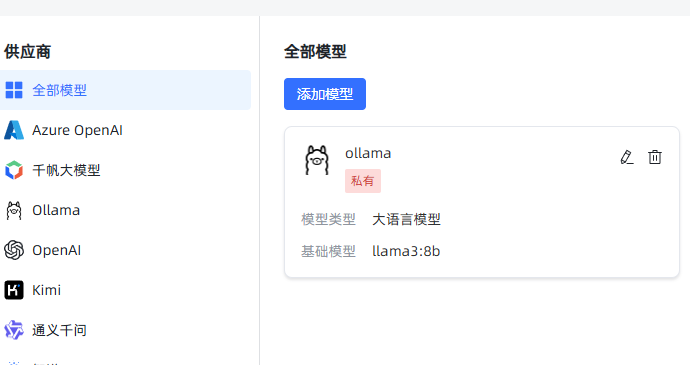
然后在应用管理中创建自定义应用,选择关联模型并保存发布,以便进行对话。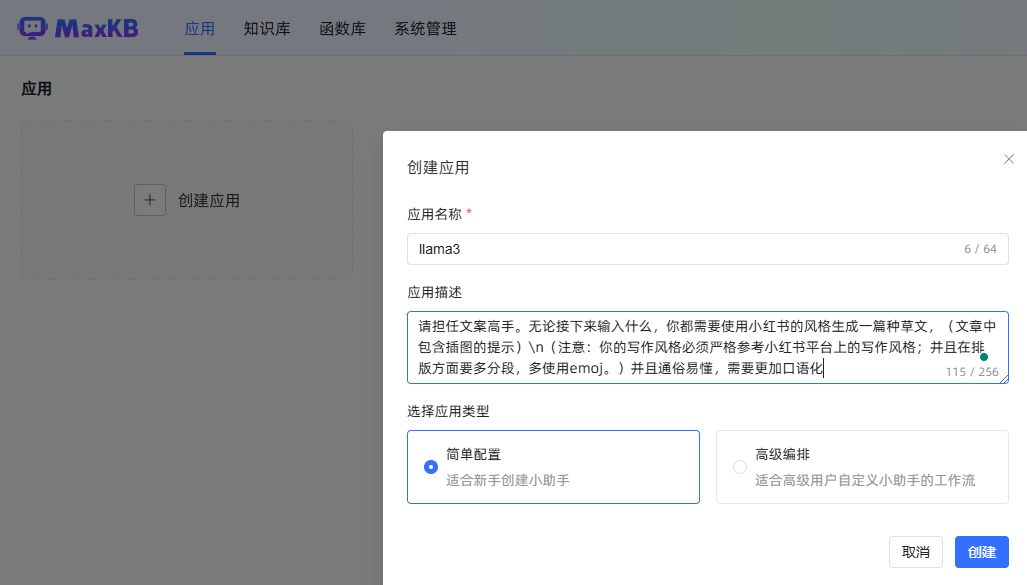
选择关联好的ollama模型,点击右上角的保存并发布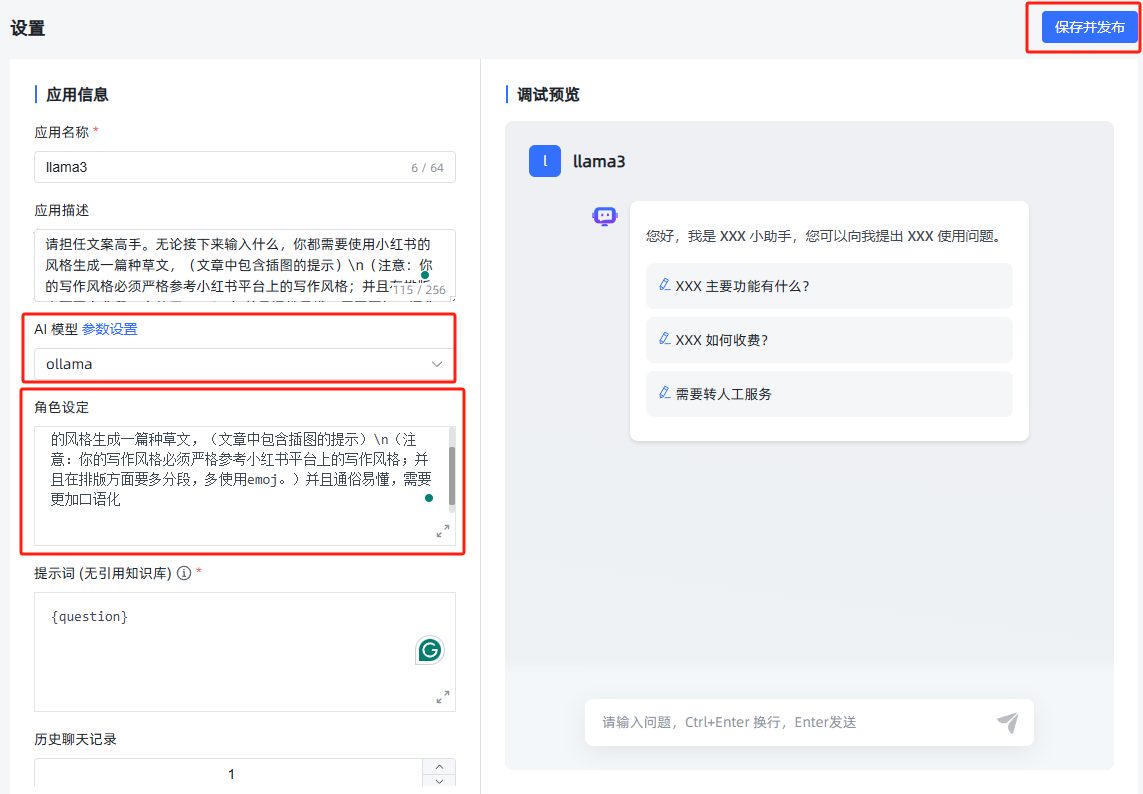
回到概览,点击演示。可以根据需求修改参数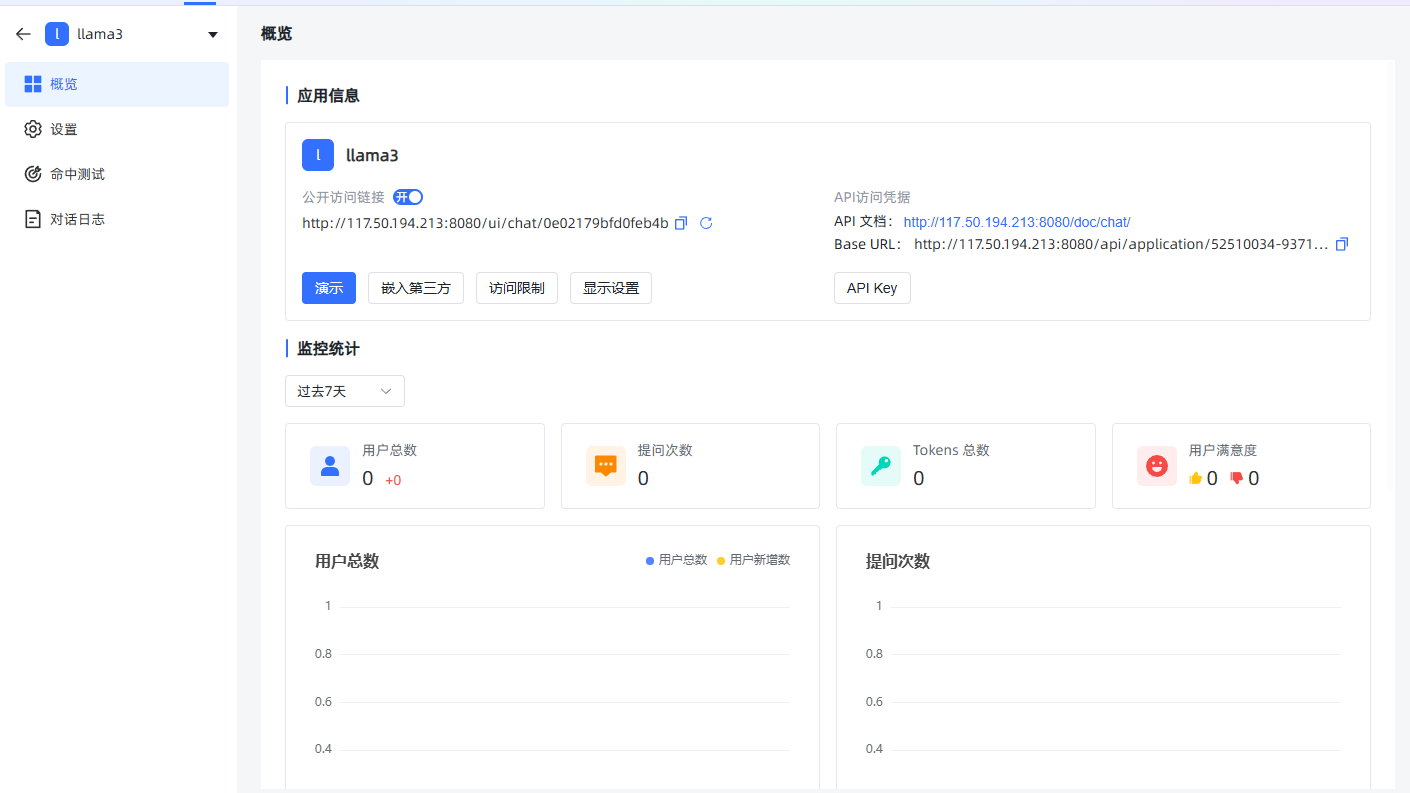
然后就可以自己完成对话了
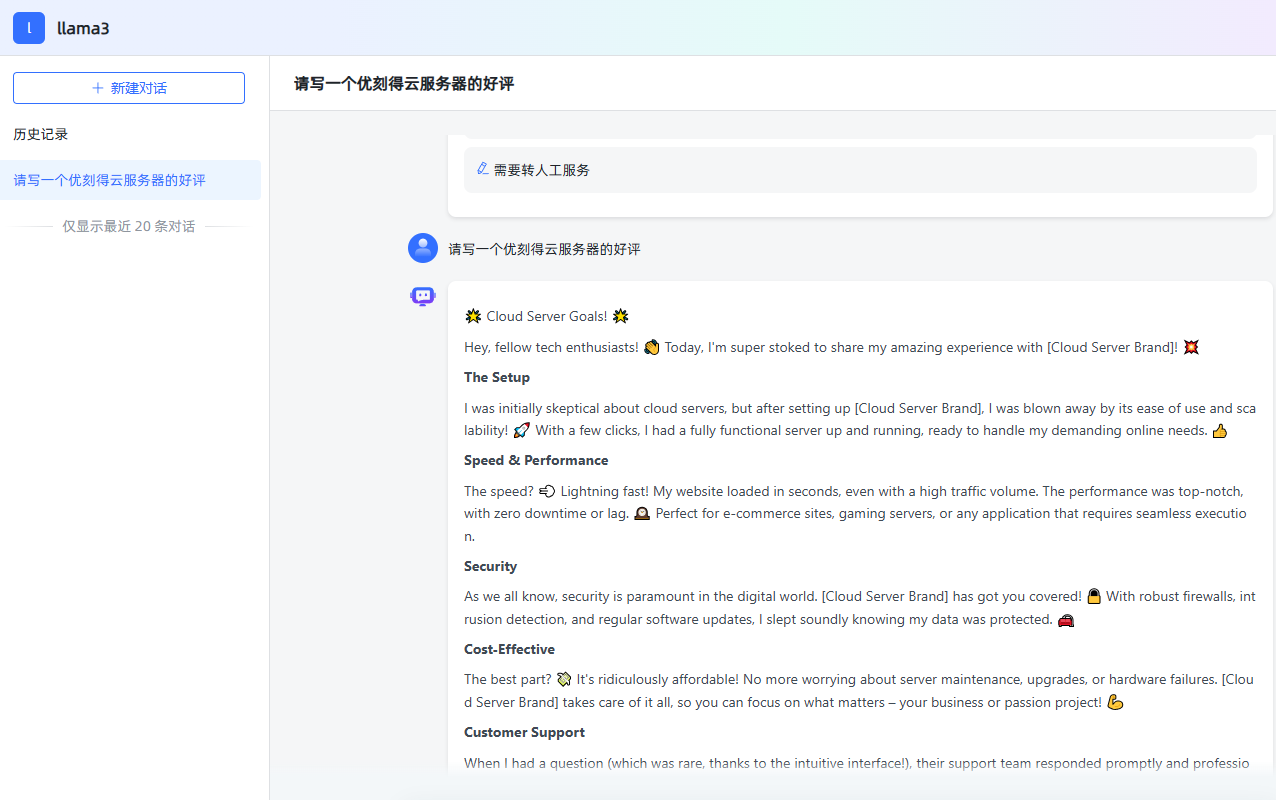
4. SimpleRAG 技术介绍
检索增强生成(RAG)结合了检索和生成两种技术,显著提升了文本生成任务的性能。在生成过程中,RAG 模型通过检索模块获取外部知识,增强生成模型的准确性和丰富性。
SimpleRAG 是基于 WPF 与 Semantic Kernel 的简单 RAG 应用。用户可以通过该应用学习如何使用 Semantic Kernel 构建 RAG 应用。具体使用可以参考官方文档
依赖框架的包会小一些,独立的包会大一些,如果你的电脑已经装了net8.0-windows框架可以选择依赖框架的包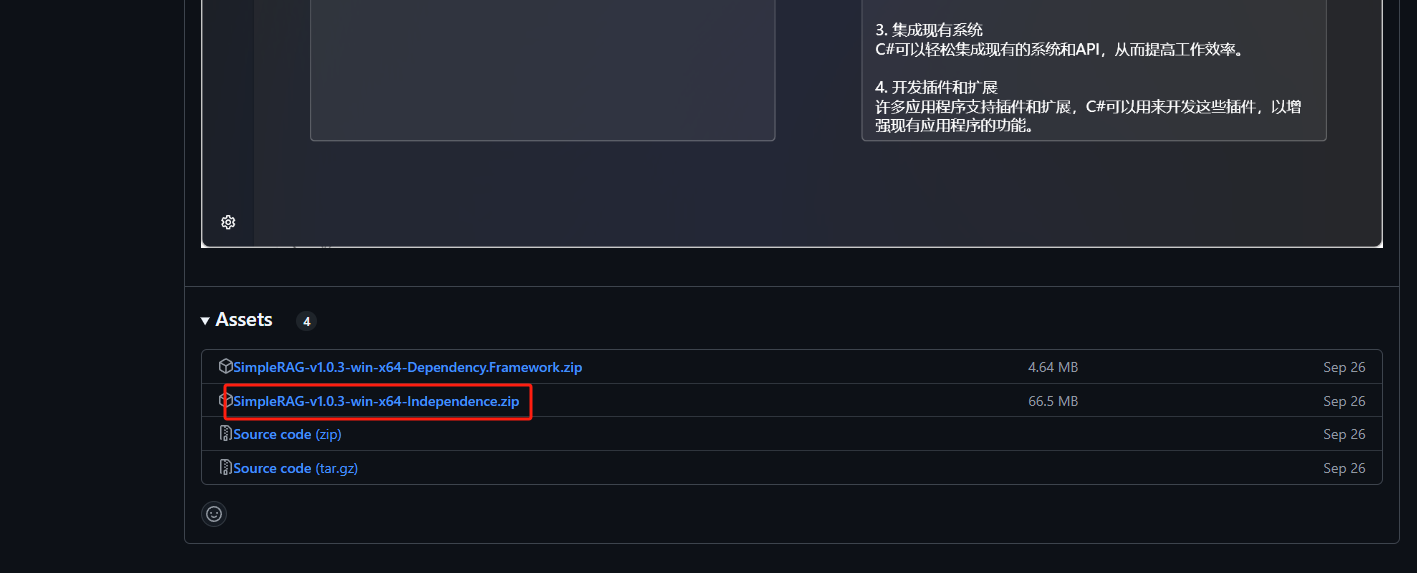
然后我们打开appsettings.json文件,并添加ollama的模块。我们在我们的框架中搜索一下ollama中下载好的模块
然后添加到文件中,Ollama不需要Api Key随便写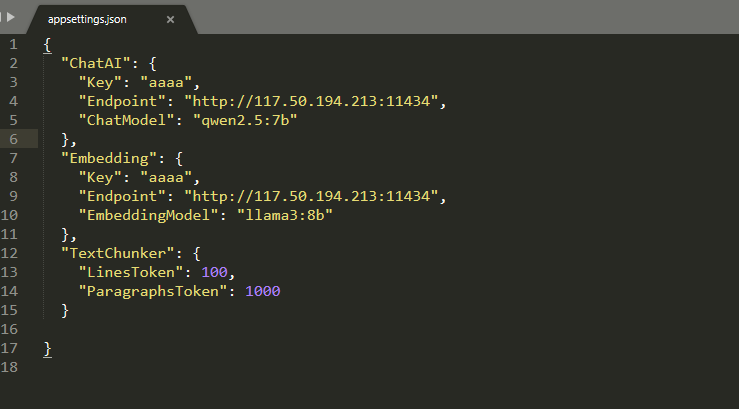
然后就可以查看对话了

5. 结论
通过 Ollama、maxkb以及SimpleRAG的结合,用户可以轻松在本地部署大模型和知识库,享受高效的 AI 服务。无论是个人还是企业,都可以利用这一技术实现更好的数据处理和知识管理。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)