大模型入门 | 浙江大学开源书籍《大模型基础》(附PDF版)
浙江大学出的这个开源的书籍《大模型基础》非常值得一看,写作风格挺吸引人,是一个易读、严谨、有深度的大模型教材。《大模型基础》
浙江大学出的这个开源的书籍《大模型基础》非常值得一看,写作风格挺吸引人,是一个易读、严谨、有深度的大模型教材。

有需要
《大模型基础》书籍PDF文档,可以微信扫描下方CSDN官方认证二维码领取

书籍主要内容
1、语言模型基础
语言是一套复杂的符号系统。语言符号通常在音韵(Phonology)、词法(Morphology)、句法(Syntax)的约束下构成,并承载不同的语义(Semantics)。
语言符号具有不确定性。同样的语义可以由不同的音韵、词法、句法构成的符号来表达;同样的音韵、词法、句法构成的符号也可以在不同的语境下表达不同的语义。因此,语言是概率的。并且,语言的概率性与认知的概率性也存在着密不可分的关系 [15]。
语言模型(Language Models, LMs)旨在准确预测语言符号的概率。从语言学的角度,语言模型可以赋能计算机掌握语法、理解语义,以完成自然语言处理任务。从认知科学的角度,准确预测语言符号的概率可以赋能计算机描摹认知、演 化智能。从 ELIZA [20] 到 GPT-4 [16],语言模型经历了从规则模型到统计模型,再到神经网络模型的发展历程,逐步从呆板的机械式问答程序成长为具有强大泛化 能力的多任务智能模型。
本章将按照语言模型发展的顺序依次讲解基于统计方法的 n-grams 语言模型、基于循环神经网络(Recurrent Neural Network,RNN)的语言模型,基于 Transformer 的语言模型。此外,本章还将介绍如何将语言模型输出概率值解码为目标文本,以及如何对语言模型的性能进行评估。


2、大语言模型架构
随着数据资源和计算能力的爆发式增长,语言模型的参数规模和性能表现实现了质的飞跃,迈入了大语言模型(Large Language Model, LLM)的新时代。凭借着庞大的参数量和丰富的训练数据,大语言模型不仅展现出了强大的泛化能力,还催生了新智能的涌现,勇立生成式人工智能(Artificial Intelligence Generated Content,AIGC)的浪潮之巅。
当前,大语言模型技术蓬勃发展,各类模型层出不穷。这些模型在广泛的应用场景中已经展现出与人类比肩甚至超过人类的能力,引领着由AIGC 驱动的新一轮产业革命。
本章将深入探讨大语言模型的相关背景知识,并分别介绍 Encoder-only、Encoder-Decoder 以及 Decoder-only 三种主流模型架构。通过列举每种架构的代表性模型,深入分析它们在网络结构、训练方法等方面的主要创新之处。最后,本章还将简单介绍一些非 Transformer 架构的模型,以展现当前大语言模型研究百花齐放的发展现状。


3、Prompt 工程
随着模型训练数据规模和参数数量的持续增长,大语言模型突破了泛化瓶颈,并涌现出了强大的指令跟随能力。泛化能力的增强使得模型能够处理和理解多种 未知任务,而指令跟随能力的提升则确保了模型能够准确响应人类的指令。
两种能力的结合,使得我们能够通过精心编写的指令输入,即 Prompt,来引导模型适应各种下游任务,从而避免了传统微调方法所带来的高昂计算成本。Prompt 工程,作为一门专注于如何编写这些有效指令的技术,成为了连接模型与任务需求之间的桥梁。它不仅要求对模型有深入的理解,还需要对任务目标有精准的把握。通过Prompt 工程,我们能够最大化地发挥大语言模型的潜力,使其在多样化的应用场景中发挥出卓越的性能。
本章将深入探讨 Prompt 工程的概念、方法及作用,并介绍上下文学习、思维链等技术,以及 Prompt 工程的相关应用。


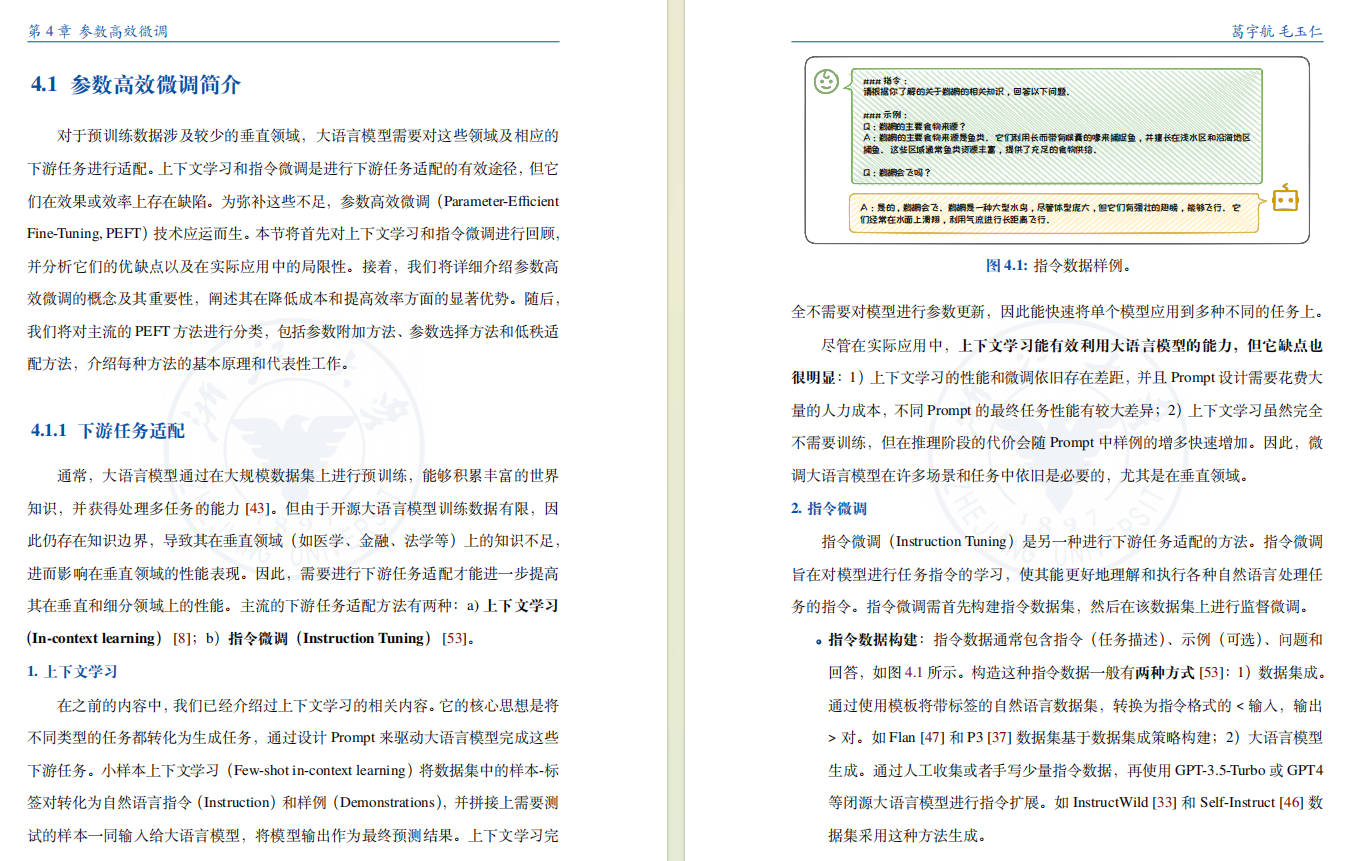
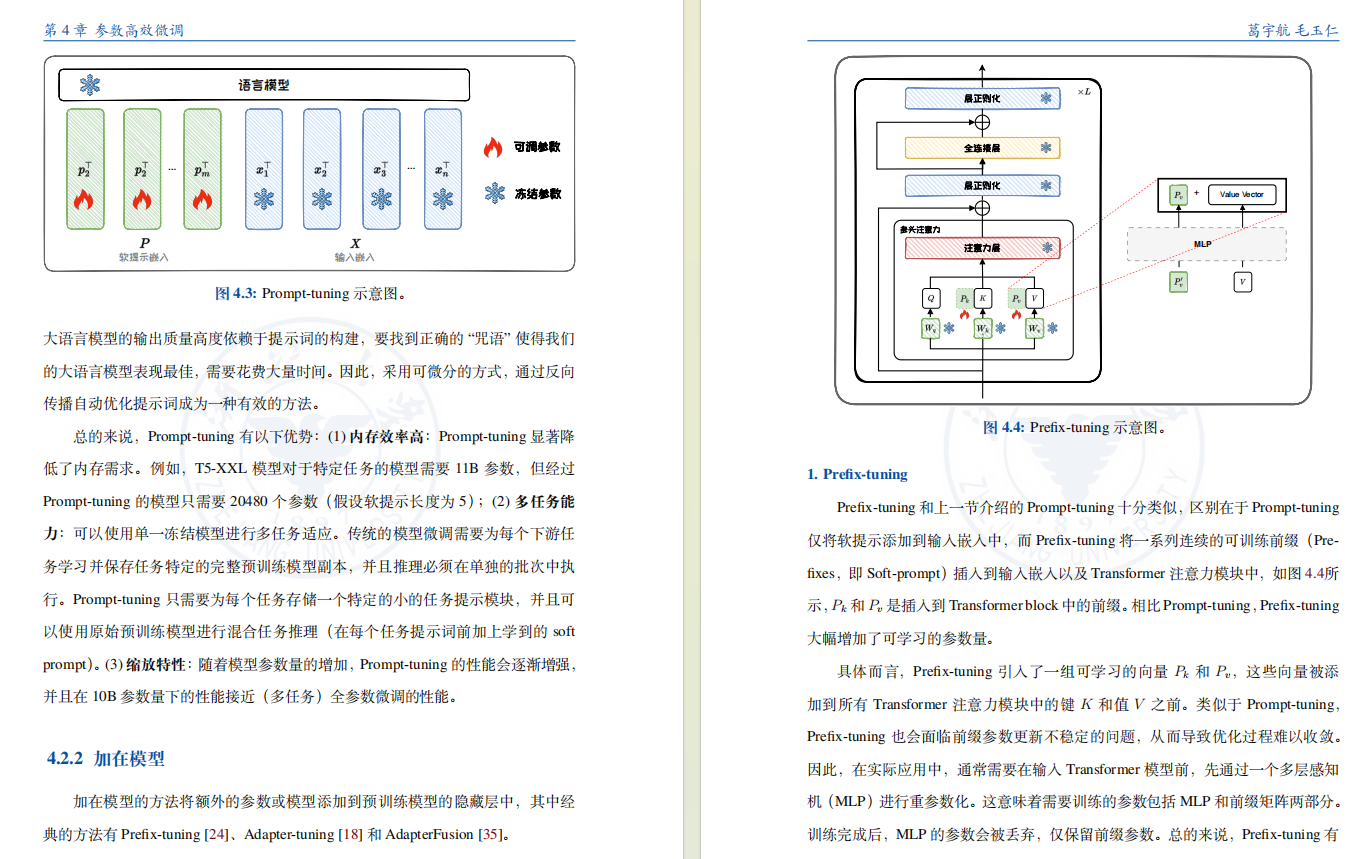
4、参数高效微调
大语言模型从海量的预训练数据中掌握了丰富的世界知识。但“尺有所短”,对于预训练数据涉及较少的垂直领域,大语言模型无法仅通过提示工程来完成领域适配。
为了让大语言模型更好的适配到这些领域,需要对其参数进行微调。但由于大语言模型的参数量巨大,微调成本高昂,阻碍了大语言模型在一些垂直领域的应用。为了降低微调成本,亟需实现效果可靠、成本可控的参数高效微调。
本章将深入探讨当前主流的参数高效微调技术,首先简要介绍参数高效微调的概念、参数效率和方法分类,然后详细介绍参数高效微调的三类主要方法,包括参数附加方法、参数选择方法和低秩适配方法,探讨它们各自代表性算法的实现和优势。最后,本章通过具体案例展示参数高效微调在垂直领域的实际应用。
5、模型编辑
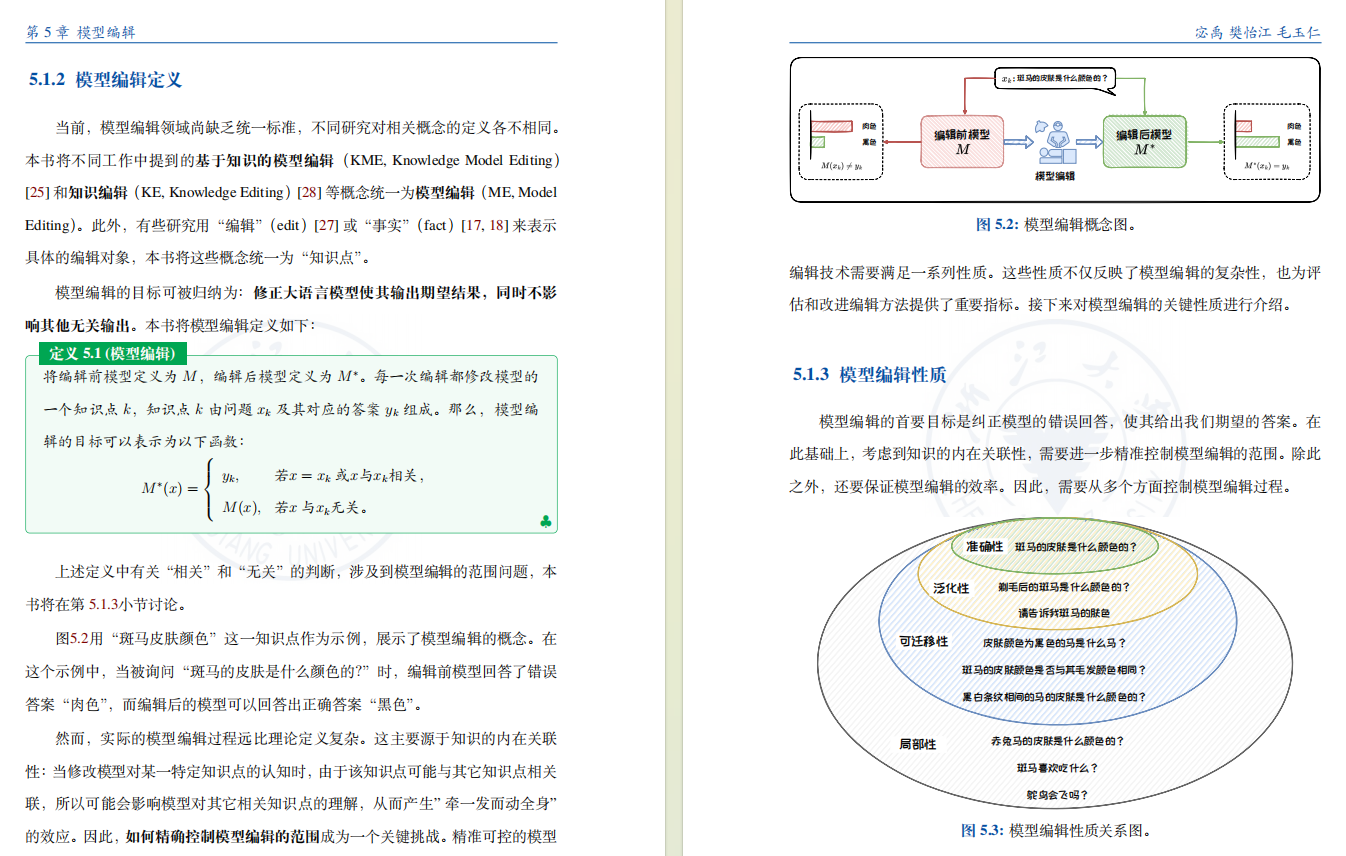
预训练大语言模型中,可能存在偏见、毒性、知识错误等问题。为了纠正这些问题,可以将大语言模型“回炉重造”——用清洗过的数据重新进行预训练,但成本过高,舍本逐末。
此外,也可对大语言模型“继续教育”——利用高效微调技术向大语言模型注入新知识,但因为新知识相关样本有限,容易诱发过拟合和灾难性遗忘,得不偿失。为此,仅对模型中的特定知识点进行修正的模型编辑技术应运而生。
本章将介绍模型编辑这一新兴技术,首先介绍模型编辑思想、定义、性质,其次从内外两个角度分别介绍模型编辑经典方法,然后举例介绍模型编辑的具体方法 T-Patcher 和 ROME,最后介绍模型编辑的实际应用。

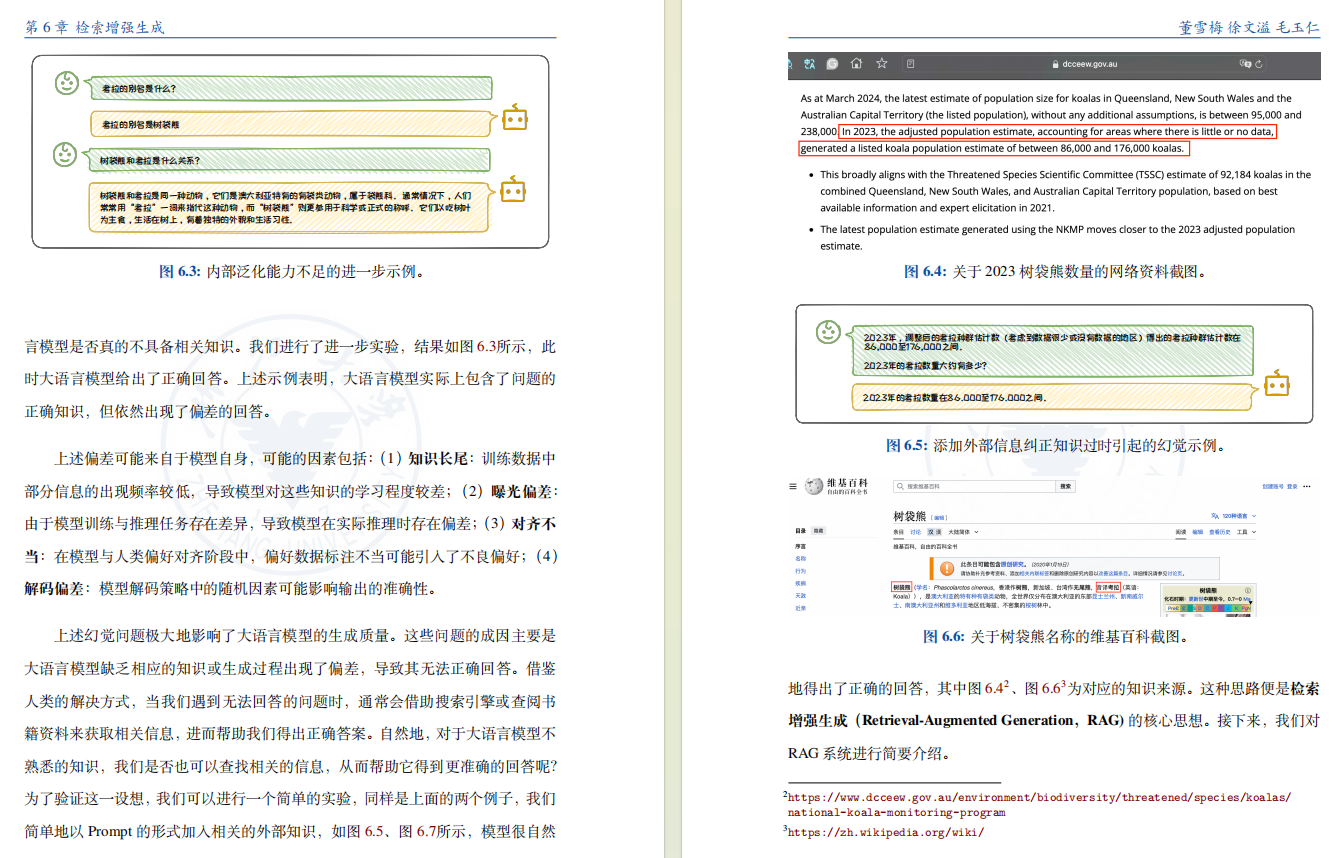
6、检索增强生成
在海量训练数据和模型参数的双重作用下,大语言模型展示出了令人惊艳的生成能力。然而,由于训练数据的正确性、时效性和完备性可能存在不足,其难以完全覆盖用户的需求;并且,根据“没有免费午餐”[55] 定理,由于参数空间有限,大语言模型对训练数据的学习也难以达到完美。
上述训练数据和参数学习上的不足将导致:大语言模型在面对某些问题时无法给出正确答案,甚至出现“幻觉”,即生成看似合理实则逻辑混乱或违背事实的回答。为了解决这些问题并进一步提升大语言模型的生成质量,我们可以将相关信息存储在外部数据库中,供大语言模型进行检索和调用。这种从外部数据库中检索出相关信息来辅助改善大语言模型生成质量的系统被称之为检索增强生成(Retrieval-Augmented Generation,RAG)。
本章将介绍 RAG 系统的相关背景、定义以及基本组成,详细介绍 RAG 系统的常见架构,讨论 RAG 系统中知识检索与生成增强部分的技术细节,并介绍 RAG 系统的应用与前景。

有需要
《大模型基础》书籍PDF文档,可以微信扫描下方CSDN官方认证二维码领取

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 22
22 0
0- 0



 已为社区贡献99条内容
已为社区贡献99条内容

所有评论(0)