大模型学习笔记一:Transformer的注意力机制
Google 的 T5、清华的 GLM 则同时采用了 Encoder 和 Decoder,即 Encoder-Decoder,而 OpenAI 的 GPT,Meta 的 LLaMA、Stanford 的 Alpaca、UC Berkerly 的 Vicuna,还有一众兄弟都只采用了 Decoder,即 Decoder-Only。而且,在输出第 1 个单词“I”的时候和输入的“我”的相关性最高,和其
Transformer 就是 GPT(Generative Pre-trained Transformer)中 “T” ,这足以彰显它在 GPT 以及大模型体系中的地位。Transformer 这种新型的深度神经网络结构是当下各主流大模型的动力源泉。可以说,若要探寻大模型的神奇之处,对 Transformer 架构和运行机制的有一定的理解是绕不开的。
不过,我在前期已经写了两篇专门讲述 Transformer 的笔记,但篇幅都无法控制在 2 万字以下(主要是自己欠缺的知识点比较多,常常不得已进行扩展),包含内容太多,写起来和读起来都比较累,不利于知识的查询和传递。于是我计划重构一下这两篇长文的逻辑,分成多个部分来介绍 Transformer:
- 第一部分:宏观认识,从“黑盒”的角度了解大模型基本运行过程
- 第二部分:自注意力机制,这是 Transformer 非常关键的内容
- 第三部分:推理过程,从输入到输出的正向传播过程
- 第四部分:训练过程,根据输出来逐步进行参数调整的反向传播过程,包括预训练、微调、RLHF 等
- 第五部分:资源消耗,包括参数规模与算力估算,以及 Transformer 原生性并行架构
这篇笔记对应的是第一部分,纳入【基础】系列,仅作为一个初步了解 Transformer 架构的楔子;其他部分在【进阶】的系列中分多篇笔记来讲述,目标是用相对通俗的文字讲清楚其中的技术流程。受限于知识深度和广度有限,可能会有遗漏或不准确的地方,也希望朋友们能够帮忙指出与海涵。
首先,可以将 Transformer 模型看成一个黑盒:接收输入,进行预测,形成输出。这个黑盒可以用来翻译语言,也可以用来生成文章的摘要,或者判断一段文本内容所表达的情感等等。

将这个黑盒用于机器翻译
把这个黑盒稍微打开一点,会发现它包含了两个大的组件:Encoder(编码器)和 Decoder(解码器)。

这个黑盒包含编码器和解码器两大组件
编码器和解码器承担着各自的职责,它们共同完成从输入序列到输出序列的转换和生成过程:
- Encoder:将输入序列转化为一组连续的、固定长度的内部向量,这些向量已经捕捉了输入序列中的上下文语义信息。Encoder 的输出是 Decoder 的输入。
- Decoder:基于 Encoder 的输出向量和已经生成的部分输出内容进行计算,生成最终的预测结果。
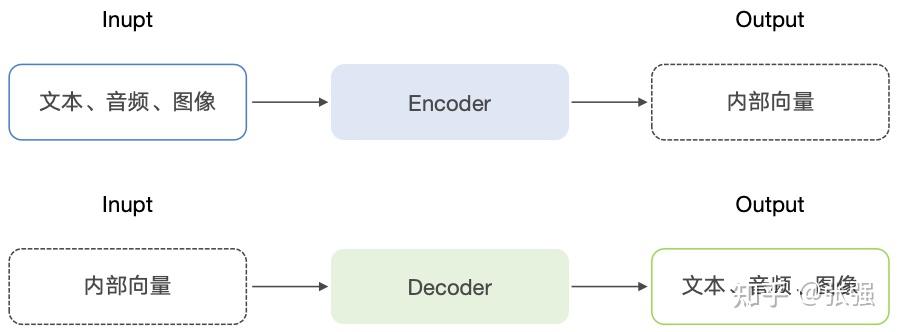
Encoder 和 Decoder 可以理解为将现实世界的问题转化为数学问题
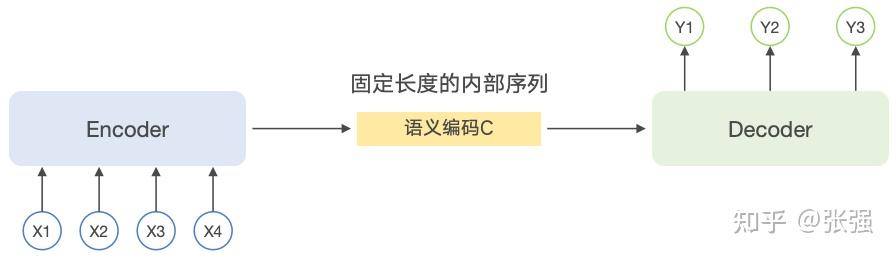
Encoder 和 Decoder 之间传递的内部向量是固定长度的语义编码
需要澄清的是,Encoder-Decoder 并非某一个具体的模型或者算法,也并非首创于 Transformer,而是一种解决问题的框架和思路,在早期的深度学习模型就已经开始使用,如循环神经网络(RNN),卷积神经网络(CNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)。Encoder-Decoder 这类模型常被用于处理 Seq2Seq(Sequence-to-Sequence,序列到序列)任务,而 Transformer 的出现又极大地推动了 Encoder-Decoder 架构的发展和应用。
不过,我们先暂时离开 Transformer,扩展一点 Seq2Seq 的知识。
Seq2Seq(Sequence to Sequence,序列到序列)是一种深度学习模型,主要用于处理序列数据,特别是那些具有不同长度的输入和输出序列的问题。Seq2Seq模型主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器和解码器通常会使用循环神经网络(RNN)或者它的变体,如长短期记忆网络(LSTM)。Seq2Seq 模型能够学习到输入序列和输出序列之间的复杂映射关系,从而实现对序列数据的生成和理解,因此在许多自然语言处理任务中都有应用,如机器翻译、文本摘要、问答系统、对话系统、文本生成、语音识别、语音转换等。
多种多样的 Seq2Seq 的任务类型
对于 RNN 这类经典的 Seq2Seq 模型,解码器进行解码的时候只会关注全局的内部的语义编码向量,并基于此进行解码,如下图所示:
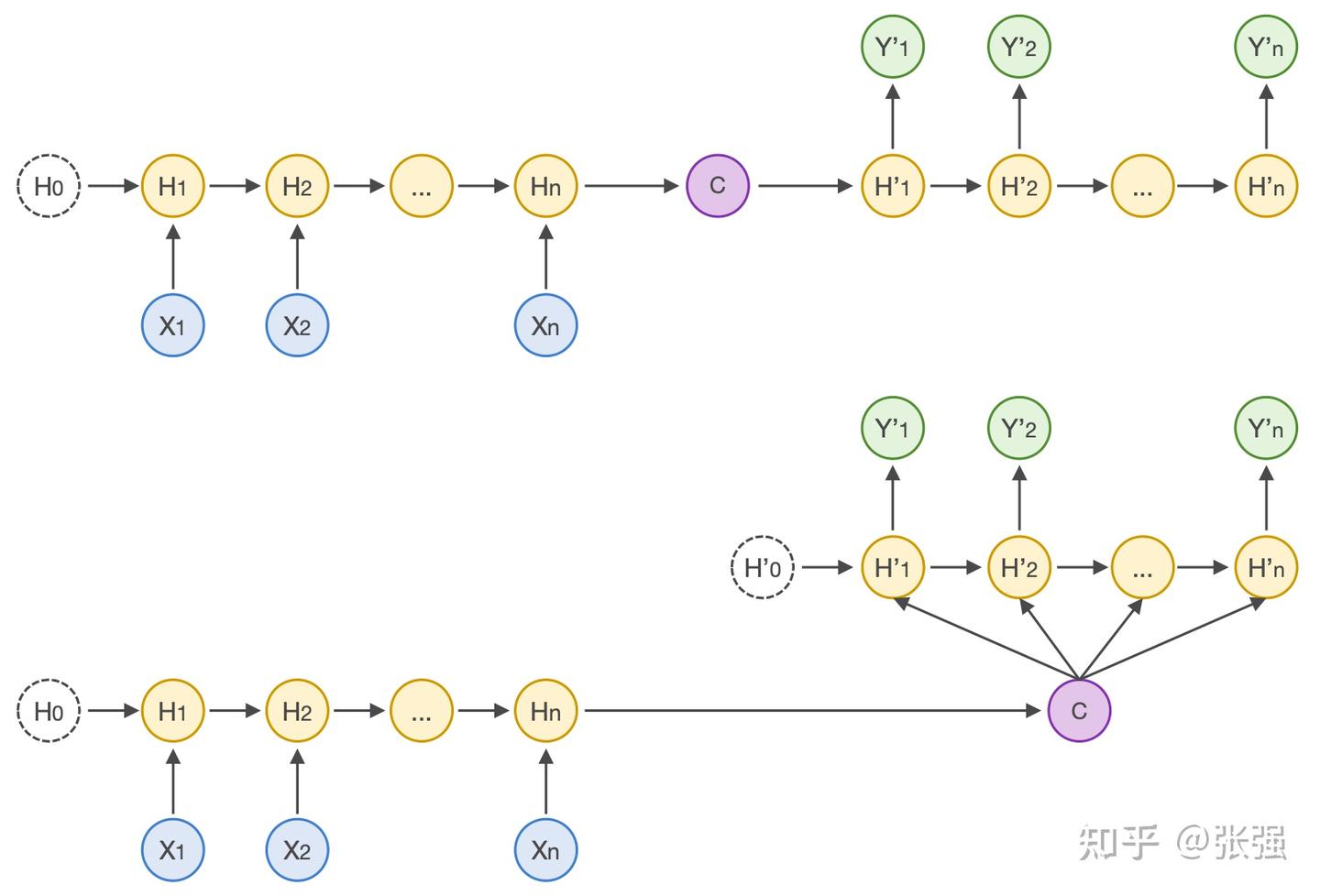
Seq2Seq 模型的两种结构类型
无论采用哪种结构,Decoder 进行解码时所采用的语义编码都是相同的,这意味着输入序列 X 的每一个单词对于输出序列 Y 的每一个单词的影响是一样的,也就是它们之间的关联度是相同的。但实际情况显然不应该是这样,每个输出和每个输入的关联度在绝大多数情况下是不同的。
而且,这种结构还会产生两个显著的问题:
- 内部的语义编码向量由于长度是固定的,必然涉及到对信息的压缩,导致很难完整表示整个输入序列的语义信息;
- 先输入的序列所携带的信息,会被后输入的序列所携带的信息“稀释掉”或“覆盖掉”,这样势必会对最终的解码输出的效果产生影响。
这使得解码一开始就无法获得足够的输入序列信息,从而影响解码的效果,输入序列长度越大,问题就越显著,这算是经典 RNN 的“原罪”吧。
继续回到 Transformer 上来。Transformer 的 Encoder 组件和 Decoder 组件都是由多个结构完全相同的原子组件堆叠而成。一般情况下,有多少个 Encoder,就有多少个 Decoder。Encoder 和 Decoder 是模型参数的主要载体。
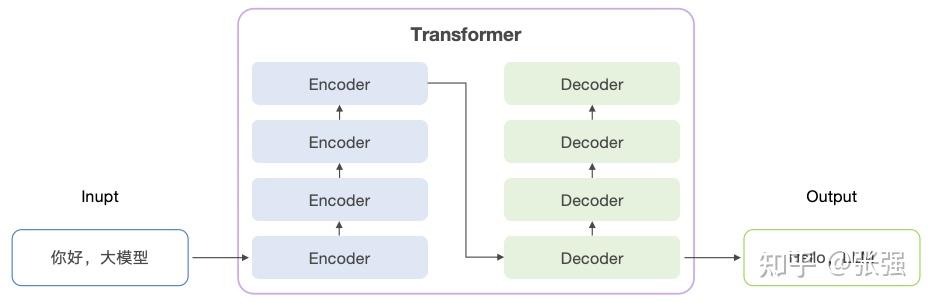
编码器和解码器均由多个原子组件堆叠而成
进一步打开编码器,每个 Encoder 的结构都是一样的,包括“自注意力层(Self-Attention Layer)”和“前馈神经网络层(Feed-Forward Neutral Network Layer)”。自注意力层帮助 Encoder 在对输入序列的每个词进行编码时,同时能够关注到其他的词,从而找到需要重点关注的部分。自注意力层的输出会输入到前馈神经网络层中作进一步的处理,输入序列的每个词所对应的前馈神经网络都是完全一样的。
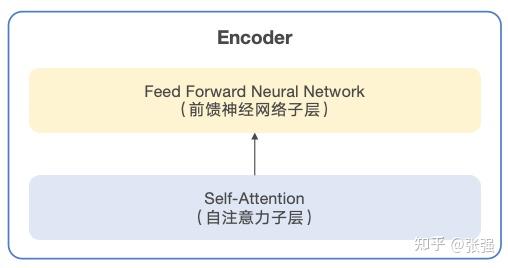
编码器的基本结构
不好意思,我们又绕出来了,先说说刚刚提到的重要概念:自注意力,即 Self-Attention。它是一种特殊的注意力,而注意力的提出又是为了解决上面所提到的 RNN 的问题,也就是 Decoder 在输出处理若只考虑 Encoder 输出的语义编码向量,可能会造成解码结果不够准确。为了改善效果,Decoder 在解码输出每一个词时,要同时考虑每个输入词对输出词的影响,这种影响或者说关联关系,就是注意力。
影响有大有小,关联关系有紧密有疏松,那么注意力自然也就有程度之分,它是可以通过计算获得的,也就是注意力得分(Attention Score)。本文主要从宏观的角度,尽可能用简单的语言讲述它的道理(不过,可能还是比较难懂,我尽力了……)。
还记得前面提到 RNN 网络结构时,Encoder 输出的是一个基于所有单词计算出来的、固定长度的语义编码向量么?而基于 Attention 的 Seq2Seq 模型中则并非如此,Encoder 输出的语义编码不固定,携带着一种“选择性的信息”,如下图所示:
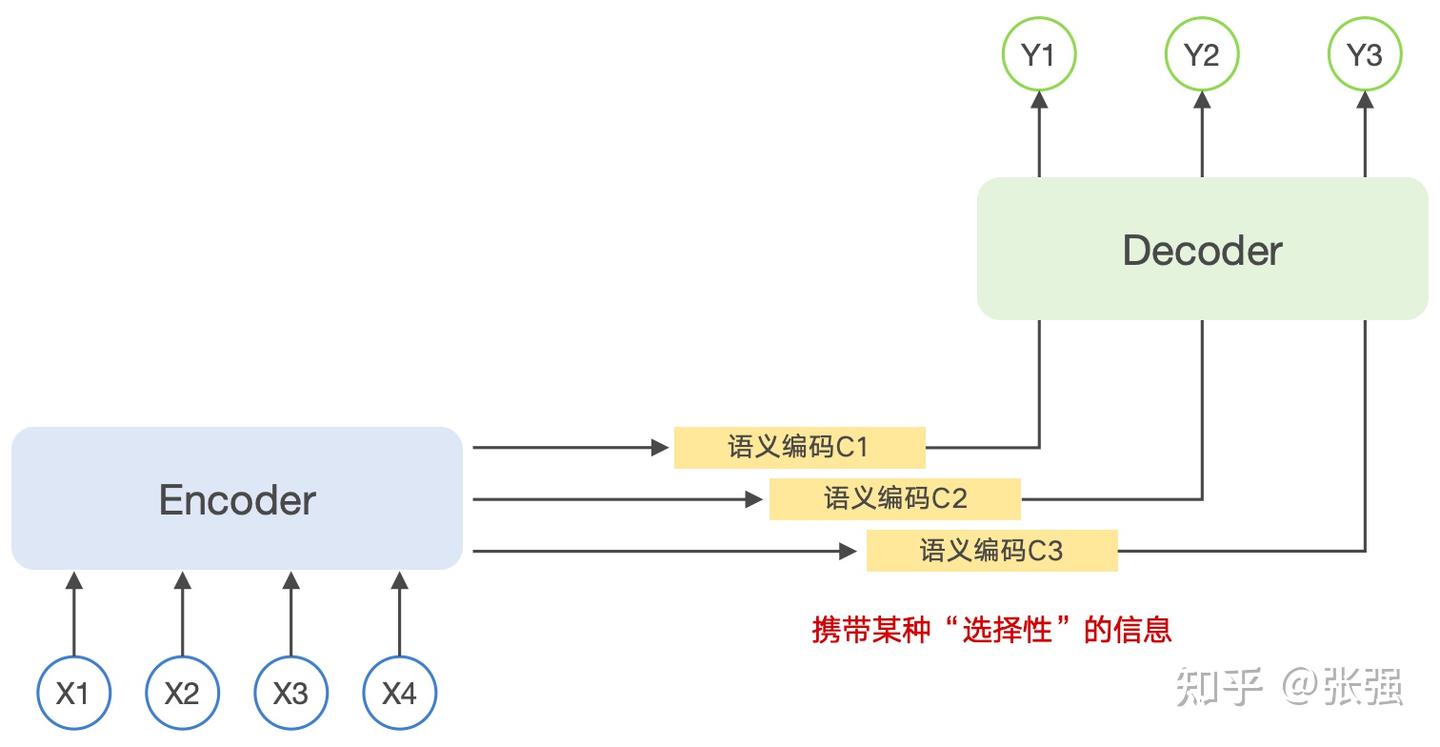
基于 Attention 的 Seq2Seq 模型结构
从这张图能够看到,在 Attention 机制下,Decoder 输出 Y1、Y2、Y3 每个词所基于的语义编码信息,即上下文信息都是不同的,可以简单表示为以下的公式:
Y1=f(C1) Y2=f(C2,Y1) Y3=f(C3,Y1,Y2)
需要注意的是,公式中 Encoder 输出的的 Ci 是语义编码信息,而不是注意力, Ci 需要根据 Encoder 中的各输入单词隐藏层状态和注意力得分进行加权求和得出。用 aij 代表注意力得分, hj 代表输入单词的隐藏层状态,其中: i 代表解码阶段,可以简单对应为解码第几个单词。 j 代表编码阶段,可以简单对应为编码第几个单词。
那么, aij 所表示的就是编码第 j 阶段(输入第 j 个单词)和解码第 i 阶段(输出第 i 个单词)的相关性大小。
举个机器翻译的例子,假设输入为“我爱中国”,输出就是“I Love China”。因此可以认为 Encoder 对应的隐藏层状态 、、、h1、h2、h3、h4 分别为“我”、“爱”、“中”、“国”,而 Decoder 对应的隐藏层状态 、、H1、H2、H3 分别为“I”、“Love”、“China”,并分别对应 Encoder 输出的三个编码向量 、、C1、C2、C3 ,如下图所示:
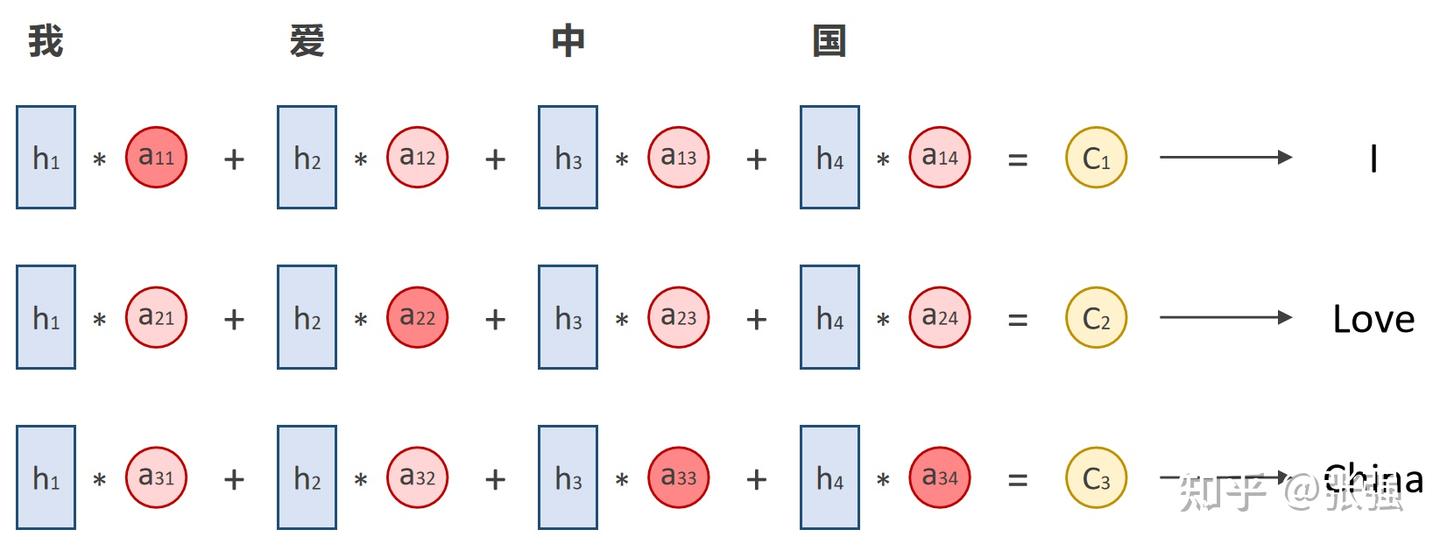
注意力机制宏观示意
上图深红色表示注意力得分较高,浅红色表示注意力得分较低,Encoder 输出的 、、C1、C2、C3 各不相同。而且,在输出第 1 个单词“I”的时候和输入的“我”的相关性最高,和其他词的相关性比较小;输出第 3 个单词“China”的时候和输入的“中”和“国”相关性最高,和其他词的相关性比较小。相关性越大,对输出的影响越大,自然应该分配更多的关注度;反之,相关性越小,对输出的影响越小,自然就应减少对其的关注多。这和人类在处理信息时的思路是趋同的。这就是 Attention 机制的宏观理解。
而 aij 是如何计算的?自注意力和注意力又有什么区别?这些知识更为复杂,计算过程涉及到大量矩阵操作,在《Transformer 架构解析:Self-Attention》一文中再详细进行介绍吧。
好了,花了一些篇幅介绍注意力机制,我们回来继续看 Transformer 的架构。打开 Decoder,同样包括“自注意力层”和“前馈神经网络层”。有所不同的是,在这两层之间,还有一个“Encoder-Decoder Attention Layer(编码器-解码器注意力层)”。
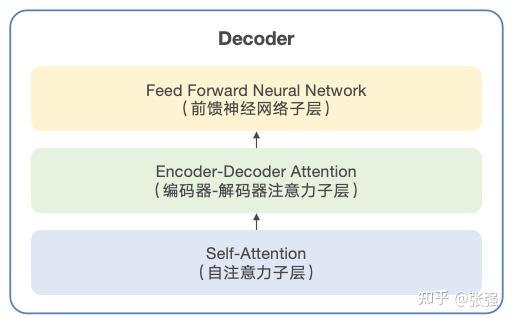
解码器的基本结构
为什么要有“编码器-解码器注意力”这一个子层呢?这主要和 Decoder 的工作原理有关系。前文提到,Decoder 的主要任务是根据 Encoder 的输出和先前生成的部分输出序列,来共同生成目标序列。自注意力子层会使 Decoder 仅聚焦先前已经生成的内容来进行预测,而不关注输入序列是什么;而中间的编码器-解码器注意力子层则允许 Decoder 从 Encoder 的输出中捕获上下文信息。这样设计相当于分别用两个子层来分担“减少对输出的干扰”和“关注输入的上下文”的责任,期望取得更优异的预测效果。这个过程如下图所示:
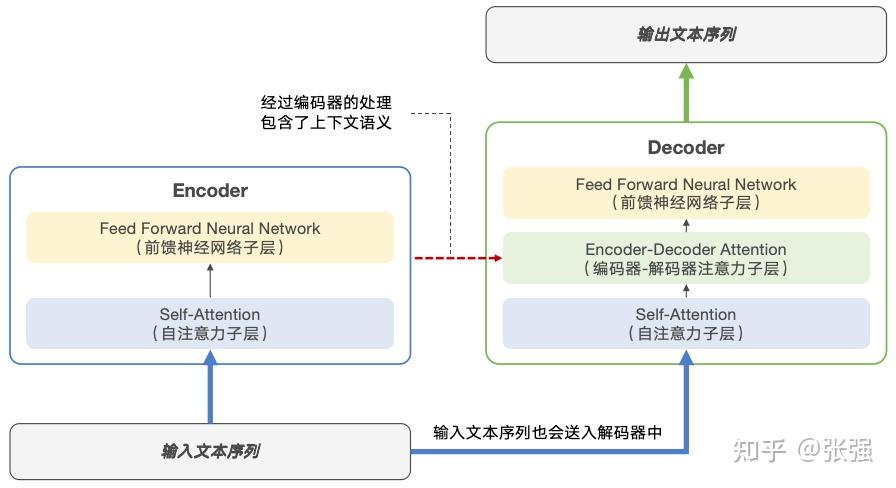
解码器和编码器的协同流程
于是,我们可以对这个黑盒的工作机制进一步描述为:Transformer 接收输入原始的文本序列,首先送入多层 Encoder 组件进行处理,然后再送到多层 Decoder 组件进行处理,最后输出预测结果的文本序列。这就是 Transformer 最基本的运行过程。
不过,需要说明的是,目前业界主流的大模型,虽然几乎都基于 Transformer 的架构思想,但未必和上面的标准 Transformer 架构完全一致(所谓标准架构,即《Attention Is All You Need》论文中提出的同时采用编码器和解码器的 Transformer):Google 的 BERT 只采用了 Encoder,即 Encoder-Only;Google 的 T5、清华的 GLM 则同时采用了 Encoder 和 Decoder,即 Encoder-Decoder,而 OpenAI 的 GPT,Meta 的 LLaMA、Stanford 的 Alpaca、UC Berkerly 的 Vicuna,还有一众兄弟都只采用了 Decoder,即 Decoder-Only。这三支队伍齐头并进,枝繁叶茂,可以看一看本系列的《大模型的演进旅程:Evolution & Stars》这篇笔记。
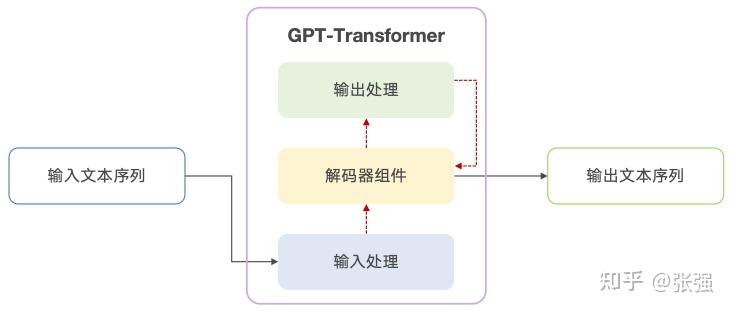
GPT-Transformer 基本结构
采用不同的结构,自然有其设计的初衷和适用的场景,这篇笔记就不再赘述了。后面关于 Transformer 架构分析的进阶笔记中,也主要以 Decoder-Only 为例展开。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)