解析稳定率达99.99%!“大模型加速器2.0”助力AI打破“幻觉”
为了让行业“安心”使用大模型,知识库产品推出溯源功能,通过在“投喂”给知识库的Markdown及JSON文件中标记页码、坐标等空间位置信息,实现对句子、段落的精确溯源,为用户提供了一个快速检验的路径。以财务分析为例,大模型在多份高达上千页的财报文件中找到收入、利润等关键数据后,券商分析师可利用溯源功能定位原表格,对信息进行复核,防止错误、遗漏。图说:知识库对财报数据所在表格进行精准溯源目前,知识库
随着大模型在社会应用中逐渐普及,人们在享受便利的同时,也面临着“AI 幻觉”产生的风险。训练数据是影响大模型“认知能力”的关键要素,近期,上海合合信息科技股份有限公司(简称“合合信息”)TextIn“大模型加速器 2.0”版本正式上线,基于领先的智能文档处理技术,对复杂文档的版式、布局和元素进行精准解析及结构化处理,从数据源头降低大模型“幻觉”风险,让大模型在与人类的沟通中“更靠谱”。
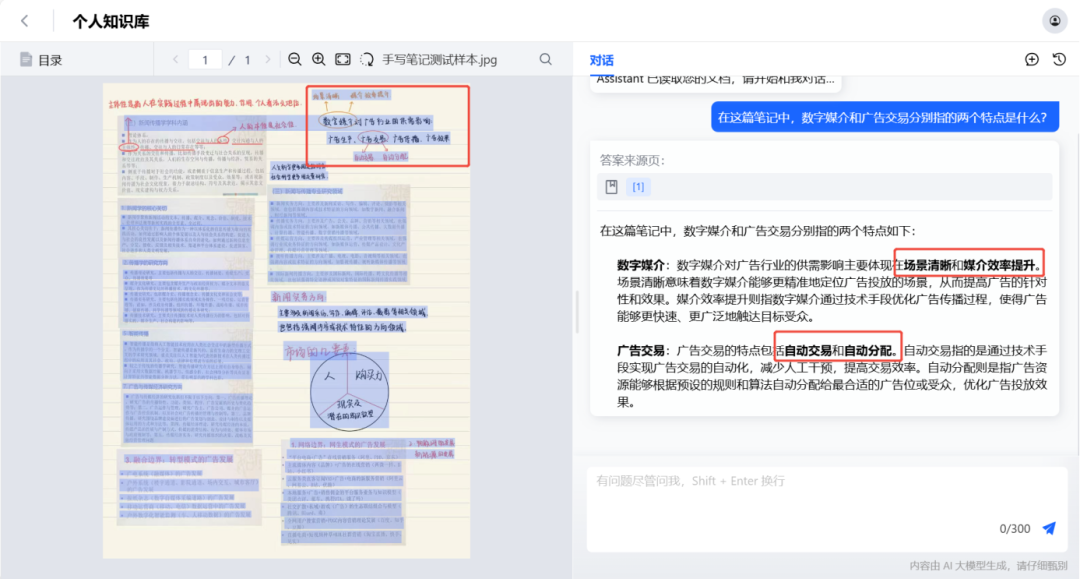 图说:“大模型加速器 2.0”文档解析引擎助力知识库理解手写笔记示意图
图说:“大模型加速器 2.0”文档解析引擎助力知识库理解手写笔记示意图
据悉,升级后的“大模型加速器”在复杂版面理解、表格及图表处理、内容溯源等能力上实现新突破,**可精准识别上千种文档中的跨页表格、合并单元格、密集表格、手写字符及公式,解析稳定率达99.99%,**单页处理耗时较行业可比产品降低超30%;可“逆还原”十余种专业图表数据,并将其转化为大模型可理解的结构化数据。此外,“大模型加速器 2.0”版本新增知识库系列开源组件,助力医疗、制造、教育等行业开发者构建个性化的知识库。
文档解析技术助力教育大模型建设
大模型需要不断“吸收”正确的专业知识,才能应对实际应用问题。合合信息技术团队成员表示,在处理年报、论文、实验室报告等专业文档的过程中,一个符号的解析失误,便可能“误导”大模型,得出与事实相悖的结论。可信性的缺失,也制约了大模型在实际应用场景中的纵深拓展。
赛尔教育科技发展有限公司(简称“赛尔教育”)系“中国教育和科研计算机网CERNET”的运营公司赛尔网络的重要子公司,是教育国际化、教育信息化、数字化教育方案的提供商。赛尔教育CTO、教育数字化事业部总经理杨林提到,教育行业中所涉及的文档格式多样,在内容上也包含了表格、公式、手写字符、多语言文字等信息。如何高效准确地提取各类文档中的文本信息,并非易事。
“教育行业的大模型建设工作中,数据的数量和质量起着决定性作用。我们做了很多尝试,模型的速度和准确性都达不到要求,严重影响科研工作的进展。”杨林表示,行业知识库的构建基于大量文档的文本信息提取,需要高效率、高准确率的工具。合合信息文档解析技术提供了专业的技术支持和服务,有效解决了文档处理过程中的问题。
在“大模型加速器”的支持下,合合信息与赛尔教育共同协作,提升大模型对复杂版面、元素的“理解力”,使其按照人类正常的阅读顺序识别文档结构,智能划分标题、段落、表格和图表等内容块,帮助大模型理解版面、内容间的对应关系,减少AI“幻觉”现象。
 图说:图表解析模块将图表还原为表格数据
图说:图表解析模块将图表还原为表格数据
除了复杂的版面布局,种类繁多、空间结构复杂的图表元素也是解析难点所在。“大模型加速器2.0”图表解析模块可智能提取多种图表中的关键数据点、坐标轴信息、图例说明等,在精准解析不同类型图表数据的基础上,将其还原为一组完整的Excel表格数据,作用于教育行业大模型微调,学科知识库建设、智能审阅等环节。
智能溯源让大模型用得更“安心”
近期,多家券商机构纷纷宣布接入大模型,帮助分析师、行业研究员等专业人士提高工作效率。为帮助用户简化专业文档数据筛选和数据抽取流程,提升文档内容解读效率与准确率,“大模型加速器 2.0” 上线了知识库产品组件,支持复杂文档的智能问答、总结与检索。
为了让行业“安心”使用大模型,知识库产品推出溯源功能,通过在“投喂”给知识库的Markdown及JSON文件中标记页码、坐标等空间位置信息,实现对句子、段落的精确溯源,为用户提供了一个快速检验的路径。以财务分析为例,大模型在多份高达上千页的财报文件中找到收入、利润等关键数据后,券商分析师可利用溯源功能定位原表格,对信息进行复核,防止错误、遗漏。
 图说:知识库对财报数据所在表格进行精准溯源
图说:知识库对财报数据所在表格进行精准溯源
目前,知识库组件已面向开发者开源,帮助其根据自身需要快速构建个性化行业知识库。此前,合合信息已开源智能文档处理“百宝箱”系列产品,解决文档解析精度低、解析效果评估难等问题,开发者可根据研发需求灵活搭配使用。未来,“大模型加速器”将持续优化迭代,助力大模型在各行各业中“百花齐放”。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 20
20 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)