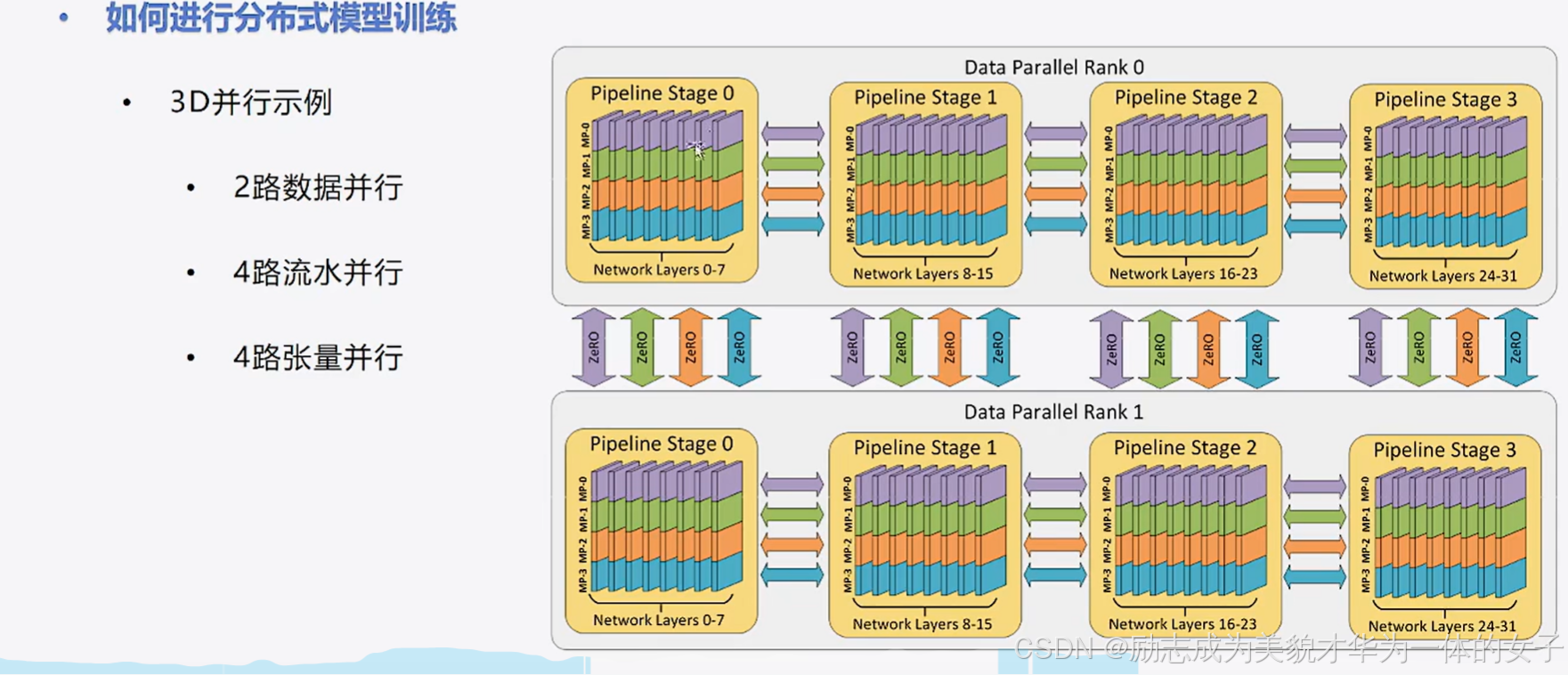
基于Acclerate的transformers模型分布式训练解决方案
数据并行、流水并行、张量(权重)并行:安装必要的库:transformers==4.36.2 accelerate==0.26.1 evaluate datasets - 阿里源。
个人学习记录笔记,本篇博文比较零散,不建议跟着学习。
数据并行、流水并行、张量(权重)并行:
安装必要的库:transformers==4.36.2 accelerate==0.26.1 evaluate datasets - 阿里源
数据并行(data parallel)
实现:每个 GPU保存完整的模型,只训练部分的数据。
单进程多线程只适合单机多卡,不支持多机多卡
2.1全部步骤:
(1)导入相关包
(2)加载数据
(3)创建dataset
(4)划分数据集
(5)创建dataloader
(6)创建模型及优化器
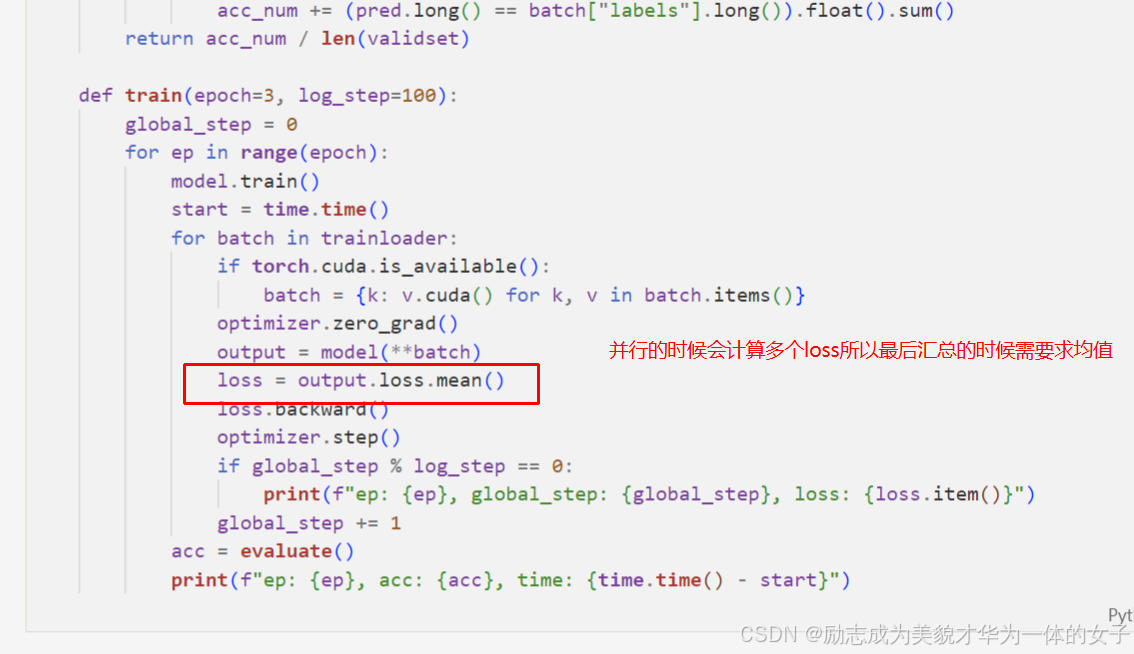
(7)训练与验证
训练得时候记下时间和batch_size
2.2实现并行时需要修改的代码,在创建模型的语句后加上这个语句:
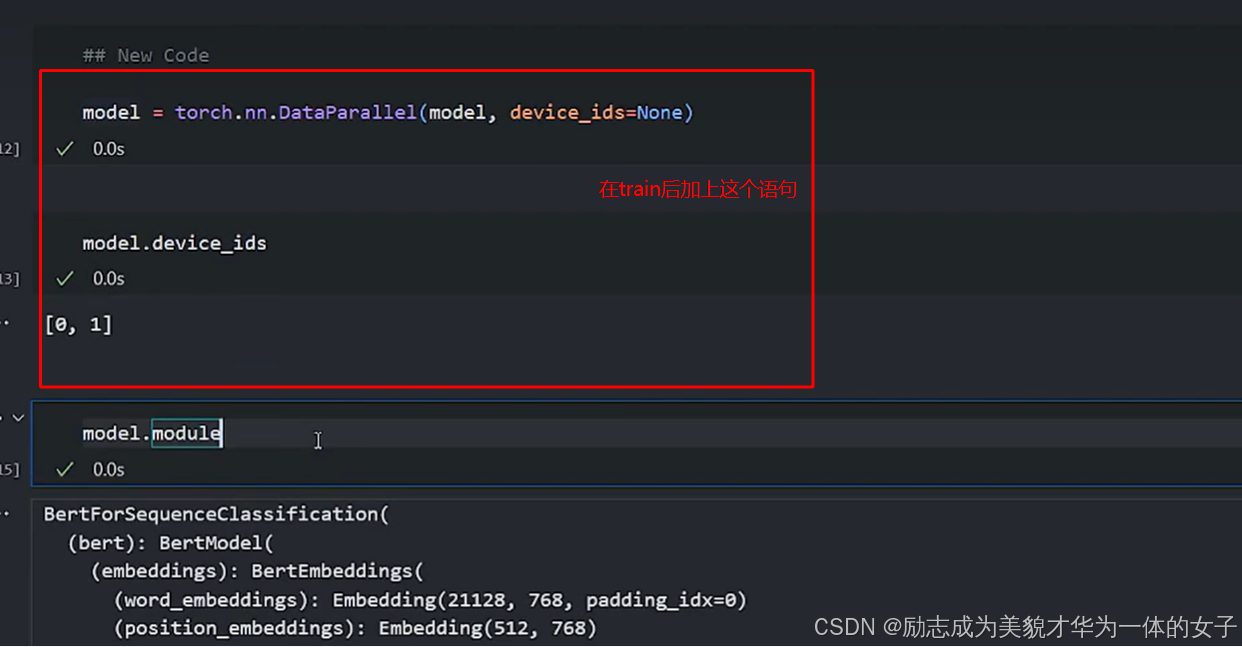
各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。
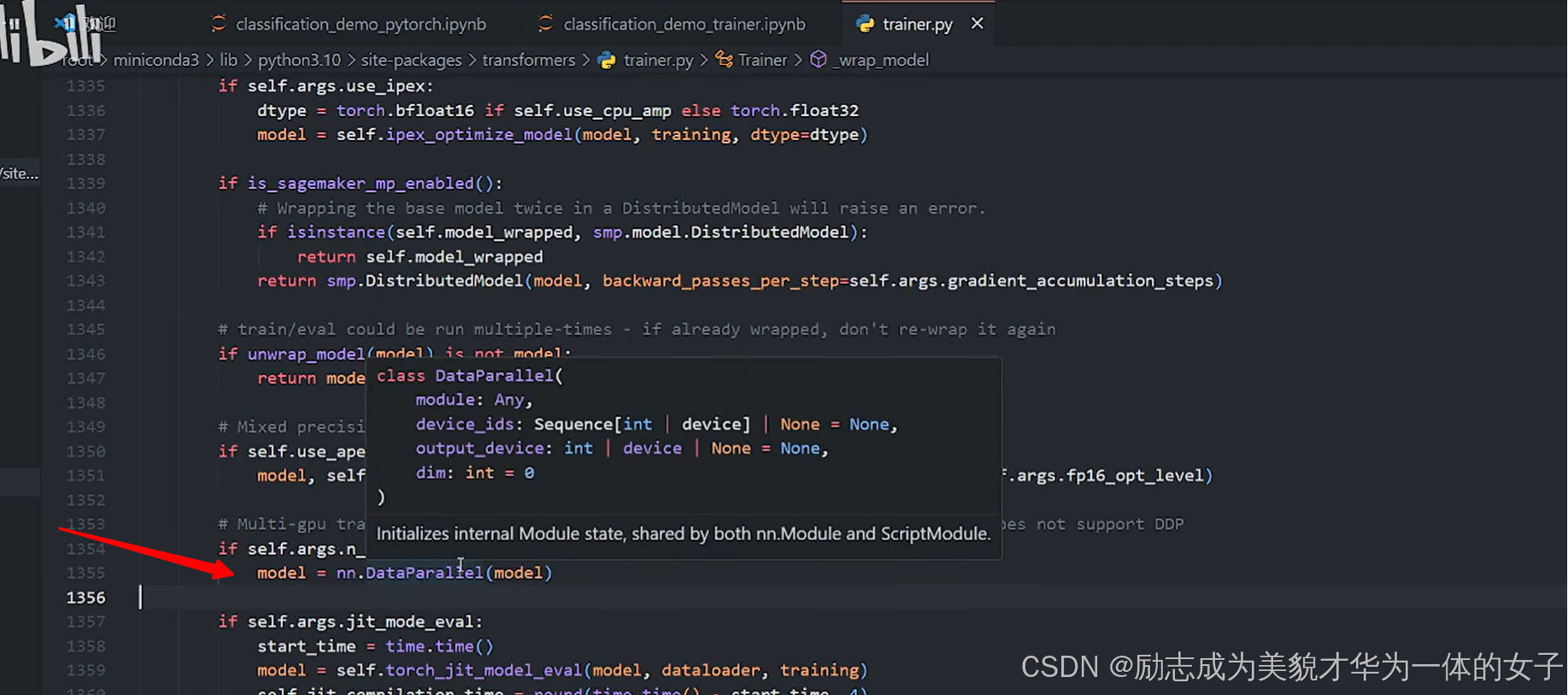
2.3 hugging face中trainer为什么可以自动dp,可以自查看其源码:
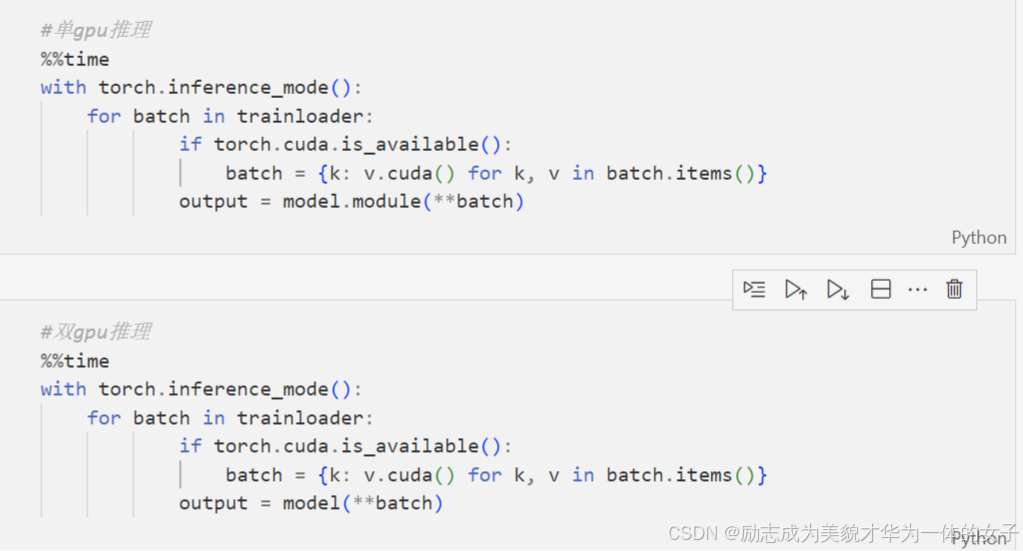
2.4 DataParallel 并行推理验证
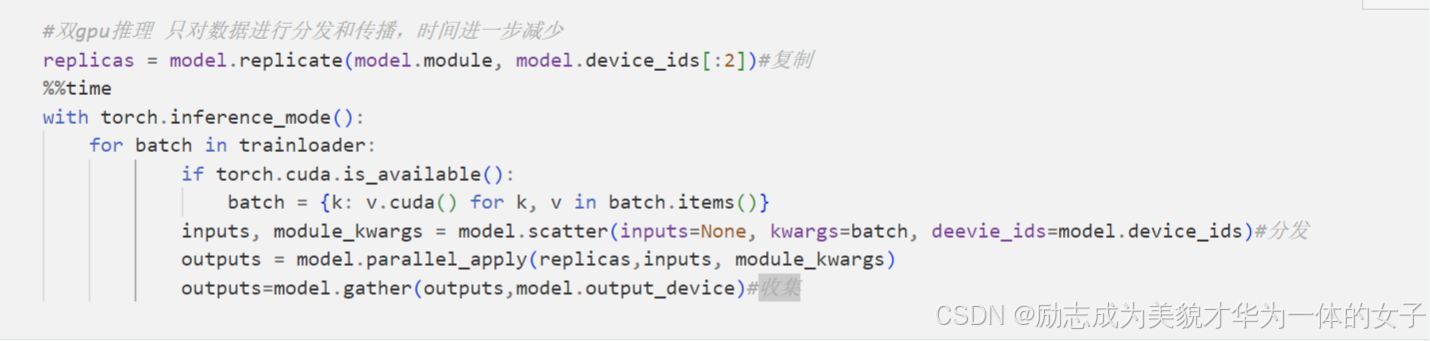
2.5
分布式数据并行
局部rank通常用于标识单个节点内部的计算单元(如GPU),而全局rank则用于标识整个分布式训练系统中的进程或节点。

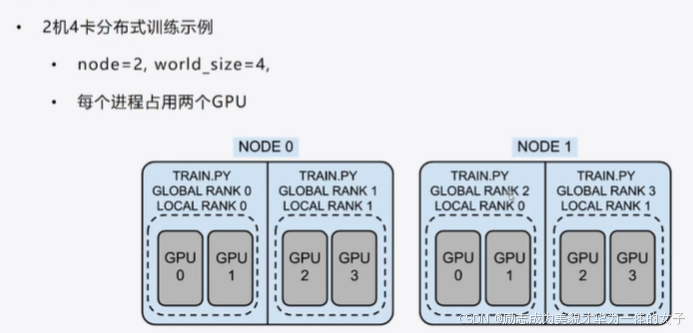
重点在第 5、6步,计算完之后各进程需要进行通信然后保持梯度同步

换成ddp
1.初始化一个分布式训练环境
import torch.distributed as dist#导入 PyTorch 的分布式训练模块
dist.init_process_group(backend="nccl")#初始化一个分布式训练的进程组,指定通信后端为 nccl2.实现不同的进程取不同的数据

3.对模型进行包装 DDP
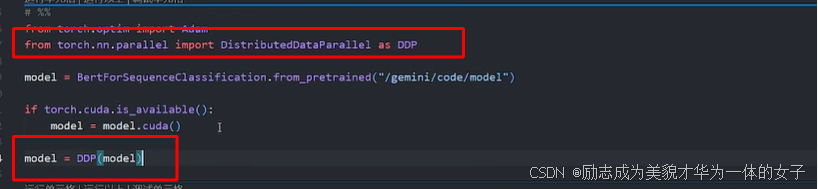
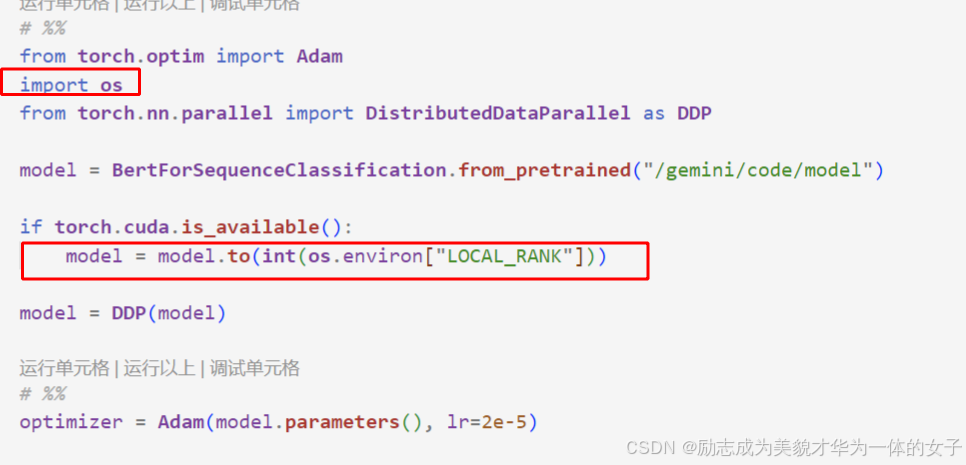
4.确定调用哪个gpu:用local rank拿到当前节点内的gpu序号
需要在环境变量里边取 import os
将所有的.cuda都换成to(int(os.environ["LOCAL_RANK"]))
5. 多进程启动任务:torchrun --nproc_per_node=2 ddp.py
6.之前在每个进程都是不一样的数据,所以损失值不一样,而且但是在评估的函数里除的是测试集样本总数,所以也不对,进行修改。
(1)对loss进行通信,现在loss打印的是各自计算的结果,需要同步。
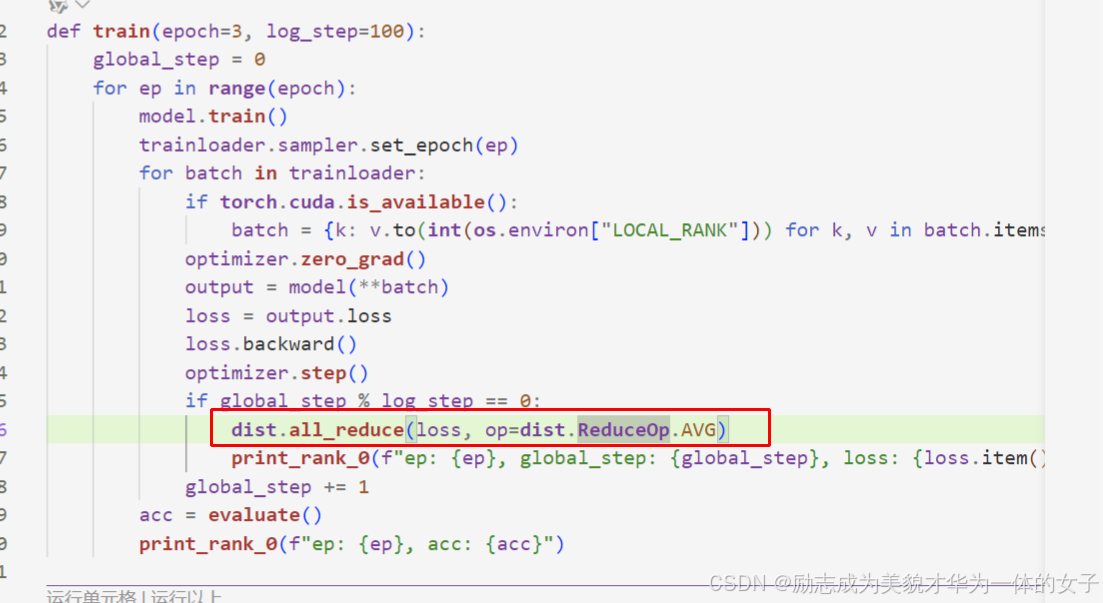
限制只打印一次,只在global rank0里打印。
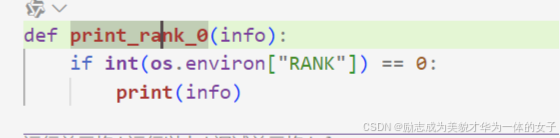

(2)评估值 也需要进行通信
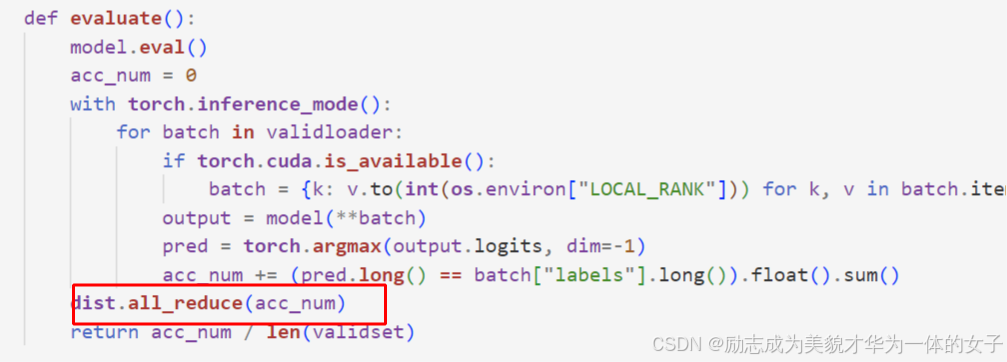
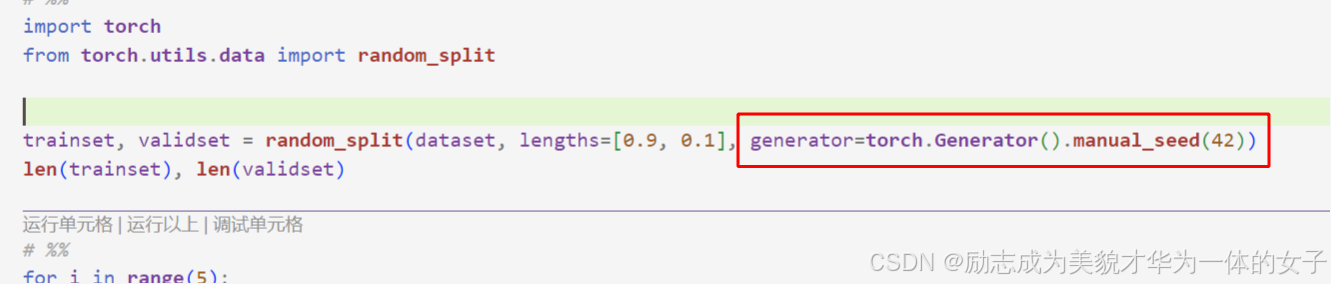
7.保证每个进程内划分的数据一致
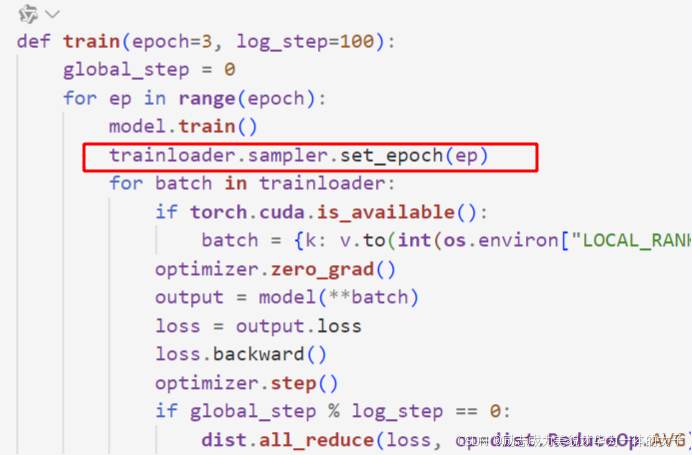
8. 每次都打乱顺序。
9.batch_size是原来的2倍
10. 如果数据不能均匀切开,distributed会填充使得一致。
11.transformer trainer实现ddp 不用怎么改代码都。
结果虚高的话,还是设置一下数据加载的随机种子


Accelerate
1.数据加载上不再需要DistributedSampler
2.模型不再需要手动的放到设备上:model.to(int(os.environ["LOCAL_RANK"]))
3.不再需要初始化进程组;dist.init_process_group(backend="nccl")
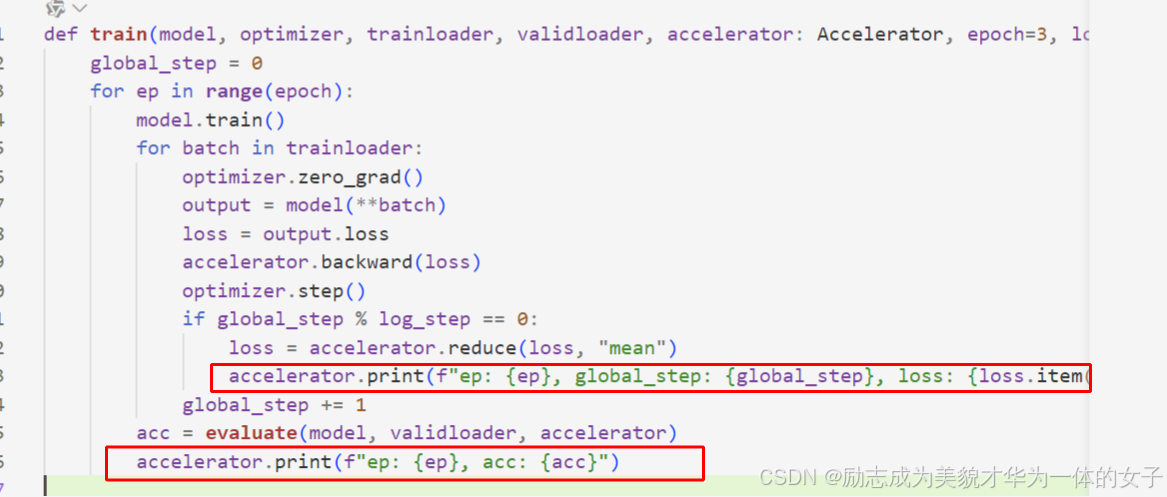
4.train时调用了accelerator.reduce和print代替之前指定rank打印和dist的通信方法。
5.train时不再需要 trainloader.sampler.set_epoch(ep)(确保每个epoch开始时不同的节点有不同的数据,同时打乱顺序)
6.evaluate时调用了accelerator.gather_for_metrics代替 dist.all_reduce计算最终的结果。

使用 accelerator 对象的 gather_for_metrics 方法对预测值 pred 和标签 batch["labels"] 进行聚合,以便在分布式训练或多 GPU 训练中收集所有进程的数据。

调accelerator的reduce方法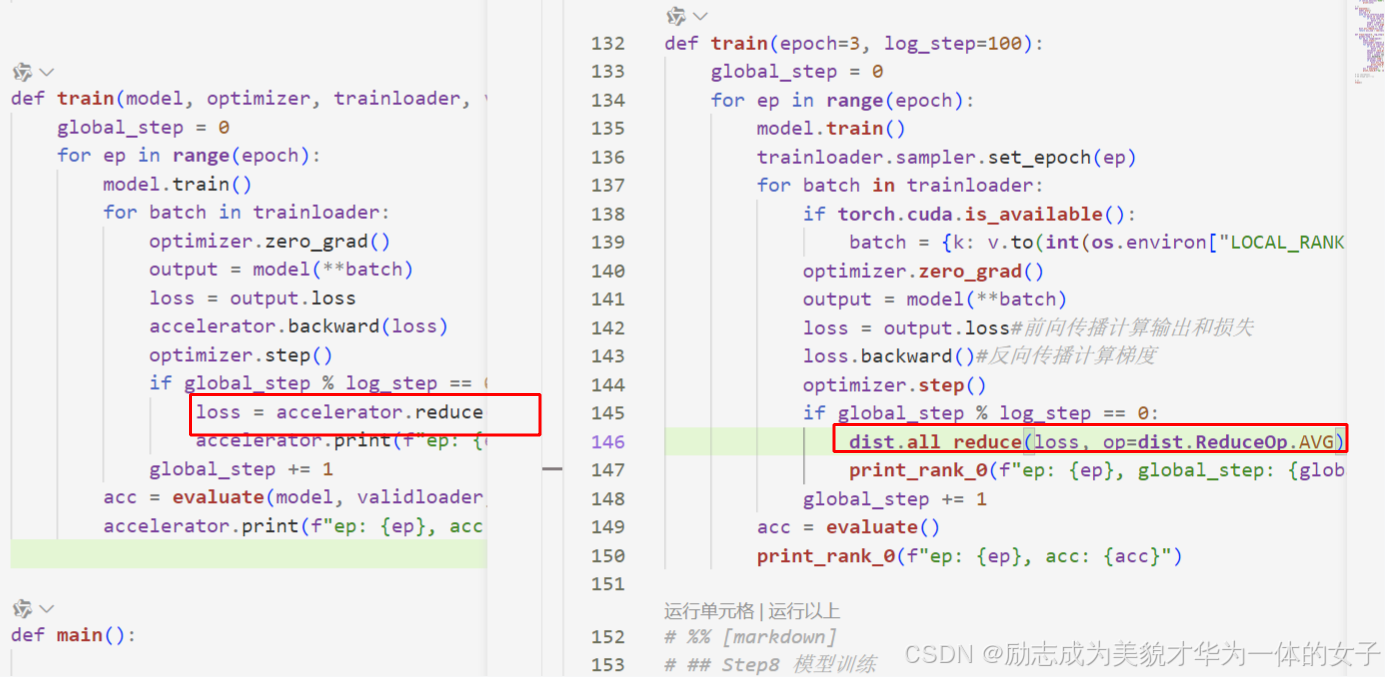
调用accelerator.print实现打印一次
acclerate的启动命令:accelerate lanch 文件名
accelerate config可以打开参数设置界面。
Accelerate 进阶
混合精度训练
三种启动方式:
accelerator = Accelertor(mixed_precision="bf16")
accelerate config --选择bf16--accelerate launch 文件名
accelerate launch --mixed_precision bf16 文件名
梯度累积

实验记录


启动tensorboard
ctrl+shift+p:输入tensorboard,选择调动哪个目录。
模型保存

Deepspeed
在将配置文件放到目录下后运行指定配置文件:accelerate launch --config_file default_config.yaml 文件名
参考说明
【手把手带你实战HuggingFace Transformers-分布式训练篇】分布式训练与环境配置_哔哩哔哩_bilibili

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)