论文笔记——early convolutions help transformers see better
一、motivation二、solution
·
一、motivation
Vision transformer (ViT) models exhibit substandard optimizability. In particular,they are sensitive to the choice of optimizer (AdamW vs. SGD), optimizer hyperparameters, and training schedule length. In comparison, modern convolutional neuralnetworks are easier to optimize。
问题假设为:
In this work, we conjecturethat the issue lies with the patchify stem of ViT models, which is implemented bya stride-p p×p convolution (p = 16 by default) applied to the input image. Thislarge-kernel plus large-stride convolution runs counter to typical design choicesof convolutional layers in neural networks.In this paper we hypothesize that the issues lies primarily in the early visual processing performed by ViT.
二、solution
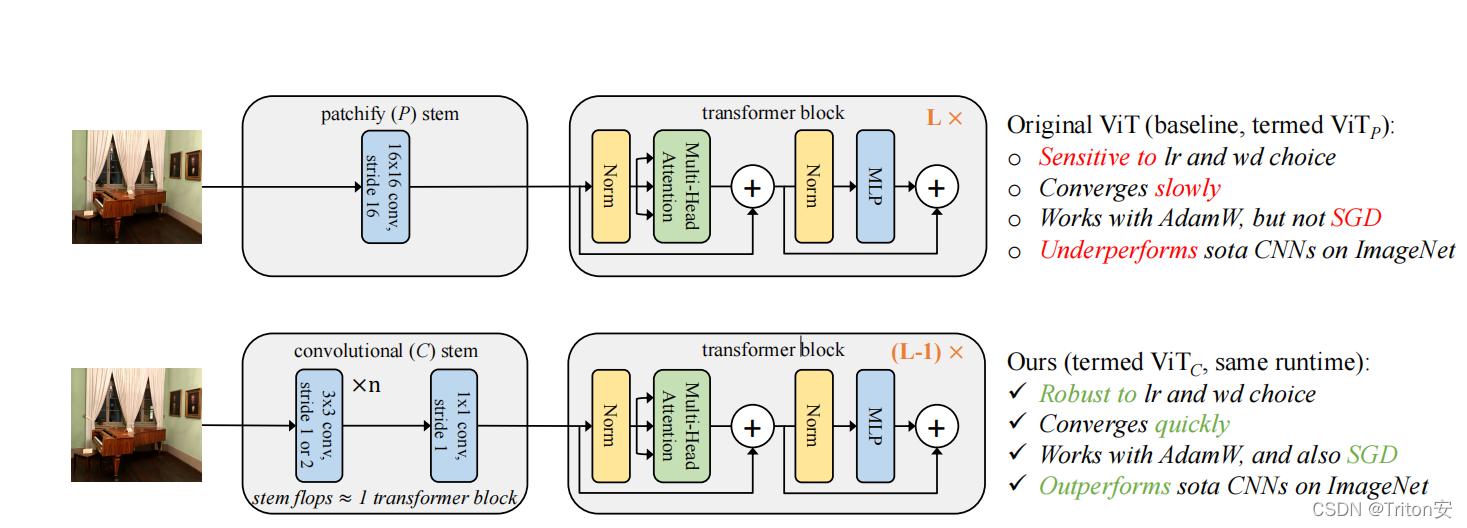

个人认为文章里面有一个很好的思路:


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)