阿里云部署langchain+ChatGLM2-6B本地知识库实战加踩坑
2>ChatGLM2-6B在web_demo.py和web_demo2.py中都把tokenizer和model的路径修改为本地chatlm2-6b的路径。<1>chatglm2-6bchatglm2-6b模型在目录的config.json文件中修改"_name_or_path"**注意:**此处可能会出现cuda和pytorch不匹配的问题(如下图),**例外:**当然还有遇到的上传文档显示报4
阿里云部署langchain+ChatGLM2-6B本地知识库实战加踩坑
1、白嫖阿里云的算力

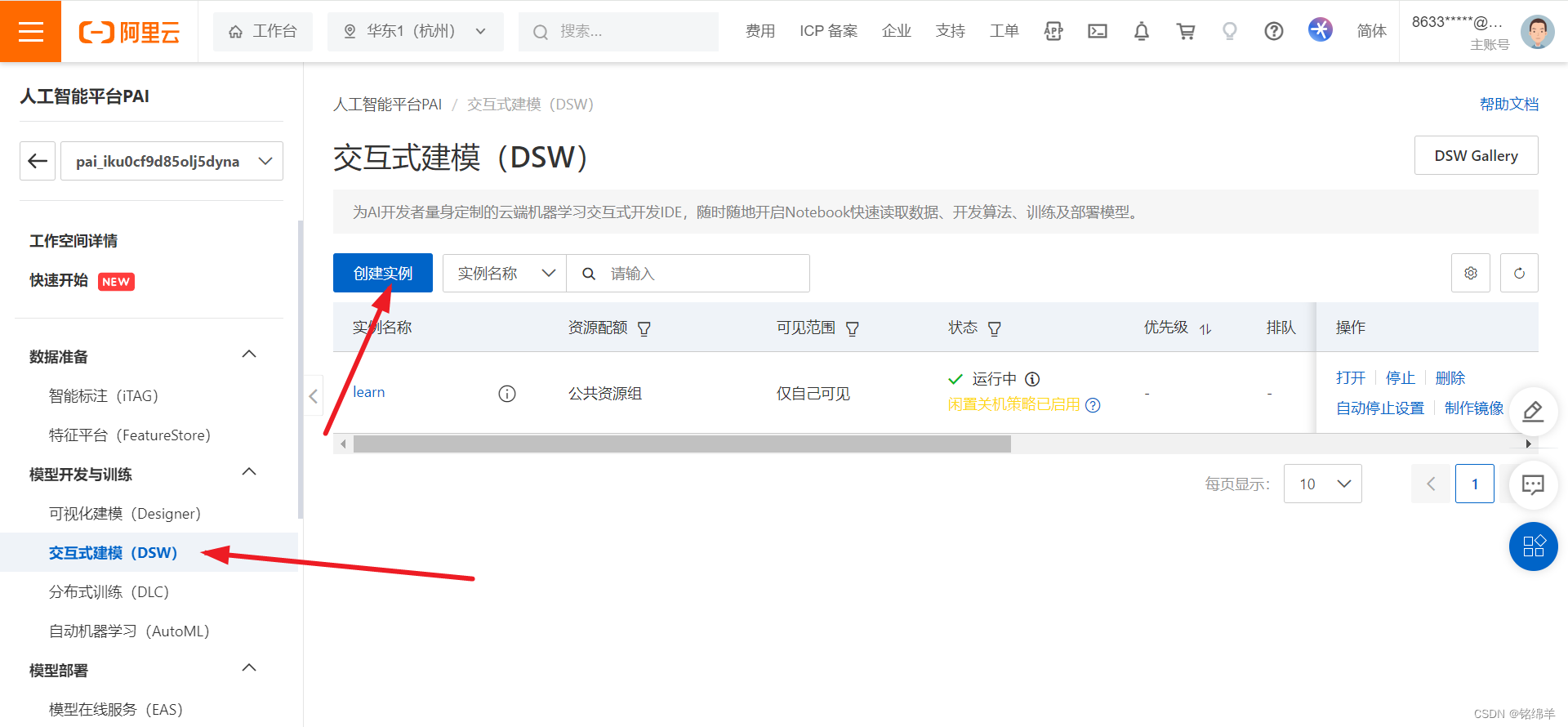



创建实例,等待机器启动即可。
创建机器完成。
2、点击打开,进入到阿里云的idea界面,通过Terminal进入控制台。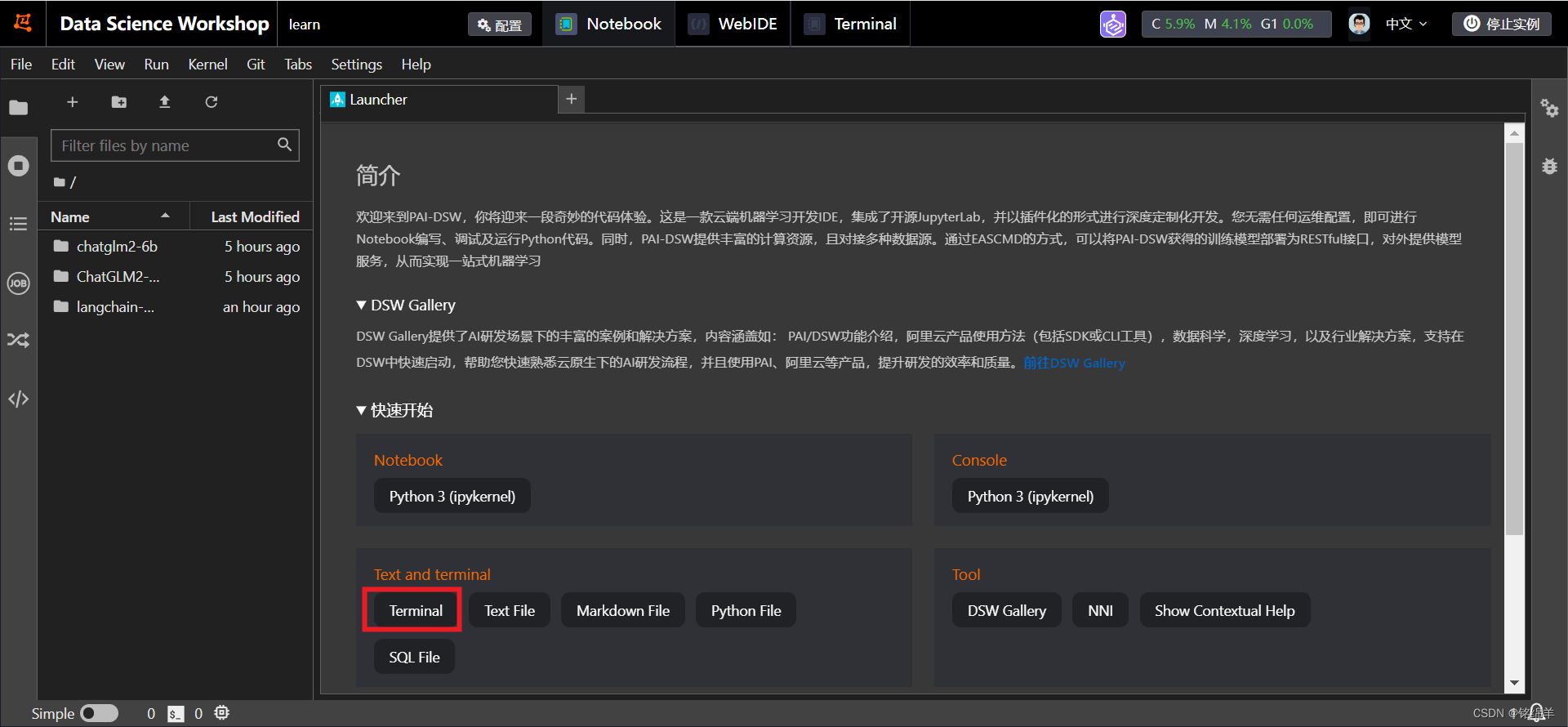
3、重点部署内容
(1)更新git及相关内容
apt-get update
apt-get install git-lfs
git init
git lfs install
(2)下载相关包
git clone https://github.com/THUDM/ChatGLM2-6B.git
git clone https://www.modelscope.cn/ZhipuAI/chatglm2-6b.git
#git clone https://github.com/chatchat-space/Langchain-Chatchat.git 这两个是一样的不过下载的文件夹名字不一样
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
cd langchain-ChatGLM
git clone https://www.modelscope.cn/xrunda/m3e-base.git
git clone https://www.modelscope.cn/thomas/text2vec-base-chinese.git
分别在/ChatGLM2-6B 和/langchain-ChatGLM目录下下载依赖
pip install –r requirements.txt
注意:
这里在按照依赖的时候会报错,不影响使用,再重新pip install –r requirements.txt即可
(3)重头戏相关
修改模型的相关内容(通过WebIDE进行修改) <1> chatglm2-6b chatglm2-6b模型在目录的config.json文件中修改"_name_or_path"
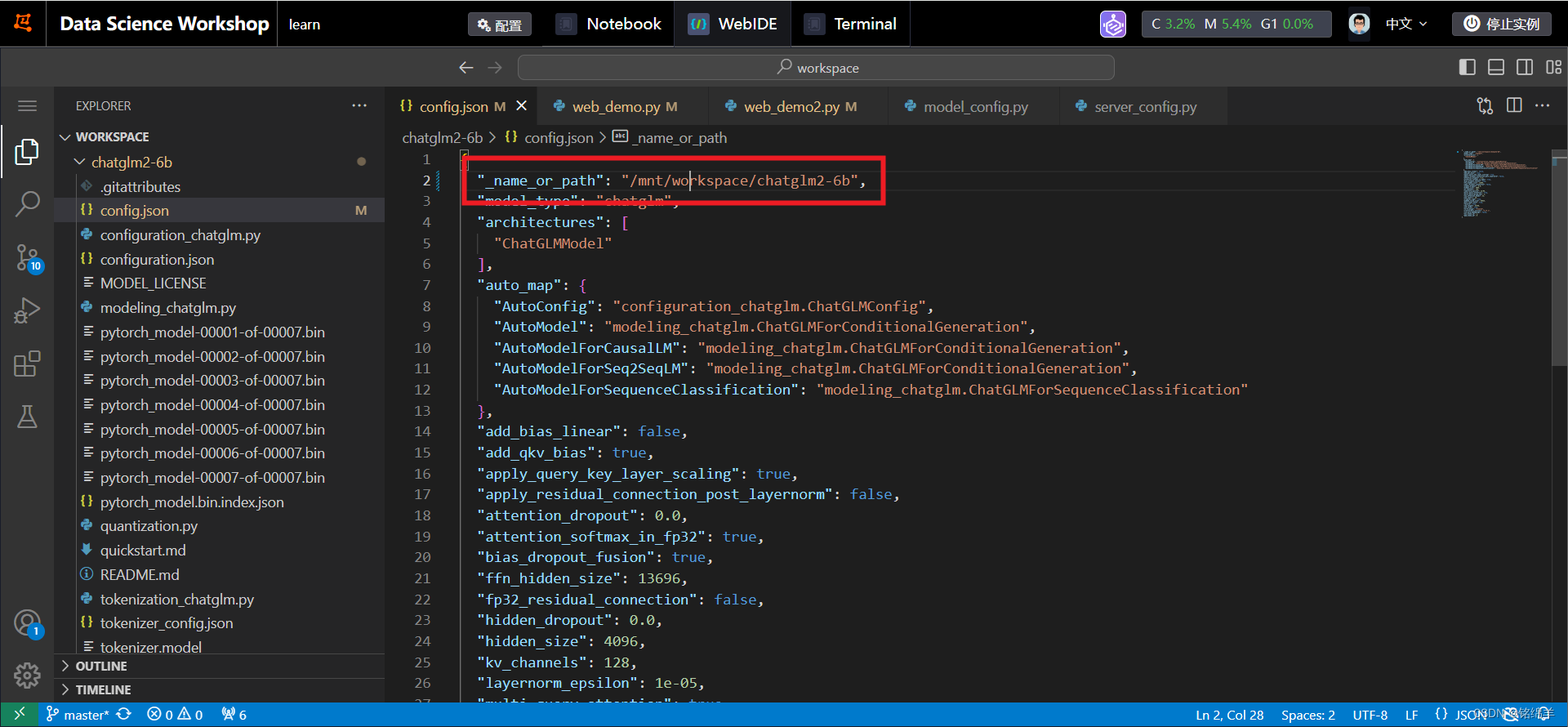
<1> chatglm2-6b chatglm2-6b模型在目录的config.json文件中修改"_name_or_path"
"_name_or_path": "/mnt/workspace/chatglm2-6b",
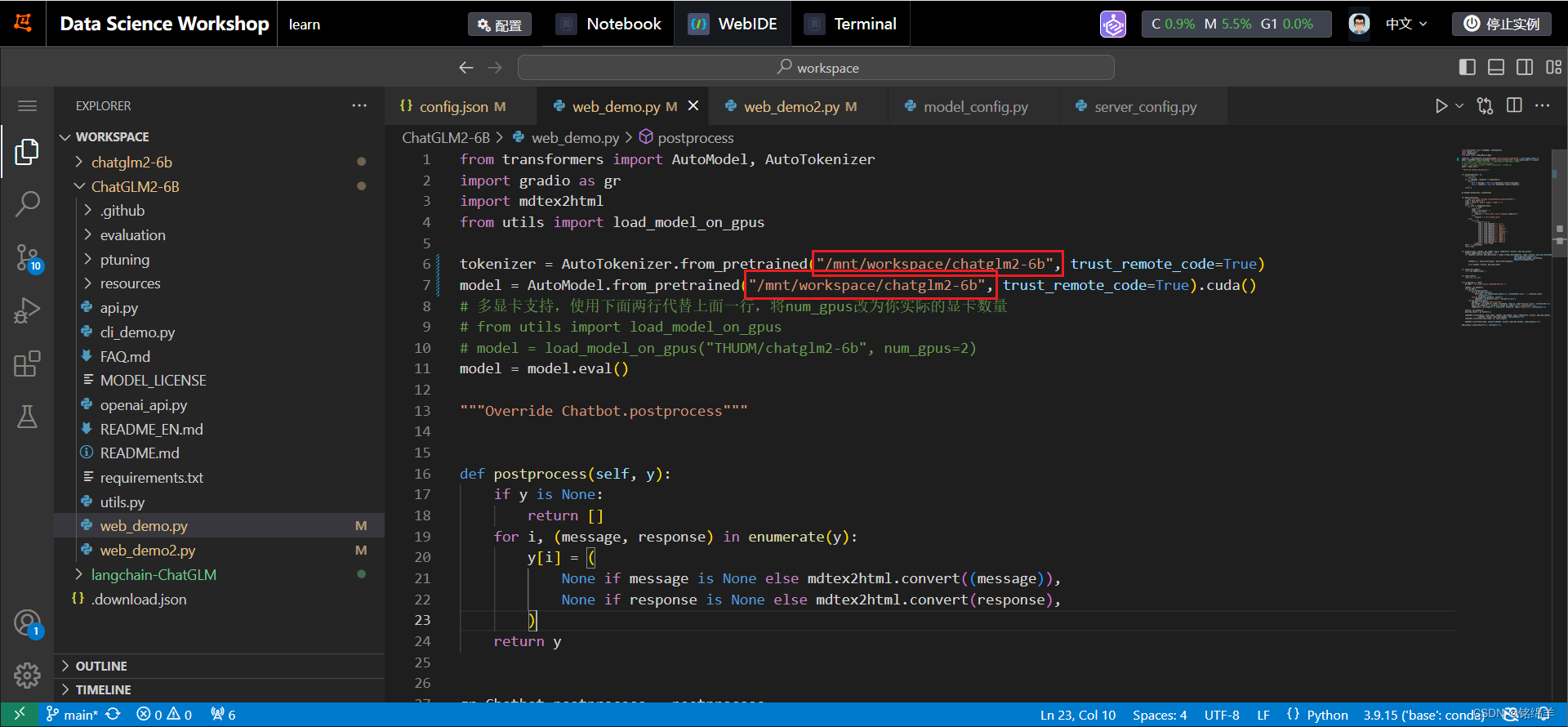
<2> ChatGLM2-6B 在web_demo.py和web_demo2.py中都把tokenizer和model的路径修改为本地chatlm2-6b的路径
tokenizer = AutoTokenizer.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/mnt/workspace/chatglm2-6b", trust_remote_code=True).cuda()
<3> langchain-ChatGLM 修改configs目录下的文件后面的.example都去掉
- 修改model_config.py(完全替换内容即可)
import os
# 可以指定一个绝对路径,统一存放所有的Embedding和LLM模型。
# 每个模型可以是一个单独的目录,也可以是某个目录下的二级子目录。
# 如果模型目录名称和 MODEL_PATH 中的 key 或 value 相同,程序会自动检测加载,无需修改 MODEL_PATH 中的路径。
MODEL_ROOT_PATH = ""
# 选用的 Embedding 名称
# EMBEDDING_MODEL = "bge-large-zh-v1.5"
EMBEDDING_MODEL = "m3e-base"
# Embedding 模型运行设备。设为 "auto" 会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
EMBEDDING_DEVICE = "auto"
# 选用的reranker模型
RERANKER_MODEL = "bge-reranker-large"
# 是否启用reranker模型
USE_RERANKER = False
RERANKER_MAX_LENGTH = 1024
# 如果需要在 EMBEDDING_MODEL 中增加自定义的关键字时配置
EMBEDDING_KEYWORD_FILE = "keywords.txt"
EMBEDDING_MODEL_OUTPUT_PATH = "output"
# 要运行的 LLM 名称,可以包括本地模型和在线模型。列表中本地模型将在启动项目时全部加载。
# 列表中第一个模型将作为 API 和 WEBUI 的默认模型。
# 在这里,我们使用目前主流的两个离线模型,其中,chatglm3-6b 为默认加载模型。
# 如果你的显存不足,可使用 Qwen-1_8B-Chat, 该模型 FP16 仅需 3.8G显存。
# LLM_MODELS = ["chatglm3-6b", "zhipu-api", "openai-api"]
LLM_MODELS = ["chatglm2-6b"]
Agent_MODEL = None
# LLM 模型运行设备。设为"auto"会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
LLM_DEVICE = "auto"
HISTORY_LEN = 3
MAX_TOKENS = 2048
TEMPERATURE = 0.7
ONLINE_LLM_MODEL = {
# "openai-api": {
# "model_name": "gpt-4",
# "api_base_url": "https://api.openai.com/v1",
# "api_key": "",
# "openai_proxy": "",
# },
# # 智谱AI API,具体注册及api key获取请前往 http://open.bigmodel.cn
# "zhipu-api": {
# "api_key": "",
# "version": "glm-4",
# "provider": "ChatGLMWorker",
# },
# # 具体注册及api key获取请前往 https://api.minimax.chat/
# "minimax-api": {
# "group_id": "",
# "api_key": "",
# "is_pro": False,
# "provider": "MiniMaxWorker",
# },
# # 具体注册及api key获取请前往 https://xinghuo.xfyun.cn/
# "xinghuo-api": {
# "APPID": "",
# "APISecret": "",
# "api_key": "",
# "version": "v3.5", # 你使用的讯飞星火大模型版本,可选包括 "v3.5","v3.0", "v2.0", "v1.5"
# "provider": "XingHuoWorker",
# },
# # 百度千帆 API,申请方式请参考 https://cloud.baidu.com/doc/WENXINWORKSHOP/s/4lilb2lpf
# "qianfan-api": {
# "version": "ERNIE-Bot", # 注意大小写。当前支持 "ERNIE-Bot" 或 "ERNIE-Bot-turbo", 更多的见官方文档。
# "version_url": "", # 也可以不填写version,直接填写在千帆申请模型发布的API地址
# "api_key": "",
# "secret_key": "",
# "provider": "QianFanWorker",
# },
# # 火山方舟 API,文档参考 https://www.volcengine.com/docs/82379
# "fangzhou-api": {
# "version": "chatglm-6b-model",
# "version_url": "",
# "api_key": "",
# "secret_key": "",
# "provider": "FangZhouWorker",
# },
# # 阿里云通义千问 API,文档参考 https://help.aliyun.com/zh/dashscope/developer-reference/api-details
# "qwen-api": {
# "version": "qwen-max",
# "api_key": "",
# "provider": "QwenWorker",
# "embed_model": "text-embedding-v1" # embedding 模型名称
# },
# # 百川 API,申请方式请参考 https://www.baichuan-ai.com/home#api-enter
# "baichuan-api": {
# "version": "Baichuan2-53B",
# "api_key": "",
# "secret_key": "",
# "provider": "BaiChuanWorker",
# },
# # Azure API
# "azure-api": {
# "deployment_name": "", # 部署容器的名字
# "resource_name": "", # https://{resource_name}.openai.azure.com/openai/ 填写resource_name的部分,其他部分不要填写
# "api_version": "", # API的版本,不是模型版本
# "api_key": "",
# "provider": "AzureWorker",
# },
# # 昆仑万维天工 API https://model-platform.tiangong.cn/
# "tiangong-api": {
# "version": "SkyChat-MegaVerse",
# "api_key": "",
# "secret_key": "",
# "provider": "TianGongWorker",
# },
# # Gemini API https://makersuite.google.com/app/apikey
# "gemini-api": {
# "api_key": "",
# "provider": "GeminiWorker",
# },
# # Claude API : https://www.anthropic.com/api
# # Available models:
# # Claude 3 Opus: claude-3-opus-20240229
# # Claude 3 Sonnet claude-3-sonnet-20240229
# # Claude 3 Haiku claude-3-haiku-20240307
# "claude-api": {
# "api_key": "",
# "version": "2023-06-01",
# "model_name":"claude-3-opus-20240229",
# "provider": "ClaudeWorker",
# }
}
# 在以下字典中修改属性值,以指定本地embedding模型存储位置。支持3种设置方法:
# 1、将对应的值修改为模型绝对路径
# 2、不修改此处的值(以 text2vec 为例):
# 2.1 如果{MODEL_ROOT_PATH}下存在如下任一子目录:
# - text2vec
# - GanymedeNil/text2vec-large-chinese
# - text2vec-large-chinese
# 2.2 如果以上本地路径不存在,则使用huggingface模型
MODEL_PATH = {
"embed_model": {
# "ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
# "ernie-base": "nghuyong/ernie-3.0-base-zh",
# "text2vec-base": "shibing624/text2vec-base-chinese",
# "text2vec": "GanymedeNil/text2vec-large-chinese",
# "text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
# "text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
# "text2vec-multilingual": "shibing624/text2vec-base-multilingual",
# "text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese",
# "m3e-small": "moka-ai/m3e-small",
"m3e-base": "/mnt/workspace/langchain-ChatGLM/m3e-base",
# "m3e-base": "moka-ai/m3e-base",
# "m3e-large": "moka-ai/m3e-large",
# "bge-small-zh": "BAAI/bge-small-zh",
# "bge-base-zh": "BAAI/bge-base-zh",
# "bge-large-zh": "BAAI/bge-large-zh",
# "bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
# "bge-base-zh-v1.5": "BAAI/bge-base-zh-v1.5",
# "bge-large-zh-v1.5": "BAAI/bge-large-zh-v1.5",
# "bge-m3": "BAAI/bge-m3",
# "piccolo-base-zh": "sensenova/piccolo-base-zh",
# "piccolo-large-zh": "sensenova/piccolo-large-zh",
# "nlp_gte_sentence-embedding_chinese-large": "damo/nlp_gte_sentence-embedding_chinese-large",
"text2vec-base-chinese": "/mnt/workspace/langchain-ChatGLM/text2vec-base-chinese",
# "text-embedding-ada-002": "your OPENAI_API_KEY",
},
"llm_model": {
"chatglm2-6b": "/mnt/workspace/chatglm2-6b",
# "chatglm2-6b-32k": "THUDM/chatglm2-6b-32k",
# "chatglm3-6b": "THUDM/chatglm3-6b",
# "chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
# "Orion-14B-Chat": "OrionStarAI/Orion-14B-Chat",
# "Orion-14B-Chat-Plugin": "OrionStarAI/Orion-14B-Chat-Plugin",
# "Orion-14B-LongChat": "OrionStarAI/Orion-14B-LongChat",
# "Llama-2-7b-chat-hf": "meta-llama/Llama-2-7b-chat-hf",
# "Llama-2-13b-chat-hf": "meta-llama/Llama-2-13b-chat-hf",
# "Llama-2-70b-chat-hf": "meta-llama/Llama-2-70b-chat-hf",
# "Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
# "Qwen-7B-Chat": "Qwen/Qwen-7B-Chat",
# "Qwen-14B-Chat": "Qwen/Qwen-14B-Chat",
# "Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
# # Qwen1.5 模型 VLLM可能出现问题
# "Qwen1.5-0.5B-Chat": "Qwen/Qwen1.5-0.5B-Chat",
# "Qwen1.5-1.8B-Chat": "Qwen/Qwen1.5-1.8B-Chat",
# "Qwen1.5-4B-Chat": "Qwen/Qwen1.5-4B-Chat",
# "Qwen1.5-7B-Chat": "Qwen/Qwen1.5-7B-Chat",
# "Qwen1.5-14B-Chat": "Qwen/Qwen1.5-14B-Chat",
# "Qwen1.5-72B-Chat": "Qwen/Qwen1.5-72B-Chat",
# "baichuan-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
# "baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
# "baichuan2-7b-chat": "baichuan-inc/Baichuan2-7B-Chat",
# "baichuan2-13b-chat": "baichuan-inc/Baichuan2-13B-Chat",
# "internlm-7b": "internlm/internlm-7b",
# "internlm-chat-7b": "internlm/internlm-chat-7b",
# "internlm2-chat-7b": "internlm/internlm2-chat-7b",
# "internlm2-chat-20b": "internlm/internlm2-chat-20b",
# "BlueLM-7B-Chat": "vivo-ai/BlueLM-7B-Chat",
# "BlueLM-7B-Chat-32k": "vivo-ai/BlueLM-7B-Chat-32k",
# "Yi-34B-Chat": "https://huggingface.co/01-ai/Yi-34B-Chat",
# "agentlm-7b": "THUDM/agentlm-7b",
# "agentlm-13b": "THUDM/agentlm-13b",
# "agentlm-70b": "THUDM/agentlm-70b",
# "falcon-7b": "tiiuae/falcon-7b",
# "falcon-40b": "tiiuae/falcon-40b",
# "falcon-rw-7b": "tiiuae/falcon-rw-7b",
# "aquila-7b": "BAAI/Aquila-7B",
# "aquilachat-7b": "BAAI/AquilaChat-7B",
# "open_llama_13b": "openlm-research/open_llama_13b",
# "vicuna-13b-v1.5": "lmsys/vicuna-13b-v1.5",
# "koala": "young-geng/koala",
# "mpt-7b": "mosaicml/mpt-7b",
# "mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
# "mpt-30b": "mosaicml/mpt-30b",
# "opt-66b": "facebook/opt-66b",
# "opt-iml-max-30b": "facebook/opt-iml-max-30b",
# "gpt2": "gpt2",
# "gpt2-xl": "gpt2-xl",
# "gpt-j-6b": "EleutherAI/gpt-j-6b",
# "gpt4all-j": "nomic-ai/gpt4all-j",
# "gpt-neox-20b": "EleutherAI/gpt-neox-20b",
# "pythia-12b": "EleutherAI/pythia-12b",
# "oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
# "dolly-v2-12b": "databricks/dolly-v2-12b",
# "stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b",
},
"reranker": {
"bge-reranker-large": "BAAI/bge-reranker-large",
"bge-reranker-base": "BAAI/bge-reranker-base",
}
}
# 通常情况下不需要更改以下内容
# nltk 模型存储路径
NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")
# 使用VLLM可能导致模型推理能力下降,无法完成Agent任务
VLLM_MODEL_DICT = {
"chatglm2-6b": "/mnt/workspace/chatglm2-6b",
# "chatglm2-6b-32k": "THUDM/chatglm2-6b-32k",
# "chatglm3-6b": "THUDM/chatglm3-6b",
# "chatglm3-6b-32k": "THUDM/chatglm3-6b-32k",
# "Llama-2-7b-chat-hf": "meta-llama/Llama-2-7b-chat-hf",
# "Llama-2-13b-chat-hf": "meta-llama/Llama-2-13b-chat-hf",
# "Llama-2-70b-chat-hf": "meta-llama/Llama-2-70b-chat-hf",
# "Qwen-1_8B-Chat": "Qwen/Qwen-1_8B-Chat",
# "Qwen-7B-Chat": "Qwen/Qwen-7B-Chat",
# "Qwen-14B-Chat": "Qwen/Qwen-14B-Chat",
# "Qwen-72B-Chat": "Qwen/Qwen-72B-Chat",
# "baichuan-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
# "baichuan-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
# "baichuan2-7b-chat": "baichuan-inc/Baichuan-7B-Chat",
# "baichuan2-13b-chat": "baichuan-inc/Baichuan-13B-Chat",
# "BlueLM-7B-Chat": "vivo-ai/BlueLM-7B-Chat",
# "BlueLM-7B-Chat-32k": "vivo-ai/BlueLM-7B-Chat-32k",
# "internlm-7b": "internlm/internlm-7b",
# "internlm-chat-7b": "internlm/internlm-chat-7b",
# "internlm2-chat-7b": "internlm/Models/internlm2-chat-7b",
# "internlm2-chat-20b": "internlm/Models/internlm2-chat-20b",
# "aquila-7b": "BAAI/Aquila-7B",
# "aquilachat-7b": "BAAI/AquilaChat-7B",
# "falcon-7b": "tiiuae/falcon-7b",
# "falcon-40b": "tiiuae/falcon-40b",
# "falcon-rw-7b": "tiiuae/falcon-rw-7b",
# "gpt2": "gpt2",
# "gpt2-xl": "gpt2-xl",
# "gpt-j-6b": "EleutherAI/gpt-j-6b",
# "gpt4all-j": "nomic-ai/gpt4all-j",
# "gpt-neox-20b": "EleutherAI/gpt-neox-20b",
# "pythia-12b": "EleutherAI/pythia-12b",
# "oasst-sft-4-pythia-12b-epoch-3.5": "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
# "dolly-v2-12b": "databricks/dolly-v2-12b",
# "stablelm-tuned-alpha-7b": "stabilityai/stablelm-tuned-alpha-7b",
# "open_llama_13b": "openlm-research/open_llama_13b",
# "vicuna-13b-v1.3": "lmsys/vicuna-13b-v1.3",
# "koala": "young-geng/koala",
# "mpt-7b": "mosaicml/mpt-7b",
# "mpt-7b-storywriter": "mosaicml/mpt-7b-storywriter",
# "mpt-30b": "mosaicml/mpt-30b",
# "opt-66b": "facebook/opt-66b",
# "opt-iml-max-30b": "facebook/opt-iml-max-30b",
}
SUPPORT_AGENT_MODEL = [
# "openai-api", # GPT4 模型
# "qwen-api", # Qwen Max模型
# "zhipu-api", # 智谱AI GLM4模型
# "Qwen", # 所有Qwen系列本地模型
# "chatglm3-6b",
"chatglm2-6b",
# "internlm2-chat-20b",
# "Orion-14B-Chat-Plugin",
]
这里主要替换的chatglm2-6B的一些内容(此次仅作model_config.py修改内容的解释)
# 00. 选用的 Embedding 名称为m3e-base
EMBEDDING_MODEL = "m3e-base"
# 01.仅指定 chatglm2-6b
LLM_MODELS = ["chatglm2-6b", ]
# 02.指定为 空
ONLINE_LLM_MODEL = { }
# 03.仅指定 text2vec-base-chinese chatglm2-6b
MODEL_PATH = {
"embed_model": {
# 我们使用的embedding模型为:m3e-base
"m3e-base":"/mnt/workspace/langchain-ChatGLM/m3e-base",
"text2vec-base-chinese": "/mnt/workspace/langchain-ChatGLM/text2vec-base-chinese",
},
"llm_model": {
# 仅指定 这一个
"chatglm2-6b": "/mnt/workspace/chatglm2-6b",
},
}
# 04.仅指定 chatglm2
SUPPORT_AGENT_MODEL = [
"chatglm2",
]
- 修改server_config.py(完全替换内容即可)
import sys
from configs.model_config import LLM_DEVICE
# httpx 请求默认超时时间(秒)。如果加载模型或对话较慢,出现超时错误,可以适当加大该值。
HTTPX_DEFAULT_TIMEOUT = 300.0
# API 是否开启跨域,默认为False,如果需要开启,请设置为True
# is open cross domain
OPEN_CROSS_DOMAIN = False
# 各服务器默认绑定host。如改为"0.0.0.0"需要修改下方所有XX_SERVER的host
DEFAULT_BIND_HOST = "0.0.0.0" if sys.platform != "win32" else "127.0.0.1"
# webui.py server
WEBUI_SERVER = {
"host": DEFAULT_BIND_HOST,
"port": 8501,
}
# api.py server
API_SERVER = {
"host": DEFAULT_BIND_HOST,
"port": 7861,
}
# fastchat openai_api server
FSCHAT_OPENAI_API = {
"host": DEFAULT_BIND_HOST,
"port": 20000,
}
# fastchat model_worker server
# 这些模型必须是在model_config.MODEL_PATH或ONLINE_MODEL中正确配置的。
# 在启动startup.py时,可用通过`--model-name xxxx yyyy`指定模型,不指定则为LLM_MODELS
FSCHAT_MODEL_WORKERS = {
# 所有模型共用的默认配置,可在模型专项配置中进行覆盖。
"default": {
"host": DEFAULT_BIND_HOST,
"port": 20002,
"device": LLM_DEVICE,
# False,'vllm',使用的推理加速框架,使用vllm如果出现HuggingFace通信问题,参见doc/FAQ
# vllm对一些模型支持还不成熟,暂时默认关闭
"infer_turbo": False,
# model_worker多卡加载需要配置的参数
# "gpus": None, # 使用的GPU,以str的格式指定,如"0,1",如失效请使用CUDA_VISIBLE_DEVICES="0,1"等形式指定
# "num_gpus": 1, # 使用GPU的数量
# "max_gpu_memory": "20GiB", # 每个GPU占用的最大显存
# 以下为model_worker非常用参数,可根据需要配置
# "load_8bit": False, # 开启8bit量化
# "cpu_offloading": None,
# "gptq_ckpt": None,
# "gptq_wbits": 16,
# "gptq_groupsize": -1,
# "gptq_act_order": False,
# "awq_ckpt": None,
# "awq_wbits": 16,
# "awq_groupsize": -1,
# "model_names": LLM_MODELS,
# "conv_template": None,
# "limit_worker_concurrency": 5,
# "stream_interval": 2,
# "no_register": False,
# "embed_in_truncate": False,
# 以下为vllm_worker配置参数,注意使用vllm必须有gpu,仅在Linux测试通过
# tokenizer = model_path # 如果tokenizer与model_path不一致在此处添加
# 'tokenizer_mode':'auto',
# 'trust_remote_code':True,
# 'download_dir':None,
# 'load_format':'auto',
# 'dtype':'auto',
# 'seed':0,
# 'worker_use_ray':False,
# 'pipeline_parallel_size':1,
# 'tensor_parallel_size':1,
# 'block_size':16,
# 'swap_space':4 , # GiB
# 'gpu_memory_utilization':0.90,
# 'max_num_batched_tokens':2560,
# 'max_num_seqs':256,
# 'disable_log_stats':False,
# 'conv_template':None,
# 'limit_worker_concurrency':5,
# 'no_register':False,
# 'num_gpus': 1
# 'engine_use_ray': False,
# 'disable_log_requests': False
},
"chatglm2-6b": {
"device": "cuda",
},
"Qwen1.5-0.5B-Chat": {
"device": "cuda",
},
# 以下配置可以不用修改,在model_config中设置启动的模型
"zhipu-api": {
"port": 21001,
},
"minimax-api": {
"port": 21002,
},
"xinghuo-api": {
"port": 21003,
},
"qianfan-api": {
"port": 21004,
},
"fangzhou-api": {
"port": 21005,
},
"qwen-api": {
"port": 21006,
},
"baichuan-api": {
"port": 21007,
},
"azure-api": {
"port": 21008,
},
"tiangong-api": {
"port": 21009,
},
"gemini-api": {
"port": 21010,
},
"claude-api": {
"port": 21011,
},
}
FSCHAT_CONTROLLER = {
"host": DEFAULT_BIND_HOST,
"port": 20001,
"dispatch_method": "shortest_queue",
}
<4> 安装依赖
pip install jq
pip install streamlit_modal
<5> 创建知识库
python init_database.py --recreate-vs
<6> 启动知识库
python startup.py -a
**注意:**此处可能会出现cuda和pytorch不匹配的问题(如下图),pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113利用这个命令按照相匹配的内容即可解决。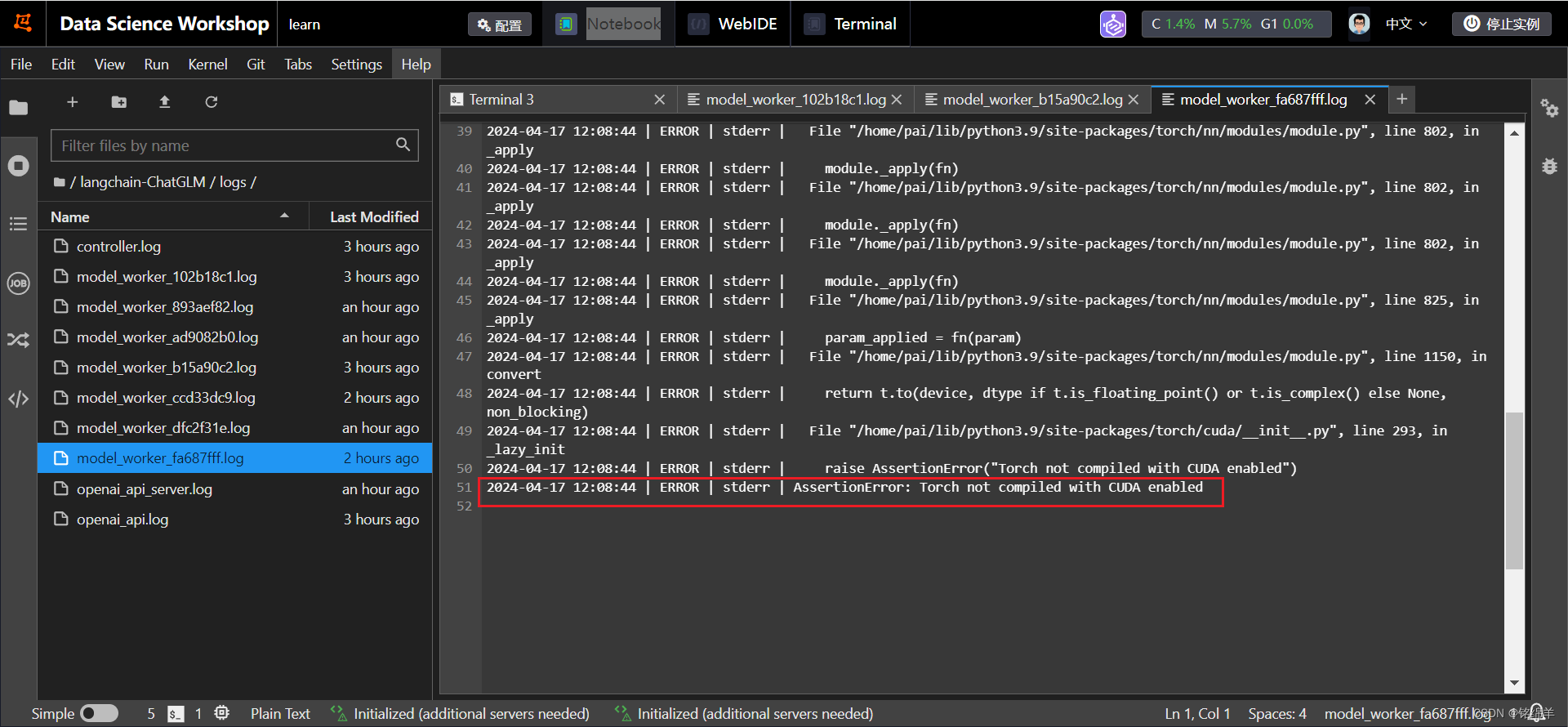
**例外:**当然还有遇到的上传文档显示报403的错误
解决方法:降级streamlit
pip install streamlit==1.28.0
然后退出重启即可解决问题:python startup.py -a

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)