fooocus读取批量prompts进行批量生成图像方法
fooocus批量读取prompt,执行出图
·
命令:
python main.py --all-in-fp16 --always-gpu --host=0.0.0.0 --disable-image-log--host=0.0.0.0 可以使用局域网访问
--disable-image-log 防止出现两份相同输出的图像数据
批量操作代码实例
import requests import json import time import pandas as pd ''' 启动命令:python main.py --all-in-fp16 --always-gpu --host=0.0.0.0 --disable-image-log ''' host = "http://127.0.0.1:7865" # 图生文 def text2img(params: dict) -> dict: """ 文生图 """ result = requests.post(url=f"{host}/v1/generation/text-to-image", data=json.dumps(params), headers={"Content-Type": "application/json"}) # print(result.text) return result.json() # 查询指定任务完成情况 def taskResult(task_id: str) -> dict: # 获取任务状态 task_status = requests.get(url=f"{host}/v1/generation/query-job", params={"job_id": task_id, "require_step_preivew": False}, timeout=30) print(task_status.text) return task_status.json() # 刷新模型 def refresh() -> dict: """ refresh-models """ response = requests.post(url=f"{host}/v1/engines/refresh-models", timeout=30) return response.json() # 查询可用模型(基础模型和lora模型) def all_models() -> dict: """ all-models """ response = requests.get(url=f"{host}/v1/engines/all-models", timeout=30) return response.json() # 查询可用样式 def styles() -> dict: """ styles """ response = requests.get(url=f"{host}/v1/engines/styles", timeout=30) return response.json() # 查询处理进度 def job_queue() -> dict: """ job-queue """ response = requests.get(url=f"{host}/v1/generation/job-queue", timeout=30) return response.json() # 读取excel指定列的数据 def read_data(ex_path, lie): # 读取excel文件 df = pd.read_excel(ex_path) # 获取sen1_trans列数据 sen1_trans_data = df[lie].tolist() return sen1_trans_data if __name__ == '__main__': # prompts = ["This part of the story paints a picture of the thick grass and the flames of war."] # 读取excel中的批量prompts prompts = read_data(r"C:\Users\pc\Downloads\ll_test.xlsx","sen1_trans") for i in prompts: result =text2img({ "prompt": i, "negative_prompt": "low quality", "style_selections": ["Fooocus V2", "Fooocus Masterpiece","Fooocus Negative"], "aspect_ratios_selection":"1024*1024", "base_model_name":"骊歌_Linger_(SDXL真实系大模型)_2.0.safetensors", "guidance_scale":8, "image_number":2, "image_seed":-1, "loras":[{"model_name": "大自然的鬼匠神工SDXL_v1.0.safetensors", "weight": 0.6}, {"model_name": "中式古建筑_V1.safetensors", "weight": 0.4}, {"model_name": "WDR|江南烟雨_v1.0.safetensors", "weight": 0.8}], "async_process": True}) print(result) time.sleep(30) # print(taskResult('a88a356b-a408-45e8-a107-169f76214250')) # 文生图参数 ''' prompt:描述词 negative_prompt: 反向描述词 style_selections: [] 风格列表, 需要是受支持的风格, 可以通过 样式接口 获取所有支持的样式 performance_selection: 性能选择, Speed, Quality, Extreme Speed 中的一个, 默认 Speed aspect_ratios_selection: 分辨率, 默认 '1152*896' image_number: 生成图片数量, 默认 1 , 最大32, 注: 非并行接口 image_seed: 默认 -1, 即随机生成 sharpness: 锐度, 默认 2.0 , 0-30 guidance_scale: 引导比例, 默认 4.0 , 1-30 base_model_name: 基础模型 refiner_model_name: 优化模型 refiner_switch: 优化模型切换时机, 默认 0.5 loras: lora 模型列表 advanced_params:高级参数 require_base64: 是否返回base64编码, 默认 False async_process: 是否异步处理, 默认 False '''测试效果:
正常运行。
批量输出结果..

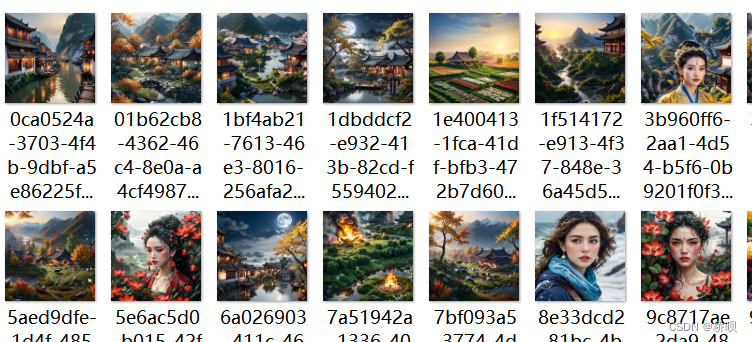
可以挂一晚上,第二天早上查看结果了

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)