LLAMA3==shenzhi-wang/Llama3-8B-Chinese-Chat。windows安装不使用ollama
非常慢,大概用了一两分钟回答一个问题。还是老实用ollama跑qwen吧。
·
创建环境:
conda create -n llama3_env python=3.10
conda activate llama3_env
conda install pytorch torchvision torchaudio cudatoolkit=11.7 -c pytorch
安装Hugging Face的Transformers库:
pip install transformers sentencepiece
下载模型
https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat/tree/main
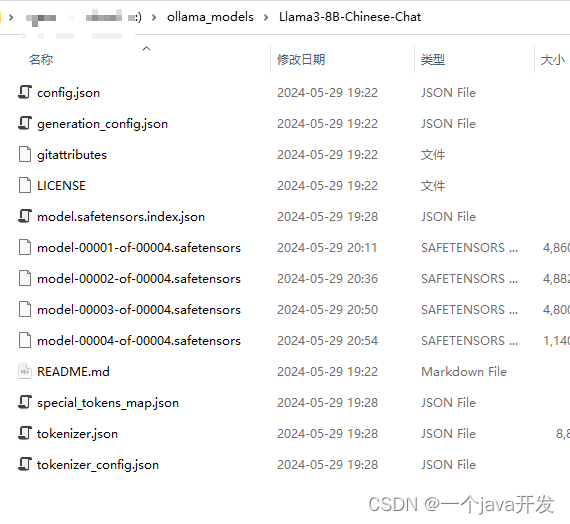
编写代码调用
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 检查CUDA是否可用,并设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(torch.cuda.is_available())
print(device)
# 加载模型和tokenizer
model_name = "F:\\ollama_models\\Llama3-8B-Chinese-Chat"
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 编写推理函数
# def generate_text(prompt):
# inputs = tokenizer(prompt, return_tensors="pt").to(device)
# outputs = model.generate(inputs['input_ids'], max_length=100)
# return tokenizer.decode(outputs[0], skip_special_tokens=True)
#
# # 示例使用
# prompt = "写一首诗吧,以春天为主题"
# print(generate_text(prompt))
messages = [
{"role": "user", "content": "写一首诗吧"},
]
input_ids = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
outputs = model.generate(
input_ids,
max_new_tokens=8192,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
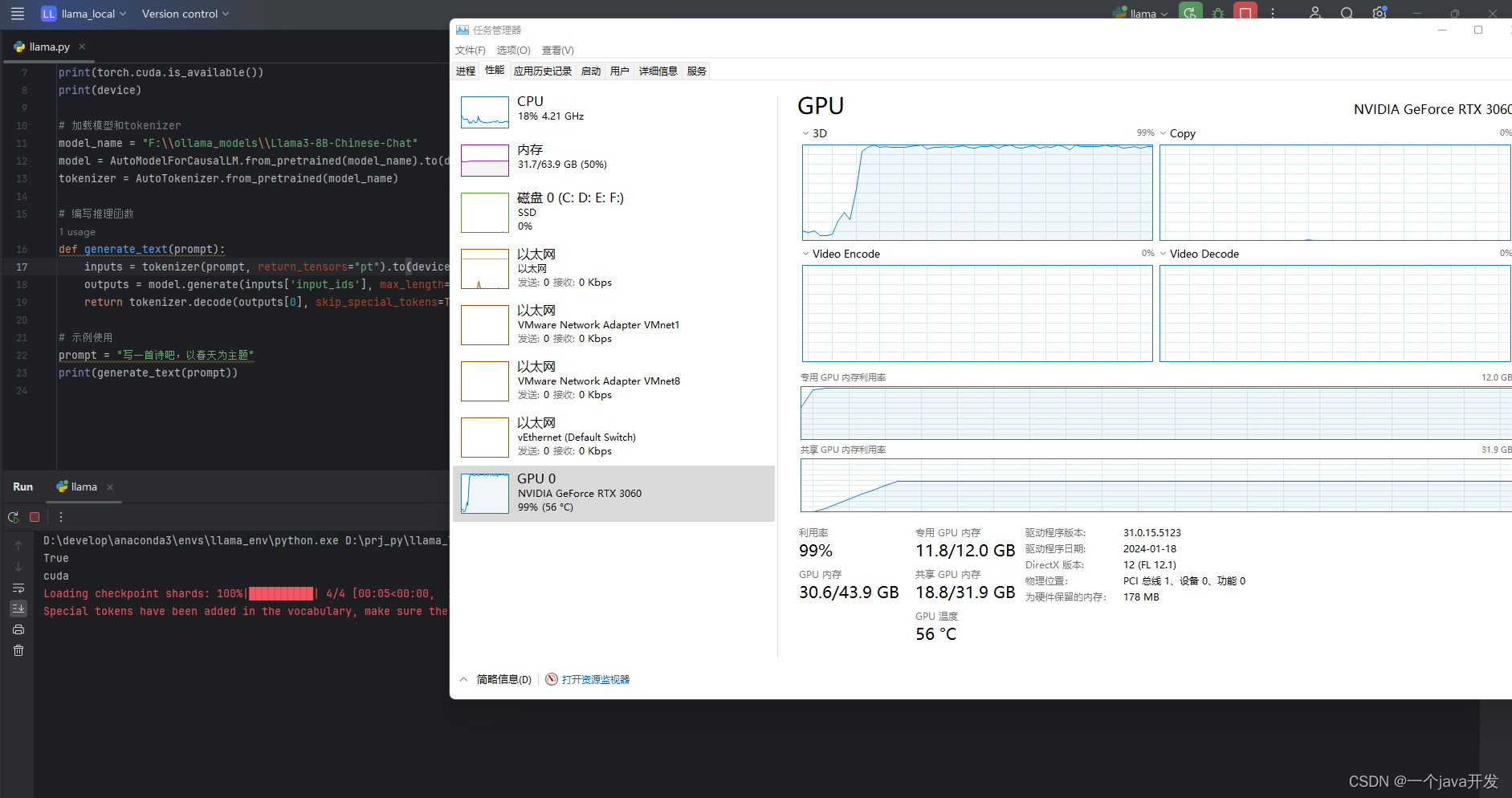
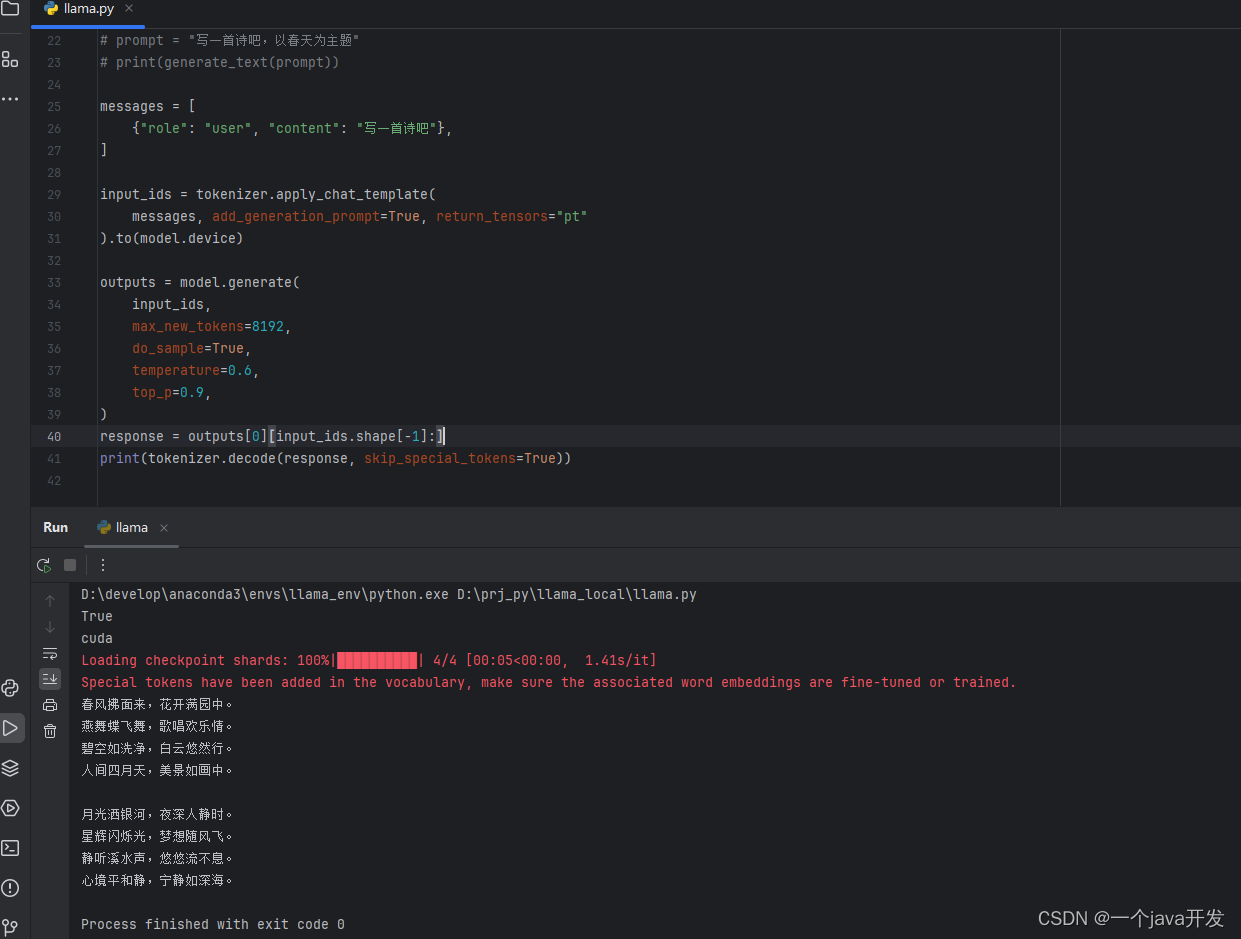
非常慢,大概用了一两分钟回答一个问题。
还是老实用ollama跑qwen吧

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)