书生·浦语大模型实战营(第二期):Lagent&AgentLego智能体应用搭建
可以感知环境中的动态条件能采取动作影响环境能运用推理能力理解信息、解决问题、产生推断、决定动作。
目录
为什么要有智能体
- 大语言模型的局限性
- 幻觉:模型可能会生成虚假信息,与现实严重不符或脱节
- 时效性:模型训练数据过时,无法反映最新趋势和信息
- 可靠性:面对复杂任务时,可能频发错误输出现象,影响信任度
什么是智能体
- 可以感知环境中的动态条件
- 能采取动作影响环境
- 能运用推理能力理解信息、解决问题、产生推断、决定动作
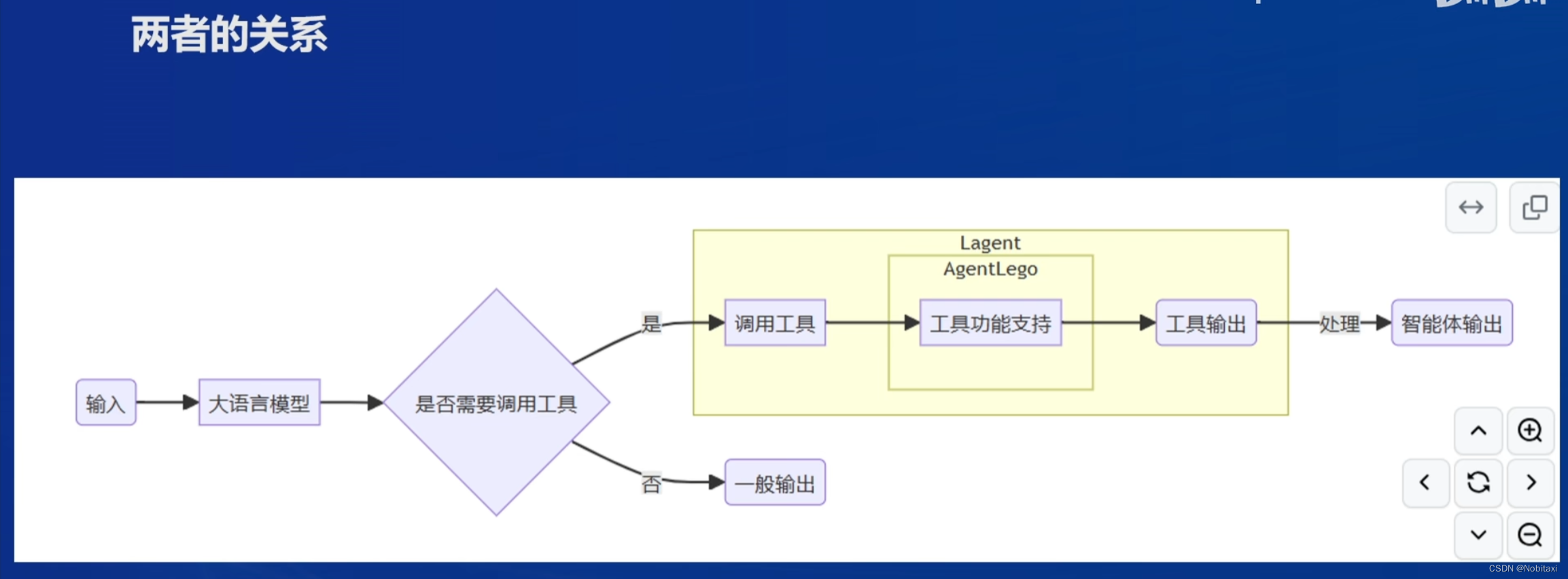
智能体组成
- 大脑:作为控制器,承担记忆、思考和决策任务。接受来自感知模块的信息,并采取相应动作
- 感知:对外部环境的多模态信息进行感知和处理,包括但不限于图像、音频、视频、传感器等
- 动作:利用并执行工具以影响环境,工具可能包括文本的检索、调用相关API、操控机械臂等
智能体范式
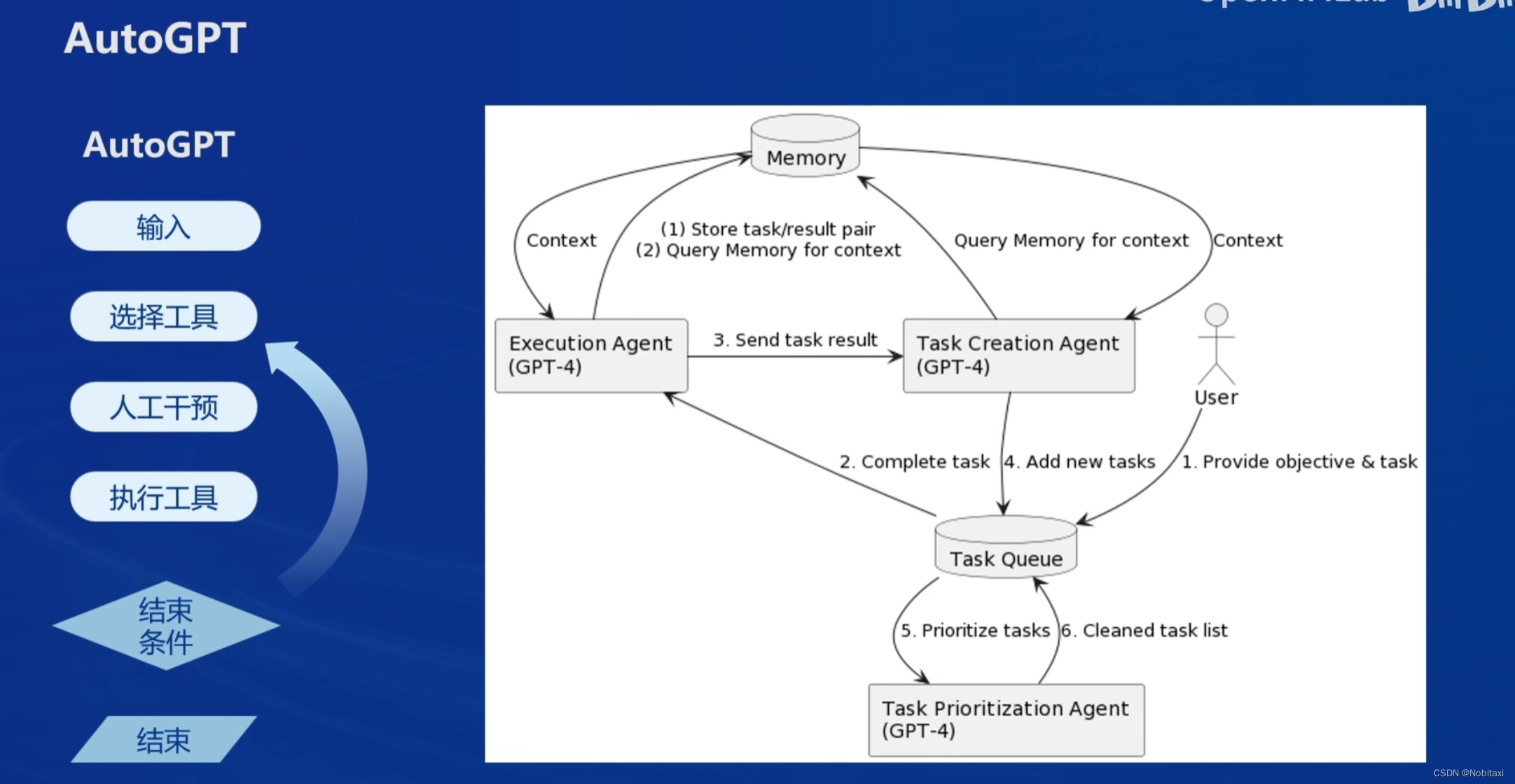

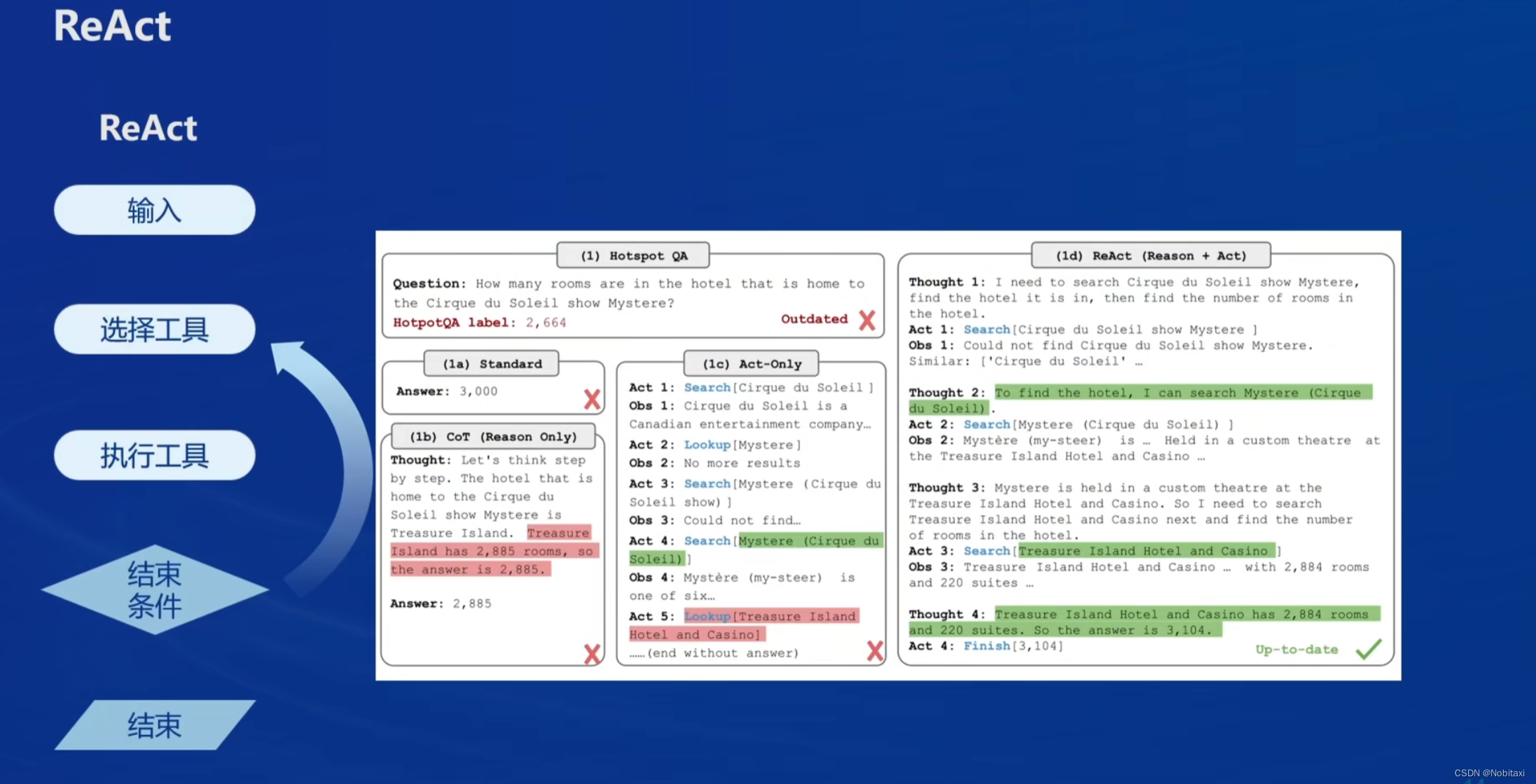
Lagent&AgentLego
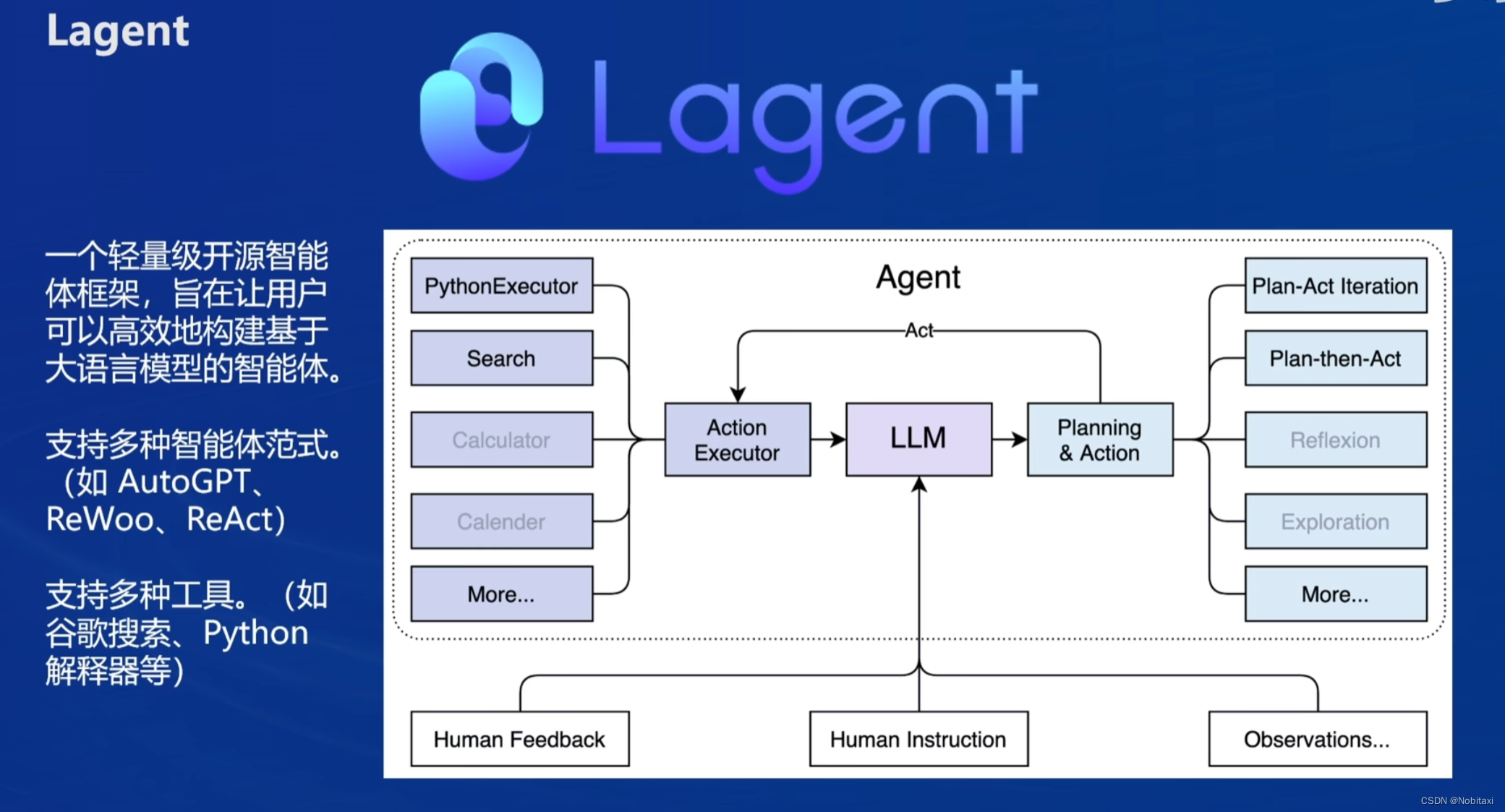
Lagent 目前已经支持了包括 AutoGPT、ReAct 等在内的多个经典智能体范式,也支持了如下工具:
- Arxiv 搜索
- Bing 地图
- Google 学术搜索
- Google 搜索
- 交互式 IPython 解释器
- IPython 解释器
- PPT
- Python 解释器
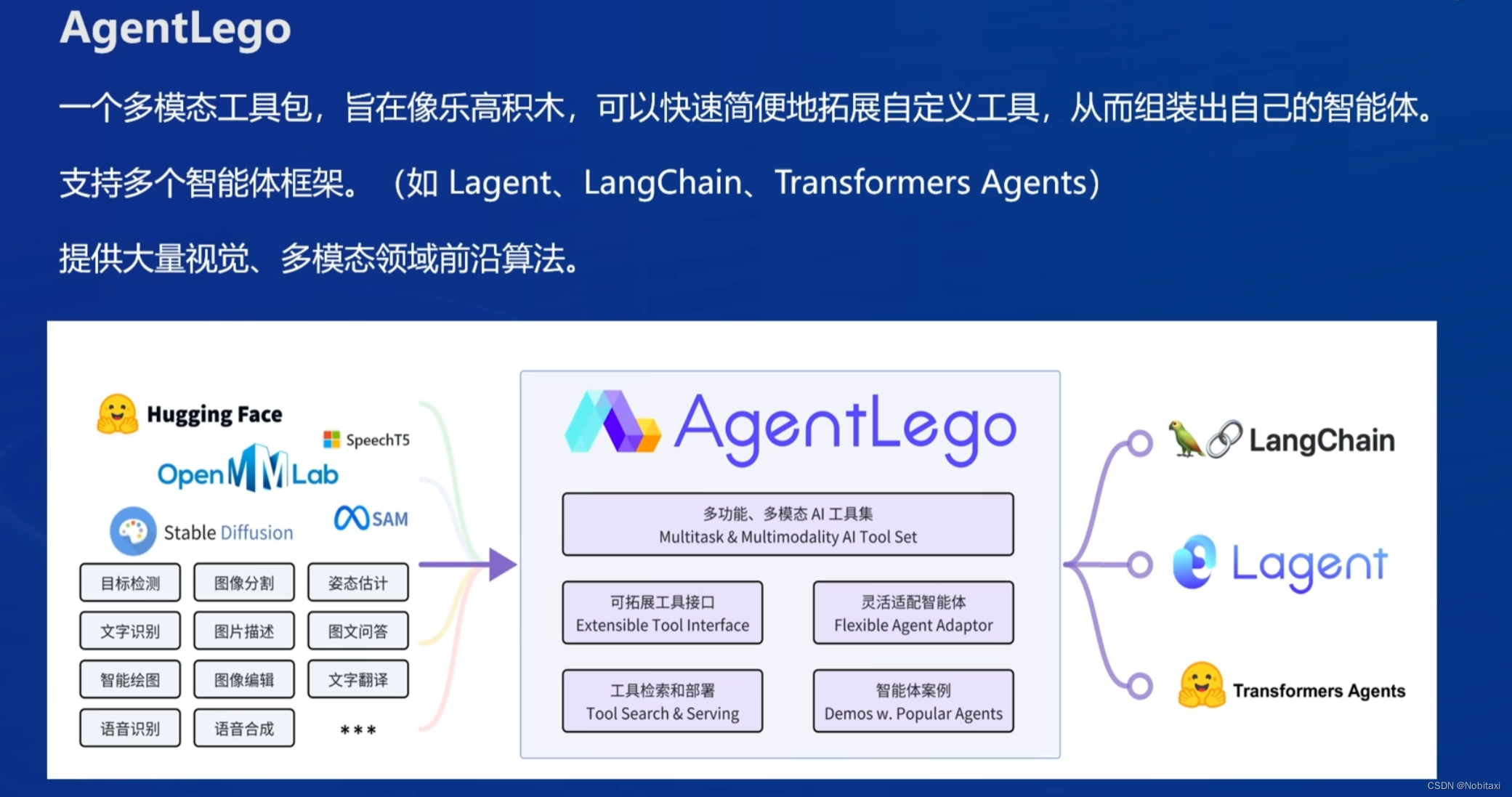
AgentLego 目前提供了如下工具:
- 通用能力
- 计算器
- 谷歌搜索
- 语音相关
- 文本 -> 音频(TTS)
- 音频 -> 文本(STT)
- 图像处理
- 描述输入图像
- 识别文本(OCR)
- 视觉问答(VQA)
- 人体姿态估计
- 人脸关键点检测
- 图像边缘提取(Canny)
- 深度图生成
- 生成涂鸦(Scribble)
- 检测全部目标
- 检测给定目标
- SAM
- 分割一切
- 分割给定目标
- AIGC
- 文生图
- 图像拓展
- 删除给定对象
- 替换给定对象
- 根据指令修改
- ControlNet 系列
- 根据边缘+描述生成
- 根据深度图+描述生成
- 根据姿态+描述生成
- 根据涂鸦+描述生成
- ImageBind 系列
- 音频生成图像
- 热成像生成图像
- 音频+图像生成图像
- 音频+文本生成图像
作业一:完成Lagent Web Demo使用
环境配置
- 配置 conda 环境
mkdir -p /root/agent
conda create -n agent
conda activate agent
conda install python=3.10
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
- 安装Lagent和AgentLego,有两种安装方法,一种是通过 pip 直接进行安装,另一种则是从源码进行安装。
cd /root/agent
conda activate agent
git clone https://gitee.com/internlm/lagent.git
cd lagent && git checkout 581d9fb && pip install -e . && cd ..
git clone https://gitee.com/internlm/agentlego.git
cd agentlego && git checkout 7769e0d && pip install -e . && cd ..
- 安装其他依赖
conda activate agent
pip install lmdeploy==0.3.0
- 由于后续的 Demo 需要用到 tutorial 已经写好的脚本,因此我们需要将 tutorial 通过 git clone 的方法准备好,以备后续使用
cd /root/agent
git clone -b camp2 https://gitee.com/internlm/Tutorial.git
Lagent Web Demo
使用LMDeploy部署
由于 Lagent 的 Web Demo 需要用到 LMDeploy 所启动的 api_server,因此我们首先按照下图指示在 vscode terminal 中执行如下代码使用 LMDeploy 启动一个 api_server。
conda activate agent
lmdeploy serve api_server /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b \
--server-name 127.0.0.1 \
--model-name internlm2-chat-7b \
--cache-max-entry-count 0.1
启动并使用Lagent Web Demo
新建一个 terminal 以启动 Lagent Web Demo
conda activate agent
cd /root/agent/lagent/examples
streamlit run internlm2_agent_web_demo.py --server.address 127.0.0.1 --server.port 7860
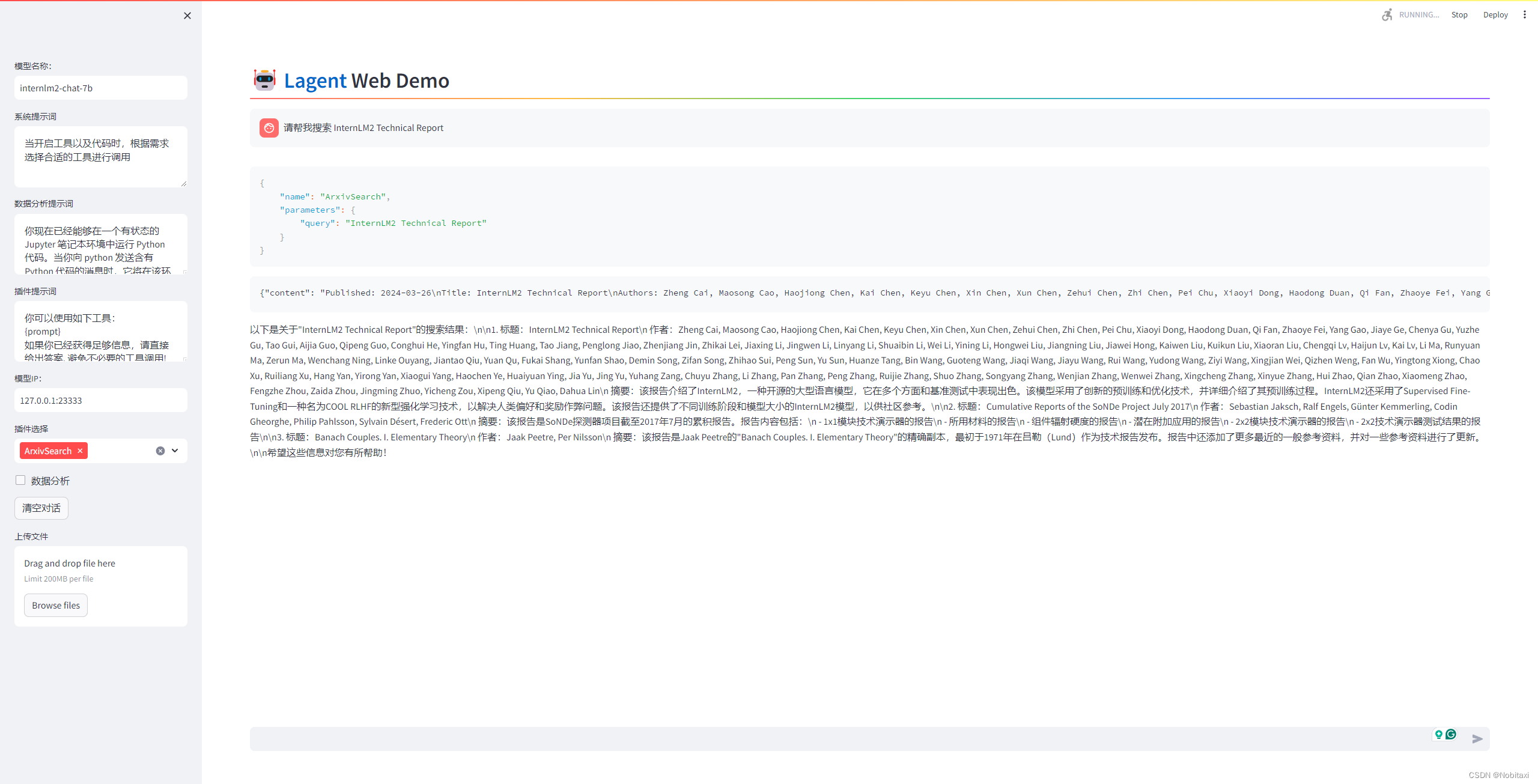
注意:首先输入模型 IP 为 127.0.0.1:23333,在输入完成后按下回车键以确认。
作业二:完成AgentLego使用
直接使用
首先下载 demo 文件:
cd /root/agent
wget http://download.openmmlab.com/agentlego/road.jpg
由于 AgentLego 在安装时并不会安装某个特定工具的依赖,因此我们接下来准备安装目标检测工具运行时所需依赖。
gentLego 所实现的目标检测工具是基于 mmdet (MMDetection) 算法库中的 RTMDet-Large 模型,因此我们首先安装 mim,然后通过 mim 工具来安装 mmdet。这一步所需时间可能会较长,请耐心等待。
conda activate agent
pip install openmim==0.3.9
mim install mmdet==3.3.0
然后通过touch /root/agent/direct_use.py新建direct_use.py以直接使用目标检测工具,代码如下:
import re
import cv2
from agentlego.apis import load_tool
# load tool
tool = load_tool('ObjectDetection', device='cuda')
# apply tool
visualization = tool('/root/agent/road.jpg')
print(visualization)
# visualize
image = cv2.imread('/root/agent/road.jpg')
preds = visualization.split('\n')
pattern = r'(\w+) \((\d+), (\d+), (\d+), (\d+)\), score (\d+)'
for pred in preds:
name, x1, y1, x2, y2, score = re.match(pattern, pred).groups()
x1, y1, x2, y2, score = int(x1), int(y1), int(x2), int(y2), int(score)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 1)
cv2.putText(image, f'{name} {score}', (x1, y1), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 1)
cv2.imwrite('/root/agent/road_detection_direct.jpg', image)
执行 python /root/agent/direct_use.py 以进行推理。
得到如下结果: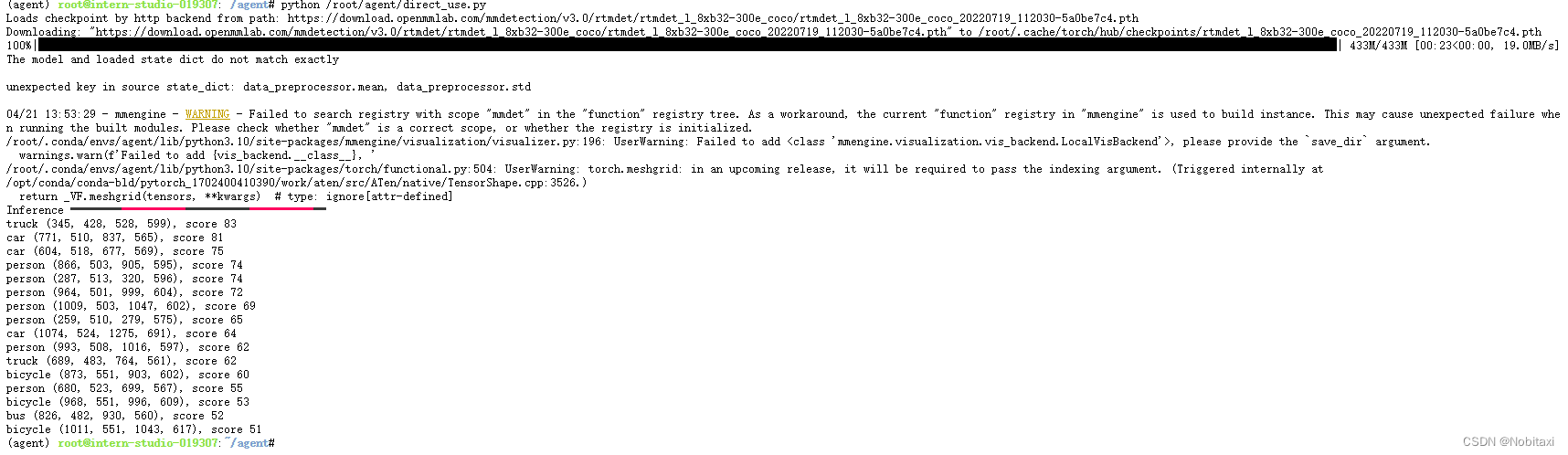

作为智能体工具使用
修改相关文件
由于 AgentLego 算法库默认使用 InternLM2-Chat-20B 模型,因此我们首先需要修改 /root/agent/agentlego/webui/modules/agents/lagent_agent.py 文件的第 105行位置,将 internlm2-chat-20b 修改为 internlm2-chat-7b
使用LMDeploy部署
conda activate agent
lmdeploy serve api_server /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b \
--server-name 127.0.0.1 \
--model-name internlm2-chat-7b \
--cache-max-entry-count 0.1
启动 AgentLego WebUI
conda activate agent
cd /root/agent/agentlego/webui
python one_click.py
- 配置Agent
- 点击上方 Agent 进入 Agent 配置页面。(如①所示)
- 点击 Agent 下方框,选择 New Agent。(如②所示)
- 选择 Agent Class 为 lagent.InternLM2Agent。(如③所示)
- 输入模型 URL 为 http://127.0.0.1:23333 。(如④所示)
- 输入 Agent name,自定义即可,图中输入了 internlm2。(如⑤所示)
- 点击 save to 以保存配置,这样在下次使用时只需在第2步时选择 Agent 为 internlm2 后点击 load 以加载就可以了。(如⑥所示)
- 点击 load 以加载配置。(如⑦所示)
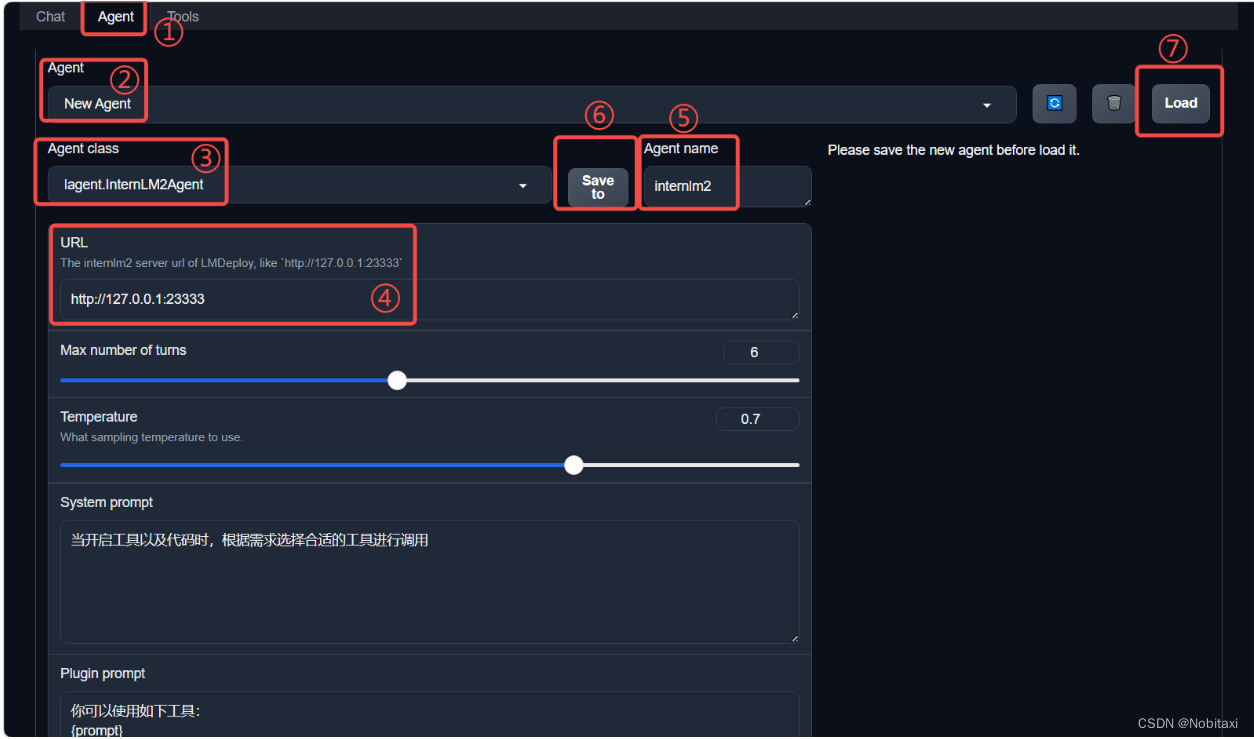
- 配置工具
- 点击上方 Tools 页面进入工具配置页面。(如①所示)
- 点击 Tools 下方框,选择 New Tool 以加载新工具。(如②所示)
- 选择 Tool Class 为 ObjectDetection。(如③所示)
- 点击 save 以保存配置。(如④所示)
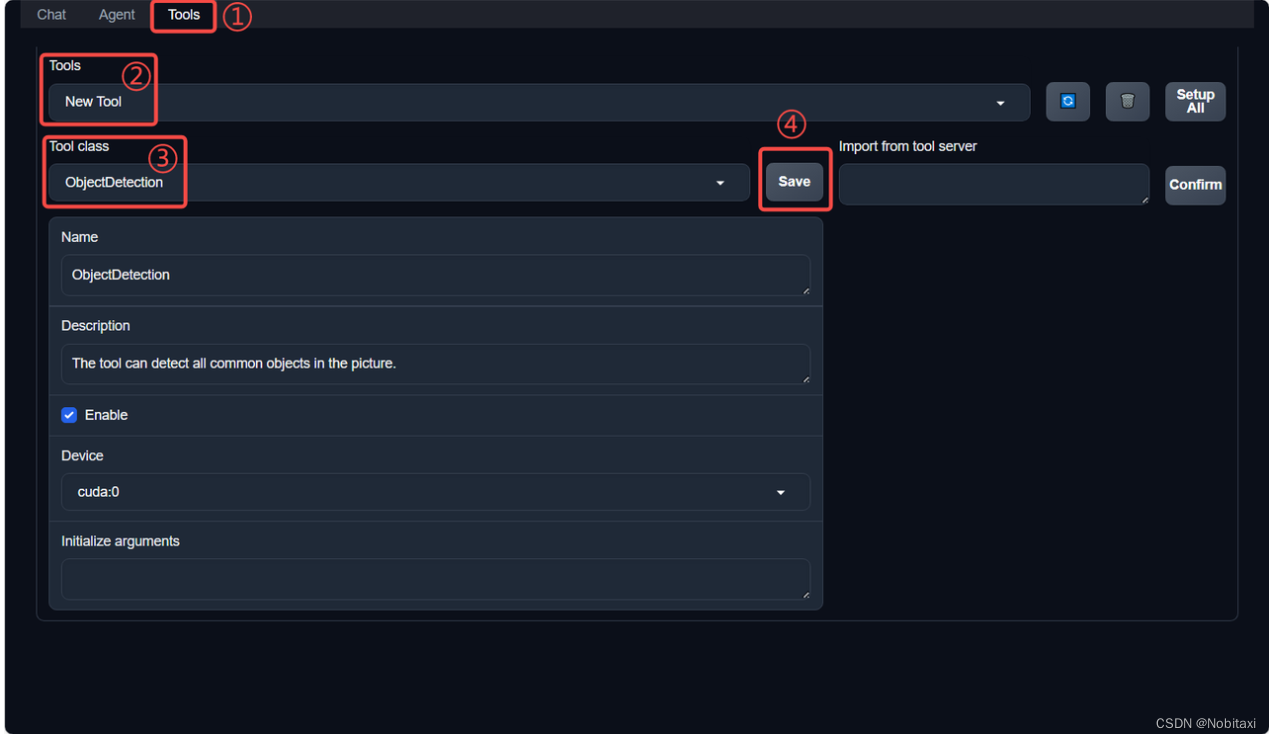
等待工具加载完成后,点击上方 Chat 以进入对话页面。在页面下方选择工具部分只选择 ObjectDetection 工具,如下图所示。为了确保调用工具的成功率,请在使用时确保仅有这一个工具启用。
接下来就可以愉快地使用 Agent 了。点击右下角文件夹以上传图片,上传图片后输入指令并点击 generate 以得到模型回复。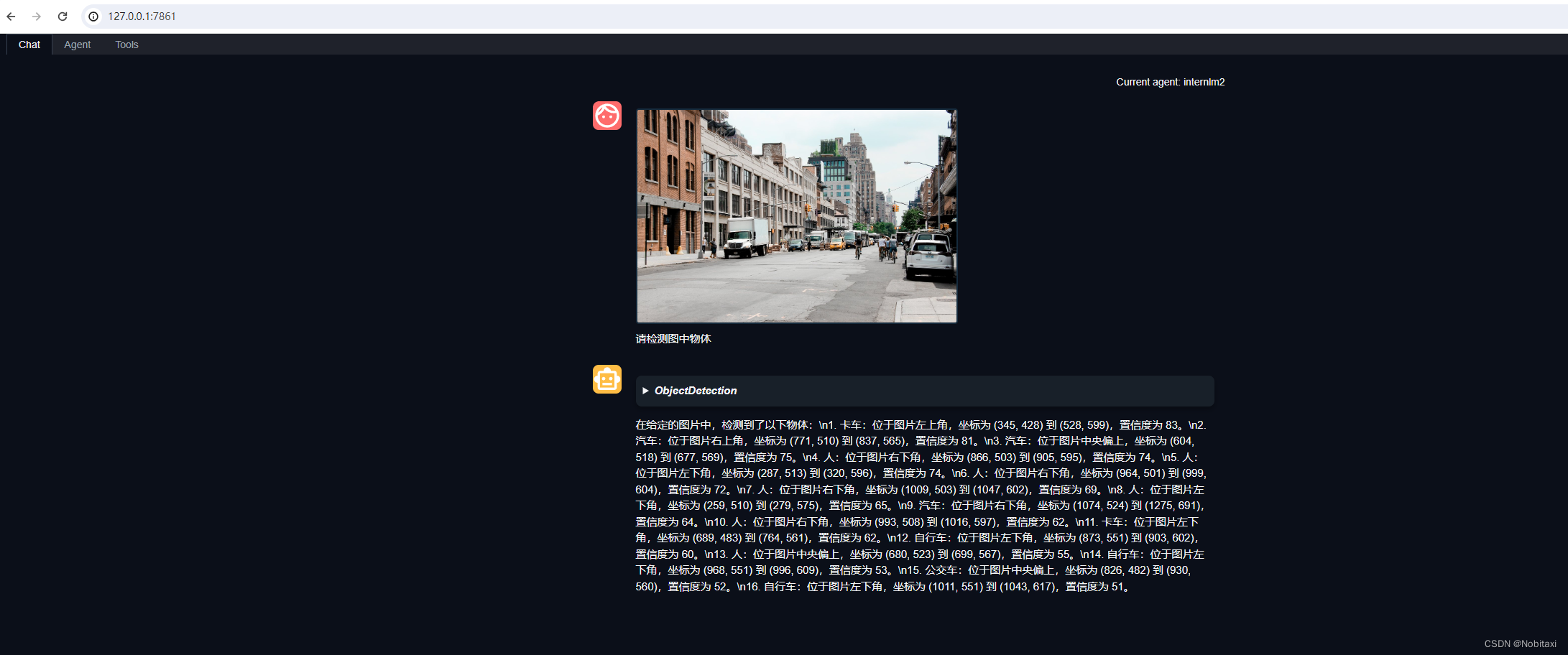

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)