什么!数据分析师要失业了?——使用 LangChain 构建多模态智能体
基于NIM构建多模态AI-Agent,适合初学者和小白,了解工作原理,快速搭建多模态智能体实现特定工作。本项目示例为从图表中读取信息,修改信息,重新绘制图片,工作流程为:接收图片 -> 分析数据 -> 修改数据 -> 生成绘制图片的代码 -> 执行代码 -> 展示结果,在这个示例的基础上可以根据业务需求定义更复杂的流程,也可以多智能体结合。
代码
LLM-Learning/multi-agent at master · aakaking/LLM-Learning · GitHub
项目概述
基于NIM构建多模态AI-Agent,适合初学者和小白,了解工作原理,快速搭建多模态智能体实现特定工作。本项目示例为从图表中读取信息,修改信息,重新绘制图片,工作流程为:接收图片 -> 分析数据 -> 修改数据 -> 生成绘制图片的代码 -> 执行代码 -> 展示结果,在这个示例的基础上可以根据业务需求定义更复杂的流程,也可以多智能体结合。
技术方案
(1)多模态模型基于 NIM 的调用方式
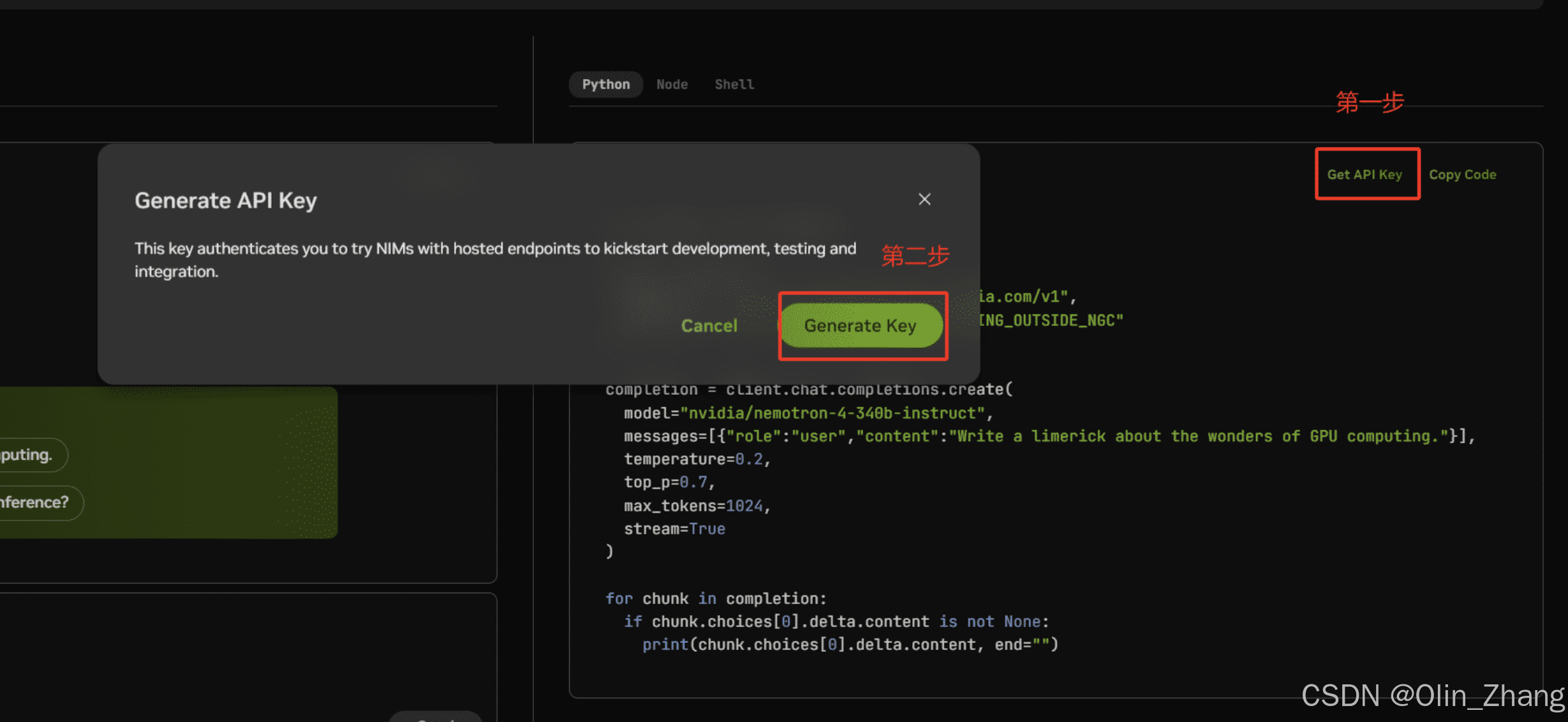
申请NIM的API Key,来调用NIM的计算资源
进入https://build.nvidia.com/microsoft/phi-3-vision-128k-instruct, 点击Get API Key按钮,生成一个秘钥
(2)基于 llama3-70b-instruct和Phi-3-Vision 的AI-Agent实践
(3)基于 Gradio 框架建立前端互动界面
环境搭建
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
主要需要三个工具包:
(1)langchain_nvidia_ai_endpoint: 用来调用nvidia nim的计算资源
(2)langchain: 用来构建对话链, 将智能体的各个组件串联起来
(3)base64: 因为本实验是构建多模态的智能体, 需要base64来对图像进行编解码
代码实现
图片解析
图片编码
def image2b64(image_file):
with open(image_file, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
return image_b64Phi 3 vison解析图片
chart_reading = ChatNVIDIA(model="microsoft/phi-3-vision-128k-instruct")
result = chart_reading.invoke(f'Generate underlying data table of the figure below, : <img src="data:image/png;base64,{image_b64}" />')
AI-Agent
应用场景:
将图片中的统计图表转换为可以用 python 进行分析的数据
Agent 工作流:
(1)接收图片,读取图片数据
image_b64 = image2b64(image)
chart_reading = ChatNVIDIA(model="microsoft/phi-3-vision-128k-instruct")
chart_reading_prompt = ChatPromptTemplate.from_template(
'Generate underlying data table of the figure below, : <img src="data:image/png;base64,{image_b64}" />'
)
chart_chain = chart_reading_prompt | chart_reading
(2)对数据进行调整、分析
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
instruct_prompt = ChatPromptTemplate.from_template(
"Do NOT repeat my requirements already stated. Based on this table {table}, {input}" \
"If has table string, start with 'TABLE', end with 'END_TABLE'." \
"If has code, start with '```python' and end with '```'." \
"Do NOT include table inside code, and vice versa."
)
instruct_chain = instruct_prompt | instruct_chat
(3)生成能够绘制图片的代码,并执行代码
execute_code = RunnableBranch(
(lambda x: '```python' in x.content, execute_and_return),
lambda x: x
)
(4)根据处理流程生成chain
chain = (
chart_reading_branch
#| RunnableLambda(print_and_return)
| instruct_chain
#| RunnableLambda(print_and_return)
| update_table
| execute_code
)
chain.invoke({"image_b64": image_b64, "input": user_input, "table": table})
封装进gradio
multi_modal_chart_agent = gr.Interface(fn=chart_agent,
inputs=[gr.Image(label="Upload image", type="filepath"), 'text'],
outputs=['image'],
title="Multi Modal chat agent",
description="Multi Modal chat agent",
allow_flagging="never")
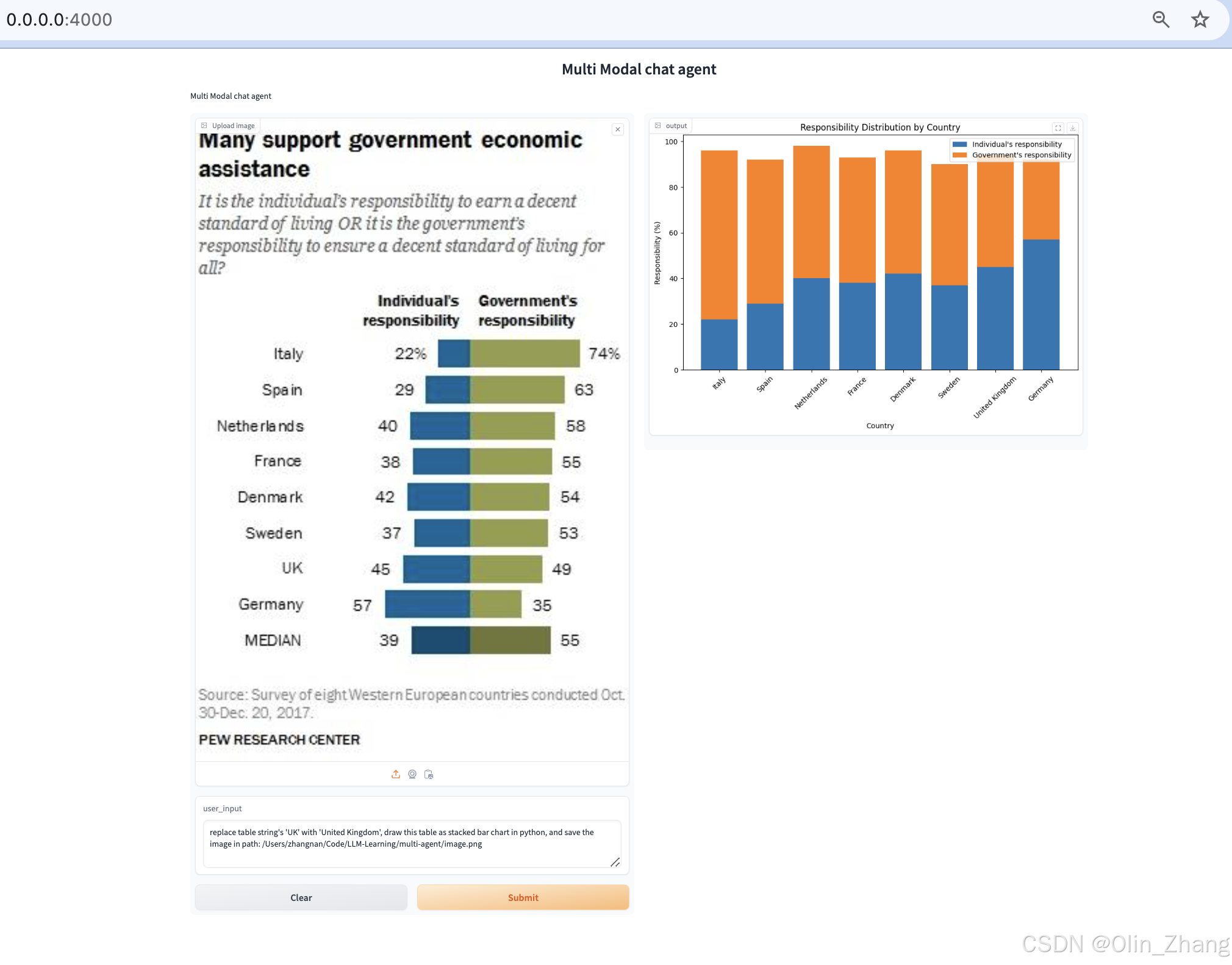
multi_modal_chart_agent.launch(debug=True, share=False, show_api=False, server_port=4000, server_name="0.0.0.0")结果展示

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)