node中使用superagent、cheerio进行爬虫
想必很多人都有这样的一个幻想,我可不可以啥也不用干,就获得别人的劳动成果呢?比如,我想做一个类似与豆瓣这样的app来练手,但是我有没有数据进行支撑,这时候我就想,能不能把豆瓣上的内容爬下来,放到我自己的app里面进行显示呢?哈哈大家都这样!ok,立马来开干。首先我们创建一个express应用express接下来用vscode进行打开,并且安装以下插件npm install --save cheer
·
想必很多人都有这样的一个幻想,我可不可以啥也不用干,就获得别人的劳动成果呢?比如,我想做一个类似与豆瓣这样的app来练手,但是我有没有数据进行支撑,这时候我就想,能不能把豆瓣上的内容爬下来,放到我自己的app里面进行显示呢?
哈哈大家都这样!
ok,立马来开干。
首先我们创建一个express应用
express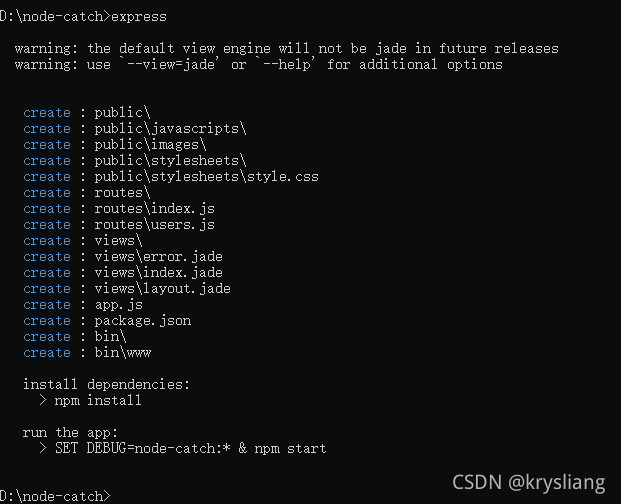
接下来用vscode进行打开,并且安装以下插件
npm install --save cheerio superagent然后打开route下面的index.js文件,加入以下代码,执行就可以啦!
var express = require('express');
var router = express.Router();
var cheerio = require('cheerio');
var superagent = require('superagent');
const fs = require("fs");
router.get('/catch', function (req, res, next) {
// 用 superagent 去抓取 网站 的内容
superagent.get('http://xuetangzaixian.com/yundong/index_4.html')
.end(function (err, sres) {
// 常规的错误处理
if (err) {
return next(err);
}
// sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
var $ = cheerio.load(sres.text);
var items = [];
$('.list ul li').each(function (idx, element) {
var $element = $(element);
let divimg = $element.find('.img a')
let href = 'http://xuetangzaixian.com/' + divimg.attr('href')
let title = divimg.attr('title')
let img = divimg.find('img').attr('src')
items.push({
title: title,
href: href,
img:img
});
});
res.send(items);
//读取文件 先把它读到缓存,然后加上新爬取的数据,再一并插入到json文件中
fs.readFile("article.json", 'utf-8', function(err, data) {
if (err) {
} else {
let olddata = JSON.parse(data)
if(olddata.length>0){
olddata = olddata.concat(items)
}else{
olddata = items
}
fs.writeFile("article.json", JSON.stringify(olddata), "utf-8", (error) => {
//监听错误,如正常输出,则打印null
if (error == null) {
console.log("恭喜您,数据爬取成功!)");
}
});
}
});
});
});
module.exports = router;
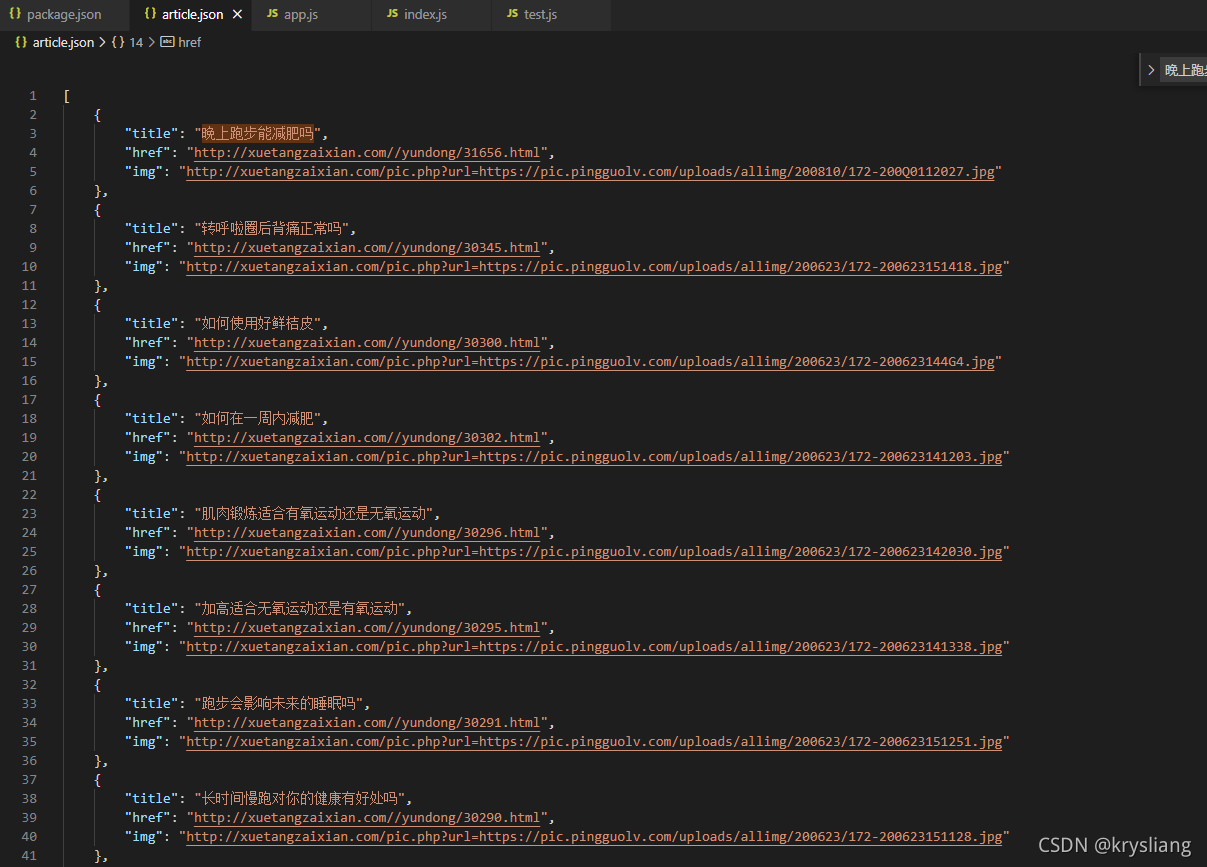
这里面,你需要注意的是,你要研究你爬取网站 所需要部分内容的格式。
就是一开始你获取到整个网页的内容,然后你把你需要的列表部分的li读取出来,然后遍历获取它的属性,就可以了。具体查看cheerio 官网 The industry standard for working with HTML in JavaScript | cheerio,里面有更详细的介绍

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)