vllm/spec_decode/spec_decode_worker.py 投机采样的一次前向推理 流程分析
vllm投机采样的前向推理流程分析
这里写自定义目录标题
_run_speculative_decoding_step
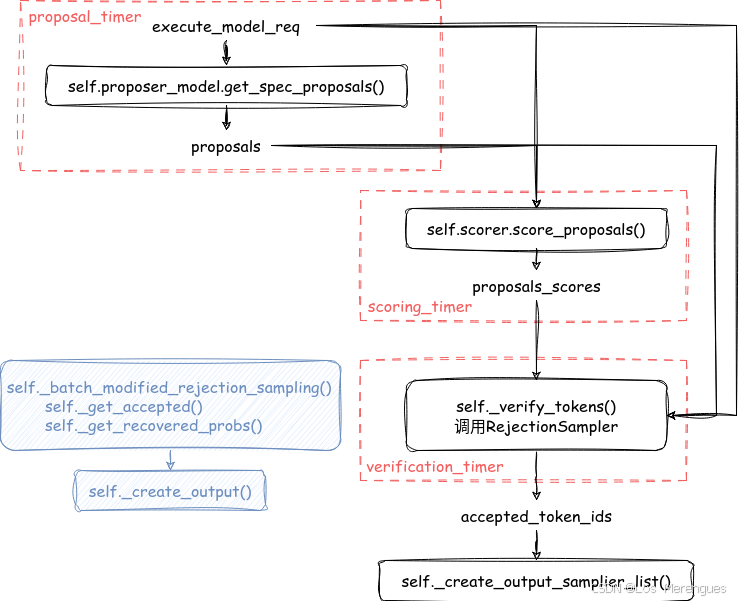
proposer_worker
self.proposer_worker.get_spec_proposals()
调用 multi_step_worker.get_spec_proposals()
调用 Top1Proposer.get_spec_proposals()
scorer_worker
RejectionSampler
def forward(
self,
target_with_bonus_probs: torch.Tensor,
bonus_token_ids: torch.Tensor,
draft_probs: torch.Tensor,
draft_token_ids: torch.Tensor,
seeded_seqs: Optional[Dict[int, torch.Generator]] = None,
) -> torch.Tensor:
# 检查尺寸
if self._strict_mode:
self._raise_if_incorrect_input(target_with_bonus_probs, draft_token_ids, bonus_token_ids, draft_probs)
batch_size, k, _ = draft_probs.shape
# batch_size = 0 when all requests in the batch are non_spec requests.
# In this case, output_token_ids is just an empty tensor.
if batch_size == 0:
return torch.empty(0, k + 1, device=draft_probs.device, dtype=int)
accepted, recovered_token_ids = (
self._batch_modified_rejection_sampling(
target_with_bonus_probs[:, :-1], # scorer
draft_probs, # draft
draft_token_ids, # draft
seeded_seqs,
))
output_token_ids = self._create_output(
accepted,
recovered_token_ids,
draft_token_ids,
bonus_token_ids,
)
return output_token_ids
_batch_modified_rejection_sampling
def _get_accepted
已知序列 x 1 , … , x n x_1, \dots, x_n x1,…,xn, q ( x ^ n + 1 ∣ x 1 , … , x n ) q(\hat{x}_{n+1}|x_1, \dots, x_n) q(x^n+1∣x1,…,xn)表示 scorer_proposal(target model)对于 x ^ n + 1 \hat{x}_{n+1} x^n+1的评分(条件概率), p ( x ^ n + 1 ∣ x 1 , … , x n ) p(\hat{x}_{n+1}|x_1, \dots, x_n) p(x^n+1∣x1,…,xn)表示草案模型对于 x ^ n + 1 \hat{x}_{n+1} x^n+1的置信度得分。这个token被接受的概率表示为:
min ( 1 , q ( x ^ n + 1 ∣ x 1 , … , x n ) p ( x ^ n + 1 ∣ x 1 , … , x n ) ) \min\left(1, \frac{q(\hat{x}_{n+1}|x_1, \dots, x_n)} {p(\hat{x}_{n+1}|x_1, \dots, x_n)}\right) min(1,p(x^n+1∣x1,…,xn)q(x^n+1∣x1,…,xn))
简单理解一下:
- target model对于该token的评分越高,被接受的概率越大;
- 如果draft model置信度 < target model评分,该token一定会被接受。
代码实现:
def _get_accepted(
self,
target_probs: torch.Tensor, # [batch_size, k, vocab_size]
draft_probs: torch.Tensor, # [batch_size, k, vocab_size]
draft_token_ids: torch.Tensor, # [batch_size, k]
seeded_seqs: Optional[Dict[int, torch.Generator]],
) -> torch.Tensor:
batch_size, k, _ = draft_probs.shape
batch_indices = torch.arange(batch_size, device=target_probs.device)[:, None]
probs_indicies = torch.arange(k, device=target_probs.device)
# 草案模型置信度序列 shape=[batch_size, k]
selected_draft_probs = draft_probs[batch_indices, probs_indicies, draft_token_ids]
# scorer_proposal得分序列 shape=[batch_size, k]
selected_target_probs = target_probs[batch_indices, probs_indicies, draft_token_ids]
# 生成随机序列 shape=[batch_size, k]
uniform_rand = self._create_uniform_samples(seeded_seqs, batch_size, k-1, target_probs.device)
capped_ratio = torch.minimum(
selected_target_probs / selected_draft_probs, torch.full((1, ), 1, device=target_probs.device))
accepted = uniform_rand < capped_ratio
return accepted # shape=[batch_size, k]
def _get_recovered_probs
作用:确保即使所有提议标记都被拒绝,拒绝抽样程序中也始终会发出至少一个token
参考链接:[Speculative decoding 1/9] Optimized rejection sampler #2336
x n + 1 ∼ ( q ( x ∣ x 1 , … , x n ) − p ( x ∣ x 1 , … , x n ) ) + x_{n+1} \sim ( q(x|x_1, \dots, x_n) - p(x|x_1, \dots, x_n) )_+ xn+1∼(q(x∣x1,…,xn)−p(x∣x1,…,xn))+
其中 ( f ( x ) ) + (f(x))_+ (f(x))+定义如下
( f ( x ) ) + = max ( 0 , f ( x ) ) ∑ x max ( 0 , f ( x ) ) (f(x))_+ = \frac{\max(0, f(x))}{\sum_x \max(0, f(x))} (f(x))+=∑xmax(0,f(x))max(0,f(x))
代码实现:
def _get_recovered_probs(
self,
target_probs: torch.Tensor, # [k, vocab_size]
draft_probs: torch.Tensor, # [k, vocab_size]
) -> torch.Tensor:
_, k, _ = draft_probs.shape
# shape [batch_size, k, vocab_size]
difference = target_probs - draft_probs
# shape [batch_size, k, vocab_size]
f = torch.clamp(difference, min=self._smallest_positive_value) # avoid division-by-zero errors
recovered_probs = f / torch.sum(f, dim=-1).reshape(-1, k, 1)
return recovered_probs
_create_output

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)