Centos7负载异常过高排查思路(Load Average)
大量小文件读写(如Web静态资源)需考虑合并或使用缓存(如Redis)。:若进程频繁读写大文件(如日志、数据库文件),需优化文件切分或归档策略。:I/O等待高,可能磁盘或网络瓶颈(需结合I/O排查)。若进程内存持续增长且无释放,需重启服务或修复代码。频繁释放,表明内存不足,需优化应用内存或扩容。:内核态占用高,可能是系统调用频繁或中断异常。:磁盘繁忙,可能频繁读写或硬件性能不足。:I/O响应慢,可
目录
确认负载高的问题类型
- 查看当前负载:
uptime # 显示1/5/15分钟负载平均值
top # 查看实时负载(Load Average行)及CPU使用率
负载值的合理范围:建议5分钟负载 ≤ CPU逻辑核心数。若持续高于核心数,需深入排查。
检查CPU使用情况
- 查看CPU整体使用率:
top # 按`1`显示多核CPU详情,观察us(用户态)、sy(内核态)、wa(I/O等待)等指标
vmstat 1 # 查看上下文切换(cs)、中断(in)等
-
高
us:用户进程占用高,需排查具体进程。 -
高
sy:内核态占用高,可能是系统调用频繁或中断异常。 -
高
wa:I/O等待高,可能磁盘或网络瓶颈(需结合I/O排查)。 -
定位高CPU进程:
top中按P(按CPU排序)或M(按内存排序)。- 记录占用最高的PID(进程ID)。
-
分析进程内线程:
top -Hp [PID] # 查看指定进程的线程CPU占用
printf "%x\n" [TID] # 将线程ID转为16进制(用于后续分析)
- 深入分析代码热点:
perf top -p [PID] # 查看进程的函数级CPU消耗(需安装perf)
strace -p [PID] # 跟踪系统调用(排查频繁调用)
检查I/O瓶颈
- 查看磁盘I/O负载:
iostat -x 1 # 观察%util(设备利用率)、await(I/O等待时间)
iotop # 按进程查看磁盘I/O使用
-
高
%util:磁盘繁忙,可能频繁读写或硬件性能不足。 -
高
await:I/O响应慢,可能磁盘故障或配置问题。 -
检查文件系统状态:
df -h # 查看磁盘空间是否耗尽
dmesg | grep -i error# 检查磁盘错误日志
内存与Swap分析
- 查看内存使用:
free -h # 查看物理内存和Swap使用
top # 按`M`排序内存占用进程
- Swap频繁使用:物理内存不足,需优化内存或扩容。
- OOM Killer触发:检查
dmesg是否有OOM日志。
排查僵尸进程和异常进程
- 检查僵尸进程:
ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]' # 列出僵尸进程
僵尸进程需终止其父进程(通过kill -9 [PPID])。
- 检查异常进程:
ps aux | grep [可疑进程名]
lsof -p [PID] # 查看进程打开的文件和网络连接
网络瓶颈排查
- 查看网络流量:
sar -n DEV 1 # 实时监控网络接口流量
netstat -antp # 查看TCP连接状态
其他工具
- sar(历史数据分析):
sar -q # 查看历史负载趋势
sar -u # 查看历史CPU使用率
- 系统日志:
journalctl -f # 实时查看系统日志
cat /var/log/messages | grep -i error
查看磁盘状态
通过命令查看磁盘IO较高
iostat -xd 2
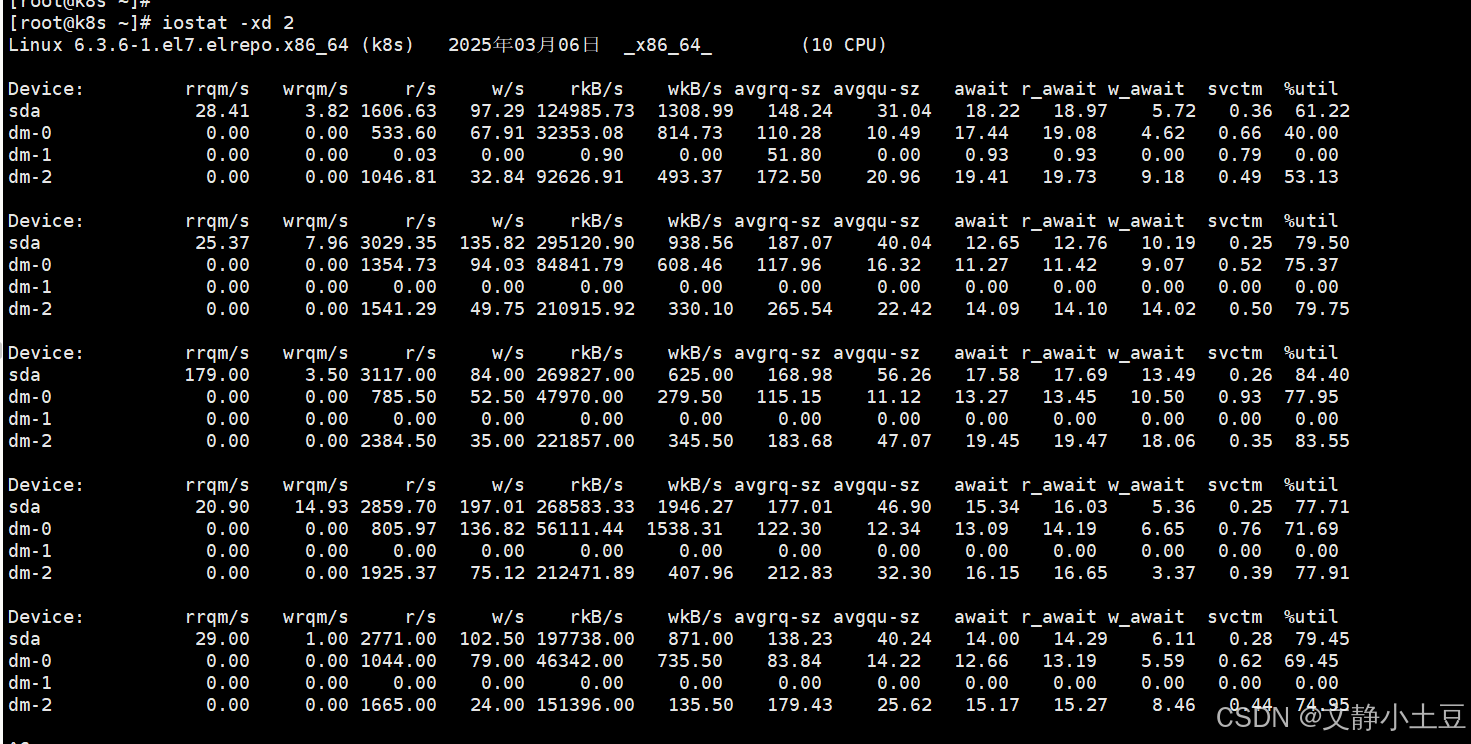
高I/O负载设备
-
sda 磁盘:
- %util:首次采样达 63.03%,后续波动在 12.45%~29.80%,但最后一次采样中
dm-0的 %util 达 100%(参考输出第二组数据)。 - 读写吞吐:首次采样 rkB/s=126,551.57(约 123.6 MB/s),说明大量读操作。
- 队列积压:
avgqu-sz首次采样为 31.26(高队列积压),await首次达 18ms(I/O延迟较高)。
- %util:首次采样达 63.03%,后续波动在 12.45%~29.80%,但最后一次采样中
-
逻辑卷 dm-0/dm-2:
- dm-0:首次采样 rkB/s=32,555.22(约 31.8 MB/s),
%util=40.64%。 - dm-2:首次采样 rkB/s=93,990.45(约 91.8 MB/s),
%util=54.94%,读写请求密集。
- dm-0:首次采样 rkB/s=32,555.22(约 31.8 MB/s),
问题定位
- I/O瓶颈:
%util多次超过 70%(如dm-0达 100%),表明磁盘已饱和,请求排队严重。 - 高读操作:
rkB/s和r/s显著偏高,可能是频繁读取大文件或数据库全表扫描导致。
排查步骤
定位高I/O进程
使用 iotop 或 pidstat 直接查看实时I/O占用:
iotop -o # 显示活跃I/O进程
pidstat -d 1 # 按进程统计I/O
重点观察 DISK READ 和 DISK WRITE 列,定位占用高的进程。
检查文件系统和磁盘空间
df -h # 确认磁盘空间是否耗尽
dmesg | grep -i error # 检查磁盘错误日志
若磁盘空间不足或存在坏道,会导致I/O性能骤降。
分析文件访问模式
-
大文件读写:若进程频繁读写大文件(如日志、数据库文件),需优化文件切分或归档策略。
-
小文件频繁操作:大量小文件读写(如Web静态资源)需考虑合并或使用缓存(如Redis)。
-
磁盘健康:使用
smartctl检测磁盘健康:
smartctl -a /dev/sda
- 直接原因:sda/dm-0/dm-2 的I/O饱和,大量读请求导致队列积压和延迟。
查看CPU使用情况
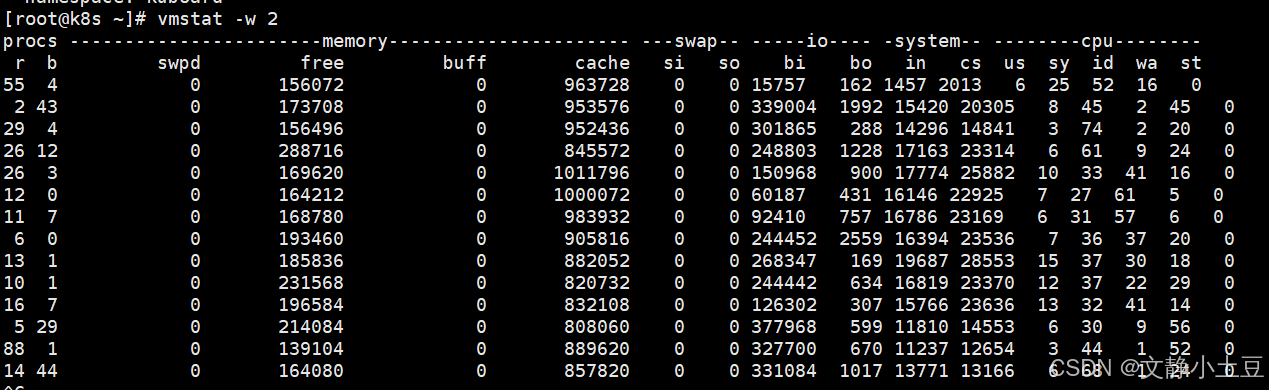
关键指标分析
-
CPU负载:
- 运行队列(
r列):多次超过 50(如r=88),远超CPU核心数(10核),说明进程排队严重。 - 等待I/O的进程(
b列):最高达 44,表明大量进程因I/O阻塞。 - CPU时间分配:
- 用户态(
us):较低(3%~15%),排除用户进程直接占用CPU的可能。 - 系统态(
sy):多次超过 70%(如sy=74%),内核处理I/O或锁竞争导致。 - I/O等待(
wa):最高达 56%,确认磁盘是瓶颈。
- 用户态(
- 运行队列(
-
I/O活动:
- 块设备读(
bi):最高达 377,968 块/秒(约 147.5 MB/s),远超机械盘吞吐能力。 - 上下文切换(
cs):高达 28,553次/秒,频繁进程切换加剧CPU压力。
- 块设备读(
-
内存:
- 空闲内存(
free):波动大(最低 139 MB),但cache较高(约 800 MB~1 GB),系统利用缓存缓解I/O压力。 - 无Swap使用(
si/so=0):内存未耗尽,但缓存频繁刷写可能影响性能。
- 空闲内存(
排查步骤
定位高I/O进程
iotop -o -P # 查看实时I/O读写进程
pidstat -d 1 # 按进程统计I/O
示例关注:
- DISK READ 列高(如 MySQL、日志服务)。
- 进程状态:若多为
D(不可中断睡眠),表明等待磁盘I/O。
检查磁盘健康
smartctl -a /dev/sda # 检查磁盘SMART状态
dmesg | grep -i error # 查看磁盘错误日志
若发现坏道或高延迟,需更换磁盘。
分析文件访问
lsof -p <PID> # 查看进程打开的文件
strace -p <PID> -e trace=file # 跟踪文件操作
确认是否为 大文件顺序读 或 小文件随机读,优化访问模式。
检查内存缓存
free -m # 查看缓存和缓冲区使用
sar -r 1 # 监控内存压力
若 cache 频繁释放,表明内存不足,需优化应用内存或扩容。
检查内存使用情况
根据提供的 free -h 输出系统存在 内存耗尽风险(总内存 15G,已用 14G,可用仅 600MB),但未触发 Swap(Swap=0),以下是详细分析和解决方案: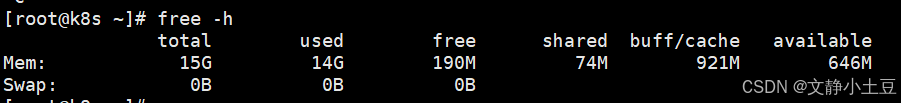
关键指标分析
-
内存分布:
- 已用内存(
used):14G,占比 93%,接近物理内存上限。 - 可用内存(
available):600MB,表明系统处于内存紧张状态,可能触发 OOM Killer。 - 缓存/缓冲区(
buff/cache):911MB,较低,说明系统未有效利用缓存缓解I/O压力。
- 已用内存(
-
潜在风险:
- OOM Killer:若突发内存需求,内核会强制终止进程释放内存(参考
/var/log/messages中的Out of memory日志)。 - 性能下降:频繁内存回收导致CPU占用升高(如
kswapd进程活跃)。
- OOM Killer:若突发内存需求,内核会强制终止进程释放内存(参考
定位高内存进程
top -o %MEM # 按内存占用排序
ps aux --sort=-%mem | head -n 10 # 列出前10内存消耗进程
重点关注:
- %MEM 列:持续高占比的进程(如 MySQL、Java 应用)。
- 进程状态:若为
D(不可中断睡眠)或Z(僵尸进程),可能关联资源泄漏。
检查内存泄漏
valgrind --leak-check=full -v [应用程序路径] # 检测特定程序内存泄漏
cat /proc/[PID]/status | grep VmRSS # 监控进程内存增长趋势
若进程内存持续增长且无释放,需重启服务或修复代码。
优化建议
系统层调优
- I/O调度器:改为
deadline或noop(SSD适用):
echo deadline > /sys/block/sda/queue/scheduler
- 内核参数:增大磁盘队列深度:
echo 1024 > /sys/block/sda/queue/nr_requests
负载高的原因
- I/O密集型负载:大量读操作(
bi高)导致磁盘饱和,进程因等待I/O堆积(b列高),引发高负载和系统态CPU占用。 - 可能的场景:数据库全表扫描、日志文件未轮转、文件系统元数据操作频繁(如小文件读写)。
- 磁盘I/O饱和(高
bi、wa)导致进程排队(高b)和系统态CPU占用(高sy)。 - 物理内存耗尽(15G 中已用 14G),主要嫌疑为 MySQL 配置不当或 应用内存泄漏。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)