rag知识库总结,零基础入门到精通,收藏这篇就够了
RAG的核心在于准确与快速的检索在之前关于RAG技术的文章中有介绍过知识库与检索增强的关系;也简单介绍了RAG的使用场景。而RAG和向量数据库的实现原理,以及怎么选择向量数据库,是在智能客服,推荐系统等领域必须要解决的一个问题。RAG与向量数据库先来回答第一个问题, 什么是检索增强——RAG?
“ RAG的核心在于准确与快速的检索 ”
在之前关于RAG技术的文章中有介绍过知识库与检索增强的关系;也简单介绍了RAG的使用场景。
而RAG和向量数据库的实现原理,以及怎么选择向量数据库,是在智能客服,推荐系统等领域必须要解决的一个问题。
RAG与向量数据库
先来回答第一个问题, 什么是检索增强——RAG?
顾名思义,RAG的全拼是Retrieval-augmented Generation,检索增强生成,R——代表的是Retrieval-检索器,G代表的是Generation-生成器,所以RAG主要有两大块组成,检索与生成。
检索
检索的过程包括数据的加载与切分,嵌入向量并构建索引,再通过向量检索召回相关结果。而生成过程则是利用基于检索结果增强的提示词(prompt)来激活LLM生成回答。
RAG技术的关键在于结合了检索与生成的优点,检索系统能提供具体相关的事实和数据;而生成模型能够灵活的构建回答,并融入更广泛的语境和信息。
这种结合使得 RAG 模型在处理复杂的查询和生成信息丰富的回答方面非常有效,在问答系统、对话系统和其他需要理解和生成自然语言的应用中非常有用。
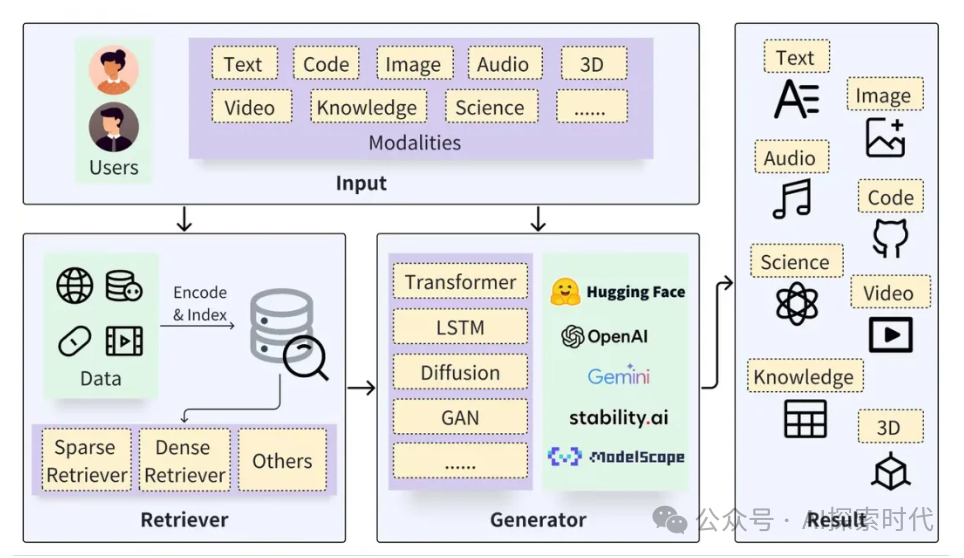
相较于大型模型本身的能力,搭配 RAG 可以解决大模型天生的缺陷问题:
减少“幻觉”问题:RAG 通过检索外部信息作为输入,辅助大型模型回答问题,这种方式能大大降低大模型的幻觉问题,增加回答的可追溯性。
数据隐私和安全:RAG 可以将知识库作为管理私有数据的一种方式,避免企业内部数据外泄。
信息的实时性:RAG 允许从外部数据源实时检索信息,因此可以获取最新的、领域特定的知识,解决知识时效性问题。
虽然大模型的前沿研究也在致力于解决以上的问题,例如基于私有数据的微调、提升模型自身的长文本处理能力,openAI CEO奥特曼还曾说要再近两年内解决大模型的幻觉问题。
虽然这些研究有助于推动大型模型技术的进步,然而在更通用的场景下,RAG 依然是一个稳定、可靠且性价比高的选择。
这主要是因为 RAG 具有以下的优势:
白盒模型:相较于微调和长文本处理的“黑盒”效应,RAG 模块之间的关系更为清晰紧密,而且更加一目了然;此外,在检索召回内容质量和置信度(Certainty)不高的情况下,RAG 系统甚至可以禁止 LLMs 的介入,直接回复“不知道”而非胡编乱造。
成本和响应速度:RAG 相比于微调模型具有训练时间短和成本低的优势;而与长文本处理相比,则拥有更快的响应速度和更低的推理成本。在研究和实验阶段,效果和精确程度是最吸引人的;但在工业和产业落地方面,成本则是不容忽视的决定性因素。
私有数据管理:通过将知识库与大型模型解耦,RAG 不仅提供了一个安全可落地的实践基础,同时也能更好地管理企业现有和新增的知识,解决知识依赖问题。而与之相关的另一个角度则是访问权限控制和数据管理,这对 RAG 的底座数据库来说是很容易做到的,但对于大模型来说却很难。
因此在作者看来,随着对大型模型研究的不断深入,RAG 技术并不会被取代,相反会在相当长的时间内保有重要地位。这主要得益于其与 LLM 的天然互补性,这种互补性使得基于 RAG 构建的应用能在许多领域大放异彩。
而 RAG 提升的关键一方面在 LLMs 能力的提升,而另一方面则依赖于检索(Retrieval)的各类提升和优化。
RAG 检索的底座:向量数据库
在业界实践中,RAG 检索通常与向量数据库密切结合,也催生了基于 ChatGPT + Vector Database + Prompt 的 RAG 解决方案,简称为 CVP 技术栈。
这一解决方案依赖于向量数据库高效检索相关信息以增强大型语言模型(LLMs),通过将 LLMs 生成的查询转换为向量,使得 RAG 系统能在向量数据库中迅速定位到相应的知识条目。这种检索机制使 LLMs 在面对具体问题时,能够利用存储在向量数据库中的最新信息,有效解决 LLMs 固有的知识更新延迟和幻觉的问题。
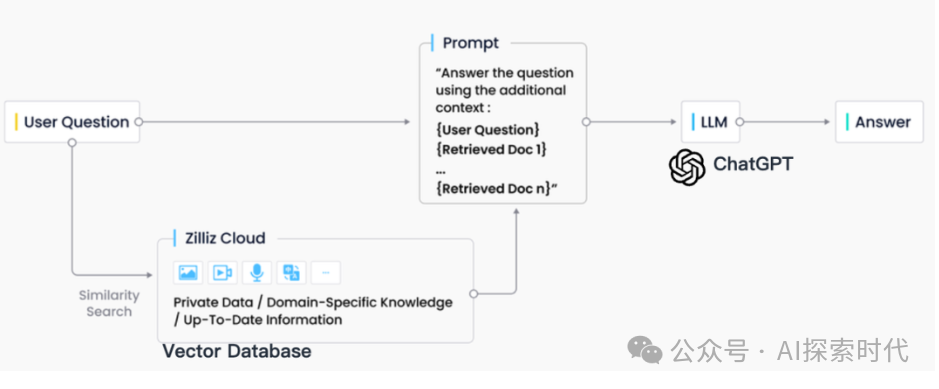
尽管信息检索领域也存在选择众多的存储与检索技术,包括搜索引擎、关系型数据库和文档数据库等,向量数据库在 RAG 场景下却成为了业界首选。
这一选择的背后,是向量数据库在高效地存储和检索大量嵌入向量方面的出色能力。这些嵌入向量由机器学习模型生成,不仅能够表征文本和图像等多种数据类型,还能够捕获它们深层的语义信息。
在 RAG 系统中,检索的任务是快速且精确地找出与输入查询语义上最匹配的信息,而向量数据库正因其在处理高维向量数据和进行快速相似性搜索方面的显著优势而脱颖而出。
首先在实现原理方面,向量是模型对语义含义的编码形式,向量数据库可以更好地理解查询的语义内容,因为它们利用了深度学习模型的能力来编码文本的含义,不仅仅是关键字匹配。受益于 AI 模型的发展,其背后语义准确度也正在稳步提升,通过用向量的距离相似度来表示语义相似度已经发展成为了 NLP 的主流形态,因此表意的 embedding 就成了处理信息载体的首选。
其次在检索效率方面,由于信息可以表示成高维向量,针对向量加上特殊的索引优化和量化方法,可以极大提升检索效率并压缩存储成本,随着数据量的增长,向量数据库能够水平扩展,保持查询的响应时间,这对于需要处理海量数据的 RAG 系统至关重要,因此向量数据库更擅长处理超大规模的非结构化数据。
至于泛化能力这个维度,传统的搜索引擎、关系型或文档数据库大都只能处理文本,泛化和扩展的能力差,向量数据库不仅限于文本数据,还可以处理图像、音频和其他非结构化数据类型的嵌入向量,这使得 RAG 系统可以更加灵活和多功能。
最后在总拥有成本上,相比于其他选项,向量数据库的部署都更加方便、易于上手,同时也提供了丰富的 API,使其易于与现有的机器学习框架和工作流程集成,因而深受许多 RAG 应用开发者的喜爱。
场景对向量数据库的需求
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。
这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
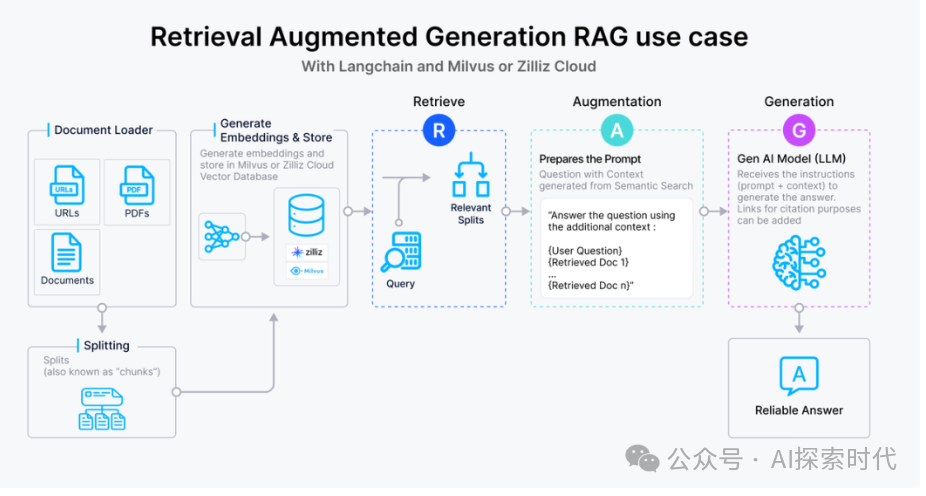
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。
为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。
而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)