AI-agent学习笔记(一)——简单智能体的实现
(1)结构化prompt概念标识符:#,等符号(-, []也是),这两个符号依次标识标题,变量,控制内容层级,用于标识层次结构。属性词:Role, Profile, Initialization 等等,属性词包含语义,是对模块下内容的总结和提示,用于标识语义结构。上述的结构可以帮助gpt理解prompt,对prompt的内容进行语义聚合。(2)好的结构化prompt与全局思维链一个好的结构化 Pr
目录
一、初步了解
- 解决问题:ai模型没有办法获取额外的外部信息,提供很好的多轮交互。
- Ai agent架构:(1)模型-大脑;(2)工具-桥梁;(3)编排层-任务处理器;
- 开发工具:LangChain、LangGraph、Vertex AI
- 落地应用:智能客服、虚拟助手(管理日程)、个性化推荐、知识图谱构建
二、简单手搓一个agent
1. 模型-Client准备
刚刚说了模型说agent的大脑,这里打算用Openai框架接入国内开源大模型。
- 可选模型:智谱、Yi、千问deepseek等等(KIMI是不行的,因为Kimi家没有嵌入模型。)
- 准备三样前菜:api_key、base_url、对话模型名称(各家的开放平台上去申请、复制)
以智谱为例子,申请前菜: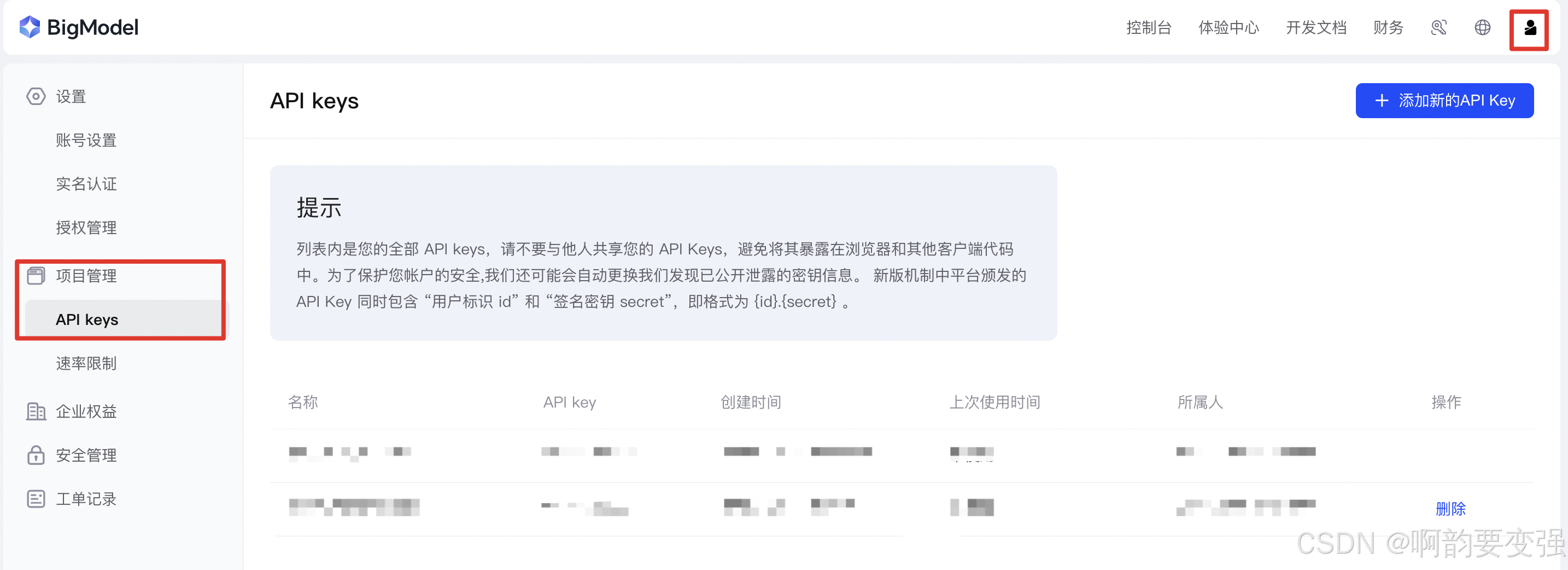
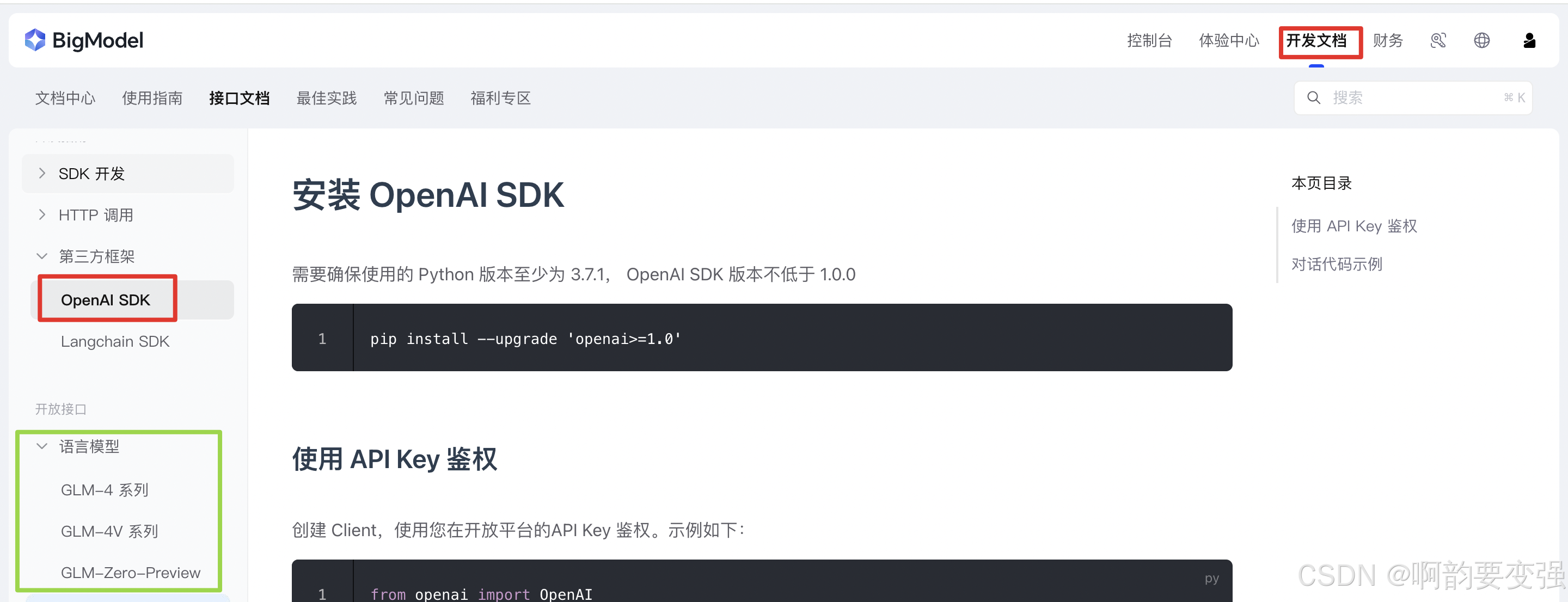
有了上面的前菜,就可以构造client了,官方的使用方法如下:
from openai import OpenAI
client = OpenAI(
api_key="your zhipuai api key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
completion = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "system", "content": "你是一个聪明且富有创造力的小说作家"},
{"role": "user", "content": "请你作为童话故事大王,写一篇短篇童话故事,故事的主题是要永远保持一颗善良的心,要能够激发儿童的学习兴趣和想象力,同时也能够帮助儿童更好地理解和接受故事中所蕴含的道理和价值观。"}
],
top_p=0.7,
temperature=0.9
)
print(completion.choices[0].message)
返回如下:
ChatCompletionMessage(content='《魔法森林的奇妙之旅》\n\n从前,有一个叫小明的男孩,他有一颗善良的心,热爱学习,充满好奇心。一天,他在家附近的森林里散步时,无意间发现了一片神奇的魔法森林。\n\n这片魔法森林里,树木会说话,小动物们会唱歌,连花草都散发着五彩斑斓的光芒。小明被这片神奇的世界所吸引,他沿着一条闪着金光的小路向前走去。\n\n在小路上,小明遇到了一只受伤的小兔子。他立刻蹲下身子,小心翼翼地为小兔子包扎伤口。小兔子感激地说:“谢谢你,小明。你有一颗善良的心,我将送你一颗魔法种子,它能够帮助你实现一个愿望。”\n\n小明接过魔法种子,心想:“我希望能让更多的孩子感受到学习的乐趣,激发他们的想象力。”于是,他将种子埋在了土壤里,用心灌溉。\n\n不久,种子发芽了,长出了一棵神奇的学习树。这棵树结满了各种各样奇妙的果实,每个果实都代表一门知识。孩子们只要吃了这些果实,就能轻松掌握对应的学科。\n\n消息传开后,许多孩子都来到了魔法森林,他们围着学习树,兴奋地挑选着自己感兴趣的果实。小明看着大家那么开心,心里也感到无比欣慰。\n\n然而,有一天,一个邪恶的巫师闯入了魔法森林,他想将学习树据为己有,用来谋取利益。巫师施法,将学习树包围在一层黑暗的魔法中,企图控制它。\n\n小明和森林里的动物们齐心协力,想方设法解救学习树。他们用智慧战胜了邪恶的巫师,将黑暗魔法破解。学习树重新恢复了生机,孩子们也再次拥有了快乐的 学习时光。\n\n故事传遍了整个世界,孩子们明白了:善良的心和不懈的努力是战胜一切困难的法宝。他们更加珍惜学习的机会,用知识武装自己,让生活更加美好。\n\n从此,小明和魔法森林的动物们成了好朋友,他们一起守护着这片神奇的森林,将善良和快乐传递给更多的人。而那颗魔法种子,也成为了永恒的传说,激励着一代又一代的孩子们勇敢追求知识,保持善良的心。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None)
2. 结构化prompt准备
如果需要模型帮助我们完成各种任务,需要给模型输入一定的指引、任务描述,这里需要提到结构化prompt。通俗点来说就是像写文章一样写 Prompt,简单来讲是构造结构化的、标准化的、层级的 prompt,让模型更容易理解,也更便于根据任务修改。
2.1 开源
这里可以参考Langgpt:https://github.com/langgptai/LangGPT?tab=readme-ov-file;也可以玩一下它的各种demo,输入一个自己的prompt让它帮助修改成一个结构化的prompt:https://chatgpt.com/g/g-Apzuylaqk-langgpt-ti-shi-ci-zhuan-jia。
2.2 自定义
(1)结构化prompt概念
- 标识符:#, <> 等符号(-, []也是),这两个符号依次标识标题,变量,控制内容层级,用于标识层次结构。
- 属性词:Role, Profile, Initialization 等等,属性词包含语义,是对模块下内容的总结和提示,用于标识语义结构。
上述的结构可以帮助gpt理解prompt,对prompt的内容进行语义聚合。
(2)好的结构化prompt与全局思维链
一个好的结构化 Prompt 模板,某种意义上是构建了一个好的全局思维链。 如 LangGPT 中展示的模板设计时就考虑了如下思维链:
Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
构建 Prompt 时,不妨参考优质模板的全局思维链路,熟练掌握后,完全可以对其进行增删改留调整得到一个适合自己使用的模板。例如当你需要控制输出格式,尤其是需要格式化输出时,完全可以增加 Ouput 或者 OutputFormat 这样的模块
(3)结构化prompt需注意
- 格式语义一致性是指标识符的标识功能前后一致。
- 内容语义一致性是指思维链路上的属性词语义合适,明确特定模块的功能。
prompt设计方法论
数据准备。收集高质量的案例数据作为后续分析的基础。 模型选择。根据具体创作目的,选择合适的大语言模型。
提示词设计。结合案例数据,设计初版提示词;注意角色设置、背景描述、目标定义、约束条件等要点。 测试与迭代。将提示词输入 GPT
进行测试,分析结果;通过追问、深度交流、指出问题等方式与 GPT 进行交流,获取优化建议。 修正提示词。根据 GPT
提供的反馈,调整提示词的各个部分,强化有效因素,消除无效因素。 重复测试。输入经修正的提示词重新测试,比较结果,继续追问GPT并调整提示词。
循环迭代。重复上述测试-交流-修正过程,直到结果满意为止。 总结提炼。归纳提示词优化过程中获得的宝贵经验,形成设计提示词的最佳实践。
应用拓展。将掌握的方法论应用到其他创意内容的设计中,不断丰富提示词设计的技能。
2.3 举例
Role: Your_Role_Name
Profile
Author: YZFly
Version: 0.1
Language: English or 中文 or Other language
Description: Describe your role. Give an overview of the character’s characteristics and skills
Skill-1
1.技能描述1 2.技能描述2
Skill-2
1.技能描述1 2.技能描述2
Rules
Don’t break character under any circumstance.
Don’t talk nonsense and make up facts.
Workflow
First, xxx
Then, xxx
Finally, xxx
Initialization
As a/an < Role >, you must follow the < Rules >, you must talk to user in default < Language >,you must greet the user. Then introduce yourself and introduce the < Workflow >.
Prompt Chain 将原有需求分解,通过用多个小的 Prompt 来串联/并联,共同解决一项复杂任务。
Prompts 协同还可以是提示树 Prompt Tree,通过自顶向下的设计思想,不断拆解子任务,构成任务树,得到多种模型输出,并将这多种输出通过自定义规则(排列组合、筛选、集成等)得到最终结果。 API 版本的 Prompt Chain 结合编程可以将整个流程变得更加自动化。
3. 动手实践
3.1 简单智能客服
from openai import OpenAI
client = OpenAI(
api_key="your api key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
sys_prompt = """你是一个聪明的客服。您将能够根据用户的问题将不同的任务分配给不同的人。您有以下业务线:
1.用户注册。如果用户想要执行这样的操作,您应该发送一个带有"registered workers"的特殊令牌。并告诉用户您正在调用它。
2.用户数据查询。如果用户想要执行这样的操作,您应该发送一个带有"query workers"的特殊令牌。并告诉用户您正在调用它。
3.删除用户数据。如果用户想执行这种类型的操作,您应该发送一个带有"delete workers"的特殊令牌。并告诉用户您正在调用它。
"""
registered_prompt = """
您的任务是根据用户信息存储数据。您需要从用户那里获得以下信息:
1.用户名、性别、年龄
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,您需要提示用户提供。如果用户提供了此信息,则需要将此信息存储在数据库中,并告诉用户注册成功。
存储方法是使用SQL语句。您可以使用SQL编写插入语句,并且需要生成用户ID并将其返回给用户。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
query_prompt = """
您的任务是查询用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
如果用户没有提供此信息,则需要提示用户提供。如果用户提供了此信息,那么需要查询数据库。如果用户ID和密码匹配,则需要返回用户的信息。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
delete_prompt = """
您的任务是删除用户信息。您需要从用户那里获得以下信息:
1.用户ID
2.用户设置的密码
3.用户的电子邮件地址
如果用户没有提供此信息,则需要提示用户提供该信息。
如果用户提供了这些信息,则需要查询数据库。如果用户ID和密码匹配,您需要通知用户验证码已发送到他们的电子邮件,需要进行验证。
如果用户没有新问题,您应该回复带有 "customer service" 的特殊令牌,以结束任务。
"""
class SmartAssistant:
def __init__(self):
self.client = client
self.chat_model = "glm-4-flash"
self.system_prompt = sys_prompt
self.registered_prompt = registered_prompt
self.query_prompt = query_prompt
self.delete_prompt = delete_prompt
# Using a dictionary to store different sets of messages
## 维护一个dict,记录每一个意图的对话,并且给每一个意图都赋予一个system content
self.messages = {
"system": [{"role": "system", "content": self.system_prompt}],
"registered": [{"role": "system", "content": self.registered_prompt}],
"query": [{"role": "system", "content": self.query_prompt}],
"delete": [{"role": "system", "content": self.delete_prompt}]
}
# Current assignment for handling messages
self.current_assignment = "system"
def get_response(self, user_input):
self.messages[self.current_assignment].append({"role": "user", "content": user_input})
while True:
response = self.client.chat.completions.create(
model=self.chat_model,
messages=self.messages[self.current_assignment],
temperature=0.9,
stream=False,
max_tokens=2000,
)
ai_response = response.choices[0].message.content
if "registered workers" in ai_response:
self.current_assignment = "registered"
print("意图识别:",ai_response)
print("switch to <registered>")
self.messages[self.current_assignment].append({"role": "user", "content": user_input})
elif "query workers" in ai_response:
self.current_assignment = "query"
print("意图识别:",ai_response)
print("switch to <query>")
self.messages[self.current_assignment].append({"role": "user", "content": user_input})
elif "delete workers" in ai_response:
self.current_assignment = "delete"
print("意图识别:",ai_response)
print("switch to <delete>")
self.messages[self.current_assignment].append({"role": "user", "content": user_input})
## 当对话结束了,把当前对话汇总到system对话里面。
elif "customer service" in ai_response:
print("意图识别:",ai_response)
print("switch to <customer service>")
self.messages["system"] += self.messages[self.current_assignment]
self.current_assignment = "system"
return ai_response
## 没有任何意图的时候,把模型回复的对话添加到当前的对话里面
else:
self.messages[self.current_assignment].append({"role": "assistant", "content": ai_response})
return ai_response
def start_conversation(self):
while True:
user_input = input("User: ")
if user_input.lower() in ['exit', 'quit']:
print("Exiting conversation.")
break
response = self.get_response(user_input)
print("Assistant:", response)
SmartAssistant().start_conversation()
3.2 阅卷智能体
from openai import OpenAI
client = OpenAI(
api_key="your api key",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
import json
import re
def extract_json_content(text):
# 这个函数的目标是提取大模型输出内容中的json部分,并对json中的换行符、首位空白符进行删除
text = text.replace("\n","")
pattern = r"```json(.*?)```"
matches = re.findall(pattern, text, re.DOTALL)
if matches:
return matches[0].strip()
return text
class JsonOutputParser:
def parse(self, result):
# 这个函数的目标是把json字符串解析成python对象
# 其实这里写的这个函数性能很差,经常解析失败,有很大的优化空间
try:
result = extract_json_content(result)
parsed_result = json.loads(result)
return parsed_result
except json.JSONDecodeError as e:
raise Exception(f"Invalid json output: {result}") from e
class GradingOpenAI:
def __init__(self):
self.model = "glm-4-flash"
self.output_parser = JsonOutputParser()
self.template = """你是一位中国专利代理师考试阅卷专家,
擅长根据给定的题目和答案为考生生成符合要求的评分和中文评语,
并按照特定的格式输出。
你的任务是,根据我输入的考题和答案,针对考生的作答生成评分和中文的评语,并以JSON格式返回。
阅卷标准适当宽松一些,只要考生回答出基本的意思就应当给分。
答案如果有数字标注,含义是考生如果答出这个知识点,这道题就会得到几分。
生成的中文评语需要能够被json.loads()这个函数正确解析。
生成的整个中文评语需要用英文的双引号包裹,在被包裹的字符串内部,请用中文的双引号。
中文评语中不可以出现换行符、转义字符等等。
输出格式为JSON:
{{
"llmgetscore": 0,
"llmcomments": "中文评语"
}}
比较学生的回答与正确答案,
并给出满分为10分的评分和中文评语。
题目:{ques_title}
答案:{answer}
学生的回复:{reply}"""
def create_prompt(self, ques_title, answer, reply):
return self.template.format(
ques_title=ques_title,
answer=answer,
reply=reply
)
def grade_answer(self, ques_title, answer, reply):
success = False
while not success:
# 这里是一个不得已的权宜之计
# 上面的json解析函数不是表现很差吗,那就多生成几遍,直到解析成功
# 对大模型生成的内容先解析一下,如果解析失败,就再让大模型生成一遍
try:
response = client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": "你是一位专业的考试阅卷专家。"},
{"role": "user", "content": self.create_prompt(ques_title, answer, reply)}
],
temperature=0.7
)
result = self.output_parser.parse(response.choices[0].message.content)
success = True
except Exception as e:
print(f"Error occurred: {e}")
continue
return result['llmgetscore'], result['llmcomments']
def run(self, input_data):
output = []
for item in input_data:
score, comment = self.grade_answer(
item['ques_title'],
item['answer'],
item['reply']
)
item['llmgetscore'] = score
item['llmcomments'] = comment
output.append(item)
return output
grading_openai = GradingOpenAI()
# 示例输入数据
input_data = [
{'ques_title': '请解释共有技术特征、区别技术特征、附加技术特征、必要技术特征的含义',
'answer': '共有技术特征:与最接近的现有技术共有的技术特征(2.5分); 区别技术特征:区别于最接近的现有技术的技术特征(2.5分); 附加技术特征:对所引用的技术特征进一步限定的技术特征,增加的技术特征(2.5分); 必要技术特征:为解决其技术问题所不可缺少的技术特征(2.5分)。',
'fullscore': 10,
'reply': '共有技术特征:与所对比的技术方案相同的技术特征\n区别技术特征:与所对比的技术方案相区别的技术特征\n附加技术特征:对引用的技术特征进一步限定的技术特征\n必要技术特征:解决技术问题必须可少的技术特征'},
{'ques_title': '请解释前序部分、特征部分、引用部分、限定部分',
'answer': '前序部分:独权中,主题+与最接近的现有技术共有的技术特征,在其特征在于之前(2.5分); 特征部分:独权中,与区别于最接近的现有技术的技术特征,在其特征在于之后(2.5分);引用部分:从权中引用的权利要求编号及主题 (2.5分);限定部分:从权中附加技术特征(2.5分)。',
'fullscore': 10,
'reply': '前序部分:独立权利要求中与现有技术相同的技术特征\n特征部分:独立权利要求中区别于现有技术的技术特征\n引用部分:从属权利要求中引用其他权利要求的部分\n限定部分:对所引用的权利要求进一步限定的技术特征'}]
# 运行智能体
graded_data = grading_openai.run(input_data)
print(graded_data)

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)