UI-TARS-1.5:一个基于强大视觉-语言模型构建的开源多模态智能体
UI-TARS-1.5是一个基于强大视觉-语言模型构建的开源多模态智能体。它具备在虚拟世界中有效执行各种任务的能力,擅长游戏和图形用户界面(GUI)相关任务。该模型建立在近期论文提出的基础架构之上,通过强化学习实现了先进的推理能力,使其能够在行动前进行思考,显著提升了性能和适应性,尤其是在推理时的扩展能力方面。UI-TARS-1.5在多个标准基准测试中取得了最先进的成果,展现出了强大的推理能力和比
UI-TARS-1.5 模型解析
一、模型概述
UI-TARS-1.5是一个基于强大视觉-语言模型构建的开源多模态智能体。它具备在虚拟世界中有效执行各种任务的能力,擅长游戏和图形用户界面(GUI)相关任务。该模型建立在近期论文提出的基础架构之上,通过强化学习实现了先进的推理能力,使其能够在行动前进行思考,显著提升了性能和适应性,尤其是在推理时的扩展能力方面。UI-TARS-1.5在多个标准基准测试中取得了最先进的成果,展现出了强大的推理能力和比以往模型更为显著的进步。
二、模型性能表现
(一)在线基准评估
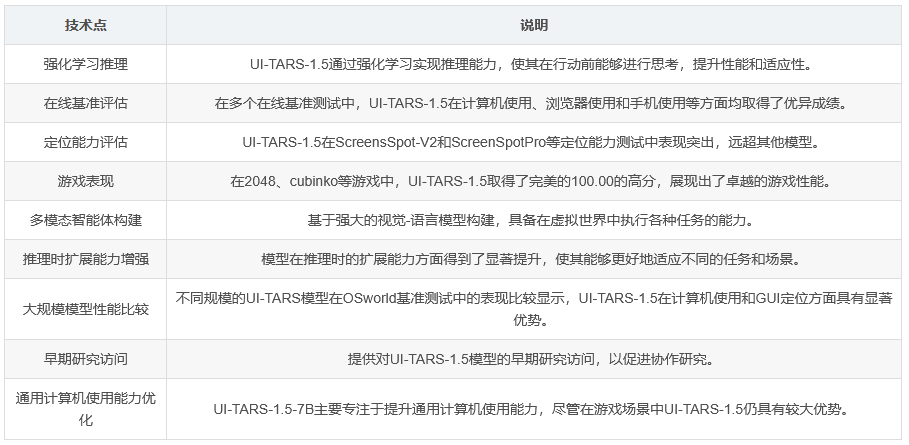
UI-TARS-1.5在计算机使用、浏览器使用和手机使用等多个基准测试中表现优异。例如,在Computer Use OSworld(100步骤)测试中,UI-TARS-1.5的得分为42.5,优于OpenAI的36.4、CUA的28以及Claude 3.7的38.1(200步骤)。在Windows Agent Arena(50步骤)测试中,UI-TARS-1.5同样以42.1的高分领先于OpenAI的29.8。在浏览器使用方面,UI-TARS-1.5在WebVoyager测试中的得分为84.8,与OpenAI的87、CUA的84.1和Claude 3.7的87相比较为接近。在Online-Mind2web测试中,UI-TARS-1.5以75.8的得分超过了OpenAI的71、CUA的62.9和Claude 3.7的71。
(二)定位能力评估
在定位能力测试中,UI-TARS-1.5同样表现出色。在ScreensSpot-V2测试中,UI-TARS-1.5的得分高达94.2,高于OpenAI的87.9、CUA的87.6和Claude 3.7的91.6。在更具挑战性的ScreenSpotPro测试中,UI-TARS-1.5的得分更是达到了61.6,远超OpenAI的23.4、CUA的27.7和Claude 3.7的43.6。
(三)游戏表现
在游戏领域,UI-TARS-1.5展现出了卓越的性能。以2048和cubinko等游戏为例,UI-TARS-1.5在这些游戏中的得分均为100.00,而其他模型如OpenAI、CUA和Claude 3.7在这些游戏中的得分则相对较低。例如,在2048游戏中,OpenAI的得分为31.04,CUA和Claude 3.7的得分为0.00;在cubinko游戏中,OpenAI的得分为0.00,CUA的得分为32.80,Claude 3.7的得分为0.00。此外,在其他游戏如energy、free、the key、Gem 11、hex、frvr、Infinity Loop、Maze:Path of Light和shapes中,UI-TARS-1.5同样取得了完美的100.00的高分。
三、模型规模比较
在不同规模的UI-TARS模型在OSworld基准测试中的表现比较中,UI-TARS-1.5在计算机使用方面得分为42.5,GUI定位方面在ScreenSpotPro测试中得分为61.6。而UI-TARS-72B-DPO在计算机使用方面的得分为24.6,在GUI定位方面的得分为38.1;UI-TARS-1.5-7B在计算机使用方面的得分为27.5,在GUI定位方面的得分为49.6。这表明UI-TARS-1.5在这些任务中具有显著的优势。尽管UI-TARS-1.5-7B主要专注于提升通用计算机使用能力,并未专门针对游戏场景进行优化,但UI-TARS-1.5在游戏场景中仍然保持了较大的优势。
四、研究合作与未来展望
目前,研发团队正在提供对表现最佳的UI-TARS-1.5模型的早期研究访问,以促进协作研究。有兴趣的研究人员可以通过联系TARS@bytedance.com来获取相关资源。关于未来的发展方向,团队计划继续对UI-TARS-1.5进行改进和优化,以提升其在更多任务和场景中的性能,同时探索其在不同领域的应用潜力。# UI-TARS-1.5 模型解析
一、模型概述
UI-TARS-1.5是一个基于强大视觉-语言模型构建的开源多模态智能体。它具备在虚拟世界中有效执行各种任务的能力,擅长游戏和图形用户界面(GUI)相关任务。该模型建立在近期论文提出的基础架构之上,通过强化学习实现了先进的推理能力,使其能够在行动前进行思考,显著提升了性能和适应性,尤其是在推理时的扩展能力方面。UI-TARS-1.5在多个标准基准测试中取得了最先进的成果,展现出了强大的推理能力和比以往模型更为显著的进步。
二、模型性能表现
(一)在线基准评估
UI-TARS-1.5在计算机使用、浏览器使用和手机使用等多个基准测试中表现优异。例如,在Computer Use OSworld(100步骤)测试中,UI-TARS-1.5的得分为42.5,优于OpenAI的36.4、CUA的28以及Claude 3.7的38.1(200步骤)。在Windows Agent Arena(50步骤)测试中,UI-TARS-1.5同样以42.1的高分领先于OpenAI的29.8。在浏览器使用方面,UI-TARS-1.5在WebVoyager测试中的得分为84.8,与OpenAI的87、CUA的84.1和Claude 3.7的87相比较为接近。在Online-Mind2web测试中,UI-TARS-1.5以75.8的得分超过了OpenAI的71、CUA的62.9和Claude 3.7的71。
(二)定位能力评估
在定位能力测试中,UI-TARS-1.5同样表现出色。在ScreensSpot-V2测试中,UI-TARS-1.5的得分高达94.2,高于OpenAI的87.9、CUA的87.6和Claude 3.7的91.6。在更具挑战性的ScreenSpotPro测试中,UI-TARS-1.5的得分更是达到了61.6,远超OpenAI的23.4、CUA的27.7和Claude 3.7的43.6。
(三)游戏表现
在游戏领域,UI-TARS-1.5展现出了卓越的性能。以2048和cubinko等游戏为例,UI-TARS-1.5在这些游戏中的得分均为100.00,而其他模型如OpenAI、CUA和Claude 3.7在这些游戏中的得分则相对较低。例如,在2048游戏中,OpenAI的得分为31.04,CUA和Claude 3.7的得分为0.00;在cubinko游戏中,OpenAI的得分为0.00,CUA的得分为32.80,Claude 3.7的得分为0.00。此外,在其他游戏如energy、free、the key、Gem 11、hex、frvr、Infinity Loop、Maze:Path of Light和shapes中,UI-TARS-1.5同样取得了完美的100.00的高分。
三、模型规模比较
在不同规模的UI-TARS模型在OSworld基准测试中的表现比较中,UI-TARS-1.5在计算机使用方面得分为42.5,GUI定位方面在ScreenSpotPro测试中得分为61.6。而UI-TARS-72B-DPO在计算机使用方面的得分为24.6,在GUI定位方面的得分为38.1;UI-TARS-1.5-7B在计算机使用方面的得分为27.5,在GUI定位方面的得分为49.6。这表明UI-TARS-1.5在这些任务中具有显著的优势。尽管UI-TARS-1.5-7B主要专注于提升通用计算机使用能力,并未专门针对游戏场景进行优化,但UI-TARS-1.5在游戏场景中仍然保持了较大的优势。
四、研究合作与未来展望
目前,研发团队正在提供对表现最佳的UI-TARS-1.5模型的早期研究访问,以促进协作研究。关于未来的发展方向,团队计划继续对UI-TARS-1.5进行改进和优化,以提升其在更多任务和场景中的性能,同时探索其在不同领域的应用潜力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)