《DispSegNet: Leveraging Semantics for End-to-End Learning of Disparity Estimation From Stereo Image》
本文对DispNet进行总结
1. 研究问题
(1)目前缺少训练端到端视差估计网络的大型真实数据集,因此研究无监督的立体匹配方法。
(2)基于CNN的视差估计方法在不适定区域(高镜面反射、遮挡或低纹理区域)的视差精度不足,引入语义分割信息被证明可以提升视差图在不适定区域的质量。
因此本文研究以语义分割任务为指导的无监督立体匹配。
2. 研究方法
设计了一个无监督学习网络DispSegNet,它将视差估计和语义分割紧密耦合,提出了一种两阶段视差细化过程,首先将语义分割任务中学到的段嵌入用于视差细化,估计一个残差以改善不适定区域的视差,然后利用语义分割分支的监督进一步改善小语义块内的视差质量。另外,该网络还能输出能够输出视差图和语义分割图,在自动驾驶中很有用。
2.1 Architecture for Disparity Estimation
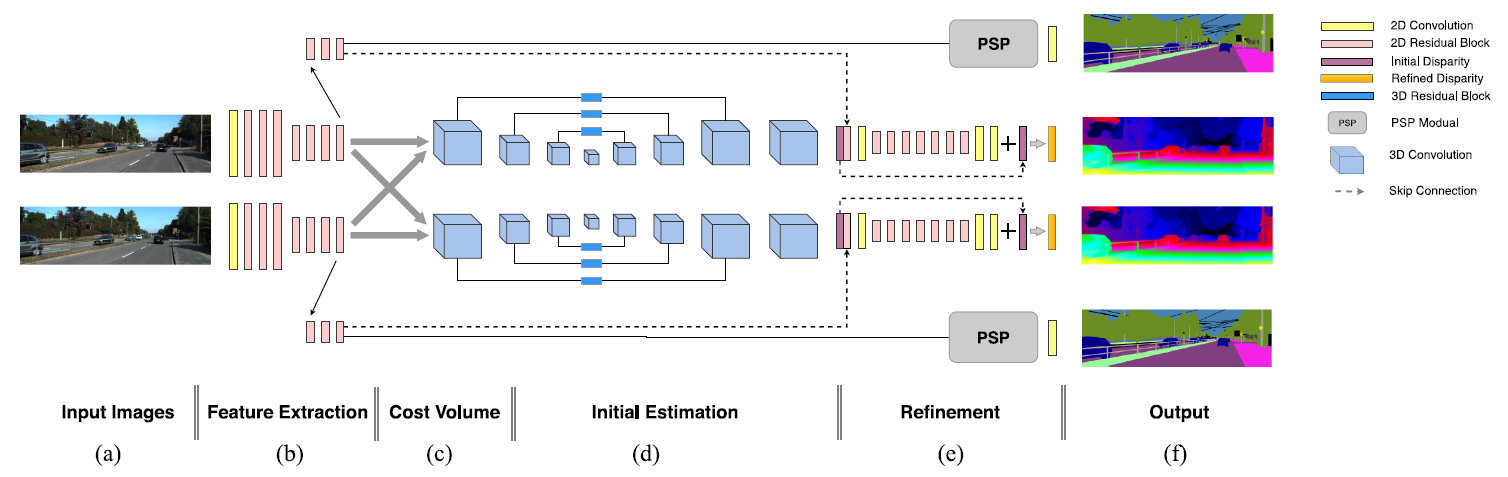
Simense 网络 使用 ResNet-50 架构处理左右图像并产生用于立体匹配和语义分割的特征。分割任务的特征来自比立体匹配任务更深的网络层,因为前者比后者需要更多的上下文信息。
每个任务对应于网络中的一个分支。在视差分支中,输入特征的大小是原始立体图像的 1/4,通过连接左右特征,产生一个4D成本量,然后使用具有 3D 卷积的八层编码器-解码器从该成本量中估计初始视差图。解码器中使用了 3D 转置卷积。跳过层由 3D 残差块处理。语义特征嵌入首先被调整为与原始图像相同的尺寸,并与初始视差图连接以进行细化。
卷积层是指一个卷积层,后面接一个BN层和一个Leaky ReLU 层,除了最后的输出层只包含一个常规卷积。除特征提取器的第一个卷积层的kernel为7外,所有kernel的大小均为3。2D残差块为三层深,3D残差块为两层深。
2.2 Cost Volume and Learning Context
通过在扫描线上连接所有可能匹配的特征向量,形成 4D 代价空间,本文分别构建左右成本量,以估计左右视差图,为了聚合更多的全局上下文信息,使用编码器-解码器架构(3D卷积)在高度、宽度、视差维度上进行代价过滤。
然后使用soft argmin函数回归初始视差图。
2.3 Disparity Refinement
初始视差图存在很多噪声,而且在不适定区域存在很多误匹配。由于不适定区域的视差应该与来自同一语义分割的区域具有相似的值,因此在生成初始视差图后,本文使用语义分割(段)信息来细化视差。
具体来说,将语义分割分支的语义块嵌入和初始视差图连接,通过细化网络计算残差图,用于修正初始视差图。
2.4 Architecture for Semantic Segmentation
在 KITTI 和 Cityscapes 数据集中,只有立体对中的左侧图像被标记为真实语义片段。因此语义分割子网络利用左视差图将右语义分割扭曲到左视图,然后在训练期间由左标签进行正则化。
PSP模块类似于PSPNet,PSP 模块的输入特征的大小是原始立体图像的 1/8。在 PSP 模块中,输入特征使用平均池化以原始输入大小的 1/2、1/4 和 1/8 的比例下采样为三种不同的大小。 然后它们之后是单独使用 1x1 滤波器的卷积,以将特征维度减少到原始输入特征维度的 1/4。在通过双线性插值将不同尺度的特征上采样到输入特征空间的形状后,将它们连接起来。最后是 1x1 卷积以混合不同尺度的特征。
2.5 Loss Function

这里补充一下,Diff 掩模是为了检测不适定区域,fLf_LfL是左图的浅层语义分割特征。
以上损失对左右视差分支都要计算。
2.6 Post Processing
传统的左右一致性检测和插值进行后处理。
3. 实验结果
数据集:
- KITTI 2015(具有语义分割真实图)
- Cityscapes:具有密集语义分割图,但视差图由SGM算法提供。
训练:
- 输入图像被归一化到
[-1, 1],并被随机剪裁到256 * 512。 - batch_size = 1,Max_disparity = 192。
- Adam优化器:β1=0.9\beta_1 = 0.9β1=0.9,β2=0.999\beta_2 = 0.999β2=0.999,ϵ=1e−8\epsilon = 1e^{-8}ϵ=1e−8
- 在Cityscapes上预训练,学习率为2e−42e^{-4}2e−4,然后在KITTI 2015上进行微调,学习率为1e−41e^{-4}1e−4。每训练20000 iters使学习率减半。
- 在Cityscapes上训练100000 iters,在KITTI 2015上训练50000。
3.1 Evaluation
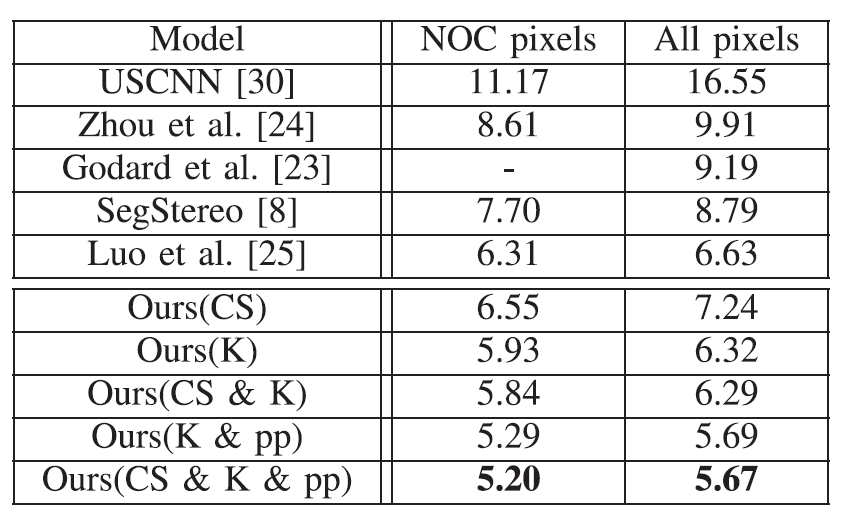
在KITTI 2015 上的结果表明,本文方法优于其他无监督方法。
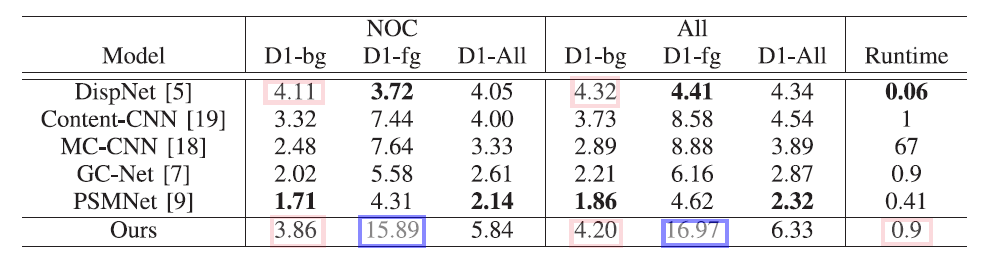
KITTI 2015 的结果表明,本文方法的性能和监督学习的方法存在较大差距,但在 背景 性能要优于DispNet。另外在前景区域存在很大的误差。
3.2 Ablation Study on Loss Components
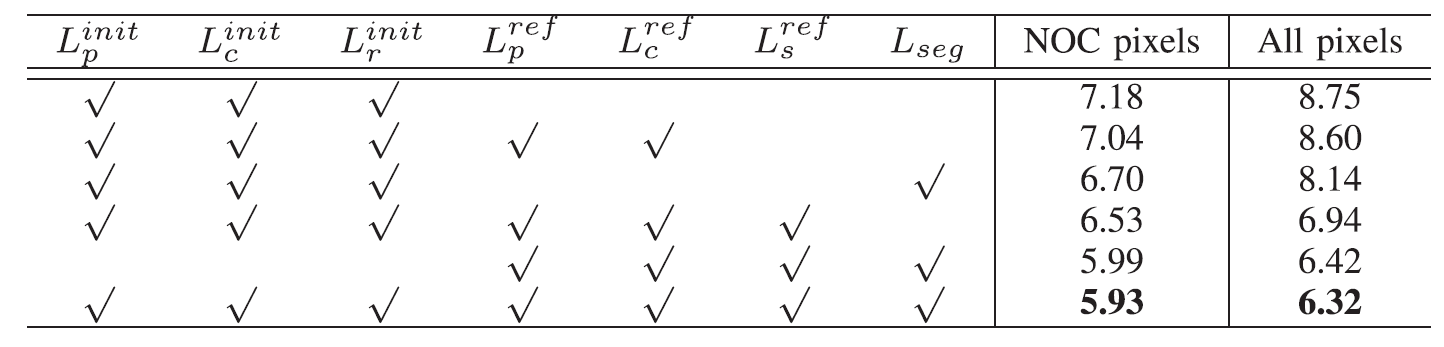
KITTI 2015 训练集的结果表明,视差细化过程中的平滑项和语义分割分支的监督提高了视差精度。
3.3 Performance Analysis

结果表明,平滑度损失会提高相对较大语义类的性能,但不会提高较小语义类的性能。 在语义分割任务的监督下,语义小类区域错误率大幅下降。
4. 结论
在 KITTI 和 Cityscapes 数据集上的实验表明,本文的模型在无监督学习方法中性能最佳,甚至在背景区域比DispNet的精度要高,但与监督方法还存在较大差距,速度也没有什么优势。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)