LLM和AI agent
一文搞懂大模型!基础知识、 LLM 应用、 RAG 、 Agent 与未来发展-CSDN博客Agent教程: 从零基础快速掌握Agent开发流程与通用开发范式_慕课手记
Agent教程: 从零基础快速掌握Agent开发流程与通用开发范式
Linux环境下sentence-transformers 之 all-MiniLM-L6-v2模型安装与使用
使用ollama分别在我的window、mac、小米手机上部署体验llama3-8b
深入理解 Embedding 和 向量:AI 应用中的核心技术
手把手教你用Ollama & AnythingLLM搭建AI知识库,无需编程,跟着做就行
中国工程院院士孙凝晖给正国级、副国级讲课的万字长稿《人工智能与智能计算的发展》
TRL - Transformer 强化学习_automodelforcausallmwithvaluehead-CSDN博客
------------------------------llama和ollama的区别----------------------------------------------
llama是Meta公司(即Facebook)开源的大语言模型(LLM),类似Qwen,Deepseek。
ollama是一个本地大模型管理工具,可以方便的运行各种大模型。windows下安装很方便,linux下如果官网的脚本出错,可以用这个命令直接下载 https://ollama.com/download/ollama-linux-amd64.tgz
ollama serve
ollama list
ollama run llama3.1:8b
ollama run qwen3:8bollama 使用离线gguf模型,以及修改上下文长度:
只是运行一下本地gguf模型的话,直接写一个modelfile(类似dockerfile),然后 ollama create modelname -f Modelfile 就构建好了,然后 ollama list, ollama run
Ollama+GGUF离线加载本地模型-腾讯云开发者社区-腾讯云
------------------------------Transformer模型、Transformer python库、ollama的区别------------------------
Transformer模型是一种神经网络,包含自注意力机制、多头注意力、位置编码、前馈神经网络 等
ollama是一个本地大模型管理工具,优势在于其易于安装和使用,但缺点是模型库有限
Transformer python库则是一个更为通用的框架,它提供了自动模型下载、运行、丰富的代码片段,以及非常适合实验和学习。然而,它要求用户对机器学习和自然语言处理有深入了解,同时还需要编码和配置技能。Transformer库支持多种模型,包括但不限于LLaMa模型,提供了更广泛的灵活性和功能。
Transformer python库可以提供了三个层次的函数(transformers包括管道pipeline、自动模型auto以及具体模型三种模型实例化方法),用于部署大模型。
Hugging face 起初是一家总部位于纽约的聊天机器人初创服务商,他们本来打算创业做聊天机器人,然后在github上开源了一个Transformers库,虽然聊天机器人业务没搞起来,但是他们的这个库在机器学习社区迅速大火起来。目前已经共享了超100,000个预训练模型,10,000个数据集,变成了机器学习界的github。
http://www.huggingface.co/ 网站已经屏蔽了中国IP,但我们可以通过hf-mirror.com网站来下载模型。python代码中这样配置 os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
7种大模型的部署方法汇总:Transformers、Llama.cpp、Llamafile、Ollama......_模型引擎vllm和transformers的关系-CSDN博客
自己调用transformer库部署大模型 https://zhuanlan.zhihu.com/p/694856151
---------------------------openai api 是什么------------------------------
是openai公司(开发gpt模型)定义的agent和GPT之间的接口。现在几乎成为业内标准,所有LLM都可以通过这个接口来访问,比如llama模型。client=openai.OpenAI(base_url='http://127.0.0.1:11434/v1',api_key='not-needed')
---------------------agent框架--------------------------
1、咖哥介绍的 LlamaIndex,LangChain
2、迪哥介绍的Phidata是一个为大型语言模型(LLM)增加记忆、知识和工具的框架。它旨在解决LLM在上下文理解和行动能力方面的局限性。为大语言模型增加记忆、知识和工具。
AI 助手 == LLM + 记忆 + 知识 + 工具 == LLM + Phidata
------------------ agent的思维模型 ---------------------------
1、React(观察、思考、行动、再观察、再思考、再行动 迭代)LlamaIndex,LangChan都在使用这个模型
2、思维链(COT)3、思维树(TOT)4、批判修正(Critique Revise)5、自问自答(Self-Ask)6、计划与执行(plan-and-Execute)
------------RAG增强技术------
1、Bert
2、bge-reranker-large模型
再次提升RAG性能:两种高效的Rerank模型实践指南 -AI.x-AIGC专属社区-51CTO.COM
3、2025年最新的Qwen3模型(Qwen3 Embedding 模型技术深度解析)
4、Embedding模型是如何训练出来的?(RAG核心技术之Embedding模型训练详解)
-----------AI接口---------
package main
import (
"bytes"
"fmt"
"io"
"net/http"
"os"
)
func t4() {
//https://zhuanlan.zhihu.com/p/712360292
//
//str:=`{"model": "llama3.1:8b","stream": false,"prompt": "redis是如何限制单并发的"}`
str := `{
"model": "llama3.1:8b",
"messages": [
{
"role": "system",
"content": "You are a warm-hearted assistant, and you only speak Chinese."
},
{
"role": "user",
"content": "李华去公园玩把腿摔断了,被送到医院了。腿摔断一般要多长时间好?"
},
{
"role": "assistant",
"content": "腿摔断的恢复时间不一,通常需要几个月才能基本康复。\n\n如果是轻微的骨折,一般可以在1-2个月内恢复,主要需要注意休息和康复锻炼。"
},
{
"role": "user",
"content": "李华为啥去医院了?"
}
],
"stream": false
}`
resp, err := http.Post("http://127.0.0.1:11434/api/chat", "application/json", //generate
bytes.NewBufferString(str))
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
defer resp.Body.Close()
body, _ := io.ReadAll(resp.Body)
fmt.Println(string(body))
}
func main() {
t4()
}
go run main.go
{"model":"llama3.1:8b","created_at":"2024-09-14T23:48:09.1991888Z","message":{"role":"assistant","content":"李华腿摔断了被送到 医院了。"},"done_reason":"stop","done":true,"total_duration":17875779000,"load_duration":5929142300,"prompt_eval_count":129,"prompt_eval_duration":9661958000,"eval_count":14,"eval_duration":2233441000}
------通过openai接口 调用-------
import openai
from openai import OpenAI
# client=OpenAI()
client=OpenAI(base_url = 'http://localhost:11434/v1',api_key='not need')
# chat_completion=client.chat.completions.create( model="gpt-3.5-turbo",
# messages=[{"role":"user","content":"Hello world"}])
chat_completion=client.chat.completions.create( model="llama3.1:8b",
messages= [
{ "role": "system",
"content": "You are a warm-hearted assistant, and you only speak Chinese."
},
{ "role": "user",
"content": "李华去公园玩把腿摔断了,被送到医院了。腿摔断一般要多长时间好?"
},
{ "role": "assistant",
"content": "腿摔断的恢复时间不一,通常需要几个月才能基本康复。\n\n如果是轻微的骨折,一般可以在1-2个月内恢复,主要需要注意休息和康复锻炼。"
},
{ "role": "user","content": "李华为啥去医院了?"}
],
)
print(chat_completion.choices[0].message.content)
D:\python> python agent1.py
她摔断腿了!去医院检查并进行治疗。
D:\python> python agent1.py
李华去了医院,是因为他玩得有些不小心,把腿摔断了!好在现在医生正在帮他治疗,他一定会早日恢复健康的!
D:\python> python agent1.py
李华公园玩的时候摔倒了,腿摔断了,被人送到了医院!
D:\python> python agent1.py
他去公园玩儿的时候不小心把腿摔断了,不得不去医院检查和治疗!curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"Why is the sky blue?"
}'上面的generate接口,适合单轮问答,下面的chat接口,适合多轮对话。
curl -X POST http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:1.5b",
"stream": false,
"messages": [
{"role": "user", "content": "你好!三国演义是什么"}
]
}'
python 代码
url = 'http://127.0.0.1:11434/api/chat'
headers = {
"Content-Type": "application/json"
}
data = {"model": "deepseek-r1:1.5b","stream": False,
"messages": [
{"role": "system","content": "你的身份是3GPP专家"},
{"role": "user","content": "请介绍一下3GPP"}
]
}
print(123)
response = requests.post(url, headers=headers, json=data)
print(response.json())
-----amd 核显 用于大模型训练 微软 DirectML-------
Pytorch在cuda、AMD DirectML和AMD CPU下性能比较_directml与cuda-CSDN博客
-----LLM--为什么Qwen2.5-Coder 32B-Instruct 模型 带了Instruct字样---------
LLM对外发布时,可以发布base模型,也可以发布经过微调(Instruction Tuning)的模型。与Base模型相比,Instruct模型更加“开箱即用”,它不需要开发者进行额外的微调,就可以直接用于各种编程和开发任务。
-----Keras 3, Jax, Pytorch, TensorFlow------------
Keras的三种后端各展所长,重要的是,就性能而言,并没有哪一个后端能够始终胜出。
Keras 3的性能普遍超过PyTorch的标准实现。
HuggingFace Diffusers的StableDiffusion推理功能上,从版本0.25.0升级到0.3.0时,性能提升超过了100%。
同样,在HuggingFace Transformers中,Gemma从4.38.1版本升级至4.38.2版本也显著提高了性能。
三种后端测评,谷歌力推的Jax在最近的基准测试中性能已经超过Pytorch和TensorFlow,12项指标中7项指标排名第一。
----------BERT模型 是啥 BERT模型指的是一类模型吗?---------------
BERT(Bidirectional Encoder Representations from Transformers)不仅仅指单一的模型,而是一类模型或一种模型架构,它代表了一种预训练语言表示的方法。由Google在2018年提出,BERT因其创新性的双向训练方法和在多个自然语言处理(NLP)任务上的卓越表现而广受关注。
BERT的核心特点包括:
-
双向训练:不同于之前的单向语言模型,BERT是通过遮蔽一些输入词(Masked Language Model, MLM),然后尝试预测这些被遮蔽的词来进行预训练。这种方法允许模型学习到一个词的左右上下文信息,因此被称为双向。
-
Transformer架构:BERT基于Vaswani等人于2017年提出的Transformer架构,该架构完全依赖于自注意力机制(self-attention mechanism),放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)。这使得模型可以并行化训练,大大提升了训练效率,并能更好地捕捉长距离依赖关系。
-
预训练+微调范式:BERT首先在一个大型文本语料库上进行无监督预训练,以学习通用的语言表征。然后,在特定任务上有标注的数据集上对模型进行微调(fine-tuning),只需少量的额外训练即可在各种下游任务中取得良好的性能。
-
模型变体:除了原始的BERT模型(如 BERT-base 和 BERT-large),社区还开发了许多基于BERT的变体,例如:
- RoBERTa:改进了BERT的预训练过程。
- ALBERT:减少了模型参数数量,提高了计算效率。
- DistilBERT:是一个更小、更快但仍然保持大部分性能的BERT版本。
- ELECTRA:使用替代的预训练目标来提高效率和效果。
所以,当人们提到“BERT模型”时,他们可能指的是使用上述BERT架构和方法构建的一系列模型中的任何一个。由于BERT的成功,很多后续的工作都是在其基础上进行了改进和发展。
---------------模板(Template)-----------------------
模板(Template)
每种模型有其特定的输入格式,在小模型时代,这种输入格式比较简单:
[CLS]杭州是个好地方[SEP][CLS]代表了句子的起始,[SEP]代表了句子的终止。在BERT中,[CLS]的索引是101,[SEP]的索引是102,加上中间的句子部分,在BERT模型中整个的token序列是:
101, 100, 1836, 100, 100, 100, 1802, 1863, 102我们可以看到,这个序列和上面千问的序列是不同的,这是因为这两个模型的词表不同。
在LLM时代,base模型的格式和上述的差不多,但chat模型的格式要复杂的多,比如千问chat模型的template格式是:
<|im_start|>system
You are a helpful assistant!
<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
其中“You are a helpful assistant!”是system字段,“How are you?”是用户问题,其他的部分都是template的格式。
system字段是chat模型必要的字段,这个字段会以命令方式提示模型在下面的对话中遵循怎么样的范式进行回答,比如:
“You are a helpful assistant!”
“下面你是一个警察,请按照警察的要求来审问我”
“假如你是一个爱哭的女朋友,下面的对话中清扮演好这个角色”
system字段规定了模型行为准则,比如当模型作为Agent使用时,工具集一般也是定义在system中的:
“你是一个流程的执行者,你有如下工具可以使用:
工具1:xxx,输入格式是:xxx,输出格式是:xxx,作用是:xxx
工具2:xxx,输入格式是:xxx,输出格式是:xxx,作用是:xxx”
复杂的template有助于模型识别哪部分是用户输入,哪部分是自己之前的回答,哪部分是给自己的要求。
比较麻烦的是,目前各开源模型还没有一个统一的template标准。在SWIFT中,我们提供了绝大多数模型的template,可以直接使用:
register_template(
TemplateType.default,
Template([], ['### Human:\n', '{{QUERY}}\n\n', '### Assistant:\n'],
['\n\n'], [['eos_token_id']], DEFAULT_SYSTEM, ['{{SYSTEM}}\n\n']))
# You can set the query as '' to serve as a template for pre-training.
register_template(TemplateType.default_generation,
Template([], ['{{QUERY}}'], None, [['eos_token_id']]))
register_template(
TemplateType.default_generation_bos,
Template([['bos_token_id']], ['{{QUERY}}'], None, [['eos_token_id']]))
qwen_template = Template(
[], ['<|im_start|>user\n{{QUERY}}<|im_end|>\n<|im_start|>assistant\n'],
['<|im_end|>\n'], ['<|im_end|>'], DEFAULT_SYSTEM,
['<|im_start|>system\n{{SYSTEM}}<|im_end|>\n'])
register_template(TemplateType.qwen, qwen_template)
register_template(TemplateType.chatml, deepcopy(qwen_template))
...
有兴趣的小伙伴可以阅读:swift/swift/llm/utils/template.py at main · modelscope/swift · GitHub 来获得更细节的信息。
template拼接好后,直接传入tokenizer即可。
----
在BERT(Bidirectional Encoder Representations from Transformers)模型中,输入序列通常以特殊符号 [CLS] 开始。这个特殊的标记对于分类任务非常重要,因为BERT会将该标记对应位置的隐藏状态作为整个输入序列的表示,用于最终的分类决策。
在实际使用中,当我们将文本输入到BERT模型时,我们会先对文本进行分词,并为每个词汇分配一个对应的索引值。这些索引值来自于预训练BERT模型自带的词汇表(vocabulary)。[CLS] 令牌也有它自己固定的索引值,在原始的BERT实现中,[CLS] 的索引通常是101。但是请注意,具体的索引可能因不同的实现或版本而略有不同。
如果您是在使用像 Hugging Face 的 transformers 库这样的第三方库,通常您不需要手动指定 [CLS] 的索引,因为这些库会自动处理令牌化和索引映射。例如,在使用 BertTokenizer 或类似的类时,您只需在文本前添加 [CLS] 标记,然后调用 tokenizer.convert_tokens_to_ids() 方法即可获得相应的索引。
----
微调任务是标注数据集,那么必然有指导性的labels(模型真实输出)存在,将这部分也按照template进行拼接,就会得到类似下面的一组tokens:
------从魔塔社区下载模型或数据,如果用的是阿里云的服务器,非常快----
git lfs install
git clone http://oauth2:AhTYtjaBsKj-CsR-rnyj@www.modelscope.cn/BadToBest/EchoMimicV2.git
-----从hf-mirror下载模型,比较慢-----
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from huggingface_hub import snapshot_download
model_path = "myEchoMimicV2"
snapshot_download(
repo_id="BadToBest/EchoMimicV2",
local_dir=model_path,
max_workers=8
)
-----单卡训练大模型----------
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# 1. 加载数据集
# 假设我们使用的是Hugging Face的内置数据集,例如SST-2
dataset = load_dataset('sst2') # 或者使用你自己的数据集
# 2. 数据预处理,可能需要根据模型进行Tokenization
# 以BERT为例,使用AutoTokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["sentence"], truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 3. 准备训练参数
training_args = TrainingArguments(
output_dir='./results', # 输出目录
num_train_epochs=3, # 总的训练轮数
per_device_train_batch_size=16, # 每个GPU的训练批次大小
per_device_eval_batch_size=64, # 每个GPU的评估批次大小
warmup_steps=500, # 预热步数
weight_decay=0.01, # 权重衰减
logging_dir='./logs', # 日志目录
logging_steps=10,
)
# 4. 准备模型
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# 5. 创建Trainer并开始训练
trainer = Trainer(
model=model, # 要训练的模型
args=training_args, # 训练参数
train_dataset=tokenized_datasets['train'], # 训练数据集
eval_dataset=tokenized_datasets['validation'], # 验证数据集
)
# 开始训练
trainer.train()
# 使用Trainer的evaluate方法进行评估
eval_result = trainer.evaluate()
print(eval_result)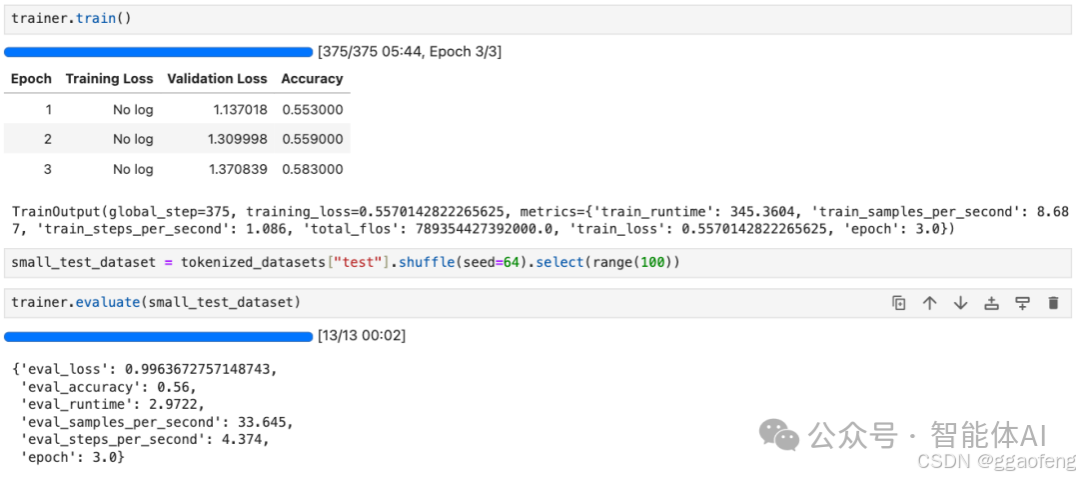
----------魔塔社区封装的训练命令------------
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_id_or_path qwen/Qwen-7B-Chat \
--dataset blossom-math-zh \
--output_dir output \
--custom_train_dataset_path xxx.jsonl zzz.jsonl \
--custom_val_dataset_path yyy.jsonl aaa.jsonl \
-----多卡用deepspeed------------
下面是一个如何使用 DeepSpeed 进行模型微调的基本示例
import deepspeed
# 定义你的模型、优化器和数据加载器
model = ...
optimizer = ...
train_loader = ...
# 配置 DeepSpeed
deepspeed_config = {
"train_batch_size": 32,
"gradient_accumulation_steps": 2,
"fp16": {
"enabled": True
},
"zero_optimization": {
"stage": 2
}
}
# 初始化 DeepSpeed
model_engine, optimizer, train_loader, _ = deepspeed.initialize(
args=None,
model=model,
optimizer=optimizer,
model_parameters=model.parameters(),
training_data=train_loader.dataset,
config_params=deepspeed_config
)
# 开始训练
for epoch in range(num_epochs):
for batch in train_loader:
inputs, labels = batch
outputs = model_engine(inputs)
loss = loss_fn(outputs, labels)
model_engine.backward(loss)
model_engine.step()下面这个例子也可以看一下
heli haiyou ge liz LLM大模型:deepspeed实战和原理解析 - 第七子007 - 博客园
-----在魔塔社区直接运行一个模型--------
魔塔的机器,已经安装了swift命令,直接调用swift命令即可
root@dsw:/mnt/workspace# swift infer --model_type qwen2-0_5b-instruct
在cpu机器中,字是一个一个蹦出来的。在gpu机器中,是一行一行刷出来的,比cpu机器快太多了。
这个占用44%的内存,可以试试这个3B模型 swift deploy --model_type qwen2_5-3b-instruct
deploy开启openapi方式,infer开启命令行方式
swift命令的文档参考:
https://swift.readthedocs.io/en/latest/Instruction/Inference-and-deployment.html
------在魔塔社区训练一个古文腔的大语言模型----
cpu的机器和gpu的机器共享了相同的个人磁盘/mnt/data /mnt/workspace, 可以在cpu的机器中下载好模型,然后在gpu机器中训练
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type qwen2-7b-instruct \
--sft_type lora \
--output_dir output \
--dataset classical-chinese-translate \
--num_train_epochs 1 \
--max_length 1024 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--learning_rate 5e-5 \
--gradient_accumulation_steps 16 \
--max_grad_norm 1.0 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10
显存基本上用完了,gpu也是100%
[INFO:swift] Saving model checkpoint to /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-300
Train: 75%|████████████████████████████████████████ | 307/411 [38:34<13:23, 7.72s/it]
root@dsw:/mnt/workspace# nvidia-smi
Sat Jan 4 14:01:33 2025
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.103.01 Driver Version: 470.103.01 CUDA Version: 12.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10 On | 00000000:00:07.0 Off | 0 |
| 0% 63C P0 148W / 150W | 22360MiB / 22731MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
----这个数据集-----
这个数据集是jsonl格式的,可以下载或预览 魔搭社区
但在环境中,却是arrow格式的,/mnt/workspace# ll .cache/modelscope/hub/datasets/swift___classical_chinese_translate/default-342e5888ddf07428/0.0.0/master/classical_chinese_translate-train.arrow
文件后缀名为 .arrow 的文件通常表示使用了 Apache Arrow 的二进制文件格式来存储数据。这种格式非常适合用来保存表格数据,如 DataFrame,因为 Arrow 提供了一种紧凑且高效的内存布局,可以支持零拷贝操作,这对于大数据处理特别有用。
Trainer.tokenizer is now deprecated. You should use Trainer.processing_class instead.
[INFO:swift] Saving model checkpoint to /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-411
{'train_runtime': 3110.1828, 'train_samples_per_second': 2.119, 'train_steps_per_second': 0.132, 'train_loss': 23.5561061, 'epoch': 1.0, 'global_step/max_steps': '411/411', 'percentage': '100.00%', 'elapsed_time': '51m 50s', 'remaining_time': '0s'}
Train: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 411/411 [51:50<00:00, 7.57s/it]
[INFO:swift] last_model_checkpoint: /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-411
[INFO:swift] best_model_checkpoint: /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-400
[INFO:swift] images_dir: /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/images
[INFO:swift] End time of running main: 2025-01-04 14:41:10.089508
root@dsw-800714-86bd86f486-9nbzr:/mnt/workspace#
swift infer --ckpt_dir /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-400
对话
或者swift deploy --ckpt_dir /mnt/workspace/output/qwen2-7b-instruct/v1-20250104-134819/checkpoint-400
用脚本测试
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url='http://localhost:8000/v1',
)
query = '讲一下唐朝建立的历史'
messages = [{
'role': 'user',
'content': query
}]
resp = client.chat.completions.create(
model='default-lora', # 注意这里的default-lora,代表使用lora进行推理,也可以使用qwen2-7b-instruct,即使用原模型了,下同
messages=messages,
seed=42)
response = resp.choices[0].message.content
print(f'query: {query}')
print(f'response: {response}')
# 我听说在遥远的东方,有一个强大的帝国,它的建立如同一颗璀璨的明珠,照亮了整个大陆。唐朝的建立,正是这样一件大事啊!公元618年,李渊在太原起兵,攻入长安,建立了唐朝。他的儿子李世民后来继承了皇位,开创了贞观之治的盛世。这难道不是一件令人惊叹的事情吗?
messages.append({'role': 'assistant', 'content': response})
query = '给我讲一个笑话'
messages.append({'role': 'user', 'content': query})
stream_resp = client.chat.completions.create(
model='default-lora',
messages=messages,
stream=True,
seed=42)
print(f'query: {query}')
print('response: ', end='')
for chunk in stream_resp:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
# 古人说:笑一笑,十年少。方圆十里的乡亲们没有人不觉得这是个好办法的。我听说在古代,有一个人在河边钓鱼,钓了一条鱼,他很高兴,就把它放在了篮子里。可是,他忘了把篮子放下,结果篮子掉进了河里,鱼也跟着跑了。这难道不是一件令人捧腹的事情吗?

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)