【2019-07-25】python爬虫urllib.request遭遇HTTP Error 503: Service Temporarily Unavailable
(1)源码:# -*- coding:utf-8 -*-import urllib.request# 针对这个网站,User-Agent也用了真实的、在使用的浏览器headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/...
·
(1)源码:
# -*- coding:utf-8 -*-
import urllib.request
# 针对这个网站,User-Agent也用了真实的、在使用的浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
javlib_url = 'http://xxxx.com/cn/'
javlib_Request = urllib.request.Request(javlib_url, headers=headers)
javlib_urlopen = urllib.request.urlopen(javlib_Request, timeout=10)
javlib_html = javlib_urlopen.read().decode('UTF-8')
(2)运行出错: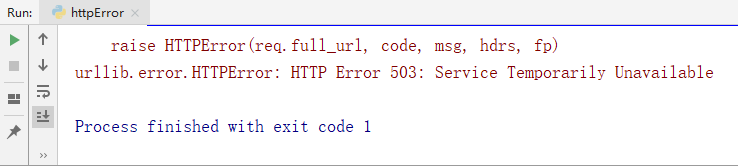
(3)百度一番后,看看前人的经历,503错误是服务器主动拒绝我的访问。
参考【HelloHaibo】python访问网页返回503错误的解决方案
Python做爬虫,经常返回HTTP Error 503, 请问要怎么解决?的回答
(4)尝试在headers中添加cookie。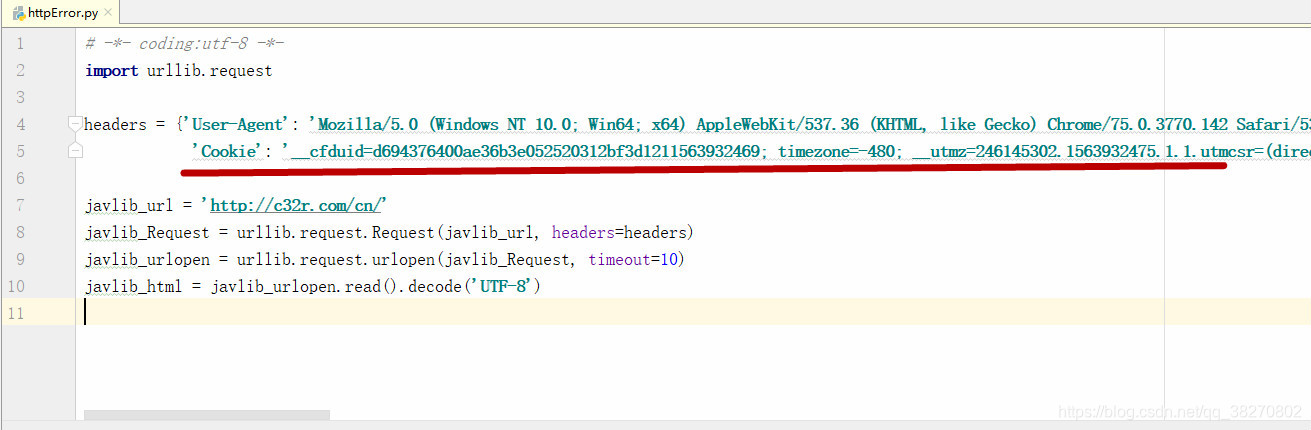
找到cookie的方法: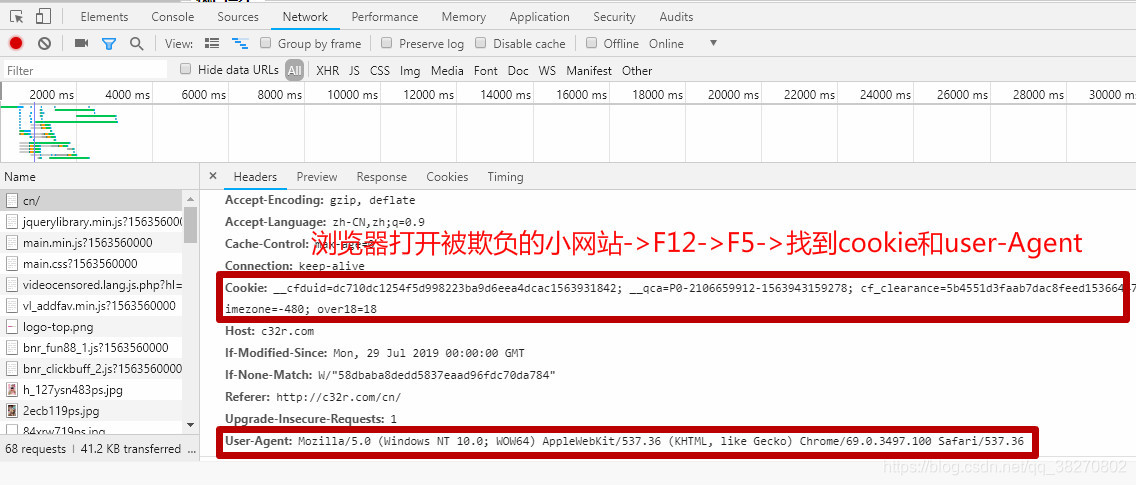
(5)问题成功解决。如果还是失败,估计还得把其他host,refer加上。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)