智能体注意力机制:Softmax与线性注意力的融合
本文提出智能体注意力机制(Agent Attention),通过引入智能体令牌代理查询操作,巧妙融合Softmax与线性注意力,实现高效全局上下文建模。该机制将计算复杂度从二次降低至线性,适用于图像分类、目标检测、语义分割及图像生成等高分辨率任务。实验表明,智能体注意力在多种视觉Transformer模型上显著提升性能,并可直接集成至Stable Diffusion,加速生成过程并提升图像质量。
摘要
本文提出智能体注意力机制(Agent Attention),通过引入智能体令牌代理查询操作,巧妙融合Softmax与线性注意力,实现高效全局上下文建模。该机制将计算复杂度从二次降低至线性,适用于图像分类、目标检测、语义分割及图像生成等高分辨率任务。实验表明,智能体注意力在多种视觉Transformer模型上显著提升性能,并可直接集成至Stable Diffusion,加速生成过程并提升图像质量。
关键词:智能体注意力、Softmax注意力、线性注意力、视觉Transformer、高分辨率建模、Stable Diffusion
1. 智能体注意力机制:Softmax与线性注意力的高效融合
作者:Dongchen Han*、Tianzhu Ye∗、Yizeng Han、Zhuofan Xia、Shiji Song、Gao Huang†
单位:清华大学自动化系,智能技术与系统国家重点实验室
2. 引言
Transformer模型在计算机视觉领域的广泛应用面临一个核心挑战:Softmax注意力机制的二次计算复杂度。传统全局自注意力虽具备强大的表达能力,但其高昂的计算成本限制了在高分辨率任务中的应用。现有方法(如局部窗口注意力或稀疏注意力)虽降低复杂度,但牺牲了长距离依赖建模能力。
本文提出智能体注意力机制(Agent Attention),通过引入一组**智能体令牌(Agent Tokens)**作为查询代理,将注意力计算分解为“聚合-广播”两步操作,在保留全局感受野的同时实现线性复杂度。实验证明,该机制不仅显著提升视觉任务性能,还可无缝集成至生成模型(如Stable Diffusion),加速推理并提升生成质量。
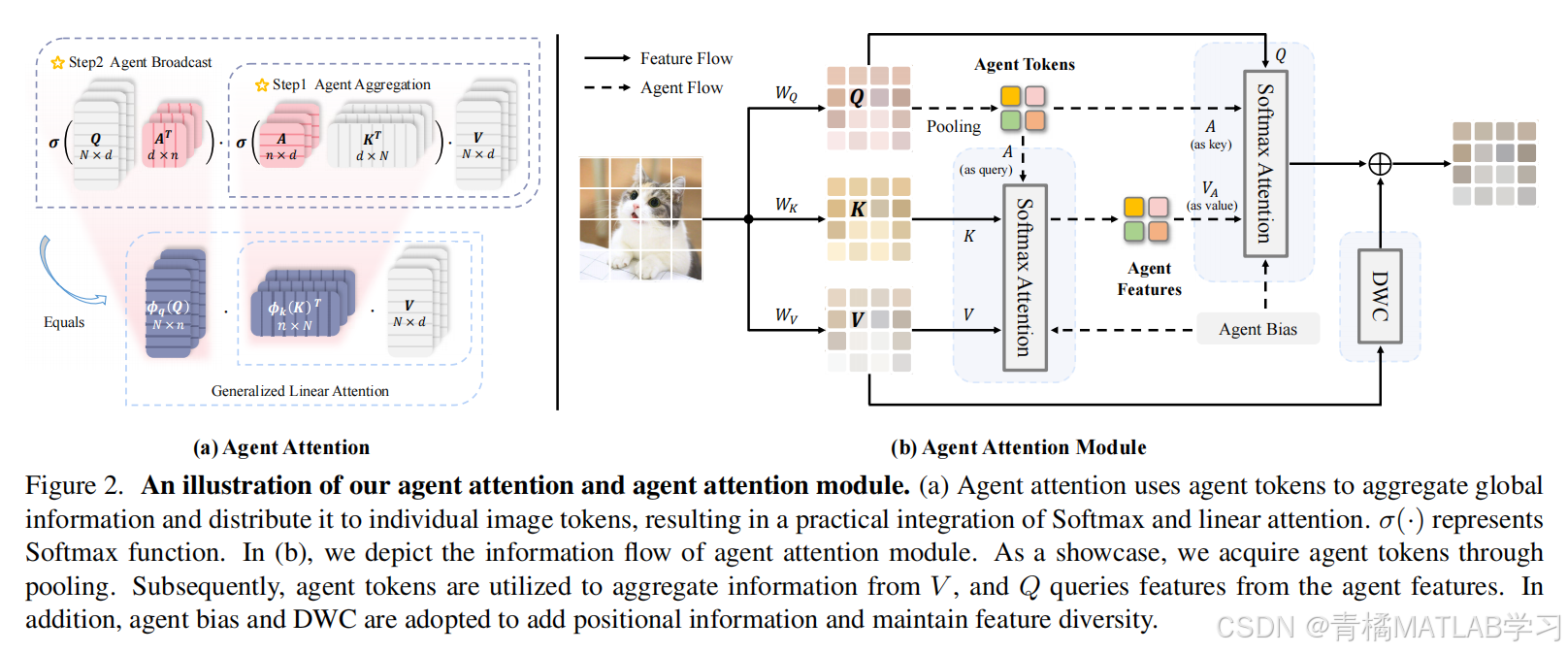
3. 智能体注意力机制设计
3.1 核心思想
智能体注意力表示为四元组 ( Q , A , K , V ) (Q, A, K, V) (Q,A,K,V),其中 A A A为新增的智能体令牌,其数量远少于查询令牌 Q Q Q。具体流程分为两步:
- 智能体聚合: A A A作为查询,从 K K K和 V V V中聚合全局信息,生成中间特征 V A V_A VA:
V A = Attn S ( A , K , V ) = σ ( A K T ) V V_A = \text{Attn}^S(A, K, V) = \sigma(AK^T)V VA=AttnS(A,K,V)=σ(AKT)V - 智能体广播: Q Q Q作为查询,从 A A A和 V A V_A VA中获取信息,生成最终输出:
O A = Attn S ( Q , A , V A ) = σ ( Q A T ) V A O^A = \text{Attn}^S(Q, A, V_A) = \sigma(QA^T)V_A OA=AttnS(Q,A,VA)=σ(QAT)VA
等效性证明:上述过程可重写为广义线性注意力形式:
O A = ϕ q ( Q ) ϕ k ( K ) T V O^A = \phi_q(Q) \phi_k(K)^T V OA=ϕq(Q)ϕk(K)TV
其中 ϕ q ( Q ) = σ ( Q A T ) \phi_q(Q) = \sigma(QA^T) ϕq(Q)=σ(QAT), ϕ k ( K ) = ( σ ( A K T ) ) T \phi_k(K) = (\sigma(AK^T))^T ϕk(K)=(σ(AKT))T,表明智能体注意力是线性注意力的高阶扩展。
3.2 优势分析
- 线性复杂度:计算复杂度从 O ( N 2 ) O(N^2) O(N2)降至 O ( N n ) O(Nn) O(Nn)( n n n为智能体令牌数量)。
- 保留全局感受野:避免局部窗口或稀疏策略的信息损失。
- 兼容Softmax与线性注意力:通过两步Softmax操作实现高效近似。
4. 智能体注意力模块优化

4.1 关键改进
- 智能体偏差(Agent Bias):
在注意力计算中引入位置偏差 B 1 B_1 B1和 B 2 B_2 B2,增强空间感知能力:
O A = σ ( Q A T + B 2 ) σ ( A K T + B 1 ) V O^A = \sigma(QA^T + B_2) \sigma(AK^T + B_1)V OA=σ(QAT+B2)σ(AKT+B1)V - 多样性恢复模块(DWC):
使用深度卷积(Depthwise Convolution)缓解线性注意力特征多样性不足的问题:
O = O A + DWC ( V ) O = O^A + \text{DWC}(V) O=OA+DWC(V)
4.2 模块结构
智能体注意力模块包含三部分:
- 纯智能体注意力
- 智能体偏差
- 深度卷积模块
5. 实验结果
5.1 图像分类(ImageNet-1K)
| 模型 | Top-1 Acc (%) | 参数量 (M) | 计算量 (GFLOPs) |
|---|---|---|---|
| PVT-L | 81.2 | 61.4 | 9.8 |
| Agent-PVT-S | 82.1 | 18.3 | 3.9 |
| Swin-T | 81.3 | 28.3 | 4.5 |
| Agent-Swin-T | 82.6 | 28.5 | 4.6 |
5.2 目标检测(COCO)
| 模型 | AP (Box) | AP (Mask) |
|---|---|---|
| PVT-S | 40.1 | 36.8 |
| Agent-PVT-S | 44.8 | 40.5 |
| Swin-T | 43.7 | 39.2 |
| Agent-Swin-T | 45.2 | 40.9 |
5.3 语义分割(ADE20K)
| 模型 | mIoU (%) |
|---|---|
| PVT-T | 39.6 |
| Agent-PVT-T | 43.2 |
| Swin-T | 44.5 |
| Agent-Swin-T | 46.6 |
5.4 图像生成(Stable Diffusion)
| 方法 | 生成速度 (倍) | FID ↓ |
|---|---|---|
| Stable Diffusion | 1.0x | 15.3 |
| ToMeSD | 1.5x | 15.5 |
| AgentSD | 1.84x | 14.6 |
可视化对比:AgentSD生成的图像细节更清晰,减少模糊和结构错误(如鸟的腿部与尾巴生成更准确)。
6. 核心优势总结
- 高效全局建模:线性复杂度下实现全局感受野,适用于高分辨率任务。
- 即插即用:无需修改模型架构,可直接替换现有注意力模块。
- 生成模型优化:在Stable Diffusion中无需额外训练,加速生成并提升质量。
7. 结论
智能体注意力机制通过引入代理令牌,在计算效率与模型表达能力间取得平衡,为视觉Transformer和生成模型提供了新的优化方向。未来可探索其在视频理解、多模态任务等长序列场景中的应用潜力。
代码地址:https://github.com/LeapLabTHU/Agent-Attention

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)