Cog-GA: A Large Language Models-based Generative Agent forVision-Language Navigation
在连续环境中的视觉语言导航(VLN-CE)是具身人工智能(Embodied AI)中的一个前沿任务,要求智能体仅通过自然语言指令,在无限制的三维空间中自由导航。这一任务对多模态理解、空间推理和决策提出了独特挑战。为应对这些挑战,我们提出了一种基于大语言模型(LLMs)的生成式智能体Cog-GA,专为VLN-CE任务设计。Cog-GA 采用了双重策略来模拟类人认知过程。首先,它构建了认知地图,整合了
Cog-GA:连续环境下基于大型语言模型的视觉语言导航生成智能体
摘要
在连续环境中的视觉语言导航(VLN-CE)是具身人工智能(Embodied AI)中的一个前沿任务,要求智能体仅通过自然语言指令,在无限制的三维空间中自由导航。这一任务对多模态理解、空间推理和决策提出了独特挑战。为应对这些挑战,我们提出了一种基于大语言模型(LLMs)的生成式智能体 Cog-GA,专为VLN-CE任务设计。
Cog-GA 采用了双重策略来模拟类人认知过程。首先,它构建了认知地图,整合了时间、空间和语义元素,从而帮助 LLMs 发展空间记忆能力。其次,Cog-GA 使用了路径点预测机制,优化探索路径以最大化导航效率。每个路径点都配备了双通道场景描述,将环境线索划分为“是什么”(What)和“在哪里”(Where)流,类似于人脑的信息处理方式。这种分离增强了智能体的注意力焦点,使其能够识别与导航相关的关键空间信息。
此外,Cog-GA 还通过反思机制记录先前导航经验中的反馈,促进了持续学习和自适应规划。通过在 VLN-CE 基准上的广泛评估,Cog-GA 展现了最先进的性能,并能够模拟类人的导航行为。本研究为开发具有战略性和可解释性的 VLN-CE 智能体做出了重要贡献。
-
任务背景(VLN-CE):
- 定义: 在连续环境中,智能体需要根据自然语言指令,在复杂的 3D 空间中找到目标位置。
- 挑战: 包括多模态理解(处理视觉和语言信息)、空间推理(规划路径)和决策(选择最佳行动)。
-
提出的模型(Cog-GA):
- 核心特点:
- 认知地图: 将时间、空间和语义信息整合在一起,模拟人类的空间记忆能力,帮助智能体更好地记住环境。
- 路径点预测机制: 通过预测下一个关键位置点,优化导航路径,提高效率。
- 双通道场景描述:
- “是什么”(What):描述环境中的对象或事件。
- “在哪里”(Where):提供这些对象或事件的位置信息。
- 效果: 类似于人类大脑的注意力机制,帮助智能体专注于最重要的信息。
- 核心特点:
-
反思机制:
- 作用: 记录智能体在过去导航中得到的反馈,推动学习能力的提升,并改进后续的规划。
- 意义: 使智能体能够不断自适应,提升任务表现。
-
性能验证:
- 在标准的 VLN-CE 测试中,Cog-GA 展现了卓越的性能,并能够模仿人类的导航行为,这表明其策略具有高效性和可解释性。
-
贡献:
- 提供了一个战略性(优化路径、关注关键信息)和可解释性(基于认知过程模拟)的智能体模型,推动了 VLN-CE 的研究进展。
介绍
视觉语言导航(VLN) 是机器人领域的重要任务,智能体根据视觉观察,在真实的三维环境中执行自然语言指令。传统上,VLN 环境中的智能体移动是基于预先准备的导航图,智能体通过这些图进行路径规划和移动。针对这一点,Krantz 等人 [17] 提出了 连续环境中的视觉语言导航(VLN-CE) 方法。与传统方法不同,VLN-CE 消除了对导航图的需求,使智能体能够在三维空间中自由移动。这一框架因其更加现实和适应性强的机器人导航方法而获得了关注,它可以让智能体更有效地响应语言指令。以往的研究,例如 ERG [26]、VLN-Bridge [10] 和 CKR 模型 [8],主要聚焦于强化学习方法。然而,强化学习需要大量交互数据,这限制了其应用和扩展。
近年来,大语言模型(LLMs)在多个领域展现了非凡的性能。一些最新研究探索了 LLM 在解读和导航复杂数字环境中的多样化能力。例如:
- Velma [23] 使用 LLM 处理街景 VLN 任务;
- Esc [31] 和 LFG [24] 专注于零样本物体导航(ZSON)任务;
- ProbES [18] 则增强了 LLM 在 REVERIE 任务中的泛化能力。
我们旨在利用 LLM 中存储的大量先验知识,构建具有更强泛化能力的 VLN-CE 智能体。该智能体接收视觉和语言两种模态的输入,通过 LLM 的抽象知识结构,提取两种模态的关键信息,连接感官模态并建立抽象概念和知识结构。
为此,我们提出了 Cog-GA(Cognitive-Generative Agent),一种基于大语言模型(LLMs)的生成式智能体,用于连续环境中的视觉语言导航(VLN-CE)。在使用 LLM 构建高效 VLN 智能体时,面临的一个关键挑战是 LLM 缺乏固有的空间记忆能力,因为它们是基于扁平化文本输入训练的,无法原生建模三维空间环境。为了解决这一问题,我们引入了 认知地图(Cognitive Map),它将每个导航步骤中的场景描述和地标对象的空间信息作为图记录下来。这些记录的空间记忆会在后续导航步骤中被检索和利用。另一个核心挑战是:对于 LLM 来说,环境中用于决策的有效路径点往往分布稀疏。为智能体构建更合理和高效的搜索空间,我们采用了路径点预测器(Waypoints Predictor)[10]。对于每个路径点,我们应用了 双通道理论(Dual-Channel Theory) [14],[19] 来高效描述观察到的场景,将场景描述分为:
- “是什么”(What)通道:与地标对象相关;
- “在哪里”(Where)通道:与室内环境的空间特性相关。
这种分离方法很好地契合了导航任务中在不同环境上下文中到达目标对象的需求。
由于智能体接收到的指令可以分为对应于到达对象和切换环境的子指令,LLM 能够有效地专注于当前目标。我们进一步引入了一种 反思机制(Reflection Mechanism),结合路径点指令方法,使智能体能够从与环境的交互中抽象出新知识。LLM 将这些过去的经验与认知地图中的空间信息结合起来,从而进行更明智的导航规划,促进连续学习和自适应能力。
Cog-GA 使用 LLM 将感知结果与历史信息融合,通过在认知地图中维护时间、空间和描述性记忆,支持导航步骤中的规划。每个导航步骤通过预测路径点优化搜索空间,并通过双通道描述场景,突出相关的对象和空间上下文。系统通过经验学习和策略适配,利用反思机制通过 LLM 捕捉导航反馈。
在 VLN-CE 数据集上的大量实验表明,Cog-GA 智能体在心理学上模拟了类人的行为,并取得了令人鼓舞的性能表现。本研究为开发更智能、类人化的视觉语言导航智能体奠定了基础,使其能够在利用语言模型先验知识的同时,战略性地适应新环境。
主要贡献总结:
- 我们提出了 Cog-GA 框架,一种基于大语言模型的生成式智能体,专注于连续环境中的视觉语言导航(VLN-CE)。Cog-GA 模拟了类人的认知过程,包括认知地图构建、记忆检索和导航反思。实验表明,Cog-GA 在 VLN-CE 数据集上达到了 48% 的成功率,与最新技术水平相当。
- 我们引入了一种基于认知地图的记忆流机制,存储空间、时间和语义信息,为 LLM 提供上下文知识以支持导航规划和决策。
- 我们引入了路径点预测器和双通道(“是什么”和“在哪里”)场景描述方法,优化了搜索空间,使 LLM 能够专注于当前目标。这种方法显著提高了导航成功率。
相关工作
VLNCE
视觉语言导航(VLN)近年来在自然语言处理、计算机视觉和机器人领域中备受关注。2018年,Anderson 等人通过 Room-to-Room (R2R) 数据集 [2] 首次提出了这一任务,此后该领域扩展到包括 Touchdown [5] 和 REVERIE [20] 等在内的多样化环境任务。在众多方法中,强化跨模态匹配(Reinforced Cross-Modal Matching, RCM)方法显著提升了性能,在路径长度加权成功率(Success Rate weighted by Path Length, SPL)指标上比基线提高了 10% [28]。历史感知多模态 Transformer (HAMT) 则通过有效整合历史上下文,进一步增强了长期导航能力 [7]。
在传统 VLN 任务中,智能体的导航路径受到限制,只能在预定义的图结构内进行操作,因而在现实世界中的应用有限。Krantz 等人 [17] 将 VLN 的范式扩展到连续环境(Continuous Environments),允许智能体在 3D 空间中没有预定义路径的情况下进行导航。这种设置更接近真实世界的条件,但也引入了新的挑战。Zhang 等人 [30] 指出,视觉外观显著影响了智能体的性能,这表明模型需要具备在不同场景中良好泛化的能力。Wang 等人 [27] 开发了强化跨模态匹配(RCM)方法,进一步提升了导航性能。此外,Guhur 等人 [9] 表明,在 BnB1 数据集上的预训练可以增强模型在新环境中的泛化能力。
[13] 模型采用了双层决策过程,利用高层推理将导航指令与视觉线索匹配,同时通过底层策略直接控制智能体的动作。[12] 引入了语义感知时空推理智能体(Semantically-aware Spatio-temporal Reasoning Agent, SASRA),将语义映射与混合 Transformer-循环架构结合,开发了时间语义记忆,从而改善了 VLN 中的空间和时间推理能力。
为进一步应对 VLN-CE 任务的挑战,Hong 等人 [10] 证明,通过预测路径点的导航方法显著提升了性能,有效弥合了离散-连续之间的差距。Wang 等人 [26] 提出了环境表示图(Environment Representation Graph, ERG),加强了语言数据与环境数据之间的联系,提升了 VLN-CE 的性能。Chen 等人 [6] 引入了方向引导导航智能体(Direction-guided Navigator Agent, DNA),将方向提示融入编码器-解码器框架中。然而,他们指出,这种方法需要大量训练来获取先验知识。
LLM引导的导航
大语言模型(LLMs)通过强大的信息处理能力和广泛的知识增强了导航任务的表现。
- VELMA 模型 [23]:使用 LLM 根据指令中描述的地标进行导航。
- Esc 模型 [31]:分析目标与物体、房间级别的相关性。
- LFG 模型 [24]:在零样本物体导航任务中采用链式推理(Chain-of-Thought, CoT),以最小化无关路径。
- Cai 等人 [3]:通过将全景图像聚类为节点,扩展了链式推理,用于制定更具策略性的导航决策。
- ProbES [18]:通过提示式环境自探索(Prompt-based Environmental Self-exploration),在 VLN 和 REVERIE 任务中增强了 LLM 的泛化能力,展示了其适应性。
- Co-NavGPT [29]:利用 LLM 进行协作式多机器人导航,基于实时地图数据设置中期目标。
通过集成更多认知过程,这些模型的表现可以进一步提升。
方法
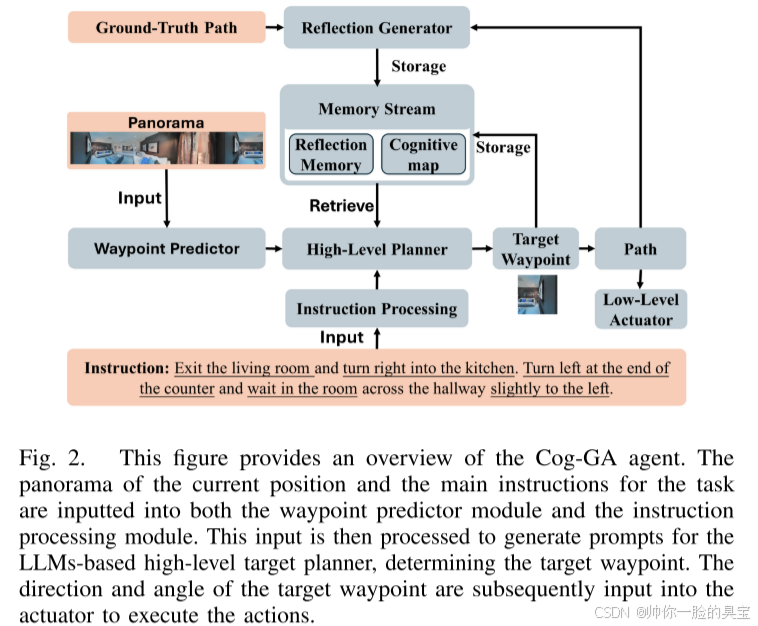
我们利用大语言模型(LLM)来模拟导航的认知过程,包括 创建认知地图(Cognitive Map)、指令理解(Instruction Understanding) 和 反思机制(Reflection Mechanism)。通过引入LLM,视觉语言导航(VLN)智能体能够获取丰富的先验知识,从而高效处理任务。我们构建了一个基于图结构的认知地图,作为外部记忆,用于弥补 LLM 缺乏长期记忆和空间记忆的不足。这种认知地图使基于 LLM 的智能体能够理解并记住连续的环境信息。
Generative Agent for VLN-CE Tasks
我们将连续环境中的视觉语言导航(VLN-CE)任务分为三个阶段:生成搜索空间、高层目标规划 和 低层运动生成。
-
生成搜索空间:
- 通过将连续环境划分为路径点(Waypoints),构建搜索空间。
- 这是一个重要的预处理步骤,可将导航简化为路径点选择,从而提高效率。
-
高层目标规划:
- 基于大语言模型(LLM)的规划器根据当前子指令选择路径点作为目标。
- 规划器利用记忆流中的认知地图存储的空间记忆来进行规划。
-
低层运动生成:
- 选择的路径点被传递给运动生成器,执行具体动作。
我们为 VLN-CE 任务设计了一种生成式智能体,包含以下模块:
- 路径点预测器(Waypoint Predictor): 利用全景观察数据,在每一步构建路径点的搜索空间。
- 记忆流(Memory Stream): 包含认知记忆和反思记忆。
- 指令处理模块(Instruction Processing Module): 将任务分解为可管理的子指令。
- 高层规划器(High-Level Planner): 基于认知地图和反思记忆生成提示(Prompts),并用 LLM 识别目标路径点。
- 反思模块(Reflection Module): 在导航过程中评估每一步的导航结果,为后续改进提供反馈。
此外,场景描述器将环境分为“是什么”(What)和“在哪里”(Where)流:
- “是什么”流: 地标对象。
- “在哪里”流: 空间特征。
这些流以及记忆流中的认知和反思记忆共同指导高层规划器生成提示,用于 LLM 确定目标路径点索引,并将其传递给低层执行器。在移动过程中,反思生成器评估导航结果,为每一步的影响提供反馈。
基于认知地图的目标推理
人类和动物通过创建认知地图来编码、存储和检索关于环境中相对位置和属性的信息。这一概念由 Edward Tolman 于 1948 年提出,用以解释老鼠如何学习迷宫结构,并扩展到人类导航和空间感知中。在基于 LLM 的智能体和 VLN-CE 任务中,我们借用这一认知地图概念。
LLM 缺乏长期和空间记忆,这使得外部记忆变得至关重要 [11],[33]。我们通过引入基于图的认知地图作为外部记忆解决这一问题,该地图能够构建并存储空间记忆,帮助 LLM 理解和记住环境。
认知地图的构建:
- 认知地图被初始化为无向图 G(E,N)G(E, N)G(E,N),其中:
- NpN_pNp: 表示已遍历的空间节点。
- NoN_oNo: 表示已观察到的物体节点。
- 连接规则:
- NoN_oNo 节点通过 1 权重的边 Ep,oE_{p,o}Ep,o 连接到其对应的 NpN_pNp 节点。
- NpN_pNp 节点之间的边 EpE_pEp 具有权重,表示路径点之间的距离和角度。
- 距离权重范围:0.25 至 3。
- 方向权重范围:1 至 8。
- 每个 NpN_pNp 节点还带有时间步标签 ttt。
认知地图图的表示为:
G({Ep,o,Ep},{Np,No})G(\{E_{p,o}, E_p\}, \{N_p, N_o\})G({Ep,o,Ep},{Np,No})
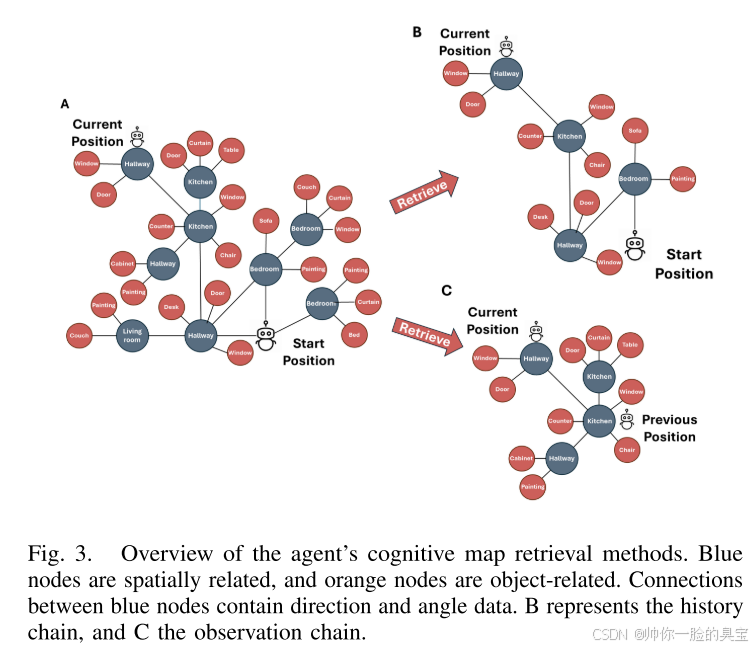
认知地图的检索: 检索认知地图对于目标推理至关重要。正如图 3 所示,我们定义了两种检索方法:
- 历史链(History Chain):
- 聚焦于已导航的节点,为规划器提供当前路径的抽象视图。
- 观察链(Observation Chain):
- 聚焦于当前和先前位置之间的潜在目标,提供对过去决策的更广泛视图。
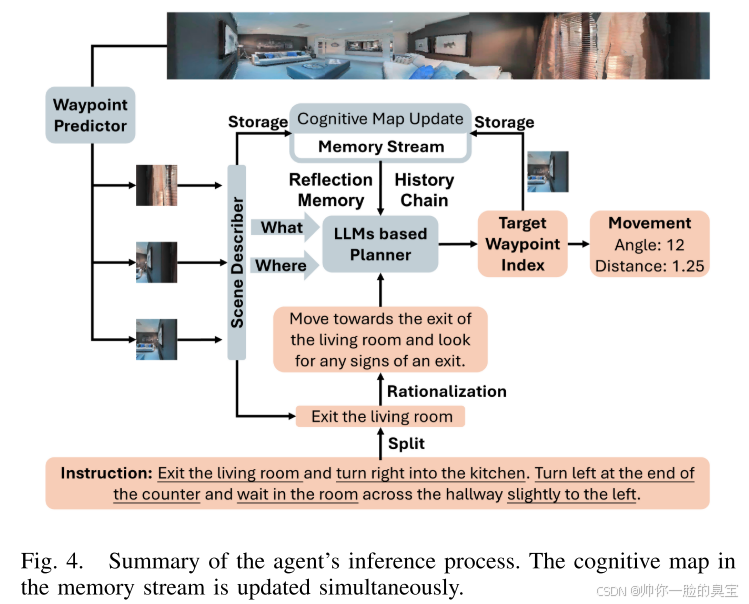
目标推理流程:
- 如图 4 所示:
- 路径点预测: 分割全景图像。
- 场景描述: 使用基于 LLama 的场景描述器处理路径点图像,将其转化为 “在哪里”(Where)和 “是什么”(What)相关词汇。
- 认知地图更新: 将这些路径点更新到记忆流中的认知地图。
- 规划输入: 将历史链、环境描述、反思记忆和子指令组合为统一的提示(Prompt)输入到基于 LLM 的规划器。
- 规划输出: 规划器输出目标路径点索引,并将其存储在认知地图的记忆流中。
- 动作执行: 执行器从地图中提取距离和角度信息,用于智能体的具体动作。
基于指令合理化的指令处理器
对于 VLN-CE 智能体而言,处理指令是一个非平凡的任务。直接使用未经处理的指令会导致规划器混淆,从而执行无意义的动作。为了解决这一问题,我们提出了一种 指令合理化机制(Instruction Rationalization Mechanism)。
我们通过 LLM 将指令分解为多个子指令,来指导智能体的行为。然而,原始子指令通常缺乏上下文信息。例如,子指令“离开客厅”可能会让智能体对当前目标感到困惑,导致重复路线。因此,我们引入当前环境信息和未经处理的指令,对子指令进行调整。
这一过程可以表示为:

例如,合理化后的子指令“找到客厅的门,并寻找通向厨房的标志”对智能体来说更为有效。在导航任务的开始阶段,智能体将自然语言指令分解为多个子指令。随着智能体的移动,每个子指令基于观测结果进行更新,这一过程称为 指令合理化(Instruction Rationalization)。
1. 问题:原始指令的复杂性与模糊性
- 直接使用原始指令的问题:
- 自然语言指令通常包含多个步骤或目标,直接使用可能导致智能体混乱。
- 缺乏环境上下文的指令可能导致智能体在导航中重复路径或误解目标。
- 示例:
- 指令“离开客厅”可能让智能体不知道目标具体在哪里。
2. 解决方案:指令合理化机制
- 子指令分解:
- 使用 LLM 将复杂的自然语言指令分解为多个简单、可执行的子指令。
- 合理化更新:
- 每个子指令结合当前环境信息(如观察到的地标、方向)和原始指令进行动态调整。
- 使指令更加明确和上下文相关。
3. 示例:
- 原始子指令:“离开客厅”。
- 合理化后:“找到客厅的门,并寻找通向厨房的标志”。
- 合理化后的指令更具体,且明确当前目标和下一步行动,提高了执行效率。
具有reflection机制的生成机器人
生成式智能体这一概念结合了人工智能与类人模拟,标志着一项重要的技术进步。这些智能体基于与环境的交互和过去的经验模拟人类行为。由于 VLN-CE 紧密模拟了现实世界的导航场景,因此它是模拟人类导航心理过程的理想应用。
在导航过程中,智能体接收全景路径点输入作为观测数据。场景描述器将每个路径点的结构化描述提供给规划器,同时提供来自认知地图(见 III-B 部分)的历史链和记忆流中的反思记忆。规划器利用这些信息,基于子指令确定下一个导航路径点。
当规划器识别出目标后,将路径点的角度和距离信息发送给低层执行器(低层控制模块),以控制智能体移动。随后,智能体对其动作进行反思,以收集未来任务的宝贵经验。这种反思帮助智能体理解成功或失败的原因,从而获得有关环境的一般知识。
然而,LLM 如果积累过多的经验,可能会因信息过载而扰乱决策过程。为了解决这一问题,我们为导航任务中的反思记忆定义了三个参数:
- 最优距离(Optimal Distance): 通过动态时间规整(Dynamic Time Warping, DTW)测量当前导航序列与正确序列之间的差距。
- 时间接近性(Proximity): 当前步骤与记忆的时间接近程度。
- 可重复性(Repeatability): 相似记忆出现的频率。
新记忆若与已有记忆相同,则不会被存储,而是更新现有记忆的时间接近性和可重复性。每个反思记忆的得分定义如下:

遗忘机制(Forgetting Process): 对于得分处于最低 10% 的反思记忆,将其从记忆中删除。
1. 反思机制的作用:
- 核心功能:
- 智能体通过对动作的反思,理解导航中的成功与失败原因。
- 帮助智能体建立对环境的通用知识(如常见障碍物位置、路径选择策略)。
- 目标:
- 在未来导航任务中,利用反思记忆提升决策效率和成功率。
2. 反思记忆的参数设计:
- 最优距离(Optimal Distance, dmd_mdm):
- 衡量当前导航路径与理想路径的差异,反映导航准确性。
- 时间接近性(Proximity, tmt_mtm):
- 优先考虑与当前步骤时间接近的记忆,保证更新的时效性。
- 可重复性(Repeatability, rmr_mrm):
- 记录相似情境出现的频率,提高对常见场景的适应性。
3. 记忆管理与优化:
- 得分计算:
- 通过得分公式对每条记忆进行评估,确保高价值记忆优先保留。
- 遗忘机制:
- 自动删除得分最低的 10% 记忆,防止 LLM 因过多无关信息而混淆决策。
- 动态更新:
- 新记忆若与已有记忆重复,则只更新其接近性和可重复性,避免存储冗余信息。
4. 工作流程:
- 输入:
- 场景描述、历史链、反思记忆,以及当前的子指令。
- 输出:
- 规划器根据上述输入信息生成目标路径点,低层执行器据此执行动作。
- 反思:
- 每个导航步骤完成后,反思模块评估当前动作的效果并更新记忆。
附录
导航任务中 LLM 的最优提示机制
1. LLM 的提示设计
- 为何需要结构化提示:
- 自然语言指令可能包含冗余和不相关信息,增加 LLM 的处理负担。
- 通过明确分类(如方向、房间类型、物体),提示设计能引导 LLM 聚焦于任务相关内容。
- 提示格式:
- 导航提示:
'Go (direction), Is (room type), See (objects).'- 用于为智能体提供导航指令的整体方向。
- 环境描述:
'In (direction), See (objects), Is (room type).'- 用于描述智能体当前环境,帮助其更好地感知周围。
- 导航提示:
2. 多步骤指令处理的挑战
- 原始指令问题:
- 常常包含多个步骤,直接分解可能导致:
- 信息丢失:关键上下文未被保留。
- 误导:任务间逻辑关系被破坏。
- 常常包含多个步骤,直接分解可能导致:
- 解决方法:
- 引入引导机制,为当前任务提供补充信息。
3. 引导机制的工作原理
- 子目标划分:
- “在哪里”(where): 提供环境切换指令,例如“进入厨房”。
- “是什么”(what): 提供物体搜索指令,例如“找到桌上的杯子”。
- 引导结构:
'You should try to go (where).''You should try to find (what).'
- 动态更新:
- 每个引导信息与合理化后的子指令同步调整,确保在任务执行中的上下文一致性。
4. 机制的优势
- 简化处理:
- 减少冗余信息输入,降低 LLM 的认知负担。
- 提高效率:
- 通过明确任务目标,提升路径点选择和动作规划的准确性。
- 保持一致性:
- 动态更新引导信息,使 LLM 的行为与导航目标高度吻合。
指令质量的影响及构建更好的子指令
1. 指令质量的重要性
- 实验发现:
- 高质量指令显著提高了智能体的导航成功率。
- 合理化的好处:
- 示例对比:
- 原始指令:“离开客厅”。
- 合理化后:“找到客厅的门,并寻找通向厨房的标志”。
- 合理化后的指令更具体,明确了智能体的目标和行为,提高了执行效率。
- 示例对比:
2. 分步指令的连贯性
- 核心发现:
- 智能体需要分步指令保持顺序的逻辑连贯性。
- 指令内容必须根据环境动态调整目标描述,确保与实际导航情况匹配。
- 类比人类认知:
- 类似的分步调整策略可能也存在于人类在完成复杂任务时的认知过程。
3. LLM 对长期指令的局限性
- 问题:
- 长期描述性指令容易混淆 LLM:
- 多个目标同时出现会导致注意力分散。
- 信息过载降低了决策效率。
- 长期描述性指令容易混淆 LLM:
- 解决方法:
- 将长指令分解为多个子指令,使 LLM 能够逐步聚焦于当前任务。
4. 对未来工作的启示
- 指令分解和合理化的重要性:
- 在设计导航任务时,应优先考虑将复杂指令分解为易于执行的短指令。
- 动态更新子指令描述以适应环境变化。
- 研究人类认知启发:
- 模拟人类认知中的指令处理方式,进一步优化 LLM 的导航能力。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)