智能体在真实世界中的感知与行动融合最新综述!探索多模态具身大模型:发展,数据集与未来方向
论文系统地回顾了具身多模态大模型的发展,分析了基础大模型的技术进步及其在具身任务中的应用。通过分析多个数据集的影响,识别了高质量数据在模型性能提升中的重要性。尽管EMLMs在多个领域取得了显著进展,但仍需解决跨模态对齐、计算资源效率和泛化能力等挑战。未来的研究应关注跨模态预训练和自监督学习,以实现更高效、更灵活的具身智能系统。本文的研究为EMLMs的未来发展提供了有价值的参考和启示。

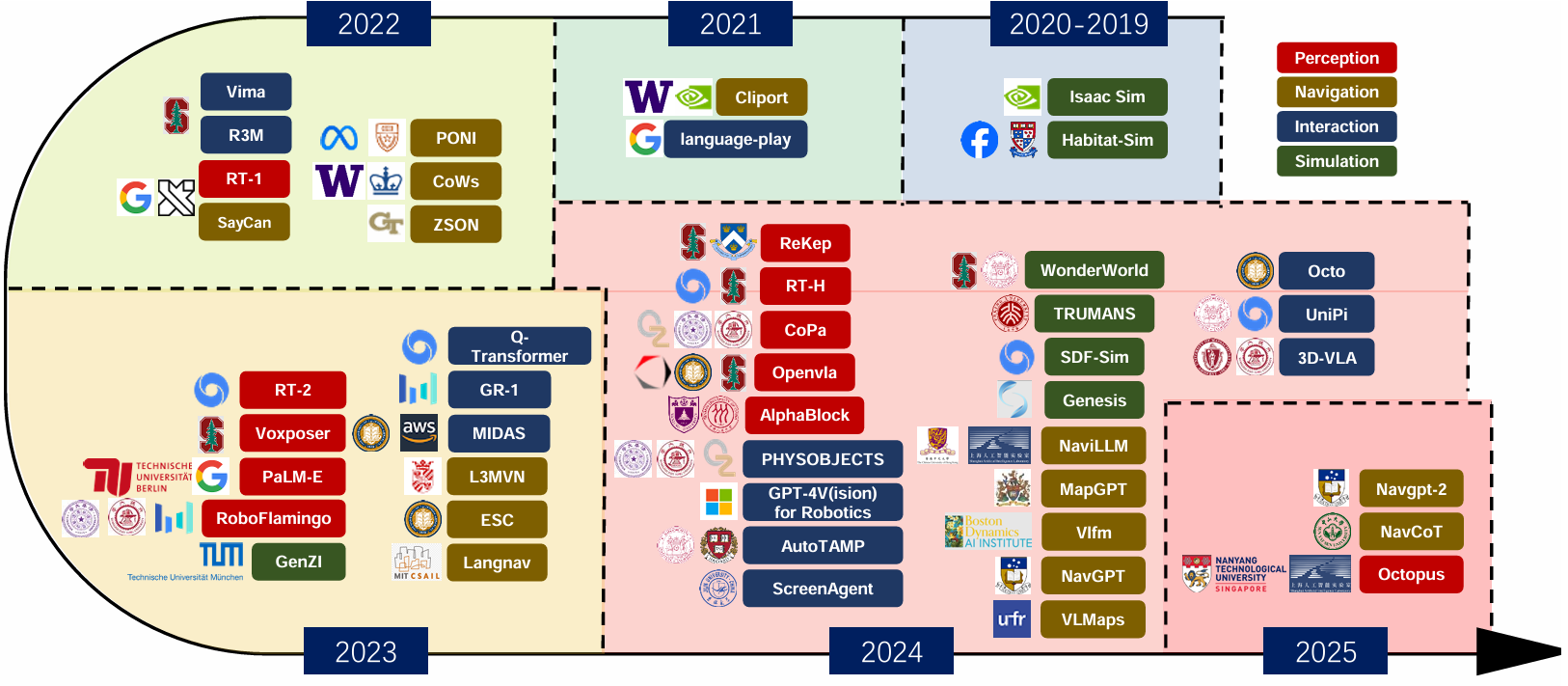
-
作者: Shoubin Chen, Zehao Wu, Kai Zhang, Chunyu Li,∗, Baiyang Zhang, Fei Ma, Fei Richard Yu, Qingquan Li
-
单位:广东省人工智能与数字经济实验室,深圳大学城市信息重点实验室,巴黎高等工程技术学院,中山大学
-
论文标题:Exploring Embodied Multimodal Large Models: Development, Datasets, and Future Directions
-
论文链接:http://arxiv.org/abs/2502.15336
团队简介
-
光明实验室泛在感知与空间智能团队由中国工程院院士李清泉领衔,主要研究方向包括:
-
精密定位与自主导航
-
多场景感知与动态探测
-
具身智能与协同感知
-
数据挖掘与空间智能
-
-
该实验室长期招聘博士后、全职序列(研究员、副研究员)和研究型实习生,招收优秀硕博研究生。联系方式:chenshoubin@gml.ac.cn。
主要贡献
-
论文首次系统性地回顾具身多模态大模型(EMLMs)研究进展,填补了现有文献中的一个重要空白,提供了一个全面的视角来分析EMLMs的发展和应用。
-
通过对300篇研究论文的深入分析,进行了全面的全栈分析,涵盖了基础大模型、具身感知大模型、具身导航大模型、具身交互大模型、仿真技术和数据集。
-
总结了用于EMLMs的基准数据集,并详细描述了它们的收集方法。通过分析这些数据集的关键特征,包括数据格式、功能、适用平台及其优缺点,为研究人员提供了有价值的信息。
-
讨论了EMLMs的主要发现和未来研究方向,特别是在多模态感知、推理和行动的整合方面。通过识别当前研究的不足和未来的研究机会,为EMLMs领域的进一步发展提供了指导。
1. 介绍
1.1.背景和动机
-
具身智能的起源:
-
具身智能(embodied intelligence)的理念是对传统认知理论的批判而产生的。
-
Rodney Brooks 在 1991 年的论文《Intelligence Without Representation》中提出了这一观点,认为智能行为可以通过与环境进行物理互动而产生,而不依赖于内部表征。
-
-
理论发展:
-
具身智能进一步由 Varela、Thompson 和 Rosch 在《The Embodied Mind》(1991)中发展,强调身体经验在塑造认知中的作用。
-
Lakoff 和 Johnson 的《Philosophy in the Flesh》(1999)也强调了感官-运动经验在认知中的基础性作用。
-
具身智能的理念在机器人学中找到了实际应用,例如 Cog 项目探索了机器人如何通过身体与世界的互动来发展认知能力。
-
1.2.大模型与具身智能的融合
-
具身多模态大模型的概念:
-
随着大模型技术的快速发展,研究人员开始将具身智能的原则应用于这些模型。
-
具身多模态大模型(EMLMs)是指结合多种数据模态(如视觉、语言和动作)以及具身能力(如感知和在物理环境中的互动)的一类模型。
-
这些模型的目标是探索人工智能如何通过与环境互动来发展更灵活和适应性的能力,旨在弥合抽象推理能力和现实世界复杂性之间的差距,允许智能系统以更接近人类认知的方式感知、行动和学习。
-
-
EMLMs 的特点:
-
EMLMs 不同于传统的 AI 系统,它们整合了多样化的传感模态,如视觉、语言和音频,使其能够感知并与物理环境互动。
-
EMLMs 可以同时处理多模态输入,并生成影响物理世界的输出,对于机器人操作、自主导航、人机交互和沉浸式虚拟环境等应用至关重要。
-
1.3.研究现状和挑战
-
近年来,大模型与多模态感知系统的集成,如具身智能体,导致了能够应对越来越复杂任务的突破性模型的发展。
-
尽管取得了显著进展,但具身智能与大模型的融合仍处于早期阶段,存在几个挑战,包括提高模型的可扩展性和泛化能力,改进处理复杂任务的能力,以及增强具身智能体与其环境的互动能力。
-
现有的文献综述主要集中在自然语言处理中的传统大模型上,如 LLMs,而不是解释具身智能体与大模型的整合。有些综述虽然关注这种整合,但范围过于宽泛,未能深入探讨多模态大模型在整个具身智能发展中的作用。
-
本文旨在填补这些空白,对 EMLMs 的最新发展进行全面综述,分析其技术进步、数据集的影响以及未来的发展方向。
2.基础模型与具身多模态大模型
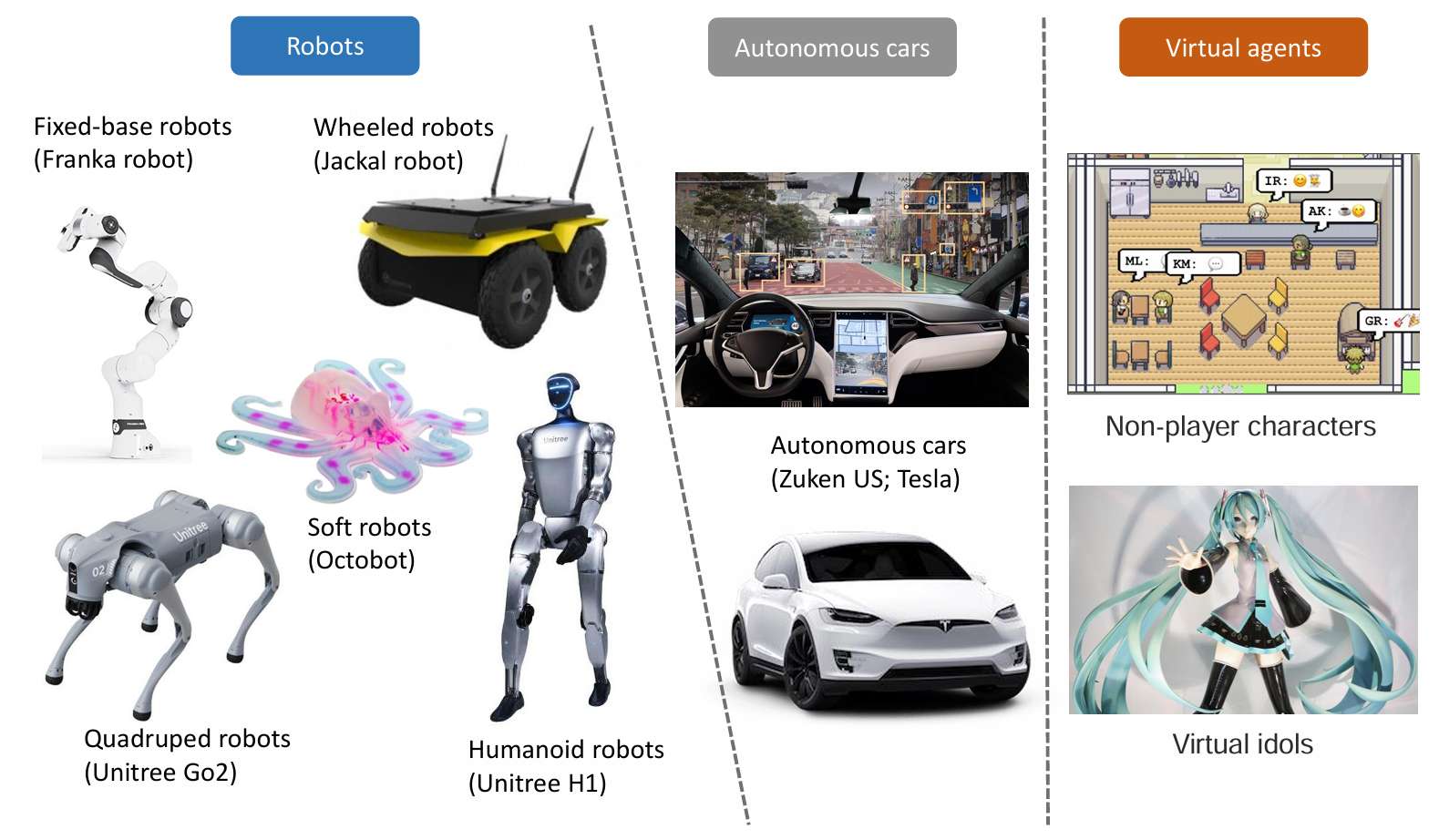
2.1.具身智能体
-
具身智能体是物理或虚拟世界中的自主实体,具有感知、行动和与环境互动的能力。这些智能体有多种形式,包括机器人、自动驾驶车辆和虚拟智能体。
-
机器人是最常见的具身智能体类型,根据应用的不同,有固定基座机器人、轮式机器人、四足机器人、仿人机器人和软体机器人等。例如,固定基座机器人如Franka机器人通常用于工业环境中的自动化任务,而仿人机器人因其类人的外观和适应性,可以应用于广泛的领域。
-
自动驾驶车辆也被视为具身智能体,它们通过感知环境、实时决策并与驾驶员及周围环境互动来执行任务。这些系统不仅能提高驾驶安全性,还能解释人类指令并参与与乘客的对话。
-
虚拟智能体在游戏、社交实验和虚拟偶像等应用中很突出。这些智能体通过多种模态(如语言、视觉和音频)与用户互动,提供丰富且沉浸式的体验。
2.2.语言大模型
-
LLMs,如GPT-4、BERT和T5,是现代AI的核心组成部分,特别是在自然语言处理(NLP)领域。这些模型通过大规模无监督学习从海量文本数据中捕捉复杂的语言模式和结构。
-
GPT系列模型通过自回归训练生成文本序列,GPT-3是迄今为止最大和最强大的版本,显著提升了文本生成、问答和翻译等任务的性能,并展示了零样本和少样本学习的潜力。
-
GPT-4进一步增强了推理能力,并引入了多模态能力,支持文本和图像输入,能够生成图像描述、回答与视觉内容相关的问题,并指导具身系统的动作。
2.3.视觉大模型
-
LVMs处理图像或视频信息,表现出色于图像识别、目标检测、图像生成和跨模态学习等任务。
-
ResNet引入了残差连接以解决深度神经网络训练中的梯度消失问题。
-
Vision Transformer(ViT)将Transformer架构应用于计算机视觉,通过自注意力机制处理全局依赖关系。
-
Swin Transformer采用窗口机制进行局部自注意力计算,提高了计算效率。
-
Segment Anything Model(SAM)提供了灵活高效的图像分割解决方案,支持语义分割、实例分割和对象分割等多种任务。
2.4.视觉语言大模型
-
LVLMs结合视觉和语言信息,增强智能体的环境理解、推理和任务执行能力。
-
CLIP通过对比学习将图像和文本嵌入到共享向量空间,支持图像分类和图像-文本检索任务。
-
DALL·E基于GPT-3生成基于文本描述的图像,DALL·E2和DALL·E3进一步提升了生成图像的质量和多样性。
-
BLIP通过双向自监督学习策略整合视觉和语言信息,优化了预训练效率。
-
Flamingo能够在少量标注数据的情况下进行少样本学习,适用于需要高效处理多种数据类型的场景。
2.5.其他模态模型
-
视觉-音频模型在日常任务中起重要作用,帮助识别场景和定位声源。SoundSpaces结合视觉和音频进行导航任务,如AudioGoal和AudioPointGoal。
-
视觉-触觉模型在操作任务中结合视觉和触觉数据,提升机器人的任务表现。研究探索了如何利用视觉和触觉数据进行物体6D位姿估计和抓取策略调整。
3.具身多模态大模型的发展
-
具身多模态大模型(EMLMs)是一类能够结合多种模态数据(如视觉、语言、听觉等)并具备具身能力(如在物理环境中感知和交互)的人工智能模型。
-
这些模型通常被设计用于执行感知、导航和交互等任务。如下图所示,EMLMs通过多种传感器(如摄像头、激光雷达等)感知环境,并根据人类语音或语言指令执行特定任务。
-
任务执行涉及三个关键模块:感知、导航和交互。这些模块的训练和评估数据可以通过仿真环境或真实场景收集。
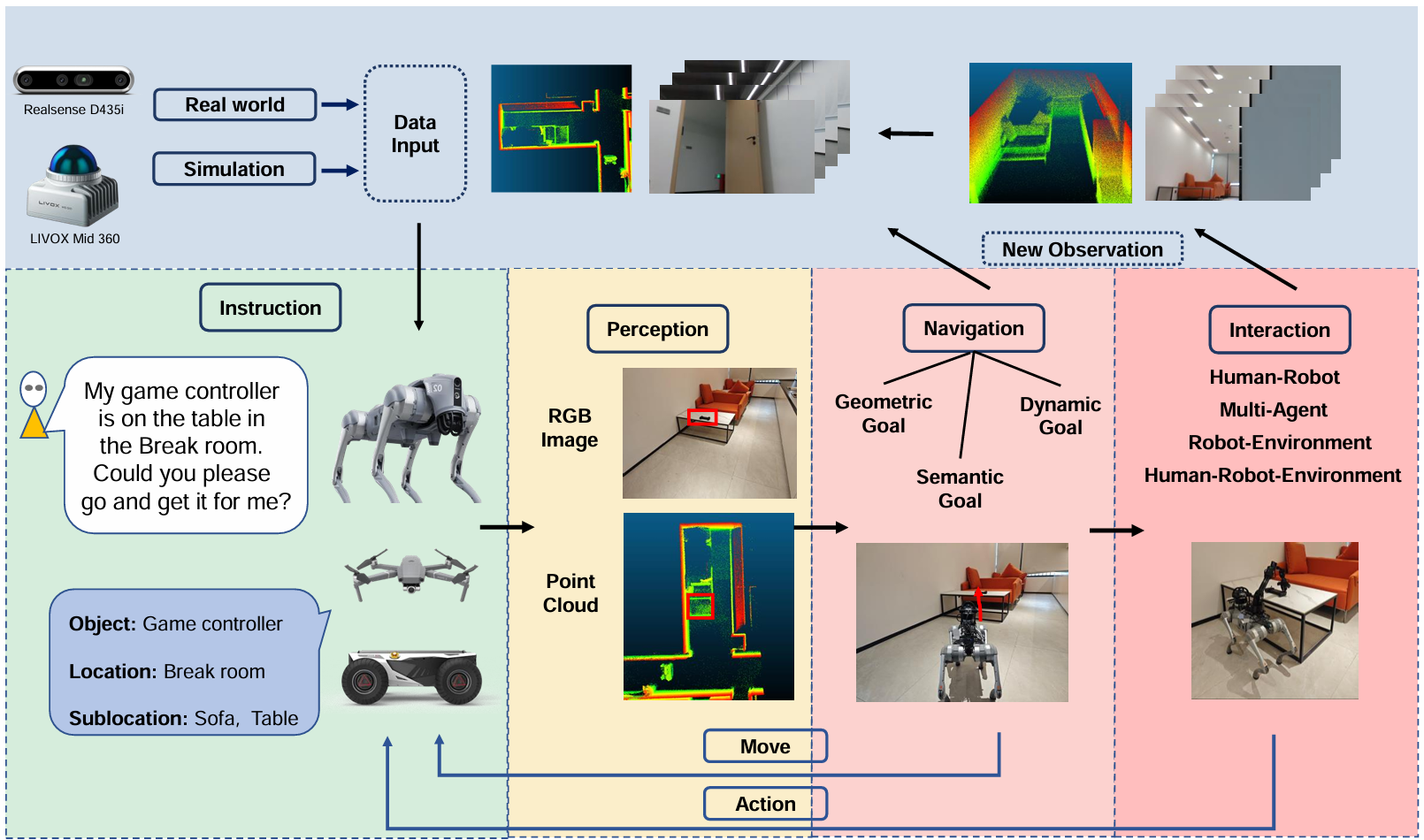
3.1.具身感知
具身感知与传统的目标识别不同,它要求模型能够更深入地理解物理世界中的物体及其运动和逻辑关系。具身感知需要视觉感知和推理能力,能够基于视觉信息预测和执行复杂任务。具身感知大模型的发展如下图所示。
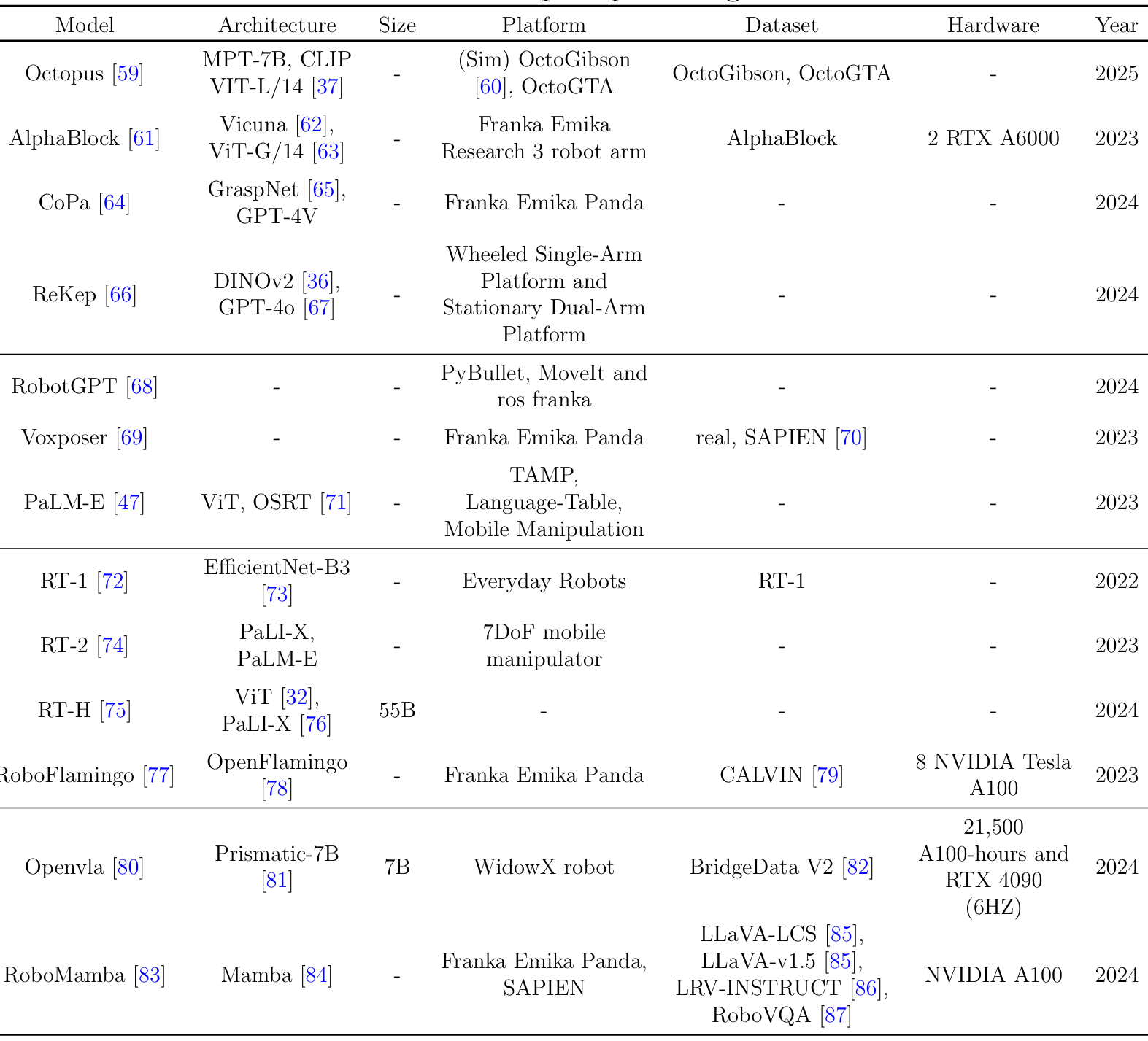
3.1.1.基于GPT的大模型
基于GPT的大模型能够接受特定任务的语言指令,并以自然语言格式返回场景理解结果,处理多种感知任务。例如,
-
Octopus使用GPT-4V动态生成对观察图像的描述和分析,包括场景中可交互物体及其空间位置。
-
CoPa利用GPT-4V直接识别和突出显示观察图像中物体的特定抓取区域和潜在抓取姿态。
-
AlphaBlock通过引入“chain-of-thought”方法,要求GPT-4V在生成坐标前进行推理,以提供对布局的理解和描述。
-
Voxposer利用多模态大模型提取物体的空间几何信息并生成3D坐标,用于生成机器人操作的代码。
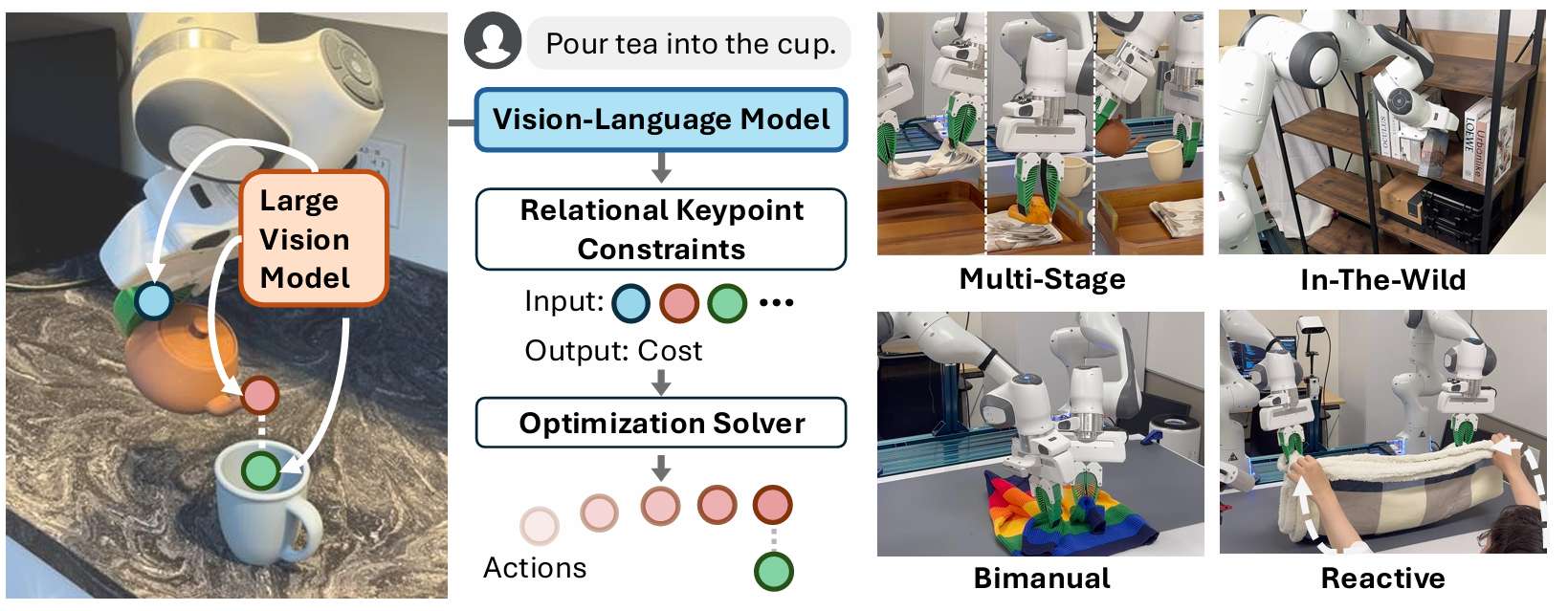
-
ReKep通过DINOv2提取图像特征,结合Segment Anything Model提取标记点,然后将这些信息输入GPT4o生成多阶段任务的子目标和路径约束。
-
RobotGPT通过GPT生成可执行代码,采用五部分提示方法,提供详细的环境、物体和任务描述。
3.1.2.其他大模型

PaLM-E直接整合来自具身智能体传感器模态的连续输入,使语言模型能够基于与语言标记相同的潜在空间进行推理,从而在现实世界中进行序列决策。
-
RT-1使用EfficientNet-B3作为感知模块,将图像编码为隐式表示,用于后续任务执行。
-
RT-2训练视觉-语言模型直接输出低级机器人动作,通过将动作表示为文本标记来实现。
-
RoboFlamingo基于OpenFlamingo,通过少量模仿学习微调,使其能够处理机器人操作数据。
-
Openvla是一个7B参数的开源视觉-语言-动作(VLA)模型,通过DINOv2和SigLIP级GPU训练,增强了Llama 2语言模型。
-
RoboMamba通过Mamba模型整合视觉编码器,通过共训练对齐视觉数据与语言嵌入,发展视觉常识和推理能力。
3.2.具身导航
-
与传统A到B的机器人导航不同,具身智能导航系统采用更动态和环境感知的方法,通过传感器实时感知和处理周围环境信息,并将其转换为可理解的语义信息供智能体使用。
-
在具身智能导航领域,主要分为两种方法:一种是利用通用大模型,另一种是专门为具身智能任务定制的EMLMs。
3.2.1.通用大模型
LVLMs能够理解和生成自然语言,因其庞大的规模、先进的架构和在大规模数据上的预训练而具备出色推理和语义理解能力。例如,
-
LM-Nav基于GPT-3实现自然语言指令解析,通过提取文本地标并结合场景图像进行导航决策。
-
L3MVN通过RoBERTa-large模型展示了LVLMs在导航任务中的两种创新范式:零样本方法和前馈方法。
-
VLMaps利用GPT-4V使LLMs推测目录中最接近目标的已知物体。
-
NavGPT完全基于LLMs,能够处理多模态输入,包括视觉观察的文本描述、导航历史和潜在的探索方向。
-
SG-Nav构建了层次化的3D场景图,并利用LLMs进行层次化链式推理,使LLMs能够基于场景图的结构信息推断目标对象的位置。
CLIP和BLIP-2等语言-图像预训练模型通过预训练大量图像-文本对来学习两者之间的相关性,适用于处理导航任务中从环境中获得的图像,以建立图像与文本指令或地标的对应关系。
-
NavGPT-2基于InstructBLIP构建,通过应用EVACLIP的视觉编码器,保留了LLMs的推理能力。
-
vlfm利用BLIP-2获得当前RGB观察帧与目标文本提示中每个对象之间的余弦相似度分数,生成2D价值图。
3.2.2.专用具身智能大模型
-
NavCoT结合现有的VLN数据集和先进模型(如LLMs和CLIP)训练LLaMA模型,从多视角图像中提取物体文本,增强未来想象任务的性能。
-
NaviLLM通过ViT提取每个位置的六视角图像特征,形成场景编码,然后使用Transformer编码器捕获不同视角之间的依赖关系。
-
Trans-EQA利用Transformer在导航模块中的全局建模优势,取代传统CNNs的局部特征提取瓶颈。
-
GOAT通过因果学习模块处理视觉、指令和历史信息,减少混杂因素的影响。
-
Rui Liu等人提出使用体素实现更全面的3D表示。
-
Berkeley AI Research团队推出的通用导航模型GNM、ViNT和NoMaD是一组通用模型,能够在多种不同机器人上进行控制,而无需特定的先验训练。
3.3.具身交互
-
传统的机器人交互方法通常需要将独立的感知、决策、规划和控制模块集成在一起以完成特定任务。
-
随着深度学习的发展,尤其是语言和视觉模型的显著进步,具身智能交互成为可能。
-
具身智能交互涉及使智能智能体和大模型具备多模态处理能力,包括自然语言推理、视觉空间语义感知以及视觉感知与语言系统的对齐等关键技术。
-
目前,具身智能交互的基础能力要求系统能够理解人类自然语言指令并自主完成任务,因此以语言为基础的具身智能交互成为研究的中心。
3.3.1.基于语言的短视距行动策略
许多研究人员专注于语言与视觉融合的行动策略,以完成简单任务。例如,
-
R3M提出了一个视觉编码器,通过大量Ego4D人类视频数据训练,学习稀疏且紧凑的表示,从而将机器人操作的成功率提高了10%。
-
Vi-PRoM从数据集、模型架构和训练方法三个维度探索视觉编码器的预训练策略。RT-1通过大量开放空间数据训练,实现机器人多任务学习能力和在未知场景中的泛化能力。
-
Google DeepMind团队基于RT-1引入了预训练视觉语言模型MOO,处理观察到的图像并输入视觉编码器,实现新环境和新物体的零样本学习。
-
Q-transformer使用Transformer训练强化学习中的Q值,而不是直接输出动作。
-
RT-2引入了大量互联网数据和机器人数据进行训练,显著提高了对物体的泛化能力。
-
UC Berkeley团队提出了Octo策略转移微调方法,测试表明该方法是有效的策略部署策略。
-
RoboFlamingo是基于开源视觉语言模型OpenFlamingo的机器人行动框架,实验结果表明该方法成本效益高且易于使用。
-
Vima是基于Transformer的机器人行动策略,引入目标的视觉裁剪图像到提示中。
-
RT-H首先预测动作语言,然后基于动作语言和视觉信息预测机器人动作。
-
GR-1是一种简单的GPT风格端到端模型,将语言指令、一系列观察图像和一系列机器人状态作为输入,预测机器人动作和未来图像。
-
Voxposer利用大语言模型的代码编写功能与视觉语言模型交互,形成3D价值图。
3.3.2.基于语言的长视距行动策略
当做出决策时,智能体会考虑长期目标和策略,而不是只关注短期目标。这种长视距策略涉及更复杂的规划和推理,目标是最大化长期回报或实现长期目标。
-
SayCan通过预训练技能将大语言模型与现实世界连接起来,帮助机器人执行复杂任务。
-
Zero-Shot Planners利用大语言模型学习的世界知识,通过描述任务提示来实现任务规划和分解,无需额外训练。
-
Text2Motion提出了一个基于语言的规划框架,使机器人能够解决长视距顺序操作任务,根据自然语言指令构建任务和运动计划,并验证计划是否完成。
-
EmbodiedGPT结合视觉和语言信息,提取与任务相关的特征,实现高效准确的任务规划。TaPA将LLMs与视觉感知模型对齐,根据场景中感知到的物体生成可执行计划序列。
-
ViLaIn使用LLMs和视觉语言模型生成问题描述,并根据符号规划器的错误消息反馈优化生成的问题描述。
-
PG-InstructBLIP整合了基于物理世界的LVLM和大语言模型,构建了机器人规划器的交互框架。
-
Model Vision使用GPT-4V增强通用视觉语言模型,将演示操作视频和自然语言指令编码为基于GPT-4的任务计划。
-
ScreenAgent表明,仅使用任务规划无法很好地解决复杂任务,需要进一步紧密耦合任务规划和运动规划。
-
AutoTAMP将自然语言任务描述转换为中间任务表示,然后结合中间任务表示和传统任务与运动规划算法共同解决任务和运动规划问题。
-
Mutex提出了一个统一的策略学习方法,基于Transformer架构整合跨模态和Transformer基础动作策略学习,有效学习跨模态任务规范,并能同时执行序列文本任务指令和多任务文本指令。
-
Octopus引入了具身视觉语言程序员,将生成的可执行代码作为连接高层任务规划和现实世界操作的媒介。
-
3D-VLA和Grid认为3D场景信息可以帮助模型更好地理解现实世界。
-
LEO开发了一个具身多模态通用智能体,擅长在3D世界中感知、推理、规划和行动。
-
Sayplan提出了一种基于LLMs和3D场景图表示的可扩展方法,用于构建机器人任务规划。
3.4.仿真
-
具身仿真对于具身智能至关重要,因为它允许在精确控制的条件下设计实验,并优化训练过程。这使得智能体能够在各种环境设置中进行测试,增强其理解和交互能力。
-
此外,它还促进了具身智能体内部的跨模态学习,并有助于生成数据的训练和评估。
-
为了实现与环境的有意义交互,必须构建一个考虑周围环境物理特性、物体属性及其相互作用的逼真仿真环境。
-
仿真平台一般分为两类:基于基础仿真的通用仿真器和基于真实场景仿真的仿真器。
3.4.1.基于基础仿真的通用仿真器
-
NVIDIA Omniverse™ Isaac Sim是一个强大的机器人仿真工具包,专为NVIDIA Omniverse™平台设计。
-
它为研究人员和实践者提供了构建虚拟机器人环境和进行实验所需的工具和工作流程。
-
Isaac Sim能够创建高度准确、物理逼真的仿真和合成数据集,具备高级物理仿真和多传感器RTX渲染能力。
-
它支持ROS2,有助于设计、调试、训练和部署机器人,加速自主系统的开发。
3.4.2.基于真实场景仿真的仿真器
-
SDF-Sim利用学习到的符号距离函数(SDFs)表示物体形状,以加速距离计算,实现复杂大规模环境的高效仿真。
-
TRUMANS数据集引入了一个自回归运动扩散模型,用于生成人类-场景交互(HSI)序列。该模型包含局部场景传感器和逐帧动作嵌入模块。
-
WonderWorld框架通过快速分层高斯面(FLAGS)表示,从单个图像生成多样化且连贯的3D场景,实现低延迟用户交互。
-
GenZI是一种开创性的零样本方法,能够从文本描述中生成3D人类-场景交互(HSI),解决了无需依赖标注3D数据生成3D交互的挑战。
-
iGibson 2.0和Habitat-Sim专注于为具身AI研究生成交互式3D环境。
-
Genesis是一个基于新开发的通用物理引擎的仿真平台,支持从物理准确和空间一致的视频到机器人操作策略等多种模态的全自动数据生成。
4.数据集
4.1.具身数据集收集方法
具身智能数据集的收集主要有两种方法:一种是使用具有物理身体的智能智能体在现实世界中收集数据,另一种是通过仿真器收集数据。
-
现实世界数据收集:
-
在现实世界中,数据通常通过多种传感器(如RGB相机、深度相机、惯性测量单元IMU、激光雷达、压力传感器、声音传感器等)收集。
-
然而,在数据收集过程中可能会遇到视野遮挡或操作细节记录不完整等问题。
-
为此,DexCap利用同时定位与建图(SLAM)技术跟踪手部运动,以解决这些问题。
-
-
仿真数据收集:
-
仿真数据收集方法允许快速生成大量多模态数据(如图像、深度图、传感器数据等),同时可以控制环境和任务变量,便于模型训练。
-
常用的仿真器包括Unity和Gazebo等。
-
4.2.具身感知和交互数据集
具身智能领域依赖于多样化的数据集,这些数据集捕捉了各种机器人操作、环境和感知模态。这些数据集可以根据数据收集方法(如真实数据、仿真数据或两者结合)进行分类,许多数据集还包含多模态信息。
-
Open X-Embodiment Dataset:由Google团队与20多个组织和研究机构合作发布,是一个大规模的多模态资源,包含来自22种机器人的数据,涵盖RGB图像、末端运动轨迹和语言指令,覆盖100万场景、500多种技能和15万任务。该数据集包含60个子数据集,是具身智能领域的重要资源。
-
RH20T Dataset:包含超过11万机器人操作序列,提供视觉、力、音频、运动轨迹、演示视频和自然语言指令等多种模态数据,是训练具身智能模型的宝贵资源。
-
ManiWAV Dataset:使用“耳内操作”数据收集设备捕捉人类在真实环境中的演示,同步音频和视觉反馈,为直接从人类演示中学习机器人操作策略提供了丰富数据。
-
ARIO Dataset:由鹏城实验室开发,包含超过300万样本,涵盖图像、语言指令、触觉反馈和语音等多种模态数据。该数据集不仅包括真实场景中使用Cobot Magic和Cloud Ginger XR-1等平台收集的数据,还包括Habitat、MuJoCo和SeaWave等仿真平台生成的数据。此外,它还整合了Open X-Embodiment、RH20T和ManiWAV等其他数据集的数据,进一步丰富了其多模态范围。
-
ManiSkill和ManiSkill2 Datasets:由加州大学圣地亚哥分校发布,包含3.6万条成功的操作轨迹以及150万点云和RGB-D帧,全部在仿真环境中捕获。
-
3D-VLA Dataset:包含来自Open-X Embodiment的2D数据集、包含深度信息的数据集(如Dobb-E和RH20T),以及仿真数据集(如RLBench和CALVIN)。此外,它还整合了人类-物体交互数据,包括HOI4D数据集。
-
DROID Dataset:包含7.6万条演示轨迹、564个场景和86个任务的多模态数据。
-
BridgeData V2:包含60,096条机器人轨迹样本,来自24个环境,整合了图像、深度和自然语言指令等感知模态。
-
TACO-RL Dataset:用于训练分层策略以解决长期机器人控制任务,通过在仿真和真实环境中遥操作机器人收集数据。
-
FurnitureBench Dataset:专注于测试与家具组装相关的复杂长期操作任务,强调精确抓取、路径规划和插入等技能。
-
Dexterous Hand Dataset:由苏黎世联邦理工学院(ETH Zurich)发布,包含210万视频帧、3D手部和物体网格、动态接触信息以及手部姿态和物体状态轨迹。
-
CLVR Jaco Play Dataset:包含1,085条通过遥操作的机器人剧集,涵盖多种数据模态,是训练机器人操作任务的重要资源。
4.3.具身导航数据集
具身导航数据集旨在通过视觉-语言结合指令增强机器人在物理或仿真环境中准确导航的能力。这些数据集通过提供长且复杂的路径和指令、真实世界数据、多样化室内和室外场景,支持训练高容量模型,并提供详细的中间产品(如3D场景重建、相对深度估计、物体标签和定位信息)。
-
HM3D:是最大规模的建筑级3D场景重建数据集,包含来自世界各地的多样化真实空间。HM3D提供1,000个几乎完整的高保真建筑内部空间重建,每个重建都使用Matterport Pro2三脚架深度传感器捕获,涵盖每个室内空间的可居住和可导航区域。此外,HM3D数据集与FAIR的Habitat模拟器无缝集成,支持家庭机器人和AI助手等智能体的训练和评估。
-
Gibson Environment:专为训练和测试真实世界感知智能体而设计,基于虚拟化的真实空间,而非人工设计的空间。Gibson包含572个完整建筑中的1,400多个楼面空间。其主要特点包括:源自真实世界并反映其语义复杂性;内部合成机制“Goggles”允许训练的模型无需领域适配即可部署到真实世界;智能体的具身性及其受到的物理和空间约束。
-
Matterport3D Dataset:是一个大规模的RGB-D数据集,包含来自90个建筑级场景的10,800个全景视图和194,400张RGB-D图像。该数据集提供表面重建、相机姿态以及2D和3D语义分割的标注。基于Matterport3D环境,Peter Anderson等人收集了R2R数据集,包含21,567条开放词汇、众包导航指令,平均长度为29个单词。每条指令描述了一条通常跨越多个房间的轨迹。相关任务要求智能体根据自然语言指令在之前未见过的建筑中导航到目标位置。
-
REVERIE Dataset:基于Matterport3D模拟器构建,提供详细的室内导航环境。与R2R不同,REVERIE首次引入了真实室内环境中远程物体的视觉指代表达任务。目标物体从起始点不可见,这意味着机器人必须具备常识和推理能力才能到达目标可能出现的位置。该任务旨在评估智能体根据高级自然语言指令导航和识别目标物体的能力,强调机器人对自然语言理解和视觉导航的需求。
-
ScanQA Dataset:旨在通过3D空间场景理解进行3D问答(3DQA)任务。它要求模型接收来自丰富RGB-D室内扫描的整个3D场景的视觉信息,并回答关于该3D场景的文本问题。该数据集包含来自ScanNet数据集的800个室内场景中的41k问答对。这些问答对是手动编辑的,答案与每个3D场景中的3D物体相关联。ScanQA数据集旨在通过结合语言表达和3D几何特征回答关于3D场景的问题,推动3D空间理解研究的发展。
-
LLaVA Dataset:是一个针对多模态任务的专门指令调整数据集,包含158k独特的语言-图像指令遵循样本,分为58k对话、23k详细描述和77k复杂推理。该数据集通过视觉指令调整增强模型在新任务上的零样本能力,使模型能够更好地理解和执行视觉指令。在导航应用中,LLaVA数据集可用于训练模型根据视觉和文本信息理解和执行指令,这对于具身导航任务至关重要。
-
SoundSpaces Simulator:基于Matterport3D和Replica,考虑空间和材料属性以在3D空间中渲染逼真的声音。它包含来自Matterport3D的85个场景、来自Replica的18个场景和102个版权免费的声音。为了扩展SoundSpaces模拟器,SoundSpacesv2被设计为能够泛化到新环境,并自由调整材料和麦克风配置。
挑战与未来研究
5.1.技术挑战
5.1.1.跨模态对齐
-
尽管多模态模型取得了显著进展,但在不同模态(如视觉、语言和动作)之间实现精确且高效的对齐仍然是一个基本挑战。
-
开发能够在实时环境中稳健融合和对齐这些模态的方法是当前研究的重点。
-
例如,当前的视觉-语言模型(如ReKep)和视觉-音频模型(如SoundSpaces)都依赖于有效对齐来自不同模态的数据。如果对齐不当,响应的准确性和效率可能会下降。
5.1.2.计算资源与效率
-
EMLMs需要大量的计算资源和存储空间。一个关键挑战是提高计算效率,减少能源消耗,并优化推理速度,同时保持高性能。
-
目前,大多数模型参数庞大,训练和推理过程依赖于高性能GPU,这既耗时又昂贵。
-
例如,OpenVLA模型通过仅使用70亿参数处理视觉和语言数据,展示了高效处理多种任务的能力。
-
然而,当引入更多模态(如激光雷达、音频、压力传感器、GPS等)以处理更复杂的任务时,模型大小、响应时间和相关成本往往会显著增加。
5.1.3.跨领域泛化
-
尽管多模态模型在特定基准测试或特定领域中表现出色,但它们在多样化环境或任务中的泛化能力仍然有限。
-
研究人员需要探索方法以增强这些模型在实际应用中的迁移能力和适应性。
-
例如,当前的具身大模型通常分为感知模型(如GPT系列)、交互模型(如3D-VLA)和导航模型(如SG-Nav),这些模型能够处理的任务范围相对固定,其泛化能力仍有待提高。
5.1.4.处理时间和序列信息
-
具身模型必须管理动态的实时数据和序列交互,这在处理连续动作、环境事件以及感知、推理和运动之间的时序依赖性方面提出了重大挑战。
-
在交互领域,模型通常分为短视距行动策略(如R3M)和长视距行动策略(如Palm-e)。
-
然而,在导航领域,缺乏为长期连续导航设计的模型。
5.2. 数据和标注问题
5.2.1.数据集的多样性和质量
-
现有的具身多模态任务数据集在多样性、规模和质量方面往往有限。缺乏能够捕捉动态环境中复杂多模态交互的高质量真实世界数据集,这限制了模型的有效训练。
-
未来的工作应优先开发更大规模、更多样化且标注更准确的数据集,以增强多模态模型的鲁棒性和泛化能力。
-
例如,当前的大规模数据集(如Open X-Embodiment数据集和ARIO数据集)虽然取得了显著进展,但它们主要集中在家庭任务和厨房操作等感知和交互任务上。
-
这些任务不足以支持具身智能智能体所需的全部能力。此外,这些数据集中的大多数传感器依赖于相机,限制了真实世界的感知能力。
-
为了改进这一点,必须整合更多的多模态传感器(如激光雷达、声音传感器、雷达、力传感器和GPS),以扩展可用数据的范围。
5.2.2.真实世界的动态数据
-
在具身任务中,如机器人技术和自主系统,获取真实世界环境中的数据是具有挑战性的,因为物理环境的不可预测性。
-
为了确保这些模型在真实世界场景中的实际适用性,它们必须在能够反映动态非静态环境的数据上进行训练。
5.3.应用和伦理考量
5.3.1.自动驾驶和机器人技术
-
随着具身多模态模型在自动驾驶、机器人技术和人机交互中的应用,确保其安全性、可靠性和伦理合规性至关重要。
-
需要解决实时决策、模型输出的可解释性以及自主系统中风险缓解的挑战。
5.3.2.伦理和偏见问题
-
多模态模型可能会无意中继承训练数据中存在的偏见,从而导致不公平或歧视性结果。
-
开发能够确保决策过程中的公平性、透明度和问责制的方法是解决这些伦理问题的关键。
5.4.未来研究方向
5.4.1.跨模态预训练和微调
未来的研究应探索更高效的跨模态预训练和微调策略,使模型能够在不需要大量重新训练的情况下,在感知到决策制定的多种任务中表现出色。
5.4.2.自监督学习
自监督学习技术的发展将是减少对大规模标注数据依赖的关键。通过利用未标注数据,模型可以学习更丰富的表示,使其更具适应性和可扩展性。
5.4.3.与多模态强化学习的整合
将多模态模型与强化学习相结合是一个有前景的方向。通过整合感知、行动和反馈循环,具身智能体可以在动态的真实世界环境中不断改进和适应其行为。
5.4.4.端到端大模型
目前,针对不同任务(如感知、导航和交互)设计了各种大模型。然而,未来的发展趋势是朝着端到端大模型方向发展,即一个模型处理从输入指令到执行最终任务的整个过程。这种方法简化了流程,提高了效率。
6.总结
-
论文系统地回顾了具身多模态大模型的发展,分析了基础大模型的技术进步及其在具身任务中的应用。
-
通过分析多个数据集的影响,识别了高质量数据在模型性能提升中的重要性。
-
尽管EMLMs在多个领域取得了显著进展,但仍需解决跨模态对齐、计算资源效率和泛化能力等挑战。
-
未来的研究应关注跨模态预训练和自监督学习,以实现更高效、更灵活的具身智能系统。
-
本文的研究为EMLMs的未来发展提供了有价值的参考和启示。


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 20
20 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)