【AI论文】Agent-R:通过迭代自训练训练语言模型代理以进行自我反思
Agent-R的提出在本文中,我们提出了一种迭代自训练框架Agent-R,旨在使语言代理能够即时进行自我反思和错误纠正。Agent-R通过利用蒙特卡洛树搜索(MCTS)构建训练数据,从错误轨迹中恢复出正确轨迹,从而赋予代理智能代理能力。Agent-R的核心思想Agent-R不同于传统方法,它不是基于动作的正确性进行奖励或惩罚,而是通过模拟和反思来构建训练数据。该框架的核心在于通过迭代的方式不断提升
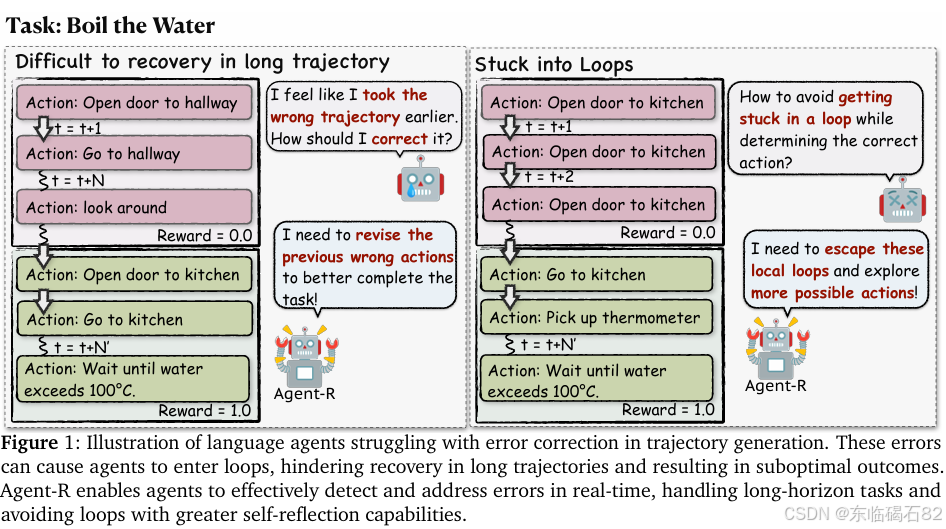
摘要:大型语言模型(LLM)代理在解决交互环境中的复杂任务方面日益发挥着关键作用。现有工作主要集中在通过从更强大的专家那里进行行为克隆来提高性能,然而这种方法在实际应用中往往表现不佳,主要原因在于其无法从错误中恢复。然而,步骤级别的评价数据难以收集且成本高昂。因此,自动化和动态构建自我批评数据集对于赋予模型智能代理能力至关重要。在本文中,我们提出了一种迭代自训练框架Agent-R,使语言代理能够即时进行自我反思。不同于传统方法根据动作的正确性进行奖励或惩罚,Agent-R利用蒙特卡洛树搜索(MCTS)构建训练数据,从错误轨迹中恢复出正确轨迹。代理反思的一个关键挑战在于需要及时修正,而不是等到整个轨迹结束后才进行。为了解决这一问题,我们引入了一种模型引导的评价构建机制:执行模型在失败轨迹中识别出第一个错误步骤(在其当前能力范围内)。从该步骤开始,我们将其与树中具有相同父节点的相邻正确路径进行拼接。这种策略使模型能够基于其当前策略学习反思,从而提高学习效率。为了进一步探索这种自我改进范式的可扩展性,我们研究了错误纠正能力和数据集构建的迭代精炼。我们的研究结果表明,Agent-R能够持续提升模型从错误中恢复的能力,并实现及时的错误纠正。在三个交互环境上的实验表明,Agent-R有效地使代理能够纠正错误动作并避免循环,与基线方法相比取得了更优的性能(+5.59%)。Huggingface链接:Paper page ,论文链接:2501.11425
1. 引言
大型语言模型(LLMs)的重要性:
- 大型语言模型(LLMs)在解决交互环境中的复杂任务方面日益发挥着关键作用。这些基于LLM的代理被广泛应用于需要自主决策、错误纠正和任务优化的场景中。
- 随着技术的不断进步,LLMs在处理自然语言任务方面展现出强大的能力,如对话系统、知识问答和文本生成等。
现有方法的局限性:
- 现有工作主要集中在通过从更强大的专家那里进行行为克隆来提高性能。然而,这种方法在实际应用中往往表现不佳,主要原因在于其无法从错误中恢复。
- 例如,在复杂的交互环境中,代理可能会遇到多种未知情况,而仅仅依赖行为克隆无法使代理具备足够的泛化能力来应对这些未知情况。
自我批评数据集的重要性:
- 步骤级别的评价数据对于训练能够自我纠正错误的代理至关重要,但这种数据难以收集且成本高昂。
- 传统的数据收集方法往往依赖于人工标注,这不仅耗时耗力,而且难以保证数据的多样性和准确性。
2. Agent-R框架概述
Agent-R的提出:
- 在本文中,我们提出了一种迭代自训练框架Agent-R,旨在使语言代理能够即时进行自我反思和错误纠正。
- Agent-R通过利用蒙特卡洛树搜索(MCTS)构建训练数据,从错误轨迹中恢复出正确轨迹,从而赋予代理智能代理能力。
Agent-R的核心思想:
- Agent-R不同于传统方法,它不是基于动作的正确性进行奖励或惩罚,而是通过模拟和反思来构建训练数据。
- 该框架的核心在于通过迭代的方式不断提升代理的错误纠正能力,使其能够在交互环境中更好地完成任务。
3. 方法论
3.1 阶段一:模型引导的反思轨迹生成
轨迹定义:
- 我们首先定义了四种类型的轨迹:初始轨迹、错误轨迹、正确轨迹和修正轨迹。
- 初始轨迹:用户提供的指令对应的初始动作和观察序列。
- 错误轨迹:在初始轨迹的基础上执行一系列次优动作导致的错误结果。
- 正确轨迹:在初始轨迹的基础上执行一系列最优或高奖励动作导致的正确结果。
- 修正轨迹:通过拼接错误轨迹中的部分与正确轨迹中的部分来构建的轨迹,用于训练代理的错误纠正能力。
利用MCTS收集轨迹:
- 我们使用蒙特卡洛树搜索(MCTS)来高效地探索轨迹空间,收集修正轨迹。
- MCTS通过选择、扩展、模拟和反向传播四个阶段来构建决策树,并基于模拟结果估计动作的价值。
过渡点确定:
- 我们提出了一种模型引导的批评构建机制,即执行模型在失败轨迹中识别出第一个错误步骤(在其当前能力范围内)。
- 从该错误步骤开始,我们将错误轨迹与具有相同父节点的相邻正确路径进行拼接,构建修正轨迹。
3.2 阶段二:使用修正轨迹的迭代自训练
混合训练策略:
- 在训练阶段,我们将修正轨迹与正确轨迹进行混合,以避免冷启动问题。
- 通过逐渐增加修正轨迹在训练数据中的比例,代理能够逐步提升其错误纠正能力。
迭代精炼:
- 我们对错误纠正能力和数据集构建过程进行了迭代精炼。在每次迭代中,我们重新收集基于当前执行模型的修正轨迹,并进行监督微调(SFT)。
- 这种迭代方式使代理能够从自己的错误中学习,并不断提升其性能。
4. 实验与结果
4.1 交互环境:
- 我们选择了三个具有代表性的交互环境进行实验:WebShop、ScienceWorld和TextCraft。
- WebShop:一个在线购物环境,代理需要执行点击、搜索等操作来完成购物任务。
- ScienceWorld:一个基于文本的科学推理环境,代理需要解决各种科学问题。
- TextCraft:一个基于文本的Minecraft物品制作环境,代理需要根据给定的配方制作物品。
4.2 实验设置:
- 我们使用AgentGym作为实验平台,并在每个环境中随机采样一定数量的模拟来进行MCTS。
- 我们设置了不同的迭代次数(如三次迭代),并在每次迭代中调整训练设置(如学习率、批次大小等)。
4.3 主要结果:
- 实验结果表明,Agent-R在三个交互环境上都显著提高了代理的性能。与基线方法相比,Agent-R的性能提升了+5.59%。
- 具体来说,Agent-R使代理能够更有效地纠正错误动作并避免循环,从而实现了更优的任务完成度。
5. 分析与讨论
修正轨迹的有效性:
- 通过对比实验,我们发现使用修正轨迹进行训练的代理在错误纠正能力上明显优于使用最优轨迹进行训练的代理。
- 这表明修正轨迹中包含的错误纠正信息对于提升代理的性能至关重要。
及时修正的重要性:
- Agent-R通过模型引导的批评构建机制实现了及时的错误修正,这有助于代理在交互环境中更好地应对未知情况。
- 相比之下,传统的基于结果正确性的奖励或惩罚方法往往难以做到及时的错误修正。
迭代精炼的效果:
- 通过迭代精炼错误纠正能力和数据集构建过程,Agent-R使代理能够不断提升其性能。
- 这种迭代方式不仅提高了代理的错误纠正能力,还使其能够更好地泛化到新的环境中。
6. 相关工作
代理学习在交互环境中的方法:
- 现有工作主要集中在三种策略上:基于提示的策略、推理时间搜索策略和基于训练的策略。
- 基于提示的策略使用人类编写的提示来引导LLMs进行总结和推理。
- 推理时间搜索策略使用各种搜索算法(如Tree-of-Thought和MCTS)来在推理过程中识别最优轨迹。
- 基于训练的策略使用监督微调(SFT)或直接偏好优化(DPO)来训练LLMs。
大型语言模型的自我纠正:
- 现有研究表明,大型语言模型在自我纠正方面表现不佳。一些方法依赖于提示工程或人类标注的数据来进行自我纠正,但这些方法往往难以取得显著的效果。
- Agent-R通过自动化和动态构建自我批评数据集来赋予代理智能代理能力,为解决这一问题提供了新的思路。
7. 结论
在本文中,我们提出了一种迭代自训练框架Agent-R,用于训练语言模型代理在交互环境中进行即时反思和自我纠正。通过利用蒙特卡洛树搜索构建修正轨迹,Agent-R使代理能够从错误中学习并不断提升其性能。实验结果表明,Agent-R在三个交互环境上都显著提高了代理的性能,并实现了更优的任务完成度。未来工作将进一步探索Agent-R的可扩展性和泛化能力,并尝试将其应用于更复杂的交互环境中。
8. 展望
进一步提升性能:
- 我们可以尝试引入更复杂的搜索算法或训练策略来进一步提升Agent-R的性能。
- 同时,结合其他技术(如知识蒸馏、迁移学习等)也可能为Agent-R带来额外的性能提升。
拓展应用场景:
- Agent-R具有广泛的应用前景,如机器人控制、智能客服、教育辅导等。
- 未来工作将尝试将Agent-R应用于这些领域,并探索其在不同场景下的表现。
研究代理的智能行为:
- 除了错误纠正能力外,我们还可以进一步研究代理的智能行为,如决策制定、计划执行等。
- 通过分析代理在不同任务中的行为模式,我们可以更深入地理解其工作原理,并为未来的研究提供有益的参考。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 20
20 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)