TheoremExplainAgent:AI 驱动的数学与科学教学动画
TheoremExplainAgent[2](简称 TEA)是由 TIGER AI Lab 开发的一款 AI 多智能体,专门设计用于将复杂的数学和科学定理转化为易于理解的 Manim 教学动画,每段动画时长能超过 5 分钟。唯一的不同就是处理 Manim Scene 时,TEA 是动态的(不可控),而小视频宝是范式的。(简称 TEA)是由 TIGER AI Lab 开发的一款 AI 多智能体,专门
TheoremExplainAgent:AI 驱动的数学与科学教学动画
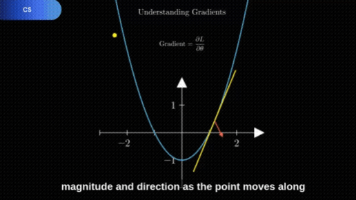
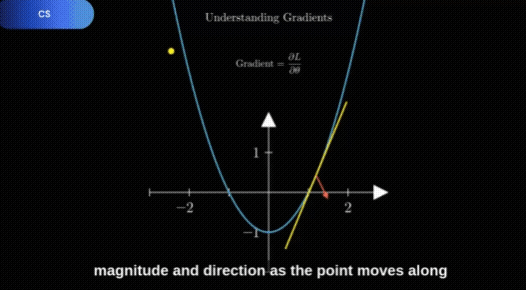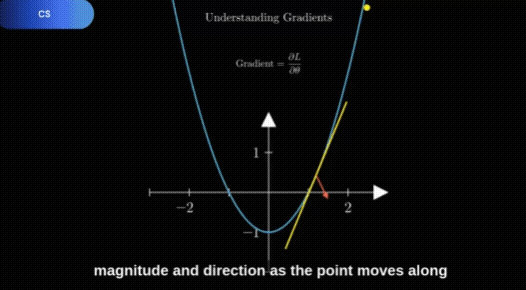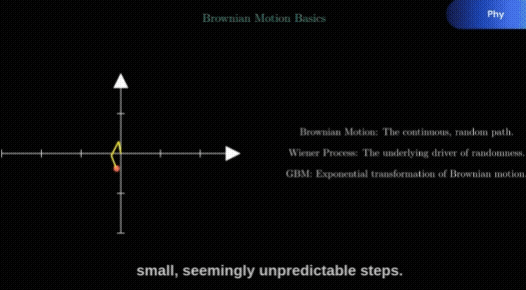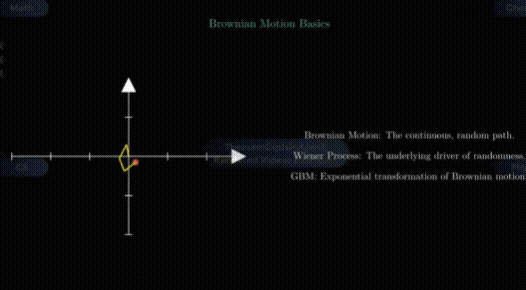 TheoremExplainAgent[2](简称 TEA)是由 TIGER AI Lab 开发的一款 AI 多智能体,专门设计用于将复杂的数学和科学定理转化为易于理解的 Manim 教学动画,每段动画时长能超过 5 分钟。
TheoremExplainAgent[2](简称 TEA)是由 TIGER AI Lab 开发的一款 AI 多智能体,专门设计用于将复杂的数学和科学定理转化为易于理解的 Manim 教学动画,每段动画时长能超过 5 分钟。
TEA 背后结合了大语言模型(LLM)的推理能力、Manim 动画技术以及语音合成技术。
这个项目和三花的小视频宝的原理差不多,同样也是大模型 + Manim + TTS 哎!唯一的不同就是处理 Manim Scene 时,TEA 是动态的(不可控),而小视频宝是范式的。
我加的几个 Manim 群表示天塌了,哈哈哈。
DiffRhythm 谛韵: 开源音乐生成模型

DiffRhythm,中文名谛韵,是由西北工业大学音频、语音与语言处理研究组(ASLP Lab)开发的一种 AI 音乐生成模型。
作为全球首个基于潜在扩散技术(Latent Diffusion)的端到端完整歌曲生成模型,DiffRhythm 只需要 8GB VRAM 就能在 10 到 12 秒内生成一首完整歌曲,目前仅支持中英文。
DiffRhythm 能够一次性生成包含人声和伴奏的完整歌曲,就像 Suno 和 Udio 一样,最长能生成 4 分 45 秒的完整歌曲。
最关键的是,DiffRhythm 完全开源,佬们可以在HF上在线体验[1]玩玩看
LTX-Video 0.9.5:开源可商用视频生成模型

TheoremExplainAgent(简称 TEA)是由 TIGER AI Lab 开发的一款 AI 多智能体,专门设计用于将复杂的数学和科学定理转化为易于理解的 Manim 教学动画,每段动画时长能超过 5 分钟。
TEA 背后结合了大语言模型(LLM)的推理能力、Manim 动画技术以及语音合成技术。
这个项目和三花的小视频宝的原理差不多,同样也是大模型 + Manim + TTS 哎!唯一的不同就是处理 Manim Scene 时,TEA 是动态的(不可控),而小视频宝是范式的。
我加的几个 Manim 群表示天塌了,哈哈哈。
ComfyUI-Pruna:无损加速 Stable Diffusion 和 Flux 模型推理

ComfyUI-Pruna[5] 提供了一个ComfyUI的自定义编译节点,能够显著加速 Stable Diffusion(SD)和 Flux 模型的推理过程,同时保持输出质量基本不变。
官方基准测试显示,使用 Pruna 的 “x-fast” 和 “torch_compile” 编译模式,每秒迭代次数(IPS)得到了显著提升,尤其是对 SD 的加速效果尤为明显。
看着还是非常的强,不知道质量影响有多大,有需要的不要错过
谷歌推出基于 Gemini 2.0 的 AI Mode 测试版

Google 在其搜索中引入了两项重要的 AI 功能升级:AI Overviews 的扩展和新的 AI Mode 测试版。
AI Overviews 相信大家在搜索时会经常碰到,而 AI Mode 是基于 Gemini 2.0 的定制版本,有点类似 Deep Research,能够通过更高级的推理、思考和多模态能力帮助用户解决搜索问题。
目前,AI Mode 还在实验阶段,你可以在Google Lab[6]中申请体验。
我的号提示“您的账号目前无法使用搜索实验室”,佬们可以试试
阿里开源 QwQ-32B:320 亿参数推理模型,性能媲美 DeepSeek-R1

阿里开源了其最新的 QwQ-32B 推理模型,这是一款拥有 320 亿参数的先进模型。
QwQ-32B 的性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相媲美,采用了 Apache 2.0 开源协议。
更多详情可以查看官方博客[7],现在已经可以在QwenChat[8]上体验这一模型了。

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)