
谷歌放大招推出Gemini 2.0,AI模型进入Agentic时代!
项目名称愿景主要能力性能/测试阶段备注🚀通用 AI 助手,实时理解和响应周围环境• 增强的多语言对话能力• 工具使用 (Google 搜索、Lens、地图)• 增强的记忆力 (长达 10 分钟会话记忆)• 接近人类对话的低延迟📱 Android 设备测试中原型眼镜测试阶段🌊在浏览器中充当用户代理,自动化执行复杂任务• 理解网页内容 (像素和 Web 元素)• 通过实验性 Chrome 扩展程
和OpenAI今天不痛不痒的更新相比,谷歌这次明显来的更猛烈一些。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
北美时间12月11日,谷歌不那么高调地(和OpenAI相比)接连发布多项更新,其中包括推出新一代系列模型Gemini 2.0,其中Gemini 2.0 Flash作为该系列的首发模型,主打一个“又快又强”,在保持1.5 Flash快速响应的同时,性能进一步提升,甚至在部分基准测试中超越了1.5 Pro。
同时,谷歌今天官宣了三个AI Agent助手的研究原型:通用助手Project Astra,浏览器助手Project Mariner,以及代码助手Jules,旨在引领AI模型进入“Agentic 时代”。
要知道,就在几天前谷歌DeepMind团队才刚刚发布了目前在LMSYS聊天机器人排行榜(Chatbot Arena Leaderboard)排名第一的新版实验模型Gemini-exp-1206。
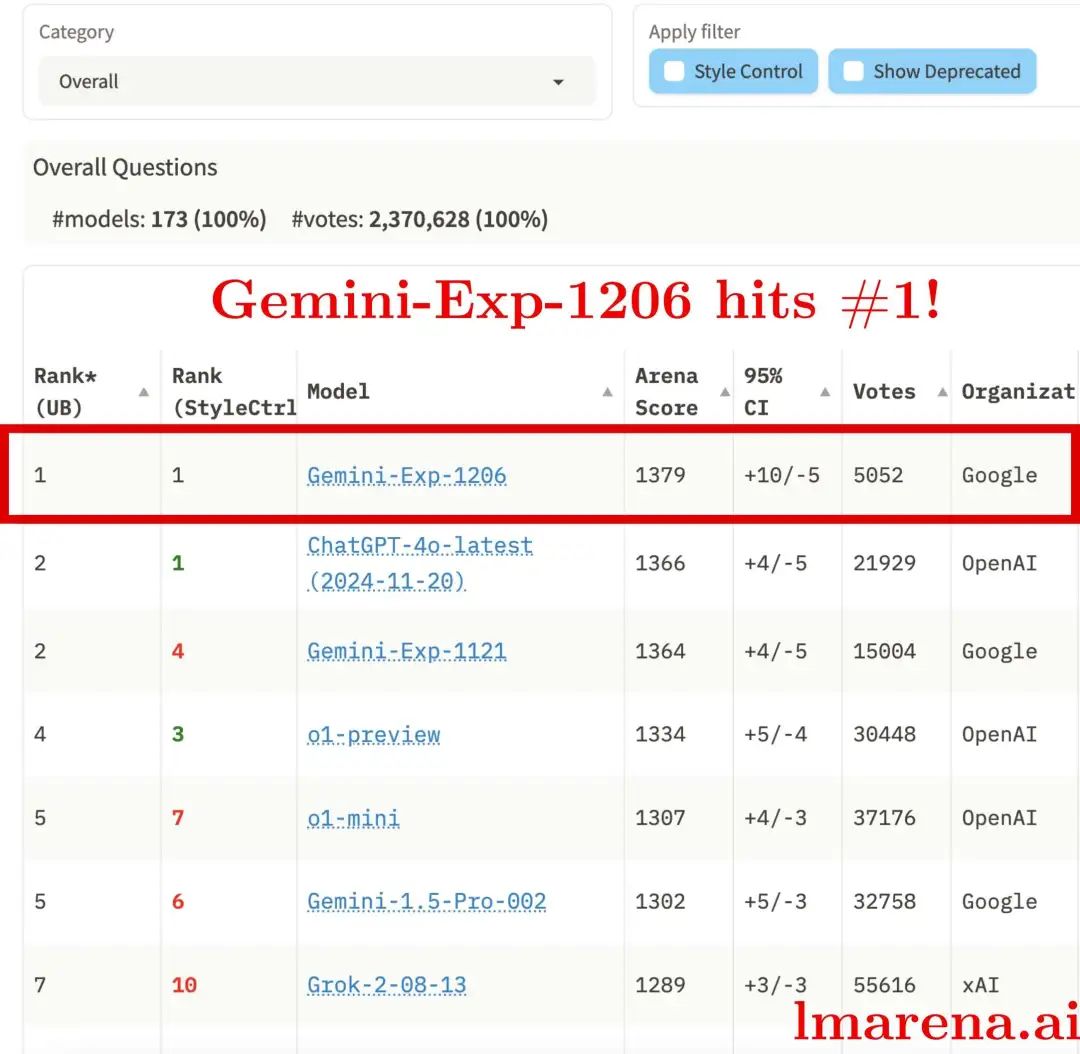
Gemini 2.0
“our new AI model for the agentic era”,这是谷歌给Gemini 2.0系列模型的slogan,也是谷歌发布说明的标题。
Gemini 2.0被定位为目前最强大的模型(此处应该加上个之一),旨在引领AI进入“Agentic 时代”,即AI不仅能理解信息,更能主动行动,像助手一样帮助人类完成任务。
Gemini 2.0系列的首发模型为Gemini 2.0 Flash,和上一代一样,Flash版本都是强调低延迟和高性能,追求的是速度和性能的平衡。而最新的Gemini 2.0 Flash不仅保持了1.5 Flash的快速响应能力,同时性能进一步提升,甚至在一些基准测试上超越了1.5 Pro。
详细的基准测试对比如下。
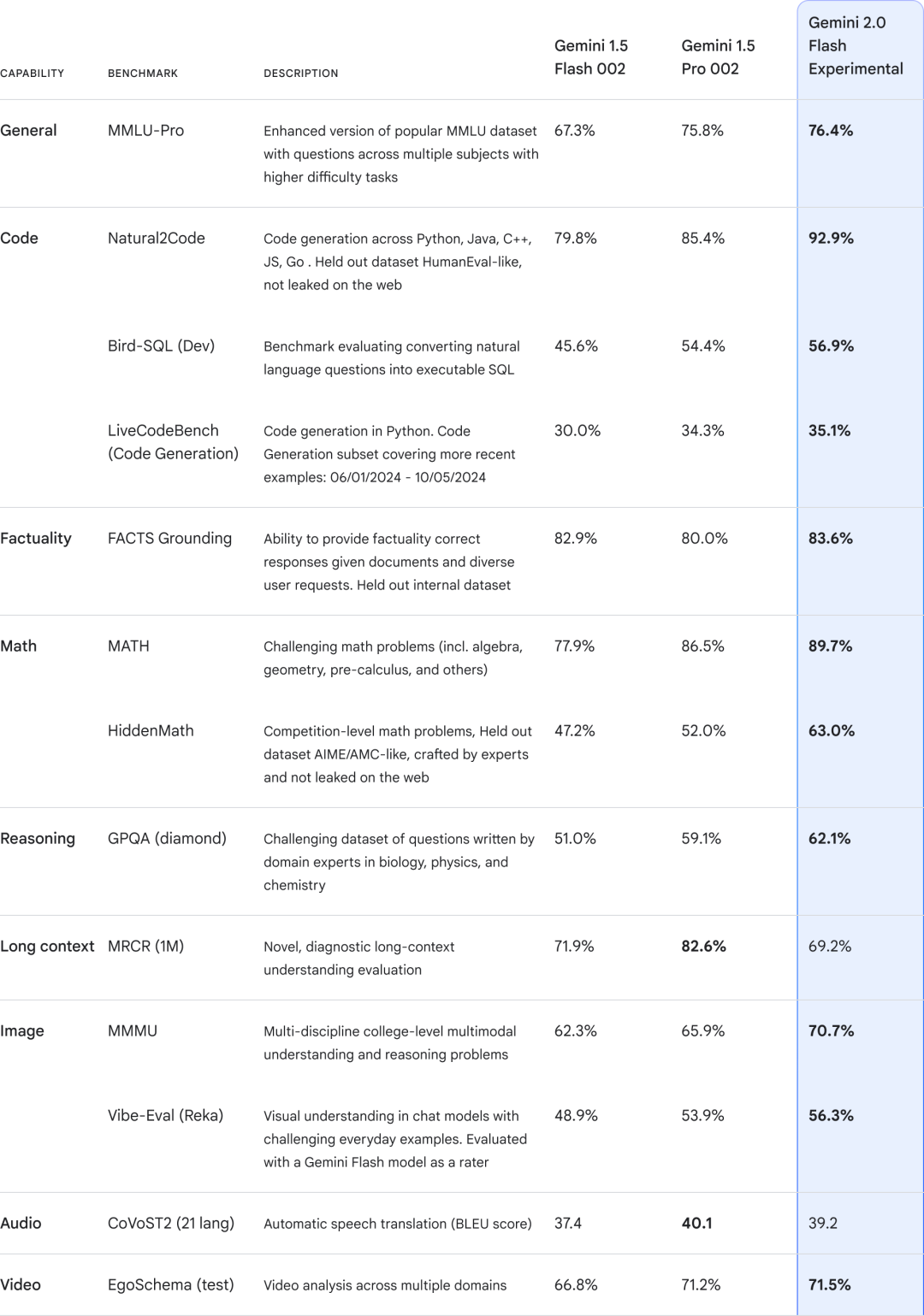
多模态输入输出
除了文本,Gemini 2.0 Flash现在支持图像、视频和音频作为输入,并能生成包含文本的图像和多语言文本转语音(TTS)音频作为输出。别的不说,单支持视频输入这一项,在AI模型领域可谓是独一份了吧。
原生工具调用
Gemini 2.0 Flash可直接调用Google搜索、代码执行以及第三方用户定义的函数,实用性大大增强。
可用性
Gemini 2.0 Flash已在谷歌Gemini应用中可用。
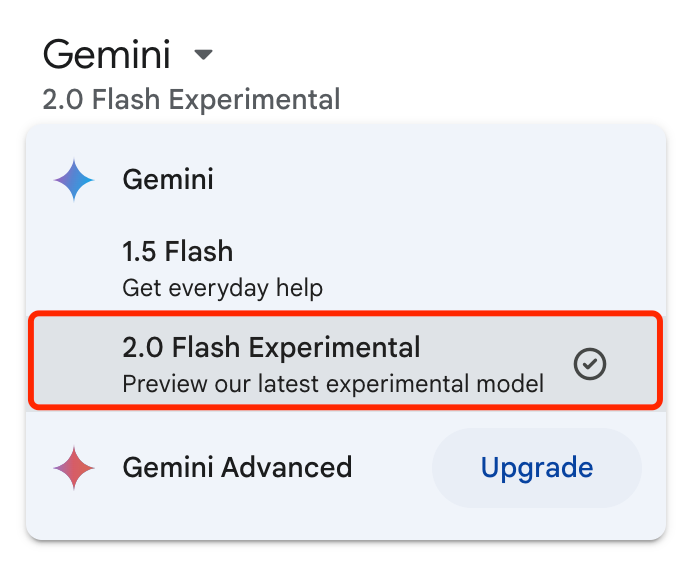
同时,和其他实验版本的模型一样,Gemini 2.0 Flash也已向开发者开放,通过谷歌AI Studio和Vertex AI的Gemini API提供。多模态输入和文本输出对所有开发者开放,而图像生成和TTS则面向早期合作伙伴。计划于明年1月全面开放,并推出更多模型尺寸。
值得一提的是,谷歌AI Studio今天也迎来了大更新,从UI到模型再到功能,并且全部都是免费可用,这里不得不夸一句谷歌“大善人”啊。
Agentic时代:AI的主动性和行动力
何为Agentic模型?
Agentic模型是指能够更好地理解周围世界,进行多步推理,并在用户监督下代表用户采取行动的AI模型。简单来说,就是AI不再是被动的工具,而是能够理解我们周围的环境,像一个真正的助手那样,进行多步推理,甚至在你的监督下,主动帮你去搞定一些事情。
如果说之前的AI模型还停留在“你问我答”的阶段,那么以Gemini 2.0为代表的新一代模型,则体现了谷歌对于AI Agent领域的野心:原生的用户界面操作能力(像人一样去操作你的电脑界面)、多模态推理(文字、图片、视频、声音)、长上下文理解、复杂指令遵循和规划、组合函数调用、原生工具使用(直接调用Google搜索、代码执行等工具)以及更低的延迟。

谷歌AI Agent研究原型总结
| 项目名称 | 愿景 | 主要能力 | 性能/测试阶段 | 备注 |
|---|---|---|---|---|
| 🚀 Project Astra | 通用 AI 助手,实时理解和响应周围环境 | • 增强的多语言对话能力 | ||
| • 工具使用 (Google 搜索、Lens、地图) | ||||
| • 增强的记忆力 (长达 10 分钟会话记忆) | ||||
| • 接近人类对话的低延迟 | 📱 Android 设备测试中 | |||
| 原型眼镜测试阶段 | ||||
| 🌊 Project Mariner | 在浏览器中充当用户代理,自动化执行复杂任务 | • 理解网页内容 (像素和 Web 元素) | ||
| • 通过实验性 Chrome 扩展程序执行操作 | ||||
| • 自动化操作执行与安全保障 | WebVoyager 测试:83.5% | |||
| 敏感操作需用户确认 | ||||
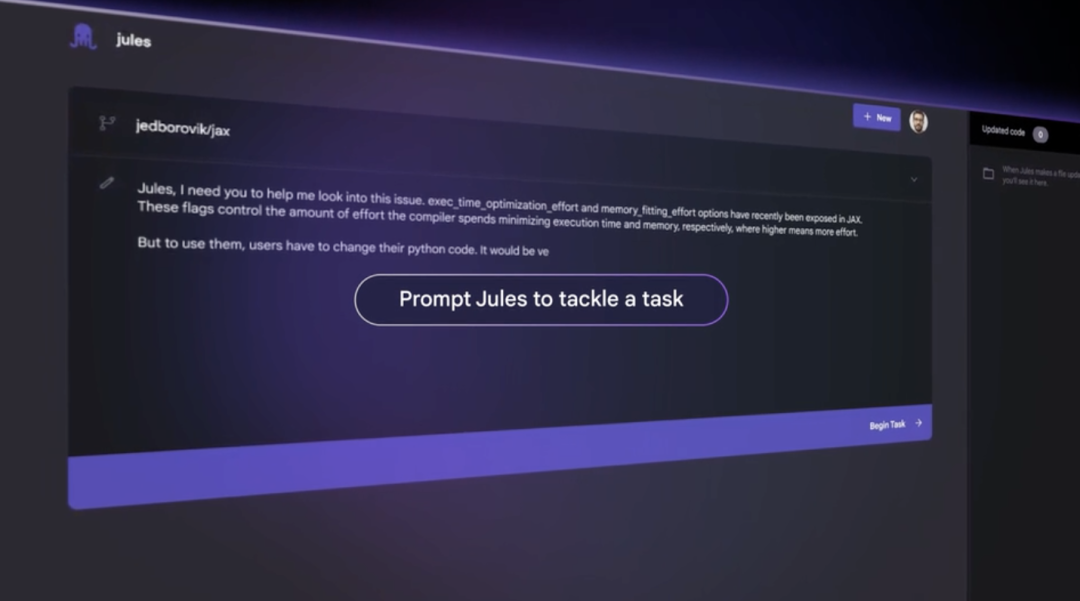
| 💻 Jules | 面向开发者的 AI 代码代理,协助代码开发 | • GitHub 工作流程集成 | ||
| • 理解问题、制定计划 | ||||
| • 自动代码执行与优化 | ||||
| 构建通用 AI 代理的重要组成部分 | ||||
| 🎮 游戏中的代理 | 基于 Gemini 2.0,提供游戏辅助 | • 理解游戏规则和机制 | ||
| • 提供实时策略建议 | ||||
| • 连接网络游戏知识库 | 正在与 Supercell 等开发商合作测试 | |||
| 🤖 机器人领域探索 | 将 Gemini 2.0 的空间推理能力应用于机器人技术 | • 空间感知与推理能力 | ||
| • 物理环境交互能力 | 早期研究阶段 | |||
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)