AI大模型开发实战:基于LangGraph、Ollama构建本地AI智能体
LangGraph 是一个强大的库,用于使用大型语言模型(LLM)构建有状态、多参与者应用程序。它有助于创建涉及单个或多个智能体的复杂工作流程,提供循环、可控性和持久性等关键优势。优势:循环和分支:与使用简单有向无环图(DAG)的其他框架不同,LangGraph 支持循环和条件语句,这对于创建复杂的智能体行为至关重要。细粒度控制:作为一个低级框架,LangGraph 提供了对应用程序流程和状态的详
前言
AI 智能体(Agent)的开发和部署被认为将重塑企业的运营方式,提升用户体验,并自动化复杂任务。AI智能体在我们智能应用产品中也涉及很多应用。
一、理解 AI 智能体
AI 智能体是能够感知其环境并采取行动以实现特定目标的实体或系统。这些智能体可以从简单的算法到能够进行复杂决策的复杂系统。
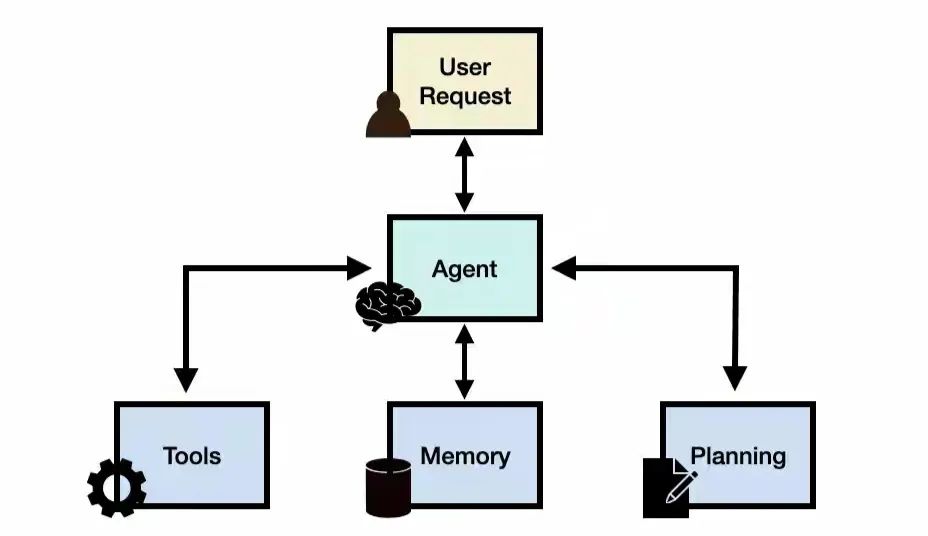
以下是关于 AI 智能体的一些关键点:
(1)感知(Perception):AI 智能体使用传感器或输入机制来感知其环境。这可能涉及从各种来源收集数据,如摄像头、麦克风或其他传感器。
(2)推理(Reasoning):AI 智能体接收信息,并使用算法和模型来处理和解释数据。这一步涉及理解模式、进行预测或生成响应。
(3)决策制定(Decision-making):像人类一样,AI 智能体根据其感知和推理来决定行动或输出。这些决策旨在实现其编程或学习过程中定义的特定目标或目的。此外,AI 智能体将更多地作为助手而不是取代人类。
(4)执行(Action):AI 智能体根据其决策执行行动。这可能涉及现实世界中的身体动作(如移动机器人臂)或数字环境中的虚拟动作(如在应用程序中提出建议)。
二、AI 智能体与 RAG 应用的区别
RAG(检索增强生成)应用和 AI 智能体指的是人工智能领域内的两个不同概念。
RAG 通过结合信息检索方法来提高大型语言模型(LLM)的性能或输出。检索系统根据输入查询从大型语料库中搜索相关文档或信息。然后,生成模型(例如基于 Transformer 的语言模型)使用这些检索到的信息生成更准确和上下文相关的响应。这有助于通过整合检索到的信息来提高生成内容的准确性。此外,这种技术消除了对新数据进行微调或训练 LLM 的需求。
另一方面,AI 智能体是设计用来执行特定任务或一系列任务的自治软件实体。它们基于预定义的规则、机器学习模型或两者结合来运行。它们通常与用户或其他系统交互,以收集输入、提供响应或执行动作。一些 AI 智能体的性能随着时间的推移而提高,因为它们可以根据新数据和经验学习和适应。AI 可以同时处理多个任务,提供可扩展性。
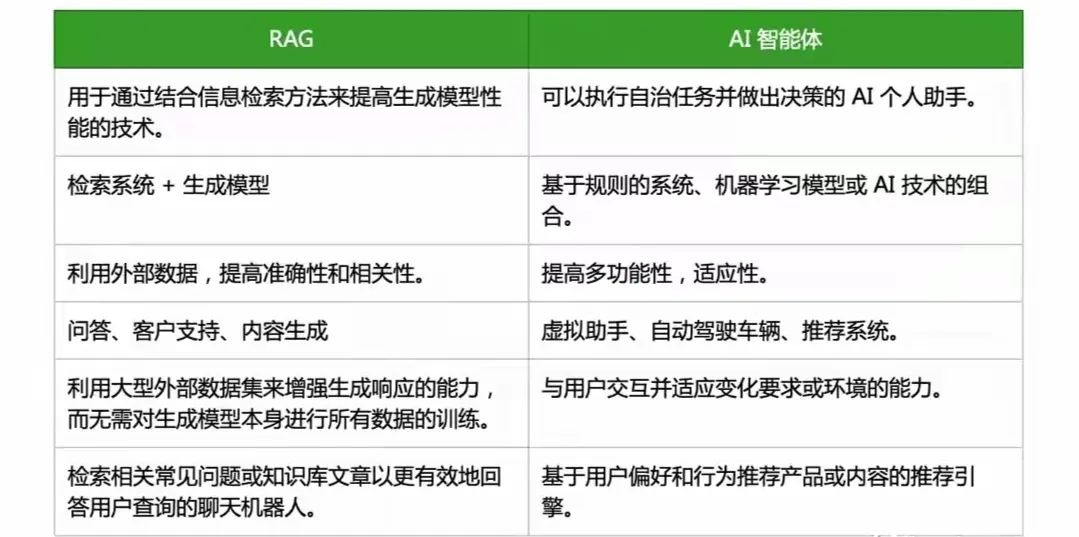
总之,RAG应用是专门设计用于通过结合检索机制来增强生成模型的能力;智能体是更广泛的实体,旨在自主执行各种任务。

三、LangGraph 简介
LangGraph 是一个强大的库,用于使用大型语言模型(LLM)构建有状态、多参与者应用程序。它有助于创建涉及单个或多个智能体的复杂工作流程,提供循环、可控性和持久性等关键优势。
优势:
-
循环和分支:与使用简单有向无环图(DAG)的其他框架不同,LangGraph 支持循环和条件语句,这对于创建复杂的智能体行为至关重要。
-
细粒度控制:作为一个低级框架,LangGraph 提供了对应用程序流程和状态的详细控制,使其成为开发可靠智能体的理想选择。
-
持久性:它包括内置的持久性,允许你在每个步骤后保存状态,暂停和恢复执行,并支持高级功能,如错误恢复和人工干预的工作流程。
特点:
-
循环和分支:在你的应用程序中实现循环和条件语句。
-
持久性:在每个步骤后自动保存状态,支持错误恢复。
-
人工干预:中断执行以供人工批准或编辑。
-
流式支持:每个节点生成输出时即时流式传输。
-
与LangChain集成:与LangChain和LangSmith无缝集成,也可以独立使用。
四、Ollama 简介
Ollama 是一个开源项目,它使在本地机器上运行大型语言模型(LLM)变得简单且用户友好。它提供了一个用户友好的平台,简化了 LLM 技术的复杂性,使其易于访问和定制,适用于希望利用 AI 力量而无需广泛的技术专业知识的用户。它易于安装。此外,我们有一系列模型和一套全面的功能和功能,旨在增强用户体验。

关键特点:
-
本地部署:直接在本地机器上运行复杂的 LLM,确保数据隐私并减少对外部服务器的依赖。
-
用户友好的界面:设计直观易用,适用于不同技术水平的用户。
-
可定制性:微调 AI 模型以满足您的特定需求,无论是研究、开发还是个人项目。
-
开源:作为开源项目,Ollama 鼓励社区贡献和持续改进,促进创新和协作。
-
轻松安装:Ollama 以其用户友好的安装过程脱颖而出,为 Windows、macOS 和 Linux 用户提供直观、无忧的设置方法。
五、使用 LangGraph 和 Ollama 创建 AI 智能体的步骤
在这个案例中,我们将使用qwen2:7b 模型创建一个简单的智能体示例。这个智能体可以使用 Tavily 搜索 API 搜索网络并生成响应。
我们将从安装 Langgraph 开始,这是一个设计用于使用 LLM 构建有状态、多参与者应用程序的库,非常适合创建智能体和多智能体工作流程。LangGraph 受到 Pregel、Apache Beam 和 NetworkX 的启发,由 LangChain Inc. 开发,可以独立于 LangChain 使用。
我们将使用qwen2:7b 作为我们的 LLM 模型,该模型将与 Ollama 和 Tavily 的搜索 API 集成。Tavily 的 API 针对 LLM 进行了优化,提供了事实性、高效、持久的搜索体验。
开始安装langgraph包:
``pip install -U langgraph``
如有需要,安装其他包:
pip install langchain-openai langchainhub
完成安装后,我们将进入下一个关键步骤:提供 Travily API 密钥。
注册 Travily 并生成 API 密钥。
export TAVILY_API_KEY="apikeygoeshere"
现在,我们将运行以下代码来获取模型。请尝试使用 Llama 或任何其他版本的
qwen2:7b。
ollama pull qwen2:7b
导入构建智能体所需的所有必要库。
from langchain import hub
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.prompts import PromptTemplate
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_community.chat_models
import ChatOllama
我们将首先定义我们想要使用的工具,并将工具与 llm 绑定。在这个简单的例子中,我们将使用通过 Tavily 提供的内置搜索工具。
示例代码如下所示:
import os
# 设置环境变量"TAVILY_API_KEY",将其值设为一个API密钥字符串
# 这个密钥用于认证和授权应用程序访问Tavily API的服务
# 通过将API密钥存储在环境变量中,可以提高代码的安全性和可维护性,避免硬编码敏感信息
os.environ["TAVILY_API_KEY"] = "tvly-xxxxxxxxxx"
# 初始化ChatOpenAI实例,设置以下参数:
# model参数指定使用的语言模型为"qwen2:7b"
# temperature参数设置为0.0,这意味着生成的响应将更加确定和基于模型的知识,减少随机性
# api_key参数设置为"ollama"
# base_url参数指定了与模型交互的API基础URL,此处指向本地主机上的一个特定端口和路径
llm = ChatOpenAI(model="qwen2:7b", temperature=0.0, api_key="ollama", base_url="http://localhost:11434/v1")
# 创建工具列表,其中包含一个TavilySearchResults实例,用于执行搜索操作
# max_results参数设置为3,这意味着每次搜索将返回最多3个结果
tools = [TavilySearchResults(max_results=3)]
下面的代码片段检索一个提示模板并以可读格式打印。然后可以根据需要使用或修改此模板。
# 从LangChain的Hub中拉取一个预定义的prompt模板
prompt = hub.pull("wfh/react-agent-executor")
# 使用pretty_print()方法以更易读的格式打印模板内容
prompt.pretty_print()
使用前面创建的语言模型(llm)、一组工具(tools)和一个提示模板(prompt)创建一个智能体(agent)。
# 创建agent对象
agent = create_react_agent(llm, tools, messages_modifier=prompt)
from IPython.display import Image, display
# agent.get_graph()方法返回代理的内部状态图,描述了代理的组件和它们之间的关系
# draw_mermaid_png()方法将状态图转换为PNG格式的图像,便于可视化展示
display(Image(agent.get_graph().draw_mermaid_png()))
这段代码的作用是在Jupyter Notebook中显示智能体的结构和工作流程图,帮助理解和调试智能体的行为。
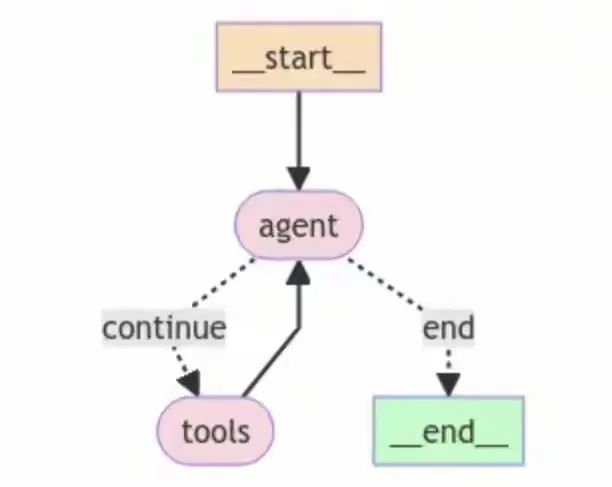
agent 节点会使用消息列表调用语言模型。如果生成的 AIMessage 包含 tool_calls,则图将调用 tools 节点。tools 节点执行工具(每个 tool_call 执行一个工具),并将响应作为 ToolMessage 对象添加到消息列表中。然后 agent 节点再次调用语言模型。这个过程会一直重复,直到响应中不再有 tool_calls。然后 agent 返回包含键 “messages” 的字典,其中包含了完整的消息列表。
# 调用agent的invoke方法
response = agent.invoke({"messages": [("user", "解释人工智能")]})
# 遍历响应字典中'messages'键对应的列表,该列表包含了代理生成的响应消息
for message in response['messages']:
print(message.content)
生成如下响应:

最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 16
16 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)