UCB CS194/294-196 (LLM Agents) Lecture 2
Brief History and OverviewWhat is LLM agents?A brief history of LLM agentsOn the future of LLM agentshttps://www.youtube.com/watch?v=RM6ZArd2nVc&list=PLS01nW3RtgopsNLeM936V4TNSsvvVglLc&index=4中文字幕较为准确
预备知识
英文缩写&术语
| 英语 | 简中 | 补充 |
|---|---|---|
| Large Language Model (LLM) | 大语言模型 | |
| Artificial General Intelligence (AGI) | 通用人工智能 | 一个远大的目标 |
| Agent | 智能体/代理 | |
| Embody | 具身 | |
| Multi-Agent System (MAS) | 多智能体系统 | |
| Token | 文本分割后得到的最小语义单位 | |
| Prompt | 提示词 | 我们向AI提出的问题或指令 |
| Reason | 推理 | 模型根据已有的知识,通过逻辑的推导得出结论 |
| align | 对齐 | 确保大语言模型的行为与用户的意图或期望一致 |
| Chain-of-Thought (CoT) | 让LLM通过(intermediate step)解决问题的技术 | |
| decode | 解码 | 将模型生成的内部表示转化为人类可读的文本的过程 |
| Universal Self-Consistency (USC) | 通用自一致性 | |
| Retrieval-Augmented Generation (RAG) | 检索增强生成 | 在生成模型中引入检索机制,使得模型能够在生成文本之前从外部知识库中检索相关信息 |
| Reinforcement Learning (RL) | 强化学习 | 智能体通过与环境进行交互,根据得到的奖励或惩罚来调整自己的行为,最终目标是最大化累计奖励 |
| Human-computer interface (HCI) | 人机界面 | |
| Agent-computer interface (ACI) |
Lecture 2, Shunyu Yao
Brief History and Overview
What is LLM agents?
A brief history of LLM agents
On the future of LLM agents
https://www.youtube.com/watch?v=RM6ZArd2nVc&list=PLS01nW3RtgopsNLeM936V4TNSsvvVglLc&index=4
中文字幕较为准确
评论区有人总结:
Chapter 1: Introduction (00:00 - 00:49)
-
Presenter: Shunyu Yao introduces LLM agents.
-
Goals: Discuss what LLM agents are, their history, and future directions.
-
Field complexity: The area is evolving, dynamic, and hard to fully define.
Chapter 2: What is an LLM Agent? (00:50 - 03:55)
-
Definition of Agent: An intelligent system interacting with an environment, physical or digital (robots, video games, chatbots).
-
LLM agents: Agents that use LLMs to interact and reason within a text-based environment.
-
Three agent categories:
-
Text agents (interact via language),
-
LLM agents (use LLMs for action),
-
Reasoning agents (LLMs reasoning before acting).
-
Chapter 3: Early Text Agents and Limitations (03:56 - 05:36)
-
Early rule-based agents (e.g., ELIZA, 1960s) were domain-specific and limited.
-
Later, reinforcement learning (RL) text agents emerged, but required extensive training and specific rewards.
Chapter 4: LLMs and Their Potential (05:37 - 07:48)
-
LLMs, trained via next-token prediction, generalize across tasks with minimal task-specific training.
-
GPT-3 (2020) marked the start of exploring LLMs in various reasoning and action tasks.
Chapter 5: LLM Agents’ History (07:49 - 09:06)
-
Historical perspective: Combining LLMs with reasoning (symbolic reasoning, acting tasks).
-
The field has grown to encompass web interaction, software engineering, and scientific discovery.
Chapter 6: Question-Answering and Reasoning Challenges (09:07 - 12:58)
-
Challenges with using LLMs for QA (e.g., outdated knowledge, complex computations).
-
Solutions:
-
Program generation for complex calculations.
-
Retrieval-Augmented Generation (RAG) for real-time knowledge retrieval.
-
Tool use: Invoke external tools like calculators or APIs for knowledge gaps.
-
Chapter 7: ReAct Paradigm (12:59 - 18:52)
-
ReAct: Combining reasoning and acting to improve task-solving by iterating thought and action.
-
Example: GPT-4 reasoning about purchasing companies by searching and calculating market caps.
-
Human-like reasoning: ReAct enables agents to adapt and improve reasoning in real-time.
Chapter 8: Limitations of Text-to-Action Mapping (18:53 - 23:00)
-
Challenges in video games: Mapping text observations directly to actions without thinking can lead to failure (e.g., imitating instead of reasoning).
-
ReAct’s advantage: Adding a thinking action allows for planning, reflection, and adaptive strategies.
Chapter 9: Long-Term Memory and Reflexion (23:01 - 33:22)
-
Short-term memory limits LLM agents (context window constraints).
-
Long-term memory: Reflexion introduces a way for agents to reflect on failures and improve over time.
-
Examples: Coding tasks with unit test feedback allow agents to persist knowledge across tasks.
Chapter 10: Broader Use of LLM Agents (33:23 - 37:53)
-
Applications beyond QA: LLM agents are being applied to real-world tasks like online shopping (WebShop) and software engineering (SWE-Bench).
-
ChemCrow example: LLM agents propose chemical discoveries, extending their impact into the physical realm.
Chapter 11: Theoretical Insights on Agents (37:54 - 43:41)
-
Traditional agents have a fixed action space (e.g., Atari agents).
-
LLM agents’ augmented action space: Reasoning allows for an infinite range of thoughts before acting, offering a more human-like approach.
Chapter 12: Simplicity and Abstraction in Research (43:42 - 54:23)
-
Simplicity: Simple concepts like chain of thought and ReAct are powerful because they are generalizable.
-
Importance of abstraction: Successful research involves both deep understanding of tasks and high-level abstraction.
Chapter 13: Future Directions (54:24 - 1:07:38)
-
Training: Models should be trained specifically for agent tasks to improve their performance in complex environments.
-
Interface: Optimizing the agent’s environment (e.g., file search commands) enhances performance.
-
Robustness: Agents must consistently solve tasks, not just occasionally succeed.
-
Human interaction: Agents need to work reliably with humans in real-world scenarios.
-
Benchmarking: Developing practical, scalable benchmarks for evaluating agents in real-life tasks.
Chapter 14: Summary and Lessons (1:07:39 - 1:08:38)
-
Key insights: LLM agents are transforming tasks across many domains.
-
The future of LLM agents involves tackling robustness, human collaboration, and expanding their applications into physical spaces.
What is "agent"?

幻灯片的原文如下:
-
What is "agent"?
-
An "intelligent" system that interacts with some "environment"
-
Physical environments: robot, autonomous car, ...
-
Digital environments: DQN for Atari, Siri, AlphaGo, ...
-
Humans as environments: chatbot
-
-
Define "agent" by defining "intelligent" and "environment"
-
It changes over time!
-
Exercise question: how would you define "intelligent"?
-
-
翻译:
-
什么是“智能体(agent)”?
-
一个与某种“环境”进行交互的“智能”系统
-
物理环境:机器人、自动驾驶汽车等
-
数字环境:用于Atari的DQN、Siri、AlphaGo等
-
人类作为环境:聊天机器人
-
-
通过定义“智能”和“环境”来定义“智能体”
-
它随着时间而变化!
-
练习问题:你会如何定义“智能”?
-
-
What is "LLM agent"?

幻灯片的原文如下:
-
What is "LLM agent"?
-
Level 1: Text agent
-
Uses text action and observation
-
Examples: ELIZA, LSTM-DQN
-
-
Level 2: LLM agent
-
Uses LLM to act
-
Examples: SayCan, Language Planner
-
-
Level 3: Reasoning agent
-
Uses LLM to reason to act
-
Examples: ReAct, AutoGPT
-
The key focus of the field and the talk
-
-
翻译:
-
什么是“LLM智能体”?
-
第一层次:文本智能体
-
使用文本行动和观察
-
示例:ELIZA, LSTM-DQN
-
-
第二层次:LLM智能体
-
使用大语言模型(LLM)来执行操作
-
示例:SayCan, 语言规划器
-
-
第三层次:推理智能体
-
使用大语言模型推理并行动
-
示例:ReAct, AutoGPT
-
本领域和讨论的重点
-
-
Text agent
-
Domain specific!
-
Requires scalar reward signals
-
Require extensive training
文本代理(Text Agent):
-
定义: 一种能够自主执行文本任务的 AI 模型。它可以理解、生成、并根据给定的目标或任务与用户或环境进行交互。
-
功能:
-
理解自然语言: 准确地理解用户指令或环境中的文本信息。
-
生成文本: 根据理解的内容,生成符合要求的文本回复、文章、代码等。
-
执行任务: 在文本环境中完成特定的任务,例如信息检索、对话、翻译等。
-
领域专业化(Domain Specific):
-
含义: 文本代理在特定领域(如医疗、法律、金融等)经过大量数据训练,使其具备该领域专业知识和技能。
-
优势:
-
准确性高: 能够更准确地理解和生成领域相关的文本。
-
效率高: 通过预训练,可以快速适应新的任务。
-
专业性强: 能够提供更专业、更深入的回答。
-
标量奖励信号(Scalar Reward Signals):
-
定义: 用于评估文本代理行为的单一数值。
-
作用:
-
强化学习: 通过不断调整模型参数,最大化累积奖励,从而实现模型的优化。
-
反馈机制: 提供模型行为的直接反馈,引导模型向目标方向发展。
-
-
示例:
-
对话系统:对话流畅度、信息准确性、用户满意度等。
-
文本摘要:摘要质量、信息覆盖率等。
-
大量训练(Extensive Training):
-
必要性: 文本代理需要大量高质量的训练数据,才能学习到复杂的语言模式和领域知识。
-
数据类型: 包括文本、代码、结构化数据等。
-
训练方式: 通常采用大规模预训练模型(如 GPT-3)进行微调,或者使用强化学习进行端到端的训练。
The promise of LLMs
Training: next-token prediction on massive text corpora
Inference: (few-shot) prompting for various tasks!
A brief history of LLM agent
LLM agent -> Reasoning agent
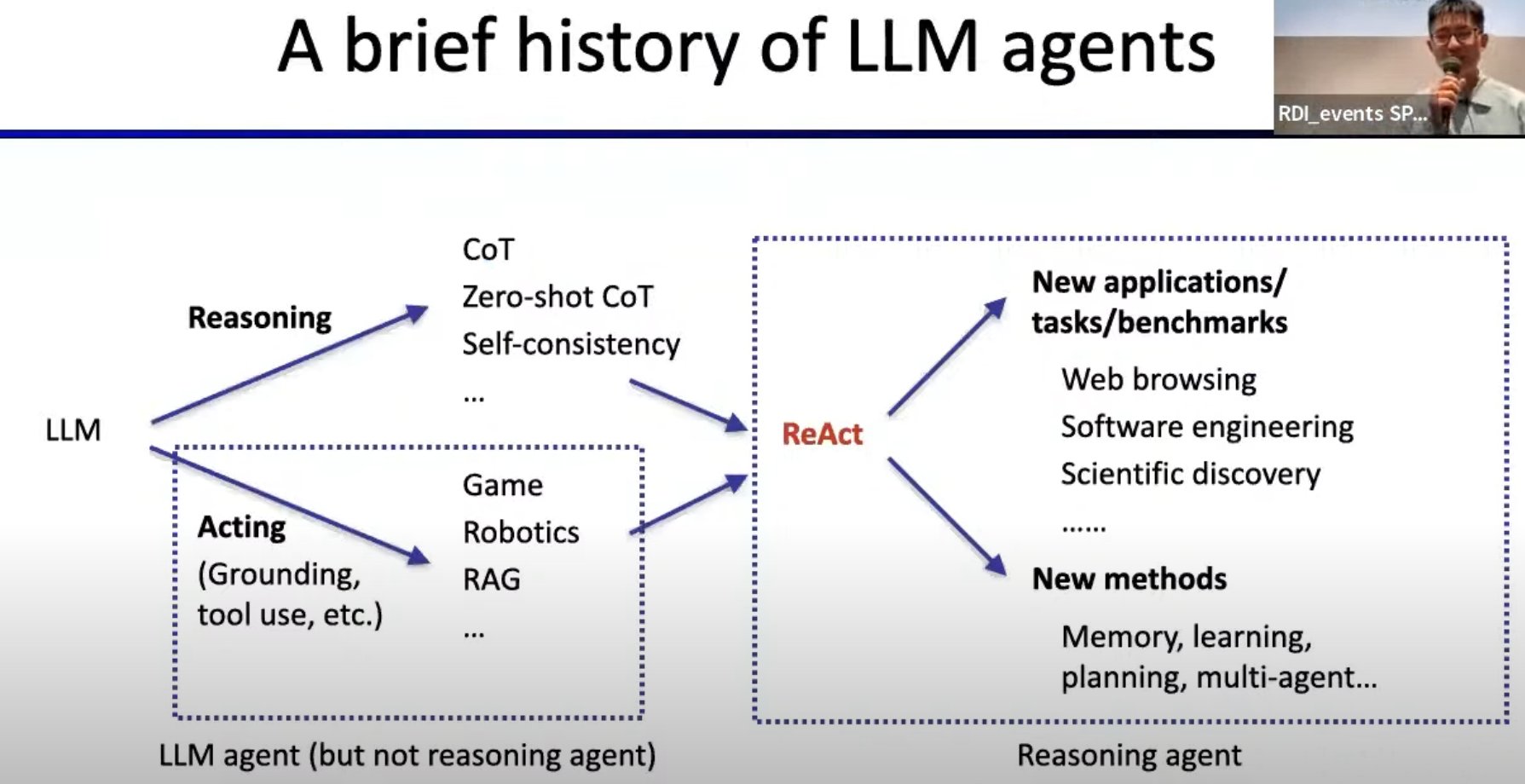
幻灯片的原文如下:
-
A brief history of LLM agents
-
Reasoning
-
CoT
-
Zero-shot CoT
-
Self-consistency
-
...
-
-
Acting
-
Grounding, tool use, etc.
-
Game
-
Robotics
-
RAG
-
...
-
-
LLM agent (but not reasoning agent)
-
ReAct
-
New applications/tasks/benchmarks
-
Web browsing
-
Software engineering
-
Scientific discovery
-
...
-
-
New methods
-
Memory, learning, planning, multi-agent
-
...
-
-
翻译:
-
LLM智能体的简史
-
推理
-
Chain of Thought (CoT, 思维链)
-
Zero-shot CoT(零次训练思维链)
-
自一致性
-
...
-
-
行动
-
基础、工具使用等
-
游戏
-
机器人
-
RAG(Retrieval-Augmented Generation, 检索增强生成)
-
...
-
-
LLM智能体(但不是推理智能体)
-
ReAct
-
新应用/任务/基准
-
网页浏览
-
软件工程
-
科学发现
-
...
-
-
新方法
-
记忆、学习、规划、多智能体
-
...
-
-
解释:
这张幻灯片提供了大语言模型(LLM)智能体的发展历史和未来趋势。重点分为推理和行动两个主要方面:
-
推理(Reasoning):包括思维链(CoT)、零次训练的思维链(Zero-shot CoT)以及自一致性等概念。这些技术帮助LLM智能体进行更复杂的推理任务。
-
行动(Acting):这一部分专注于智能体如何使用工具,执行游戏任务,或用于机器人和检索增强生成(RAG)等应用。此类智能体虽然有行动能力,但不具备高深度推理能力。
-
ReAct:这是一个新出现的框架,它结合了推理和行动的能力,将LLM智能体推向了一个新的发展阶段。
-
新应用和任务:幻灯片还列出了LLM智能体未来可能应用的领域,如网页浏览、软件工程、科学发现等。这表明LLM智能体正在扩展到更多实际应用领域。
-
新方法:新出现的研究方向包括如何让智能体具备记忆、学习、规划和多智能体协作能力,以进一步提高其智能水平。
RAG for knowledge

Retrieval-Augmented Generation,是一种结合了信息检索和生成模型的新型方法。它通过在生成模型中引入检索机制,使得模型能够在生成文本之前从外部知识库中检索相关信息,从而提升生成文本的质量、准确性和多样性。
核心思想:
-
检索相关信息: 当模型接收到一个问题或任务时,它会先从外部知识库(如维基百科、公司内部文档等)中检索与之相关的文本片段。
-
结合上下文生成: 将检索到的相关信息与原始输入一同输入到生成模型中,生成模型在生成文本时会参考这些额外的信息,从而生成更符合上下文、更准确的文本。
优势:
-
提高生成质量: 通过引入外部知识,模型能够生成更准确、更相关、更具信息量的文本。
-
增强模型泛化能力: 模型不再仅仅依赖于训练数据,能够处理更多样的任务和问题。
-
解决幻觉问题: 减少模型生成虚假或不真实信息的概率。
-
提高模型可解释性: 通过展示检索到的信息,可以更好地理解模型的生成过程。
应用场景:
-
问答系统: 提高回答的准确性和全面性。
-
文本摘要: 生成更精炼、更准确的摘要。
-
对话系统: 增强对话的连贯性和信息量。
-
内容生成: 自动生成新闻报道、产品描述等。
与传统生成模型的区别:
| 特点 | 传统生成模型 | RAG模型 |
|---|---|---|
| 知识来源 | 仅依赖训练数据 | 训练数据 + 外部知识库 |
| 生成过程 | 基于训练数据中的模式进行生成 | 在生成过程中引入检索到的相关信息 |
| 优势 | 生成多样性 | 生成质量、准确性、可解释性 |
Tool use
Special tokens to invoke(调用) tool calls for:
Search engine, calculator, etc.
Task-specific models (translation)
APIs
特殊标记用于调用工具:
-
搜索引擎、计算器等
-
任务特定模型(翻译)
-
API
工具使用(Tool Use):
-
直译: 工具使用
-
意译: 工具调用、工具辅助、工具集成
-
含义: 在大语言模型中,将外部工具(如搜索引擎、计算器、翻译模型等)集成进来,让模型能够在生成文本时调用这些工具,从而获取更准确、更全面的信息,提升生成结果的质量。
特殊标记(Special Tokens):
-
直译: 特殊标记
-
意译: 特殊符号、控制符
-
含义: 在文本中插入一些特殊的符号或序列,用于触发模型的特定行为,比如调用某个工具、切换到不同的模式等。这些标记通常是预定义的,模型在训练过程中学习到它们的含义。
模型调用(Model Calls for: Search engine, calculator, etc.):
-
直译: 模型调用(用于搜索引擎、计算器等)
-
意译: 模型调用外部工具、模型集成
-
含义: 当模型在生成文本时遇到需要计算、搜索或翻译等任务时,它会通过特定的标记或机制调用相应的工具或模型来完成这些任务。
举例:
Search Engine
Prompt: "What is the capital of Australia?"
Special Token: [SEARCH]
Model: Recognizes the [SEARCH] token and calls a search engine API. The API returns "Canberra" as the capital of Australia.
Response: "The capital of Australia is Canberra."
Calculator
Prompt: "How much is 500 divided by 7?"
Special Token: [CALC]
Model: Recognizes the [CALC] token and calls a calculator API. The API calculates the result.
Response: "500 divided by 7 equals approximately 71.43."
Task-Specific Model (Translation)
Prompt: "Translate 'Hello, how are you?' into French."
Special Token: [TRANSLATE]
Model: Recognizes the [TRANSLATE] token and calls a translation model. The model translates the text.
Response: "Bonjour, comment allez-vous?"
API
Prompt: "Get me the current weather in Tokyo."
Special Token: [WEATHER]
Model: Recognizes the [WEATHER] token and calls a weather API. The API retrieves the current weather data for Tokyo.
Response: "The current weather in Tokyo is sunny with a temperature of 25 degrees Celsius."
Note: The specific special tokens used may vary depending on the implementation. These examples illustrate the general concept of using special tokens to trigger tool calls within a large language model.
步骤:
-
自然语言输入
-
问题类型识别
-
特殊标记匹配
-
任务执行
-
结果输出
What if both knowledge and reasoning are needed?
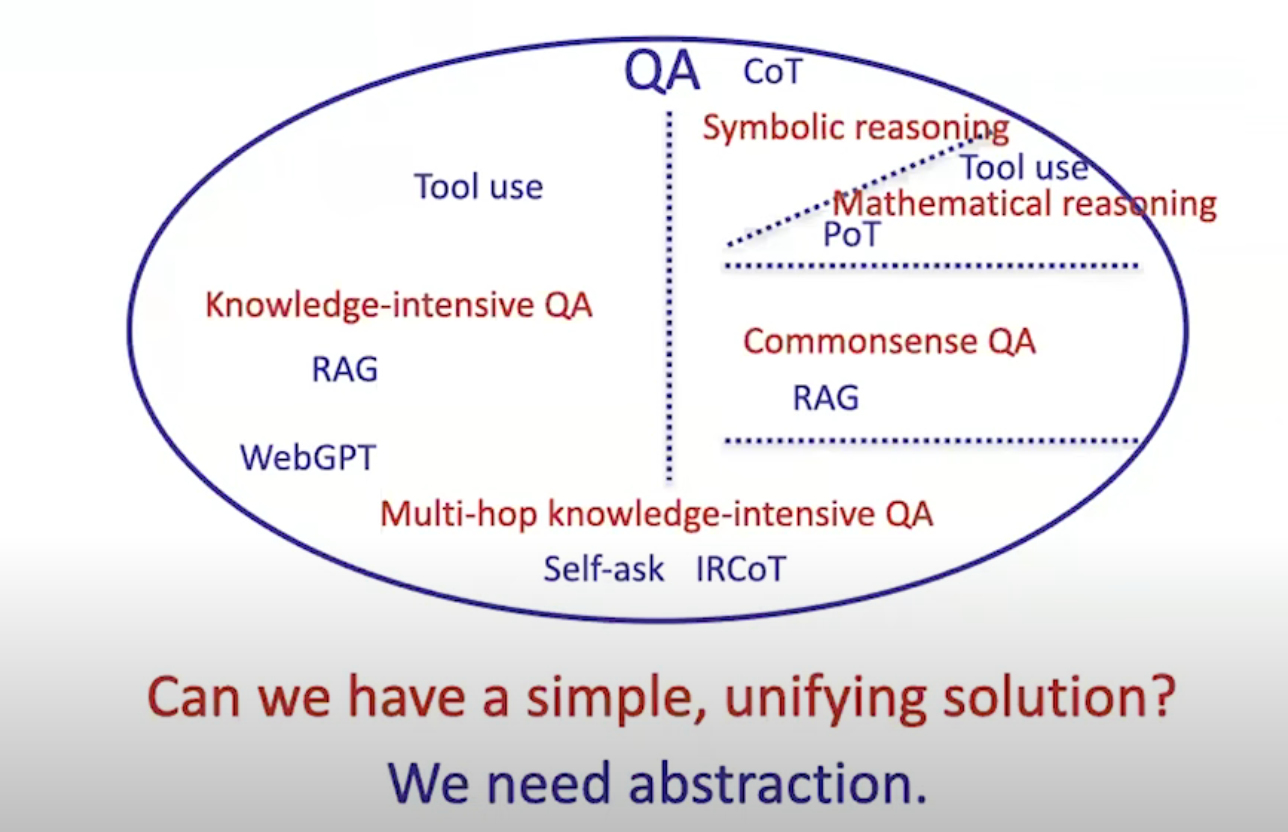
幻灯片的原文如下:
-
QA
-
Knowledge-intensive QA
-
Tool use
-
RAG
-
WebGPT
-
-
Symbolic reasoning
-
CoT
-
-
Mathematical reasoning
-
Tool use
-
PoT
-
-
Commonsense QA
-
RAG
-
-
Multi-hop knowledge-intensive QA
-
Self-ask
-
IRCOT
-
-
Knowledge-intensive 知识密集型
-
含义: 要求模型具备丰富的背景知识才能回答的问题。
-
例子: “为什么地球是圆的?”、“谁发明了电灯?”
-
Tool use 工具使用:指模型在回答问题时,可以调用外部工具(如搜索引擎、计算器)来获取信息。
-
RAG Retrieval-Augmented Generation:检索增强生成,即模型先从外部知识库中检索相关信息,然后结合这些信息生成答案。
-
WebGPT:OpenAI开发的一个大语言模型,能够通过搜索引擎获取实时信息,并将其整合到回答中。
Symbolic reasoning 符号推理
-
含义: 模型通过符号和逻辑规则进行推理,以解决问题。
-
例子: 推导数学定理、解决逻辑谜题。
-
CoT Chain-of-Thought:思维链,即模型在推理过程中,会逐步生成中间步骤,最终得出结论。
Mathematical reasoning 数学推理
-
含义: 模型能够进行数学计算和证明。
-
例子: 解方程、证明几何定理。
-
Tool use 工具使用:与Knowledge-intensive QA类似,模型可以调用计算器等工具进行数学计算。
-
PoT Proof-of-the-Theorem:定理证明,指模型能够证明数学定理。
Commonsense 常识
-
含义: 人类在日常生活中习得的、不言自明的知识。
-
例子: “鸟会飞”、“水往低处流”。
-
RAG
Multi-hop knowledge-intensive 多跳知识密集型
-
含义: 需要通过多个信息来源或推理步骤才能回答的问题。
-
例子: “谁是诺贝尔文学奖得主中最年轻的人?”(需要先找到诺贝尔文学奖得主名单,再比较他们的年龄。)
-
Self-ask 自问自答:模型在回答问题时,会主动提出一些子问题,并尝试回答这些子问题,以最终得出答案。
-
IRCOT Iterative Retrieval and Chain-of-Thought:迭代检索和思维链,结合了RAG和CoT的优点,通过多次迭代检索和推理来回答复杂问题。
abstract of Reasoning or Acting
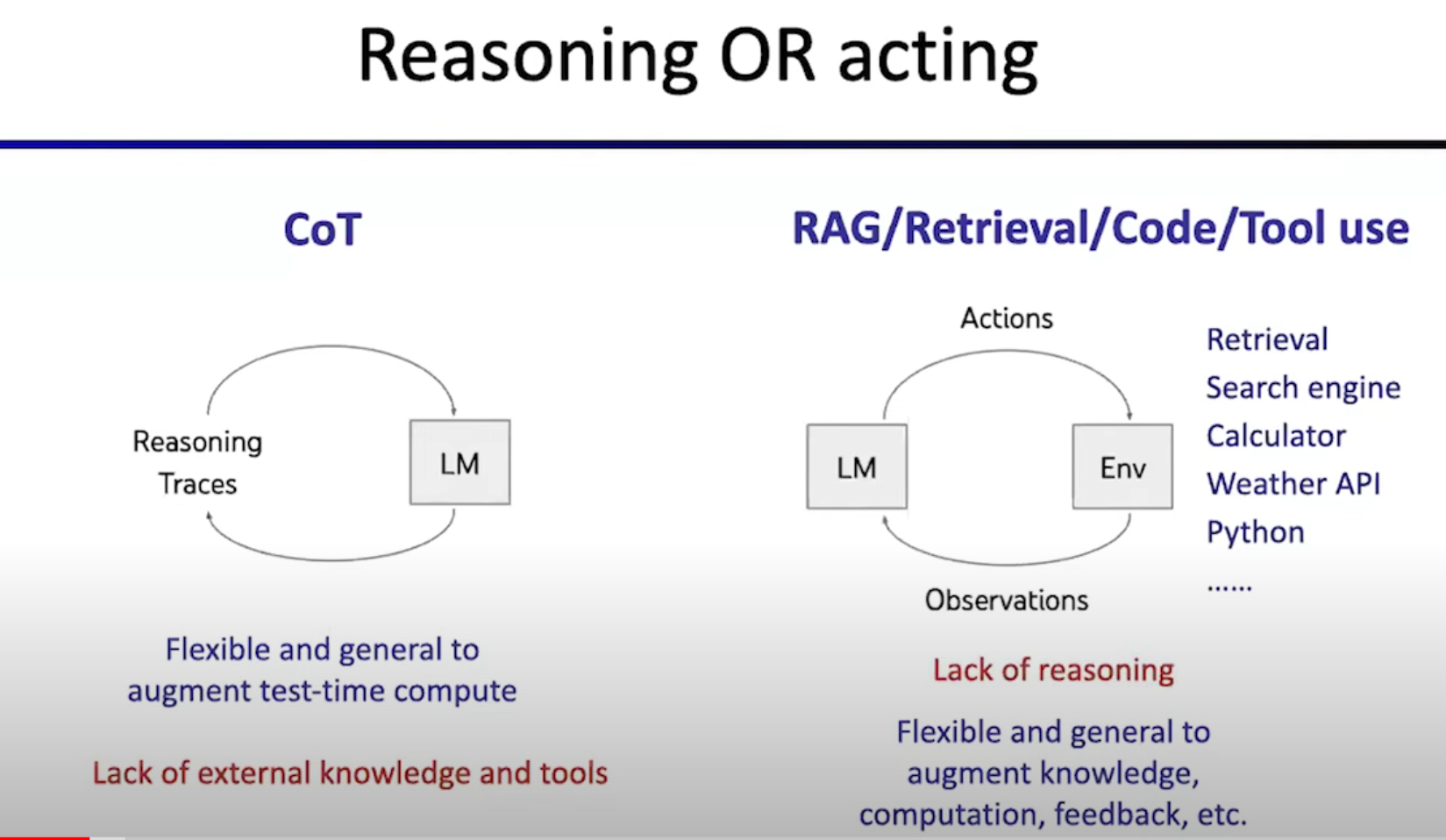
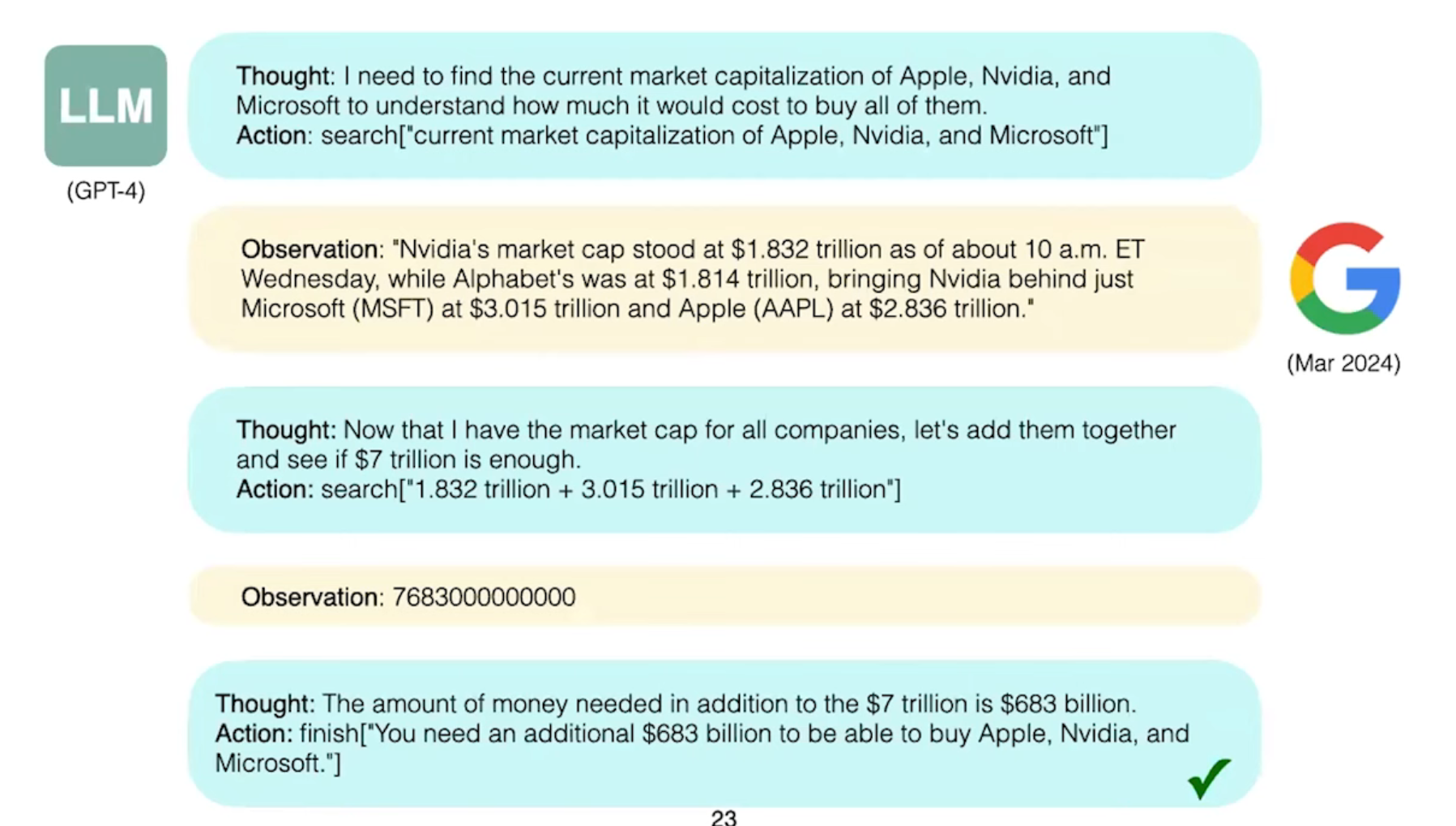
ReAct = Reasoning + Acting
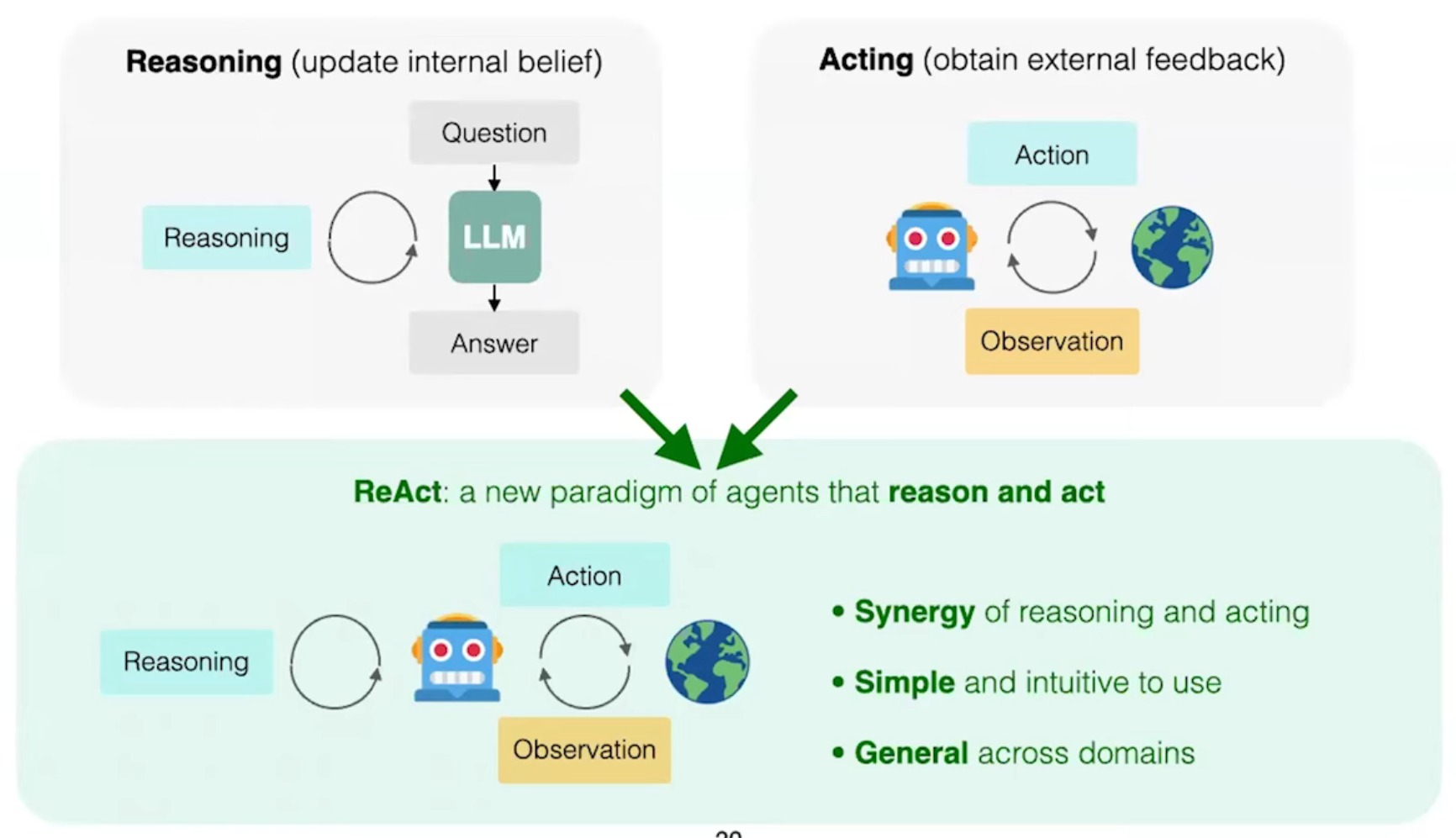
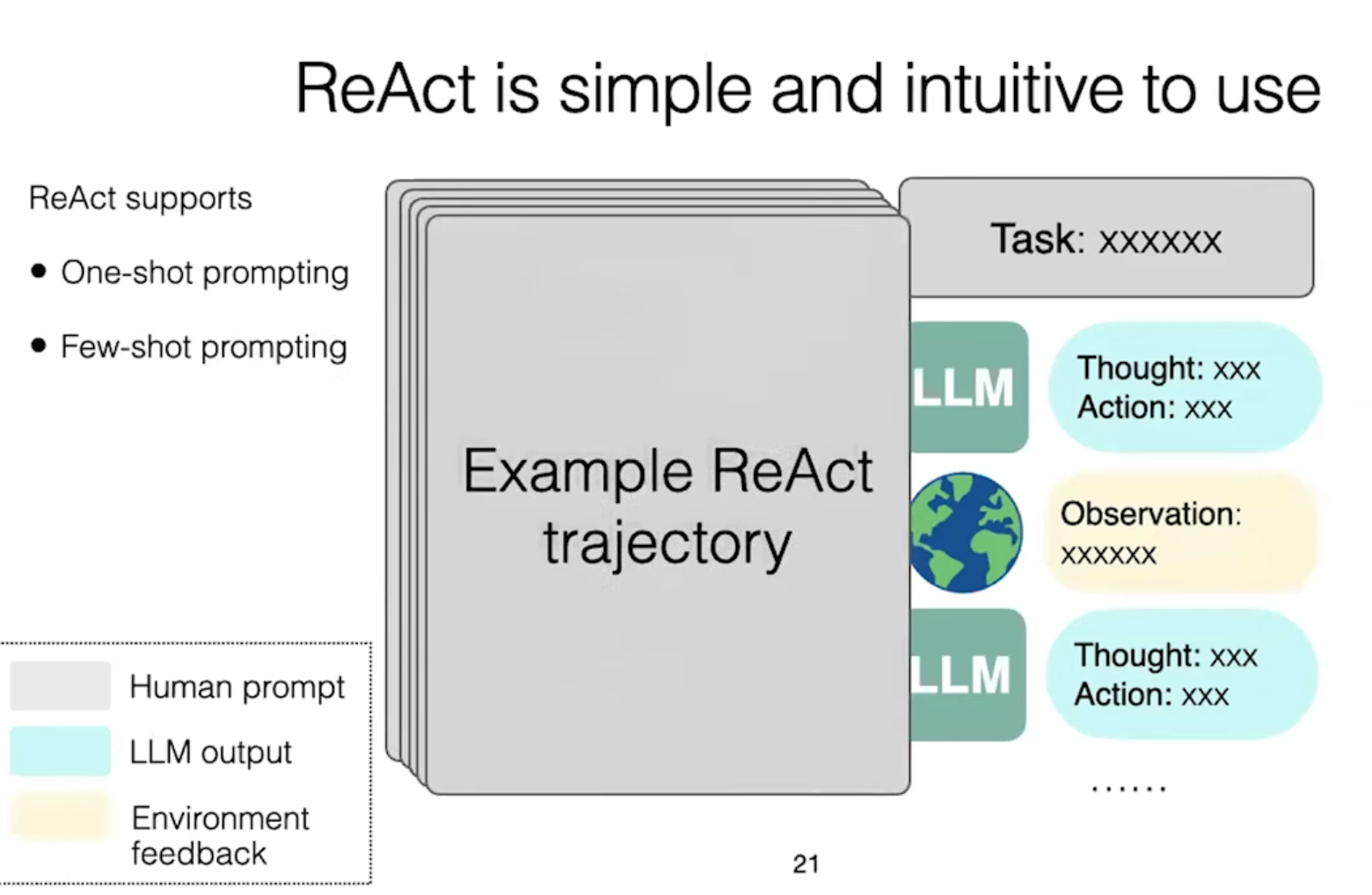
ReAct is simple and intuitive to use
intuitive易懂的
流程:
人类输入:task
模型生成:thought + action
action被模型输入到外部环境中产生:observation
thought + action + observation 附加到模型的上下文:thought_2 + action_2
循环...
例子:



Many tasks can be turned into text games
一个伟大的idea:将ReAct范式可以应用到其他领域











ReAct Enables Systematic Exploration



Reasoning agent: reasoning is an internal action for agents




long-term memory
几个项目:
Reflexion: Language Agents with Verbal Reinforcement Learning
Also check: Self-refine, Self-debugging, etc.
VOYAGER: An Open-Ended Embodied Agent with Large Language Models
Generative Agent: Interactive Simulacra of Human Behavior
Generative Agent
Episodic memory of experience
Semantic memory of (reflective) knowledge
Cognitive architrctures for language agrnts (CoALA)
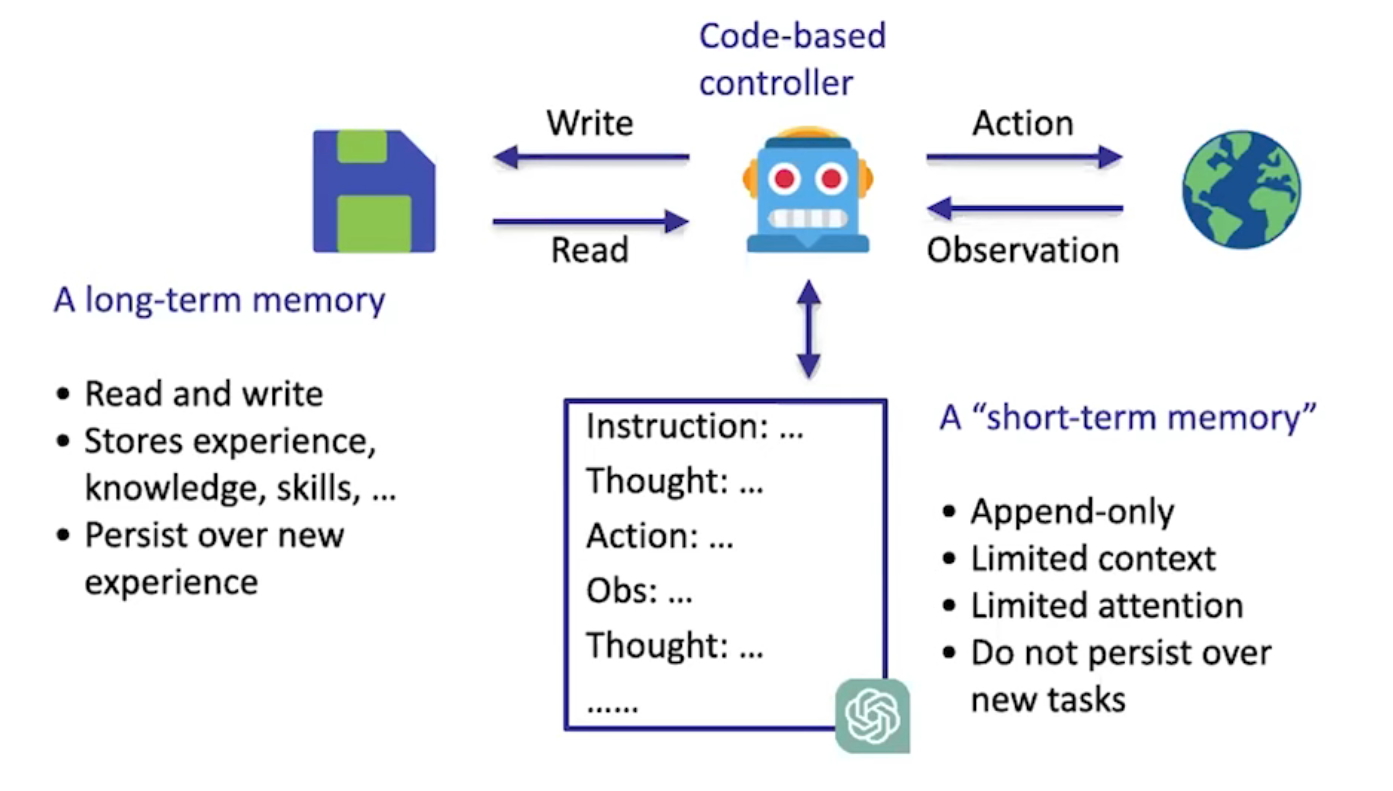
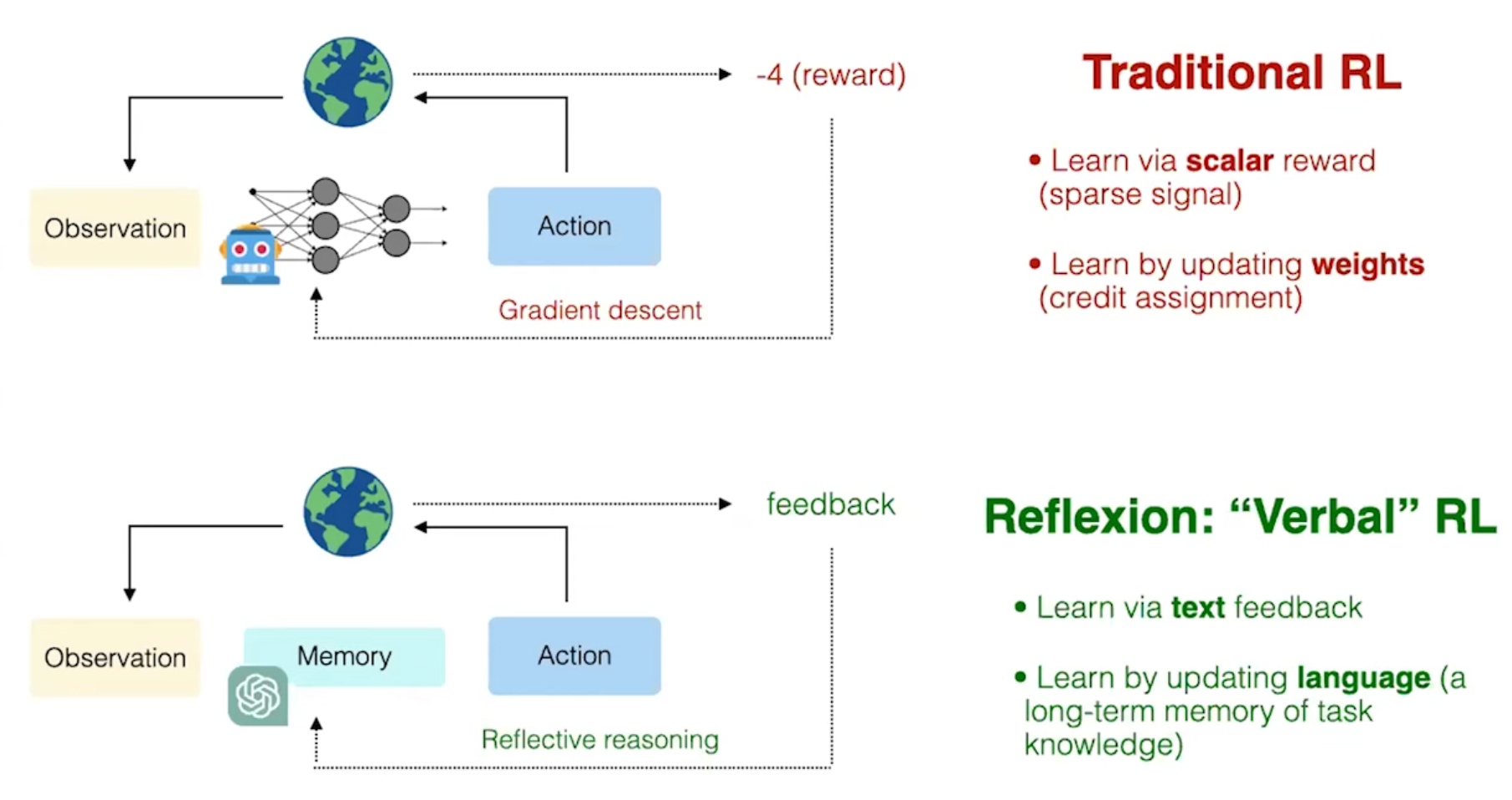
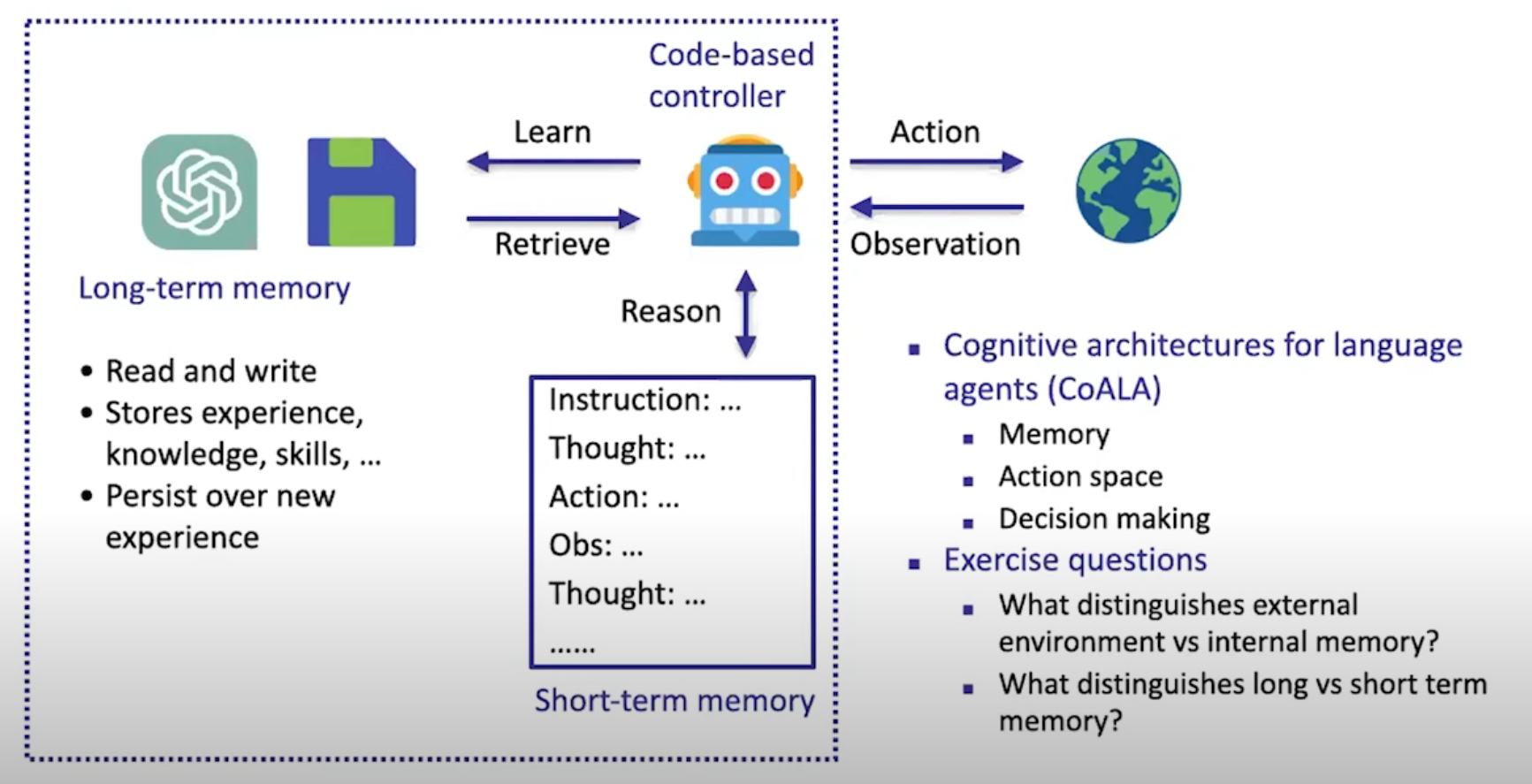
幻灯片的原文如下:
Long-term memory
-
Read and write
-
Stores experience, knowledge, skills, ...
-
Persist over new experience
Short-term memory
Code-based controller
-
Learn
-
Retrieve
-
Reason
-
Action
Cognitive architectures for language agents (CoALA)
-
Memory
-
Action space
-
Decision making
Exercise questions
-
What distinguishes external environment vs internal memory?
-
What distinguishes long vs short term memory?
翻译:
长期记忆
-
读写能力
-
储存经验、知识、技能等
-
在新体验中持续保存
短期记忆
基于代码的控制器
-
学习
-
检索
-
推理
-
行动
语言代理的认知架构(CoALA)
-
记忆
-
行动空间
-
决策制定
练习问题
-
外部环境与内部记忆的区别是什么?
-
长期记忆和短期记忆的区别是什么?
解释:
这张幻灯片描述了大语言模型(LLM)智能体的认知架构和其核心组件。
-
长期记忆(Long-term memory):类似于人类的大脑,长期记忆部分能够读取和写入信息,储存模型的经验、知识和技能,并且在新的体验中持续保存。这意味着模型不仅能够记住过去的经验,还能在未来的任务中加以利用。
-
短期记忆(Short-term memory):这是模型在短时间内处理信息和执行任务的能力。短期记忆一般用于处理当前任务的步骤和推理过程,如接受指令、思考、执行行动并观察结果。
-
基于代码的控制器(Code-based controller):这是模型的核心逻辑控制单元,它管理学习、检索和推理过程,并且执行任务中的具体行动。通过观察外部环境和获取反馈,控制器能够不断调整模型的行为。
-
语言代理的认知架构(CoALA):这是一个专门针对语言智能体设计的认知架构,主要包括记忆、行动空间和决策制定等模块。记忆模块存储信息,行动空间决定智能体能够执行的动作,而决策制定则是在不同选择之间进行权衡,决定智能体的行为。
-
练习问题(Exercise questions):两个提出的问题用于帮助进一步思考语言智能体的认知架构。
-
第一个问题是关于外部环境与内部记忆的区分,即智能体如何处理来自外部的感知数据与其内部储存的信息。
-
第二个问题涉及长期记忆与短期记忆的差异,即如何在处理当前任务时有效利用长期存储的经验和短期存储的即时信息。
-
Some lessons for research
-
Simplicity and generality
-
You need both...
-
Thinking in abstraction
-
Familiarity with tasks (not tasks-specific methods!)
-
-
Learning history and other subjects helps!
-
简单性和通用性
-
你两者都需要。。。
-
抽象思维
-
熟悉任务(不是特定任务的方法!)
-
-
学习历史和其他科目会有所帮助!
What's next
55:47
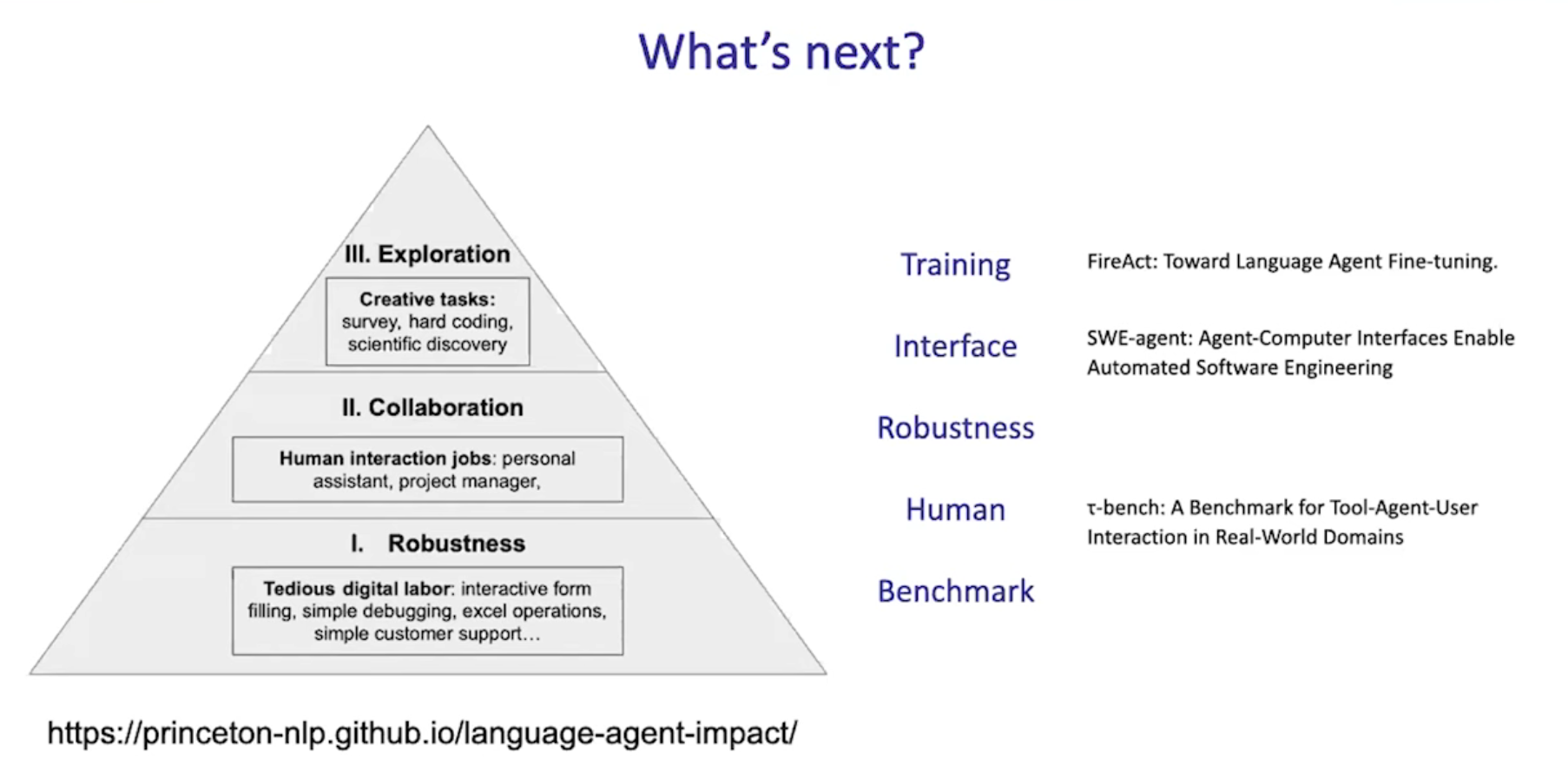




Training
FireAct: Training LLM for agents
如何训练用于agents的模型?
在哪里获得数据?
现在,研究LLM和研究Agent的人仍然是分开的,这是不对的,模型需要针对Agent进行训练。就像GPU和DL,模型和agent之间的协同作用应该加强。

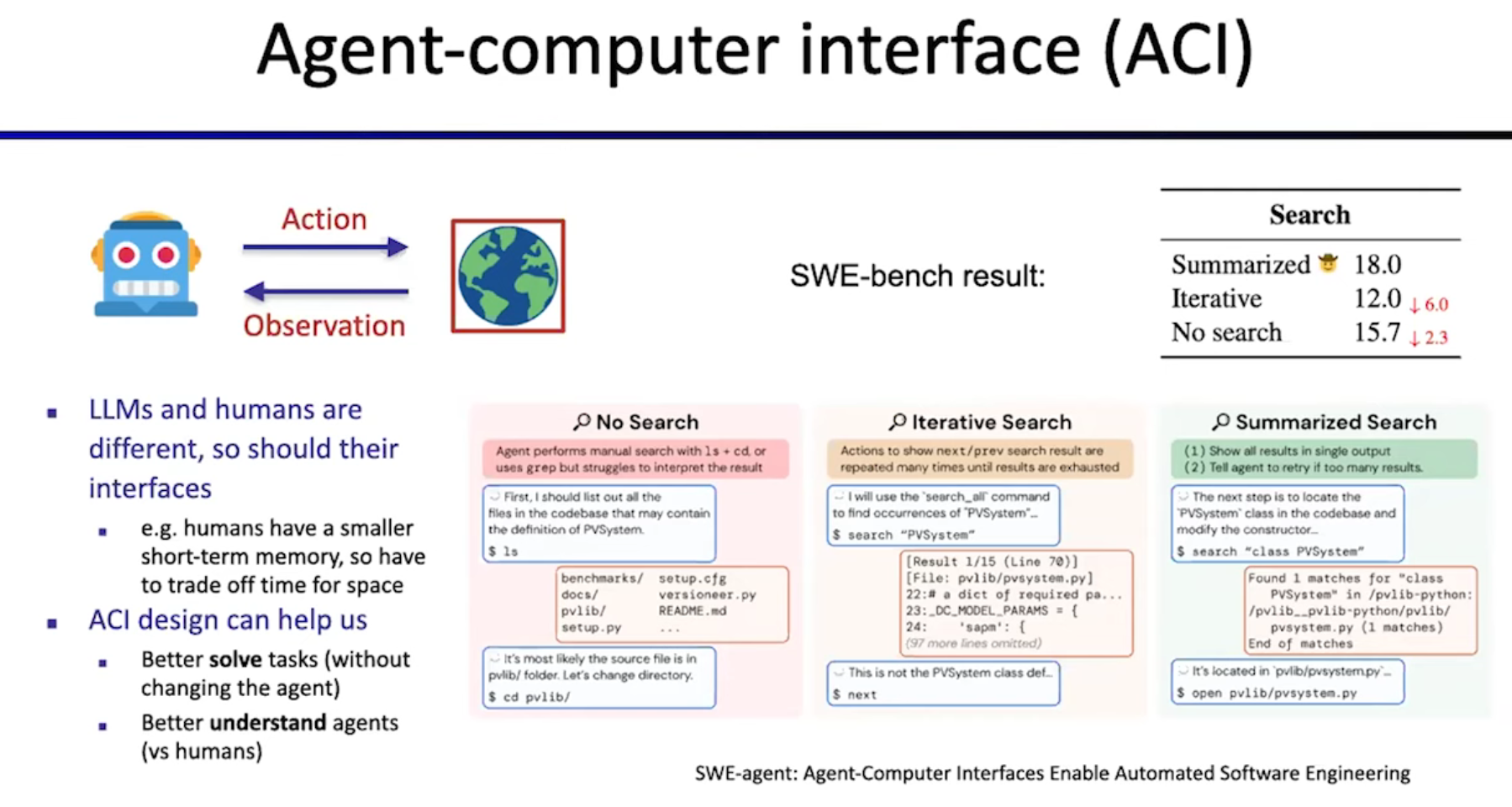
Interface
Human-computer interface (HCI)
Agent-computer interface (ACI)
如何为我们的LLM agents构建一个环境?
idea: 如果无法优化agent,则可以优化环境
Robustness
如何确作品在现实世界中有效?
Human
如何确保作品在现实世界中与人类工作?
Benchmark
基准测试(benchmarking)是一种通过运行一系列标准测试和试验,来评估计算机程序、一组程序或其他操作的相对性能的方法。简单来说,就是用一个统一的标准去测量不同事物(如电脑、软件、算法)的性能,看看谁更好。
怎样建立良好的基准测试?
现有的基准测试和现实中人们真正关心的东西之间存在很大差异
还需要将更多现实世界的元素纳入基准测试中,且需要新的指标
未完待续。。。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)